Usando Notebooks para Estabelecer Conexão com o Serviço Data Flow
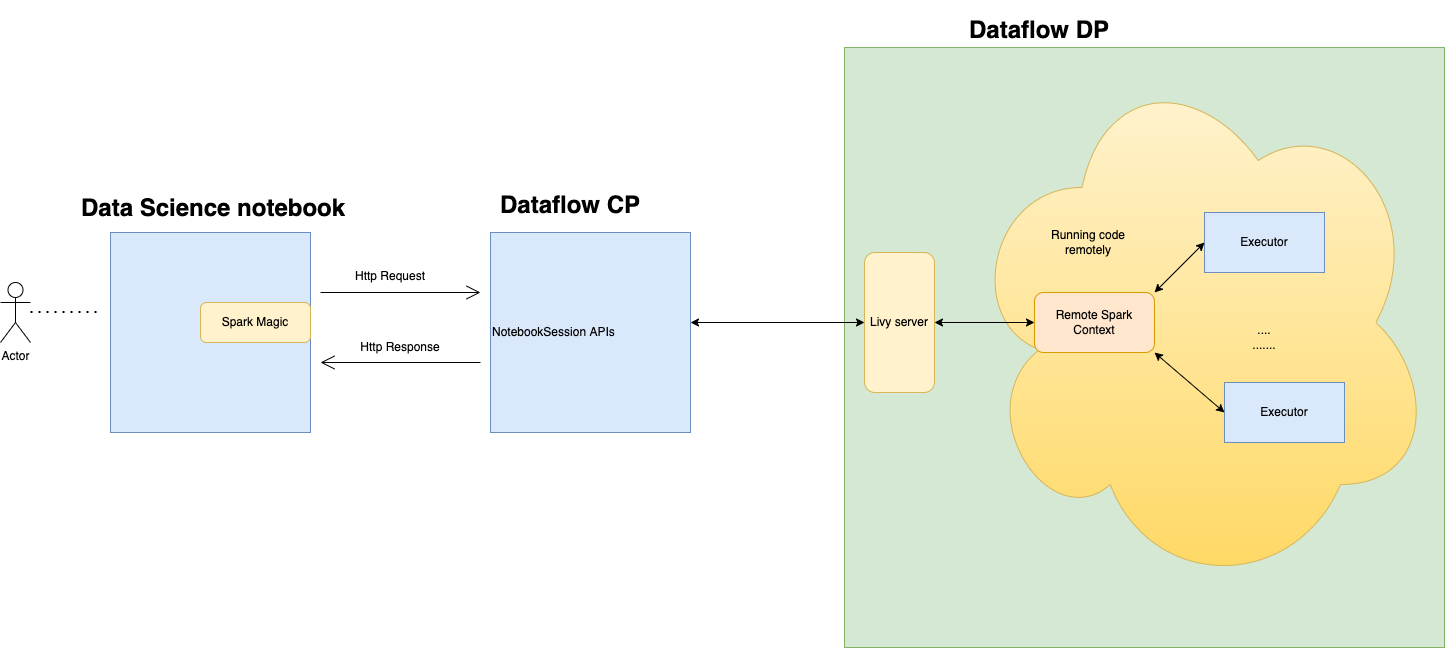
Você pode estabelecer conexão com o serviço Data Flow e executar um aplicativo Apache Spark em uma sessão de notebook do serviço Data Science. Essas sessões permitem executar cargas de trabalho interativas do Spark em um cluster de Fluxo de Dados de longa duração por meio de uma integração do Apache Livy.
O serviço Data Flow usa Notebooks Jupyter totalmente gerenciados para permitir que cientistas de dados e engenheiros de dados criem, visualizem, colaborem e depurem aplicativos de engenharia de dados e ciência de dados. Você pode gravar esses aplicativos em Python, Scala e PySpark. Você também pode conectar uma sessão de notebook do serviço Data Science ao serviço Data Flow para executar aplicativos. Os kernels e aplicativos do serviço Data Flow são executados no Oracle Cloud Infrastructure Data Flow. O Data Flow é um serviço Apache Spark totalmente gerenciado que executa tarefas de processamento em conjuntos de dados extremamente grandes, sem a necessidade de implantar ou gerenciar a infraestrutura. Para obter mais informações, consulte a documentação do serviço Data Flow.
O Apache Spark é um sistema de computação distribuído projetado para processar dados em escala. Ele suporta tarefas SQL em grande escala, tarefas de processamento em batch e de streams e tarefas de aprendizado de máquina. O Spark SQL fornece suporte semelhante a banco de dados. Para consultar dados estruturados, use o Spark SQL. Ele é uma implementação SQL padrão ANSI.
O serviço Data Flow é um serviço Apache Spark totalmente gerenciado que executa tarefas de processamento em conjuntos de dados extremamente grandes, sem infraestrutura para implantar ou gerenciar. Você pode usar o Spark Streaming para executar ETL na nuvem em seus dados de streaming produzidos continuamente. Ele permite a entrega rápida de aplicativos porque você pode se concentrar no desenvolvimento de aplicativos, não no gerenciamento de infraestrutura.
O Apache Livy é uma interface REST para o Spark. Submeta jobs do Spark tolerantes a falhas do notebook usando métodos síncronos e assíncronos para recuperar a saída.
O SparkMagic permite comunicação interativa com o Spark usando o Livy. Usando a diretiva mágica `%%spark` em uma célula de código JupyterLab. Os comandos SparkMagic estão disponíveis para o ambiente conda do serviço Spark 3.2.1 e do serviço Data Flow.
As Sessões do serviço Data Flow suportam recursos de cluster do serviço Data Flow de dimensionamento automático. Para obter mais informações, consulte Dimensionamento Automático na documentação do serviço Data Flow. As Sessões do Serviço Data Flow suportam o uso de ambientes conda como ambientes de runtime Spark personalizáveis.
- Limitações
-
-
As Sessões do serviço Data Flow duram até 7 dias ou 10.080 minutos (maxDurationInMinutes).
- As sessões do serviço Data Flow têm um valor de timeout por inatividade padrão de 480 minutos (8 horas) (idleTimeoutInMinutes). Você pode configurar outro valor.
- A Sessão do serviço Data Flow só está disponível por meio de uma Sessão de Notebook do serviço Data Science.
- Somente o Spark versão 3.2.1 é compatível.
-
Assista ao vídeo tutorial sobre como usar o Data Science com o Data Flow. Consulte também a documentação do Oracle Accelerated Data Science SDK para obter mais informações sobre como integrar o serviço Data Science e o serviço Data Flow.