Visão Geral do Serviço Data Flow
Saiba mais sobre o serviço Data Flow e como você pode usá-lo para criar, compartilhar, executar e exibir facilmente a saída dos aplicativos Apache Spark .
O que é o Oracle Cloud Infrastructure Data Flow
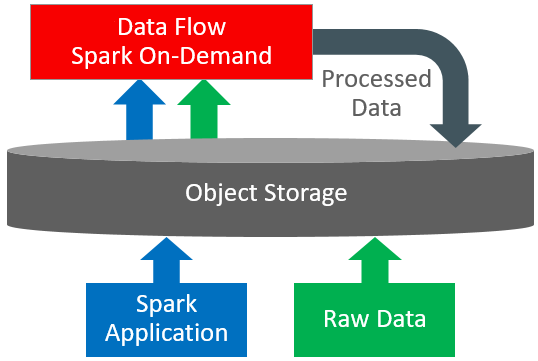
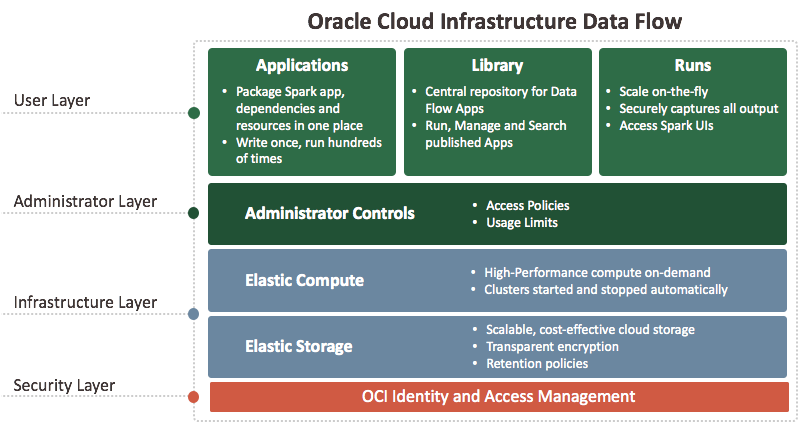
O serviço Data Flow é uma plataforma sem servidor baseada em nuvem com uma interface de usuário avançada. Ele permite que desenvolvedores do Spark e cientistas de dados criem, editem e executem jobs do Spark em qualquer escala, sem a necessidade de clusters, uma equipe de operações ou conhecimento altamente especializado do Spark. Estar sem servidor significa que não há infraestrutura para implantar ou gerenciar. Ele é totalmente orientado pelas APIs REST, proporcionando fácil integração com aplicativos ou workflows. Você pode controlar o serviço Data Flow usando esta API REST. Você pode executar o serviço Data Flow na CLI porque os comandos do serviço Data Flow estão disponíveis como parte da Interface de Linha de Comando do Oracle Cloud Infrastructure. É possível:
-
Estabelecer conexão com as origens de dados do Apache Spark.
-
Criar aplicativos Apache Spark reutilizáveis.
-
Iniciar jobs do Apache Spark em segundos.
-
Crie aplicativos Apache Spark usando SQL, Python, Java, Scala ou o script spark-submit.
-
Gerenciar todos os aplicativos Apache Spark em uma única plataforma.
-
Processar dados na Nuvem ou no local em seu data center.
-
Crie blocos de construção de Big Data que você pode montar facilmente em aplicativos de Big Data avançados.