简介
本教程支持客户和合作伙伴配置具有机器学习功能的高级预测,以便通过考虑关键业务驱动因素来生成更准确的预测。本教程介绍如何配置高级预测,并根据业务注意事项和 IPM 解决方案功能提供实施建议。本教程重点介绍有关批量预测的特定业务用例,并考虑一些关键输入驱动因素来训练机器学习模型并生成更准确的预测。各节基于彼此构建,应按顺序完成。
背景信息
高级预测或机器学习预测是指使用机器学习模型基于输入功能预测数据的过程。
高级预测的主要优势:
- 通过与提供的其他数据点关联,实现更强大的预测。
- 嵌入在 Oracle EPM 中,为财务和运营用户提供针对多维计划和预测用例进行优化的数据科学。
- 利用更复杂的算法并提高准确性。
- 使用分步配置向导可以更轻松地进行配置。
高级预测的优势:
- 基于您的 EPM 数据和上下文:用户无需使用任何外部数据科学平台或机器学习工具。高级预测功能嵌入到 EPM 数据和上下文中,为财务和运营用户赋能。
- 由 OCI AI 基础设施提供支持:在 EPM 系统中构建、训练和部署机器学习模型。
- 提高预测准确性:高级预测可以在运行预测之前对数据执行特征工程和特征选择,从而提高预测准确性。
- 增强的决策:了解哪些业务驱动因素对预测的影响最大,并将每个驱动因素的相对贡献与功能重要性图表进行比较。
- 每一层的隐私和安全:Advanced Prediction 尊重 EPM 安全层,这意味着 ML 模型生成的预测数据的访问由管理 EPM 系统其他领域的强大安全框架控制。
- 嵌入式,无需额外付费:Oracle EPM Enterprise 许可证支持,无需额外付费。
- 可扩展框架:支持数据处理和预处理,支持使用包含外部数据的管道的可扩展框架,支持使用 API BYOML 的多个平台进行预测。
高级预测的主要注意事项:
- 仅适用于企业 EPM 许可证
- 仅通过 Redwood 主题访问
- 是仅选择加入功能 - 在应用程序设置中提供选择加入功能
- 通过 OCI Data Science 嵌入到 EPM 中,因此无需额外付费即可部署 OCI Data Science
- 可用于不同的 Planning 应用程序,包括 Modules、Custom、FreeForm、Sales Planning、Strategic Workforce Planning、Predictive Cash Forecasting
- 适用于 BSO 和 ASO 多维数据集
批量预测用例

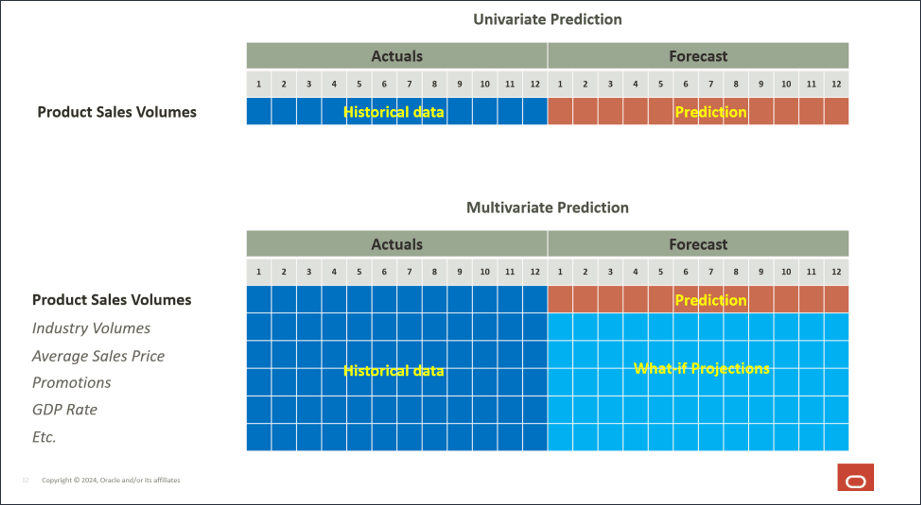
考虑您希望根据 1 月 FY22 到 6 月 FY24 之间的历史销售量按产品预测销售量的用例。除了历史销售量之外,您还使用输入驱动因素,如行业销售量、平均销售价格、广告和营销促销以及折扣率 - 所有可能影响未来销售量预测的内部因素。您还可以使用几个外部驱动因素,例如 GDP 增长率等经济指标,以及可能会影响未来数量预测的个人消费支出。
历史输入动因主要从数据源导入,未来输入动因值可以使用传统方法(如动因或基于趋势)进行计划,也可以使用作为高级预测作业本身一部分的单变量预测(计算功能)。
先决条件
Cloud EPM 实操教程可能需要您将快照导入 Cloud EPM Enterprise Service 实例。在导入教程快照之前,必须请求另一个 Cloud EPM Enterprise Service 实例或删除当前应用程序和业务流程。教程快照不会通过现有应用程序或业务流程导入,也不会自动替换或恢复您当前使用的应用程序或业务流程。
在开始本教程之前,您必须:
- 具有服务管理员对 Cloud EPM Enterprise Service 实例的访问权限。不应创建实例的业务流程。
