Usar o OKE para Melhorar a Localidade de Dados da Atividade do Cassandra e do Spark
Introdução
O Apache Cassandra é um banco de dados distribuído e sem mestre em que cada nó possui intervalos de token. O Apache Spark é um mecanismo de computação distribuído que pode usar o conector Spark–Cassandra para leitura nas réplicas Cassandra. No Kubernetes, os pods são programados sem conhecimento de onde os dados residem, portanto, a localidade dos dados não é garantida.
Este tutorial mostra como o OKE pode melhorar a localidade com os primitivos do Kubernetes: StatefulSets (identidade estável para Cassandra), labels de nó e afinidade/anti-afinidade para co-localizar executores do Spark com pods Cassandra — portanto, as leituras são servidas do mesmo nó (ideal) ou, pior dos casos, um salto para a réplica co-localizada.
Objetivos
- Implante um cluster e um bastion do OKE de 3 nós (ORM ou Terraform).
- Co-localize Cassandra e Spark em dois nós com rótulos + afinidade.
- Execute e verifique um Job de leitura do Spark em relação ao Cassandra.
- Observe o tráfego entre nós com Logs de Fluxo da VCN.
Pré-requisitos
- Tenancy do OCI com permissões para VCN, OKE, Compute, Logging (Log de Fluxo); Monitoramento opcional.
- Par de chaves SSH para acesso de bastion.
- Familiaridade básica com o Kubernetes (nós, labels, pods etc.).
Tarefa 1: Implantar o Ambiente com o OCI Resource Manager (ORM) (recomendado).
-
Clique abaixo para abrir a pilha na console do OCI:

-
Siga o fluxo guiado para:
-
Aceite os termos de uso.
-
Insira uma chave SSH e selecione o Domínio de Disponibilidade.
-
Você pode deixar o restante dos valores como padrão para obter uma VCN, um cluster do OKE e um bastion implantados.
-
Inicie a pilha.
-
Depois que a pilha for concluída, você obterá o IP do bastion na seção de saída.
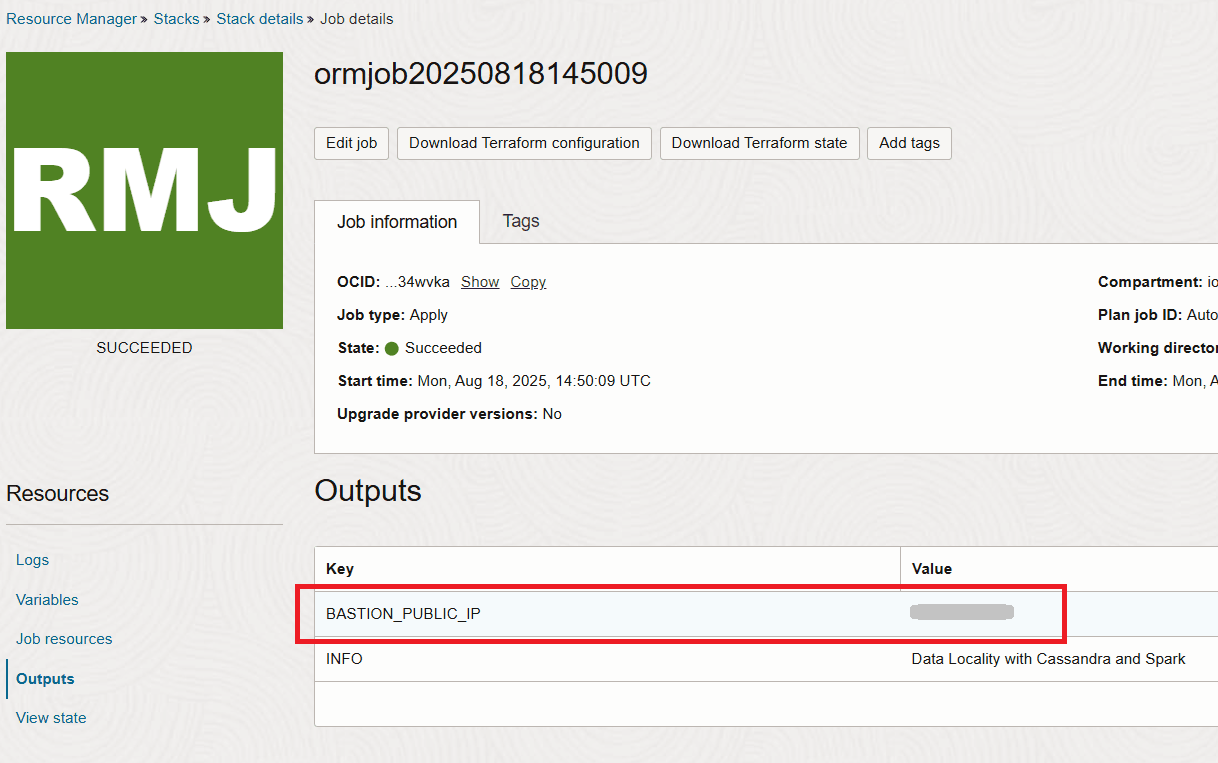
Tarefa 2: Estabelecer Conexão com o Bastion e Verificar a Implantação
O provisionamento inicial da infraestrutura é concluído em cerca de 15 minutos, mas a configuração completa (via cloud-init no bastion) leva cerca de 20 minutos a mais para instalar o Helm, implantar o Cassandra e o Spark e executar o job de leitura.
