Usando Pesquisa com os Plug-ins de Alerta e Notificações OpenSearch
Use os plug-ins de alerta e notificação integrados do OpenSearch para monitorar a integridade do cluster, as métricas de desempenho e os problemas operacionais.
O dimensionamento e a otimização corretos dos clusters OpenSearch são essenciais para o desempenho e a economia. Com o tempo, os padrões de uso do cluster podem mudar, levando a sobrecarga, aumento de latências ou erros. O monitoramento e os alertas proativos são essenciais para detectar e mitigar possíveis problemas antes que eles se intensifiquem.
O OpenSearch tem um plug-in de monitoramento e alerta incorporado que pode ajudar a criar esses alertas. Este tópico fornece orientação sobre a configuração de alertas, a integração com o ONS (Oracle Notification Service) e a mitigação de problemas comuns.
OpenSearch Plug-in de Alerta
O plug-in de alerta fornece monitoramento e notificação para eventos no OpenSearch. Ele usa APIs REST para criar alertas complexos com base em métricas de cluster e nó. O plug-in de alerta contém os seguintes recursos:
- Monitoramentos encadeados: Combina várias condições de diferentes saídas de API REST para criar alertas complexos.
- Intervalos controlados: Define a frequência com que os alertas são avaliados para evitar a fadiga de notificação.
- Suporte RBAC: Usa controle de acesso baseado em função para gerenciar alertas.
Para obter mais informações sobre o monitoramento OpenSearch, consulte Monitoramento.
Métricas e Alertas Suportados
Você pode configurar o plug-in de alerta para as seguintes métricas:
- Integridade do Cluster: Alterações de status (Verde, Amarelo, Vermelho).
- Métricas do Nó: Alto uso de disco, CPU, pressão de JVM.
- Métricas de Fragmento: Fragmentos grandes, contagens excessivas de fragmentos.
- Métricas da Tarefa: tarefas presas ou rejeitadas, altas contagens de tarefas de rolagem.
- Throttling: Aceleração de índice ou consulta.
Configurando Alertas
Você pode configurar alertas nas saídas das seguintes APIs OpenSearch:
- _cluster/integridade
- _cluster/estatísticas
- _cluster/configurações
- _nós/estatificações
- _cat/índices
- _cat/pending_tasks
- _cat/recuperação
- _cat/shards
- _cat/Instantâneos
- _cat/tarefas
Para obter mais informações, consulte Por monitores de métricas de cluster.
OpenSearch Plug-in de Notificação
Use o plug-in de notificação para obter notificações automáticas sobre os alertas configurados usando o plug-in de alerta. O ONS (Oracle Notification Service) está integrado ao plug-in de notificação. Você pode criar canais usando o plug-in de notificação que envia notificações para o tópico do ONS configurado. Em seguida, você pode vincular esses canais a alertas para receber notificações sobre alertas de disparo.
Veja a seguir um exemplo de notificação de alerta:
Monitor Test index stats just entered alert status. Please investigate the issue.
- Trigger: test
- Severity: 2
- Period start: 2025-02-06-06T08:48:45.047Z
- Period end: 2025-02-06-06T08:49:45.047ZPara obter mais informações sobre o plug-in de Notificações OpenSearch, consulte Notificações.
ONS (Oracle Notification Service)
O serviço Oracle Cloud Infrastructure Notifications (ONS) transmite mensagens seguras e altamente confiáveis a componentes distribuídos por meio de um padrão publicar-assinar. Você pode usá-lo para aplicativos hospedados no Oracle Cloud Infrastructure e externamente. Use o ONS para ser notificado quando regras de evento forem acionadas ou alarmes forem violados ou para publicar diretamente uma mensagem.
O ONS oferece suporte aos seguintes canais para entrega de mensagens:
- Funções
- Ponto Final HTTP (para aplicativos externos)
- PagerDuty
- Slack
- SMS
Para obter mais informações sobre o serviço OCI Notification, consulte Notificações.