- 将此快照上载并导入到 Planning 业务流程。
- 将此日期映射下载到本地计算机。
提示:
要在本地保存文件,可以右键单击并选择将链接另存为。确保将文件另存为 .csv 文件。 - 将此销售量预测报表下载到本地计算机。
提示:
要在本地保存文件,可以右键单击并选择将链接另存为。
注意:
如果导入快照时遇到迁移错误,请重新运行迁移(不包括 HSS-Shared Services 组件),以及核心组件中的“安全性”和“用户首选项”对象。有关上载和导入快照的更多信息,请参阅 Administering Migration for Oracle Enterprise Performance Management Cloud 文档。选择加入高级预测
如果要开始使用高级预测和 AI 功能,需要首先转到“应用程序设置”页面并启用它。
- 在主页中,依次单击应用程序和设置。
- 在 "Settings"(设置)中,向下滚动并在右下角的 Enable AI(启用 AI)中,选择 Advanced Predictions(高级预测)以对高级多变量预测启用 AI 数据分析。

- 在“信息”消息中,单击确定。

- 向上滚动并单击保存。
- 在“信息”消息中,单击确定。
- 单击
 (主页)以返回到主页。
(主页)以返回到主页。
为应用程序做准备
在执行本教程中的步骤之前,您需要准备应用程序。提供的应用程序不包括组、角色或安全性,因此您需要创建 EPM 组,然后将其分配给 EPM 云导航流。您可以使用 EPM 云导航流查看使用高级预测生成的预测。
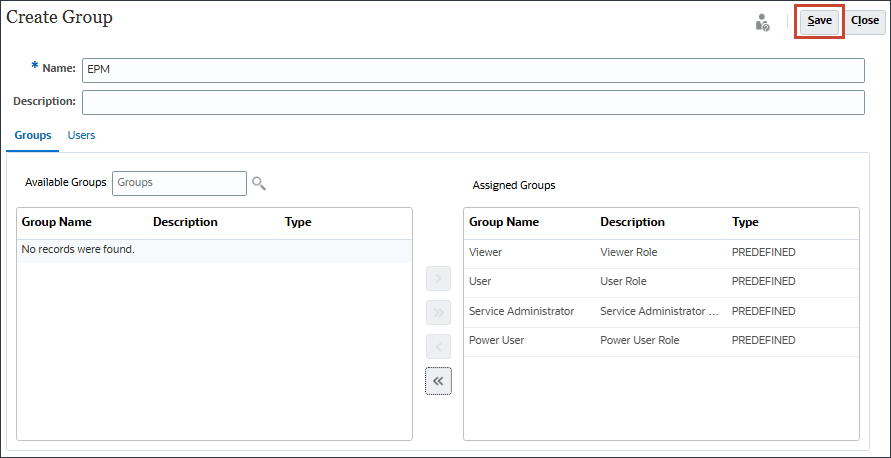
创建 EPM 组
- 在主页中,依次单击工具和访问控制。
- 在管理组中,单击创建。
- 在创建组中,为名称输入 EPM 。
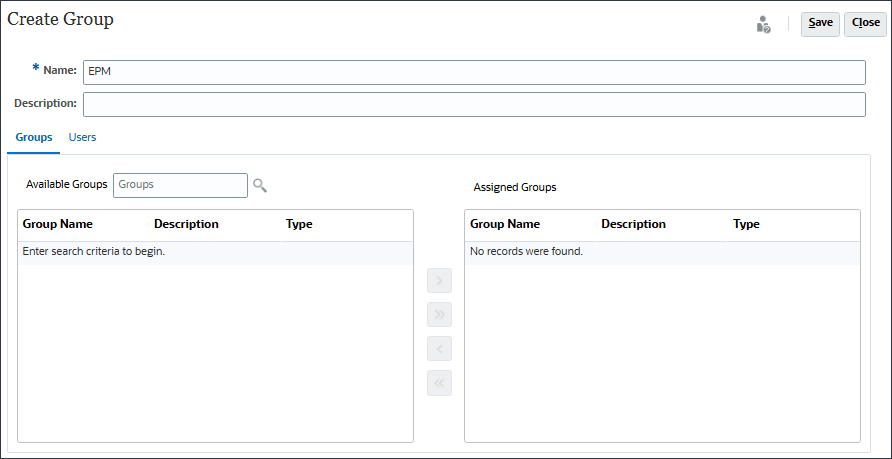
- 选择“Groups(组)”后,单击“Available Groups(可用组)”旁边的
 (搜索)。
(搜索)。
将列出可用组。
- 要移动所有预定义的角色,请单击
 (全部移动)。
(全部移动)。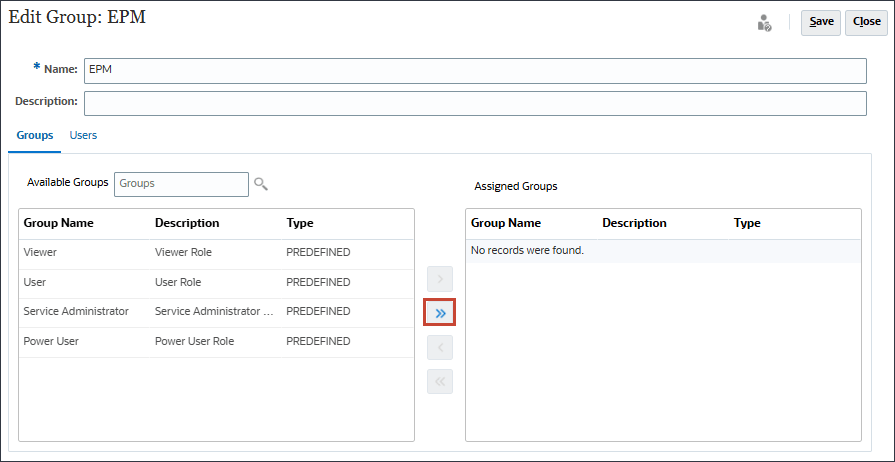
- 单击保存。
- 在信息消息中,单击确定。

- 验证 EPM 是否在管理组中列出。
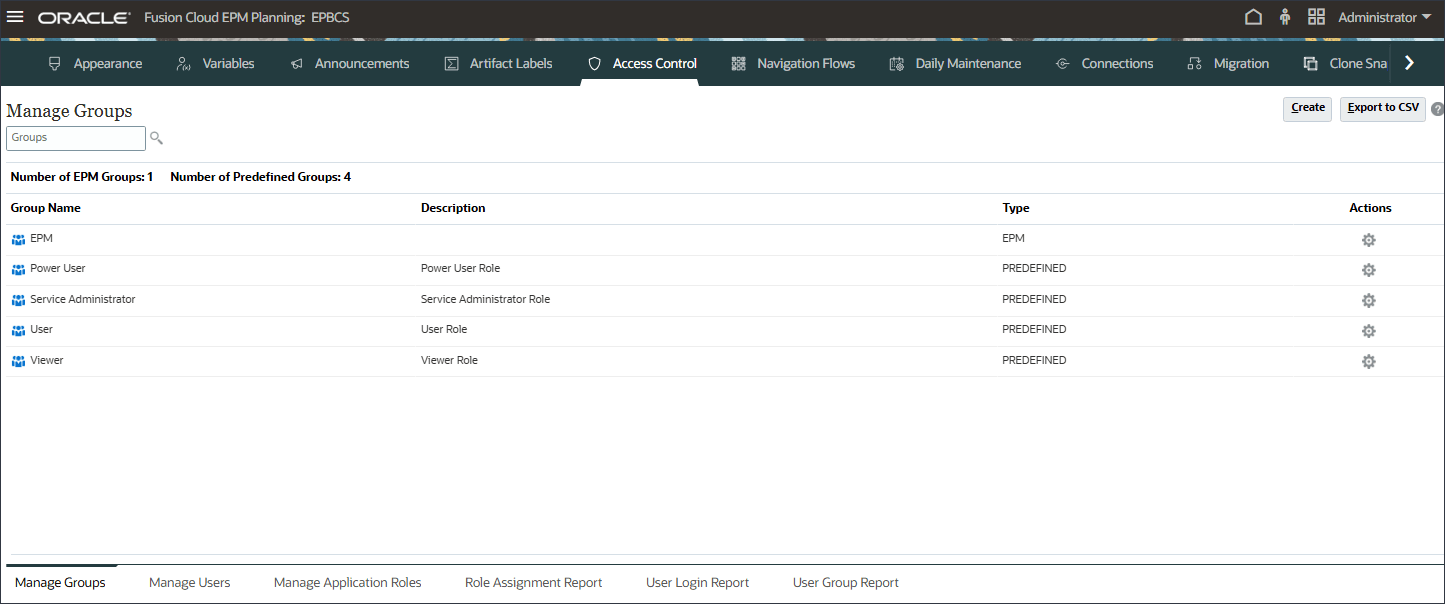
- 单击 (主页)以返回到主页。
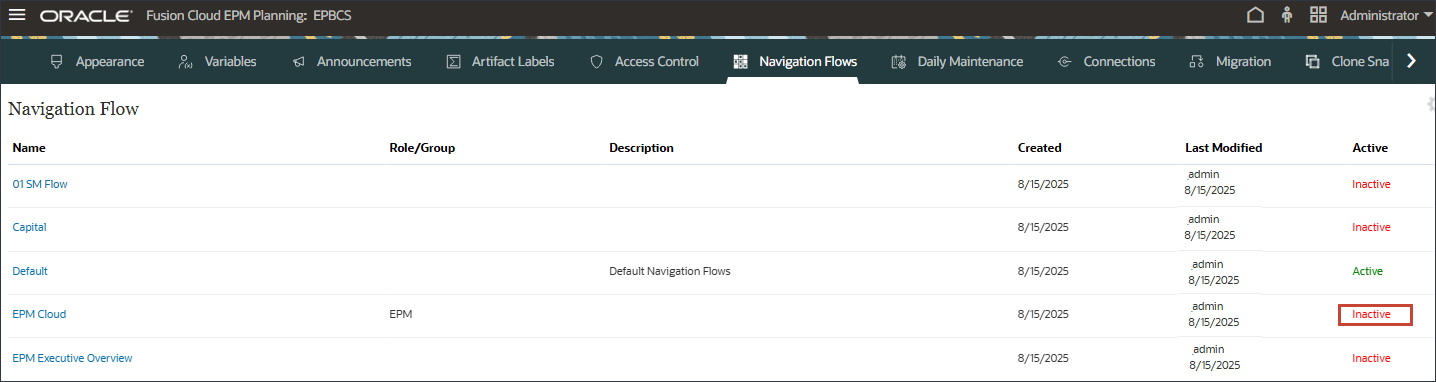
- 在主页中,依次单击工具和导航流。
- 在导航流中,验证 EPM 云是否设置为无效,然后单击 EPM 云。
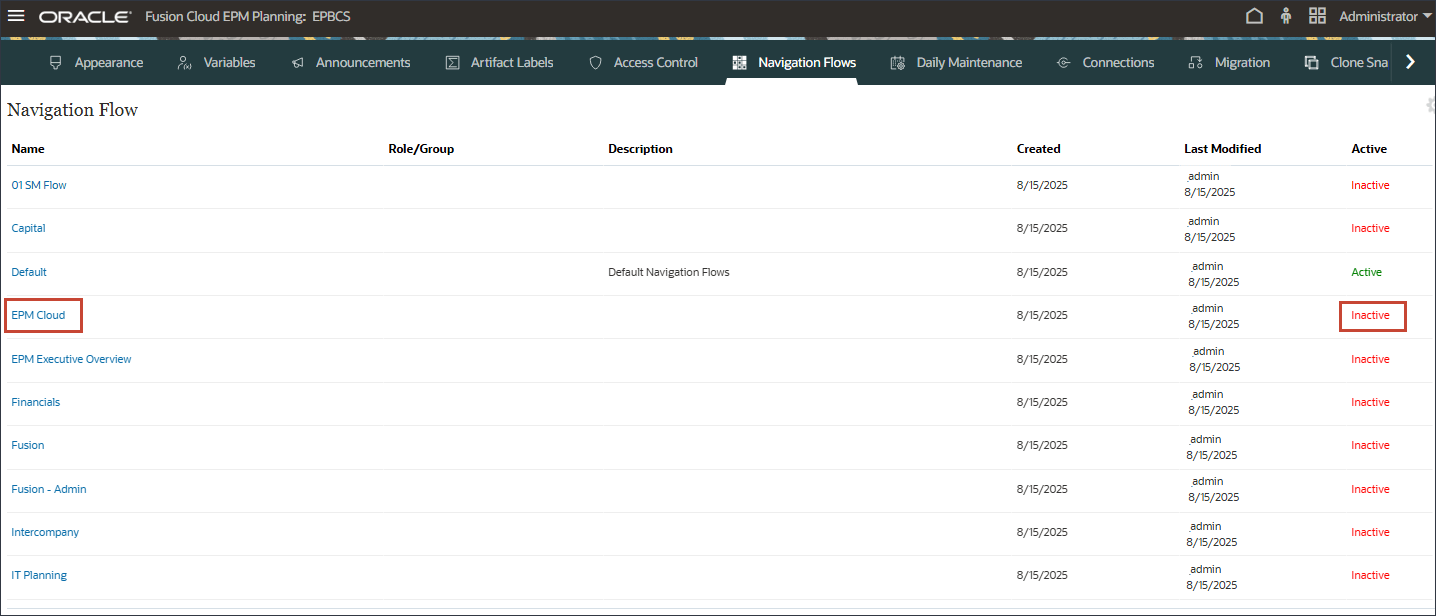
- 在 EPM 云中,对于 Assign to ,输入 EPM ,然后单击 Save and Close(保存并关闭)。
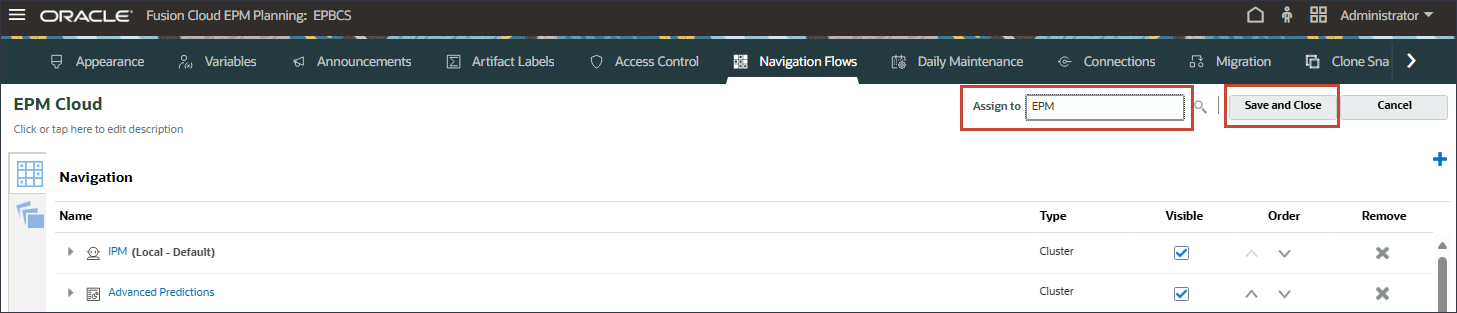
- 对于 EPM 云,单击非活动以激活 EPM 云导航流。
- 单击 (主页)以返回到主页。
将 EPM 组分配给 EPM 云导航流。
为高级预测做准备
在此部分中,您将先完成最终用户步骤,然后再配置高级预测。您可以确保设置了用户变量并选择 EPM 云导航流。您还可以查看卷分析仪表盘。查看并编辑输入动因。您将复核将来期间缺少的输入动因值,并复核预测表单。
设置用户变量
您可以设置用户变量,以便可以在表单和仪表盘中查看数据。
- 在主页中,依次单击工具和用户首选项。
- 单击用户变量。
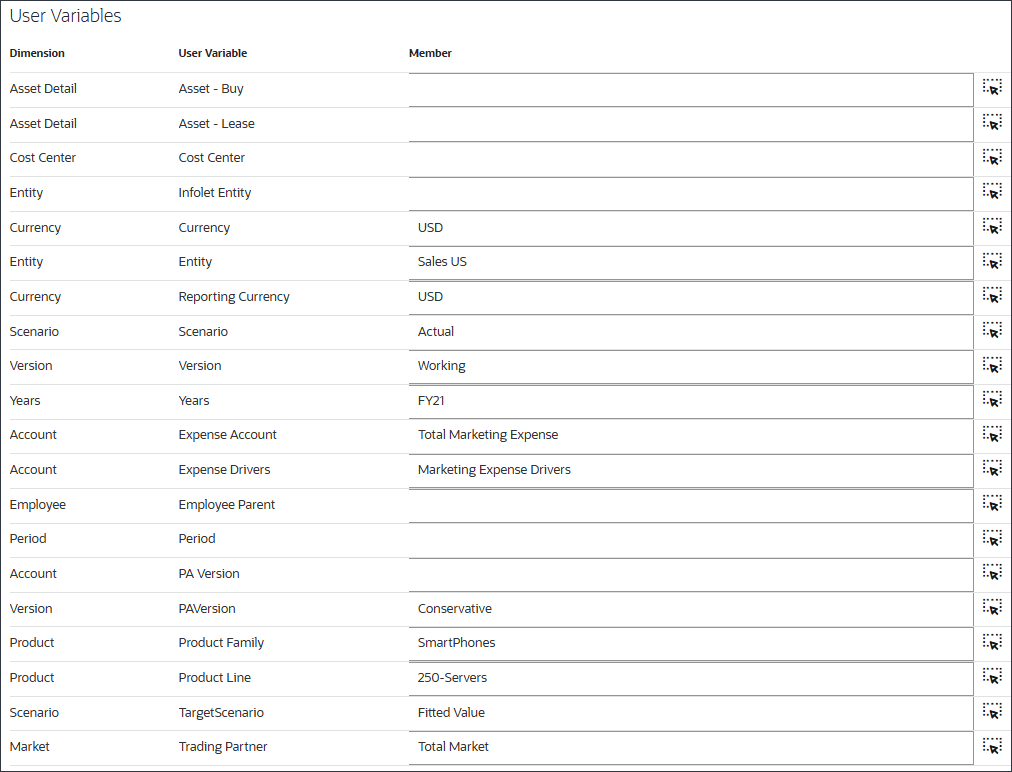
- 对于用户变量,输入或选择以下内容,然后单击保存。
