Aplicativos ML
ML Applications é uma representação independente de casos de uso de ML no Data Science.
O ML Applications é um novo recurso do Data Science que oferece uma plataforma MLOps robusta para entrega de IA/ML. Ele padroniza o empacotamento e a implementação da funcionalidade de IA/ML, permitindo que você crie, implante e opere o machine learning como serviço. Com Aplicativos de ML, você pode aproveitar a Ciência de Dados para implementar casos de uso de IA/ML e provisioná-los em produção para seus aplicativos ou clientes. Ao encurtar o ciclo de vida de desenvolvimento de meses para semanas, os Aplicativos de ML aceleram o tempo de lançamento no mercado, reduzindo a complexidade operacional e o custo total de propriedade. Ele fornece uma plataforma de ponta a ponta para implementar, validar e promover soluções de ML em todos os estágios - desde o desenvolvimento e a garantia de qualidade até a pré-produção e a produção.
O ML Applications também suporta uma arquitetura desacoplada, fornecendo uma camada de integração unificada entre os recursos de IA/ML e os aplicativos clientes. Isso permite o desenvolvimento, o teste e a evolução independentes de soluções de ML sem exigir alterações no aplicativo cliente, permitindo uma integração perfeita e inovação mais rápida.
Aplicativos de ML são ideais para provedores de SaaS, que precisam provisionar e manter a funcionalidade de ML em uma frota de clientes, garantindo ao mesmo tempo o isolamento rigoroso de dados e cargas de trabalho. Ele permite que os fornecedores do SaaS forneçam os mesmos recursos baseados em ML para muitos locatários sem comprometer a segurança ou a eficiência operacional. Quer esteja incorporando insights orientados por IA, automatizando a tomada de decisões ou permitindo análises preditivas, os Aplicativos de ML garantem que cada cliente SaaS se beneficie de uma implementação de ML totalmente gerenciada e isolada.
Além do SaaS, o ML Applications também é ideal para implementações multirregionais e organizações que buscam criar um mercado de ML onde os provedores possam se registrar, compartilhar e monetizar soluções de IA/ML. Os clientes podem instanciar e integrar perfeitamente esses recursos de ML em seus fluxos de trabalho com o mínimo de esforço.
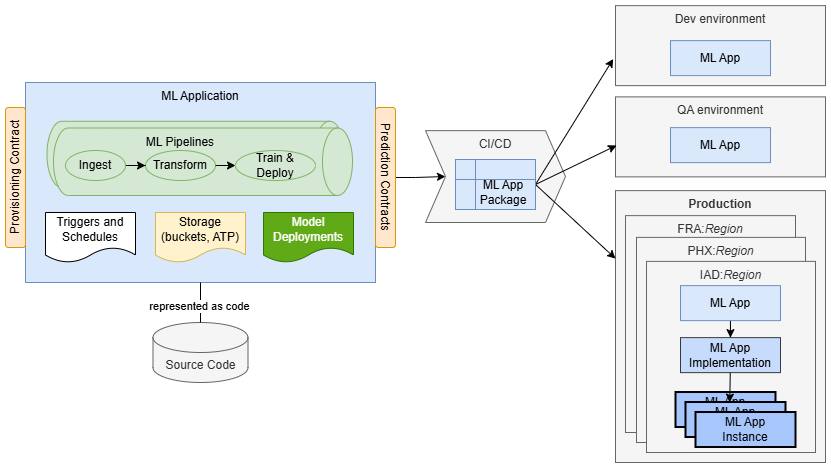
Por exemplo, um Aplicativo ML para um caso de uso de previsão de rotatividade de clientes pode consistir em:
- um Pipeline com etapas de ingestão, transformação e treinamento que preparam dados de treinamento, treinam um novo modelo e o implantam.
- um Bucket que é usado para armazenar dados ingeridos e transformados.
- um Trigger que atua como um ponto de entrada e garante a execução segura de execuções de pipeline no contexto de um cliente SaaS específico.
- uma Programação que aciona execuções periódicas do pipeline de treinamento para manter o modelo atualizado.
- uma Implantação de Modelo que atende a solicitações de previsão provenientes de clientes.
Aplicativos ML permitem representar toda a implementação como código e armazená-la e criá-la em um repositório de código-fonte. A solução é empacotada como um pacote de Aplicativos de ML que contém principalmente metadados. Os metadados incluem informações de controle de versão, o contrato de provisionamento e declarações de dependências de ambiente, tornando o pacote independente de região e de ambiente. Quando construído, o pacote pode ser implantado em qualquer ambiente de destino sem modificações. Isso ajuda a padronizar o empacotamento e a entrega de sua funcionalidade de ML.