A imagem a seguir mostra como as notificações são transmitidas usando o ONS:
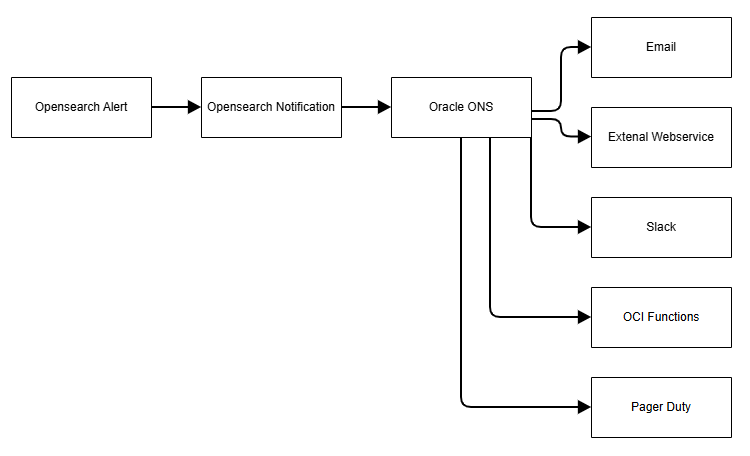
Alertas de Amostra com Notificações
Você pode criar alertas para monitorar a maioria das áreas importantes do OpenSearch que podem afetar o desempenho do cluster OpenSearch. As melhores práticas são configurar alertas de nível de advertência que indicam que alguns parâmetros estão se tornando problemáticos, de modo que seja possível executar uma ação corretiva antes que o cluster OpenSearch entre em um estado inválido.
As seções a seguir fornecem alertas no nível de advertência e erro que podem ser configurados no cluster OpenSearch.
Canal de Notificação
Antes de criar alertas, recomendamos que você configure um canal de notificação. Você pode usar sua assinatura para o canal ONS para obter notificações automáticas por meio de vários métodos de comunicação, incluindo e-mail, Slack, funções da OCI, fluxos e outros.
O exemplo a seguir mostra como criar um canal de notificação:
{
"config_id": "sample-id",
"name": "test-ons1",
"config": {
"name": "test-ons1",
"description": "send notifications",
"config_type": "ons",
"is_enabled": true,
"ons": {
"topic_id": "ocid1.onstopic.oc1.iad.amaaaaaawtpq47yar24xitgso2wble2a5shal52r6zoc6eyth3jzsmbvxspa"
}
}
}Cluster Integridade
Seu cluster OpenSearch tem os seguintes estados de integridade:
- Verde: Todos os shards disponíveis.
- Amarelo: Alguns shards de réplica não estão disponíveis. O desempenho pode sofrer devido à disponibilidade de menos réplicas.
- Vermelho: Alguns shards principais não estão disponíveis. Vermelho indica indisponibilidade de dados, resultando em falha de consultas para shards indisponíveis.
Configurando Alertas de Cluster Amarelos
Use a seguinte configuração para configurar Alertas Amarelos para seu cluster:
POST: {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthYellow",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"yellow\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Configurando Alertas de Cluster Amarelos
Use a seguinte configuração para configurar Alertas Vermelhos para seu cluster:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthRed",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"red\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Número de Nós
Use a seguinte configuração para especificar o número de nós do cluster:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterNodesUnavailable",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check all nodes available",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].number_of_nodes< 8",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Solução de Problemas
A integridade do cluster pode se tornar Amarela ou Vermelha por vários motivos, como falha em uma restauração, nós sendo desconectados temporariamente, disco ficando cheio. Embora alguns problemas precisem ser corrigidos pela equipe do OCI OpenSearch, você mesmo pode solucionar e corrigir outros problemas.
Siga estas etapas para se dirigir às questões:
- Obtenha uma lista de todos os shards usando a API de Shards Cat para ter uma ideia dos shards não atribuídos.
- Se o cluster OpenSearch for Vermelho:
- Verifique o motivo da alocação para os shards não alocados usando a API de alocação CAT.
- Use a API de redirecionamento de imposição para tentar realocação de shards, se o problema for temporário e for mitigado.
- Se a explicação de alocação de shard mencionar uma tentativa de restauração com falha, restaure o cluster para um estado bom conhecido anterior.
- Se o problema ainda persistir, entre em contato com a equipe do OCI OpenSearch.
- Se o cluster OpenSearch for Amarelo:
- Verifique se o número de nós é igual ou maior que as réplicas máximas de um índice.
- Verifique o motivo da alocação para os shards não alocados usando a API de alocação CAT
- Se o problema parecer ser temporário, use a API de redirecionamento de força para realocar os shards.