维 用户变量 成员 货币 货币 美元 实体 实体 销售美国 货币 报告币种 美元 Scenario Scenario 实际 Version Version 正在处理 年 年 FY21 账户 费用科目 营销费用总计 账户 费用动因 营销费用动因 Version PA 版本 保守型 Product 产品系列 SmartPhones Product 产品线 250-Servers Scenario TargetScenario 拟合值 Market 交易伙伴 总市场 将选择用户变量。
- 在“信息”消息中,单击确定。
- 单击 (主页)以返回到主页。
选择导航流
您可以选择 EPM 云导航流,其中包含用于高级预测的卡,以便查看数量预测。
- 在主页上,单击
 (默认),然后选择 EPM 云。
(默认),然后选择 EPM 云。
此时将显示 EPM 云导航流。

- 在 EPM 云导航流中,请注意 Advanced Predictions 卡。
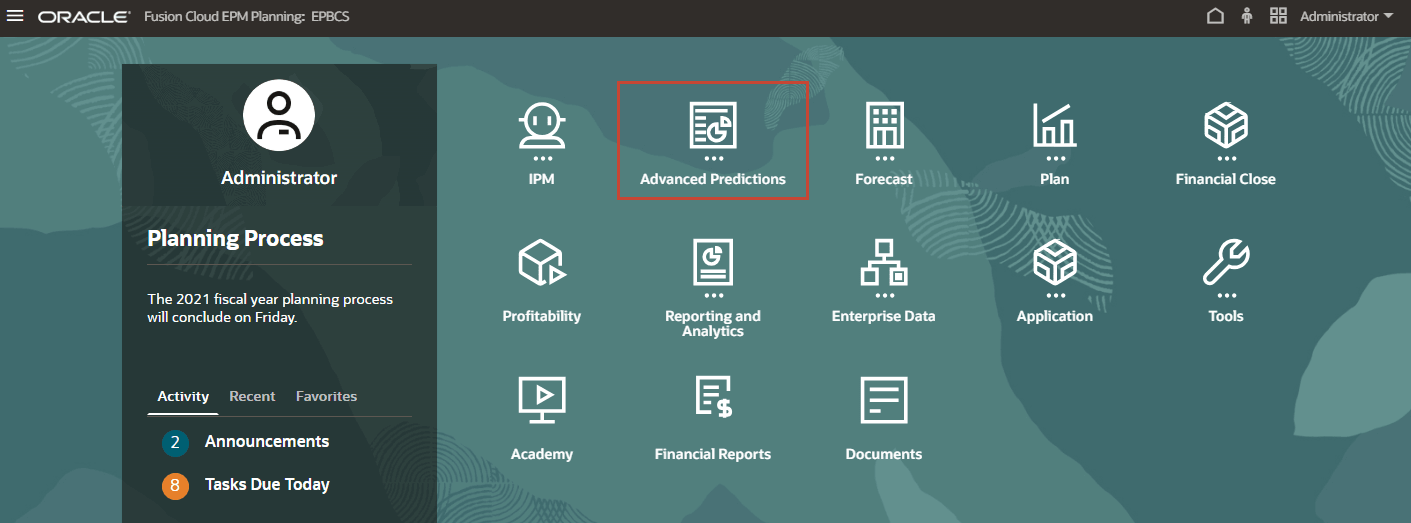
- 单击高级预测。
这是一个导航流,您可以在其中查看使用高级预测生成的预测。
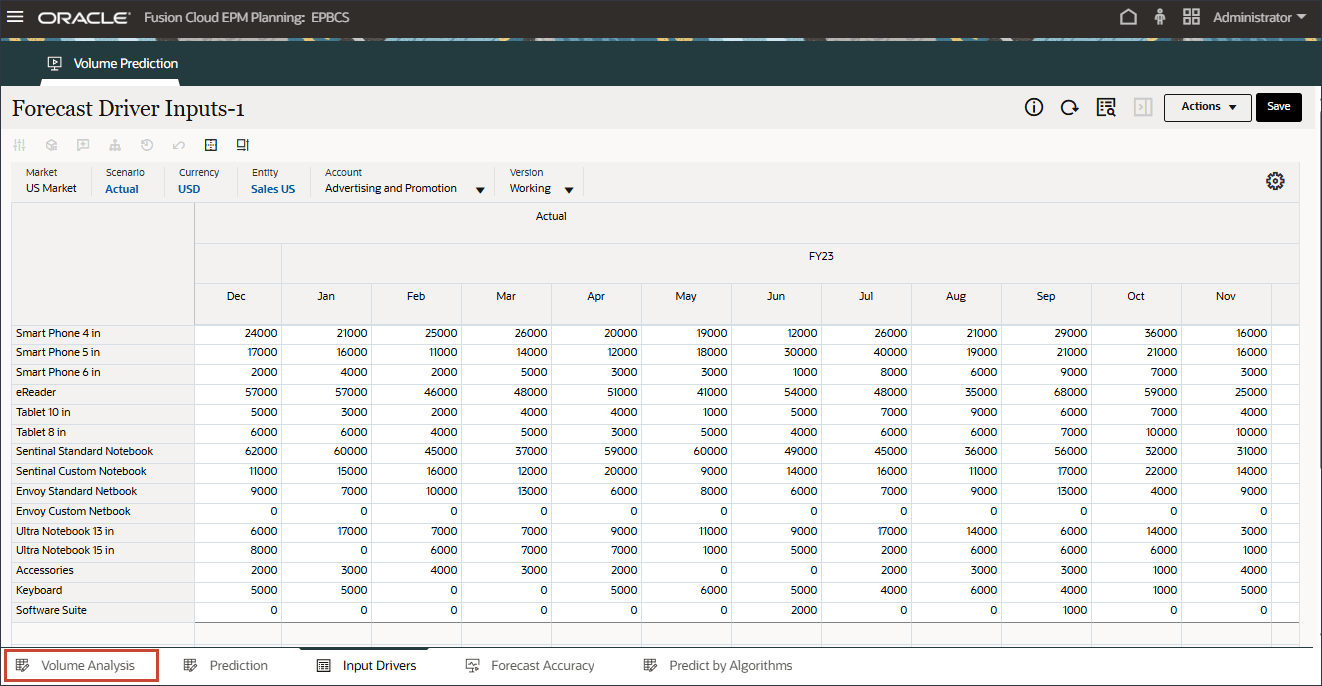
查看批量预测
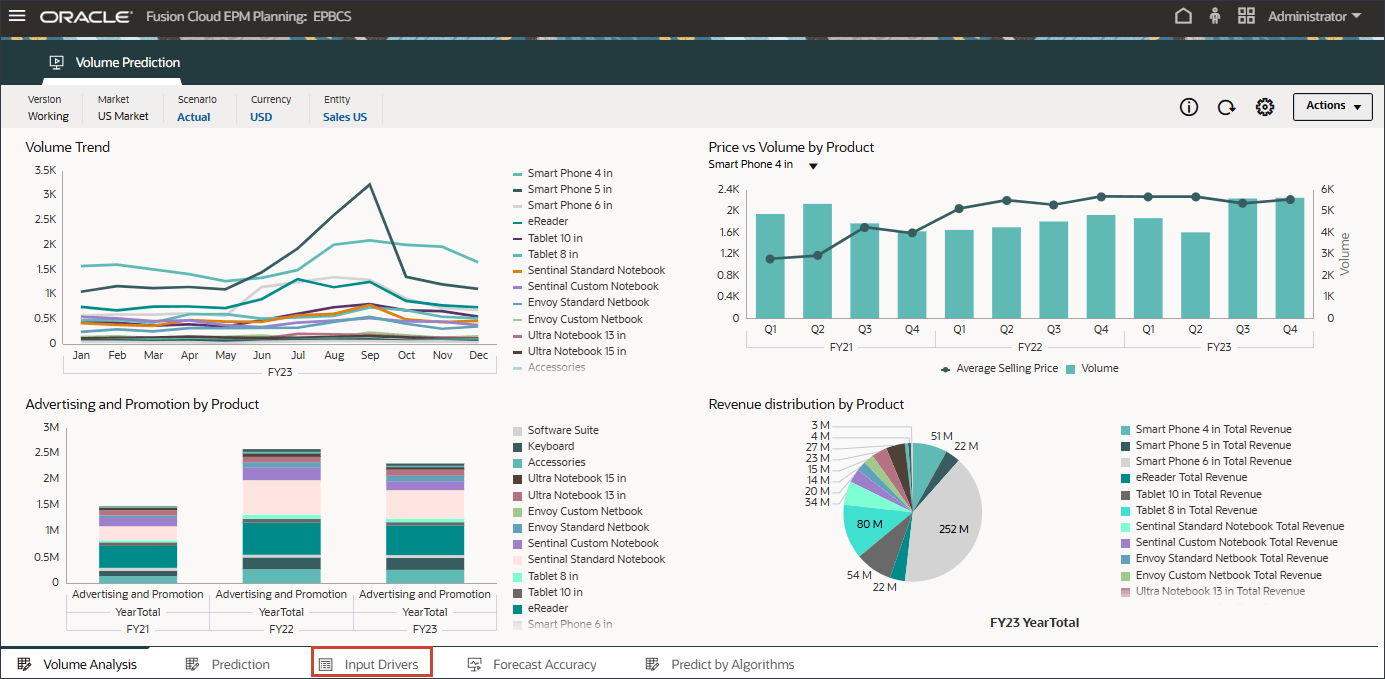
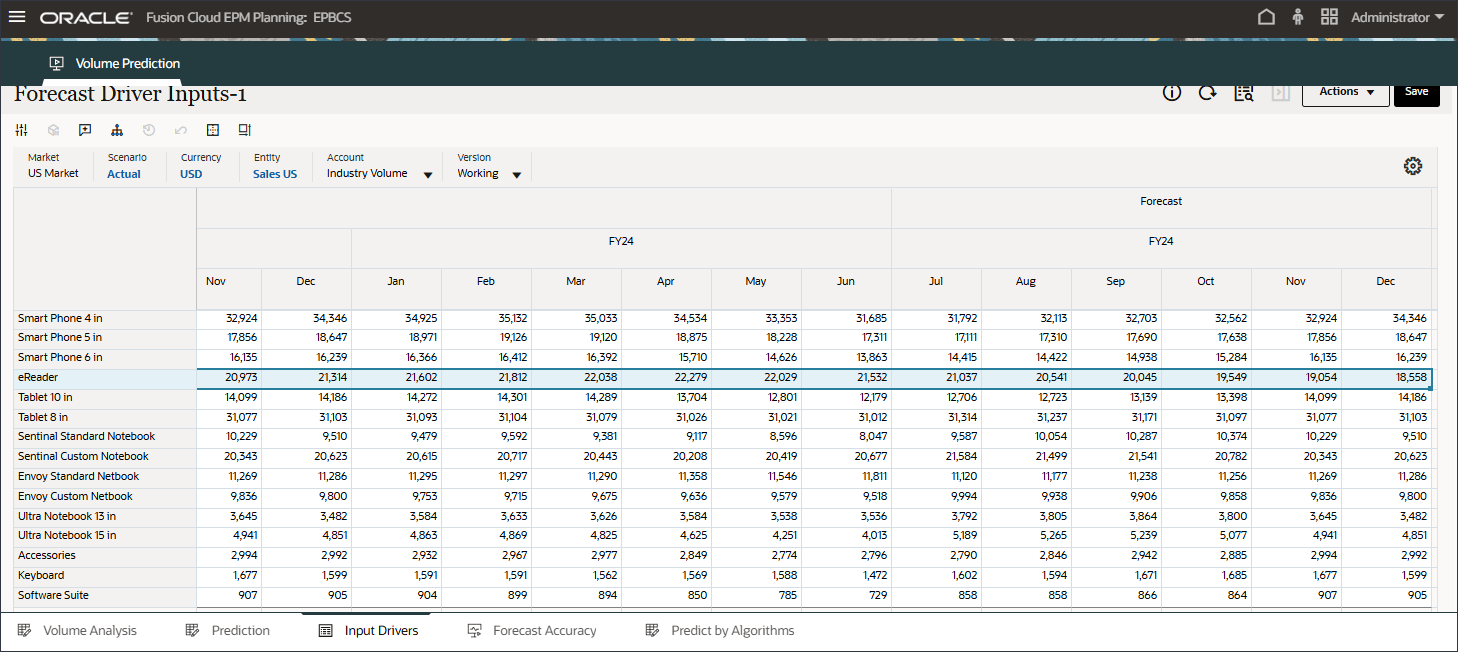
在创建和运行数量预测之前,请查看数量预测仪表盘以及为此用例准备的历史数据。您可以使用“音量预测”卡,该卡设置为按期间和其他驱动程序显示音量分析。此卡还包含用于显示动因值和预测结果的选项卡。
- 在主页上,依次单击高级预测和批量预测。
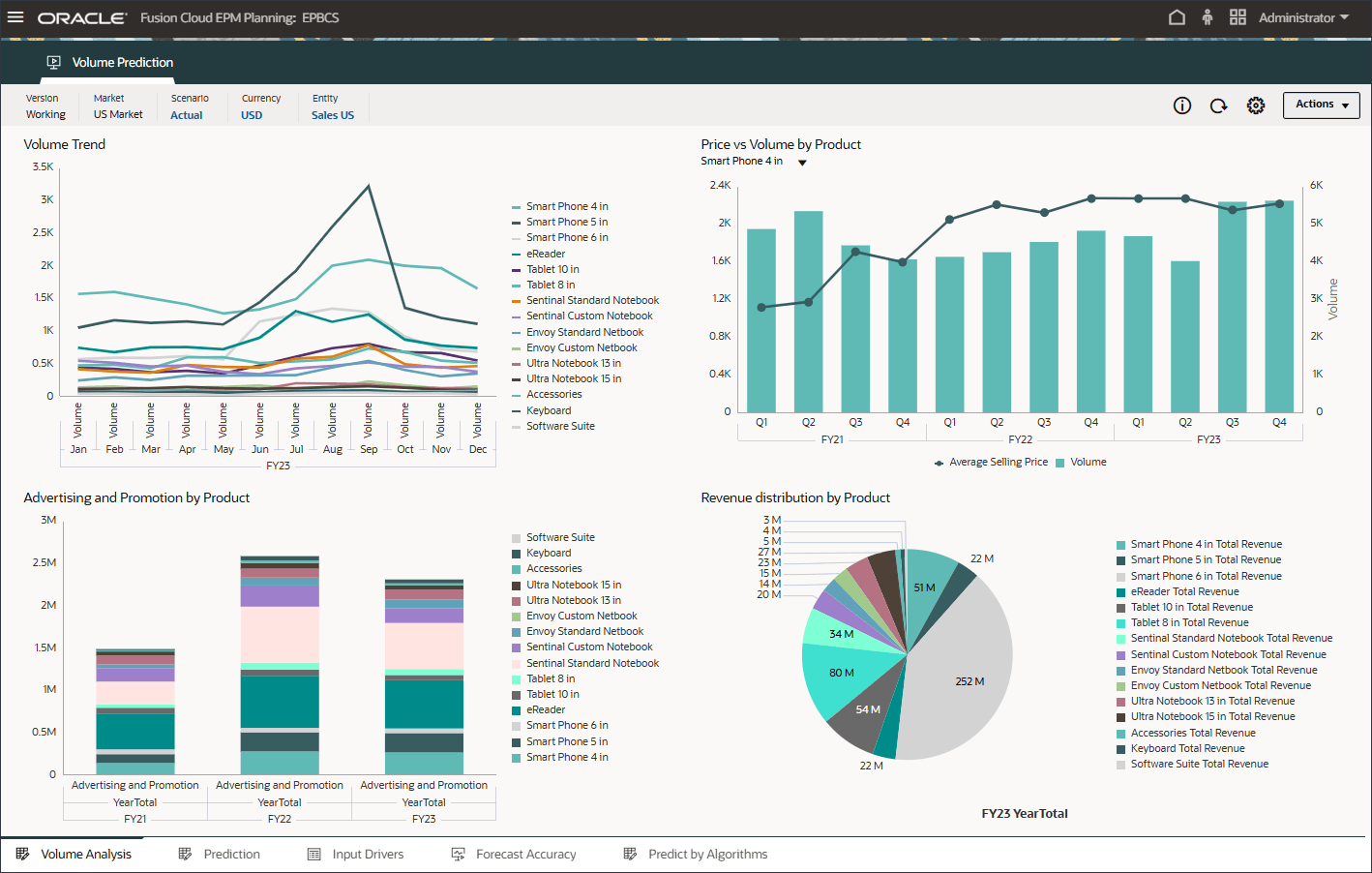
- 查看数量预测,包括按产品列出的数量趋势、价格与数量、按产品列出的广告和促销以及按产品列出的收入分配。
- 在底部,单击预测选项卡。
- 在顶部的条形图中,查看历史数量预测。
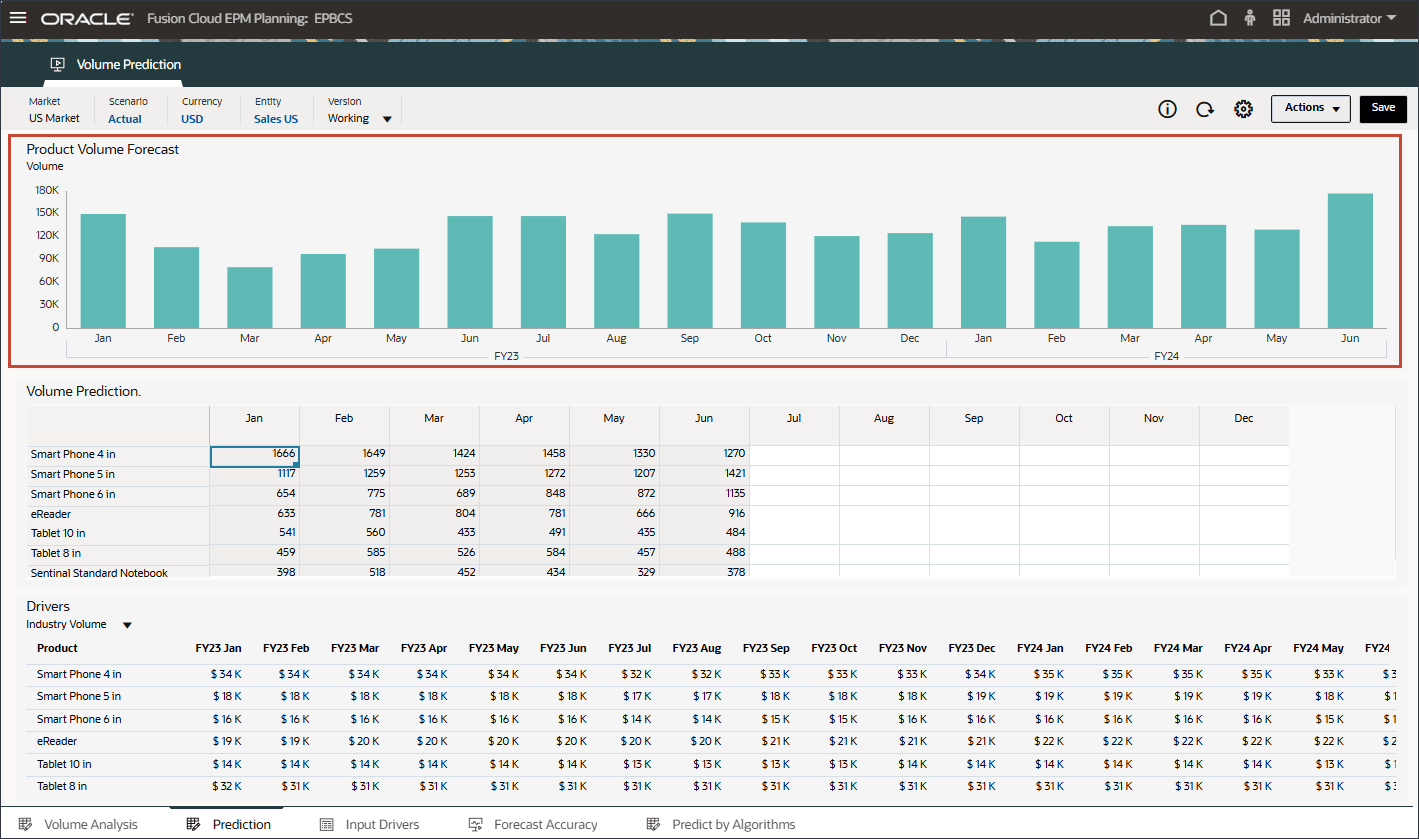
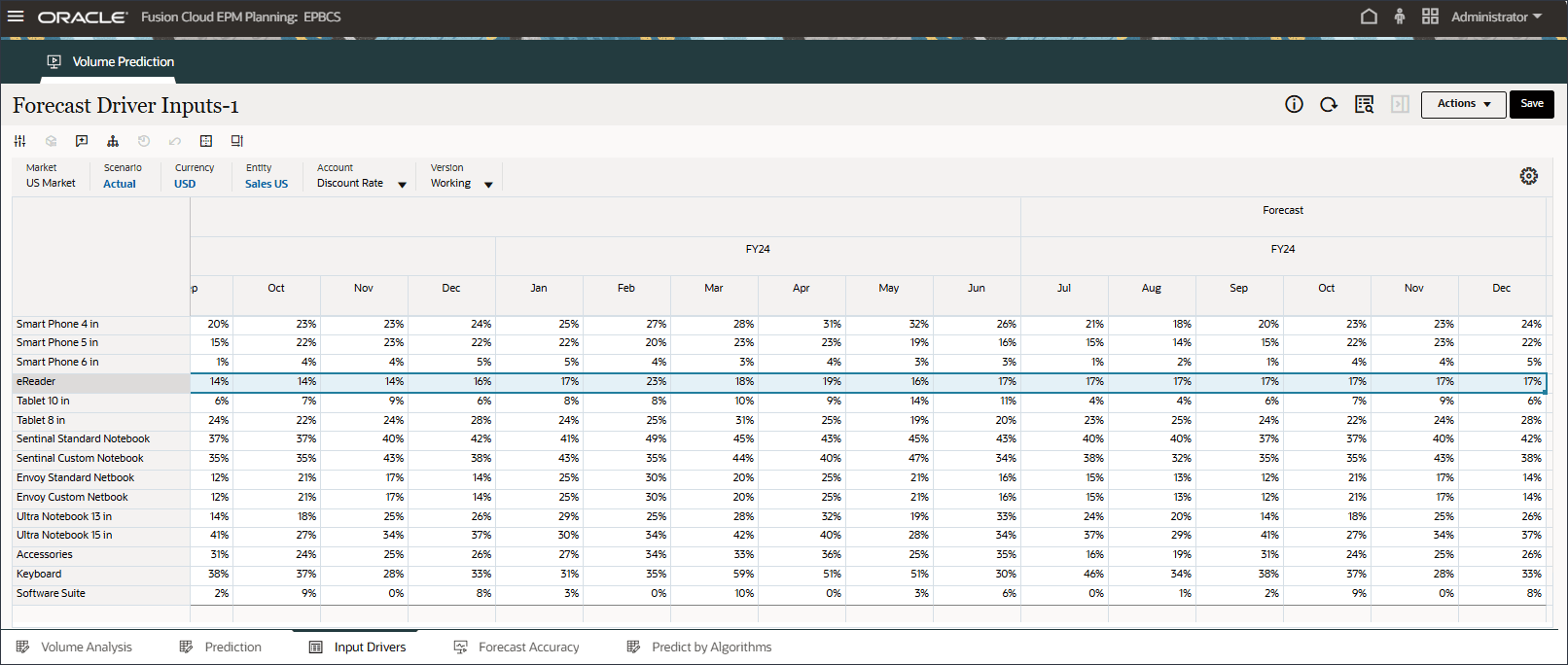
- 在底部的“Drivers(驱动程序)”网格中,查看高级预测中使用的驱动程序数据。这包括历史和将来的驱动程序数据。
虽然驱动器的历史实际数据可以通过集成从不同的系统获取,但未来的驱动数据可以通过传统的预测方法(例如基于驱动因素/趋势/手动)获取,或者可以基于高级预测任务中的设置,使用单变量预测(统计方法)自动生成输入驱动数据。
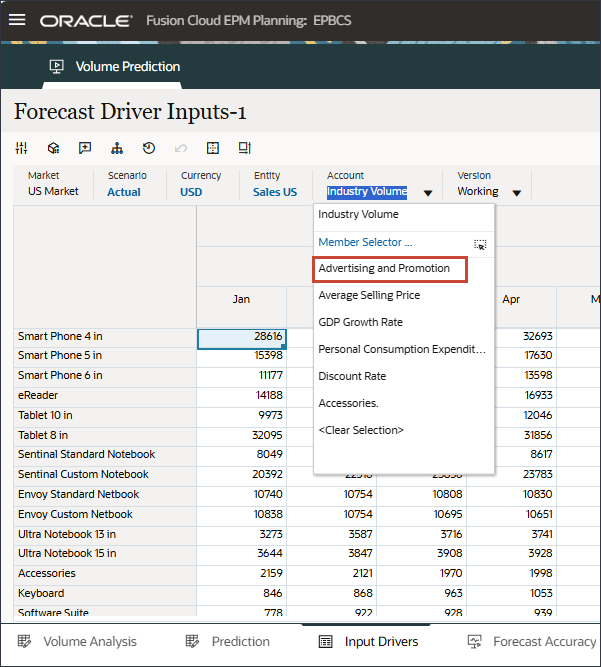
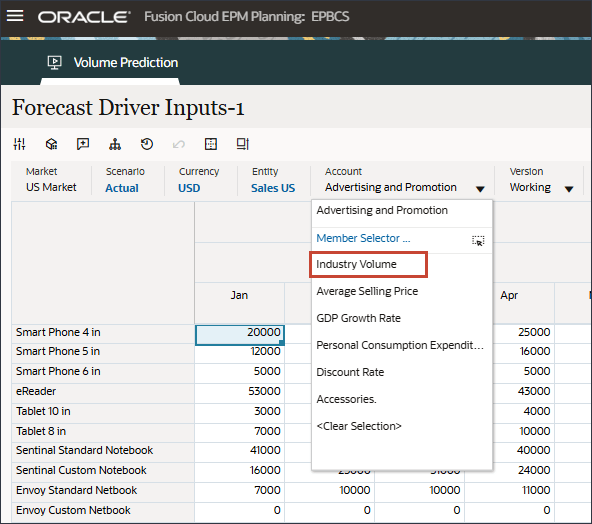
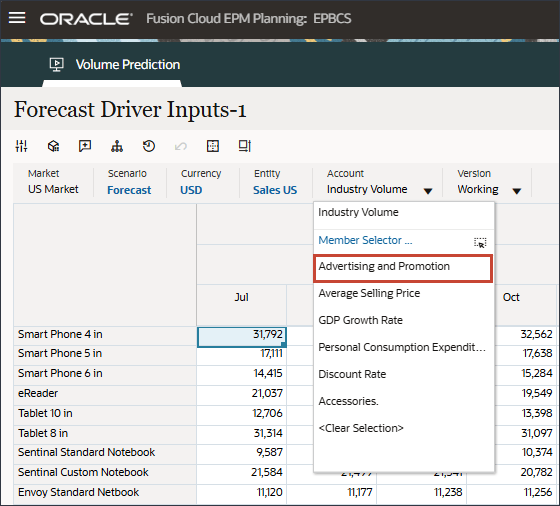
- 在“驱动程序”中,单击 Industry Volume 以查看驱动程序。然后,在查看驱动程序后,再次单击行业卷以关闭列表。
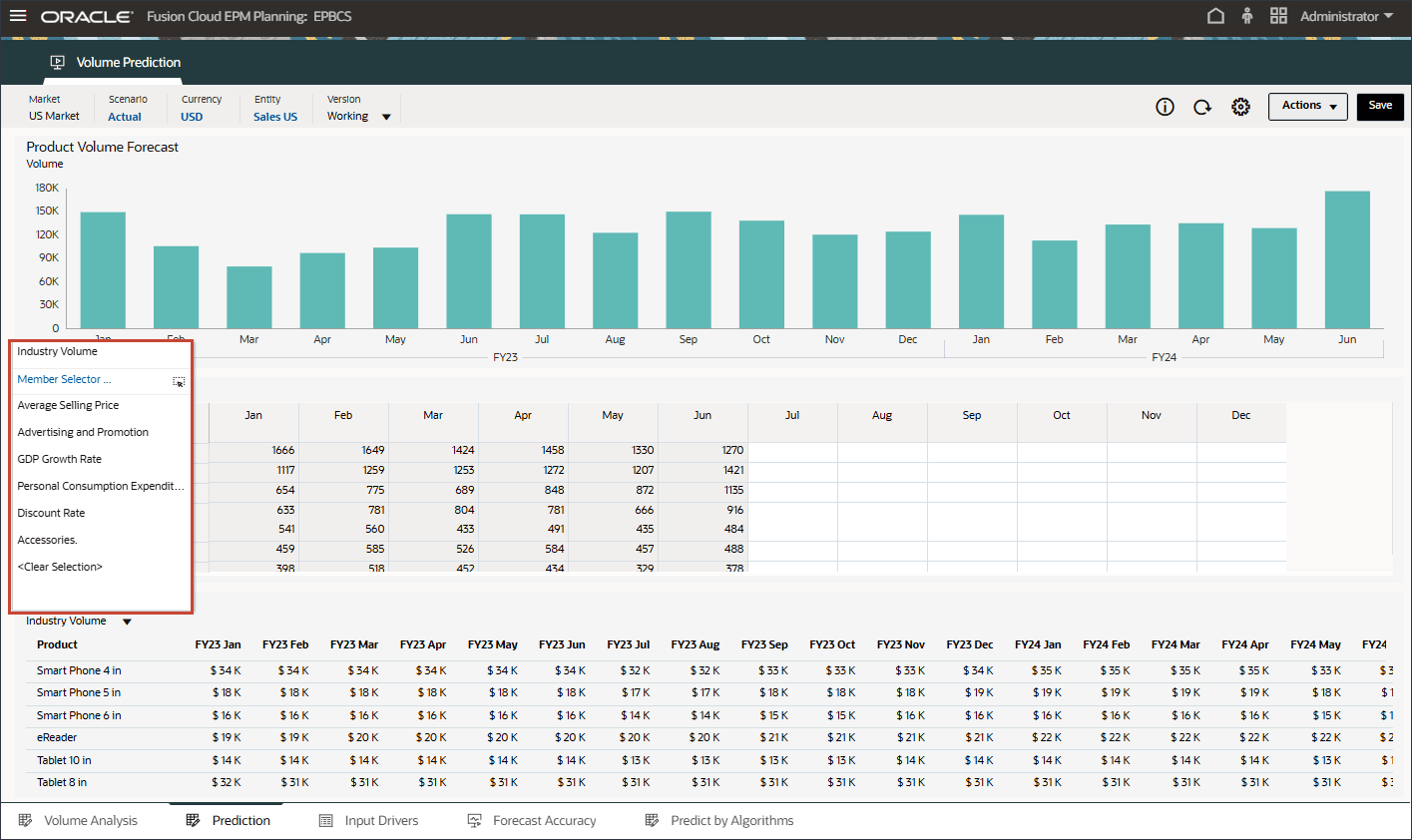
您可以选择几种驱动因素之一,包括平均销售价格、广告和促销以及折扣率。
- 在“驱动程序”网格中,单击
 (操作),然后选择最大化。
(操作),然后选择最大化。
- 查看行业卷的过去和未来数据的输入动因。
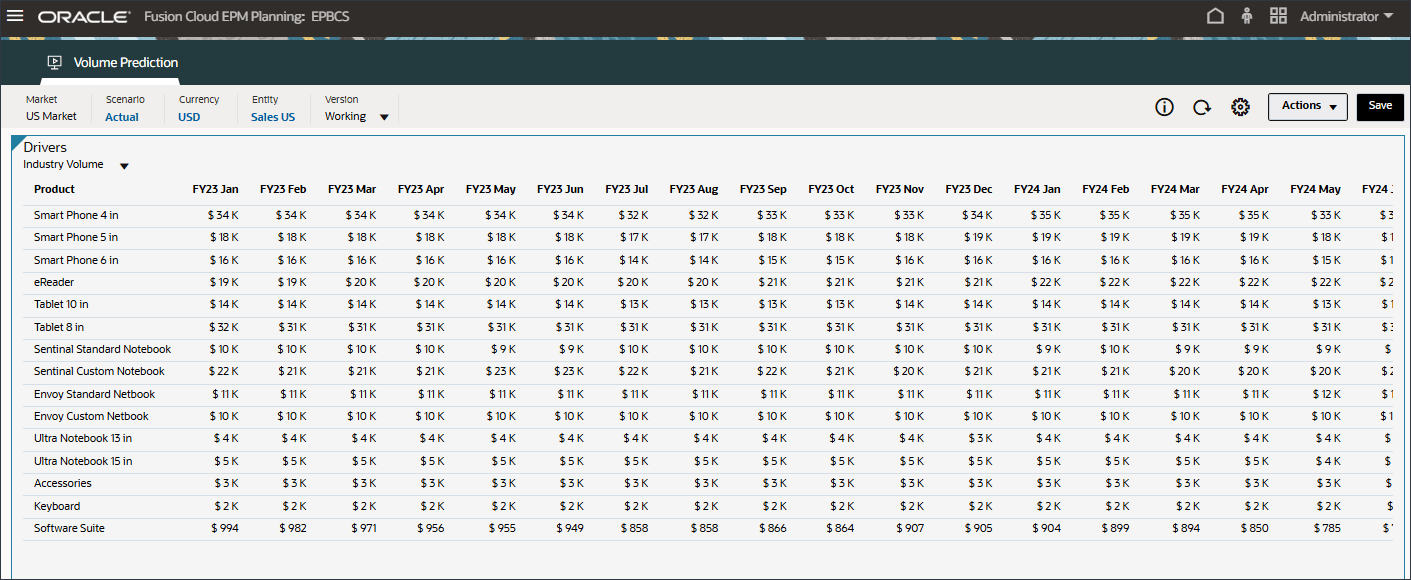
- 向右滚动以查看将来的值。
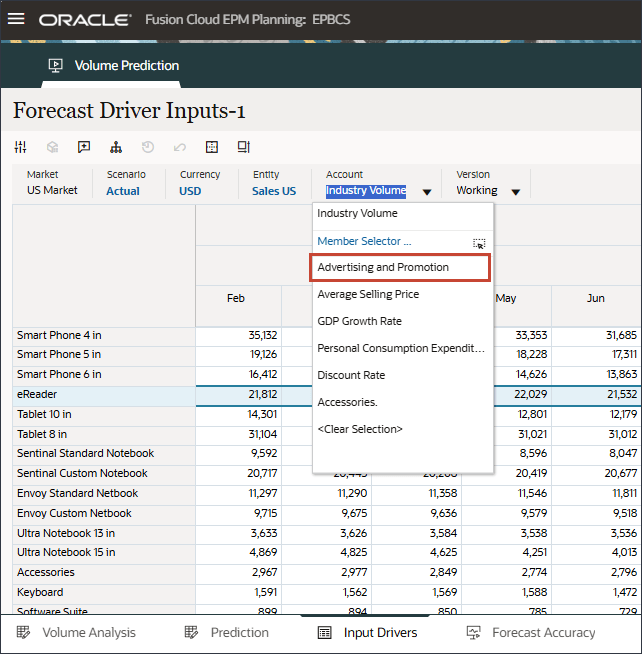
- 在“驱动程序”下拉列表中,单击行业数量,然后选择平均销售价格。
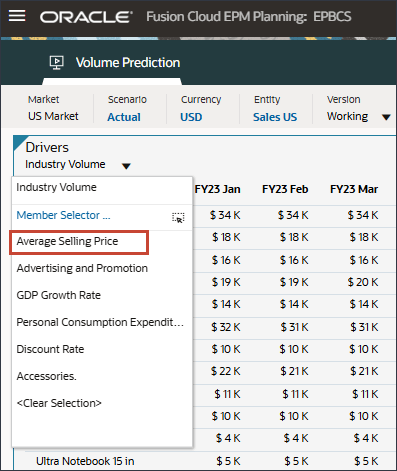