Quando um Aplicativo de ML é implantado, ele é representado por recursos de Aplicativo de ML e Implementação de Aplicativo de ML. Nesta fase, ele pode ser provisionado para uso. Normalmente, um aplicativo cliente (como uma plataforma SaaS, sistema empresarial ou ferramenta de automação de workflow) solicita o serviço Aplicativo ML para provisionar uma nova instância do Aplicativo ML para um cliente ou unidade operacional específica. Somente nesse ponto a solução será totalmente instanciada e pronta para uso.
Resumindo, os Aplicativos de ML fornecem uma maneira padronizada de criar, empacotar e fornecer funcionalidade de ML em escala, reduzindo a complexidade e acelerando o tempo de produção em vários cenários, incluindo:
- SaaS Adoção de IA, em que as plataformas SaaS precisam integrar recursos de ML para milhares de clientes, garantindo segurança, escalabilidade e eficiência operacional.
- Implantações multirregionais, nas quais a funcionalidade ML deve ser provisionada consistentemente em diferentes locais com o mínimo de sobrecarga operacional.
- Adoção de IA empresarial, em que as organizações precisam implementar instâncias de ML isoladas entre equipes, unidades de negócios ou subsidiárias, mantendo a governança e a conformidade.
- Mercados de ML, onde os provedores podem empacotar e distribuir soluções de ML, permitindo que os clientes descubram, implementem e usem-nas facilmente como um serviço.
Além do SaaS, os Aplicativos de ML podem ser usados em vários outros cenários. Eles são benéficos sempre que há necessidade de fornecer uma solução de ML muitas vezes, como em diferentes locais geográficos. Além disso, os Aplicativos de ML podem ser usados para criar um mercado em que os provedores possam registrar seus aplicativos e oferecê-los como um serviço aos clientes, que podem instanciá-los e usá-los.
A própria capacidade de Aplicativos de ML é gratuita. Você só será cobrado pela infraestrutura subjacente (computação, armazenamento e rede) usada, sem marcação extra.
Recursos de Aplicativos de ML
- Aplicativo ML
- Um recurso que representa um caso de uso de ML e serve como um guarda-chuva para Implementações e Instâncias de Aplicativos de ML. Ele define e representa uma solução de ML, permitindo que os provedores forneçam recursos de ML aos consumidores.
- Implementação de Aplicativo de ML
- Um recurso que representa uma solução específica para o caso de uso de ML definido por um Aplicativo de ML. Ele contém todos os detalhes da implementação que permitem a instanciação da solução para os consumidores. Um Aplicativo ML pode ter apenas uma implementação.
- Versão de Implementação do Aplicativo de ML
- Um recurso somente leitura que representa um instantâneo de uma Implementação de Aplicativo ML. A versão é criada automaticamente quando uma Implementação do Aplicativo ML atinge um novo estado consistente.
- Instância do Aplicativo ML
- Um recurso que representa uma única instância isolada de um Aplicativo de ML, permitindo que os consumidores configurem e usem a funcionalidade de ML fornecida. As instâncias de aplicativos de ML desempenham um papel crucial na definição de limites para o isolamento de dados, cargas de trabalho e modelos. Esse nível de isolamento é essencial para as organizações do SaaS, pois significa que elas podem garantir a segregação e a segurança dos recursos de seus clientes.
- ML - Visualização da Instância do Aplicativo
- Um recurso somente para leitura, que é uma cópia gerenciada automaticamente da Instância do Aplicativo ML estendida com detalhes adicionais, como referências a componentes da instância. Ele permite que os provedores rastreiem o consumo de seus Aplicativos de ML. Isso significa que os provedores podem observar detalhes de implementação de instâncias, monitorá-las e solucioná-las de problemas. Quando consumidores e provedores trabalham em diferentes tenancies, as exibições da Instância do Aplicativo ML são a única maneira de os provedores reunirem informações sobre o consumo de seus aplicativos.
Os recursos do Aplicativo ML são somente para leitura na Console do OCI. Para gerenciamento e criação dos recursos, você pode usar a CLI mlapp que faz parte do projeto de amostra, da CLI oci do Aplicativo ML ou das APIs.
Conceitos do Aplicativo ML
- Pacote de Aplicativos ML
- Trigger do Aplicativo ML
- Pacote de Aplicativos ML
- Permite um empacotamento padronizado da funcionalidade ML que é independente de região e ambiente. Ele contém detalhes de implementação, como componentes, descritores e esquema de configuração do Terraform, e é uma solução portátil que pode ser usada em qualquer tenancy, região ou ambiente. As dependências de infraestrutura da implementação contida (por exemplo, VCN e OCIDs de Log) que são específicas de uma região ou ambiente são fornecidas como argumentos de pacote durante o processo de upload.
