No Spark, a conectividade do serviço Object Storage é usada para executar consultas no banco de dados hospedado no serviço Object Storage usando spark-sql, spark-shell, spark-submit etc.
Pré-requisitos:
- O usuário do Hadoop no cluster deve fazer parte do grupo Spark.
No Linux:
id bdsuser
uid=54330(bdsuser) gid=54339(superbdsgroup) groups=54339(superbdsgroup,985(hadoop),984(hdfs),980(hive),977(spark)
Em Ranger:

No Ranger, acesse a guia Usuários e verifique na coluna Grupos se o usuário faz parte do grupo Spark.
- Os usuários do Spark e do Hadoop devem ser adicionados às seguintes políticas no Ranger.
tag.download.auth.userspolicies.download.auth.users
Para verificar, na IU do Ranger, selecione Access Manager > Políticas Baseadas em Recursos e, em seguida, selecione o botão de edição da instância do Spark. A janela Propriedades de Configuração é exibida.
Exemplo:
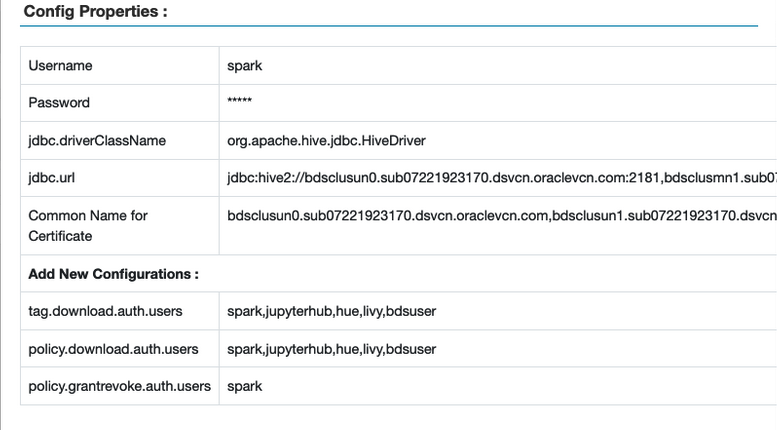
- Certifique-se de que o usuário do Hadoop seja adicionado à política
all - database, table, column para fornecer o privilégio SELECT no banco de dados, na tabela e nas colunas. Para verificar:
- Na IU do Ranger, selecione Access Manager > Políticas Baseadas em Recursos e, em seguida, selecione o repositório SPARK3.
- Selecione as políticas criadas para o usuário.
- Selecione all - database, table, column e, em seguida, selecione Edit.
- Na seção Permitir condições, verifique se o usuário do Hadoop está listado; caso contrário, adicione o usuário.
Observação
Você pode usar nós de cluster do Big Data Service para configuração de serviço e exemplos em execução. Para usar um nó Edge, você deve criar e acessar o nó Edge.
- (Opcional) Para usar um nó de Borda para configurar o Object Storage, primeiro crie um nó de Borda e, em seguida, acesse o nó. Em seguida, copie a chave de API do nó un0 para o nó Edge.
sudo dcli rsync -a <un0-hostname>:/opt/oracle/bds/.oci_oos/ /opt/oracle/bds/.oci_oos/
-
Crie um usuário com permissões suficientes e um arquivo JCEKS com o valor de frase-senha necessário. Se você estiver criando um arquivo JCEKS local, copie o arquivo para todos os nós e altere as permissões do usuário.
sudo dcli -f <location_of_jceks_file> -d <location_of_jceks_file>
sudo dcli chown <user>:<group> <location_of_jceks_file>
-
Adicione uma das seguintes combinações
HADOOP_OPTS ao perfil bash do usuário.
Opção 1:
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region> -DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Opção 2:
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id> -DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
No Ambari, adicione as opções do Hadoop ao modelo hive-env para acesso ao Object Storage.
-
Acesse o Apache Ambari.
-
Na barra de ferramentas lateral, em Serviços, selecione Hive.
-
Selecione Configurações.
-
Selecione Avançado.
-
Na seção Desempenho, vá para Avançado hive-env.
-
Vá para modelo hive-env e adicione uma das opções a seguir na linha
if [ "$SERVICE" = "metastore" ]; then.
Opção 1:
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region>
-DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Opção 2:
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
-DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
Reinicie todos os serviços necessários por meio do Ambari.
-
Execute um dos seguintes comandos de exemplo para iniciar o shell spark SQL:
Por exemplo 1:
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
Exemplo 2: Usando o alias de chave de API e a frase-senha.
spark-sql --conf spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE=<api_key_passphrase>
--conf spark.hadoop.OCI_SECRET_API_KEY_ALIAS=<api_key_alias>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region>
Exemplo 3: Usando parâmetros de Chave de API do Serviço IAM.
spark-sql --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region> --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PASSPHRASE=<api_key_passphrase>
Observação Se houver algum problema com o espaço de heap Java, informe a memória do driver e do executor como parte do Spark SQL. Por exemplo.
--driver-memory 2g –executor-memory 4g. Exemplo de instrução spark-sql:
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}"
--conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
--driver-memory 2g --executor-memory 4g
-
Verificar conectividade do Object Storage:
Exemplo de Tabela Gerenciada:
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet;
INSERT INTO <table_name> partition(part=1, part2=1) values (333, 'Object Storage Testing with Spark SQL Managed Table');
SELECT * from <table_name>;
Exemplo de Tabela Externa:
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE EXTERNAL TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet LOCATION 'oci://<bucket-name>@<namespace>/';
INSERT INTO <table_name> partition(part=1, part2=1) values (999, 'Object Storage Testing with Spark SQL External Table');
SELECT * from <table_name>;
- (Opcional) Use
pyspark com spark-submit com o serviço Object Storage.
Observação
Crie o banco de dados e a tabela antes de executar essas etapas.
-
Execute o seguinte:
from pyspark.sql import SparkSession
import datetime
import random
import string
spark=SparkSession.builder.appName("object-storage-testing-spark-submit").config("spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE","<jceks-provider>").config("spark.hadoop.OCI_SECRET_API_KEY_ALIAS",
"<api_key_alias>").enableHiveSupport().getOrCreate()
execution_time = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
param1 = 12345
param2 = ''.join(random.choices(string.ascii_uppercase + string.digits, k = 8))
ins_query = "INSERT INTO <database_name>.<table_name> partition(part=1, part2=1) values ({},'{}')".format(param1,param2)
print("##################### Starting execution ##################" + execution_time)
print("query = " + ins_query)
spark.sql(ins_query).show()
spark.sql("select * from <database_name>.<table_name>").show()
print("##################### Execution finished #################")
-
Execute o seguinte comando em
/usr/lib/spark/bin:
./spark-submit --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}" <location_of_python_file>