Configure o Apache Hue para usar componentes Hadoop diferentes.
-
Na IU do Hue, crie um usuário administrador com a senha que você usou ao Criar um Cluster.
-
Navegue até Administrar usuários e faça o seguinte:
- Selecione o usuário do Hue.
- Atualize a senha.
- Faça com que o usuário tenha permissão para se conectar como usuário do Hue para log-ins subsequentes.
Você pode criar mais usuários de acordo com sua necessidade.
Observação
Para clusters seguros, marque a caixa de seleção Criar diretório home e crie o usuário no nó de utilitário usando o comando sudo useradd <new_user> para gerenciar as políticas de acesso usando o ranger.
-
Para executar os aplicativos DistCp e MapReduce, adicione a biblioteca MapReduce ao classpath YARN. Para adicionar a biblioteca, siga estas etapas:
- Na IU do Ambari, em YARN, selecione Configurações.
- Procure
yarn.application.classpath.
- Copie a seguinte configuração e cole-a para o valor
yarn.application.classpath:$HADOOP_CONF_DIR,/usr/lib/hadoop-mapreduce/*,/usr/lib/hadoop/*,/usr/lib/hadoop/lib/*,/usr/lib/hadoop-hdfs/*,/usr/lib/hadoop-hdfs/lib/*,/usr/lib/hadoop-yarn/*,/usr/lib/hadoop-yarn/lib/*
- Salve e reinicie os serviços YARN, Oozie e MapReduce.
-
Configure o Sqoop. Para configurar, siga estas etapas:
- Copie o mysql-connector para o classpath do oozie.
sudo cp /usr/lib/oozie/embedded-oozie-server/webapp/WEB-INF/lib/mysql-connector-java.jar /usr/lib/oozie/share/lib/sqoop/
sudo su oozie -c "hdfs dfs -put /usr/lib/oozie/share/lib/sqoop/mysql-connector-java.jar /user/oozie/share/lib/sqoop"
- Reinicie o serviço Oozie por meio do Ambari.
- Os jobs do Sqoop são executados nos nós de trabalho.
Nos clusters do Big Data Service com a versão 3.0.7 ou mais recente, o acesso ao usuário mysql hue está disponível em todos os nós de trabalho.
Para clusters com versões anteriores, execute as declarações de concessão, conforme descrito na Etapa 2 das seções do cluster seguro e não seguro do serviço Configuring Apache Hue. Ao executar os comandos, substitua o host local pelo nome do host de trabalho e repita isso para cada nó de trabalho no cluster. Por exemplo:
grant all privileges on *.* to 'hue'@'wn_host_name ';
grant all on hue.* to 'hue'@'wn_host_name';
alter user 'hue'@'wn_host_name' identified by 'secretpassword';
flush privileges;
-
No nó principal ou do utilitário, no diretório a seguir, use os jars relacionados ao spark e adicione como dependência ao projeto do spark. Por exemplo, copie os arquivos jar spark-core e spark-sql em lib/ para o projeto sbt.
/usr/lib/oozie/share/lib/spark/spark-sql_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar
/usr/lib/oozie/share/lib/spark/spark-core_2.12-3.0.2.odh.1.0.ce4f70b73b6.jar
Veja a seguir um exemplo de código de contagem de palavras. Monte o código no JAR:
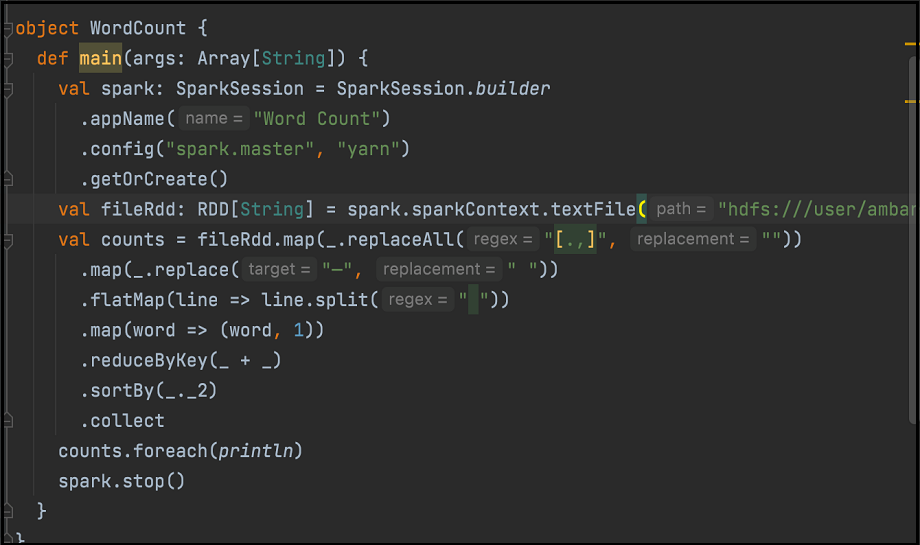
Na interface do Spark do Hue, use os arquivos jar relevantes para executar o job do Spark.