将显示平均销售价格的数据。
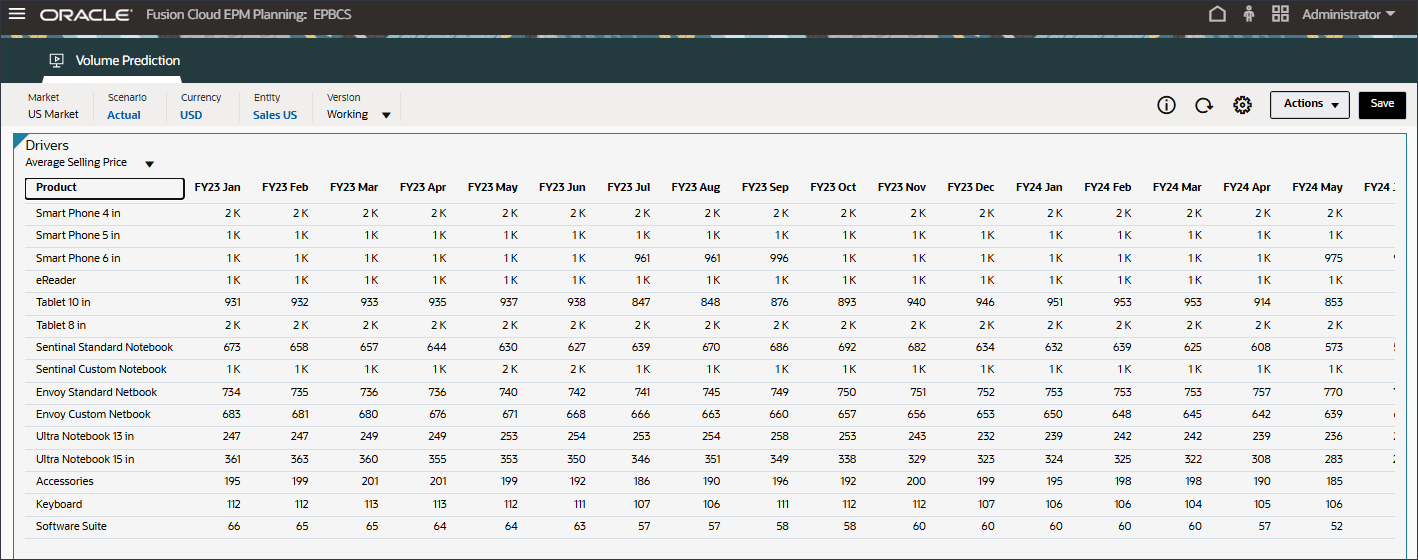
- 在“驱动程序”下拉列表中,单击平均销售价格,然后选择广告和促销。
将显示用于广告和推广的数据。
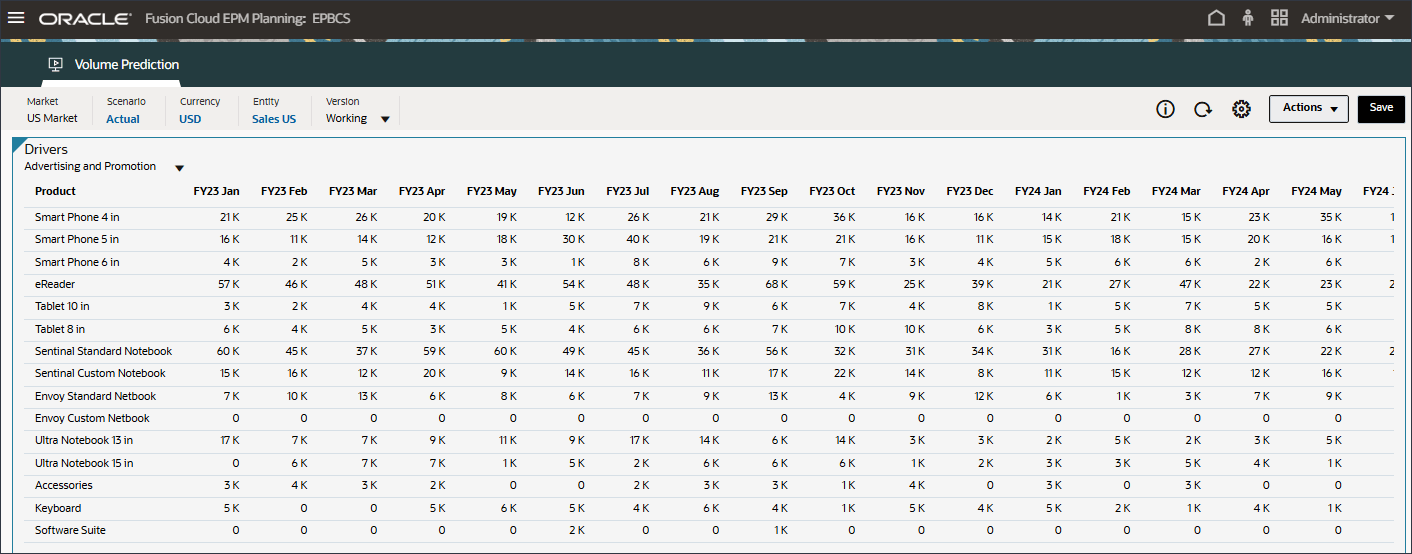
- 在“驱动程序”下拉列表中,单击广告和促销,然后选择 GDP 增长率。
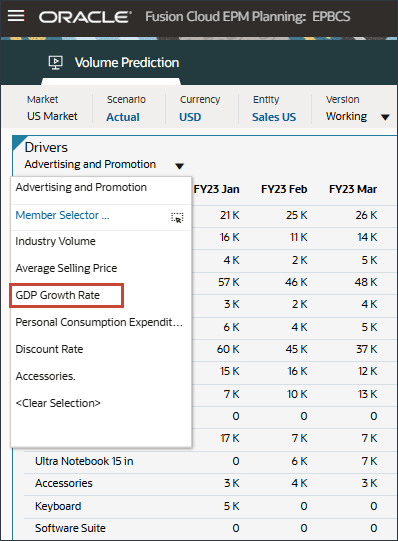
显示 GDP 增长率的数据。
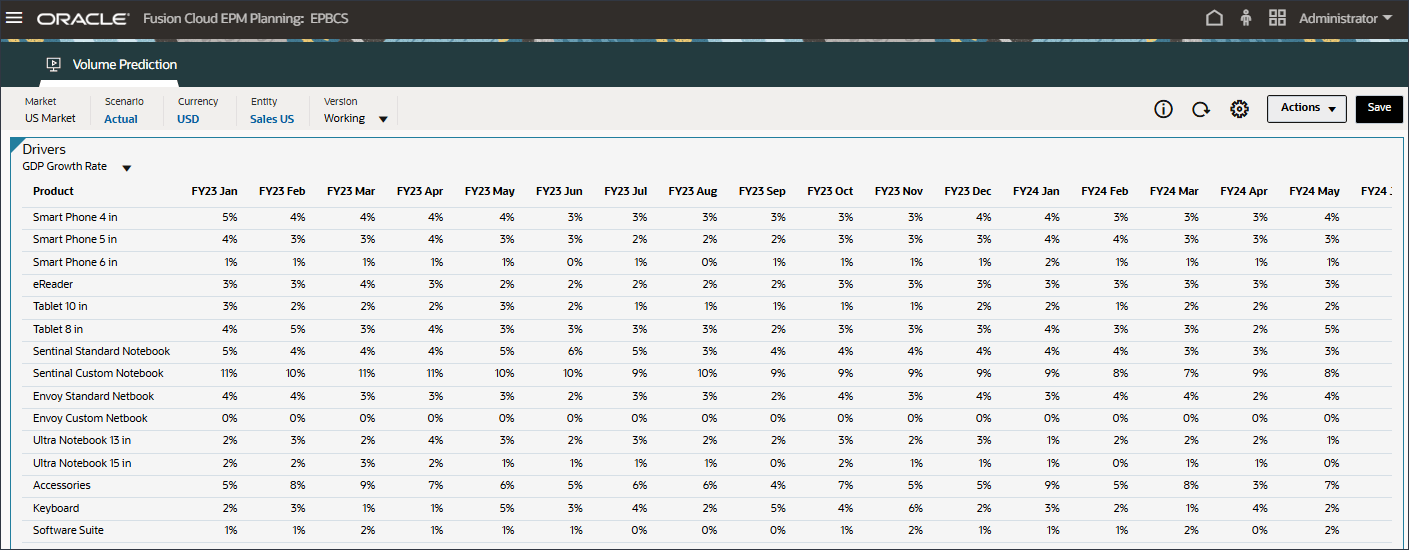
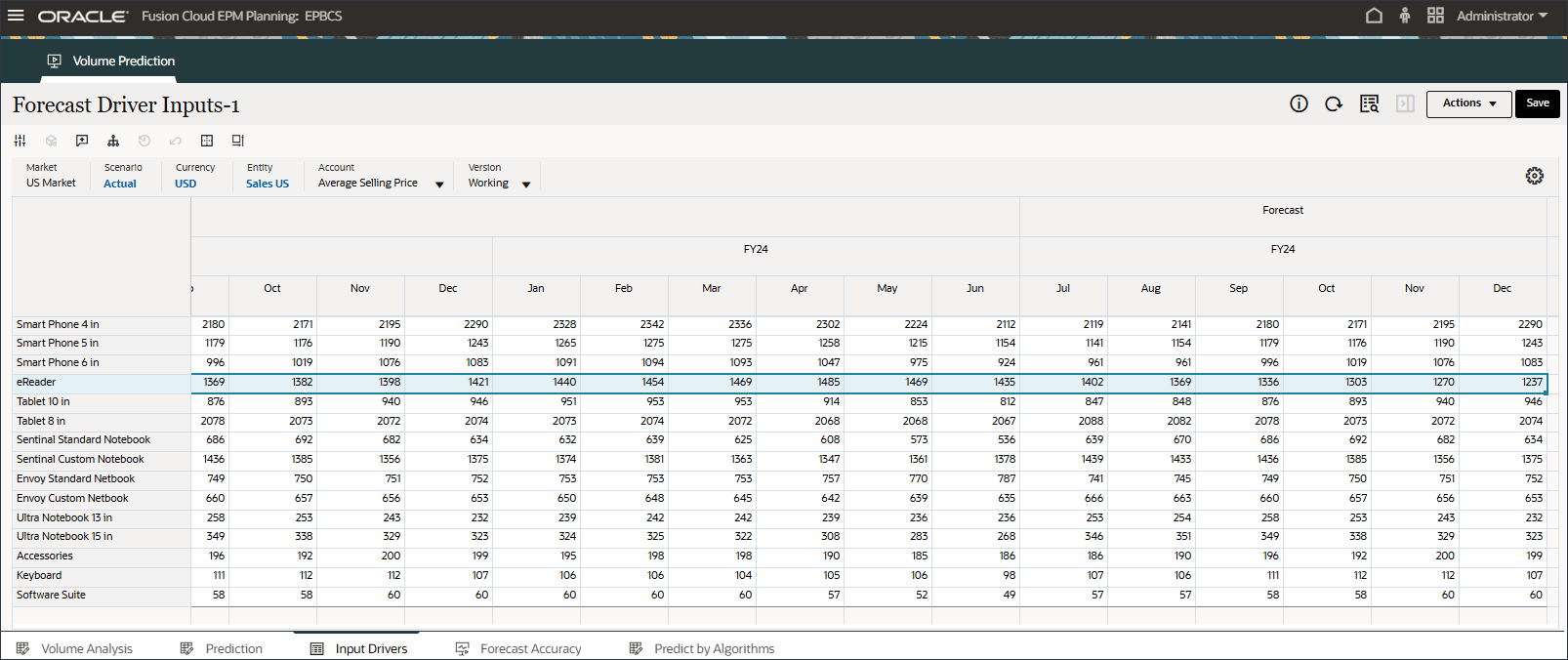
- 在“动因”下拉列表中,单击 GDP 增长率,然后选择个人消费支出(耐用品)。
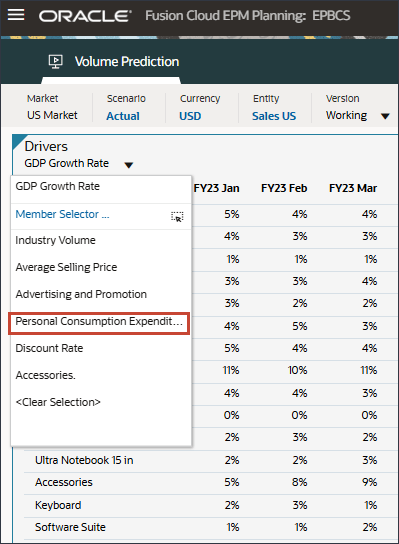
显示个人消费支出(耐用品)的数据。
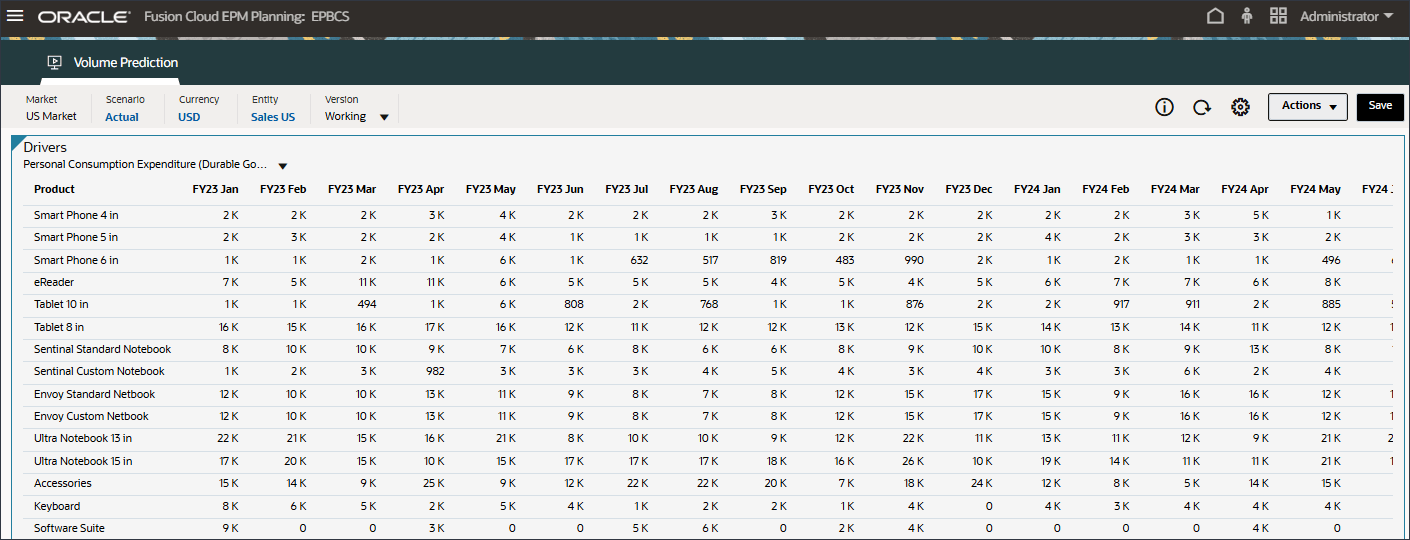
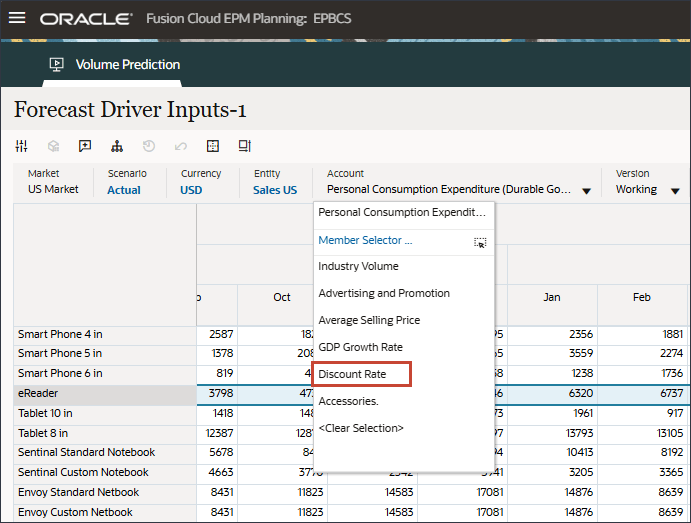
- 在“动因”下拉列表中,单击个人消耗量支出(耐用品),然后选择折扣率。
此时将显示折扣率数据。
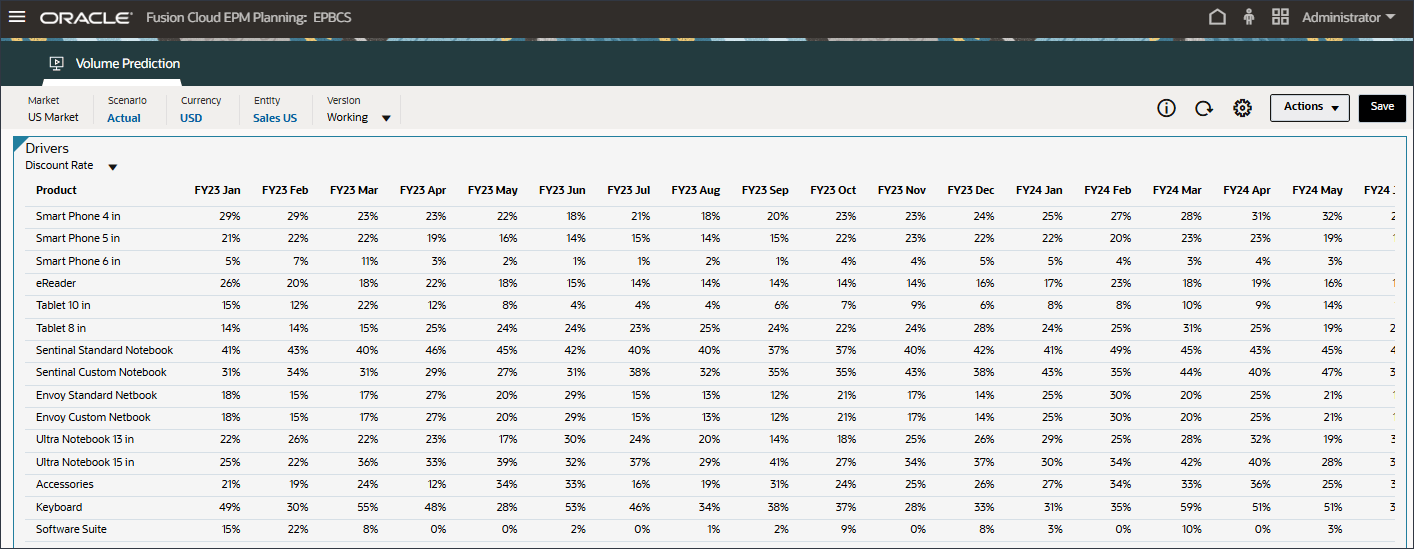
- 在页面底部,单击输入驱动程序选项卡。
此时将显示预测动因输入。
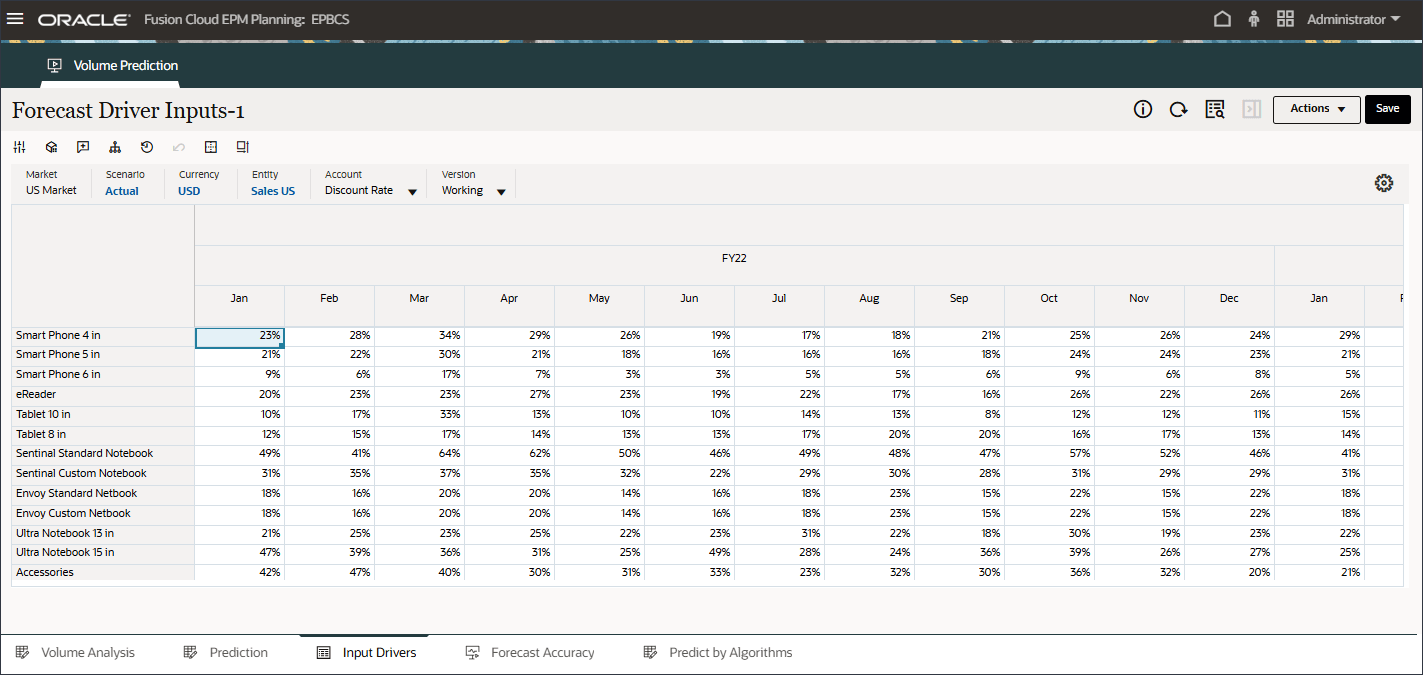
- 在“帐户”中,单击折扣率,然后选择行业数量。
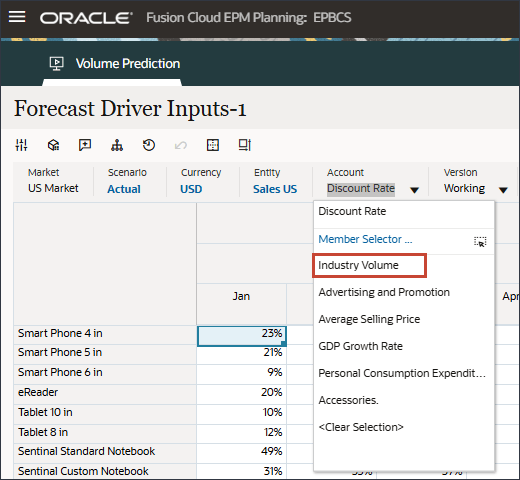
如果进行了更改,请单击 Save(保存)以保存更改。
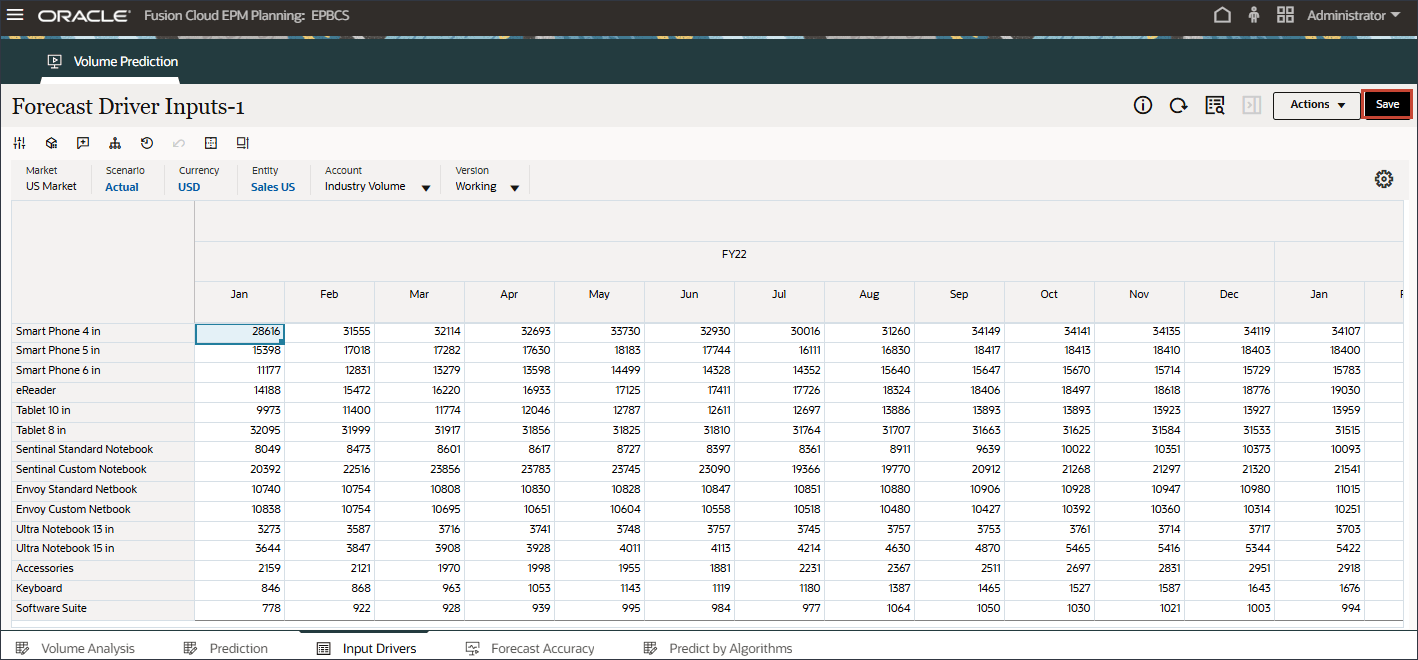
同样,您可以选择任何驱动程序并进行编辑。
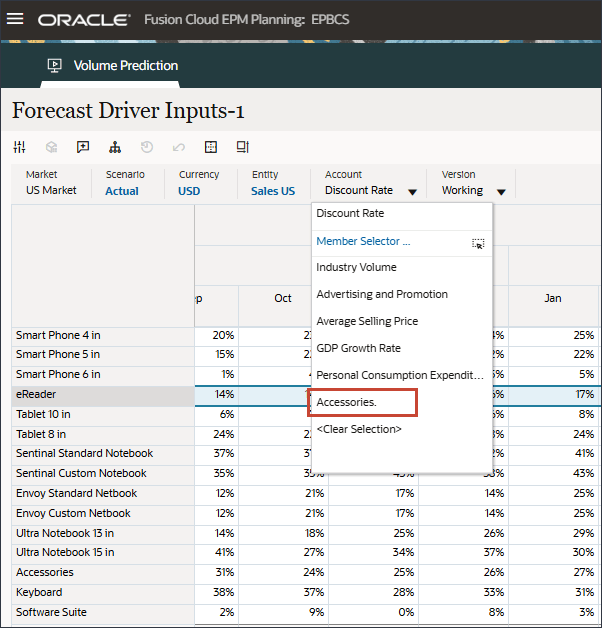
- 在“帐户”中,单击行业卷,然后选择附件。
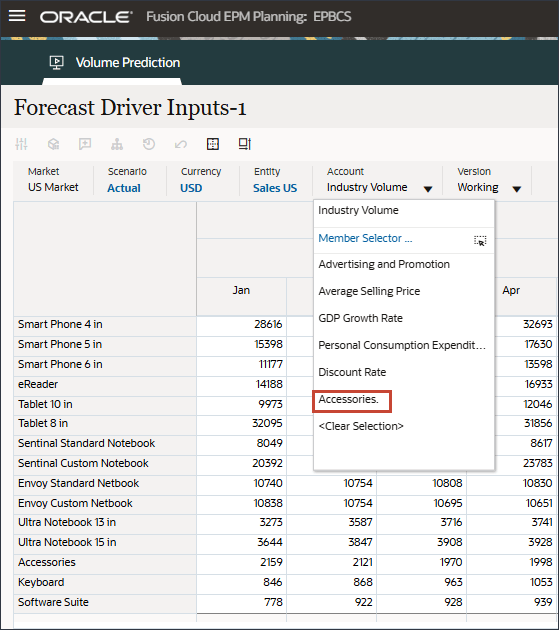
Accessories 驱动程序使用智能列表。在数据科学中,这称为分类变量。要计算将来的销售量,可以使用数值或智能列表值。在这种情况下,根据所选的智能列表值(带或不带附件),未来的销售量预测可能会受到影响。
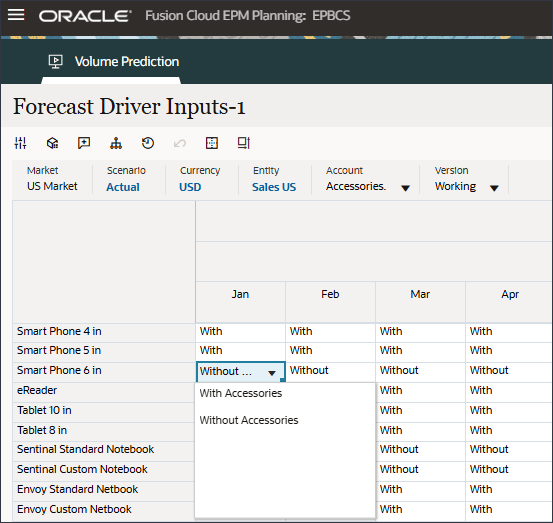
- 在“帐户”中,单击附件,然后选择行业卷。
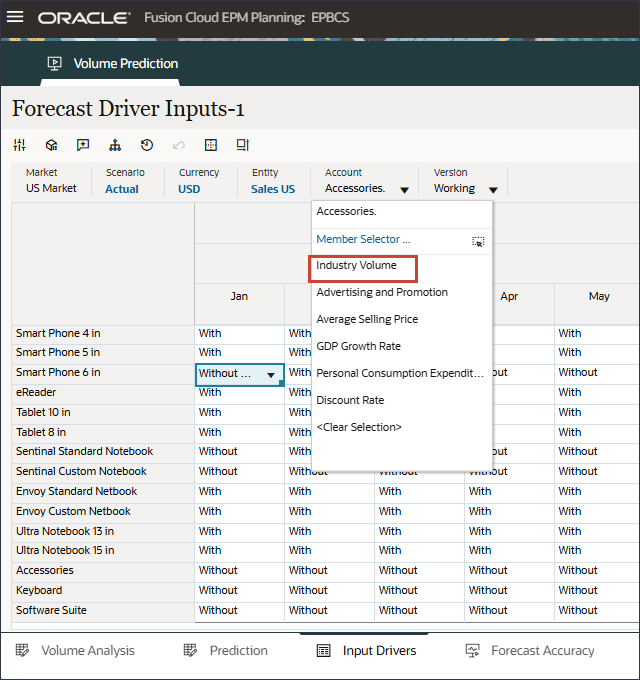
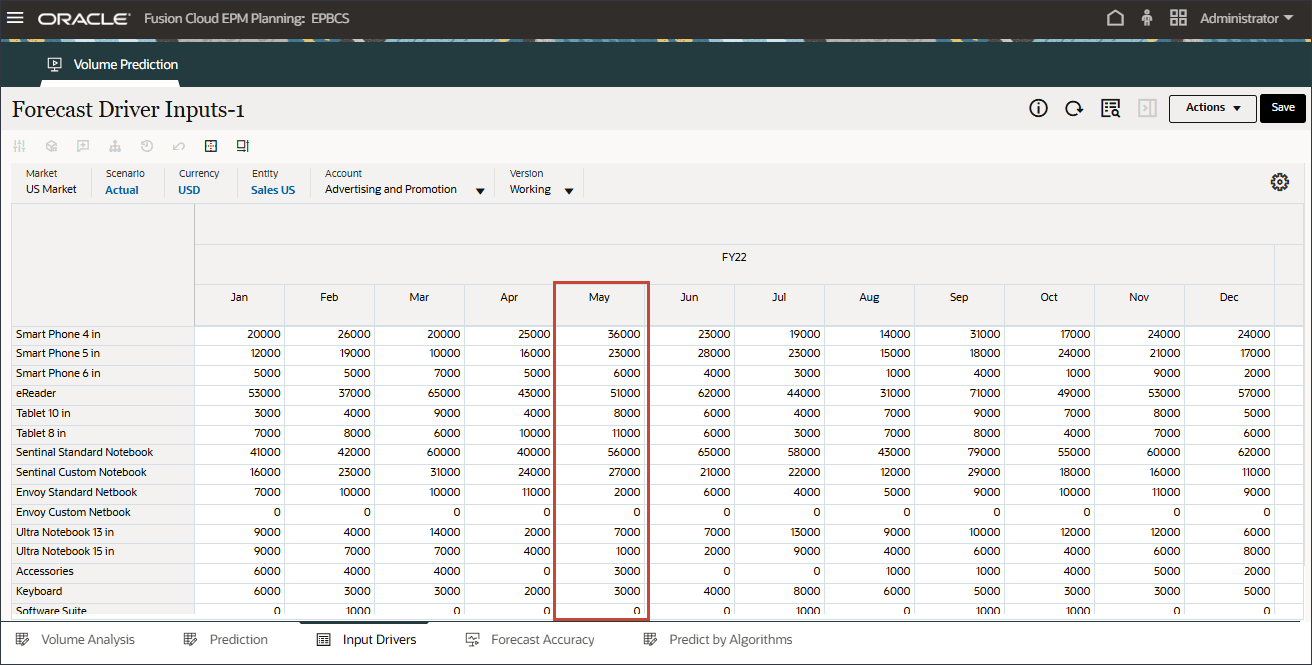
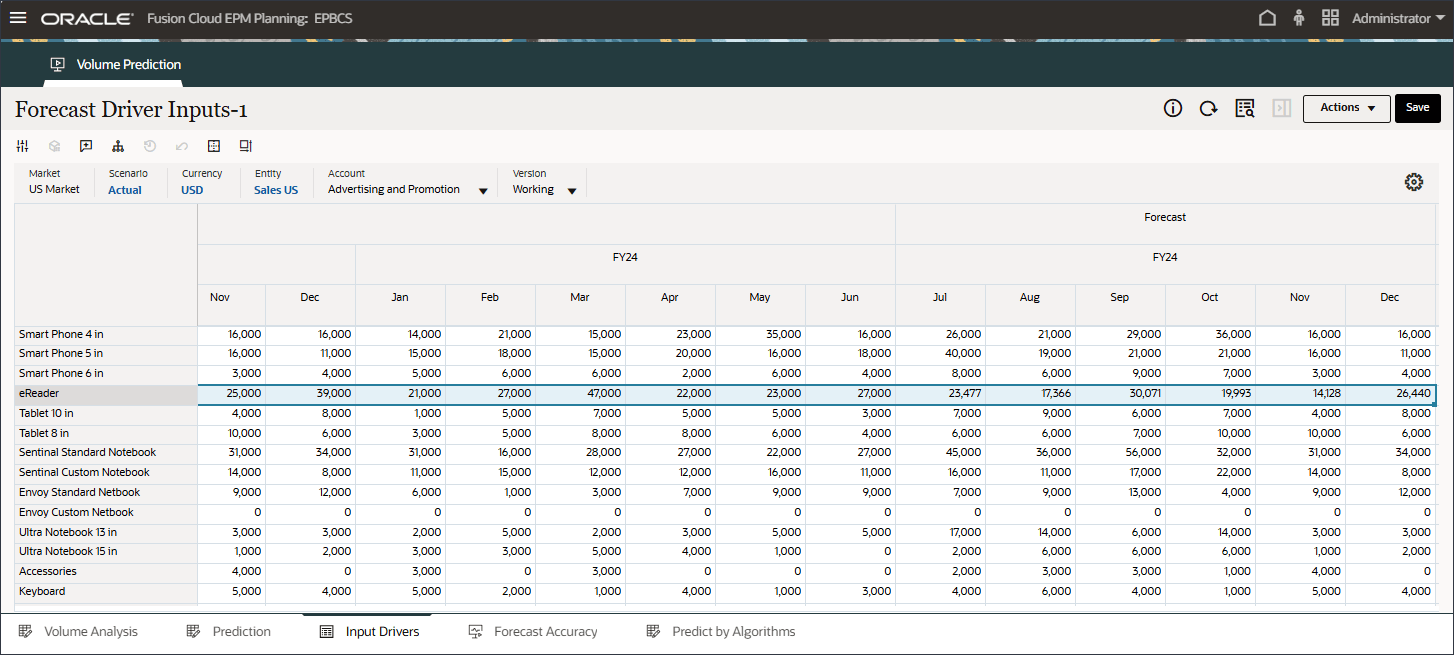
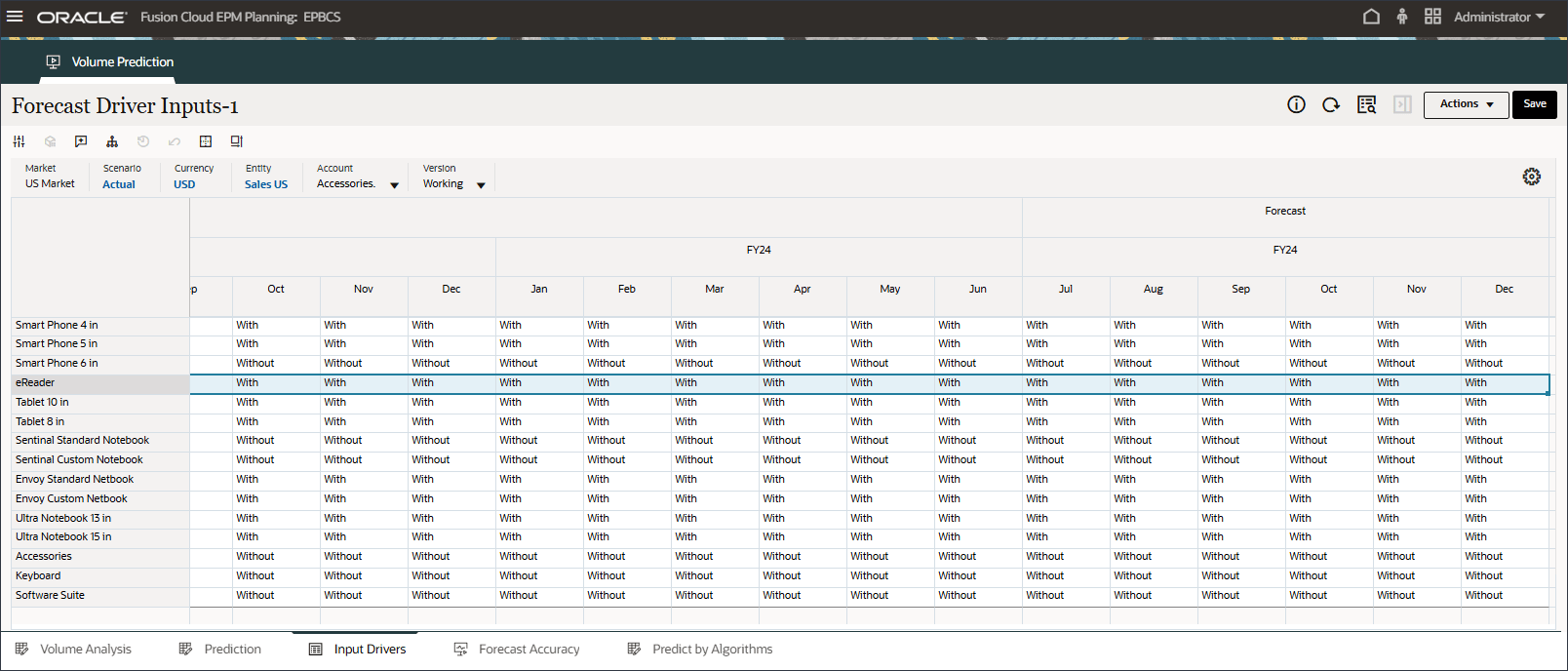
- 滚动到右侧,对于 eReader,对于“预测”,请注意 7 月至 12 月之间的行业量缺少值 FY24。
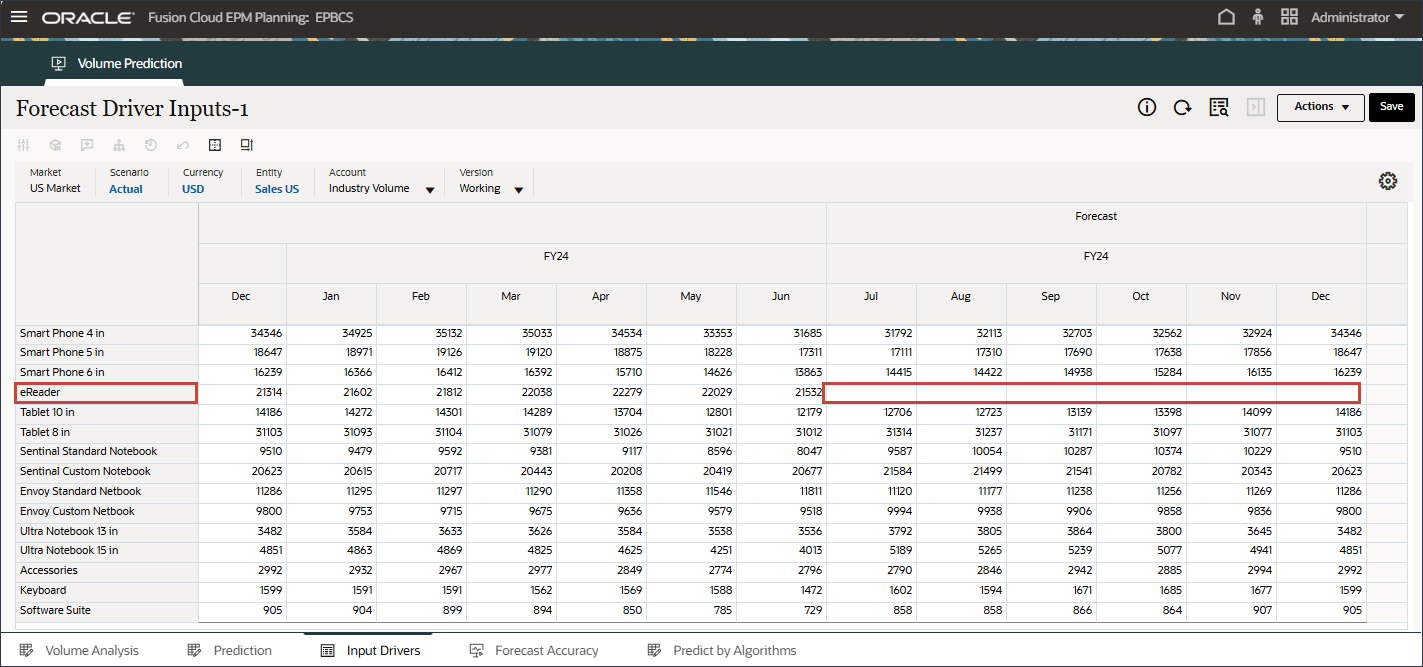
- 在“帐户”中,单击行业数量,然后选择广告和促销。
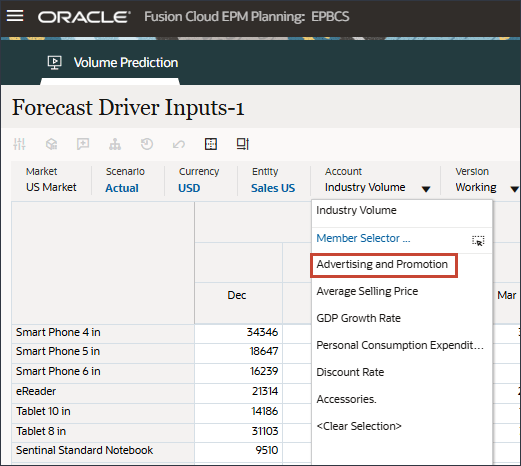
- 滚动到右侧,对于 eReader,对于预测,请注意 FY24 7 月至 12 月之间广告和促销缺少值。
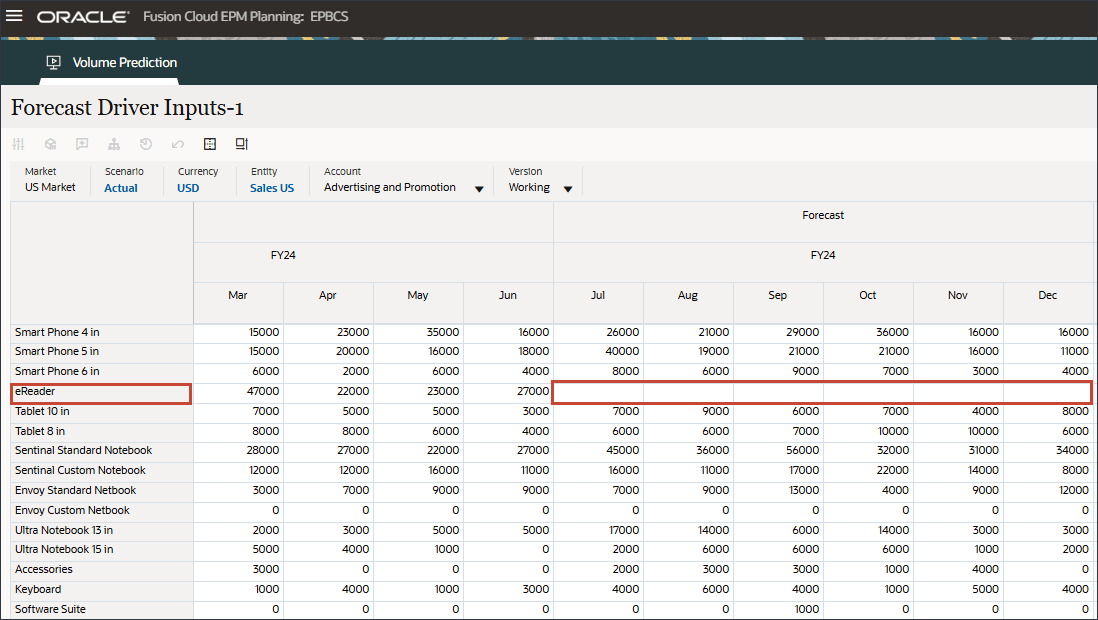
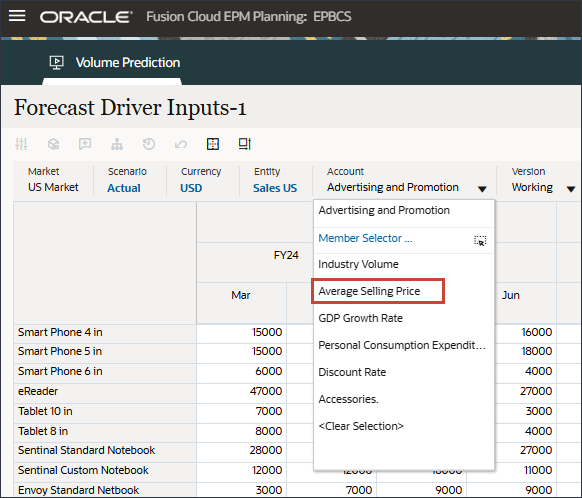
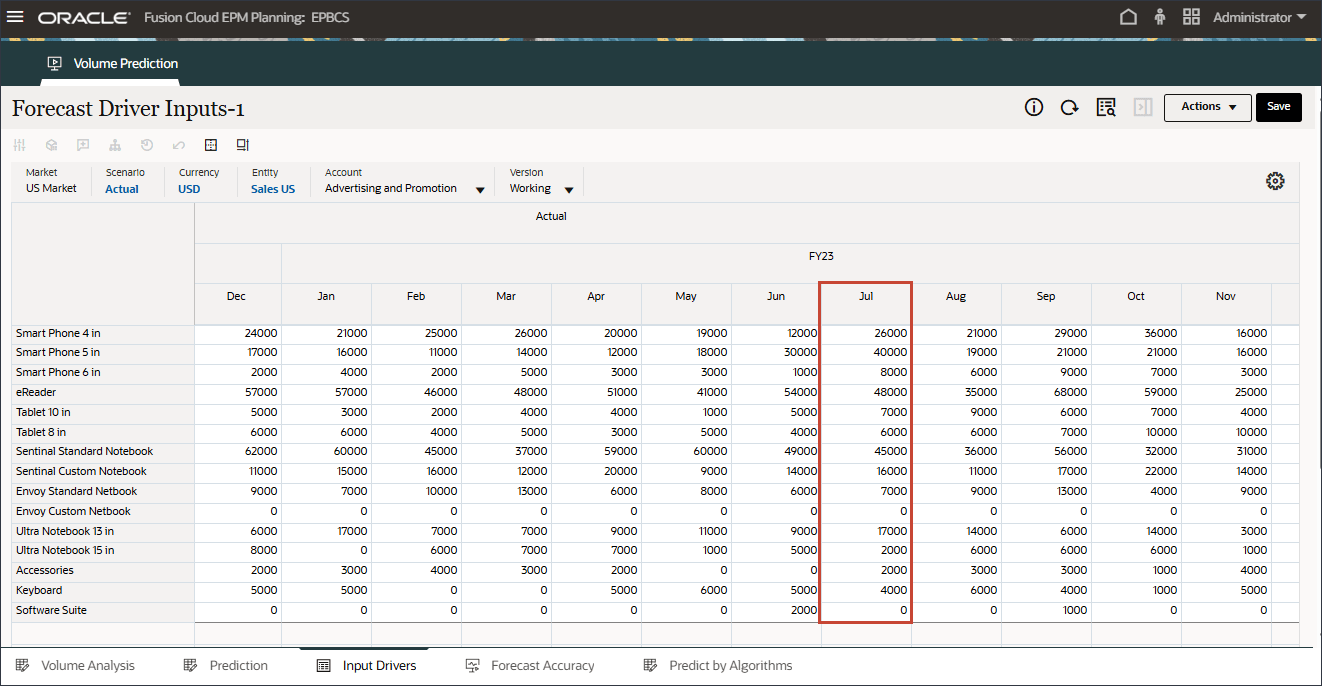
