Referência do Serviço Oracle NoSQL Database Cloud
Saiba mais sobre tipos de dados suportados, instruções DDL, parâmetros e métricas do Oracle NoSQL Database Cloud Service Service.
Este artigo tem os seguintes tópicos:
Tipos de Dados Suportados
Para muitos tipos de dados comuns, o Oracle NoSQL Database Cloud Service.
| Tipo de Dados | Descrição |
|---|---|
BINARY |
Uma sequência de zero ou mais bytes. O tamanho do armazenamento é o número de bytes mais uma codificação do tamanho da matriz de bytes, que é uma variável, dependendo do tamanho da matriz. |
FIXED_BINARY |
Um array de bytes de tamanho fixo. Não há sobrecarga de codificação extra para este tipo de dados. |
BOOLEAN |
Um tipo de dados com um dos dois valores possíveis: TRUE ou FALSE. O tamanho do armazenamento do booliano é de 1 byte. |
DOUBLE |
Um número longo de ponto flutuante, codificado usando 8 bytes de armazenamento para chaves de índice. Se for uma chave primária, ela usará 10 bytes de armazenamento. |
FLOAT |
Um número de ponto flutuante longo, codificado usando 4 bytes de armazenamento para chaves de índice. Se for uma chave primária, ela usará 5 bytes de armazenamento. |
LONG |
Um número inteiro longo tem uma codificação de comprimento variável que usa 1-8 bytes de armazenamento, dependendo do valor. Se for uma chave primária, ela usará 10 bytes de armazenamento. |
INTEGER |
Um número inteiro longo tem uma codificação de comprimento variável que usa 1-4 bytes de armazenamento, dependendo do valor. Se for uma chave primária, ela usará 5 bytes de armazenamento. |
STRING |
Uma sequência de zero ou mais caracteres Unicode. O tipo de String é codificado como UTF-8 e armazenado nessa codificação. O tamanho do armazenamento é o número de UTF-8 bytes mais o tamanho, que pode ser de 1 a 4 bytes, dependendo do número de bytes da codificação. Quando armazenado em uma chave de índice, o tamanho do armazenamento é o número de UTF-8 bytes mais um único byte de encerramento nulo. |
NUMBER |
Um número decimal assinado com precisão arbitrária. Ela é serializada em um formato de matriz de bytes que pode ser usado para comparações ordenadas. O formato tem 2 partes: 1. O sinal e o expoente mais um único dígito. Isso leva 1-6 bytes, mas normalmente é 2, a menos que o expoente seja bastante grande 2. A mantissa do valor que é aproximadamente um byte para cada 2 dígitos Exemplos: 12,345678 é serializada em 6 bytes 1,234E+102 é serializada em 5 bytes Observação: Quando você precisa usar valores numéricos no seu esquema, ele é recomendável decidir sobre os tipos de dados na ordem fornecida abaixo: INTEGER, LONG, FLOAT, DOUBLE, NUMBER Evite NUMBER, a menos que você realmente precise dele para seu caso de uso, pois NUMBER é caro em termos de armazenamento e poder de processamento usado. |
TIMESTAMP |
Um ponto no tempo com uma precisão. A precisão afeta o tamanho e o uso do armazenamento. O timestamp é armazenado e gerenciado no fuso horário UTC (Coordinated Universal Time). O tipo de dados Timestamp requer de 3 a 9 bytes, dependendo da precisão usada. O seguinte detalhamento ilustra o armazenamento usado por este tipo de dados: - bit[0~13] ano - 14 bits - bit[14~17] mês - 4 bits - bit[18~22] dia - 5 bits - bit[23~27] hora - 5 bits [opcional] - bit[28~33] minuto - 6 bits [opcional] - bit[34~39] segundo - 6 bits [opcional] - bit[40~71] segundo fracionário [opcional com comprimento variável] |
