Pipelines
Um pipeline de aprendizado de máquina (ML) do serviço Data Science é um recurso que define um workflow de tarefas, chamado etapas.
O ML geralmente é um processo complexo, envolvendo várias etapas trabalhando juntas em um fluxo de trabalho, para criar e atender a um modelo de aprendizado de máquina. Essas etapas geralmente incluem: aquisição e extração de dados, preparação de dados para ML, featurização, treinamento de um modelo (incluindo seleção de algoritmo e ajuste de hiperparâmetro), avaliação de modelo e implantação de modelo.
As etapas do pipeline podem depender de outras etapas para criar o workflow. Cada etapa é discreta, portanto, oferece a flexibilidade de misturar ambientes diferentes e até linguagens de codificação diferentes no mesmo pipeline.
Um pipeline típico (workflow) inclui estas etapas:
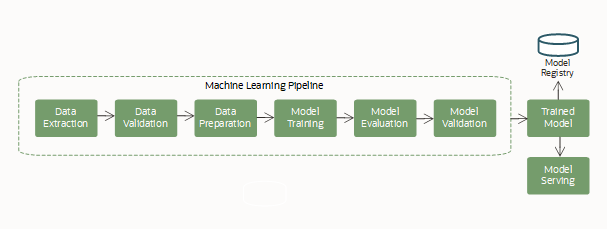
Este ciclo de vida de ML é executado como um pipeline de ML repetível e contínuo.
Conceitos de Pipeline
Um pipeline pode se parecer com o seguinte workflow:
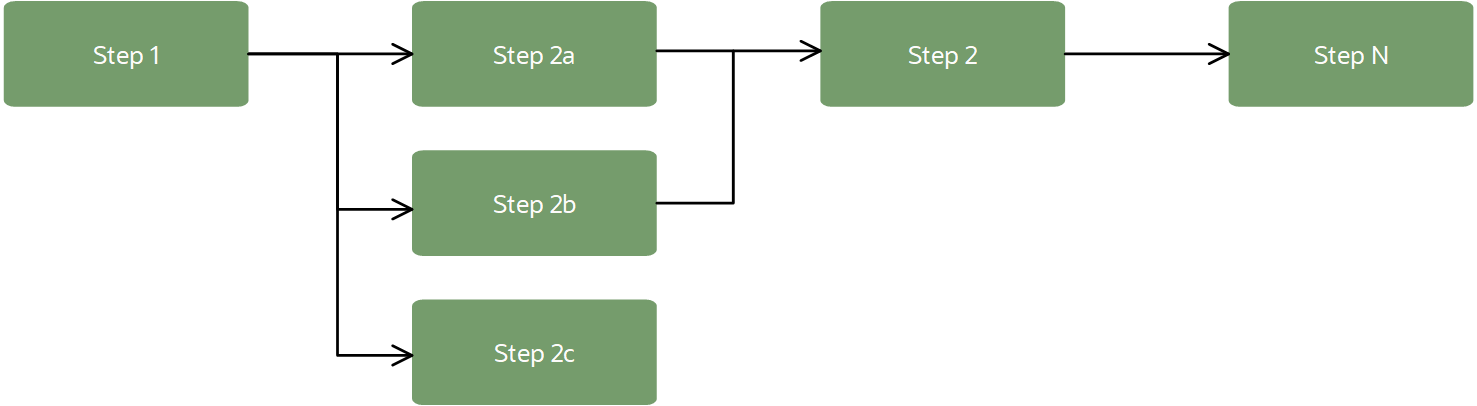
Em um contexto de ML, os pipelines geralmente fornecem um workflow para importação de dados, transformação de dados, treinamento de modelo e avaliação de modelo. As etapas do pipeline podem ser executadas em sequência ou em paralelo, desde que estejam criando um gráfico acíclico dirigido (DAG).
- Pipeline
-
Um recurso que contém todas as etapas e suas dependências (o workflow DAG). Você pode definir configurações padrão para infraestrutura, logs e outras definições a serem usadas nos recursos do pipeline. Essas definições padrão são utilizadas quando não são definidas nas etapas do pipeline.
Você também pode editar algumas das configurações do pipeline após sua criação, como nome, log e variáveis de ambiente personalizadas.
- Etapa de Pipeline
-
Uma tarefa a ser executada em um pipeline. A etapa contém o artefato da etapa, a infraestrutura (forma de computação, volume em blocos) a ser usada durante a execução, definições de log, variáveis de ambiente e outras.
Uma etapa do pipeline pode ser um destes tipos:
- Um script (arquivos de código). Python, Bash e Java são suportados) e uma configuração para executá-lo.
-
Um job existente no serviço Data Science identificado por seu OCID.
- Artefato da Etapa
-
Obrigatório ao trabalhar com um tipo de etapa de script. Um artefato é todo o código a ser utilizado para executar a etapa. O próprio artefato deve ser um único arquivo. No entanto, pode ser um arquivo compactado (zip) que inclui vários arquivos. Você pode definir o arquivo específico a ser executado ao executar a etapa.
Todas as etapas de script em um pipeline devem ter um artefato para que o pipeline esteja no estado ATIVO para que possa ser executado.
- DAG
-
O workflow de etapas, definido por dependências de cada etapa em outras etapas no pipeline. As dependências criam um workflow lógico ou gráfico (deve ser acíclico). O pipeline busca executar etapas em paralelo a fim de otimizar o tempo de conclusão do pipeline, a menos que as dependências imponham etapas para serem executadas de forma sequencial. Por exemplo, o treinamento deve ser concluído antes de avaliar o modelo, mas vários modelos podem ser treinados em paralelo para competir pelo melhor modelo.
- Execução de Pipeline
-
A instância de execução de um pipeline. Cada execução do pipeline inclui suas execuções por etapa. Uma execução de pipeline pode ser configurada para substituir alguns dos padrões do pipeline antes de iniciar a execução.
- Execução da Etapa do Pipeline
-
A instância de execução de uma etapa do pipeline. A configuração da execução da etapa é obtida da execução do pipeline primeiro quando definida ou da definição do pipeline secundariamente.
- Estado do Ciclo de Vida do Pipeline
-
À medida que o pipeline está sendo criado, construído e até excluído, ele pode estar em vários estados. Após a criação do pipeline, ele estará no estado CREATING e não poderá ser executado até que todas as etapas tenham um artefato ou job para ser executado; em seguida, o pipeline será alterado para o estado ACTIVE.
- Acesso aos Recursos do OCI
-
As etapas do pipeline podem acessar todos os recursos da OCI em uma tenancy, desde que exista uma política para permitir. Você pode executar pipelines nos dados do ADW ou do Object Storage. Além disso, você pode usar vaults para fornecer uma maneira segura de autenticação de recursos de terceiros. As etapas do pipeline poderão acessar origens externas se você tiver configurado a VCN apropriada.