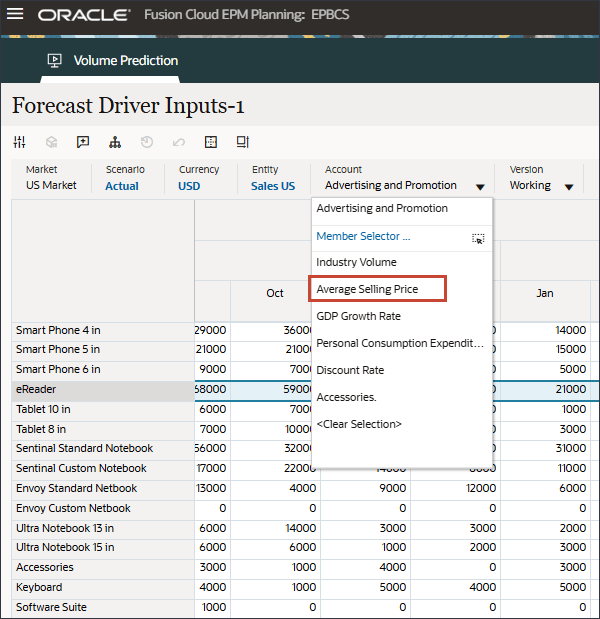
- 在“帐户”中,单击广告和促销,然后选择平均销售价格。
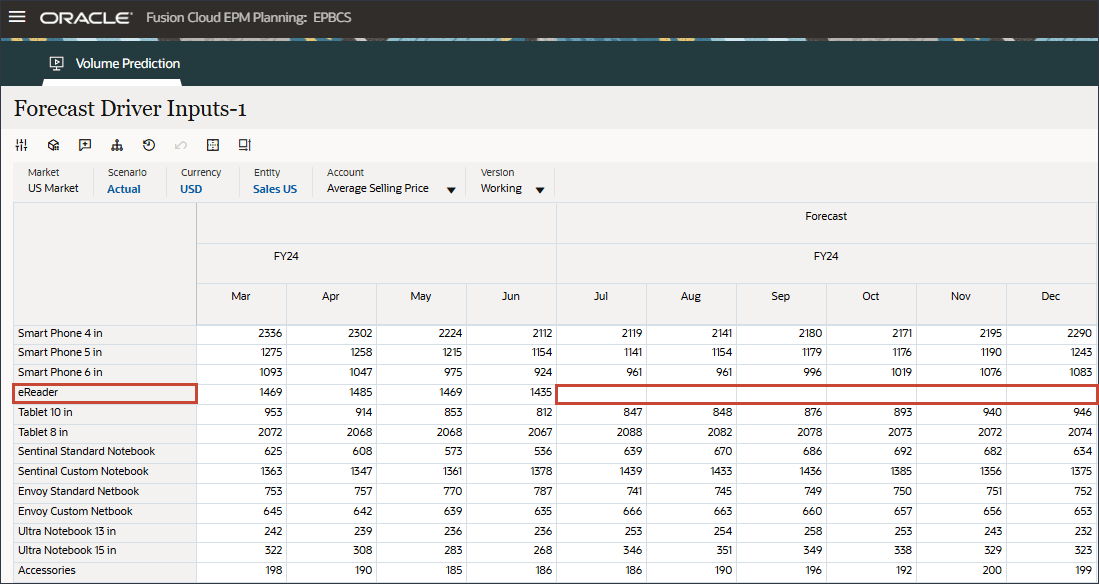
- 滚动到右侧,对于 eReader,对于预测,请注意 FY24 之间的 7 月至 12 月的平均销售价格缺少值。
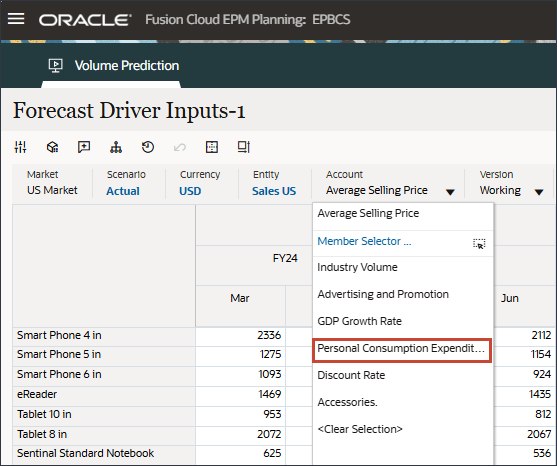
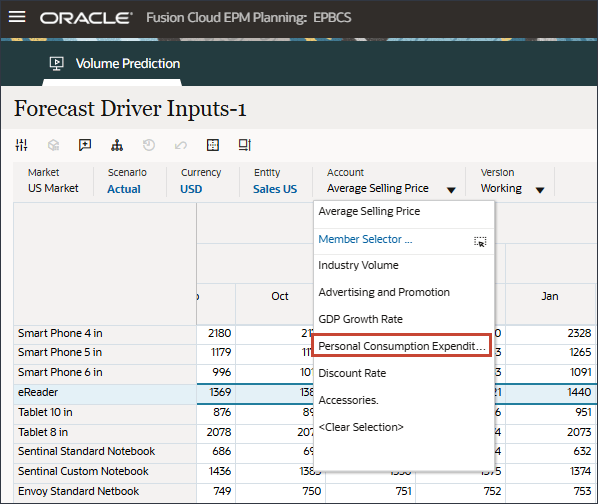
- 在“帐户”中,单击平均销售价格,然后选择个人消费支出(耐用品)。
- 滚动到右侧,对于 eReader,对于“预测”,请注意 FY24 之间的 7 月至 12 月个人消费支出(耐用品)缺少值。
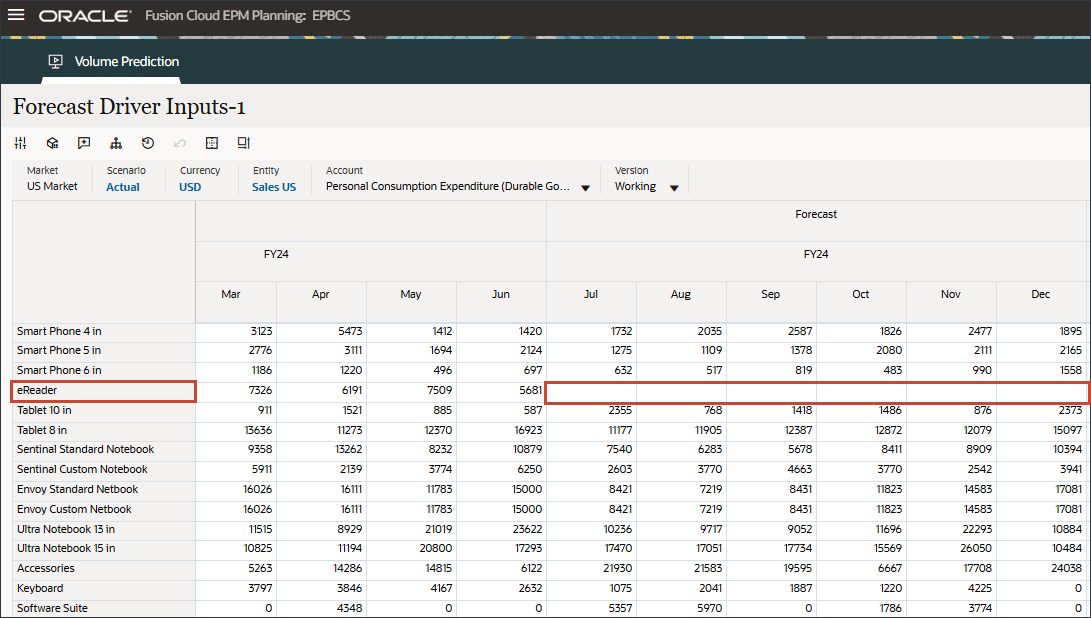
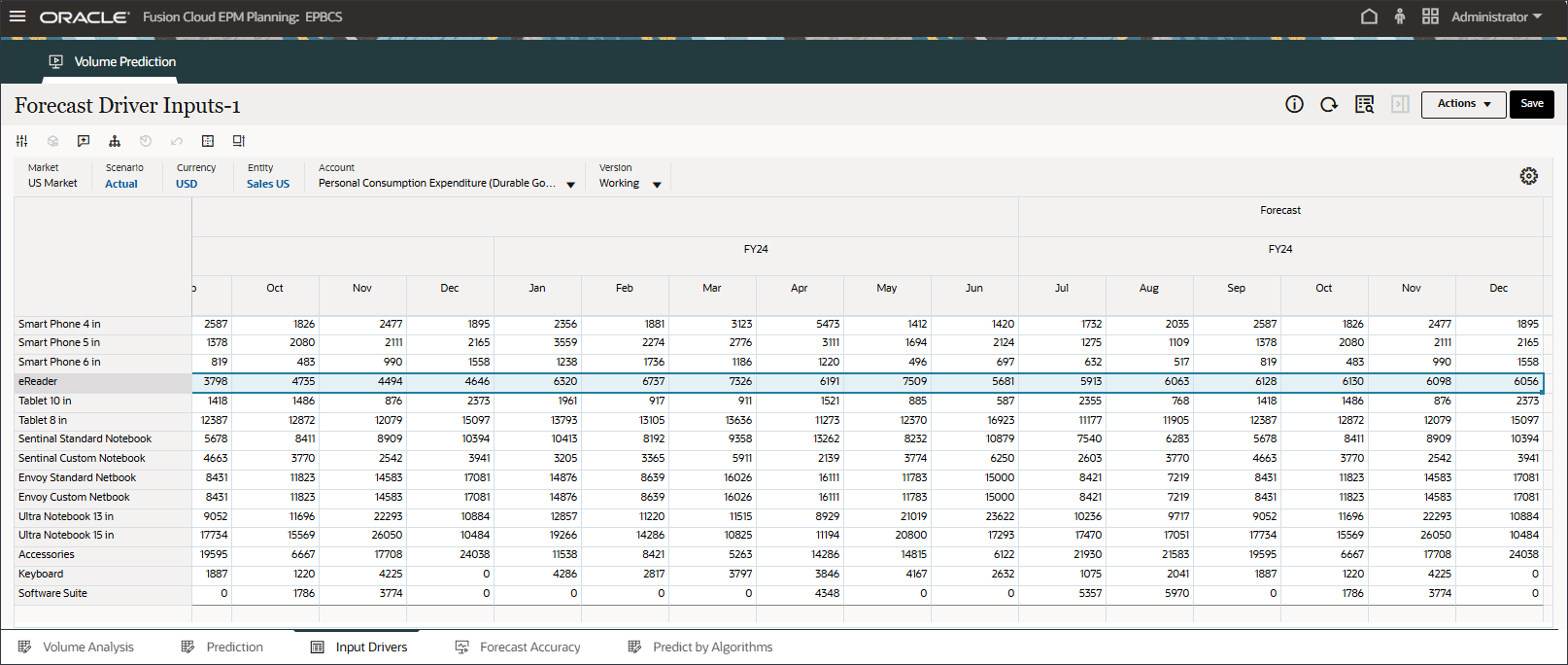
- 在“帐户”中,单击个人消耗量支出(耐用品),然后选择折扣率。
- 滚动到右侧,对于 eReader,对于“预测”,请注意 7 月至 12 月之间的折扣率缺少值 FY24。
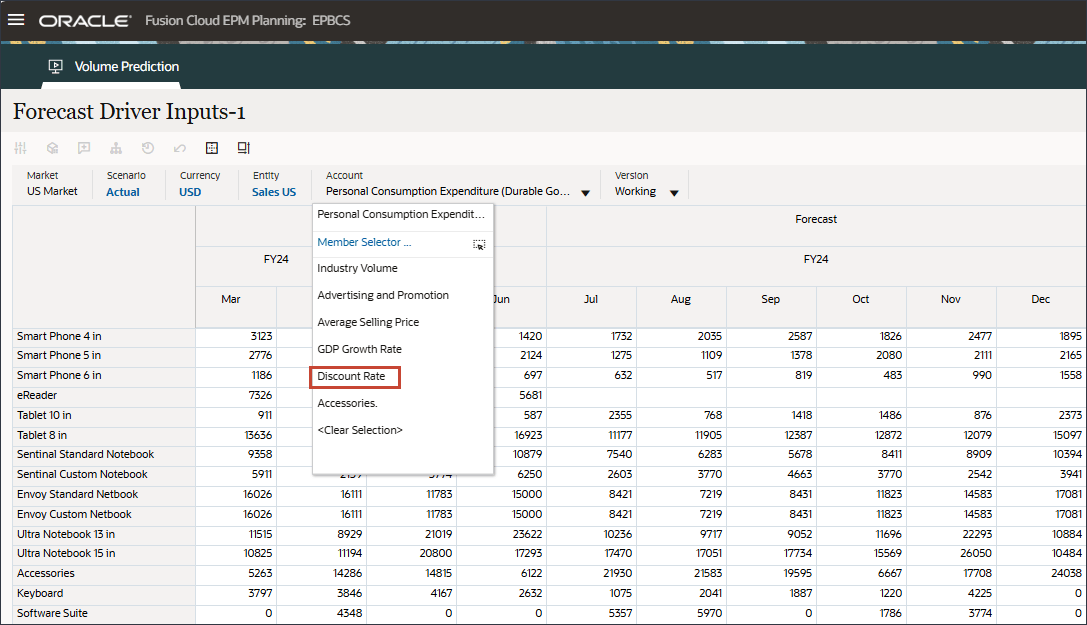
- 在“帐户”中,单击折扣率,然后选择附件。
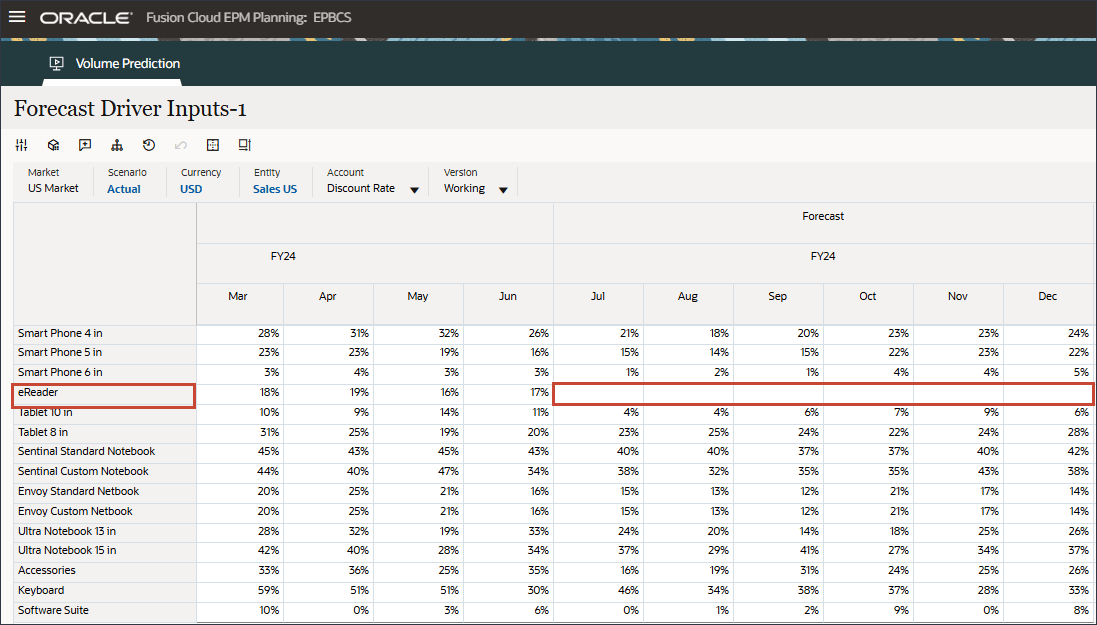
- 滚动到右侧,对于 eReader,对于“预测”,请注意 7 月至 12 月 FY24 之间的附件缺少值。
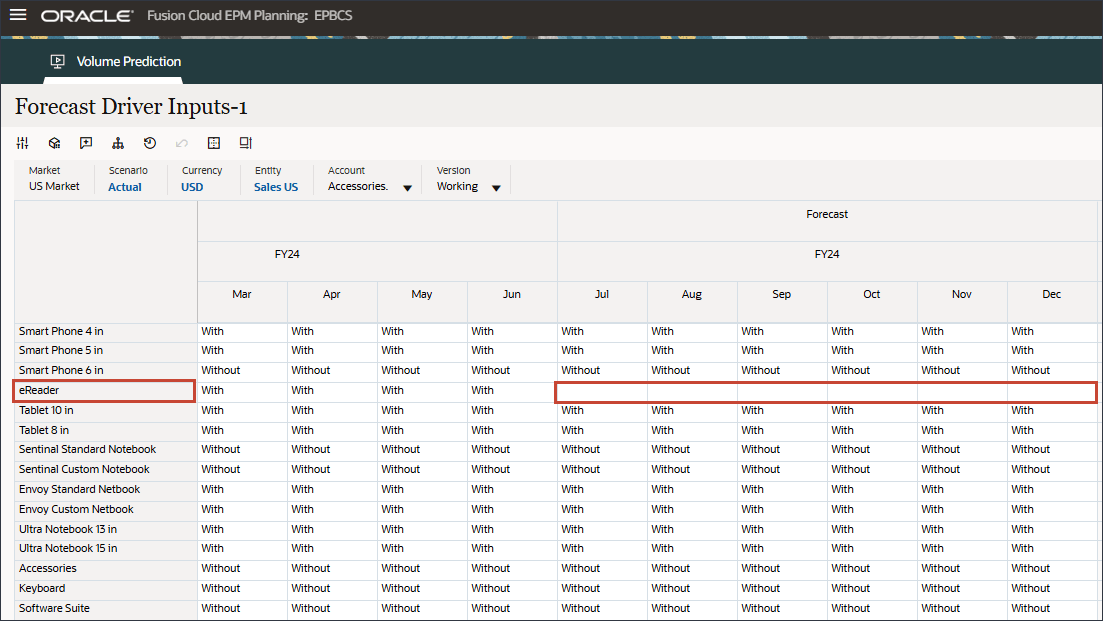
高级预测可以预测缺少输入动因值。在本教程的后面部分中,您将配置高级预测作业以确保预测 eReader 的未来输入动因值。
- 在底部,单击预测选项卡。
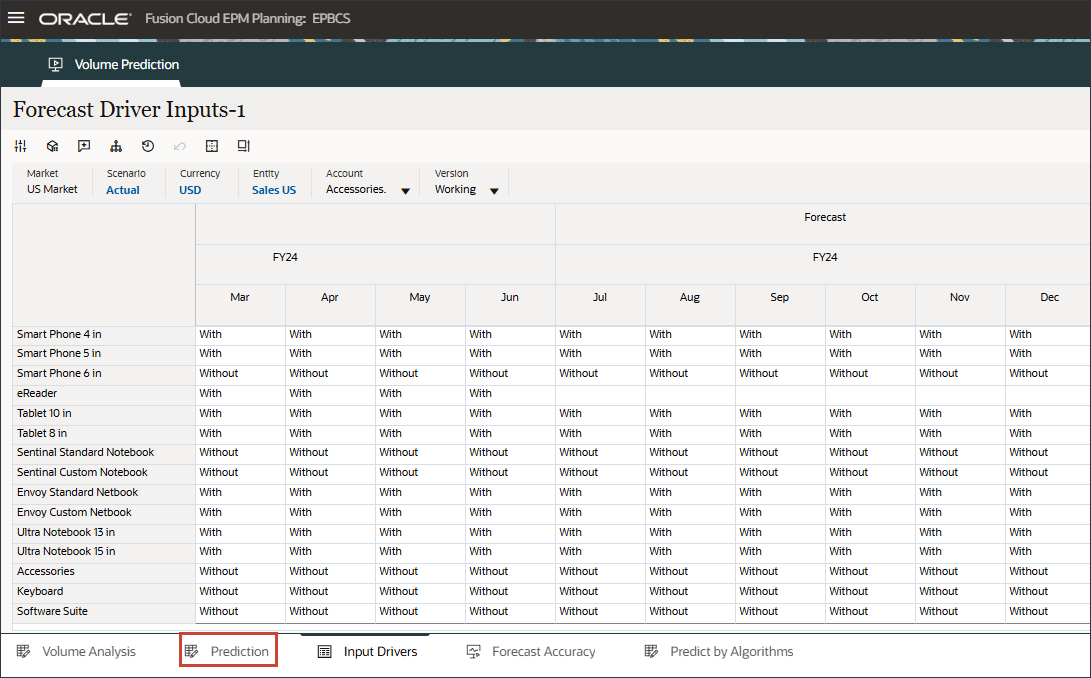
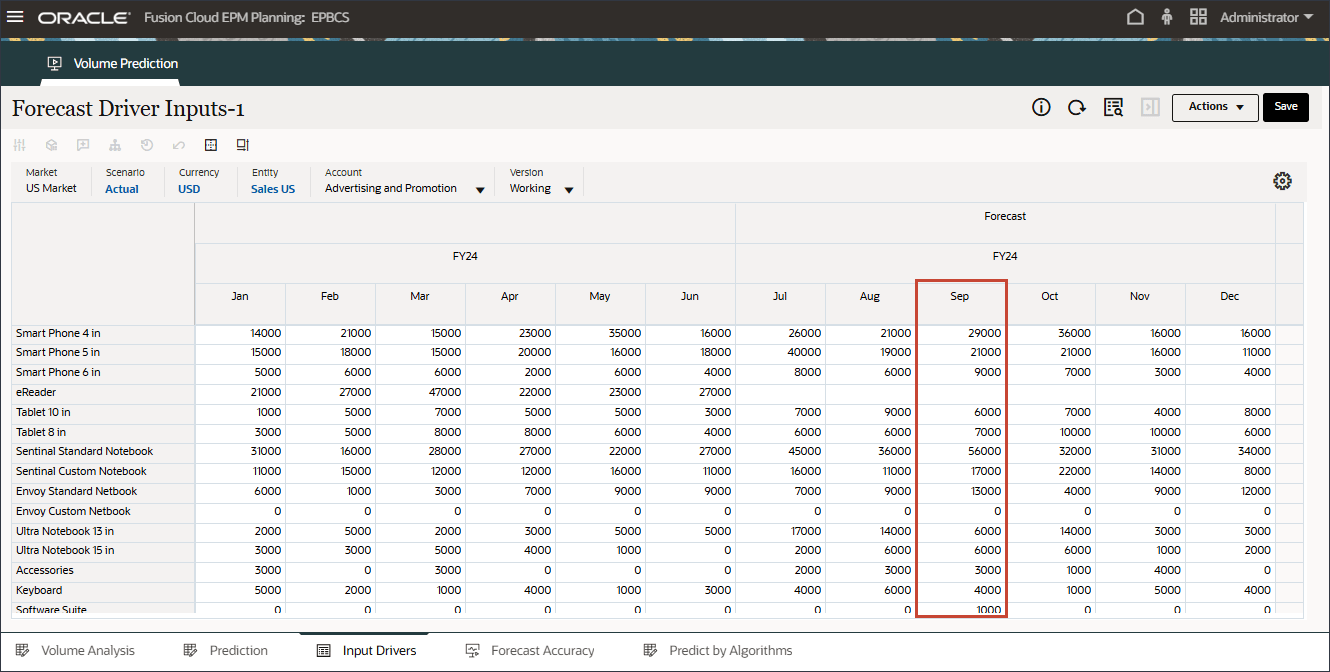
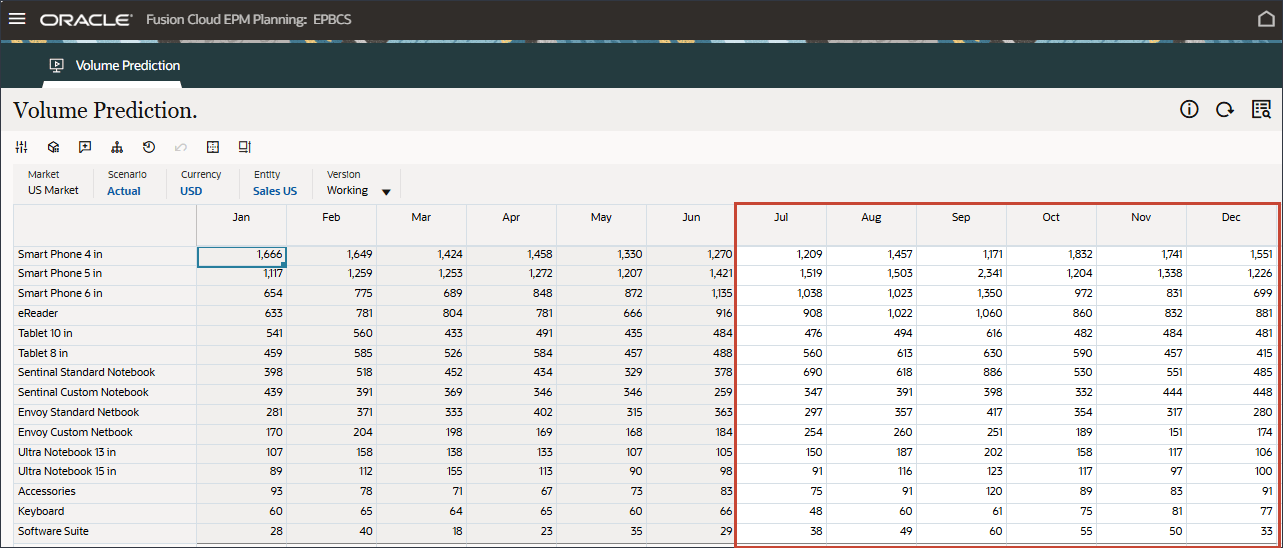
- 在“卷预测”表单的右侧,单击 (操作),然后选择打开表单。
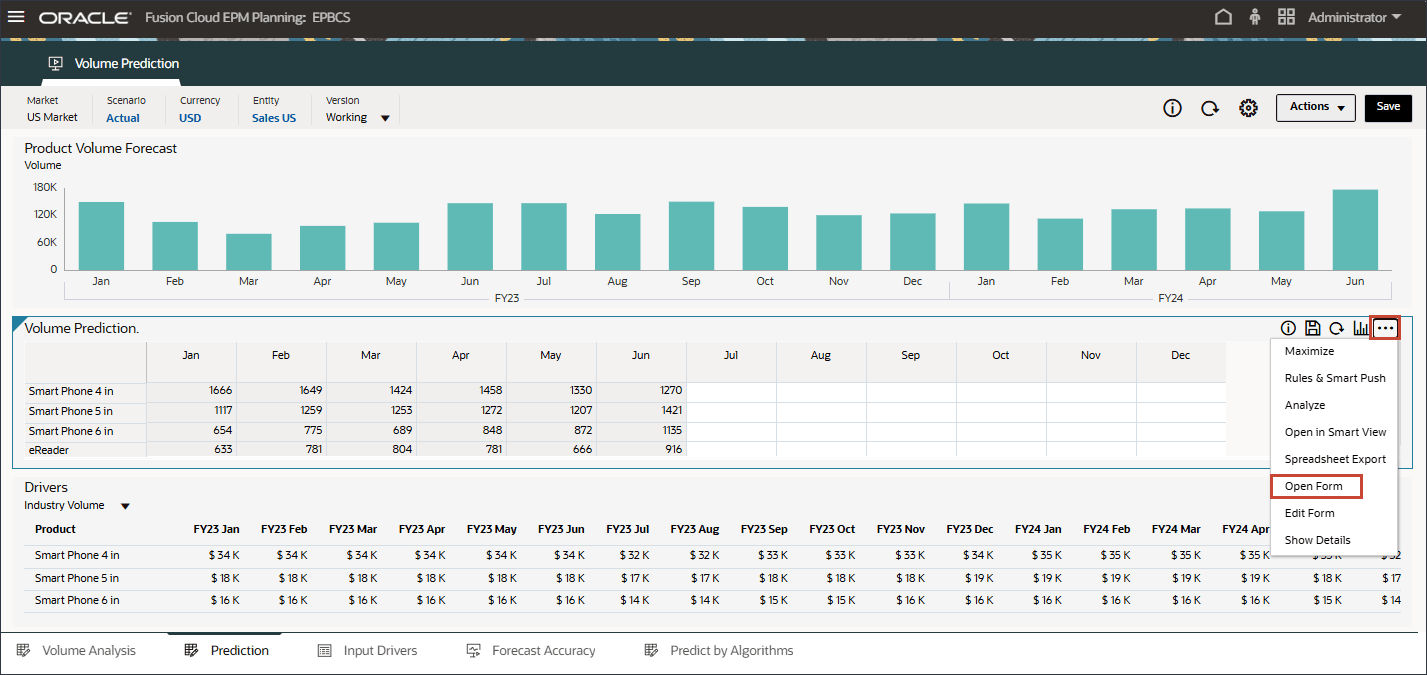
- 请注意,7 月至 12 月期间缺少预测结果 FY24。
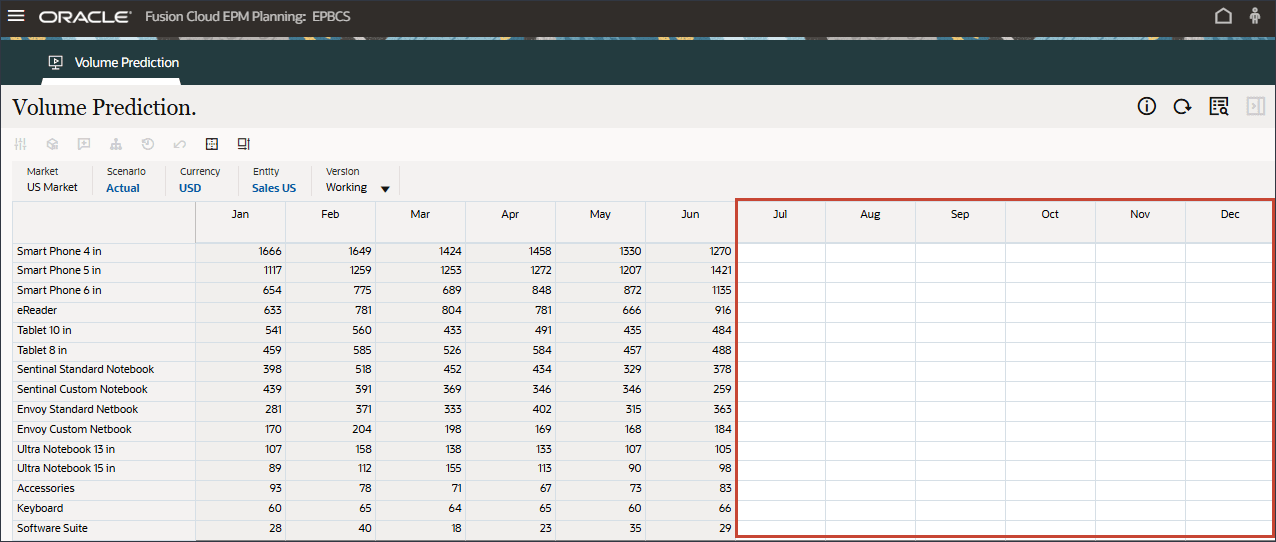
这些是我们希望使用高级预测功能对所有产品进行预测的时期。
- 单击 (主页)以返回到主页。
“预测”选项卡显示仪表盘,其中包含计划预测的量,并且还包含包含将用于预测量的所有动因的表。
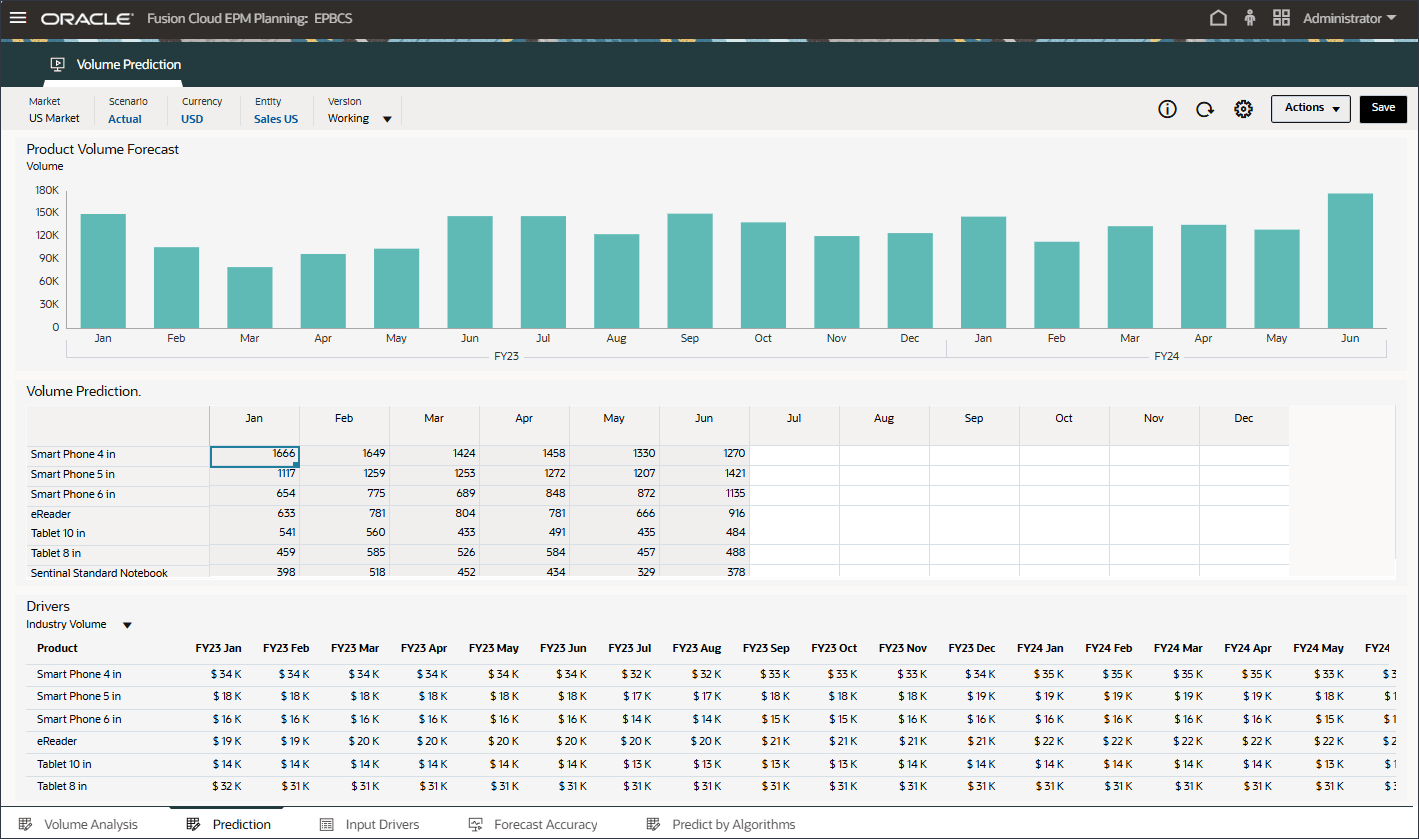
这些输入驱动程序有助于使用高级预测算法准确推导卷预测。
编辑输入驱动程序
您可以编辑任何输入驱动程序。您可以编辑历史数据和未来数据。
检查将来期间缺少的输入动因值
在此部分中,您将检查缺少的输入驱动程序。
查看预测表单
在此部分中,您将查看“批量预测”表单中缺少的值。
配置高级预测
在此部分中,您将配置“高级预测”以预测将来的产品数量。
完成 IPM 配置向导中的步骤以配置高级预测。
设置高级预测日历
在配置高级预测之前,必须定义包括历史期间和未来期间的日历。
- 在主页上,依次单击 IPM 和配置。
- 在底部,单击日历选项卡。
- 单击添加日历。
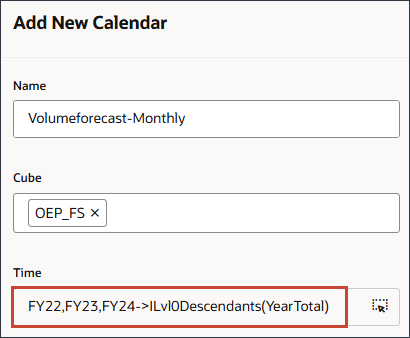
- 在“名称和说明”中,输入 Volumeforecast-Monthly 。
为新日历输入名称和说明。
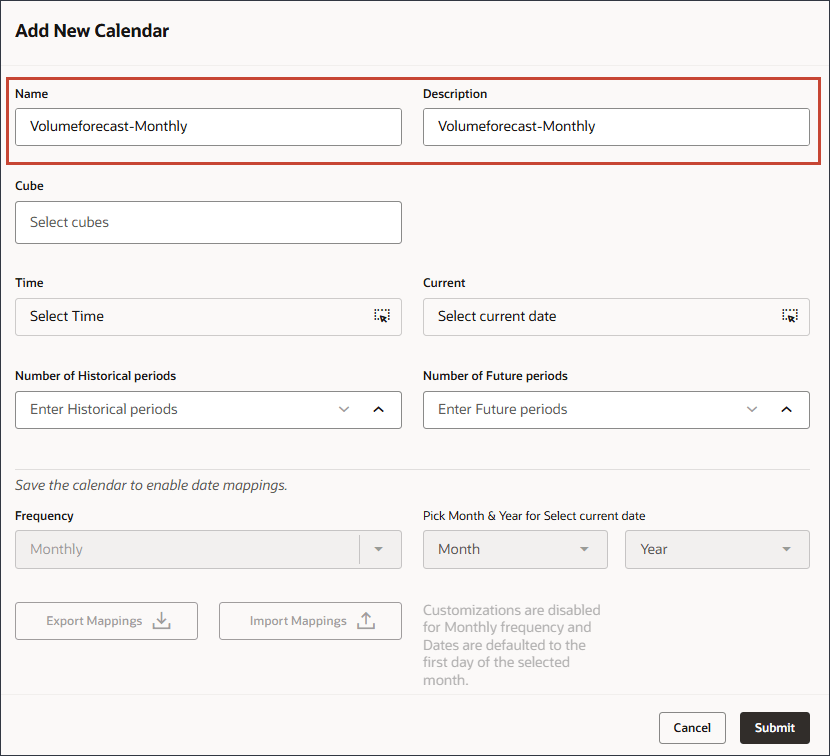
