Monitorando o Serviço Oracle NoSQL Database Cloud
O serviço Oracle Cloud Infrastructure Monitoring permite que você monitore ativa e passivamente seus recursos de nuvem usando os recursos Métricas e Alarmes. O serviço Monitoring usa métricas para monitorar recursos e alarmes a fim de notificá-lo quando essas métricas atendem a acionadores especificados por alarme.
Métrica é uma medida relacionada à integridade, capacidade ou desempenho de um determinado recurso. Um alarme é uma regra de acionamento e uma consulta. Os alarmes monitoram passivamente seus recursos de nuvem usando métricas. Você pode configurar definições de notificação ao criar um alarme.
As medições são emitidas para o serviço Monitoring como pontos de dados brutos (um par de timestamp/valor para uma métrica especificada) juntamente com dimensões (um identificador de recurso fornecido na definição da métrica) e metadados. O serviço Monitoring publica mensagens de alarme em destinos configurados gerenciados pelo serviço Notifications.
Quando você consulta uma métrica, o serviço Monitoring retorna dados agregados de acordo com os parâmetros especificados. Você pode especificar um intervalo (como as últimas 24 horas), uma estatística e um intervalo. Uma estatística é a função de agregação aplicada aos pontos de dados brutos. A função de agregação SUM é um exemplo de estatística. Intervalo é o intervalo de tempo usado para converter um determinado conjunto de pontos de dados brutos. Por exemplo, 5 minutos.
A Console exibe um gráfico de monitoramento por métrica para os recursos selecionados. Os dados agregados em cada gráfico refletem a estatística e o intervalo selecionados. As solicitações de API podem filtrar por dimensão e especificar uma resolução. As respostas de API incluem o nome da métrica com seu compartimento de origem e namespace de métricas (indica o recurso, o serviço ou o aplicativo que emite uma métrica). O namespace é fornecido na definição da métrica. Por exemplo, a definição da métrica de CpuUtilization emitida pelo Oracle Cloud lista o namespace de métricas oci_computeagent como a origem da métrica.
Os dados da métrica e do alarme podem ser acessados pela Console, CLI e API. Para obter mais informações sobre conceitos do serviço OCI Monitoring, consulte Conceitos do Serviço Monitoring.
Este artigo tem os seguintes tópicos:
Métricas do Oracle NoSQL Database Cloud Service
O Oracle NoSQL Database Cloud Service emite métricas usando o namespace de métricas oci_nosql.
As métricas do Oracle NoSQL Database Cloud Service incluem as seguintes dimensões:
RESOURCEIDO OCID da Tabela NoSQL no Oracle NoSQL Database Cloud Service.
Observação: O OCID é um ID exclusivo designado pela Oracle que é incluído como parte das informações do recurso na console e no API.
-
TABLENAMEO nome da tabela noSQL no Oracle NoSQL Database Cloud Service.
-
REPLICAO nome da região que recebe a atualização da tabela de outra região.
O Oracle NoSQL Database Cloud Service envia métricas para o Oracle Cloud Infrastructure Monitoring Service. Você pode exibir ou criar alarmes nessas métricas usando os SDKs ou a CLI da Console do Oracle Cloud Infrastructure.
Tabela - Métrica do Oracle NoSQL Database Cloud Service
| Métrica | Nome de Exibição da Métrica | Unidade | Descrição | Dimensões |
|---|---|---|---|---|
ReadUnits |
Unidades de Leitura | Unidades | O número de unidades de leitura consumidas durante esse período. | resourceId tableName |
WriteUnits |
Unidades de Gravação | Unidades | O número de unidades de gravação consumidas durante esse período. | resourceId tableName |
StorageGB |
Tamanho do Armazenamento | GB | O volume máximo de armazenamento consumido pela tabela. Como essas informações são geradas a cada hora, você pode ver valores desatualizados entre os pontos de atualização. | resourceId tableName |
ReadThrottleCount |
Limite de Leitura | Count | O número de exceções de limite de leitura nesta tabela no período. | resourceId tableName |
WriteThrottleCount |
Limite de Gravação | Count | O número de exceções de limitação de gravações nesta tabela no período. | resourceId tableName |
StorageThrottleCount |
Limitação de Armazenamento | Count | O número de exceções de limite de armazenamento nesta tabela no período. | resourceId tableName |
MaxShardSizeUsagePercent |
Uso Máximo do Tamanho do Shard | Porcentagem | A proporção do espaço usado no shard sobre o espaço total alocado para o shard. Isso é específico de uma tabela e será o valor mais alto em todos os shards. | resourceId tableName |
Replica Lag |
Atraso na Réplica | Milissegundo | Um intervalo de tempo na replicação das alterações de dados de uma tabela Global Ativa de uma região do remetente para uma região do recebedor. | |
Além disso, você pode publicar métricas personalizadas de acordo com sua necessidade. Por exemplo, você pode configurar métricas para capturar a latência da transação da aplicação (tempo gasto por transação concluída) e, em seguida, lançar esses dados no serviço Monitoring.
Explicação das Métricas do NDCS
O Oracle NoSQL Database Cloud Service envia métricas para o Oracle Cloud Infrastructure Monitoring Service.
Unidades de Leitura:
O número de unidades de leitura consumidas durante esse período. É a taxa de transferência de até 1 KB de dados por segundo para uma operação eventualmente consistente de leitura. Se os seus dados tiverem mais de 1 KB, serão necessárias várias unidades de leitura para lê-los. O gráfico de métricas Unidade de Leitura de uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.
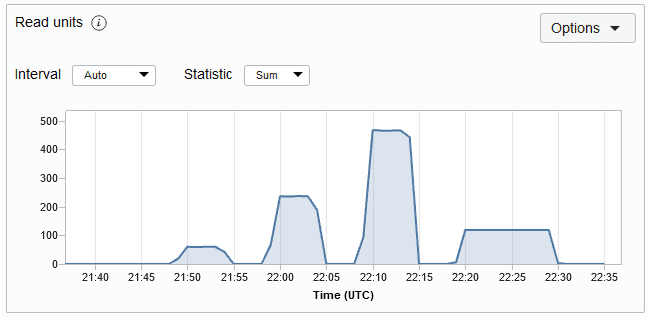
Descrição da ilustração readmetric.png
Unidades de Gravação:
O número de unidades de gravação consumidas durante esse período. É a taxa de transferência de até 1 KB de dados por segundo para uma operação da gravação. As operações de gravação são acionadas durante as operações de inserção, atualização e exclusão. Se os seus dados tiverem mais de 1 KB, serão necessárias várias unidades de leitura para gravá-los. O gráfico de métricas Unidade de Gravação de uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.