Se um ou mais nós do cluster não estiverem disponíveis por um período prolongado, entre em contato com a equipe do OCI OpenSearch. Esses sintomas indicam que algo pode estar errado com a infraestrutura subjacente.
Estatísticas no Nível do Nó
Todos os nós OpenSearch devem ter um bom buffer em termos de todas as métricas básicas, como CPU, RAM e espaço em disco, para que funcionem de forma ideal. Atingir níveis críticos dessas métricas pode levar à redução de latências, ao aumento de atrasos e, eventualmente, à suspensão ou à saída dos nós do cluster.
Você pode definir dois níveis de alertas nas seguintes métricas: um para um nível de aviso e outro para um nível crítico.
Disco Alto/CPU/JVM
Nível de Advertência
Use a seguinte configuração para especificar um alerta de Nível de Advertência para os nós OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 70) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}Nível Crítico
Use a seguinte configuração para especificar um alerta de Nível Crítico para os nós OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 85) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}Diagnóstico e Solução de Problemas
Para alto uso do disco, tente aumentar o tamanho do disco ou configurar políticas ISM para expurgar dados antigos.
Revise suas configurações de tráfego e nó, se o cluster estiver sob estresse por causa de parâmetros de nó por um longo tempo, ele normalmente indica um cluster subconfigurado.
Tarefas Pendentes
A lista de tarefas pendentes especifica quais tarefas do OpenSearch estão sendo executadas em quais nós. A maioria das tarefas do OpenSearch, além de algumas como operação de reindexação, são pequenas tarefas que o OpenSearch dividiu de esforços maiores.
Use a seguinte configuração para listar as tarefas pendentes para os nós OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "pending_tasks",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"enabled_time": 1746584774661,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_TASKS",
"path": "_cat/tasks",
"path_params": "",
"url": "http://localhost:9200/_cat/tasks",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "jUOQqJYBQxJTy-1pqNIF",
"name": "test",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].tasks){\n\nif(item.running_time_in_nanos> 300000000000) return true;\n}\nreturn false\n",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false
}Diagnóstico e Solução de Problemas
Tarefas pendentes podem indicar uma sobrecarga no nó, um estado incorreto do nó ou um parâmetro incorreto para a tarefa. Use a seguinte orientação para solucionar problemas relacionados a nós pendentes:
- Se o cluster estiver executando várias mesclagens de tipo ou índices em massa, execute uma mesclagem forçada para resolver o problema à medida que ele mescla tudo em uma ação.
- Se o cluster tiver definições de atualização de cluster do tipo paradas, isso poderá indicar um problema com o estado do nó ou as filas do nó. Tente excluir tarefas paralisadas ou reiniciar o nó para corrigir o problema.
- Se o cluster tiver snapshots do tipo ficando presos, isso poderá indicar um problema com o repositório. Verifique as definições do repositório. Entre em contato com a equipe do OCI OpenSearch se o erro estiver relacionado a backups automatizados.
Tarefas e Threads Rejeitados
Threads rejeitados indicam um alto nível de limitação entre tarefas. Por exemplo, pode ser quando há tanta atividade, muitas solicitações de índice e pesquisa que não podem ser atendidas são limitadas.
Use a seguinte configuração para listar as tarefas e os threads rejeitados:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Rejected threads",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "1kNRrpYBQxJTy-1pGtJ9",
"name": "rejected thread pool",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{\n for (e in entry.getValue().thread_pool.entrySet()) {\n if(e.getValue().rejected>10){\n return true;\n}\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Diagnóstico e Solução de Problemas
Tarefas rejeitadas podem indicar uma sobrecarga no sistema. Revisar no tipo de tarefas rejeitadas. Verifique se o tráfego dessas tarefas pode ser reduzido ou se as configurações/estrutura da tarefa foram alteradas.
Se a função Pesquisar estiver sendo limitada, verifique se a consulta de pesquisa pode ser otimizada.
Se a função de indexação estiver sendo limitada, verifique se você pode atualizar a taxa de indexação ou as configurações em massa ou se pode dividir o índice e os shards em tarefas menores.