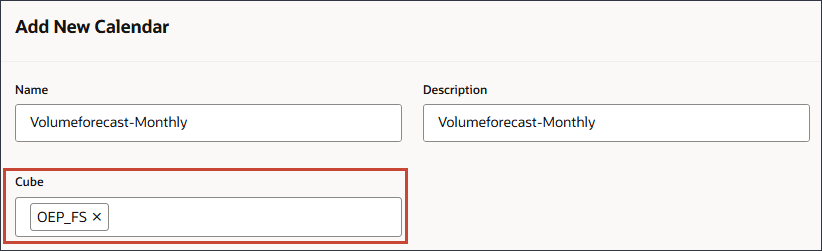
- 对于多维数据集,选择 OEP_FS 。
- 对于时间,请单击
 (选择时间)。
(选择时间)。
- 在“选择成员”、“年份”和“全年”中,选择 FY22 、FY23 和 FY24 。
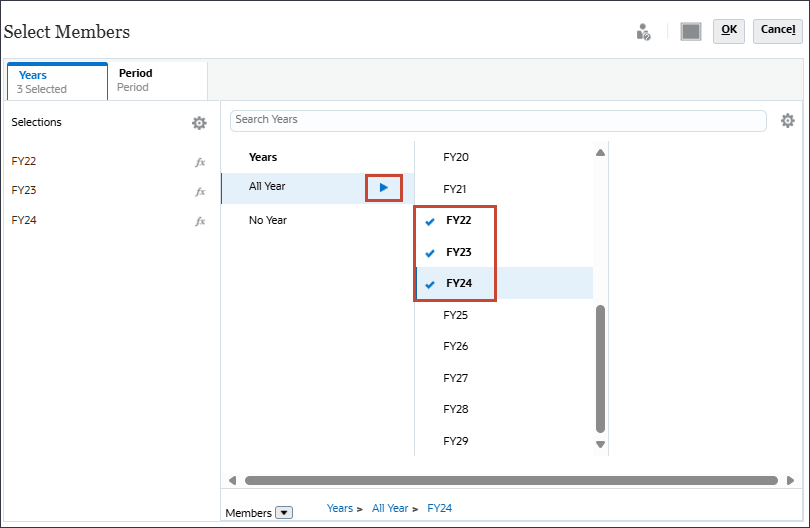
对于时间,您可以包括预测所需的全部历史期间和未来期间。
- 单击期间。
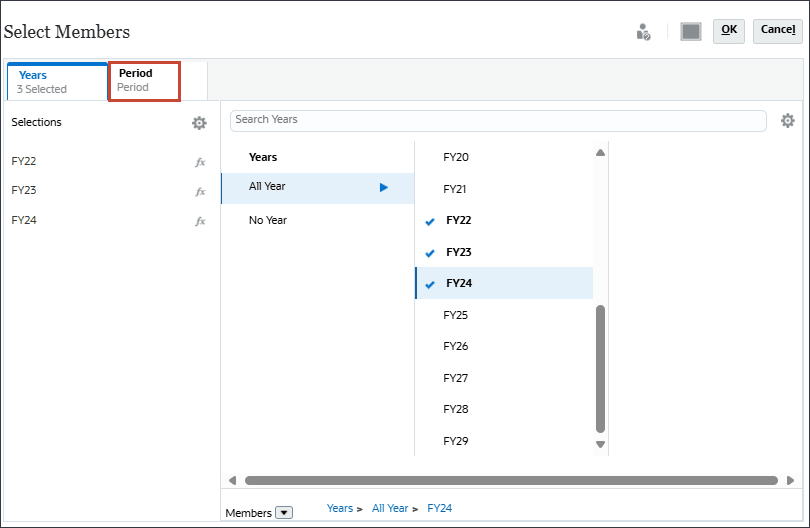
- 对于 YearTotal ,选择
 (函数选择器),然后选择 Level 0 Descendants 。
(函数选择器),然后选择 Level 0 Descendants 。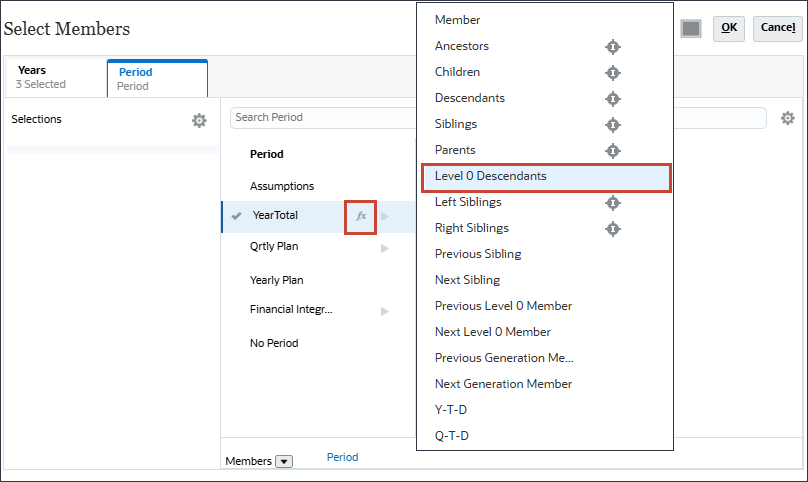
此时将显示所选内容。
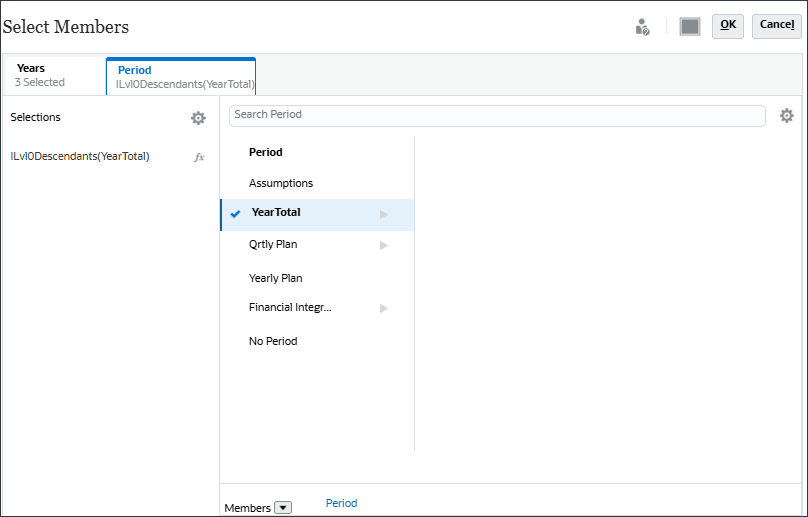
对于期间,您可以包括要使用数据的起始历史期间。对于您想要预测的未来,您可以为要预测的未来数据包括多少年。在此示例中,您选择了年份 -FY22、FY23 和 FY24 以及句点 -YearTotal 的所有级别 0 的后代(所有月份)。
- 单击确定。
日历中包括年份和期间选择。
- 在“当前”中,单击 (选择当前日期)。
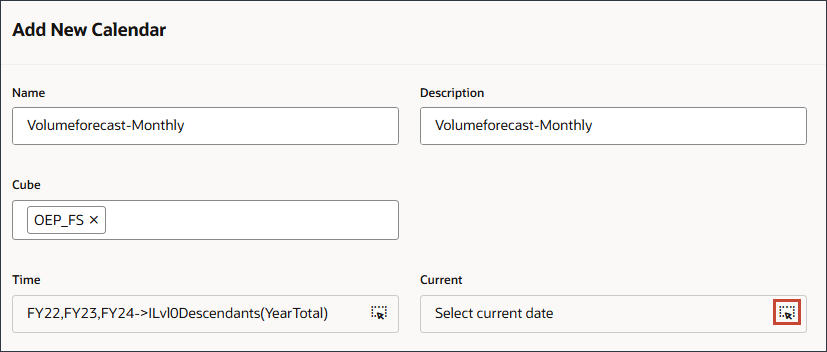
- 对于“年”,选择 FY24 。
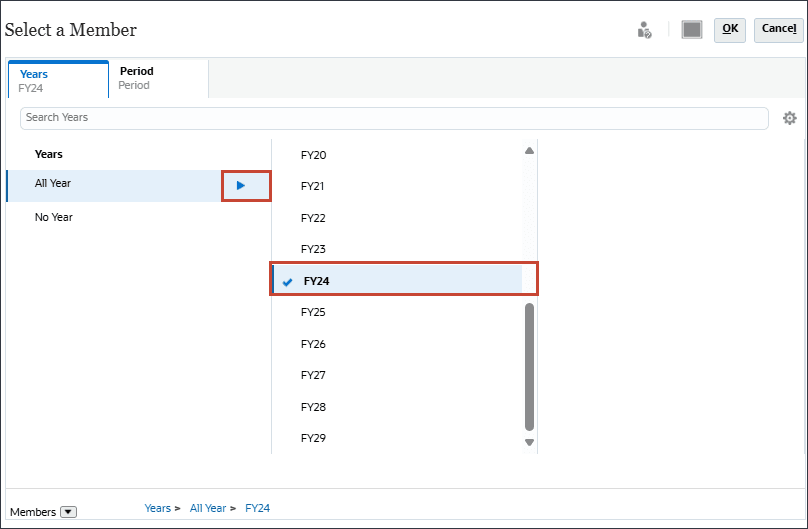
- 单击期间。
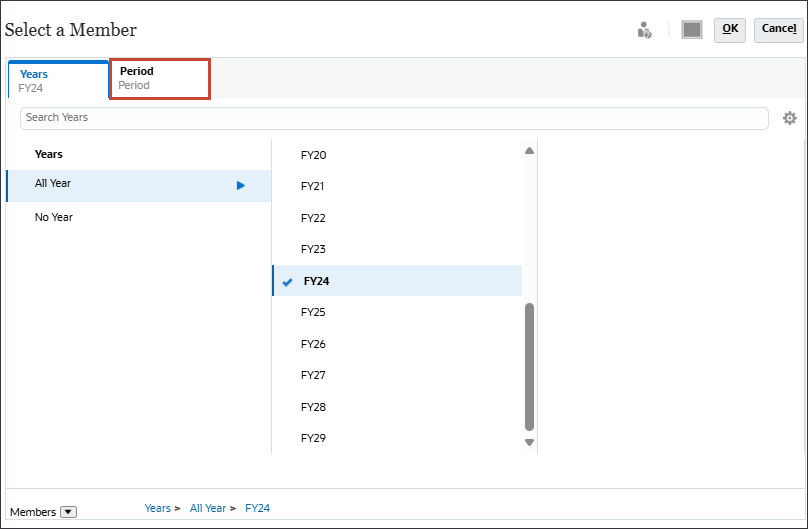
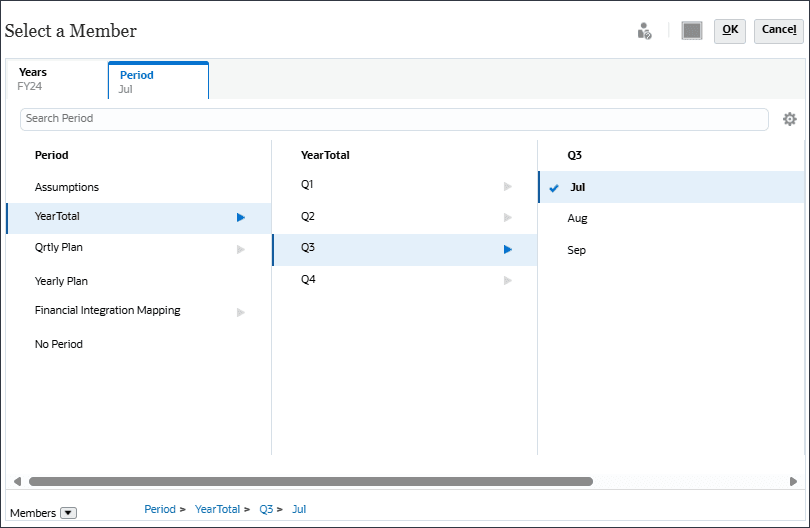
- 在 YearTotal 和 Q3 下,选择 Jul(七月),然后单击 OK(确定)。
注意:
您可以使用替代变量设置当前年份。 - 对于“历史期间数”,输入 30 ;对于“未来期间数”,输入 6 。
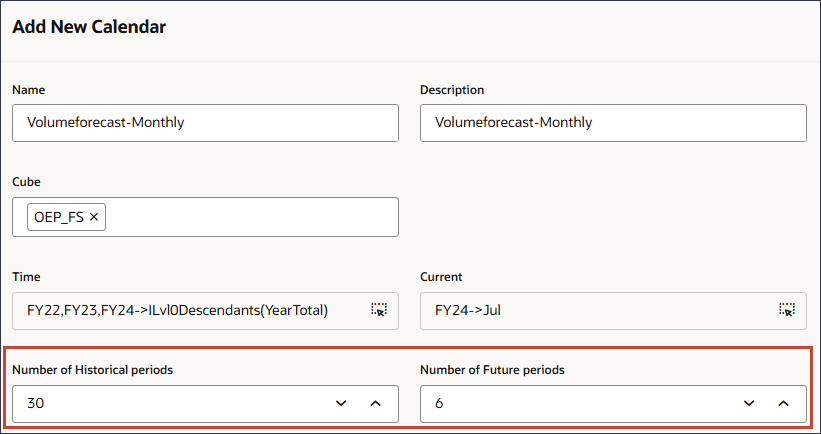
- 单击提交。
此时将显示一条确认消息。

- 对于 Volumeforecast-Monthly ,单击 (操作),然后选择编辑。

- 在“频率”中,确保选择了每月。
定义频率和日期格式的日期映射是将期间数据发送到数据科学引擎的重要步骤。
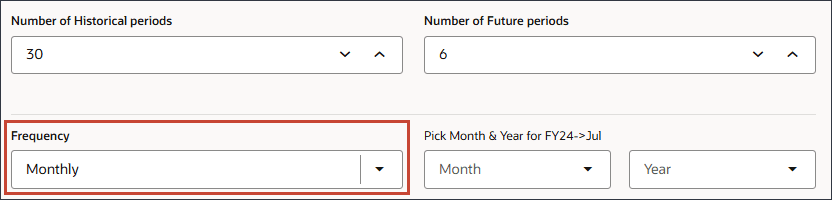
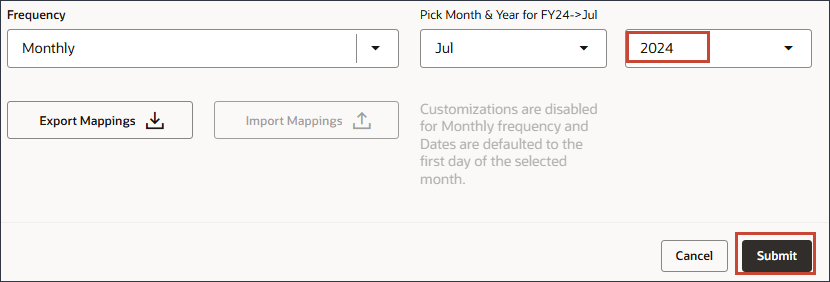
- 在“FY24 -> 七月”的“选取月份”和“年份”中,确保选择月份并为“月份”选择七月。

- 单击“年”,对于“年”,选择 2024 ,然后单击提交。
- 要查看映射,请在 VolumeForecast-Monthly 日历中单击 (操作),然后选择编辑。

- 单击导出映射。
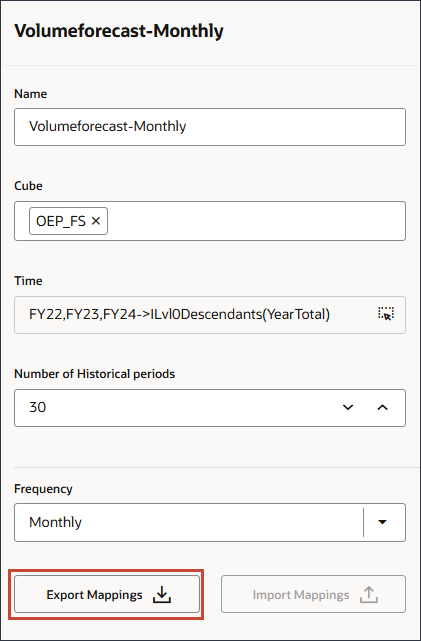
您可以打开该文件并查看映射。请务必使用记事本打开 .csv 文件。
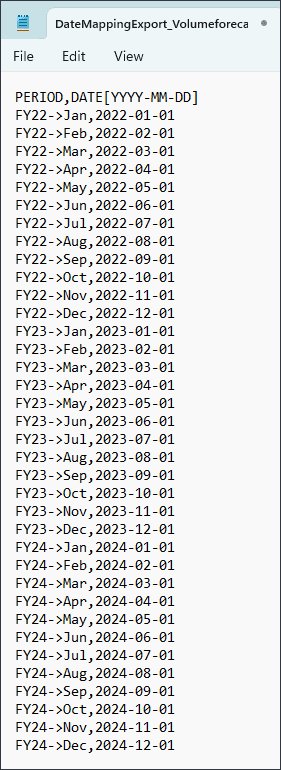
- 关闭记事本文件,然后单击取消。
注意:
在通过单击“提交”设置日期映射之前,请确保保存日历。创建定制日历
由于 GDP 增长率存储在 FY22、FY23 和 FY24 的 BegBalance 中,因此您可以创建自定义日历,以便高级预测可以包括 BegBalance 期间的输入。
- 在创建定制日历之前,请在记事本中打开 DateMappingExport_GDPCal.csv 文件以查看其内容。
