Traga Seu Próprio Contêiner
Crie e use um contêiner personalizado (Bring Your Own Container ou BYOC) como a dependência de runtime ao criar uma implantação de modelo.
Com contêineres personalizados, você pode empacotar dependências de sistema e idioma, instalar e configurar servidores de inferência e configurar diferentes tempos de execução de idioma. Tudo dentro dos limites definidos de uma interface com um recurso de implantação de modelo para executar os contêineres.
O BYOC permite a transferência de contêineres entre diferentes ambientes para que você possa migrar e implantar aplicativos na OCI Cloud.
Para executar o job, crie um Dockerfile e, em seguida, crie uma imagem. Você começa com um Dockerfile, que usa uma imagem do Python. O Dockerfile foi projetado para que você possa criar builds locais e remotos. Use o build local ao testar localmente seu código. Durante o desenvolvimento local, você não precisa criar uma nova imagem para cada alteração de código.
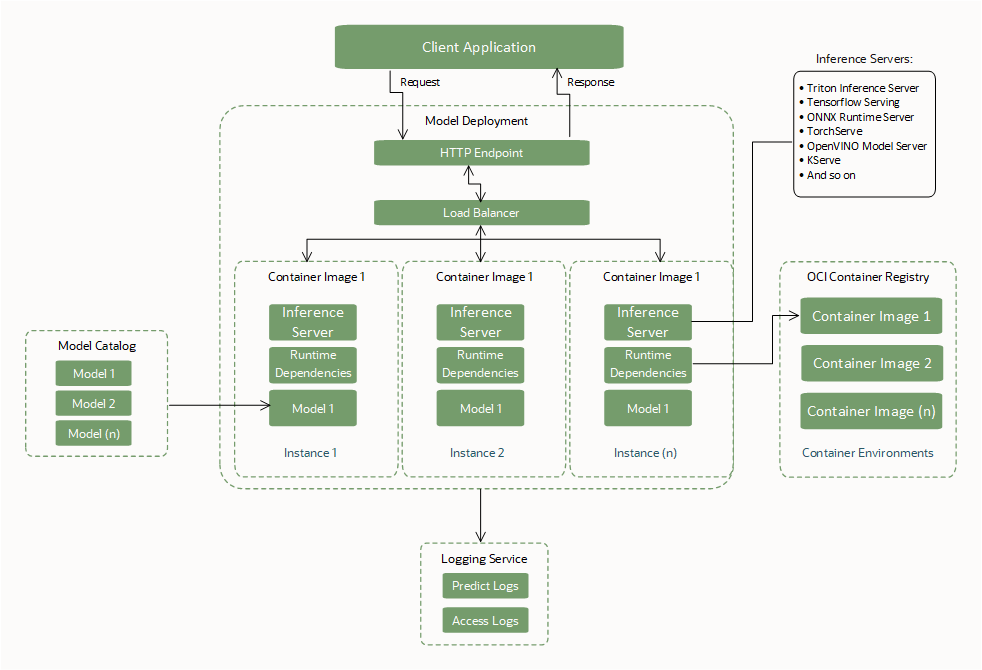
Interfaces Obrigatórias BYOC
Crie ou especifique essas interfaces necessárias para usar uma implantação de modelo.
Artefato de Modelo
| Interface | Descrição |
|---|---|
| Faça upload de artefatos de modelo para o catálogo de modelos do Data Science. | Os artefatos de modelo, como lógica de pontuação, modelo de ML e arquivos dependentes, devem ser carregados no catálogo de modelos do Data Science antes de serem usados por um recurso de implantação de modelo. |
| Nenhum arquivo obrigatório. |
Nenhum arquivo é obrigatório para criar uma implantação de modelo BYOC.