- Acionador de Aplicativo ML
- Os triggers permitem que os provedores de Aplicativos ML especifiquem o mecanismo de trigger para seus jobs ou pipelines de ML, facilitando a implementação do MLOps totalmente automatizado. Triggers são os pontos de entrada para as execuções de seus workflows de ML. Eles são definidos por arquivos YAML dentro do pacote de Aplicativos ML como componentes de instância. Os acionadores são criados automaticamente quando uma nova Instância do Aplicativo ML é criada, mas somente quando todos os outros componentes da instância são criados. Assim, quando um trigger é criado, ele pode se referir a outros componentes de instância criados anteriormente.
Funções do Aplicativo ML
- Provedores
- Consumidores
- Provedor
- Provedores são clientes da OCI que criam, implementam e operam recursos de ML. Eles empacotam e implantam recursos de ML como Aplicativos e Implementações de ML. Eles usam Aplicativos de ML para fornecer serviços de previsão de maneira como Serviço aos consumidores. Eles garantem que os serviços de previsão atendam aos acordos de nível de serviço (SLAs) acordados.
- Consumidor
- Os consumidores são clientes da OCI que criam Instâncias de Aplicativo de ML e usam serviços de previsão oferecidos por essas instâncias. Normalmente, os consumidores são aplicativos SaaS, como o Fusion. Eles usam Aplicativos de ML para integrar a funcionalidade de ML e entregá-la a seus clientes.
Gerenciamento do Ciclo de Vida
As aplicações de ML abrangem todo o ciclo de vida das soluções de ML.
Isso começa com os estágios iniciais de design, onde as equipes podem concordar com os contratos e começar a trabalhar de forma independente. Inclui implantação de produção, gerenciamento de frota e o lançamento de novas versões.
Build
- Representação como código
- Toda a solução, incluindo todos os seus componentes e fluxos de trabalho, é representada como código. Isso promove as melhores práticas de desenvolvimento de software, como consistência e reprodutibilidade.
- Automação
- Com os aplicativos de ML, a automação é simples. Você pode se concentrar em automatizar os fluxos de trabalho dentro da solução usando os acionadores Data Science Scheduler, ML Pipelines e ML Application. A automação dos fluxos de provisionamento e configuração é gerenciada pelo serviço ML Application.
- Embalagem padronizada
- Os Aplicativos de ML fornecem empacotamento independente do ambiente e independente da região, incluindo metadados para controle de versão, dependências e configurações de provisionamento.
Implantar
- Implantação gerenciada pelo serviço
- Você pode implantar e gerenciar suas soluções de ML como recursos do Aplicativo ML. Ao criar seu recurso de Implementação de Aplicativo de ML, você pode implantar sua implementação em pacote como um pacote de Aplicativos de ML. O Serviço de Aplicativo de ML orquestra a implantação para você, validando sua implementação e criando os recursos do OCI correspondentes.
- Ambientes
- Os Aplicativos de ML permitem que os provedores implementem por meio de vários ambientes de ciclo de vida, como desenvolvimento, garantia de qualidade e pré-produção, fornecendo uma implementação controlada dos Aplicativos de ML para produção. Na produção, algumas organizações oferecem aos clientes vários ambientes, como "preparação" e "produção". Com os Aplicativos de ML, novas versões podem ser implantadas, avaliadas e testadas em "preparação" antes de serem promovidas à "produção". Isso dá aos clientes um grande controle sobre a adoção de novas versões, incluindo a funcionalidade de ML.
- Implantação entre regiões
- Implemente soluções em várias regiões, incluindo as não comerciais, como regiões governamentais.
Operar
- Entrega como serviço
- Os provedores oferecem serviços de previsão "como serviço", lidando com toda a manutenção e operações. Os clientes consomem os serviços de previsão sem ver os detalhes da implementação.
- Monitoramento e Solução de Problemas
- Monitoramento simplificado, solução de problemas e análise de causa raiz com controle de versão detalhado, rastreabilidade e insights contextuais.
- Desenvolvabilidade
- Ajude a fornecer iterações, atualizações e patches rápidos com tempo de inatividade zero, garantindo melhoria contínua e adaptação às necessidades do cliente.
Recursos Principais
Alguns dos principais recursos dos Aplicativos de ML são:
- Entrega As-a-Service
- Os Aplicativos de ML permitem que as equipes criem e forneçam serviços de previsão como SaaS (software como serviço). Isso significa que os provedores podem gerenciar e evoluir soluções sem afetar os clientes. O ML Applications serve como um meta-serviço, facilitando a criação de novos serviços de previsão que podem ser consumidos e dimensionados como ofertas SaaS.
- nativo do OCI
- A integração perfeita com os recursos da OCI garante consistência e simplifica a implementação em ambientes e regiões.
- Embalagem padrão
- O empacotamento independente do ambiente e da região padroniza a implementação, facilitando a implementação de Aplicativos de ML globalmente.
