使用 AWS Glue 数据目录查询外部数据
自治 AI 数据库支持与 Amazon AWS Glue Data Catalog 实例同步的系统。
关于使用 AWS Glue 数据目录进行查询
自治 AI 数据库允许您与 Amazon Web Service (AWS) Glue Data Catalog 元数据同步。自治 AI 数据库会自动为 AWS Glue 收集的有关 Amazon Simple Storage Service (S3) 中存储的数据的每个表创建数据库外部表。用户可以从 Autonomous AI Database 查询存储在 S3 中的数据,而无需手动为外部数据源推导方案并创建外部表。
Amazon AWS Glue Data Catalog 是一个集中式元数据管理服务,可帮助数据专业人员发现数据,并支持 AWS 云中的数据治理。Autonomous AI Database 实例可以将自动数据目录元数据与 AWS Glue Data Catalog 同步,让数据库用户可以立即使用 Autonomous AI Database 查询存储在 AWS 云中的数据。
与 AWS Glue Data Catalog 同步的属性与与与 OCI Data Catalog 同步的属性相同。同步是动态的,可使数据库保持对底层数据更改的更新,从而降低管理成本,因为它可以自动维护数十到数千个表。
与使用 AWS Glue 数据目录查询相关的概念
要查询 Amazon Web Service (AWS) Glue 数据目录,必须了解以下概念。
AWS Glue 数据目录:数据库
AWS Glue 数据库表示一组关系表定义,这些定义按逻辑组组织。每个 AWS Glue 数据目录实例管理多个数据库。
AWS Glue 数据目录:表
AWS Glue 表代表与存储在 AWS 云中的数据相关的关系表。AWS Glue 表定义基础数据的模式,由列信息、分区信息、序列化信息、存储信息、统计信息、用户定义的元数据和其他元数据组成。AWS Glue 数据目录中的表可以手动创建,也可以使用 AWS Glue Crawler 自动创建。
胶水数据目录:Crawler
可以使用 Crawler 使用表填充 AWS Glue 数据目录。这是大多数 AWS Glue 用户使用的主要方法。Crawler 可以在一次运行中搜索多个数据存储。完成后,Crawler 将在数据目录中创建或更新一个或多个表。提取、转换和加载在 AWS Glue 中定义的 (ETL) 作业时,使用这些数据目录表作为源和目标。ETL 作业从源和目标数据目录表中指定的数据存储进行读取和写入。
AWS Glue 表可由用户手动创建,也可以使用预定义或自定义爬网程序自动创建。Crawlers 连接到底层数据存储(例如 Amazon S3),调用分类器以派生数据的模式,并创建 AWS Glue 表以存储推断的元数据。AWS Glue 为常见文件类型(例如 CSV、JSON、Parquet 和 AVRO)提供分类器。
自治 AI 数据库与 AWS Glue 之间的映射
在同步过程中,外部表是在基于 Amazon S3 的 AWS Glue 数据目录数据库和表派生的自治 AI 数据库中创建的。
AWS Glue 在数据库和表中组织收集的元数据。AWS Glue 数据库是关系表定义的集合。AWS Glue 表,用于描述与表关联的文件的通用模式和属性。
AWS Glue 遵循用于表示属性的关系模型。对于将分层方案映射到关系方案,AWS Glue 推断半结构化数据的方案,并使用 ETL 流程将数据扁平化为关系方案。
下表显示了 OCI 数据目录概念与 AWS Glue 数据目录概念之间的映射。
| OCI 数据目录 | AWS Glue 数据目录 | Oracle 数据库 |
|---|---|---|
| 数据资产 | Database | 方案 |
| Folder - 文件夹 | (存储桶) | 方案 |
| 逻辑主体 | 表 | 表 |
使用 AWS Glue 数据目录进行查询的用户工作流
