关于自治 AI 数据库上的数据管道
自治 AI 数据库数据管道是负载管道或导出管道。
加载管道提供从外部源持续的增量数据加载(当数据到达对象存储时,数据会加载到数据库表)。导出管道提供持续的增量数据导出到对象存储(当新数据显示在导出到对象存储的数据库表中时)。管道使用数据库调度程序连续加载或导出增量数据。
自治 AI 数据库数据管道提供以下功能:
-
统一操作:通过管道,您可以快速轻松地加载或导出数据,并定期重复这些操作以获得新数据。
DBMS_CLOUD_PIPELINE程序包提供了一组统一的 PL/SQL 过程,用于管道配置以及创建和启动用于加载或导出操作的调度作业。 -
调度的数据处理:管道监视其数据源,并在新数据到达时定期加载或导出数据。
-
高性能:管道使用自治 AI 数据库上的可用资源扩展数据传输操作。默认情况下,管道对所有负载或导出操作使用并行处理,并根据自治 AI 数据库上可用的 CPU 资源或可配置的优先级属性进行扩展。
-
原子性和恢复:管道保证原子性,以便为装入管道仅装入一次对象存储中的文件。
-
监视和故障排除:管道提供详细的日志和状态表,允许您监视和调试管道操作。
-
Multicloud Compatible :自治 AI 数据库上的管道支持在云提供商之间轻松切换,无需更改应用。管道支持自治 AI 数据库支持的所有身份证明和对象存储 URI 格式(Oracle Cloud Infrastructure Object Storage、Amazon S3、Azure Blob Storage、Google Cloud Storage 和 Amazon S3 兼容对象存储)。
数据管道生命周期
DBMS_CLOUD_PIPELINE 软件包提供了创建、配置、测试和启动管道的过程。加载和导出管道的管道生命周期和过程相同。
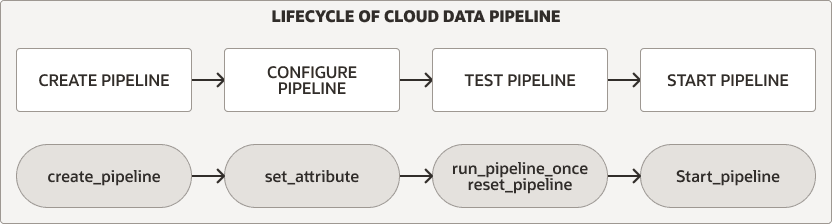
对于任一管道类型,请执行以下步骤来创建和使用管道:
-
创建和配置管道。有关更多信息,请参见 Create and Configure Pipelines 。
-
测试新管道。有关详细信息,请参阅测试管道。
-
启动管道。有关详细信息,请参阅启动管道。
此外,您可以监视、停止或删除管道:
-
在管道运行时,无论是在测试期间还是在启动管道后常规使用期间,都可以监视管道。有关更多信息,请参见 Monitor and Troubleshoot Pipelines 。
-
您可以停止某个管道,稍后再次启动它,或者在管道使用完毕后删除管道。有关更多信息,请参见 Stop a Pipeline 和 Drop a Pipeline 。
加载管道
使用加载管道从对象存储中的外部文件向数据库表中连续加载增量数据。加载管道定期标识对象存储中的新文件,并将新数据加载到数据库表中。
负载管道的运行方式如下(可以使用管道属性配置其中一些功能):
-
对象存储文件将并行加载到数据库表中。
-
加载管道使用对象存储文件名来唯一标识和加载较新的文件。
-
在数据库表中加载对象存储中的文件后,如果对象存储中的文件内容发生更改,则不会再次加载该文件。
-
如果删除了对象存储文件,则不会影响数据库表中的数据。
-
-
如果遇到故障,加载管道将自动重试该操作。每次后续运行管道的调度作业时都会尝试重试。
-
如果文件中的数据不符合数据库表,则将其标记为
FAILED,并且可以对其进行检查以调试问题并对其进行故障排除。- 如果任何文件无法加载,则管道不会停止并继续加载其他文件。
-
负载管道支持多种输入文件格式,包括:JSON、CSV、XML、Avro、ORC 和 Parquet。

从非 Oracle 数据库迁移是加载管道的一个可能用例。当您需要将数据从非 Oracle 数据库迁移到专用 Exadata 基础结构上的 Oracle Autonomous AI Database 时,您可以提取数据并将其加载到自治 AI 数据库中(Oracle Data Pump 格式不能用于从非 Oracle 数据库进行迁移)。通过使用 CSV 等通用文件格式从非 Oracle 数据库导出数据,可以将数据保存到文件并将文件上载到对象存储。接下来,创建一个管道,将数据加载到自治 AI 数据库。使用加载管道加载大量 CSV 文件具有重要优势,例如容错、恢复和重试操作。对于具有大型数据集的迁移,您可以为非 Oracle 数据库文件创建多个管道(每个表一个),以将数据加载到自治 AI 数据库中。
导出管道
使用导出管道连续将数据从数据库增量导出到对象存储。导出管道定期标识候选数据并将数据上载到对象存储。
有三个导出管道选项(可以使用管道属性配置导出选项):
-
使用日期或时间戳列作为跟踪较新数据的键,将查询的增量结果导出到对象存储。
-
使用日期或时间戳列作为跟踪较新数据的键,将表的增量数据导出到对象存储。
-
使用查询将表的数据导出到对象存储,以在不引用日期或时间戳列的情况下选择数据(以便管道导出查询为每个计划程序运行选择的所有数据)。
导出管道具有以下功能(其中一些可使用管道属性进行配置):
-
结果将并行导出到对象存储。
-
如果出现任何故障,后续管道作业将重复导出操作。
-
导出管道支持多种导出文件格式,包括:CSV、JSON、Parquet 或 XML。
Oracle 维护的管道
专用 Exadata 基础结构上的自治 AI 数据库提供内置管道,以 JSON 格式将特定日志导出到对象存储。这些管道是预配置的,并由 ADMIN 用户启动和拥有。
Oracle 维护的管道包括:
-
ORA$AUDIT_EXPORT:此管道将数据库审计日志以 JSON 格式导出到对象存储,并在启动管道后每 15 分钟运行一次(基于interval属性值)。 -
ORA$APEX_ACTIVITY_EXPORT:此管道将 Oracle APEX 工作区活动日志导出到 JSON 格式的对象存储。此管道预先配置了用于检索 APEX 活动记录的 SQL 查询,并在启动管道后每 15 分钟运行一次(基于interval属性值)。
要配置和启动 Oracle 托管管道,请执行以下操作:
-
确定要使用的 Oracle 托管管道:
ORA$AUDIT_EXPORT或ORA$APEX_ACTIVITY_EXPORT。 -
设置
credential_name和location属性。注:
credential_name是专用 Exadata 基础结构上的自治 AI 数据库的必填值。例如:
BEGIN DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'credential_name', attribute_value => 'DEF_CRED_OBJ_STORE' ); DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'location', attribute_value => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/bucketname/o/' ); END; /数据库中的日志数据将导出到您指定的对象存储位置。
有关更多信息,请参见 SET_ATTRIBUTE 。
-
(可选)设置
interval、format或priority属性。有关更多信息,请参见 SET_ATTRIBUTE 。
-
启动管道。
有关更多信息,请参见 START_PIPELINE 。