-
Para executar MapReduce por meio do Oozie, faça o seguinte:
- Copie
oozie-sharelib-oozie-5.2.0.jar (contém a classe OozieActionConfigurator) na amostra de código.
- Defina as classes mapeador e redutor conforme fornecidas em qualquer exemplo de contagem de palavras padrão MapReduce.
- Crie outra classe conforme mostrado aqui:
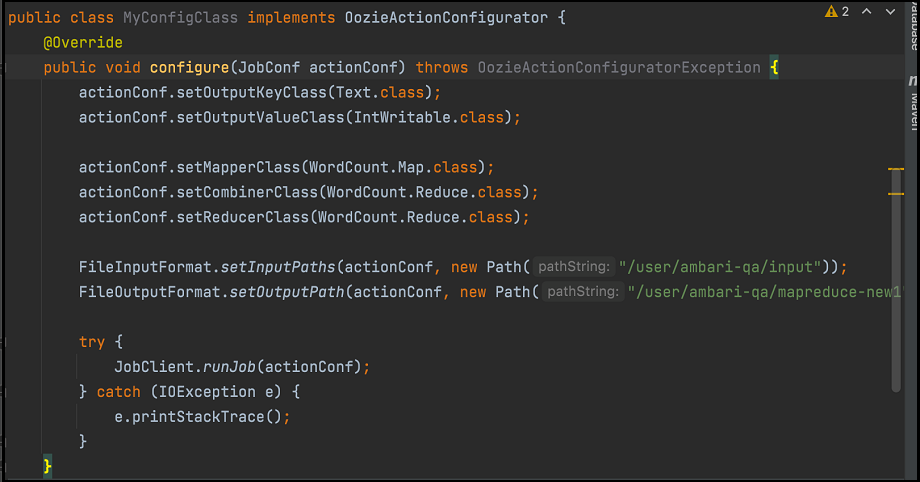
Compacte o código conforme mostrado na imagem anterior com as classes mapeador e redutor em um jar e faça o seguinte:
- Faça upload dele para o HDFS por meio do navegador de arquivos do Hue.
- Forneça o seguinte para executar o programa MapReduce, em que
oozie.action.config.class aponta para o nome de classe totalmente qualificado no trecho de código, conforme mostrado na imagem anterior.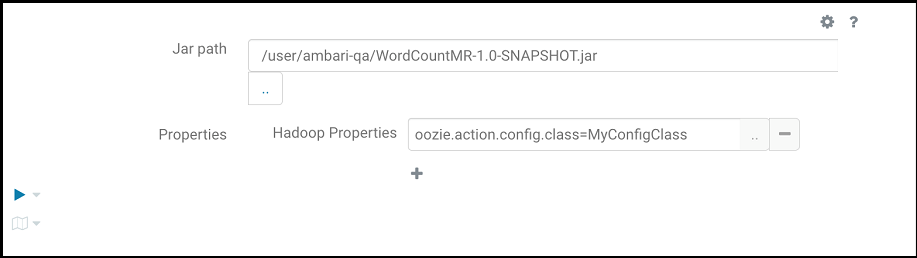
-
Configure HBase.