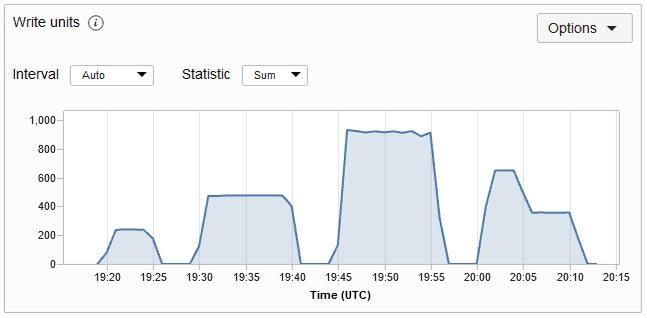
Descrição da ilustração writeremetric.png
StorageGB:
O volume máximo de armazenamento consumido pela tabela. O gráfico de métricas de Armazenamento de uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.
Observação: leva uma hora após a criação da tabela para pré-implantação do início do rastreamento do tamanho do armazenamento. Após a hora inicial, as estatísticas de armazenamento são atualizadas a cada 5 minutos.
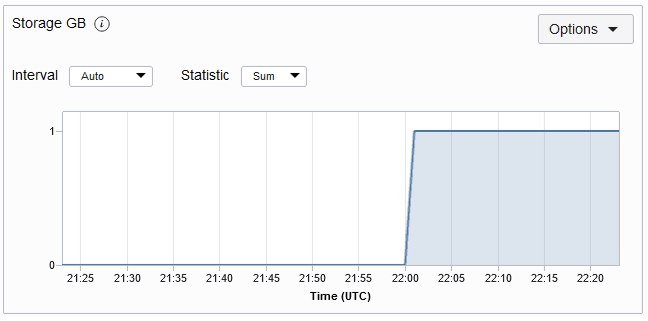
Descrição da ilustração almofadaetric.png
Observação: A métrica GB de armazenamento é truncada. Portanto, o uso de armazenamento inferior a 1 GB será exibido como 0. O gráfico começará a exibir o armazenamento quando o uso for maior que 1 GB.
ReadThrottleCount:
Isso fornece uma contagem do número de exceções de limitação de leitura na tabela fornecida no período. Uma exceção de limitação geralmente indica que o throughput de leitura provisionado foi excedido. Se você obtê-los com frequência, então você deve considerar aumentar as Unidades de Leitura em sua tabela. O gráfico de métricas de contagem de aceleradores de Leitura de uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.

Descrição da ilustração readthrottlemetric.png
WriteThrottleCount:
Isso fornece uma contagem do número de exceções de limitação de gravação na tabela fornecida no período. Uma exceção de limitação geralmente indica que o throughput de gravação provisionado foi excedido. Se você obtê-los com frequência, então você deve considerar aumentar as Unidades de Gravação em sua tabela. O gráfico de métricas de contagem de aceleradores de Gravação para uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.
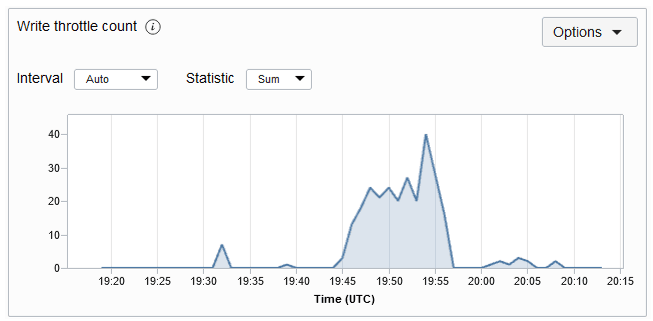
Descrição da ilustração writethrottlemetric.png
StorageThrottleCount:
Isso fornece uma contagem do número de exceções de limitação de armazenamento na tabela fornecida no período. Uma exceção de limitação geralmente indica que a capacidade de armazenamento provisionada foi excedida. Se você obtê-los com frequência, considere aumentar a capacidade de armazenamento da sua tabela. O gráfico de métricas de contagem de aceleradores de armazenamento para uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.
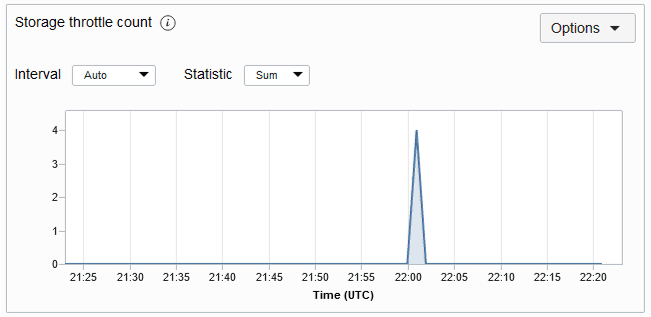
Descrição da ilustração storagethrottlemetric.png
MaxShardSizeUsagePercentual
O uso mais alto do espaço em um shard para uma tabela específica, como uma porcentagem do espaço usado nesse shard.
Observação: O Oracle NoSQL Database Cloud Service hashes keys to shards to provide distribution over a collection of storage nodes that provide storage for the tables. Embora não estejam diretamente visíveis para você, as tabelas do Oracle NoSQL Database Cloud Service são fragmentadas e replicadas para obter disponibilidade e desempenho. Uma chave de shard 100% corresponde à chave primária ou é um subconjunto da chave primária. Todos os registros que compartilham uma chave de shard estão co-localizados para atingir a localidade de dados.
Quando maxShardSizeUsagepercent atingir 100, você não poderá mais fazer uma operação de gravação na tabela. Você precisa aumentar a capacidade de armazenamento para executar uma gravação na tabela. Essa métrica ajuda a determinar se existe um ponto de acesso de armazenamento para sua tabela NoSQL.
Esse cenário acontece por causa de um desequilíbrio na forma como os dados da tabela são armazenados nos shards. Um desequilíbrio pode ocorrer quando a maioria dos dados da tabela é armazenada em um subconjunto dos shards. O armazenamento em um banco de dados NoSQL é particionado e a chave de partição faz parte da definição da tabela. Em tabelas hierárquicas, as tabelas pai e filho compartilham a mesma chave de partição. Se você tiver uma tabela pai com tabelas filho, todos os registros compartilharão a mesma chave de partição. Todos esses dados serão armazenados juntos. Se uma tabela pai tiver menos filhos, ela ocupará menos espaço de armazenamento em um único shard. Devido a esse desequilíbrio, certos shards podem conter muito mais dados do que outros shards.
Em um determinado ponto, um shard terá o uso mais alto de espaço para uma tabela específica e a porcentagem usada nesse shard será MaxShardSizeUsagePercent. O gráfico de métricas maxShardSizeUsagepercent de uma tabela é mostrado abaixo. A métrica é obtida a cada minuto e os gráficos de métricas são plotados para um intervalo de 5 minutos por padrão.