使用 AWS Glue Data Catalog 查询 AWS S3 数据的基本用户工作流包括连接到 AWS Glue Data Catalog,与 Autonomous AI Database 同步以自动创建外部表,然后查询 S3 数据。
数据库数据目录管理员在 Autonomous AI Database 实例与 AWS Glue Data Catalog 实例之间创建连接,然后配置并运行 AWS Glue Data Catalog 与 Autonomous AI Database 之间的同步(同步)。自治 AI 数据库自动为 AWS Glue 收集的有关存储在 S3 中的数据的表创建外部表。
数据库数据目录查询管理员或数据库管理员授予对生成的外部表的 READ 访问权限,以便数据分析师和其他数据库用户可以浏览和查询自治 AI 数据库,而无需手动推导外部数据源的方案并创建外部表。
用户
下表介绍了执行用户工作流操作的不同类型的用户。
| User | 说明 |
|---|---|
| 数据库数据目录管理员 | 具有 DCAT_SYNC 角色的数据库用户。 |
| 数据库数据目录查询管理员 | 数据库用户能够向其他用户授予对自动创建的外部表的访问权限。 |
| 数据分析师 | 自治 AI 数据库上的数据库用户通过查询自动创建的外部表或直接与 AWS Glue 数据目录交互来查询 AWS S3 中的数据。 |
| AWS Glue 数据目录用户 | 可访问 AWS Glue 数据目录的 AWS 用户。 |
| AWS S3 对象存储用户 | 可以访问 AWS S3 中存储的数据的 AWS 用户 |
用户工作流
注:DBMS_DCAT 程序包可用于执行使用 AWS Glue Data Catalog 查询 AWS S3 对象存储所需的任务。请参见 DBMS_DCAT Package 。
| 操作 | 用户是谁 | 说明 |
|---|---|---|
| 创建策略 | 数据库数据目录管理员 | 自治 AI 数据库用户身份证明必须具有适当的权限,才能访问 AWS Glue 数据目录并从 S3 对象存储进行读取。 有关更多信息:必需的身份证明和 IAM 策略。 |
| 创建身份证明 | 数据库数据目录管理员 | {::nomarkdown} <p> 确保数据库身份证明已到位,可以访问 AWS Glue 数据目录和查询 S3 对象存储。用户调用 DBMS_CLOUD.CREATE_CREDENTIAL 以创建用户身份证明。</p><p> 注:仅支持 Amazon Web Services (AWS) 身份证明。AWS Amazon 资源名称 (ARN) 身份证明不受支持。</p><p> 详细信息: DBMS_CLOUD CREATE_CREDENTIAL 过程 </p> |
| CONNECT | 数据库数据目录管理员 | 在自治 AI 数据库实例与 AWS Glue 数据目录实例之间建立连接。此连接使用 AWS Glue Data Catalog 用户的权限。支持从自治 AI 数据库实例到多个 AWS Glue 数据目录实例的连接。 要启动自治 AI 数据库实例与 AWS Glue 数据目录实例之间的连接,用户:
建立连接后,自治 AI 数据库将存储关联的元数据,例如 AWS Glue 目录 ID、区域、端点和身份证明对象。 有关更多信息: SET_DATA_CATALOG_CONN Procedure 、 UNSET_DATA_CATALOG_CONN Procedure 、 DBMS_DCAT。SET_DATA_CATALOG_CREDENTIAL 、 DBMS_DCAT.SET_OBJECT_STORE_CREDENTIAL 。 |
| 同步 | 数据库数据目录管理员 | 用户可以使用 同步执行以下操作:
|
| 监视器同步 | 数据库数据目录管理员 | 用户可以通过查询 USER_LOAD_OPERATIONS 视图来查看同步状态。同步过程完成后,用户可以查看同步结果的日志,包括有关到外部表的映射的详细信息。 |
| 授予权限 | 数据库数据目录查询管理员,数据库管理员 | 数据库数据目录查询管理员或数据库管理员必须向数据分析师用户授予对生成的外部表的 READ 权限。这允许数据分析师查询生成的外部表。 |