Observação: Quando BYOC não é usado para uma implantação de modelo, os arquivos |
| Localização dos artefatos de modelo montados. |
Durante as implantações do modelo de bootstrap, descompacte o artefato do modelo e monte os arquivos no diretório Compactar um conjunto de arquivos (incluindo modelo de ML e lógica de pontuação) ou uma pasta contendo conjunto de arquivos tem um caminho de localização diferente para o modelo de ML dentro do contêiner. Certifique-se de que o caminho correto seja usado ao carregar o modelo na lógica de pontuação. |
Imagem do Contêiner
| Interface | Descrição |
|---|---|
| Dependências de runtime de pacote. | Empacote a imagem do contêiner com as dependências de runtime necessárias para carregar e executar o binário do modelo ML. |
| Empacote um servidor Web para expor pontos finais. |
Empacote a imagem do contêiner com um servidor Web sem monitoramento de estado baseado em http (FastAPI, Flask, Triton, serviço TensorFlow, serviço PyTorch etc.). Exponha um ponto final
Observação: Se o ponto final do seu servidor de inferência não puder ser personalizado para atender à interface do ponto final do Data Science, use um proxy (por exemplo, NGINX) para mapear os pontos finais exigidos pelo serviço para os pontos finais fornecidos pelo seu framework. |
| Portas expostas. |
As portas a serem usadas para os pontos finais Os portos estão limitados entre 1024 e 65535. As portas 24224, 8446 e 8447 estão excluídas. As portas fornecidas são expostas no contêiner pelo serviço; portanto, não é necessário expô-las novamente no arquivo do Docker. |
| Tamanho da imagem. | O tamanho da imagem do contêiner é limitado a 16 GB em formato descompactado. |
| Acesso à imagem. | O operador que cria a implantação de modelo deve ter acesso à imagem do contêiner a ser usada. |
| Pacote Curl. | O pacote curl deve ser instalado na imagem do contêiner para que a política HEALTHCHECK do Docker tenha sucesso. Instale o comando curl estável mais recente que não possui vulnerabilidades abertas. |
CMD, Entrypoint
|
O docker CMD ou Entrypoint deve ser fornecido por meio da API ou do arquivo do Docker que inicializa o servidor Web. |
CMD, tamanho Entrypoint. |
O tamanho combinado de CMD e Entrypoint não pode ter mais de 2048 bytes. Se o tamanho for maior que 2048 bytes, especifique os argumentos do aplicativo usando o artefato de modelo ou use o Object Storage para recuperar os dados. |
Recomendações Gerais
| Recomendação | Descrição |
|---|---|
| Empacote o Modelo ML em artefatos de modelo. |
Empacotar o modelo de ML como um artefato e fazer upload para o catálogo de modelos do serviço Data Science para usar os recursos de governança e controle de versão do modelo por meio de uma opção para empacotar o modelo de ML na imagem do contêiner. Salve o modelo no catálogo do modelo. Depois que o modelo é submetido a upload para o catálogo de modelos e referenciado durante a criação da implantação do modelo, o Data Science faz download de uma cópia do artefato e o descompacta no diretório |
| Forneça compilação de imagem e imagem para todas as operações | Recomendamos fornecer a compilação de imagem e imagem para criar, atualizar e ativar operações de implantação de modelo para manter a consistência no uso da imagem. Durante uma operação de atualização para uma imagem diferente, a imagem e a compilação de imagem são essenciais para atualizar a imagem esperada. |
| Verificação de Vulnerabilidade | Recomendamos o uso do serviço Vulnerability Scanning do OCI para verificar vulnerabilidades na imagem. |
| Campo API como nulo | Se um campo de API estiver vazio, não passe uma string vazia, um objeto vazio ou uma lista vazia. Passe o campo como nulo ou não passe, a menos que você queira explicitamente passar como objeto vazio. |
Melhores Práticas BYOC
- A implantação de modelo só suporta imagem de contêiner que reside no OCI Registry.
- Certifique-se de que a imagem do contêiner exista no OCI Registry durante todo o ciclo de vida da implantação do modelo. A imagem deve existir para garantir a disponibilidade caso uma instância seja reiniciada automaticamente ou a equipe de serviço execute a aplicação de patches.
- Somente contêineres docker são suportados com BYOC.
- O Data Science usa o artefato de modelo compactado para trazer a lógica de pontuação do modelo de ML e espera que ele esteja disponível no catálogo de modelos do Data Science.
- O tamanho da imagem do contêiner é limitado a 16 GB em formato descompactado.
-
O Data Science adiciona uma tarefa
HEALTHCHECKantes de iniciar o contêiner para que a políticaHEALTHCHECKnão precise ser adicionada explicitamente ao arquivo do Docker porque ela foi substituída. A verificação de integridade começa a ser executada 10 minutos após o início do contêiner e, em seguida, verifica/healtha cada 30 segundos, com timeout de três segundos e três novas tentativas por verificação. - Um pacote curl deve ser instalado na imagem do contêiner para que a política
HEALTHCHECKdo Docker tenha sucesso. - O usuário que cria o recurso de implantação de modelo deve ter acesso à imagem do contêiner no OCI Registry para usá-la. Caso contrário, crie uma política de IAM de acesso do usuário antes de criar uma implantação de modelo.