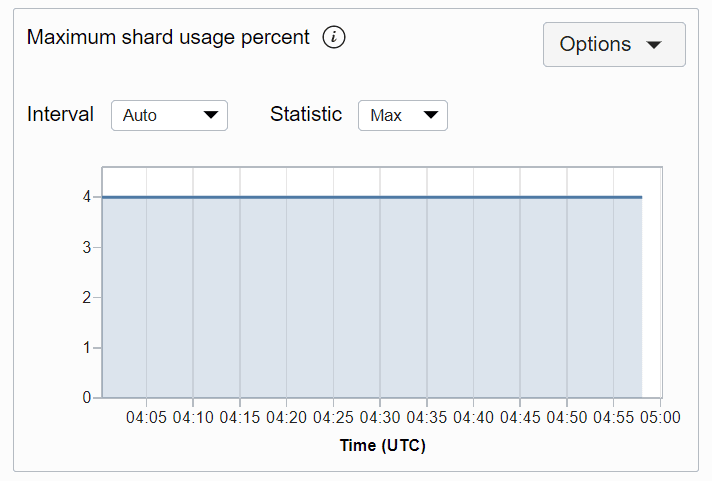
Descrição da ilustração maxshardusageprct.png
Além de visualizar o gráfico de uma métrica, você tem as seguintes opções.
Descrição da ilustração métrico-options.png
Você pode obter a view de tabela para verificar o valor de uma métrica em um determinado momento.
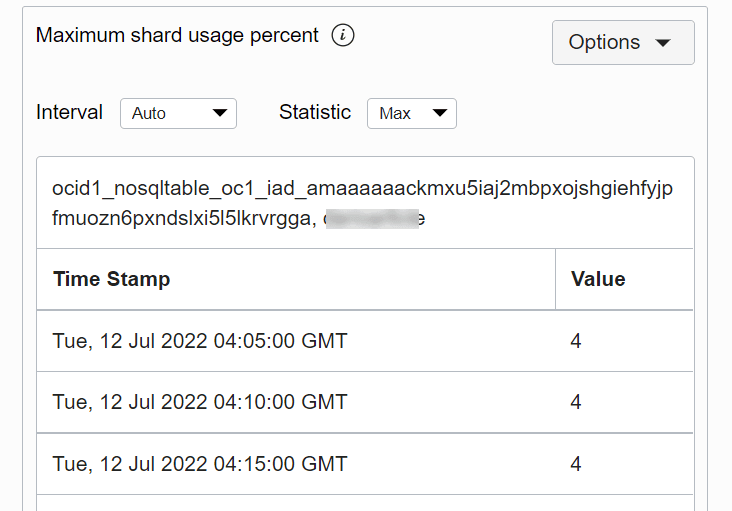
Descrição da ilustração tableview.png
Monitorando a métrica MaxShardSizeUsagePercent
Você precisa monitorar periodicamente esse gráfico para saber se o maxShardSizeUsagepercent foi atingido ou não. Proativamente, você pode criar um alarme para essa métrica.
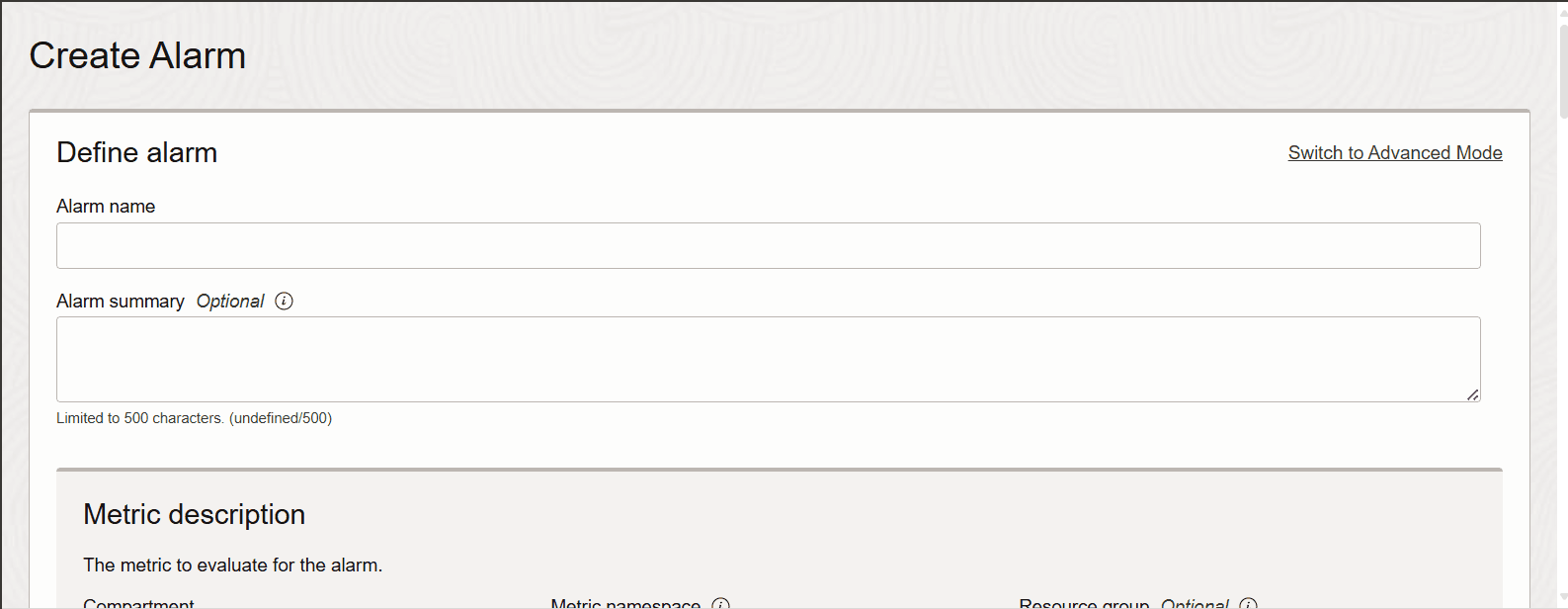
Descrição da ilustração new-alarm-crt-1.png
Ou seja, você deve acionar um alarme quando a métrica atingir um valor específico, por exemplo, 90%.