UUID |
Nota: O tipo de dados UUID é considerado um subtipo do tipo de dados STRING. O tamanho do armazenamento é 16 bytes como chave de índice. Se usado como chave primária, o tamanho do armazenamento será de 19 bytes. |
ENUM |
Uma enumeração é representada como um array de strings. Os valores ENUM são identificadores simbólicos (tokens) e são armazenados como um pequeno valor inteiro que representa uma posição ordenada na enumeração. |
ARRAY |
Uma coleção ordenada de zero de itens mais tipados. As matrizes não definidas como JSON não podem conter valores NULL. As matrizes declaradas como JSON podem conter qualquer JSON válido, incluindo o valor especial, nulo, que é relevante para JSON. |
MAP |
Uma coleção não ordenada de zero ou mais pares de item-chave, em que todas as chaves são strings e todos os itens são do mesmo tipo. Todas as chaves devem ser exclusivas. Os pares chave-item são chamados de campos, as chaves são nomes de campo e os itens associados são valores de campo. Os valores de campos podem ter diferentes tipos, mas os mapas não podem conter valores de campos NULL. |
RECORD |
Uma coleção fixa de um ou mais pares de item/chave, em que todas as chaves são strings. Todas as chaves de um registro devem ser exclusivas. |
JSON |
Qualquer dado JSON válido. |
Estados da Tabela e Ciclos da Vida
Saiba mais sobre os diferentes estados de tabela e seu significado (processo de ciclo de vida de tabela).
Cada tabela passa por uma série de diferentes estados, desde a criação da tabela até a exclusão (eliminação). Por exemplo, uma tabela no estado DROPPING não pode prosseguir para o estado ACTIVE, ao passo que uma tabela no estado ACTIVE pode passar para o estado UPDATING. Você pode rastrear os diferentes estados da tabela monitorando o ciclo de vida da tabela. Esta seção descreve os vários estados de tabela.
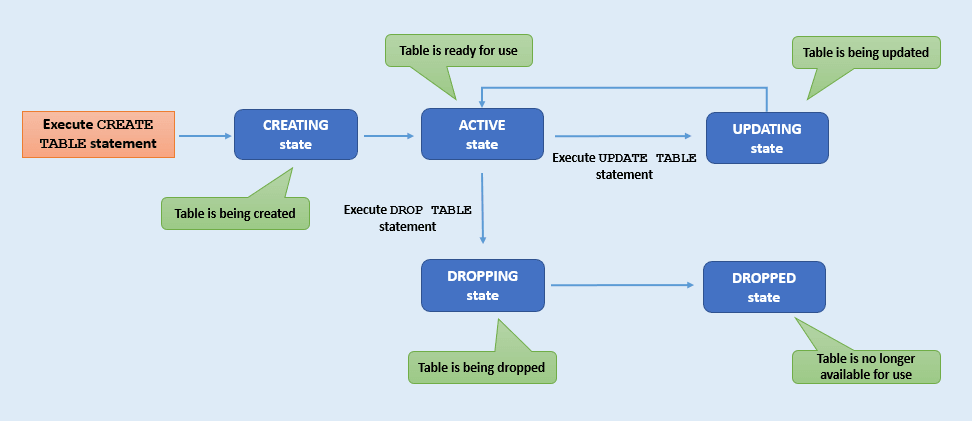
Descrição da ilustração table-state.png
| Estado da Tabela | Descrição |
|---|---|
CREATING |
A tabela está em processo de criação. Não está pronto para uso. |
UPDATING |
A atualização da tabela está em andamento. Não são possíveis mais modificações de tabela enquanto a tabela estiver nesse estado. Uma tabela está no estado UPDATING quando:- Os limites da tabela estão sendo alterados - O esquema da tabela está evoluindo - Adicionando ou eliminando um índice da tabela |
ACTIVE |
A tabela pode ser usada no estado atual. A tabela pode ter sido criada ou modificada recentemente, mas o estado da tabela agora é estável. |
DROPPING |
A tabela está sendo eliminada e não pode ser acessada para nenhuma finalidade. |
DROPPED |
A tabela foi eliminada e não existe mais para atividades de leitura, gravação ou consulta. Observação: Uma vez eliminada, uma tabela com o mesmo nome poderá ser criada novamente. |
Depurando erros de instrução SQL na console do OCI
Quando estiver usando a console do OCI para criar uma tabela usando uma instrução DDL ou uma instrução DML para inserir ou atualizar dados ou usar uma consulta SELECT para extrair dados, você poderá obter um erro de que sua instrução está Incompleto ou com falha em um dos seguintes cenários comuns:
- Se houver um ponto-e-vírgula no fim da instrução SQL.