Nos clusters do Big Data Service com a versão 3.0.7 ou mais recente, ative o Módulo HBase do Hue usando o Apache Ambari. 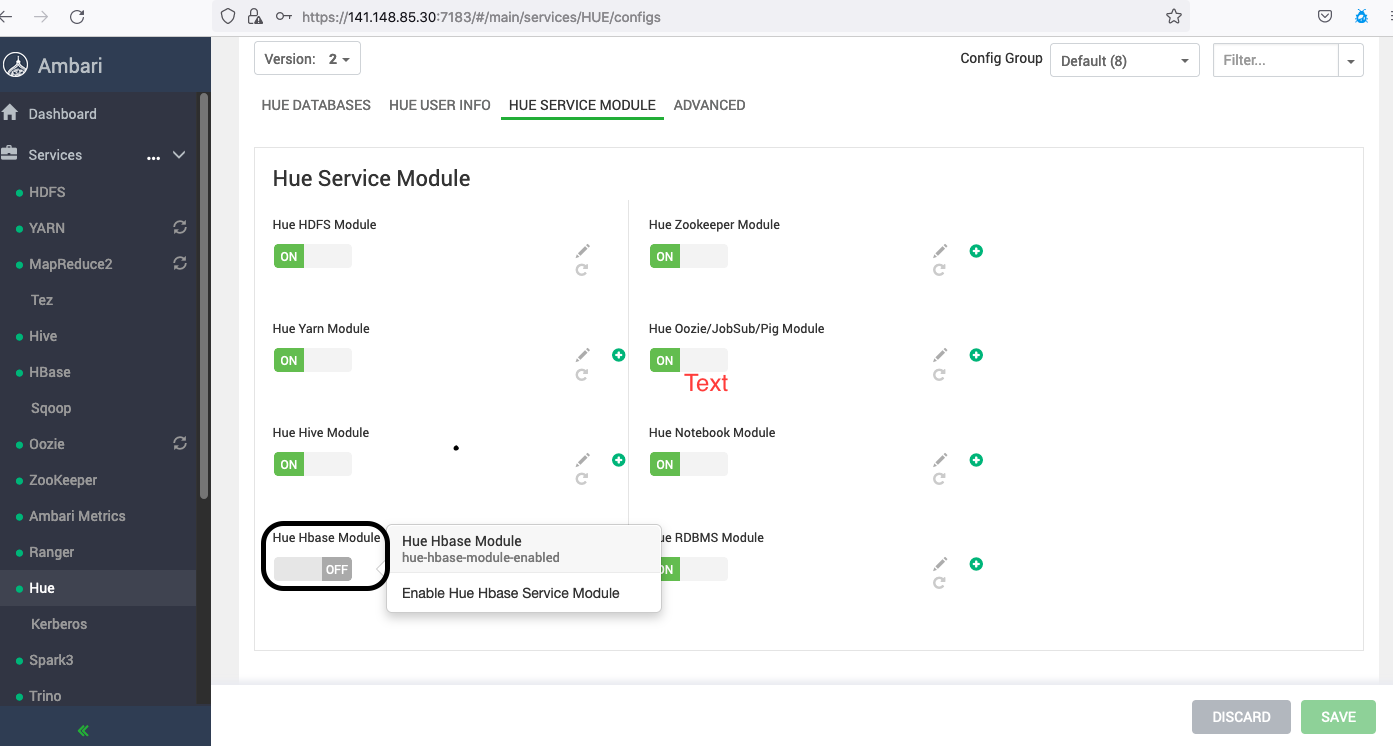
O Hue interage com o servidor HBase Thrift. Portanto, para acessar o HBase, inicie o servidor Thrift. Siga estas etapas:
- Depois de adicionar o serviço HBase na página Ambari, navegue até Hbase-Site.xml Personalizado (em HBase, vá para Configurações e, em Avançado, selecione Hbase-Site.xml Personalizado).
- Adicione os parâmetros a seguir substituindo o keytab ou o principal.
hbase.thrift.support.proxyuser=true
hbase.regionserver.thrift.http=true
##Skip the below configs if this is a non-secure cluster
hbase.thrift.security.qop=auth
hbase.thrift.keytab.file=/etc/security/keytabs/hbase.service.keytab
hbase.thrift.kerberos.principal=hbase/_HOST@BDSCLOUDSERVICE.ORACLE.COM
hbase.security.authentication.spnego.kerberos.keytab=/etc/security/keytabs/spnego.service.keytab
hbase.security.authentication.spnego.kerberos.principal=HTTP/_HOST@BDSCLOUDSERVICE.ORACLE.COM
- Execute os seguintes comandos no terminal de nós mestres:
# sudo su hbase
//skip kinit command if this is a non-secure cluster
# kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/<master_node_host>@BDSCLOUDSERVICE.ORACLE.COM
# hbase thrift start
- Acesse o nó do utilitário em que o Hue está instalado.