- Isolamento de locatário
- Garante o isolamento completo de dados e cargas de trabalho para cada cliente, aprimorando a segurança e a conformidade.
- Versão
- Suporta implementações em evolução com processos de lançamento independentes, permitindo atualizações e aprimoramentos rápidos.
- Atualizações sem tempo de inatividade
- Os upgrades de instância automatizados garantem um serviço contínuo sem interrupções.
- Provisionamento entre tenancies
- Suporta observabilidade entre tenancies e consumo no mercado, expandindo as possibilidades de implementação.
Aplicativos ML apresentam os seguintes recursos:
- Aplicativo ML
- Implementação de Aplicativo de ML
- Versão de Implementação do Aplicativo de ML
- Instância do Aplicativo ML
- ML - Visualização da Instância do Aplicativo
Valor Agregado
Os Aplicativos de ML servem como plataforma como serviço (PaaS), fornecendo às organizações a estrutura e os serviços básicos necessários para criar, implementar e gerenciar recursos de ML em escala.
Isso equipa as equipes com uma plataforma predefinida para modelar e implementar casos de uso de ML, eliminando a necessidade de desenvolver estruturas e ferramentas personalizadas. Assim, as equipes podem dedicar seus esforços à criação de soluções inovadoras de IA, reduzindo assim o tempo de lançamento no mercado e o custo total de propriedade dos recursos de ML.
O ML Applications oferece às organizações APIs e abstrações para supervisionar todo o ciclo de vida dos casos de uso de ML. As implementações são representadas como código, empacotadas em Pacotes de Aplicativos ML e implantadas em recursos de Implementação de Aplicativos ML. As versões históricas das implementações são rastreadas como recursos da Versão de Implementação do Aplicativo ML. ML Applications é a cola que estabelece a rastreabilidade entre todos os componentes usados pelas implementações, controle de versão e informações de ambiente e dados de consumo do cliente. Por meio de Aplicativos de ML, as organizações obtêm insights precisos sobre quais implementações de ML são implementadas em ambientes e regiões, quais clientes usam aplicativos específicos e a integridade geral da frota de ML. Além disso, os Aplicativos de ML oferecem recursos de recuperação de instância, permitindo fácil recuperação de erros de infraestrutura e configuração.
Com limites bem definidos, os Aplicativos de ML ajudam no estabelecimento de contratos de provisionamento e previsão, permitindo que as equipes dividam e conquistem tarefas com mais eficiência. Por exemplo, as equipes que trabalham no código do aplicativo cliente (por exemplo, uma plataforma SaaS ou um sistema empresarial) podem colaborar perfeitamente com as equipes de ML concordando em contratos de previsão, permitindo que ambas as equipes trabalhem de forma independente. Da mesma forma, as equipes de ML podem definir contratos de provisionamento, permitindo que as equipes lidem com tarefas de provisionamento e configuração de forma autônoma. Esse desacoplamento elimina dependências e acelera os prazos de entrega.
O ML Applications simplifica a evolução das soluções de ML automatizando o processo de atualização de versão. As atualizações são orquestradas inteiramente por Aplicativos de ML, mitigando erros e permitindo o dimensionamento de soluções para muitas instâncias (clientes). Os implementadores podem promover e verificar alterações em uma cadeia de ambientes de ciclo de vida (por exemplo, desenvolvimento, garantia de qualidade, pré-produção, produção), mantendo o controle sobre a liberação de alterações para os clientes.
O isolamento do locatário se destaca como um benefício fundamental dos Aplicativos de ML, garantindo a segregação completa de dados e cargas de trabalho para cada cliente, aprimorando assim a segurança e a conformidade. Ao contrário dos métodos tradicionais que dependem do isolamento baseado em processos, os Aplicativos de ML permitem que os clientes implementem restrições com base em privilégios, protegendo o isolamento do inquilino mesmo em caso de defeitos.
Projetado com escalabilidade em mente, o ML Applications significa que as grandes organizações, especialmente as organizações SaaS, podem adotar uma plataforma padronizada para desenvolvimento de ML, garantindo consistência em muitas equipes. Centenas de soluções de ML podem ser desenvolvidas sem que toda a iniciativa de ML caia no caos. Graças à automação que abrange a implementação de pipelines de ML, a implantação de modelos e o provisionamento, as organizações do SaaS podem industrializar o desenvolvimento de recursos de ML para o SaaS e gerenciar com eficiência milhões de pipelines e modelos em execução autônoma na produção.
Tempo de comercialização
- Implementação padronizada
- Remove a necessidade de estruturas personalizadas, permitindo que as equipes se concentrem em casos de uso de negócios.
- Automação
- Aumenta a velocidade e reduz intervenções manuais, cruciais para dimensionar soluções SaaS.