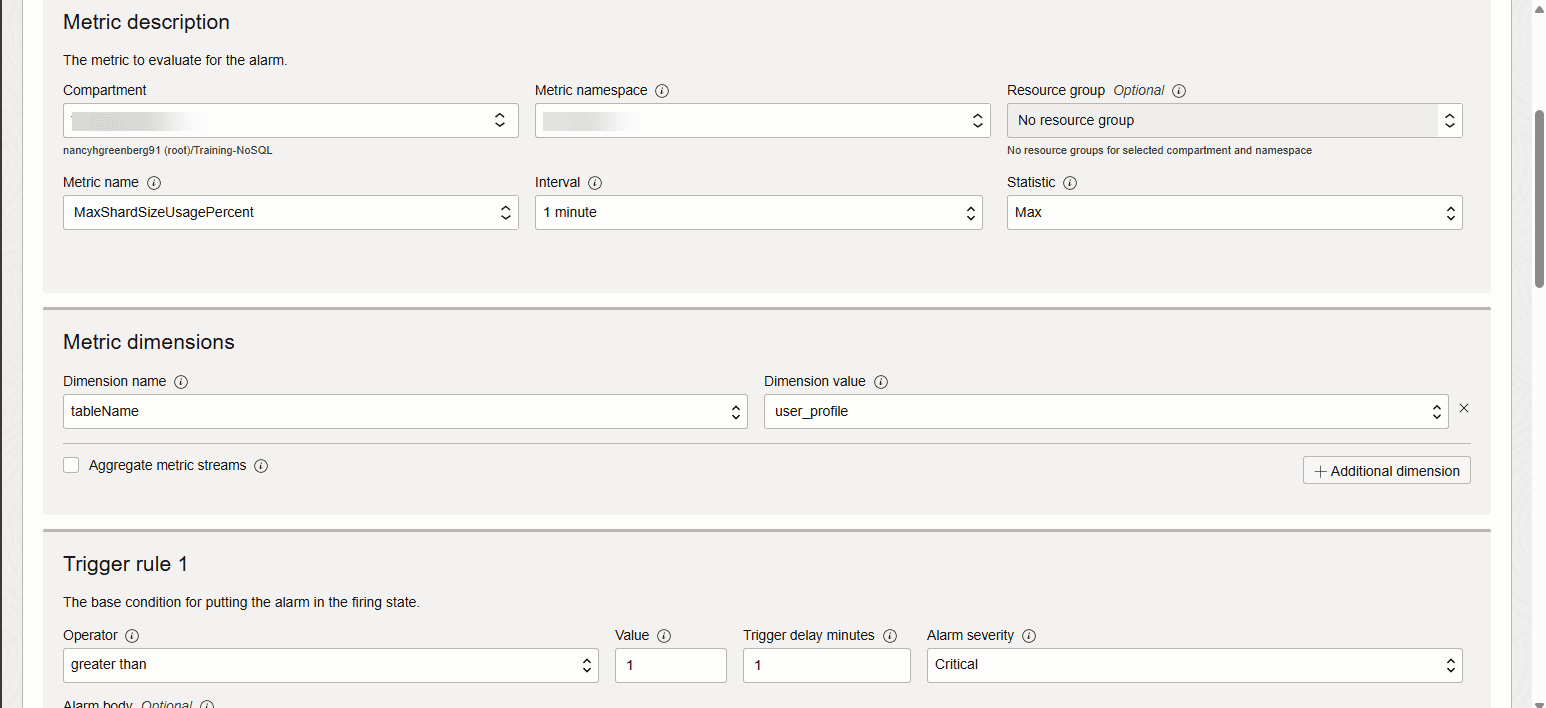
Descrição da ilustração new-alarm-crt-2.png
O alarme da OCI usa o serviço de notificação da OCI para enviar notificações. Normalmente, o alarme será configurado para enviar notificações por email configurado. Quando o maxShardSizeUsagepercent atinge 90%, uma notificação por e-mail é enviada.
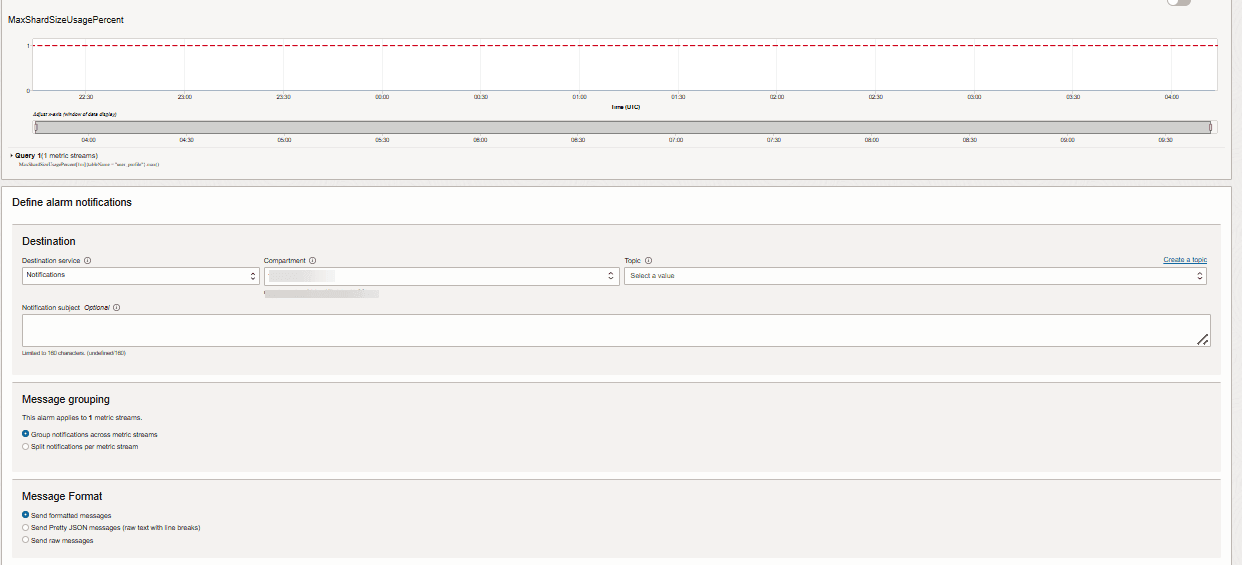
Descrição da ilustração new-alarm-crt-3.png
Consulte Gerenciando Alarmes e Notificações para obter mais detalhes.
Quando houver um desequilíbrio na forma como os dados da sua tabela são distribuídos entre shards, você não poderá utilizar a capacidade de armazenamento alocada à sua tabela ao máximo. Neste cenário, maxShardSizeUsagepercent atinge o valor de 100 mesmo sem utilizar todo o armazenamento alocado para a tabela. Agora você precisa adicionar mais armazenamento para continuar gravando na sua tabela. Esse cenário pode ser evitado seguindo algumas diretrizes ao projetar sua tabela.
-
Decida a chave de partição correta para sua tabela. Os atributos com alta cardinalidade são uma boa escolha para chaves de partição.
-
Limite o número de tabelas filho para evitar uma possível situação de desequilíbrio de armazenamento de shards.