- Se houver um erro de sintaxe na instrução SQL, como o uso errado de vírgulas, o uso de qualquer caractere desnecessário na instrução etc.
- Se houver um erro de ortografia na instrução SQL em qualquer uma das palavras-chave SQL ou na definição do tipo de dados.
- Se você definiu a coluna como NOT NULL, mas não atribuiu um valor DEFAULT a ela.
- Se você definiu a coluna como NOT NULL, mas não atribuiu um valor DEFAULT a ela.
Como tratar alguns erros Incompleto ou com falha ao usar a console do OCI para criar ou gerenciar dados:
- Remova o ponto e vírgula ( se houver) no final da instrução SQL.
- Verifique se há algum caractere indesejado ou pontuação errada na instrução SQL.
- Verifique se há erros de ortografia na instrução SQL.
- Verifique se todas as definições de coluna estão completas e corretas.
- Verifique se você definiu uma chave primária para sua tabela.
Se você ainda receber um erro depois de eliminar algumas das possíveis situações, conforme discutido acima, poderá usar o Cloud Shell para executar sua consulta e capturar o erro exato, conforme mostrado no exemplo abaixo.
Exemplo: Obtendo a mensagem de erro de uma instrução SELECT do cloud shell
O comando summarize verifica a sintaxe e retorna um breve resumo de uma instrução SQL.
-
Na console do OCI, Abra o Cloud Shell no menu superior direito.
-
Copie sua instrução SQL SELECT( por exemplo,
query1.sql) em uma variável (SQL_SELECTSTMT).Exemplo:
SQL_SELECTSTMT=$(cat ~/query1.sql | tr '\n' ' ') -
Chame o comando oci abaixo para verificar a sintaxe da instrução SQL SELECT.
Observação: Você precisa fornecer o
compartment_idpara esta instrução SELECT.oci raw-request --http-method GET --target-uri https://nosql.${OCI_REGION}.oci.oraclecloud.com/20190828/query/summarize?compartmentId=$NOSQL_COMPID\ &statement="$SQL_SELECTSTMT" | jq '.data'
Isso causará o erro exato na instrução SQL.
Referência da Linguagem de Definição de Dados
Saiba como usar a DDL no Oracle NoSQL Database Cloud Service.
Use a DDL do Oracle NoSQL Database Cloud Service para criar, alterar e eliminar tabelas e índices.
Para obter informações sobre a sintaxe da linguagem DDL, consulte o Table Data Definition Language Guide. Este guia documenta a linguagem DDL, conforme suportado pelo produto Oracle NoSQL Database local. O Oracle NoSQL Database Cloud Service suporta um subconjunto dessa funcionalidade e as diferenças são documentadas nas Diferenças de DDL na seção Nuvem.
Além disso, cada driver de linguagem NoSQL fornece uma API para executar uma instrução DDL. Para gravar seu aplicativo, consulte Usando APIs para Criar Tabelas e Índices no Oracle NoSQL Database Cloud Service .