- Separação de preocupações
- Limites claros, contratos e APIs permitem que diferentes equipes trabalhem de forma independente, simplificando o desenvolvimento e a implementação.
Custos operacionais e de desenvolvimento
- Custos de desenvolvimento reduzidos
- O uso de serviços predefinidos reduz a necessidade de trabalho básico.
- Desenvolvabilidade
- iterações rápidas e atualizações independentes com tempo de inatividade zero garantem melhoria contínua.
- Rastreabilidade
- Insights detalhados sobre ambientes, componentes e revisões de código ajudam a entender e gerenciar soluções de ML.
- Provisionamento e observabilidade automatizados
- Simplifica o gerenciamento e o monitoramento de soluções de ML, reduzindo a sobrecarga operacional.
- Gerenciamento de frotas
- Gerencie todo o ciclo de vida das instâncias de aplicativos de ML em escala. Os Aplicativos de ML fornecem visibilidade de todas as instâncias provisionadas, oferecem suporte a atualizações e upgrades em toda a frota e permitem provisionamento e desprovisionamento conforme necessário. Além disso, as soluções de ML criadas com Aplicativos de ML podem ser monitoradas usando o OCI Monitoring para acompanhar o desempenho e a integridade.
Segurança e Confiabilidade
- Isolamento de dados e cargas de trabalho
- Garante que os dados e as cargas de trabalho de cada cliente sejam isolados de forma segura.
- Confiabilidade
- Atualizações automatizadas e monitoramento robusto eliminam erros e garantem operações estáveis.
- Nenhum problema de vizinho barulhento
- Garante que as cargas de trabalho não interfiram entre si, mantendo o desempenho e a estabilidade.
Workflow de Criação e Implantação
O desenvolvimento de aplicativos de ML se assemelha ao desenvolvimento de software padrão.
Engenheiros e cientistas de dados gerenciam sua implementação em um repositório de código-fonte, usando a documentação e os repositórios do ML Applications para obter orientação. Normalmente, eles começam clonando um projeto de amostra fornecido pela equipe de Aplicativos de ML, que promove as melhores práticas e ajuda as equipes do SaaS a iniciar rapidamente o desenvolvimento, evitando uma curva de aprendizado íngreme.
Começando com um exemplo de ponta a ponta totalmente funcional, as equipes podem criar, implementar e provisionar rapidamente o exemplo, familiarizando-se rapidamente com Aplicativos de ML. Em seguida, eles podem alterar o código para adicionar uma lógica de negócios específica, como adicionar uma etapa de pré-processamento ao pipeline de treinamento ou ao código de treinamento personalizado.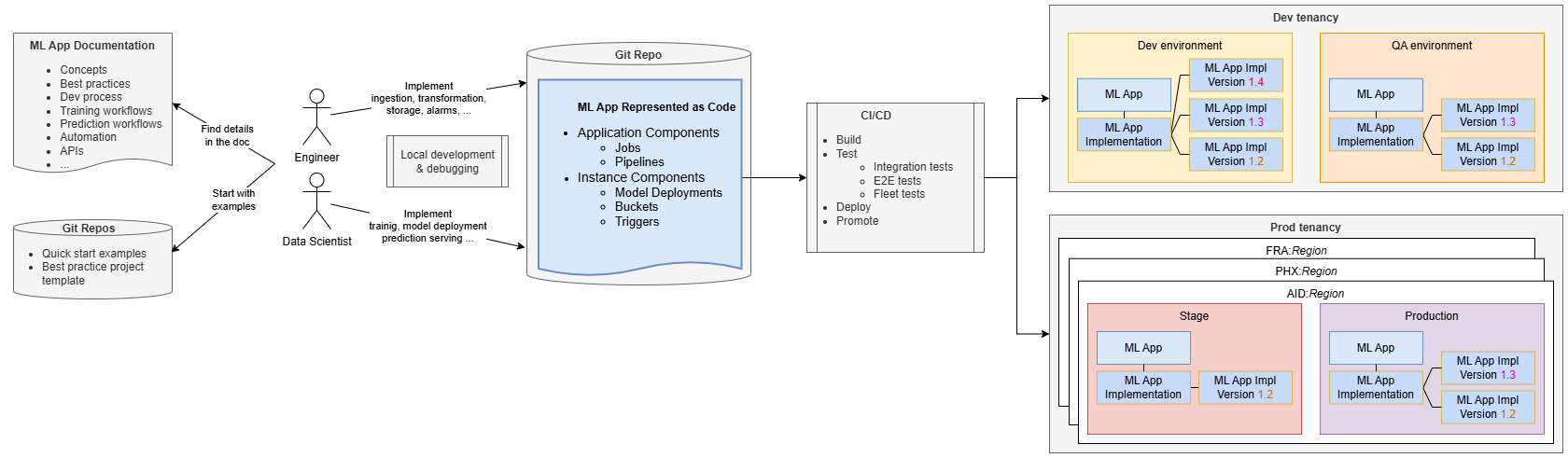
O desenvolvimento e o teste podem ser conduzidos localmente em seus computadores, mas a configuração de Integração Contínua/Entrega Contínua (CI/CD) é essencial para ciclos de lançamento mais rápidos, colaboração aprimorada e consistência. As equipes podem usar exemplos e ferramentas fornecidos pela equipe do Aplicativo de ML para implementar pipelines de CI/CD.