Atraso na Réplica
Um intervalo de tempo na replicação das alterações de dados (INSERT/UPDATE ou DELETE) de uma tabela Global Ativa de uma região do remetente para uma região do recebedor. A operação de gravação que aconteceu na região do remetente de uma tabela Global Ativa é refletida na região do receptor após um intervalo de tempo. As informações sobre o intervalo de tempo são expressas como uma métrica chamada Atraso de Réplica. O atraso de réplica é uma medida da atualidade dos dados da tabela na região de replicação do receptor, em relação aos dados na tabela da região do remetente. A defasagem de réplica indica que a tabela na região do receptor ainda não recebeu atualizações da região do remetente que ocorreram durante o período de defasagem. Se não houver gravações de aplicativo para a tabela na região do remetente, o serviço usará os mecanismos de ping para calcular uma aproximação do lag, e a estatística de lag ainda estará disponível na região do receptor.
Obter informações sobre atraso de réplica:
Na região do receptor, clique na tabela Ativo Global e exiba as informações da tabela. Em Recursos, clique em Métricas. Você vê uma métrica, Lag de réplica, que exibe o lag de replicação em milissegundos. No gráfico de exemplo abaixo, você vê que a métrica Atraso de réplica é usada na região Sudeste do Canadá (Toronto), que é a região do receptor. Esta tabela Ativa Global tem duas réplicas de tabela regionais, uma em cada nas regiões Sudeste do Canadá (Montreal) e Leste dos EUA (Ashburn). Você vê que o gráfico tem duas linhas uma cada para essas réplicas de tabela regionais em Montreal e Ashburn.
No gráfico abaixo, o Intervalo indica a janela de tempo usada para plotar o gráfico. Várias opções de intervalo disponíveis são 1 minuto, 5 minutos, 1 hora e 1 dia. Por padrão, o atraso da réplica é monitorado a cada 1 minuto e o gráfico é plotado a cada 5 minutos. Você pode selecionar diferentes estatísticas para a métrica de Lag de Réplica.
Exemplo 1:Lag de réplica com Sudeste do Canadá (Toronto) como a região receptora e Sudeste do Canadá (Montreal) e Leste dos EUA (Ashburn) como regiões remetentes.
O gráfico abaixo é plotado para a estatística Média para um intervalo de 5 minutos.
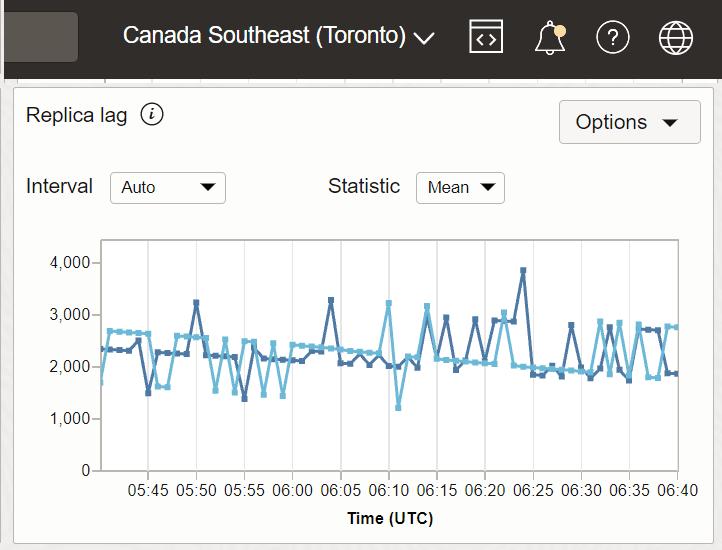
Descrição da ilustração metric_replica2.png
Neste exemplo, Montreal e Ashburn são duas regiões do remetente e Toronto é a região do destinatário na qual a métrica é capturada. Considere o valor de Replica Lag às 12:25 UTC para Montreal. São 2020 milissegundos. Isso significa que a região receptora Canadá Sudeste (Toronto) não recebeu atualizações que aconteceram na região remetente Canadá Sudeste (Montreal) nos últimos 2020 milissegundos. Da mesma forma, considere o valor do atraso de réplica às 12:25 UTC para Ashburn. São 2954 milissegundos. Isso significa que a região receptora Sudeste do Canadá (Toronto) não recebeu atualizações que ocorreram na região remetente Leste dos EUA (Ashburn) nos últimos 2954 milissegundos.
Exemplo 2: Atraso de réplica com Leste dos EUA (Ashburn) como região receptora e Sudeste do Canadá (Montreal) e Sudeste do Canadá de Toronto como regiões remetentes.
Neste exemplo, Montreal e Toronto são duas regiões do remetente e Ashburn é a região do destinatário na qual a métrica é capturada.
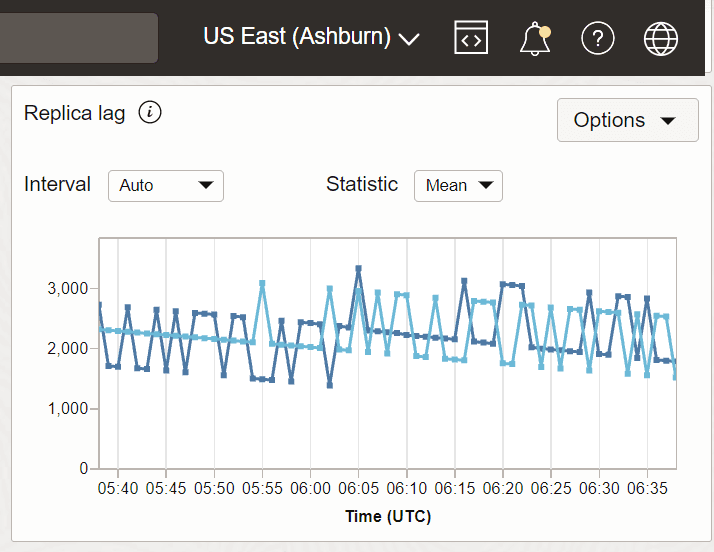
Descrição da ilustração metric_replica3.png
Exemplo 3: Atraso na réplica com o Sudeste do Canadá (Montreal) como região receptora e Leste dos EUA (Ashburn) e Sudeste do Canadá Toronto como regiões remetentes.
Neste exemplo, Ashburn e Toronto são duas regiões do remetente e Montreal é a região do destinatário na qual a métrica é capturada.