Estatísticas de Nível de Índice
Dimensionamento do Shard
Os dados de índice são armazenados em estruturas independentes, conhecidas como shards. Cada fragmento é composto de segmentos, que são carregados na memória OpenSearch para auxiliar a função de Pesquisa. Shards na faixa de 30 a 50 GB ou maior levam a segmentos maiores, o que leva ao aumento do uso de memória. O dimensionamento correto de shards é importante para o desempenho do cluster. Em geral, os tamanhos dos shards podem ser controlados pelas políticas do Index Lifecycle Management (ILM). Para índices que não têm ILM, você pode configurar alertas sobre tamanhos de shard para evitar que os índices se tornem muito grandes.
Use a seguinte configuração para listar os shards e seus tamanhos:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Big shard size",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_SHARDS",
"path": "_cat/shards",
"path_params": "",
"url": "http://localhost:9200/_cat/shards",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "pkOWqJYBQxJTy-1pO9Im",
"name": "big shards",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].shards)\nif((item.store != null)&&(item.store.contains(\"gb\"))&&(item.store.length()>4)\n&&(Double.parseDouble(item.store.substring(0,item.store.length()-3))>30)) return true\n",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false
}Diagnóstico e Solução de Problemas
Configure a política de ILM do seu cluster para percorrer índices quando eles atingirem um determinado tamanho.
Aumente o número de shards para índices existentes que cresceram usando o recurso de reindexação. Para índices grandes acima de 100 GB, siga estas melhores práticas:
- Divida a tarefa em partes menores usando a API de consulta.
- Defina o tamanho do lote apropriado e o número de solicitações por segundo.
Indexação em atraso
Quando os dados são indexados no cluster, o OpenSearch inicialmente os grava em um arquivo de log de tradução. Em seguida, o processo OpenSearch seleciona entradas desse arquivo em intervalos regulares para ingerir os dados em suas estruturas do Apache Lucene, criando segmentos apropriados com objetos internos necessários, como tokenizadores, dados de campo etc. Altas taxas de ingestão ou um cluster subconfigurado podem levar ao atraso do processo de ingestão. Aqui, o tamanho do arquivo de translog cresce junto com o atraso na indexação de documentos. Você pode monitorar esse comportamento usando as estatísticas de indexação.
Use a seguinte configuração para monitorar o atraso de índice:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "UncommittedSize large",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Uncommited size",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.translog.uncommitted_size_in_bytes>1000000000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Diagnóstico e Solução de Problemas
Ao solucionar problemas de indexação de atraso, execute as seguintes tarefas:
- Revisar a pressão de indexação.
- Revise as estatísticas de outros nós, como CPU, memória, estatísticas de E/S de disco.
Considere as seguintes opções com base nos resultados das tarefas anteriores:
- Reduza a pressão de indexação.
- Aumente a configuração dos nós.
- Aumente o refresh_interval, se o log de tradução não estiver muito alto.
Throttling
OpenSearch armazena dados na forma de segmentos Lucene. Os segmentos são condensados e mesclados continuamente para reunir muitas operações nos mesmos documentos. Quando a velocidade de indexação necessária é maior do que a que o cluster OpenSearch pode acomodar, essas mesclagens são limitadas. Você pode monitorar a limitação usando estatísticas de indexação e atualizar o limite de limitação para atender aos seus requisitos.
Use a seguinte configuração para configurar o controle de fluxo:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Merge Throttling",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "Merge Throttling",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.merges.total_throttled_time_in_millis>300000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}
Diagnóstico e Solução de Problemas
Ao solucionar problemas de limitação, execute as seguintes tarefas:
- Revisar a pressão de indexação.
- Revise as estatísticas de outros nós, como CPU, memória, estatísticas de E/S de disco.
Considere as seguintes opções com base nos resultados das tarefas anteriores:
- Reduza a pressão de indexação.
- Aumente a configuração dos nós.
- Aumente o refresh_interval, se o log de tradução não estiver muito alto.
Pesquisar
Rolagens
A pesquisa com rolagem é usada quando muitos resultados são esperados. No entanto, o uso de muitas rolagens ocupa memória no OpenSearch porque ele deve manter o contexto, levando a um desempenho insatisfatório. O alerta f pode ser usado para manter uma guia sobre o número de rolagens abertas consistentemente.
Use a configuração a seguir para rastrear o número de rolagens abertas consistentemente.
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Large Number of Open Scrolls",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Open Scrolls",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.search.scroll_current>200) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}