- O docker
CMDouEntrypointdeve ser fornecido por meio da API ou do Dockerfile, que inicializa o servidor Web. - O tempo limite definido pelo serviço para que o contêiner seja executado é de 10 minutos, portanto, certifique-se de que o contêiner de serviço de inferência seja iniciado (está íntegro) dentro desse período.
- Sempre teste o contêiner localmente antes de implantá-lo na Nuvem usando uma implantação de modelo.
Compilações de Imagem do Docker
As imagens de um registro do Docker são identificadas por repositório, nome e uma tag. Além disso, o Docker fornece a cada versão de uma imagem uma compilação alfanumérica exclusiva. Ao enviar uma imagem do Docker atualizada, recomendamos fornecer à imagem atualizada uma nova tag para identificá-la, em vez de reutilizar uma tag existente. No entanto, mesmo que você envie uma imagem atualizada e dê a ela o mesmo nome e tag de uma versão anterior, a versão recém-promovida tem outra compilação da versão anterior.
Ao criar um recurso de implantação de modelo, especifique o nome e a tag de uma versão específica de uma imagem na qual basear a implantação de modelo. Para evitar inconsistências, a implantação de modelo registra a compilação exclusiva dessa versão da imagem. Você também pode fornecer a compilação da imagem ao criar uma implantação de modelo.
Por padrão, quando você envia uma versão atualizada de uma imagem para o registro Docker com o mesmo nome e tag da versão original da imagem na qual a implantação do modelo se baseia, ela continua a usar a compilação original para extrair a versão original da imagem. Se você quiser que a implantação de modelo use a versão mais recente da imagem, altere explicitamente o nome da imagem com uma tag e digest que a implantação de modelo usa para identificar qual versão da imagem será extraída.
Para ajudar a garantir a integridade da imagem ao usar resumos, considere assinar imagens de contêiner. Para obter mais informações, consulte Assinando Imagens para Segurança.
Preparar o Artefato do Modelo
Crie um arquivo zip de artefato e salve-o com o modelo no catálogo de modelos. O artefato inclui o código para operar o contêiner e executar as solicitações de inferência.
O contêiner precisa expor um ponto final /health para retornar a integridade do servidor de inferência e um ponto final /predict para inferência.
O seguinte arquivo Python no artefato de modelo define esses pontos finais usando um servidor Flask com a porta 5000:
# We now need the json library so we can load and export json data
import json
import os
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neural_network import MLPClassifier
import pandas as pd
from joblib import load
from sklearn import preprocessing
import logging
from flask import Flask, request
# Set environnment variables
WORK_DIRECTORY = os.environ["WORK_DIRECTORY"]
TEST_DATA = os.path.join(WORK_DIRECTORY, "test.json")
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE_LDA = os.environ["MODEL_FILE_LDA"]
MODEL_PATH_LDA = os.path.join(MODEL_DIR, MODEL_FILE_LDA)
# Loading LDA model
print("Loading model from: {}".format(MODEL_PATH_LDA))
inference_lda = load(MODEL_PATH_LDA)
# Creation of the Flask app
app = Flask(__name__)
# API 1
# Flask route so that we can serve HTTP traffic on that route
@app.route('/health')
# Get data from json and return the requested row defined by the variable Line
def health():
# We can then find the data for the requested row and send it back as json
return {"status": "success"}
# API 2
# Flask route so that we can serve HTTP traffic on that route
@app.route('/predict',methods=['POST'])
# Return prediction for both Neural Network and LDA inference model with the requested row as input
def prediction():
data = pd.read_json(TEST_DATA)
request_data = request.get_data()
print(request_data)
print(type(request_data))
if isinstance(request_data, bytes):
print("Data is of type bytes")
request_data = request_data.decode("utf-8")
print(request_data)
line = json.loads(request_data)['line']
data_test = data.transpose()
X = data_test.drop(data_test.loc[:, 'Line':'# Letter'].columns, axis = 1)
X_test = X.iloc[int(line),:].values.reshape(1, -1)
clf_lda = load(MODEL_PATH_LDA)
prediction_lda = clf_lda.predict(X_test)
return {'prediction LDA': int(prediction_lda)}
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port = 5000)
Crie o Contêiner
Você pode usar qualquer imagem do OCI Container Registry. Veja a seguir uma amostra do Dockerfile que usa o servidor Flask:
FROM jupyter/scipy-notebook
USER root
RUN \
apt-get update && \
apt-get -y install curl
ENV WORK_DIRECTORY=/opt/ds/model/deployed_model
ENV MODEL_DIR=$WORK_DIRECTORY/models
RUN mkdir -p $MODEL_DIR
ENV MODEL_FILE_LDA=clf_lda.joblib
COPY requirements.txt /opt/requirements.txt
RUN pip install -r /opt/requirements.txtO pacote Curl deve ser instalado na imagem do contêiner para que a política HEALTHCHECK do docker funcione.
