Desenvolvendo Aplicativos do Serviço Data Flow
Saiba mais sobre a Biblioteca , incluindo modelos de aplicativos Spark reutilizáveis e segurança de aplicativos. Além disso, saiba como criar e exibir aplicativos, editar aplicativos, excluir aplicativos e aplicar argumentos ou parâmetros.
- Ao Criar Aplicativos usando a Console
- Em Opções Avançadas, especifique a duração em Minutos máximos de duração da execução.
- Ao Criar Aplicativos usando a CLI
- Opção de linha de comando de passagem de
--max-duration-in-minutes <number> - Ao Criar Aplicativos usando o SDK
- Forneça o argumento opcional
max_duration_in_minutes - Ao Criar Aplicativos usando a API
- Defina o argumento opcional
maxDurationInMinutes
Modelos de Aplicativos Spark Reutilizáveis
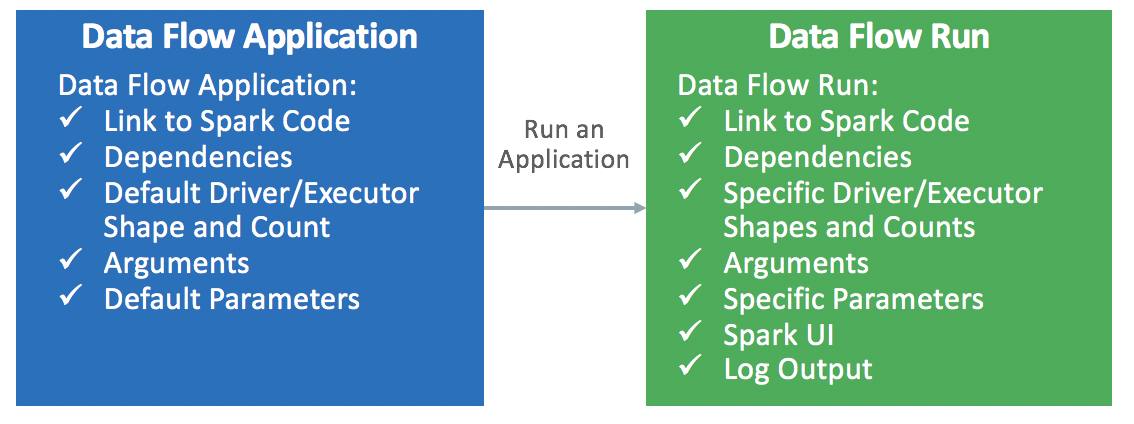
Um Aplicativo é um modelo de aplicativo Spark infinitamente reutilizável.
Os Aplicativos do Data Flow consistem em um aplicativo Spark, suas dependências, seus parâmetros padrão e uma especificação de recurso de runtime padrão. Depois que um desenvolvedor do Spark cria um Aplicativo do serviço Data Flow, qualquer pessoa pode usá-lo sem se preocupar com as complexidades de implantá-lo, configurá-lo ou executá-lo. É possível usá-lo por meio de análises do Spark em painéis de controle, relatórios, scripts ou chamadas de API REST personalizados.
Toda vez que você chama o Aplicativo do serviço Data Flow, você cria uma Execução . Ele preenche os detalhes do modelo de aplicativo e o inicia em um conjunto específico de recursos IaaS.