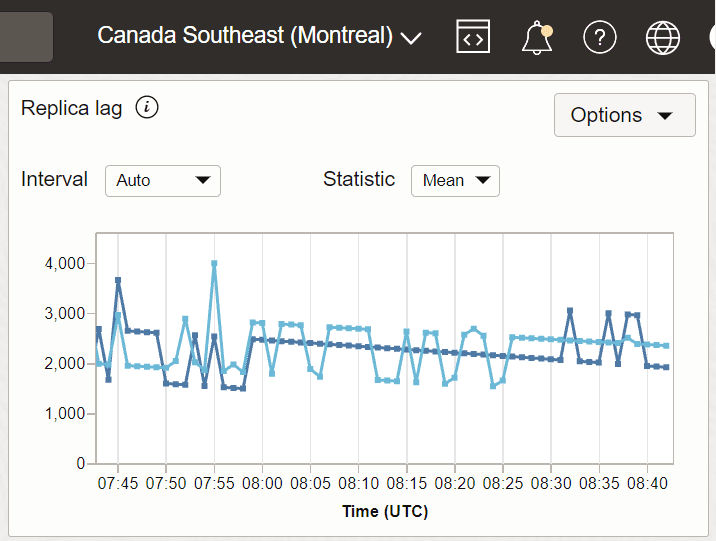
Descrição da ilustração metric_replica1.png
Além de visualizar o gráfico para o atraso da réplica, você tem as seguintes opções.
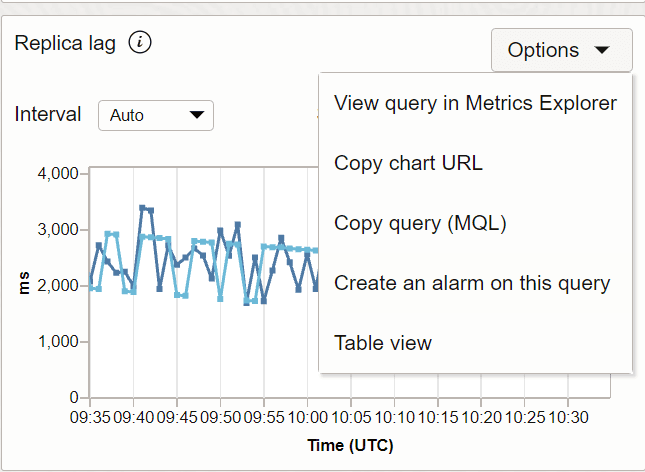
Descrição da ilustração metric_options.png
Você pode obter a view de tabela para verificar o valor do atraso da Réplica em um determinado momento.
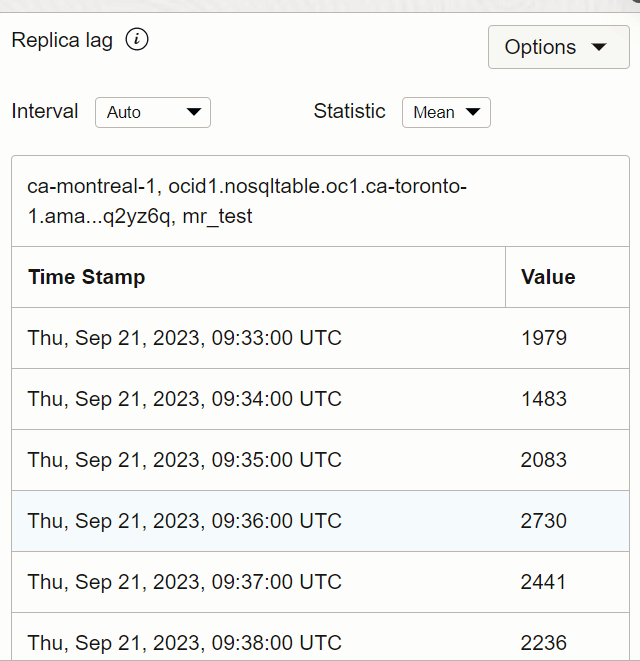
Descrição da ilustração tabview_toronto.png
Exibindo ou Listando Métrica do Oracle NoSQL Database Cloud Service
Você pode exibir as métricas disponíveis para o Oracle NoSQL Database Cloud Service na Console. Além disso, você pode obter a lista de métricas disponíveis para o Oracle NoSQL Database Cloud Service usando comandos da CLI do OCI.
-
Abra o menu de navegação e clique em Observabilidade & Gerenciamento. Em Monitoramento, clique em Métricas de Serviço.
-
Selecione o Compartimento e o Namespace de métricas (oci_nosql).
No Cloud Shell, execute o comando a seguir. Retorna definições de métrica que correspondem aos critérios especificados na solicitação. OCID do Compartimento obrigatório. Para obter mais informações sobre as OPÇÕES disponíveis com o comando list, consulte Métricas da Lista.
oci monitoring metric list --compartment-id <Compartment_OCID> --namespace oci_nosql
Por exemplo:
oci monitoring metric list --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya --namespace oci_nosqlExemplo de resposta:
{
"data": [
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "ReadThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "ReadUnits",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "StorageGB",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "StorageThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "WriteThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "WriteUnits",
"namespace": "oci_nosql",
"resource-group": null
}
]
}Como Coletar Métrica do Oracle NoSQL Database Cloud Service?
Você pode criar consultas de métrica para coletar conjuntos específicos de métricas (dados agregados). Uma consulta de métrica contém a expressão MQL (Monitoring Query Language) para ser avaliada com a devolução de dados agregados. A consulta deve especificar uma métrica, estatística e intervalo.
Você pode usar consultas de métrica para monitorar ativa e passivamente seus recursos de nuvem. Monitore ativamente com consultas de métrica que você gera espontaneamente, sob demanda. Na Console, atualize um gráfico para mostrar dados de várias consultas. Armazene as consultas que deseja reutilizar. Monitore passivamente com alarmes que adicionam uma condição ou regra do acionador a uma consulta de métrica.
Sintaxe de consulta de métrica:
metric[interval] {dimensionname=dimensionvalue}.groupingfunction.statisticSintaxe da consulta de Alarme de Limite:
metric[interval]{dimensionname=dimensionvalue}.groupingfunction.statistic alarmoperator alarmvaluePara obter os valores de parâmetros suportados, consulte Referência do Monitoring Query Language (MQL).
Consultas de Exemplo Consulta de métrica simples
Soma das contagens do Acelerador de Armazenamento para todas as tabelas em um compartimento em um intervalo de um minuto.
O número de linhas exibidas no gráfico de métricas (Console): 1 por tabela.
StorageThrottleCount[1m].sum()Consulta de métrica filtrada
Soma das contagens do Acelerador de Armazenamento em um compartimento em um intervalo de um minuto, filtradas para uma única tabela.
O número de linhas exibidas no gráfico de métricas (Console): 1 por tabela.
StorageThrottleCount[1m]{tableName = "demoKeyVal"}.sum()Consulta de métrica agregada
Média agregada de operação de leitura em um intervalo de sessenta minutos, filtrada para um compartimento e agregada para a média.
O número de linhas exibidas no gráfico de métricas (Console): 1 por tabela.
ReadUnits[60m]{compartmentId="ocid1.compartment.oc1.phx..exampleuniqueID"}.grouping().mean()Consulta de métrica agregada ao grupo
Média agregada da Contagem de Aceleradores de Leitura por unidade de leitura em um intervalo de sessenta minutos, filtrada para uma única tabela em um compartimento.