Crie um arquivo requirements.txt com os seguintes pacotes no mesmo diretório do Dockerfile:
flask
flask-restful
joblibExecute o comando docker build:
docker build -t ml_flask_app_demo:1.0.0 -f Dockerfile .O tamanho máximo de uma imagem de contêiner descompactada que você pode usar com implantações de modelo é de 16 GB. Lembre-se de que o tamanho da imagem do contêiner diminui o tempo de provisionamento da implantação do modelo porque ela é extraída do Container Registry. Recomendamos que você use as menores imagens de contêiner possíveis.
Testar o Contêiner
Certifique-se de que o artefato de modelo e o código de inferência estejam no mesmo diretório do Dockerfile. Execute o contêiner em sua máquina local. Você precisa consultar os arquivos armazenados em sua máquina local montando o diretório de modelo local em /opt/ds/model/deployed_model:
docker run -p 5000:5000 \
--health-cmd='curl -f http://localhost:5000/health || exit 1' \
--health-interval=30s \
--health-retries=3 \
--health-timeout=3s \
--health-start-period=1m \
--mount type=bind,src=$(pwd),dst=/opt/ds/model/deployed_model \
ml_flask_app_demo:1.0.0 python /opt/ds/model/deployed_model/api.pyEnvie uma solicitação de integridade para verificar se o contêiner está em execução dentro do serviço definido por 10 minutos:
curl -vf http://localhost:5000/healthTeste enviando uma solicitação de previsão:
curl -H "Content-type: application/json" -X POST http://localhost:5000/predict --data '{"line" : "12"}'Envie o Contêiner para o OCI Container Registry
Para poder enviar e extrair imagens de/ para o Oracle Cloud Infrastructure Registry (também conhecido como Registro de Contêiner), você deve ter um token de autorização do Oracle Cloud Infrastructure. Você vê apenas a string do token de autenticação quando a cria, portanto, copie o token de autenticação para um local seguro imediatamente.
- Para exibir os detalhes na Console: Na barra de navegação, selecione o menu Perfil e, em seguida, selecione Definições do usuário ou Meu perfil, dependendo da opção exibida.
- Na página Tokens de Autenticação, selecione Gerar Token.
- Digite uma descrição amigável para o token de autenticação. Evite fornecer informações confidenciais.
- Selecione Gerar Token. O novo token de autenticação será exibido.
- Copie o token de autenticação imediatamente para um local seguro em que você poderá recuperá-lo posteriormente. Você não verá o token de autenticação novamente na Console.
- Feche a caixa de diálogo Gerar Token.
- Abra uma janela de terminal em sua máquina local.
- Acesse o Container Registry para que você possa criar, executar, testar, marcar e enviar a imagem do contêiner.
docker login -u '<tenant-namespace>/<username>' <region>.ocir.io -
Marque a imagem do contêiner local:
docker tag <local_image_name>:<local_version> <region>.ocir.io/<tenancy_ocir_namespace>/<repository>:<version> -
Envie a imagem do contêiner:
docker push <region>.ocir.io/<tenancy>/byoc:1.0Observação
Certifique-se de que o recurso de implantação de modelo tenha uma política para o controlador de recursos para que ele possa ler a imagem do OCI Registry no compartimento no qual você armazenou a imagem. Para obter mais informações, consulte Dar Acesso de Implantação de Modelo a um Contêiner Personalizado Usando o Controlador de Recursos
Observação
(Assinatura de imagem): Antes de implantar, siga o processo de assinatura de imagem e grave o OCID da assinatura de imagem para auditoria e verificação. Para obter detalhes, consulte a seção de assinatura de imagem em Compilações de Imagem do Docker.Observação
(Requisito de acesso ao Vault): O usuário que cria a implantação de modelo deve ter pelo menos acesso no nívelUSEàs chaves do Vault e aos recursos da família de segredos no serviço Vault. Para obter mais informações, consulte Detalhes do Serviço Vault.
Você está pronto para usar essa imagem de contêiner com a opção BYOC ao criar uma implantação de modelo.