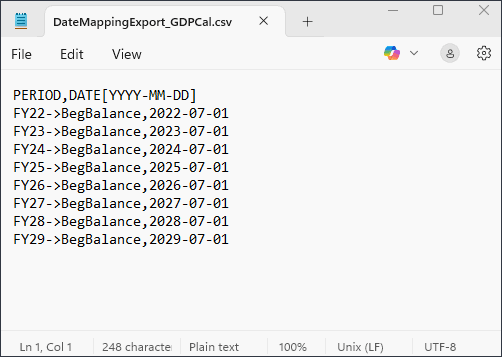
该文件包含 BegBalance(对于 7 月的第一天从 FY22 到 FY29 的每一年)。
- 关闭记事本。
- 单击添加日历。
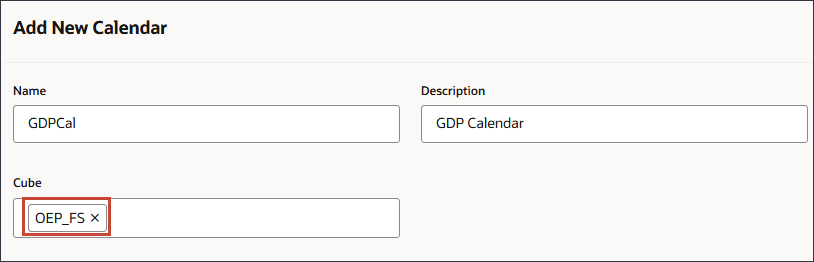
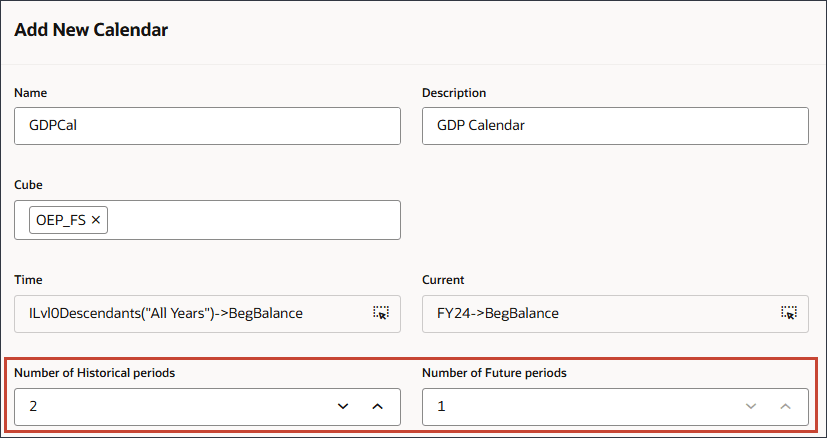
- 在“名称”中,输入 GDPCal 。
- 在“说明”中,输入 GDP 日历。

- 对于多维数据集,选择 OEP_FS 。
- 对于时间,单击 (选择时间)。
- 在“选择成员”、“年数”中,针对全年,单击 (函数选择器),然后选择 Level0Descendants 。
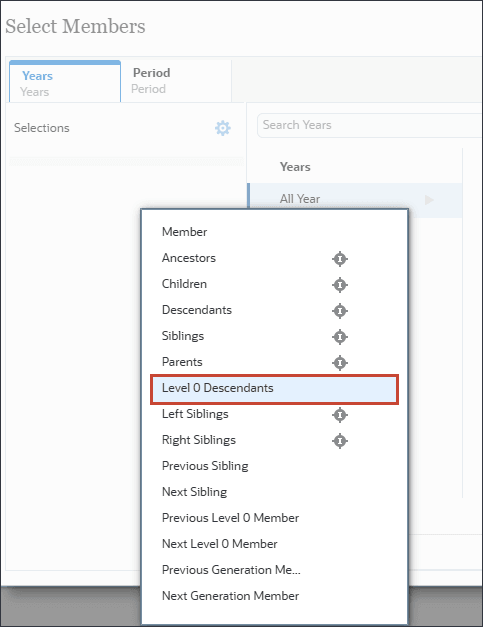
对于时间,您可以包括预测所需的全部历史期间和未来期间。
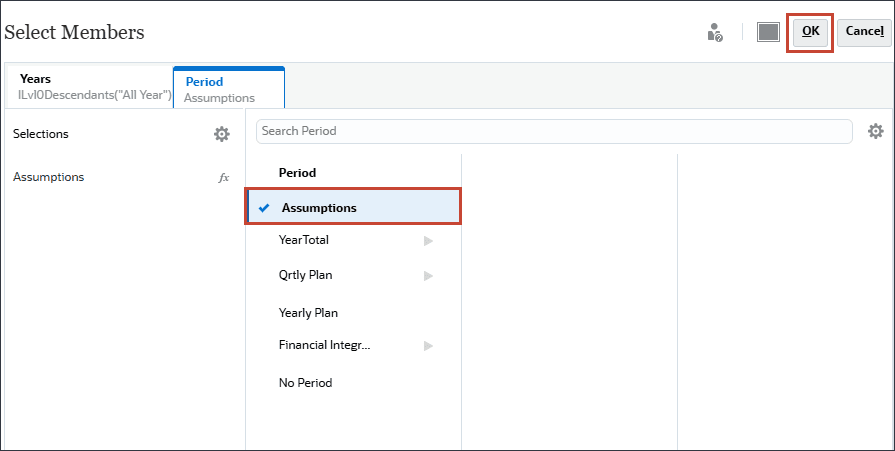
- 单击期间。
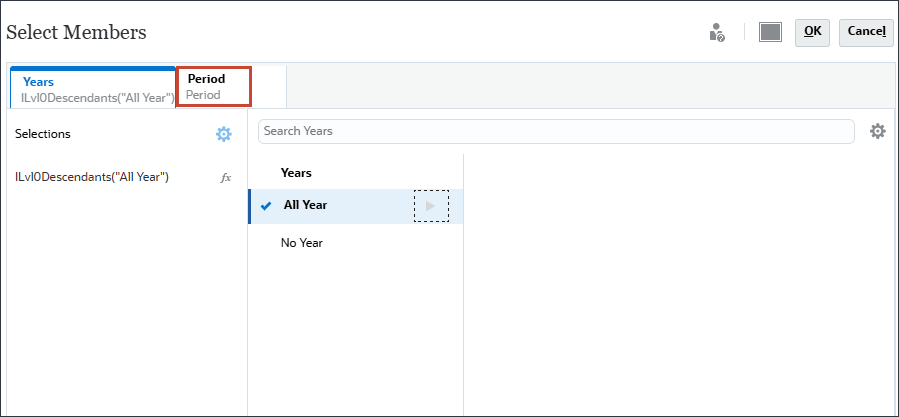
- 对于期间,选择假设,然后单击确定。
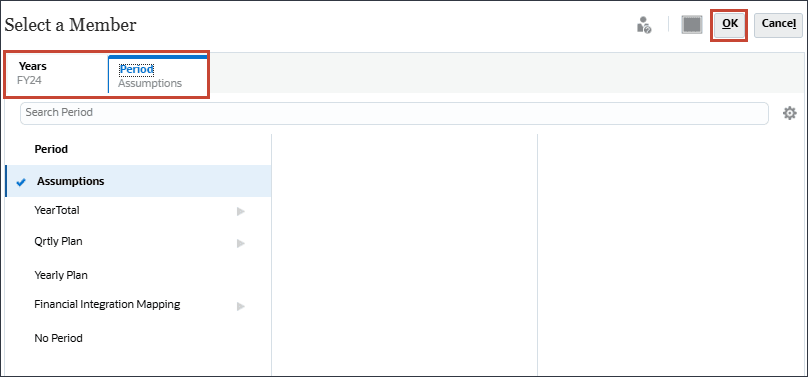
- 在“当前”中,单击 (选择当前日期)。
- 对于当前日期,对于年,选择 FY24 ,对于期间,选择假设,然后单击确定。
- 对于“历史期间数”,输入 2 ;对于“未来期间数”,输入 1 ,然后单击提交。
此时将显示一条确认消息。

您可以关闭确认消息。
-
在 GDPCal 行中,单击 (操作),然后选择编辑。
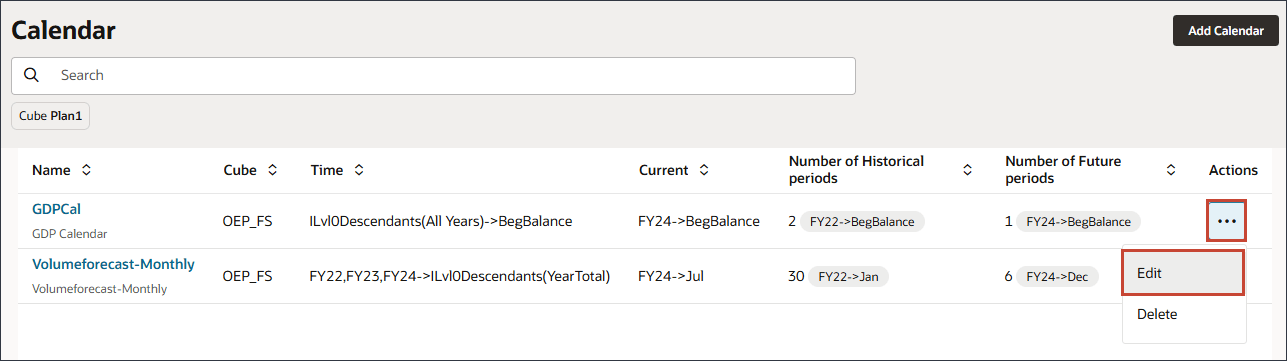
- 在“频率”中,选择自定义。
- 单击导入映射。
- 找到并选择 DateMappingExport_GDPCal.csv ,然后单击打开。
- 单击提交。
已添加 GDP 日历。
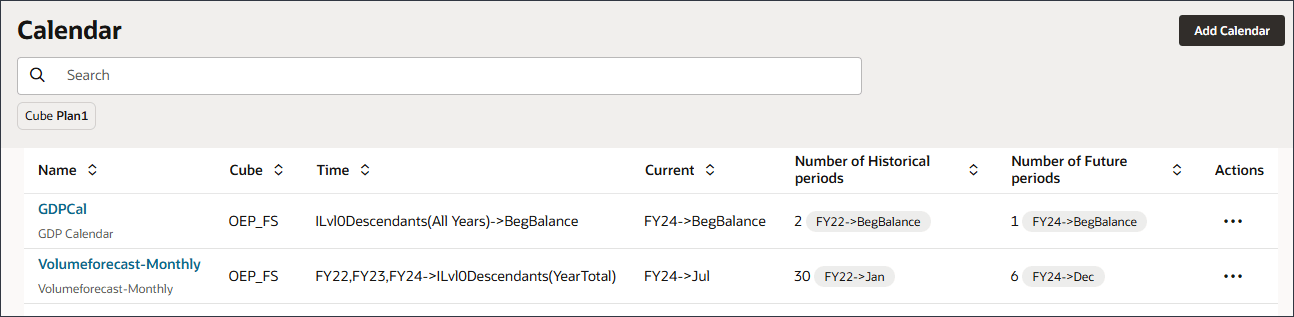
- 单击 (主页)以返回到主页。
注意:
在通过单击“提交”设置日期映射之前,请确保保存 GDPCal。在 IPM 作业中配置高级预测
- 在主页上,依次单击 IPM 和 Config 。
- 单击 IPM 选项卡。
- 在 "IPM" 页面上,单击创建。
- 在“详细信息”的“名称”中,输入销售量预测;在“说明”中,输入基于输入动因的预测销售量。
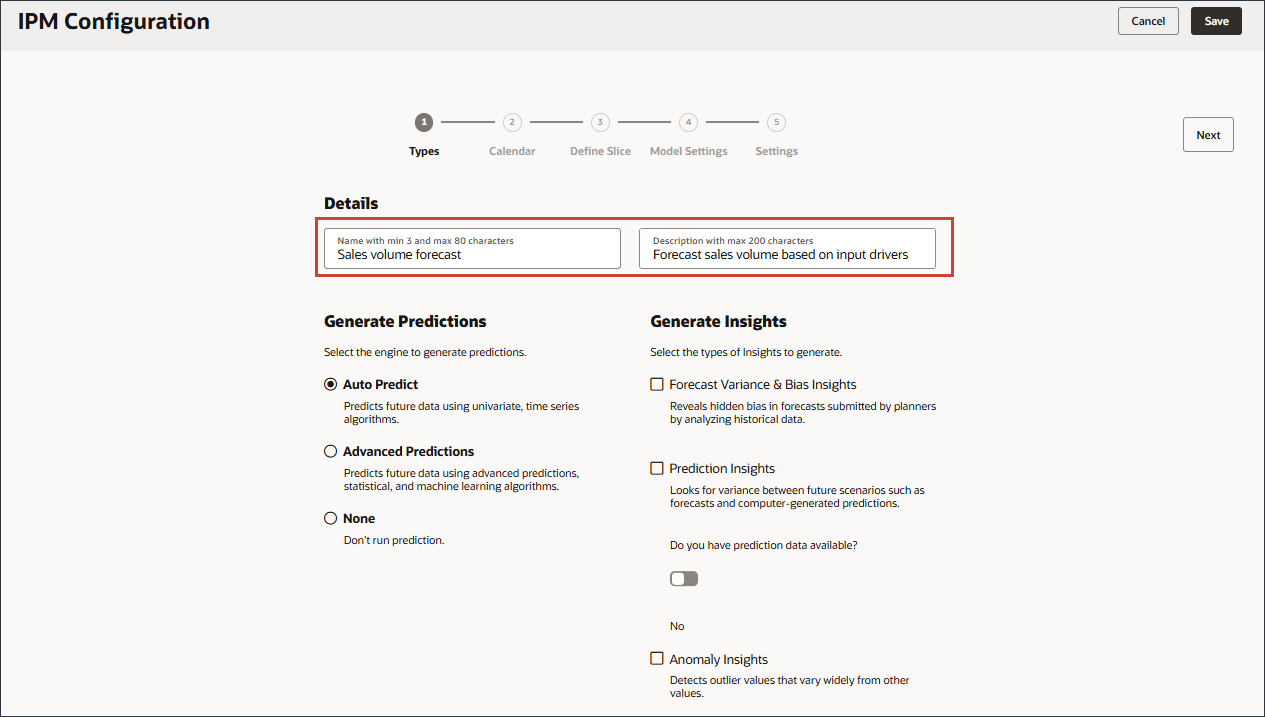
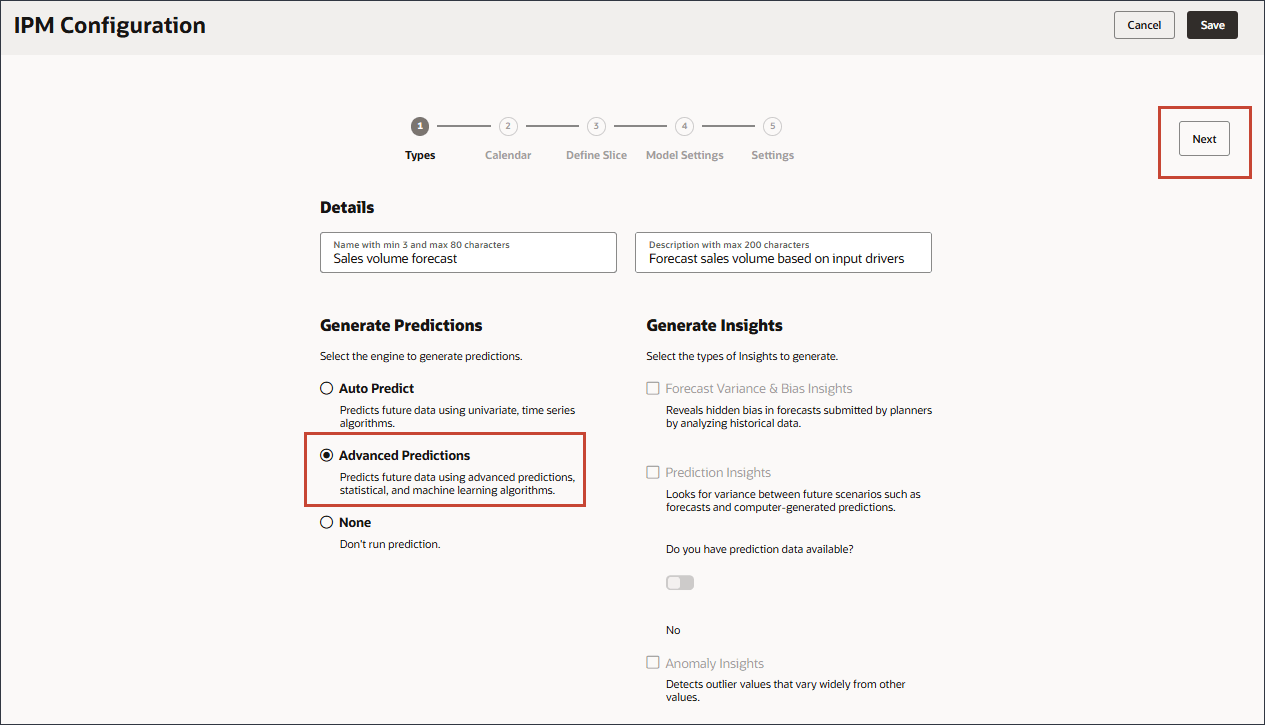
- 要使用多变量、统计和机器学习算法预测未来数据,请选择高级预测,然后单击下一步。
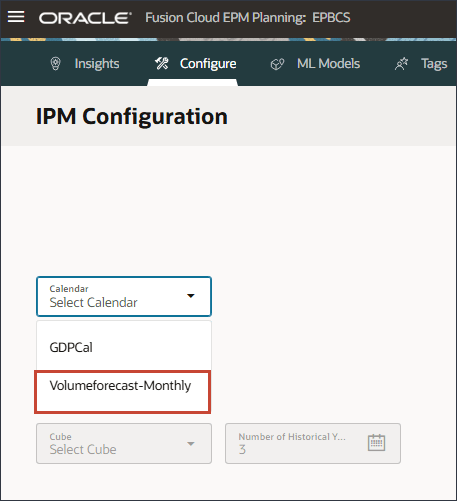
选择日历
您可以通过选择日历或手动提供期间范围来定义历史期间和未来期间的时间范围。
- 要选择日历,请单击日历,然后选择 Volumeforecast-Monthly 。
选择日历后,将自动填充历史和未来期间范围。
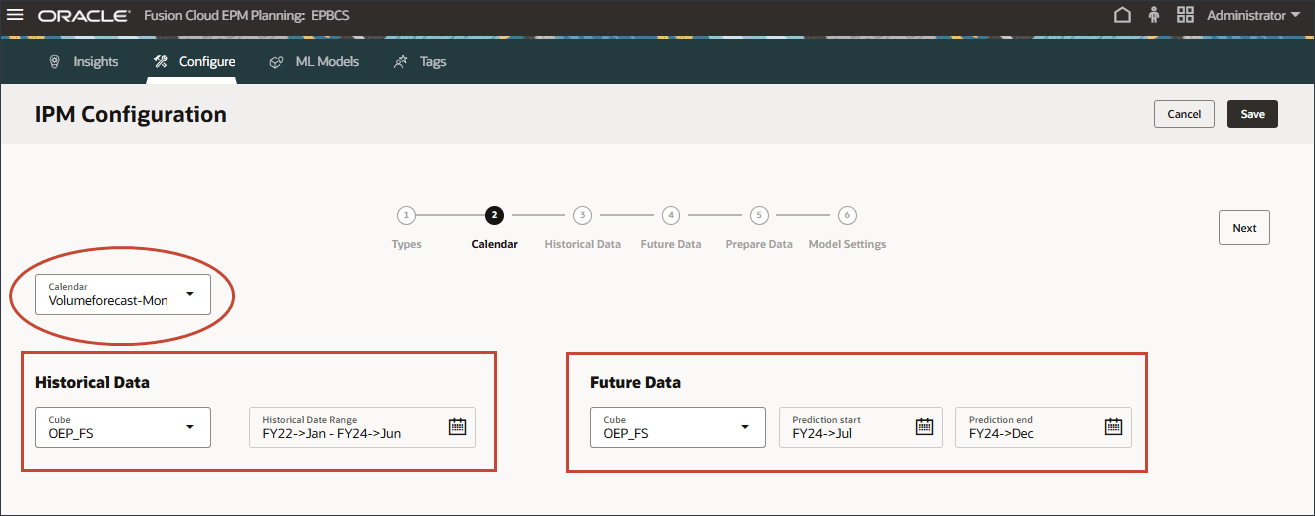
从“日历”定义中自动填充多维数据集选择。
如果选择了日历,则无法更改期间范围,因为期间范围定义是根据日历定义填充的。如果要对期间进行任何更改,则需要返回到日历设置并在其中进行更改。
- 单击下一步。
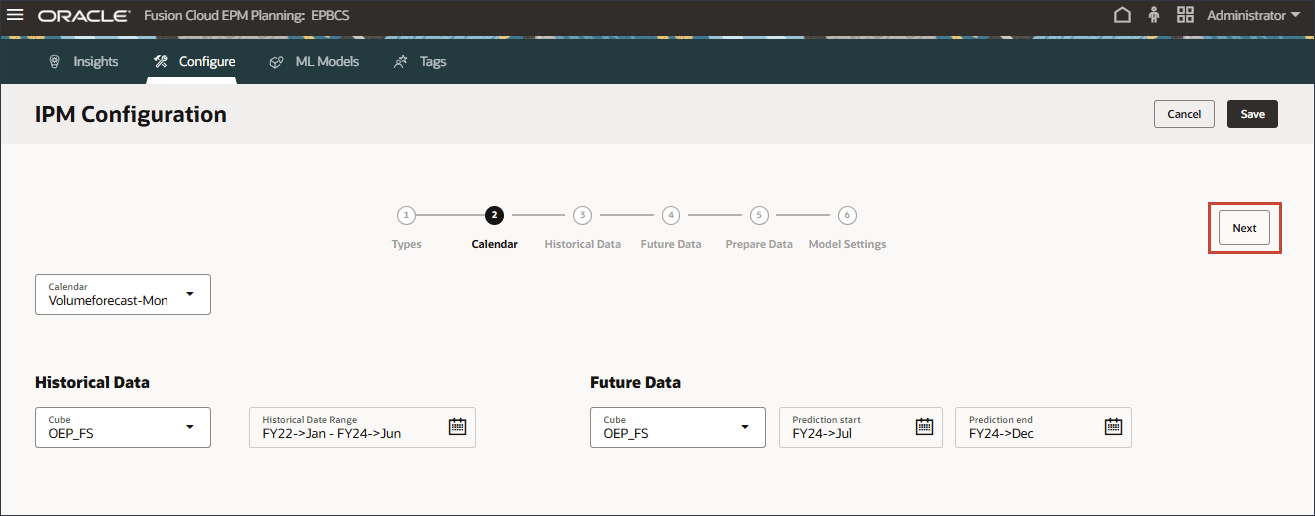
注意:
对于高级预测,无法在 IPM 配置中手动选择历史数据或将来数据。必须预定义日历。为历史数据选择时段定义
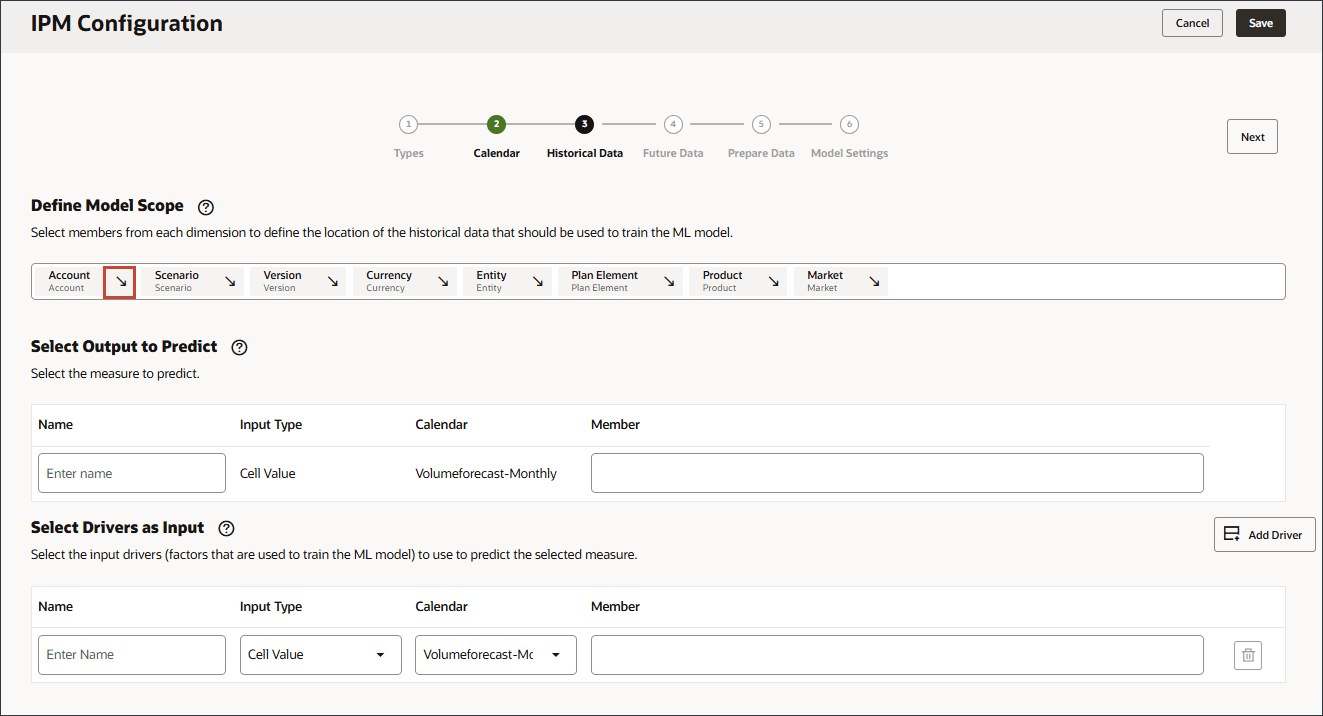