-
Para monitorar o processo, use SSH no bastion:
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
Execute o comando abaixo para monitorar o andamento do script cloudinit.
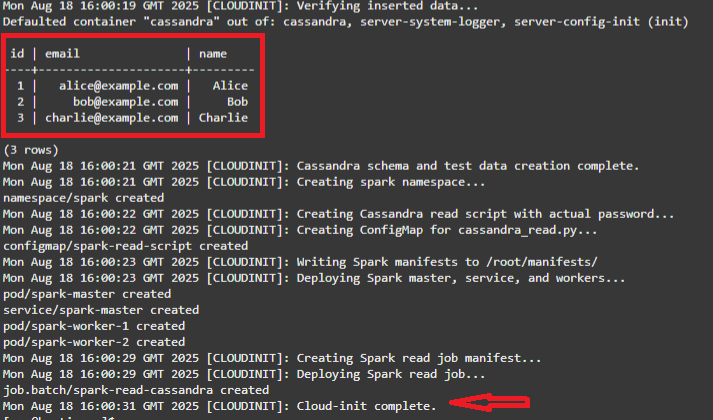
tail -f /var/log/oke-automation.log -
A pilha é concluída quando você vê os 3 valores pré-implantados do Cassandra sendo lidos e a mensagem Cloud-init complete.
Observação: O que o script cloudinit fez é:
- Instalar o kubectl, o Helm, a CLI do OCI (instance principals), extrair o kubeconfig.
- Aguardar Colaboradores
- Identifique os dois primeiros nós com:
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - Instalar cert-manager e k8ssandra-operator (CRDs)
- Aplicar K8ssandraCluster
- Espere por Cassandra
- Criar testks.users e inserir 3 linhas
- Criar namespace do spark; criar ConfigMap com /scripts/cassandra_read.py (leitura testks.users)
- Implante o Spark master, o Service e dois workers (nodeSelector spark-locality: "verdadeiro", antiafinidade do worker)
- Submeter Job spark-read-cassandra
-
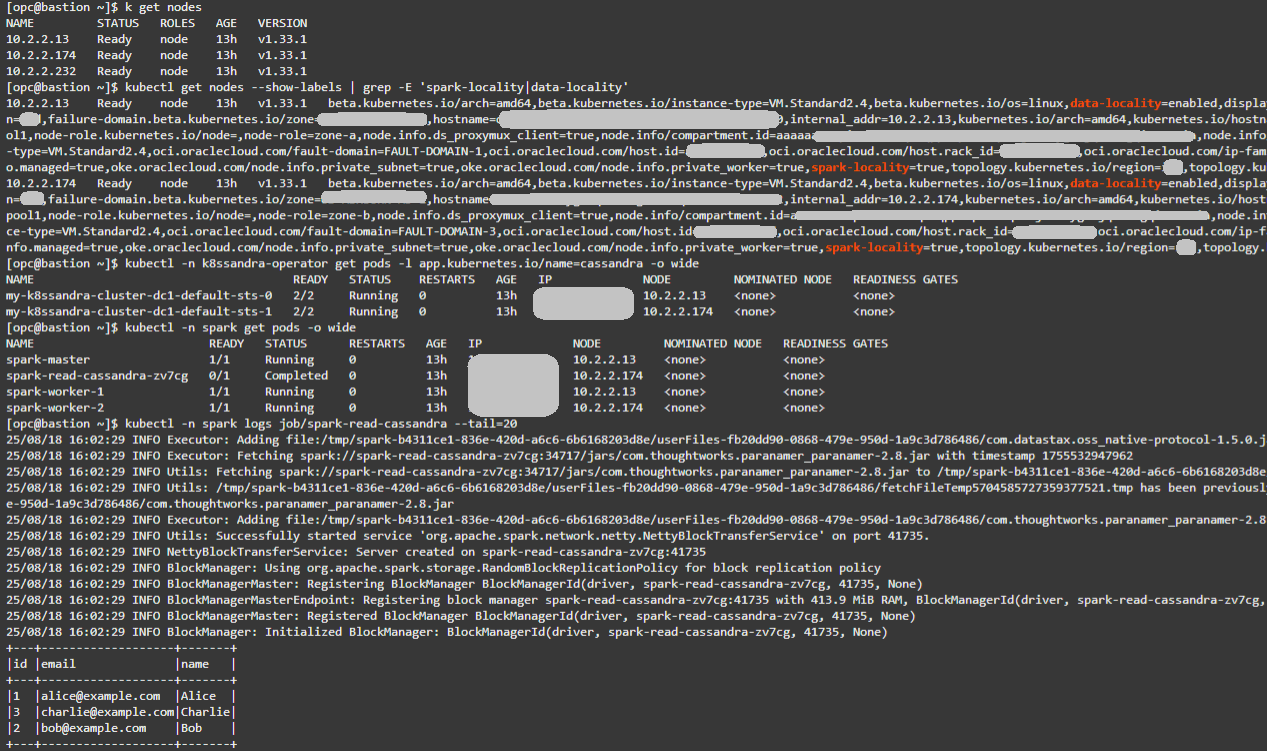
Na VM do bastion, confirme os nós existentes:
kubectl get nodes -
Confirmar rótulos de localidade. Espere dois nós com spark-locality=true e data-locality=enabled.
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Verificar posicionamento do Cassandra:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Verifique o posicionamento do Spark:
kubectl -n spark get pods -o wide -