Os pipelines de CI/CD implantam o Aplicativo de ML no ambiente necessário (por exemplo, Desenvolvimento) e executam testes de integração para garantir a exatidão da solução de ML independentemente do aplicativo SaaS. Esses testes podem implantar o Aplicativo e sua implementação, criar instâncias de teste, acionar o fluxo de treinamento e testar o modelo implantado. Os testes de ponta a ponta garantem a integração adequada com o aplicativo SaaS.
Quando seu Aplicativo de ML é implantado, ele é representado como um recurso de Aplicativo de ML junto com uma Implementação de Aplicativo de ML. O recurso Versão de Implementação do Aplicativo ML ajuda a rastrear informações sobre as diferentes versões implantadas. Por exemplo, a versão 1.3 é a versão implantada mais recente, que atualiza a versão anterior 1.2.
Os pipelines de CI/CD precisam promover a solução por meio de ambientes de ciclo de vida até a produção. Na produção, geralmente é necessário implantar o Aplicativo ML em várias regiões para se alinhar com a implantação do aplicativo cliente. Quando os clientes têm vários ambientes de produção (por exemplo, preparação e produção), os pipelines CI/CD precisam promover o Aplicativo ML por meio de todos esses ambientes.
Você pode usar Pipelines de ML como componentes de aplicativos em seus Aplicativos de ML para implementar um workflow de várias etapas. Os Pipelines de ML podem orquestrar etapas arbitrárias ou jobs que você precisa implementar.
Operação de Implantação
A operação de implantação envolve várias etapas principais para garantir que os Aplicativos de ML sejam implementados e atualizados corretamente entre os ambientes.
Primeiro, é necessário garantir que os recursos de Aplicativo de ML e Implementação de Aplicativo de ML existam. Se não, eles são criados. Se eles já existirem, eles serão atualizados:
- Crie ou atualize o recurso Aplicativo ML. Isso representa todo o caso de uso de ML e todos os recursos e informações relacionados.
- Crie ou atualize o recurso Implementação do Aplicativo ML. Isso existe nos recursos do Aplicativo ML e representa a implementação, permitindo que você a gerencie. Você precisa da Implementação do Aplicativo ML para implantar seu pacote de implementação.
- Faça upload do Pacote de Aplicativos ML. Este pacote contém a implementação do seu Aplicativo ML junto com outros metadados, empacotados como um arquivo zip com uma estrutura específica.
Quando um pacote é carregado em um recurso de Implementação de Aplicativo ML, o serviço de Aplicativo ML o valida e, em seguida, executa a implantação. Simplificando, as principais etapas durante a implantação do pacote são:
- Os componentes do aplicativo (componentes multitenant) são instanciados.
- Todos os recursos existentes da Instância do Aplicativo de ML já provisionados para clientes do SaaS são atualizados. Os componentes de cada instância são atualizados para corresponder às definições recém-carregadas por upload.
Fluxo de Provisionamento
Para que as Instâncias do Aplicativo ML possam ser provisionadas, o Aplicativo ML deve ser implantado e registrado no aplicativo cliente.
- 1. Assinatura do cliente e verificação do Aplicativo de ML
- O fluxo de provisionamento começa quando um cliente se inscreve no aplicativo cliente. O aplicativo cliente verifica se algum Aplicativo ML é provisionado para o cliente.
- 2. Solicitação de provisionamento
- Se Aplicativos ML forem necessários, o aplicativo cliente entrará em contato com o serviço Aplicativo ML e solicitará o provisionamento de uma instância, incluindo detalhes de configuração específicos do tenant.
- 3. Criando e configurando uma Instância do Aplicativo ML
- O serviço Aplicativo ML cria o recurso Instância do Aplicativo ML com a configuração específica. Esse recurso é gerenciado pelo aplicativo cliente, que pode ativar, desativar, reconfigurar ou excluir a instância. Além disso, o serviço Aplicativo ML cria um recurso de Exibição de Instância do Aplicativo ML para que os provedores os informem sobre o consumo e os componentes da instância do Aplicativo ML. O serviço Aplicativo ML também cria todos os componentes de instância definidos na implementação, como triggers, buckets, execuções de pipeline, execuções de job e implantações de modelo.