Instruções DDL Típicas
Alguns exemplos de instruções DDL comuns são os seguintes:
Criar Tabela
CREATE TABLE [IF NOT EXISTS] (
field-definition, field-definition-2 ...,
PRIMARY KEY (field-name, field-name-2...),
) [USING TTL ttl]Por exemplo:
CREATE TABLE IF NOT EXISTS audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Alterar Tabela
ALTER TABLE table-name (ADD field-definition)
ALTER TABLE table-name (DROP field-name)
ALTER TABLE table-name USING TTL ttlPor exemplo:
ALTER TABLE audience_info USING TTL 7 daysCriar Índice
CREATE INDEX [IF NOT EXISTS] index-name ON table-name (path_list)Por exemplo:
CREATE INDEX segmentIdx ON audience_info
(audience_segment.sports_lover AS STRING)Eliminar Tabela
DROP TABLE [IF EXISTS] table-namePor exemplo:
DROP TABLE audience_infoConsulte os guias de referência para ver uma lista completa:
Diferenças de DDL na Nuvem
A linguagem DDL do serviço de nuvem difere do que é descrito no guia de referência da seguinte maneira:
Nomes de Tabela
- Limitados a 256 caracteres e estão restritos a caracteres alfanuméricos e sublinhados
- Deve começar com uma letra
- Não podem incluir caracteres especiais
- Tabelas filhas não são suportadas
Conceitos Não Suportados
- Instruções
DESCRIBEeSHOW TABLE. - Índices de texto completo
- Gerenciamento de usuários e funções
- Regiões locais
Referência de Linguagem de Consulta
Saiba como usar instruções SQL para atualizar e consultar dados no Oracle NoSQL Database Cloud Service.
O Oracle NoSQL Database usa a linguagem de consulta SQL para atualizar e consultar dados em tabelas NoSQL. Consulte Referência SQL do Oracle NoSQL Database para obter a sintaxe da linguagem de consulta.
Consultas Típicas
SELECT <expression>
FROM <table name>
[WHERE <expression>]
[GROUP BY <expression>]
[ORDER BY <expression> [<sort order>]]
[LIMIT <number>]
[OFFSET <number>];Por exemplo:
SELECT * FROM Users;
SELECT id, firstname, lastname FROM Users WHERE firstname = "Taylor";UPDATE <table_name> [AS <table_alias>]
<update_clause>[, <update_clause>]*
WHERE <expr>[<returning_clause>];Por exemplo:
UPDATE JSONPersons $j
SET TTL 1 DAYS
WHERE id = 6
RETURNING remaining_days($j) AS Expires;Diferenças de Linguagem de Consulta na Nuvem
O suporte à consulta de serviço em nuvem difere do que é descrito no manual de referência da linguagem da consulta da seguinte maneira:
Restrições nas Expressões Usadas na Cláusula SELECT
O Oracle NoSQL Database Cloud Service suporta expressões de agrupamento ou expressões aritméticas entre funções agregadas. Nenhum outro tipo de expressão é permitido na cláusula SELECT. Por exemplo, expressões CASE não são permitidas na cláusula SELECT.
Cada driver do NoSQL Database fornece uma API para executar uma instrução de consulta.
Referência do Plano de Consulta
Um plano de execução de consulta é a sequência de operações que o Oracle NoSQL Database executa para executar uma consulta.
Um plano de execução de consulta é uma árvore de iteradores de plano. Cada tipo de iterador avalia um tipo diferente de expressão que pode aparecer em uma consulta. Em geral, a escolha do índice e o tipo de predicados de índice associados podem ter um efeito drástico no desempenho da consulta. Como resultado, você, como usuário, geralmente quer ver qual índice é usado por uma consulta e quais predicados foram enviados para ele. Com base nessas informações, talvez você queira forçar o uso de um índice diferente por meio de dicas de índice. Esta informação está contida no plano de execução da consulta. Todos os drivers do Oracle NoSQL fornecem APIs para exibir o plano de execução de uma consulta.
Estes são alguns dos iteradores mais comuns e importantes usados nas consultas:
iterador de tabela: um iterador de tabela é responsável por:
- Verificando o índice usado pela consulta (que pode ser o índice principal).
- Aplicando qualquer predicado de filtragem enviado ao índice
- Recuperar as linhas indicadas pelas entradas de índice de qualificação, se necessário. Se o índice estiver sendo coberto, o conjunto de resultados do iterador TABLE será um conjunto de entradas de índice; caso contrário, será um conjunto de linhas da tabela.