Verifique os logs do Job de leitura do Spark. Você deverá ver os 3 registros do testks.users e uma execução bem-sucedida.
kubectl -n spark logs job/spark-read-cassandra --tail=20
Dica: A correspondência de valores NODE entre os pods Cassandra e Spark confirma a co-localização e as condições ideais para a localidade. Para obter resultados de Log de Fluxo mais conclusivos, insira linhas adicionais em testks.users usando cqlsh. Conjuntos de dados maiores gerarão mais tráfego de leitura, facilitando a observação de efeitos de localidade versus não localidade.
Abaixo você pode ver um exemplo de saída para os comandos acima:
Tarefa 3: Observar Efeitos de Rede com Logs de Fluxo da VCN
Use Logs de Fluxo da VCN para entender onde o tráfego do Cassandra flui durante as leituras do Spark. A automação atual usa o Flannel (VXLAN), que afeta o que os Logs de Fluxo podem ver.
O que muda com o CNI
- Flannel (VXLAN, este laboratório):
- O tráfego de pods no mesmo nó permanece na ponte do host → nenhuma entrada de Log de Fluxo da VCN.
- O tráfego de pods entre nós é encapsulado como UDP
(VXLAN). Por padrão, o Flannel usa a porta 8472, mas se essa porta estiver indisponível, ele poderá selecionar outra porta UDP alta. A porta exata pode variar de acordo com a implantação.
- NPN (VCN-Native Pod Networking):
- Os pods obtêm IPs da VCN e o tráfego é roteado em L3 sem sobreposição.
- Os Logs de Fluxo mostram as portas reais do aplicativo (para Cassandra: TCP 9042).
-
Ativar Logs de Fluxo na sub-rede do colaborador.