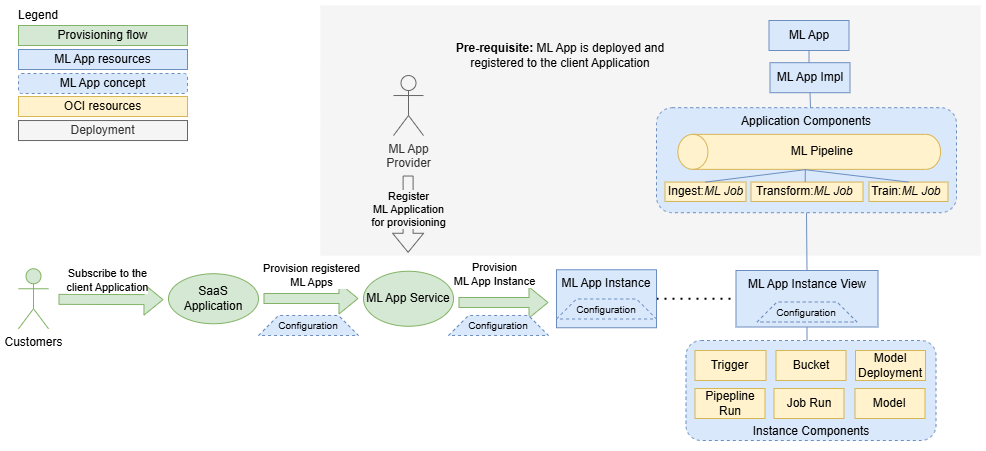
Quando um novo pacote de Aplicativos de ML é implantado após a criação de instâncias, o serviço Aplicativo de ML garante que todas as instâncias sejam atualizadas com as definições de implementação mais recentes.
Fluxo de Runtime
Quando seu Aplicativo de ML é provisionado para um cliente, toda a implementação é totalmente instanciada.
- Componentes multitenant
- Instanciado apenas uma vez em um Aplicativo de ML, oferecendo suporte a todos os clientes (por exemplo, pipelines de ML). Eles são definidos como componentes do aplicativo.
- Componentes de tenant único
- Instanciado para cada cliente, executado apenas dentro do contexto de um cliente específico. Eles são definidos como componentes de instância.
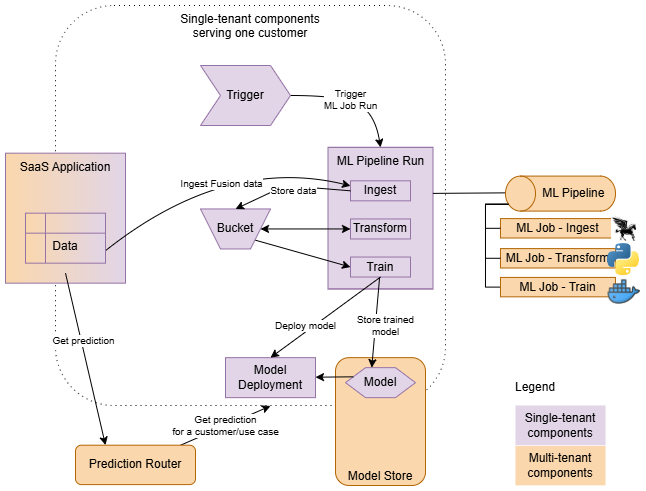
Pipelines ou jobs em sua implementação são iniciados por triggers. Os acionadores criam pipeline e execuções de job no contexto de cada cliente, passando os parâmetros apropriados (contexto) para as execuções criadas. Além disso, os gatilhos são essenciais para garantir o isolamento do inquilino. Eles garantem que o controlador de recursos (identidade) dos recursos da Instância do Aplicativo ML seja herdado por todas as cargas de trabalho que iniciam. Isso permite criar políticas que estabeleçam um sandbox de segurança para cada instância provisionada.
As Pipelines permitem definir um conjunto de etapas e orquestrá-las. Por exemplo, um fluxo típico pode envolver a ingestão de dados do aplicativo cliente, transformando-os em um formato adequado para treinamento e, em seguida, treinando e implantando novos modelos.
A Implantação de Modelo é usada como backend de previsão, mas não é acessada diretamente pelo aplicativo cliente. O aplicativo cliente, que pode ser um locatário único (provisionado para cada cliente) ou vários locatários (servindo muitos clientes), obtém previsões entrando em contato com o Roteador de Previsão de Aplicativo de ML. O Roteador de Previsão localiza o backend de previsão correto com base na instância usada e no caso de uso de previsão implementado pelo seu aplicativo.
Exemplo de risco fetal
Vejamos os detalhes da implementação de um Aplicativo de ML de amostra para entender como implementar um.
