Configurar Serviço Data Flow
Antes de criar, gerenciar e executar aplicativos no serviço Data Flow, o administrador do tenant (ou qualquer usuário com privilégios elevados para criar buckets e alterar políticas no IAM) deve criar grupos, um compartimento, armazenamento e políticas associadas no IAM.
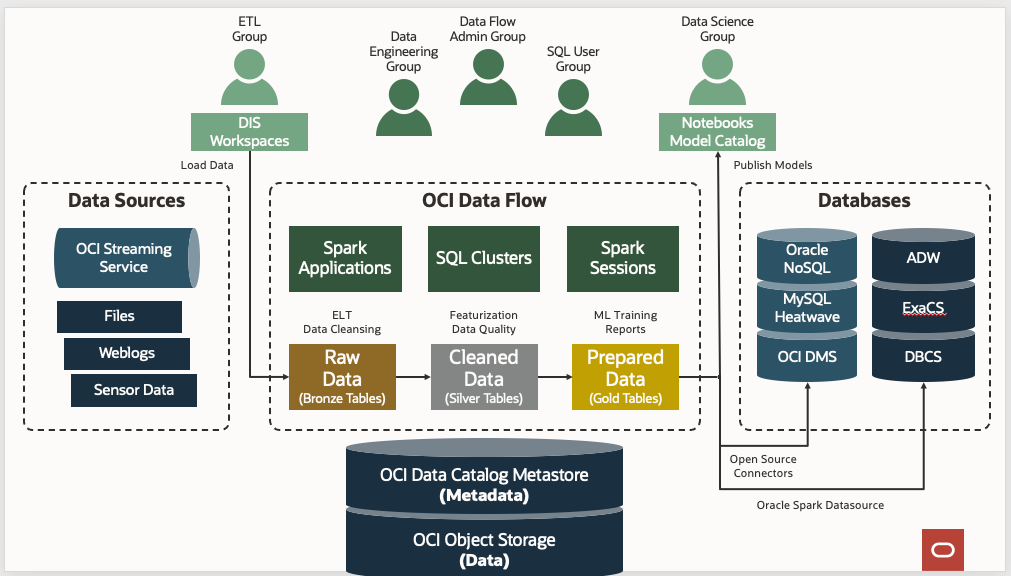 Estas são as etapas necessárias para configurar o serviço Data Flow:
Estas são as etapas necessárias para configurar o serviço Data Flow:- Configurando grupos de identidades.
- Configurando os buckets de compartimento e armazenamento de objetos.
- Configurando políticas de Gerenciamento de Identidades
Configurar Grupos de Identidades
Como prática geral, categorize os usuários do serviço Data Flow em três grupos para separar claramente seus casos de uso e nível de privilégio.
Crie os três grupos a seguir em seu serviço de identidade e adicione usuários a cada grupo:
- administradores de fluxo de dados
- dataflow-data-engineers
- fluxo de dados-usuários SQL
- administradores de fluxo de dados
- Os usuários desse grupo são administradores ou superusuários do serviço Data Flow. Eles têm privilégios para executar qualquer ação no serviço Data Flow ou para configurar e gerenciar diferentes recursos relacionados ao serviço Data Flow. Eles gerenciam Aplicativos pertencentes a outros usuários e Execuções iniciadas por qualquer usuário em sua tenancy. Os administradores de fluxo de dados não precisam de acesso de administração aos clusters do Spark provisionados sob demanda pelo serviço Data Flow, pois esses clusters são totalmente gerenciados pelo serviço Data Flow.
- dataflow-data-engineers
- Os usuários desse grupo têm privilégio de gerenciar e executar Aplicativos e Execuções do serviço Data Flow para seus jobs de engenharia de dados. Por exemplo, executando jobs ETL (Extract Transform Load) nos clusters Spark sem servidor sob demanda do serviço Data Flow. Os usuários desse grupo não têm nem precisam de acesso de administração aos clusters do Spark provisionados sob demanda pelo serviço Data Flow, pois esses clusters são totalmente gerenciados pelo serviço Data Flow.
- fluxo de dados-usuários SQL
- Os usuários desse grupo têm o privilégio de executar consultas SQL interativas conectando-se aos clusters SQL Interativos do serviço Data Flow por JDBC ou ODBC.
Configurando os Buckets de Compartimento e Armazenamento de Objetos
Siga estas etapas para criar um compartimento e buckets do serviço Object Storage para o serviço Data Flow.