Observação: Um índice será chamado de índice de cobertura em relação a uma consulta se a consulta puder ser avaliada usando apenas as entradas desse índice, ou seja, sem a necessidade de recuperar as linhas associadas.
SELECT iterator: É responsável por executar a expressão SELECT.
Todas as consultas têm uma cláusula SELECT. Portanto, cada plano de consulta terá um iterador SELECT. Um iterador SELECT tem a seguinte estrutura:
"iterator kind" : "SELECT",
"FROM" :
{
},
"FROM variable" : "...",
"SELECT expressions" :
[
{
}
]O iterador SELECT tem campos como: "FROM", "WHERE", "FROM variável" e "SELECT expressões". "FROM" e "FROM variable" representam a cláusula FROM da expressão SELECT, WHERE representa a cláusula de filtro e "SELECT expression" representa a cláusula SELECT.
RECEIVE iterator: É um iterator interno especial que separa o plano de consulta em 2 partes:
-
O iterador RECEIVE em si e todos os iteradores que estão acima dele na árvore do iterador são executados no driver.
-
Todos os iteradores abaixo do iterador RECEIVE são executados nos nós de replicação (RNs); esses iteradores formam uma subárvore enraizada no filho exclusivo do iterador RECEIVE.
Em geral, o iterador RECEIVE atua como um coordenador de consultas. Ele envia seu subplano aos RNs apropriados para execução e coleta os resultados. Ele pode executar operações adicionais, como classificação e eliminação duplicada, e propagar os resultados para seus iteradores ancestrais (se houver) para processamento posterior.
Tipos da distribuição:
Um tipo de distribuição especifica como a consulta será distribuída para execução entre os RNs que participam de um banco de dados Oracle NoSQL (um armazenamento). O tipo de distribuição é uma propriedade do iterador RECEIVE.
As diferentes opções de tipos de distribuição são:
- SINGLE_PARTITION: Uma consulta SINGLE_PARTITION especifica uma chave de partição completa em sua cláusula WHERE. Como resultado, seu conjunto completo de resultados está contido em uma única partição, e o iterador RECEIVE enviará seu subplano para um único RN que armazena essa partição. Uma consulta SINGLE_PARTITION pode usar o índice de chave primária ou um índice secundário.
- ALL_PARTITIONS: As consultas usam o índice de chave primária aqui e não especificam uma chave de partição completa. Como resultado, se a loja tiver partições M, o iterador RECEIVE enviará cópias M de seu subplano para serem executadas em uma das partições M cada.
- ALL_SHARDS: As consultas usam um índice secundário aqui e não especificam uma chave de partição completa. Como resultado, se a loja tiver N shards, o iterador RECEIVE enviará N cópias de seu subplano para serem executadas em um dos N shards cada.
Anatomia de um plano de execução de consulta:
A execução da consulta ocorre em lotes. Quando um subplano de consulta é enviado para uma partição ou shard para execução, ele é executado lá até que um limite de batch seja atingido. O limite de lote é um número de unidades de leitura consumidas localmente pela consulta. O padrão é 2000 unidades de leitura (cerca de 2MB de dados) e só pode ser diminuído por meio de uma opção no nível da consulta.
Quando o limite de batch é atingido, qualquer resultado local produzido é enviado de volta ao iterador RECEIVE para processamento posterior, juntamente com um sinalizador booliano que informa se mais resultados locais podem estar disponíveis. Se o sinalizador for verdadeiro, a resposta incluirá informações de currículo. Se o iterador RECEIVE decidir reenviar a consulta para a mesma partição/shard, ele incluirá essas informações de retomada em sua solicitação, para que a execução da consulta seja reiniciada no ponto em que ela foi interrompida durante o batch anterior. Isso ocorre porque nenhum estado de consulta é mantido no RN após o término de um lote. O próximo lote para a mesma partição/partição pode ocorrer no mesmo RN do lote anterior ou em um RN diferente que também armazena a mesma partição/partição.