Utilizamos um aplicativo de predição de risco fetal que utiliza dados de Cardiotocografia (CTG) para classificar o estado de saúde de um feto. Este aplicativo visa ajudar os profissionais de saúde, prevendo se a condição fetal é normal, arriscada ou anormal com base nos registros de exames de CTG.
Detalhes da Implementação
A implementação segue o padrão de previsão on-line padrão e consiste em um pipeline com etapas de ingestão, transformação e treinamento e implantação de modelo.
-
Ingestão: Esta etapa prepara o conjunto de dados bruto e o armazena no bucket da instância.
-
Transformação: a preparação de dados é executada usando a biblioteca ADS. Isso envolve:
- Amostragem: O conjunto de dados é inclinado para casos normais, portanto, a amostragem é feita para equilibrar as classes.
- Dimensionamento de Recursos: Os recursos são dimensionados usando QuantileTransformer.
- O conjunto de dados preparado é armazenado novamente no bucket da instância.
-
Treinamento e Implantação de Modelo: O algoritmo XGBoost é usado para treinar os modelos por causa de sua precisão superior em comparação com outros algoritmos (por exemplo, Random Forest, KNN, SVM). A biblioteca ADS é usada para esse processo e o modelo treinado é implantado na implantação do modelo de instância.
A implementação consiste em:
-
Componentes do aplicativo: O componente principal é o pipeline que orquestra três jobs:
- Job de ingestão
- Job de transformação
- Trabalho de treinamento
-
Componentes de instância: Quatro componentes de instância são definidos aqui:
- Bucket de instância
- Modelo default
- Implantação de modelo
- Trigger de pipeline
- descriptor.yaml: Contém os metadados que descrevem a implementação (o pacote).
-
Componentes do aplicativo: O componente principal é o pipeline que orquestra três jobs:
O código-fonte está disponível neste projeto.
descriptor.yaml :descriptorSchemaVersion: 1.0
mlApplicationVersion: 1.0
implementationVersion: 1.2
# Package arguments allow you to resolve dependencies of your implementation that are environment-specific.
# Typically, OCIDs of infrastructure resources like subnets, data science projects, logs, etc., are passed as package arguments.
# For illustration purposes, only 2 package arguments are listed here.
packageArguments:
# The implementation needs a subnet, and it is environment-specific. It is provided as a package argument.
subnet_id:
type: ocid
mandatory: true
description: "Subnet OCID for ML Job"
# similarly for the ID of a data science project
data_science_project_id:
type: ocid
mandatory: true
description: "Project OCID for ML Job"
# Configuration schema allows you to define the schema for your instance configuration.
# It will be used during provisioning, and the initial configuration provided must conform to the schema.
configurationSchema:
# The implementation needs to know the name of the external bucket (not managed by ML Apps) where the raw dataset is available.
external_data_source:
type: string
mandatory: true
description: "External Data Source (OCI Object Storage Service URI in form of <a target="_blank" href="oci://">oci://</a><bucket_name>@<namespace>/<object_name>"
sampleValue: "<a target="_blank" href="oci://test_data_fetalrisk@mynamespace/test_data.csv">oci://test_data_fetalrisk@mynamespace/test_data.csv</a>"
# This application provides 1 prediction use case (1 prediction service).
onlinePredictionUseCases:
- name: "fetalrisk"Todos os recursos do OCI usados em sua implementação são definidos usando o Terraform. O Terraform permite especificar de forma declarativa os componentes necessários para sua implementação.
# For illustration purposes, only a partial definition is listed here.
resource oci_datascience_job ingestion_job {
compartment_id = var.app_impl.compartment_id
display_name = "Ingestion_ML_Job"
delete_related_job_runs = true
job_infrastructure_configuration_details {
block_storage_size_in_gbs = local.ingestion_job_block_storage_size
job_infrastructure_type = "STANDALONE"
shape_name = local.ingestion_job_shape_name
job_shape_config_details {
memory_in_gbs = 16
ocpus = 4
}
subnet_id = var.app_impl.package_arguments.subnet_id
}
job_artifact = "./src/01-ingestion_job.py"
}resource "oci_objectstorage_bucket" "data_storage_bucket" {
compartment_id = var.compartment_ocid
namespace = var.bucket_namespace
name = "ml-app-fetal-risk-bucket-${var.instance_id}"
access_type = "NoPublicAccess"
}Os componentes da instância geralmente se referem a variáveis específicas da instância, como id da instância. Você pode confiar em variáveis implícitas definidas pelo serviço de Aplicativo ML. Quando precisar, por exemplo, do nome do aplicativo, você poderá consultá-lo com ${var.ml_app_name}.
Em conclusão, a implementação de Aplicativos de ML requer alguns componentes principais: um descritor de pacote e algumas definições do Terraform. Seguindo a documentação fornecida, você pode aprender detalhes sobre como criar seus próprios Aplicativos de ML.