O número de linhas exibidas no gráfico de métricas (Console): 1 por unidade de leitura.
ReadThrottleCount[60m]{tableName = "demoKeyVal"}.groupBy(ReadUnits).mean()Criando uma Consulta de Métrica
Há duas maneiras de criar uma consulta de métrica. Você pode criar uma consulta usando a Console ou o comando da CLI do OCI.
-
Abra o menu de navegação e clique em Observabilidade & Gerenciamento. Em Monitoramento, clique em Explorador de Métricas.
A página Explorador de Métrica exibe um gráfico vazio com campos para criar uma consulta.
-
Preencha os campos de uma nova consulta.
-
Compartimento: O compartimento que contém as tabelas do Oracle NoSQL Database Cloud Service que você deseja monitorar. Por padrão, o primeiro compartimento acessível é selecionado.
-
Namespace de métricas: O Oracle NoSQL Database Cloud Service que está emitindo métricas para as tabelas que você deseja monitorar. Exemplo: oci_nosql.
-
Grupo de recursos (opcional): O grupo ao qual a métrica pertence. Um grupo de recursos é uma string personalizada fornecida com uma métrica personalizada. Não aplicável a métricas de serviço.
-
Nome da métrica: O nome da métrica. de Só é possível especificar uma métrica. As seleções de medição de consumo dependem do compartimento e namespace de medição selecionados. Exemplo: ReadUnits
-
Intervalo: A janela de agregação.
-
Estatística: A função de agregação.
-
Dimensões de métrica: Filtros opcionais para restringir os dados de métrica avaliados.
- Campos de dimensão: Para métricas do Oracle NoSQL Database Cloud Service, você pode selecionar resourceId ou tableName como nome da Dimensão e par de valores da Dimensão.
-
Agregar streams de medição: Plota uma única linha no gráfico de métrica para representar o valor combinado de todos os streams de medição para a estatística selecionada.
-
-
Clique em Atualizar Gráfico.
O gráfico mostra os resultados da nova consulta. Valores muito pequenos ou grandes são indicados pelo Sistema Internacional de Unidades (unidades SI), como M para mega (10 à sexta potência). As unidades correspondem à métrica selecionada e não se alteram pela estatística.
-
Para exibir a consulta como uma expressão MQL (Monitoring Query Language), selecione Modo avançado.
-
O modo avançado está localizado à direita, no gráfico.
Use o modo Avançado para editar sua consulta usando a sintaxe MQL para agregar resultados por grupo. A sintaxe MQL também suporta valores de parâmetros adicionais. Para obter mais informações sobre parâmetros de consulta nos modos Básico e Avançado, consulte Referência de MQL (Monitoring Query Language).
-
No Cloud Shell, execute o comando a seguir. Retorna dados agregados que correspondem aos critérios especificados na solicitação. OCID do Compartimento obrigatório.
oci monitoring metric-data summarize-metrics-data --compartment-id<Compartment_OCID> --namespace oci_nosql --query-text [text]
--query-text é a expressão MQL (Monitoring Query Language) a ser usada ao procurar pontos de dados de métrica para agregar. A consulta deve especificar uma métrica, estatística e intervalo. Valores suportados para o intervalo: 1m-60m (também 1h). Opcionalmente, você pode especificar dimensões e funções de agrupamento. Funções de agrupamento suportadas: agrupamento(), groupBy(). Para obter mais informações sobre as OPÇÕES disponíveis com o comando sumarize-metrics-data, consulte Resumir Dados de Métricas. No exemplo abaixo, estamos criando uma consulta de métrica filtrada para obter a Soma de Unidades de Leitura em um compartimento em um intervalo de um minuto, filtrada em uma única tabela.
Por exemplo:
oci monitoring metric-data summarize-metrics-data --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya
--namespace oci_nosql --query-text 'ReadUnits[1m]{tableName="articles"}.sum()'Exemplo de resposta:
{
"data": [
{
"aggregated-datapoints": [
{
"timestamp": "2022-02-17T11:03:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T11:04:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T11:05:00+00:00",
"value": 0.0
},
...
...
...
{
"timestamp": "2022-02-17T13:59:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T14:00:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T14:01:00+00:00",
"value": 0.0
}
],
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyav7f67yuj3t2q6rk7lp2a2obfdxa6hg2ho2ea7qabin4q",
"tableName": "demo"
},
"metadata": {},
"name": "ReadUnits",
"namespace": "oci_nosql",
"resolution": null,
"resource-group": null
}
]
}Criando Alarmes
Você pode criar um alarme que avalie a consulta de alarme e envie uma notificação quando o alarme estiver no estado de acionamento, juntamente com outras propriedades de alarme. Quando acionado, um alarme envia uma mensagem de alarme para o tópico configurado (no Notifications), que, em seguida, envia a mensagem para todas as assinaturas do tópico. Slack, Email, SMS e PagerDuty são alguns dos exemplos de Tópico Configurado no Notifications.
Quando configurado, as notificações repetidas lembram um estado de acionamento contínuo no intervalo de repetição configurado. Você também será notificado quando um alarme voltar ao estado OK ou quando um alarme for redefinido.
Uma consulta de alarme contém a expressão MQL (Monitoring Query Language) para avaliar a devolução de dados agregados. A consulta deve especificar uma métrica, estatística e intervalo.
Existem duas maneiras de criar um alarme. Você pode criar uma consulta usando a Console ou a CLI do OCI.
-
Abra o menu de navegação e clique em Observabilidade & Gerenciamento. Em Monitoramento, clique em Definições de Alarme.
-
Clique em Create Alarm.
Observação: você também pode criar um alarme com base em uma consulta predefinida da página Métricas de Serviço. Expanda as Opções e clique em Criar um Alarme nesta Consulta. Para obter mais informações sobre métricas de serviço, consulte Exibindo ou Listando Métricas do Oracle NoSQL Database Cloud Service.
-
Na página Criar Alarme, em Definir alarme, preencha ou atualize as definições do alarme. Para alternar entre Modo Básico e Modo Avançado, clique em Alternar para Modo Avançado ou Alternar para Modo Básico (à direita de Definir Alarme):
-
Nome do alarme: O nome amigável para o novo alarme. Este nome é enviado como o título para notificações relacionadas a este alarme. Evite digitar informações confidenciais.
-
Resumo do alarme: Informe um resumo amigável para o novo alarme. Esse campo é opcional.
-
Tags (opcional): Se você tiver permissão para criar um recurso, também terá permissão para aplicar tags de formato livre a esse recurso. Para aplicar uma tag definida, você deverá ter permissão para usar o namespace de tag. Para obter mais informações sobre tags, consulte Tags de Recurso. Se você não tiver certeza se deve aplicar tags, ignore essa opção (você poderá aplicar tags posteriormente) ou pergunte ao administrador.