- Abra o arquivo
sudo vim /etc/hue//conf/pseudo-distributed.ini e remova hbase de app_blacklist.
# Comma separated list of apps to not load at startup.
# e.g.: pig, zookeeper
app_blacklist=search, security, impala, hbase, pig
- Reinicie o Hue do Ambari.
- O Ranger controla o acesso ao serviço HBase. Portanto, para usar o Hue e acessar tabelas HBase em um cluster seguro, você deve ter acesso ao serviço HBase do Ranger.
-
Configurar o fluxo de trabalho da ação de script:
- Entre no Hue.
- Crie um arquivo de script e faça upload dele para o Hue.
- Acesse o Hue e, no menu de navegação mais à esquerda, selecione Scheduler.
- Workflow e, em seguida, selecione Meu Workflow para criar um workflow.
- Selecione o ícone de shell para arrastar a ação do script para a área Eliminar sua ação aqui.
- Selecione o script na lista drop-down Comando Shell.
- Selecione o workflow na lista suspensa FILES.
- Selecione o ícone Salvar.
- Selecione o workflow na estrutura de pastas e, em seguida, selecione o ícone de envio.
Observação Ao executar qualquer ação de shell em um workflow do Hue, se o job estiver travado ou falhar por causa de erros como
Permission Denied or Exit code[1], execute as instruções a seguir para resolver o problema.
- Certifique-se de que todos os arquivos necessários (arquivo de script e outros arquivos relacionados) estejam disponíveis no local especificado, conforme mencionado no fluxo de trabalho, com as permissões necessárias para o usuário de execução do fluxo de trabalho (usuário conectado).
- Às vezes, como spark-submit, se você submeter um job do Spark sem um usuário específico, por padrão, o job será executado com o proprietário do processo do contêiner (yarn), nesse caso, certifique-se de que o usuário yarn tenha todas as permissões necessárias para executar o job.
Por exemplo:
// cat spark.sh
/usr/odh/current/spark3-client/bin/spark-submit --master yarn --deploy-mode client --queue default --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.2.1.jar
// Application throws exception if yarn user doesn't have read permission to access spark-examples_2.12-3.2.1.jar.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=yarn, access=READ, inode="/workflow/lib/spark-examples_2.12-3.2.1.jar":hue:hdfs:---------x
Nesse caso, o fio do usuário deve ter as permissões necessárias para incluir
spark-examples_2.12-3.2.1.jar
no job do Spark.
- Se você submeter um job do Spark com um usuário específico (--proxy-user spark), certifique-se de que o usuário do Yarn possa representar esse usuário especificado. Se o usuário Yarn não puder representar o usuário especificado e receber erros como (
User: Yarn is not allowed to impersonate Spark), adicione as configurações a seguir.
// cat spark.sh
/usr/odh/current/spark3-client/bin/spark-submit --master yarn --proxy-user spark --deploy-mode client --queue default --class
org.apache.spark.examples.SparkPi spark-examples_2.12-3.2.1.jar
Nesse caso, o job é executado usando o usuário do Spark. O usuário do Spark deve ter acesso a todos os arquivos relacionados (spark-examples_2.12-3.2.1.jar). Além disso, certifique-se de que o usuário do Yarn possa representar o usuário do Spark. Adicione as seguintes configurações para que o usuário do fio personifique outros usuários.
- Acessar o Apache Ambari.
- Na barra de ferramentas lateral, em Serviços, selecione HDFS.
- Selecione a guia Avançado e adicione os seguintes parâmetros em Site principal personalizado.
- hadoop.proxyuser.yarn.groups = *
- hadoop.proxyuser.yarn.hosts = *
- Selecione Salvar e reinicie todos os serviços necessários.
-
Execute o workflow do Hive no Oozie.
- Entre no Hue.
- Crie um arquivo de script e faça upload dele para o Hue.
- Acesse o Hue e, no menu de navegação mais à esquerda, selecione Scheduler.
- Workflow.
- Arraste o terceiro ícone de HiveServer2 para a área Eliminar sua ação aqui.
- Para selecionar o script de consulta do Hive no HDFS, selecione o menu de script. O script de consulta é armazenado em um caminho do HDFS que é acessível ao usuário que está conectado.
- Para salvar o workflow, selecione o ícone Salvar.
- o ícone de execução.