Na Console do OCI, ative Logs de Fluxo para a sub-rede de trabalho do OKE. Execute novamente (ou aguarde) o Job de leitura do Spark para gerar tráfego.
-
Logs de Fluxo de Consulta (escolha o caminho que corresponde ao seu cluster)
Se estiver usando esta automação (Flannel/VXLAN): Use uma consulta avançada semelhante a:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
Substitua
- O tráfego Pod-to-pod é encapsulado em UDP
entre os IPs do nó de trabalho (em vez da porta Cassandra 9042). - Leituras no mesmo nó: nenhuma entrada de Log de Fluxo da VCN (o tráfego permanece local).
- Leituras entre nós: visível como fluxos UDP 14789 entre os IPs do nó de trabalho na imagem abaixo.
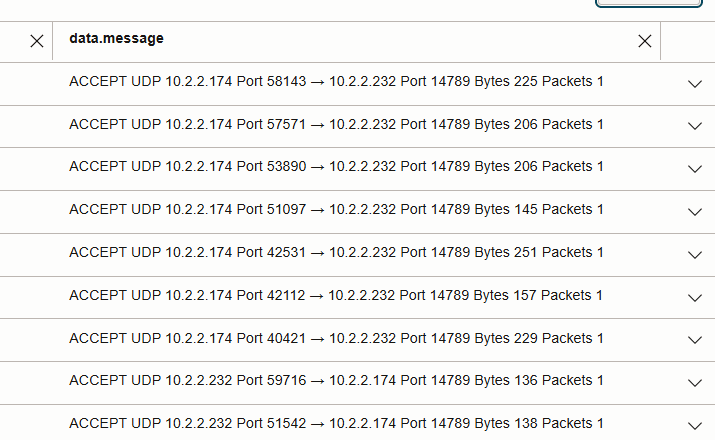
- Comparar as contagens de pacotes no UDP 14789 destaca o efeito da localidade de dados vs não-localidade.
Se o cluster usar NPN:
- Filtre diretamente para TCP dstPort = 9042 entre IPs de pod/trabalhador.
- Você deve ver Cassandra CQL lê / escreve como fluxos 9042. (idealmente muito pouco)
Observação: os Logs de Fluxo podem levar alguns minutos para ingerir novas entradas.
Principais Considerações
-
Clusters com >3 nós:
A localização é mais importante à medida que o tamanho do cluster aumenta. Sem regras de posicionamento, os executores do Spark podem ser executados em nós sem réplicas locais, causando muitas leituras remotas. A co-localização garante que as leituras sejam locais ou, na pior das hipóteses, um único salto para outra réplica.
- Ganhos de desempenho de co-localização:
- Leituras locais com salto zero → menor latência.
- Menos leituras entre nós → uso reduzido de largura de banda e menor contenção.
- Throughput mais alto para jobs do Spark que leem Cassandra em paralelo.
- Mecanismos utilizados nesta automação:
- StatefulSets → identidades de pod Cassandra estáveis.
- Os labels de nó (
spark-locality,data-locality) → designam nós para co-localização. - Afinidade de pod/anti-afinidade → executores Spark programados para nós Cassandra, equilibrados entre eles.
- K8ssandra Operador → implantação e gerenciamento declarativos do Cassandra.
- ConfigMap + job do Spark → valida leituras e geração de tráfego do Cassandra.
- Logs de Fluxo da VCN → observam e confirmam efeitos de localidade.
- Fora do escopo do OKE (fatores no nível do aplicativo):
- Programação de tarefas Spark e designação de partição.
- Fator de replicação Cassandra e nível de consistência.
- Lógica do conector Spark–Cassandra para selecionar réplicas.
Links Relacionados
Forneça links a recursos adicionais. Esta seção é opcional; exclua se não for necessário.
Confirmações
- Autores - Adina Nicolescu (Arquiteta de Nuvem Principal)
Mais Recursos de Aprendizado
Explore outros laboratórios em docs.oracle.com/learn ou acesse mais conteúdo de aprendizado gratuito no canal do Oracle Learning YouTube. Além disso, acesse education.oracle.com/learning-explorer para se tornar um Oracle Learning Explorer.
Para obter a documentação do produto, visite o Oracle Help Center.
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53304-01