| 查询 | 数据分析师 | 数据分析师能够查看 GLUE$* 方案中的同步方案和表,并通过支持 Oracle SQL 的任何工具或应用程序查询外部表。 使用 AWS S3 对象存储用户的权限访问 S3 中的数据。 有关详细信息:示例:使用 AWS Glue 数据目录查询 |
| 终止连接 | 数据库数据目录管理员 | 要删除现有的数据目录关联,用户将调用 仅当您不再计划使用连接的 AWS Glue 数据目录和从目录派生的外部表时,才会执行此操作。此操作会删除 AWS Glue 数据目录元数据,并从自治 AI 数据库实例中删除已同步的外部表。 |
示例:使用 AWS Glue 数据目录进行查询
本示例将引导您完成使用 AWS Glue 数据目录对存储在 Amazon Simple Storage Service (Amazon S3) 中的数据集运行查询的过程。
在此示例中,将检查 AWS Glue 数据目录中的元数据,以查看以前在数据目录中搜索和存在的 Amazon S3 对象。然后,自治 AI 数据库与 AWS Glue 数据目录和 Amazon S3 关联。数据目录与自治 AI 数据库同步,以便基于存储在 Amazon S3 中的数据集创建外部表。外部表用于查询 Amazon S3 中的数据集。
-
检查 AWS Glue 数据目录中的元数据。
-
启动 AWS Glue 控制台。
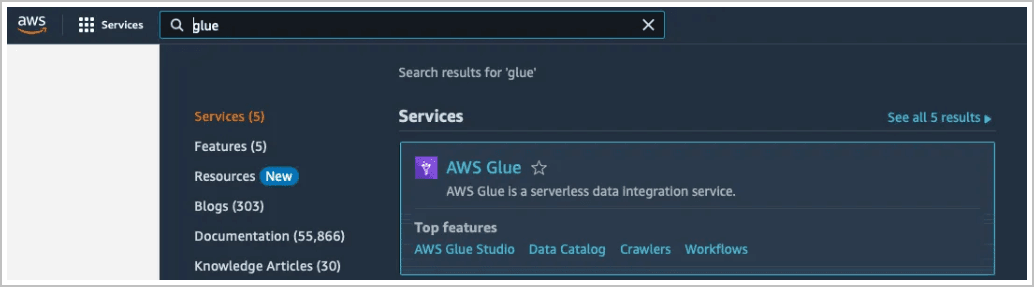
-
导航到数据目录、数据库和表以查找现有对象。
在此示例中,Amazon S3 中存在 AWS Glue 以前搜索并创建了表的一些对象,如下所示:
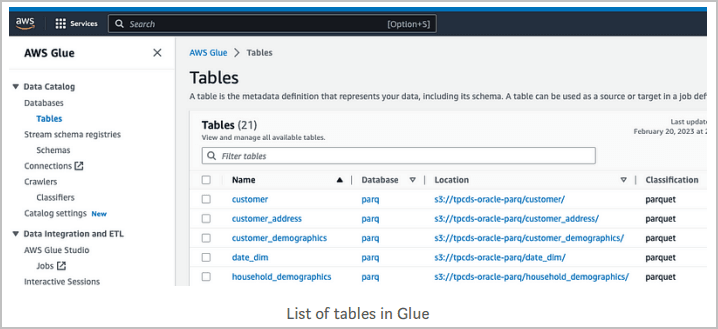
-
-
将 AWS Glue 与自治 AI 数据库关联。
-
在自治 AI 数据库中创建身份证明。
以下过程调用包括访问 ID 和密钥,以向自治 AI 数据库提供对 Amazon S3 中底层数据的访问权限。
exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>'); -
将凭证与 AWS Glue 数据目录和 Amazon S3 对象存储关联。
这些过程调用分别将数据目录和对象存储与凭证关联。
exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS'); -
设置运行 Glue 的 AWS 区域。
exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');
-
-
同步元数据以在从 AWS Glue 数据库和表派生的自治 AI 数据库中创建外部表。
-
现在该关联已经完成,请使用
all_glue_databases视图查找 AWS Glue 数据目录中的数据库。select * from all_glue_databases order by name; -
使用
all_glue_tables视图可获取可同步的表列表。select * from all_glue_tables order by database_name, name;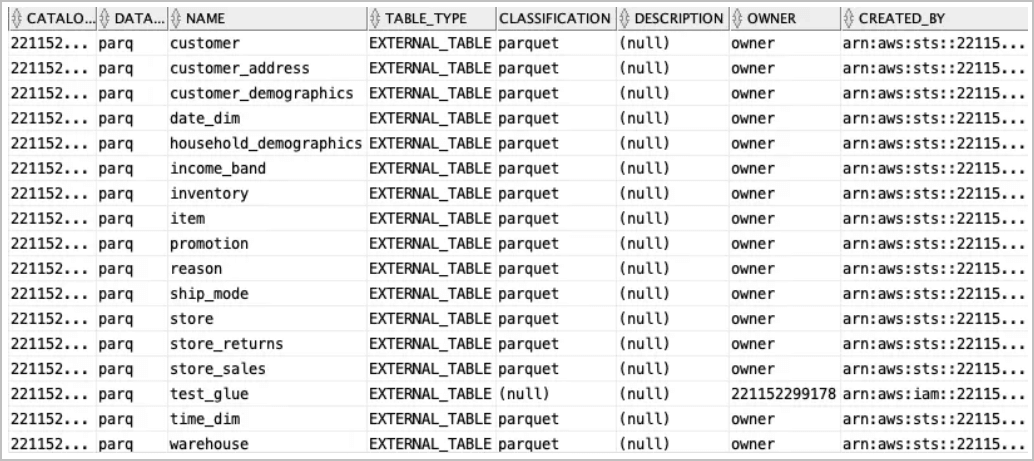
-
将自治 AI 数据库与
parq数据库中的两个表store和item同步。begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /
-
-
检查自治 AI 数据库中的新对象并在 S3 上运行查询。
-
使用 SQL Developer 查看由上一个同步操作创建的新对象。
GLUE$PARQ_TPCDS_ORACLE_PARQ方案由dbms_dcat.run_sync过程调用自动生成并命名。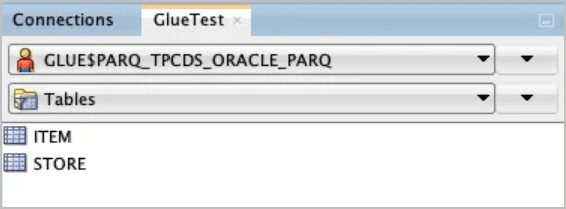
-
对 Amazon S3 中的数据集存储运行 SQL 查询。
SELECT * FROM glue$parq_tpcds_oracle_parq.store;
-