As implantações de modelo BYOC não suportam extração de imagem de contêiner entre regiões. Por exemplo, ao executar uma implantação de modelo BYOC em uma região IAD (Ashburn), você não pode extrair imagens de contêiner do OCIR (Oracle Cloud Container Registry) na região PHX (Phoenix).
Comportamento da Operação de Atualização BYOC
As operações de atualização BYOC são atualizações parciais do tipo mesclagem superficial.
Um campo de nível superior gravável deve ser completamente substituído quando aparece definido no conteúdo da solicitação e, caso contrário, preservado inalterado. Por exemplo, para um recurso como o seguinte:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 5454,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"imageSignatureId": "ocid1.containerimagesignature.oc1.iad.0.ociodscprod.aaaaaaaavkjvrldo4etdpdas3o5vuom3t6anoixneey737cr57if7jhkh6nq",
"environmentVariables": {
"a": "b",
"c": "d",
"e": "f"
},
"entrypoint": [ "python", "-m", "uvicorn", "a/model/server:app", "--port", "5000","--host","0.0.0.0"]
"cmd": ["param1"]
}Uma atualização bem-sucedida com o seguinte:
{
"environmentConfigurationDetails": {
"serverPort": 2000,
"environmentVariables": {"x":"y"},
"entrypoint": []
}
}Resulta em um estado no qual serverPort e environmentVariables são substituídos pelo conteúdo de atualização (incluindo a destruição de dados presentes anteriormente em campos profundos que estão ausentes no conteúdo de atualização). O image é preservado inalterado porque não apareceu no conteúdo de atualização e o entrypoint é apagado por uma lista vazia explícita:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 2000,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"imageSignatureId": "ocid1.containerimagesignature.oc1.iad.0.ociodscprod.aaaaaaaavkjvrldo4etdpdas3o5vuom3t6anoixneey737cr57if7jhkh6nq",
"environmentVariables": {"x": "y"},
"entrypoint": []
"cmd": ["param1"]
}O campo
imageSignatureId é opcional.Uma atualização bem-sucedida usando { "environmentConfigurationDetails": null or {} } resulta em nada sendo substituído. Uma substituição completa no nível superior apaga todos os valores que não estão no conteúdo da solicitação, portanto, evite isso. Todos os campos são opcionais no objeto de atualização, portanto, se você não fornecer a imagem, ela não deverá cancelar a definição da imagem na implantação. O Data Science só substituirá os campos de segundo nível se eles não forem nulos.
Não definir um campo no objeto de solicitação (passando um valor nulo) significa que o Data Science não considerará esse campo para encontrar a diferença e a substituição pelo valor de campo existente.
Para redefinir um valor de qualquer campo, informe um objeto vazio. Para campos de tipo de lista e mapa, o Data Science pode aceitar uma lista vazia ([]) ou um mapa ({}) como uma indicação para apagar os valores. Em qualquer caso, nulo não significa apagar os valores. No entanto, você sempre pode alterar o valor para outra coisa. Para usar uma porta padrão e cancelar a definição do valor do campo para ela, defina explicitamente a porta padrão.
A atualização para os campos de lista e mapa é uma substituição completa. O Data Science não procura valores individuais dentro dos objetos.
Para imagem e compilação, o Data Science não permite apagar o valor.
Implantar com um Contêiner do Servidor de Inferência Triton
O NVIDIA Triton Inference Server simplifica e padroniza a inferência de IA, permitindo que as equipes implementem, executem e dimensionem modelos de IA treinados de qualquer estrutura em qualquer GPU ou infraestrutura baseada em CPU.
Algumas características-chave do Tritão são:
- Execução de Modelo Concorrente: A capacidade de atender vários modelos de ML simultaneamente. Esse recurso é útil quando vários modelos que precisam ser implantados e gerenciados juntos em um único sistema.
- Batch dinâmico: Permitir que o servidor reúna solicitações em batch dinamicamente com base na carga de trabalho para ajudar a melhorar o desempenho.
A Implantação de Modelo tem suporte especial para o Servidor de Inferência de Tritão NVIDIA. Você pode implantar uma imagem Triton existente no catálogo de contêineres da NVIDIA e a implantação de modelo garante que as interfaces Triton sejam correspondidas sem a necessidade de alterar nada no contêiner usando a seguinte variável de ambiente ao criar a implantação de modelo:
CONTAINER_TYPE = TRITONUma amostra documentada completa sobre como implantar modelos ONNX no Triton está disponível no repositório GitHub de implantação do modelo do serviço Data Science.