Observação: clique em Mostrar opções avançadas na parte inferior da página para acessar as opções de Tags.
-
Descrição da métrica: A métrica a ser avaliada para a condição do alarme.
-
Compartimento: O compartimento que contém as tabelas do Oracle NoSQL Database Cloud Service que você deseja monitorar. Por padrão, o primeiro compartimento acessível é selecionado.
-
Namespace de métricas: O Oracle NoSQL Database Cloud Service que está emitindo métricas para as tabelas que você deseja monitorar. Exemplo: oci_nosql.
-
Grupo de recursos (opcional): O grupo ao qual a métrica pertence. Um grupo de recursos é uma string personalizada fornecida com uma métrica personalizada. Não aplicável a métricas de serviço.
-
Nome da métrica: O nome da métrica. Só é possível especificar uma métrica. As seleções de medição de consumo dependem do compartimento e namespace de medição selecionados. Exemplo: ReadUnits
-
Intervalo: A janela de agregação.
-
Estatística: A função de agregação.
-
Dimensões de métrica: filtros opcionais para restringir os dados de métrica avaliados.
- Campos de dimensão: Para métricas do Oracle NoSQL Database Cloud Service, você pode selecionar resourceId ou tableName como nome da Dimensão e par de valores da Dimensão.
-
-
Agregar streams de medição: Plota uma única linha no gráfico de métrica para representar o valor combinado de todos os streams de medição para a estatística selecionada.
-
Regra de acionamento: A condição que deve ser atendida para o alarme estar no estado de acionamento. A condição pode especificar um limite, como 90% para o StorageGB.
-
Operador: O operador usado no limite da condição.
-
Valor: O valor a ser usado para o limite de condição.
-
Minutos de atraso do trigger: O número de minutos em que a condição deve ser mantida antes que o alarme esteja em um estado de acionamento.
-
Gravidade do alarme: O tipo de resposta percebida necessária quando o alarme está no estado de acionamento.
-
Corpo de alarme: O conteúdo legível pela pessoa da notificação entregue. A Oracle recomenda fornecer orientação aos operadores para resolver a condição do alarme. Exemplo: "High Read Throttle Count".
-
-
-
Para alterar a exibição dos resultados da consulta, clique na opção apropriada acima dos resultados, à direita do:
-
Mostrar Tabela de Dados: Lista pontos de dados, indicando timestamp e bytes para cada.
-
Mostrar Gráfico (padrão): Plota pontos de dados em um gráfico.
-
-
Configurar notificações: Em Notificações, preencha os campos.
-
Destinos: O tópico a ser usado para notificações.
-
Repetir notificação?: Enquanto o alarme estiver no estado de acionamento, ele reenvia notificações no intervalo especificado.
-
Frequência de notificação: O período de tempo a ser aguardado para reenviar a notificação.
-
Suprimir notificações: Configure um intervalo de tempo da supressão durante o qual as avaliações e notificações devem ser suspensas. Útil para evitar notificações de alarme durante períodos de manutenção do sistema.
-
-
Se você quiser desativar o novo alarme, desmarque Ativar este alarme?
-
Clique em Salvar alarme.
No Cloud Shell, execute o comando a seguir para criar um novo alarme no compartimento especificado. OCID do Compartimento obrigatório.
oci monitoring alarm create --compartment-id <Compartment_OCID> --namespace oci_nosql --query-text [text] --destinations [complex type] --display-name [text] --is-enabled [boolean] --metric-compartment-id [text] --severity [text]
--query-text é a expressão MQL (Monitoring Query Language) a ser usada ao procurar pontos de dados de métrica para agregar. A consulta deve especificar uma métrica, estatística e intervalo. Valores suportados para o intervalo: 1m-60m (também 1h). Opcionalmente, você pode especificar dimensões e funções de agrupamento. Funções de agrupamento suportadas: agrupamento(), groupBy(). Para obter mais informações sobre as OPÇÕES disponíveis com o comando criar alarme, consulte create - alarm. No exemplo abaixo, estamos criando um alarme com consulta de alarme quando o percentil 90 do StorageGB é maior que 85 em um compartimento em um intervalo de um minuto, filtrado em uma única tabela.
Exemplo de alarme de limite:
oci monitoring alarm create --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya
--namespace oci_nosql --query-text 'StorageGB[1m]{tableName="demo"}.groupBy(WriteUnits).percentile(0.9) > 85'
--display-name HighStorageConsumption --metric-compartment-id demonosql --severity Critical --is-enabled trueGerenciando Alarmes
Você pode seguir estas diretrizes sobre como gerenciar seus alarmes.
-
Criar um Conjunto de Alarmes para Cada Métrica. Para cada métrica emitida pela tabela do Oracle NoSQL Database Cloud Service, crie alarmes que definam os seguintes comportamentos de recursos:
-
Em risco - O Oracle NoSQL Database Cloud Service corre o risco de se tornar inoperante, conforme indicado pelos valores de métrica. Por exemplo, o tamanho do armazenamento de uma tabela está em risco de alta utilização.
-
Não ideal - O desempenho do Oracle NoSQL Database Cloud Service é semelhante a níveis não ideais, conforme indicado por valores de métrica. Por exemplo, ReadUnits ou Write Units têm alta latência.
-
O recurso está ativo ou inativo - O Oracle NoSQL Database Cloud Service não pode ser acessado ou não está em operação. Por exemplo, Número alto para ReadThrottleCount ou WriteThrottleCount.
-
-
Configure um processo para responder a alarmes. Com base na gravidade do alarme, você pode optar por responder aos alarmes das seguintes maneiras diferentes:
-
Para alarmes Críticos para Em Risco, você pode decidir notificar a equipe de operações imediatamente porque o reparo é necessário para trazer as instâncias de volta aos níveis operacionais ideais. Você configura notificações de alarme para a equipe responsável pelo PagerDuty e por e-mail, solicitando uma investigação e correções apropriadas antes que as instâncias entrem em um estado inoperante. Você define notificações repetidas a cada minuto. Quando alguém responde às notificações do alarme, você interrompe temporariamente essas notificações suprimindo o alarme. Depois que as métricas retornam aos valores ideais, você remove a supressão.
-
Para alarmes Advertência ou Não Ideal, você pode decidir notificar o indivíduo ou a equipe apropriada de que a tabela do Oracle NoSQL Database Cloud Service está consumindo mais Tamanho de Armazenamento do que o normal. Você configura um alarme de limite para notificar os contatos apropriados, pois não são necessárias ações imediatas para investigar e reduzir o Tamanho do Armazenamento. Defina a notificação somente para e-mail, direcionada para o desenvolvedor ou equipe apropriada, com notificações repetidas a cada 24 horas para reduzir o ruído de notificação por e-mail.
-