在此部分中,您将定义要预测的内容以及要使用的输入动因。您可以定义输入驱动程序并将其映射到多维数据集中的数据。必须已在 EPM 多维数据集中定义这些输出度量和输入驱动程序。正如您之前在教程中所述,您拥有各种帐户(目标和输入驱动程序)所需的帐户成员和数据。
在此配置中,“帐户”维包含输出和输入动因的必要度量和帐户,因此“帐户”维需要包括在配置定义行中。
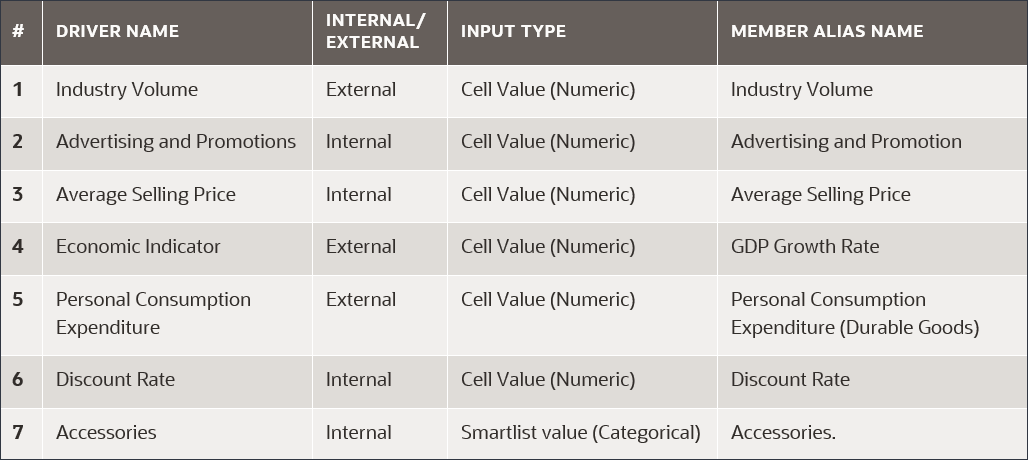
您可以定义输入动因,这些动因是用于训练预测模型以预测所选度量的因素。有七个输入驱动程序:
- 在帐户右侧,单击箭头。
账户已添加到行中。
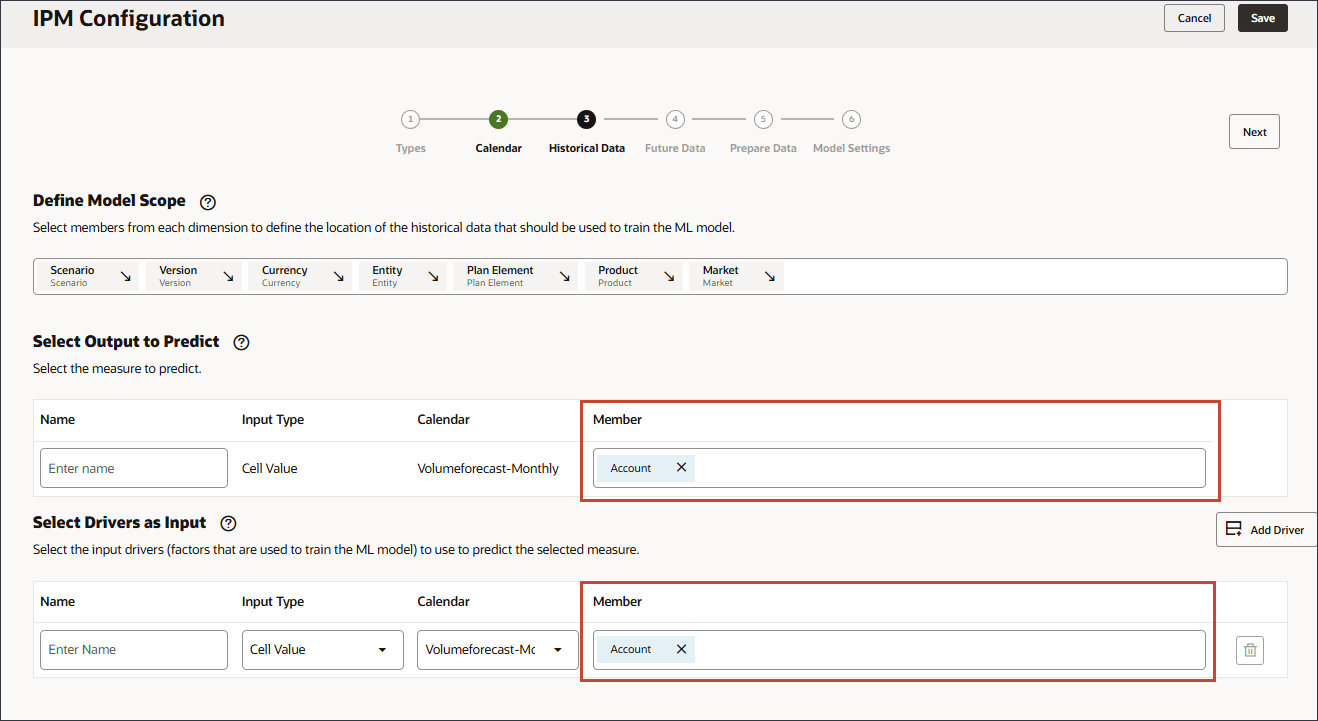
- 对于方案,单击方案以打开成员选择器。

- 展开 OEP_Scenarios ,选择实际。
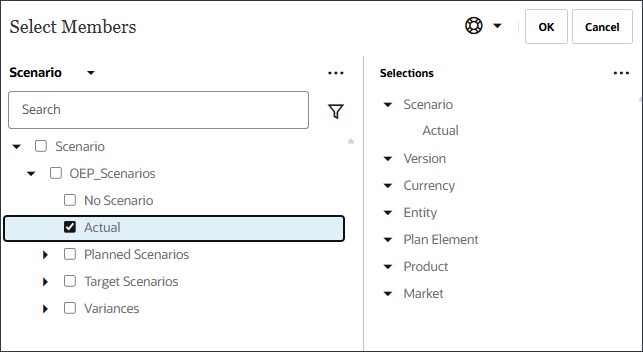
- 单击方案,然后选择版本。
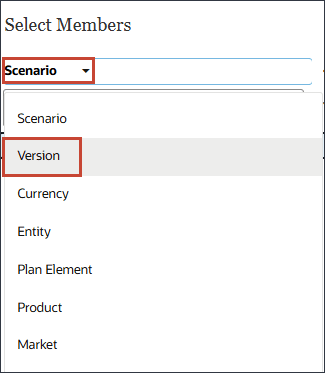
- 展开 OEP_Versions ,然后选择正在处理。
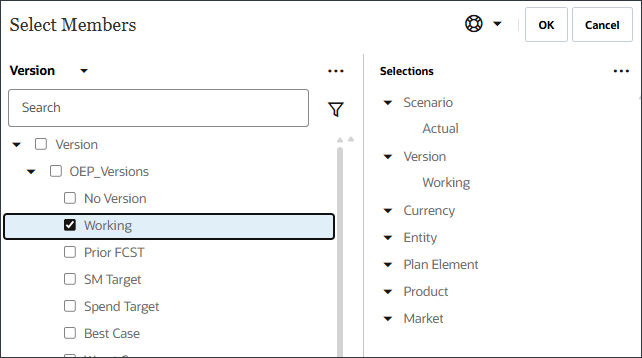
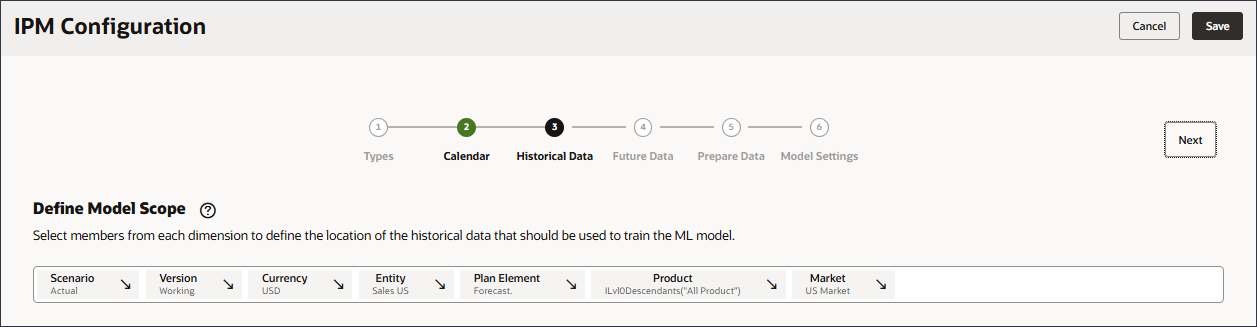
- 通过使用成员选择器并选择以下 POV 维成员来定义模型范围。选择所有成员后,单击确定。
提示:
要定义 POV(Model Scope,模型范围),请选择每个维,然后在“Select Members(选择成员)”对话框中选择包括函数的成员。您可以搜索成员。维 成员 Scenario 实际 Version 正在处理 货币 美元 实体 销售美国 规划元素 预测。 Product Ilvl0Descendants(“所有产品”) Market 美国市场 提示:
对于“计划要素”,选择“计划要素”下的“预测”和“计划合计”。"Forecast." 是 OFS_Load 成员的别名。别名 "Forecast." 在名称中包含句点。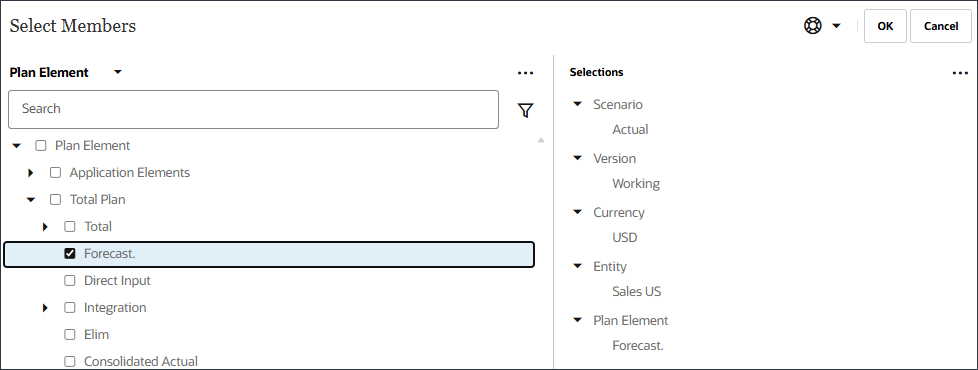
提示:
对于产品,选择“所有产品”的 Lev 0 后代。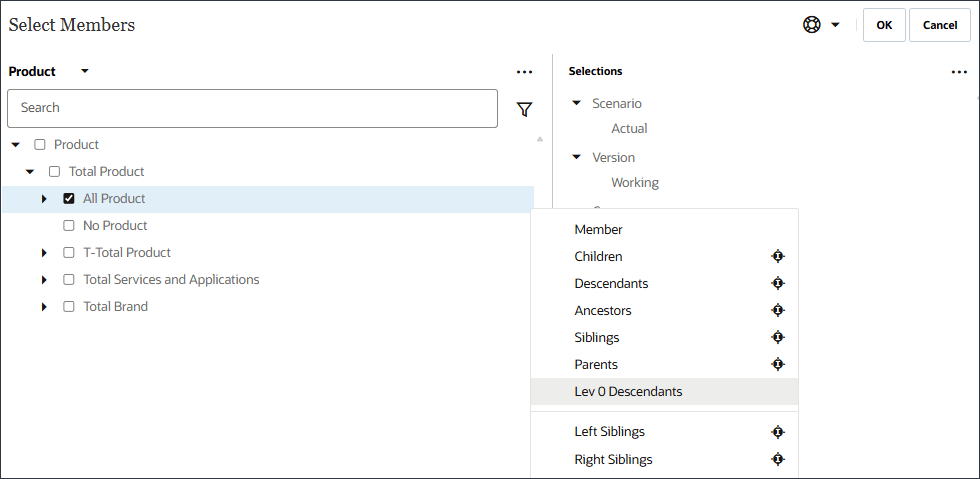
从每个维中选择 POV 成员,以定义应该用于训练高级预测模型的历史数据的位置。例如,训练高级预测模型以预测 Ilvl0Descendants(“所有产品”)的所有成员的数量,使用实际方案和工作版本中的历史数据,使用美元货币,使用 Sales US 实体等。
- 验证您的选择。
- 在“选择要预测的输出”中,对于“名称”,输入卷。
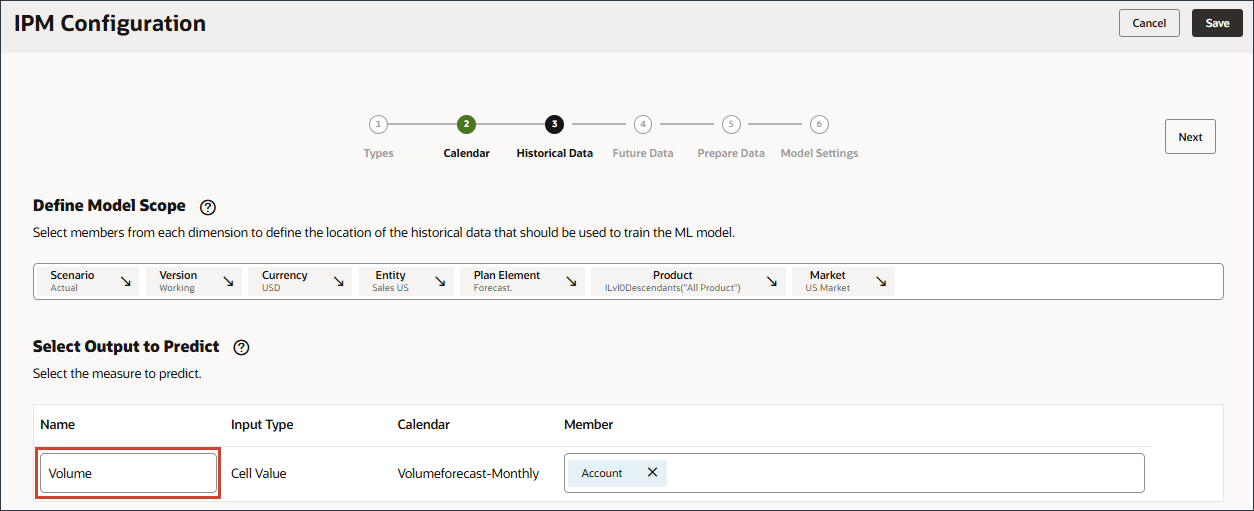
- 在“选择要预测的输出”中,单击账户。
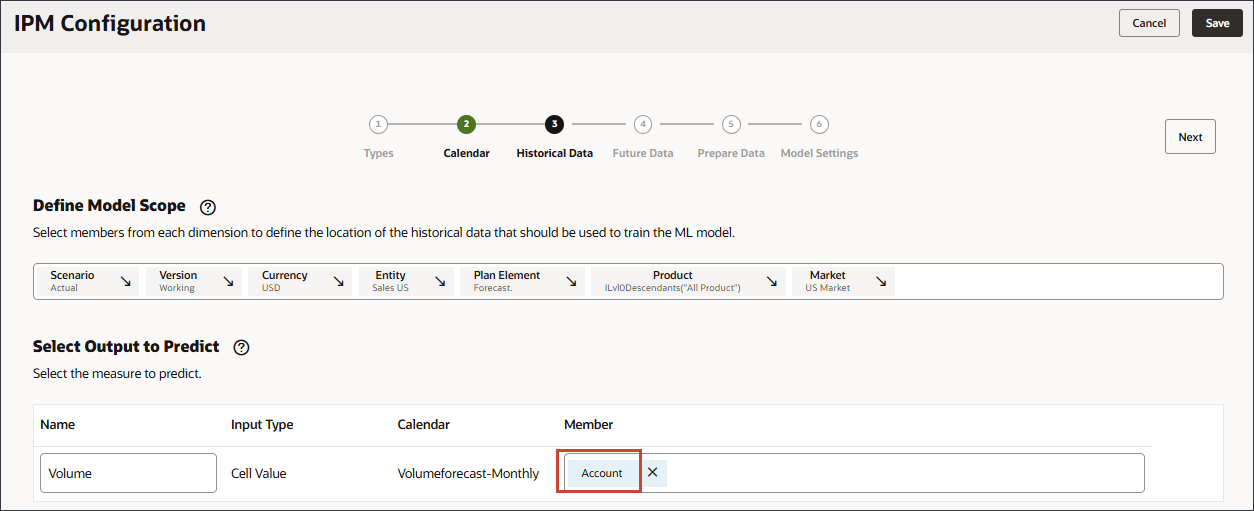
- 使用成员选择器,选择卷,然后单击确定。
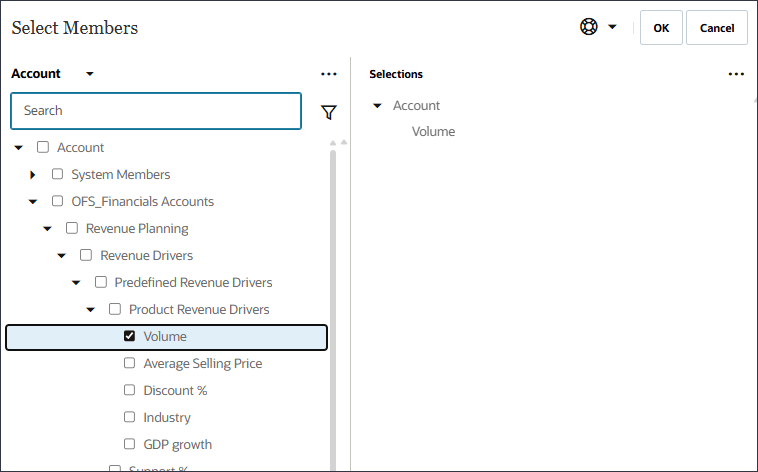
注意:
确保选择正确的批量帐户。当别名是“卷”时,此帐户的成员名称为 OFS_Volume。卷已选定。
- 在“选择动因作为输入”中,为“名称”输入行业量,然后单击帐户。
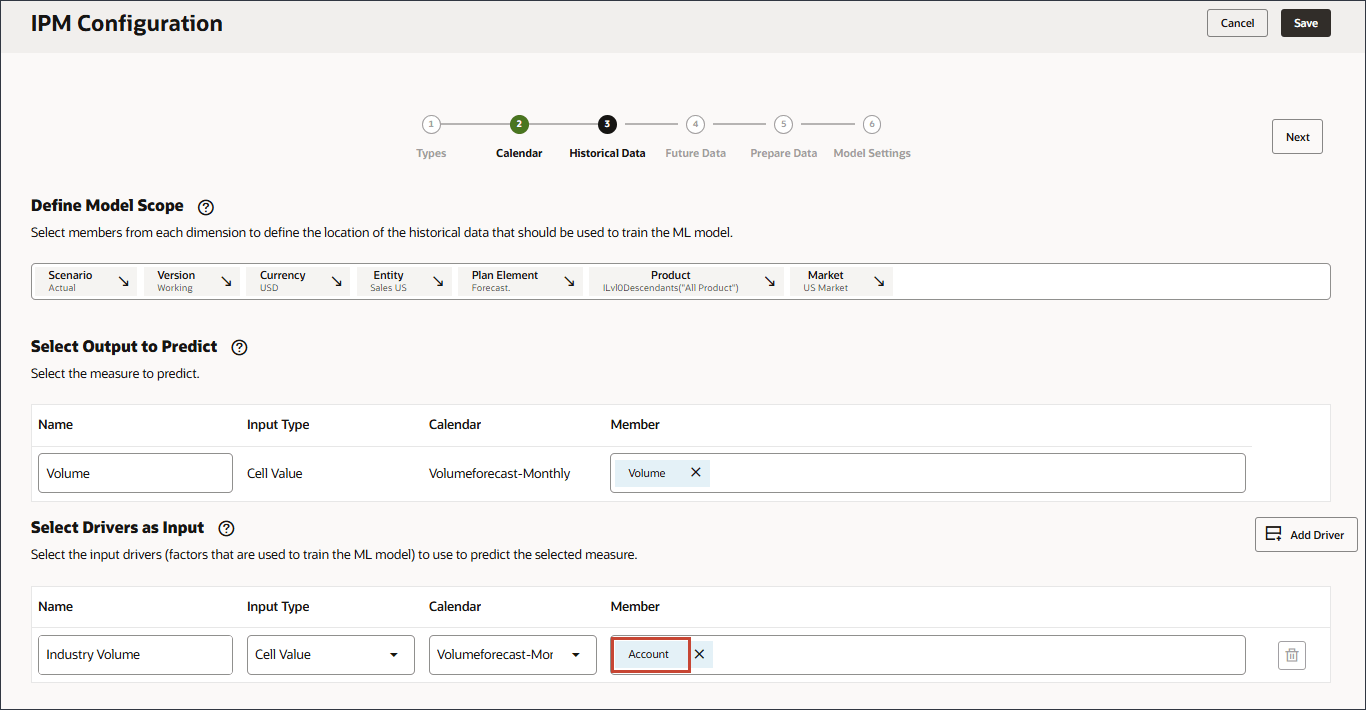
- 选择行业卷,然后单击确定。
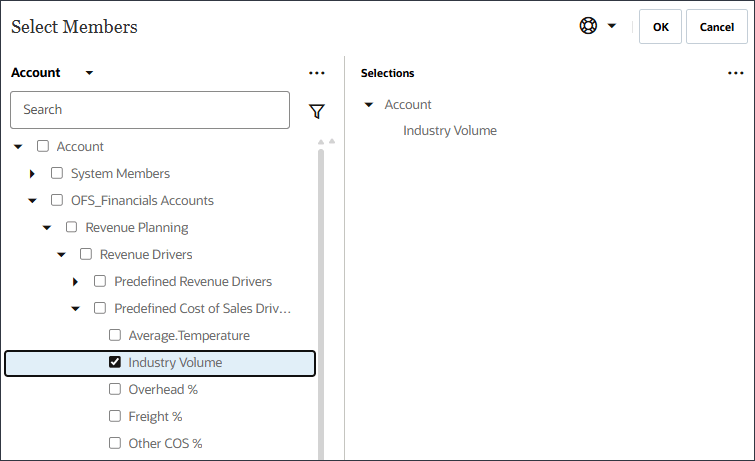
注意:
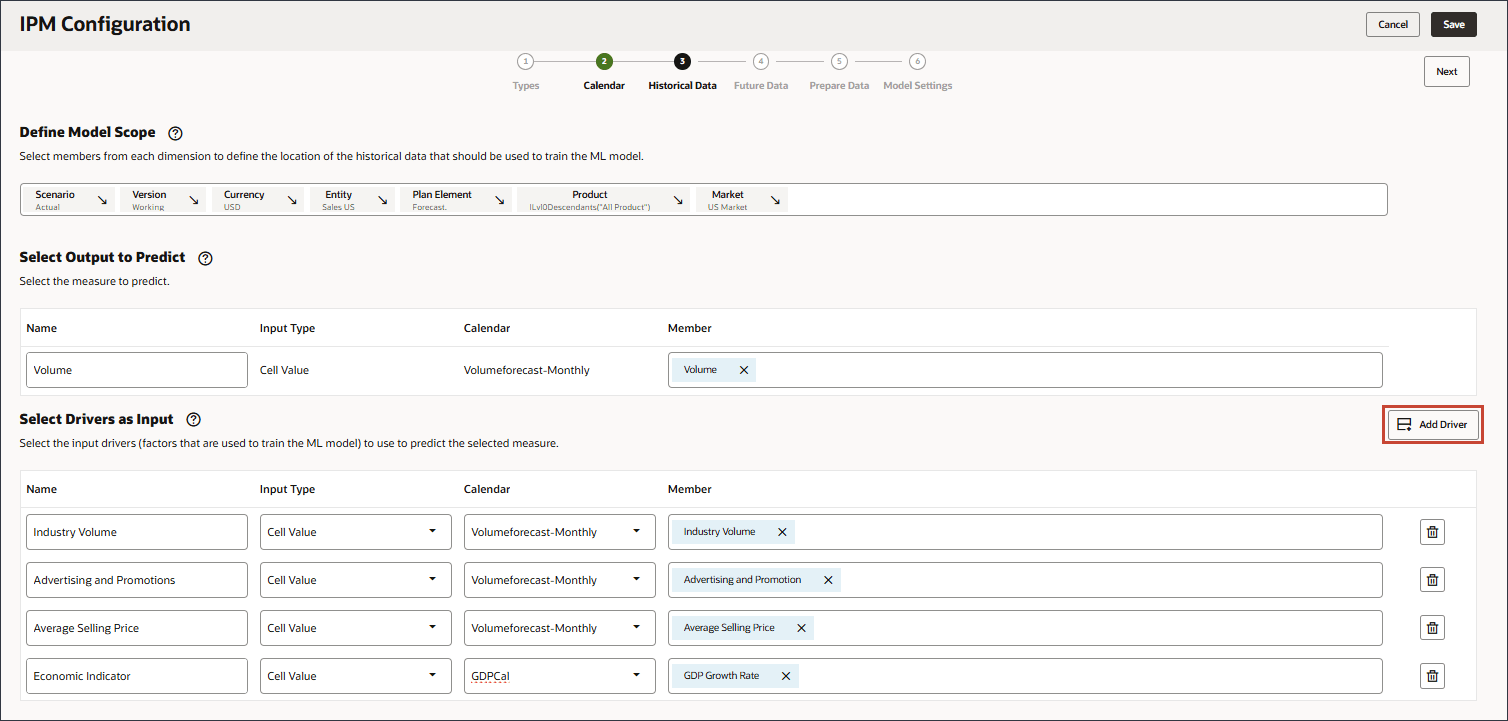
确保选择正确的“行业批量”科目,该科目位于层次结构中的“预定义销售驱动因素成本”下。 - 单击添加驱动程序。
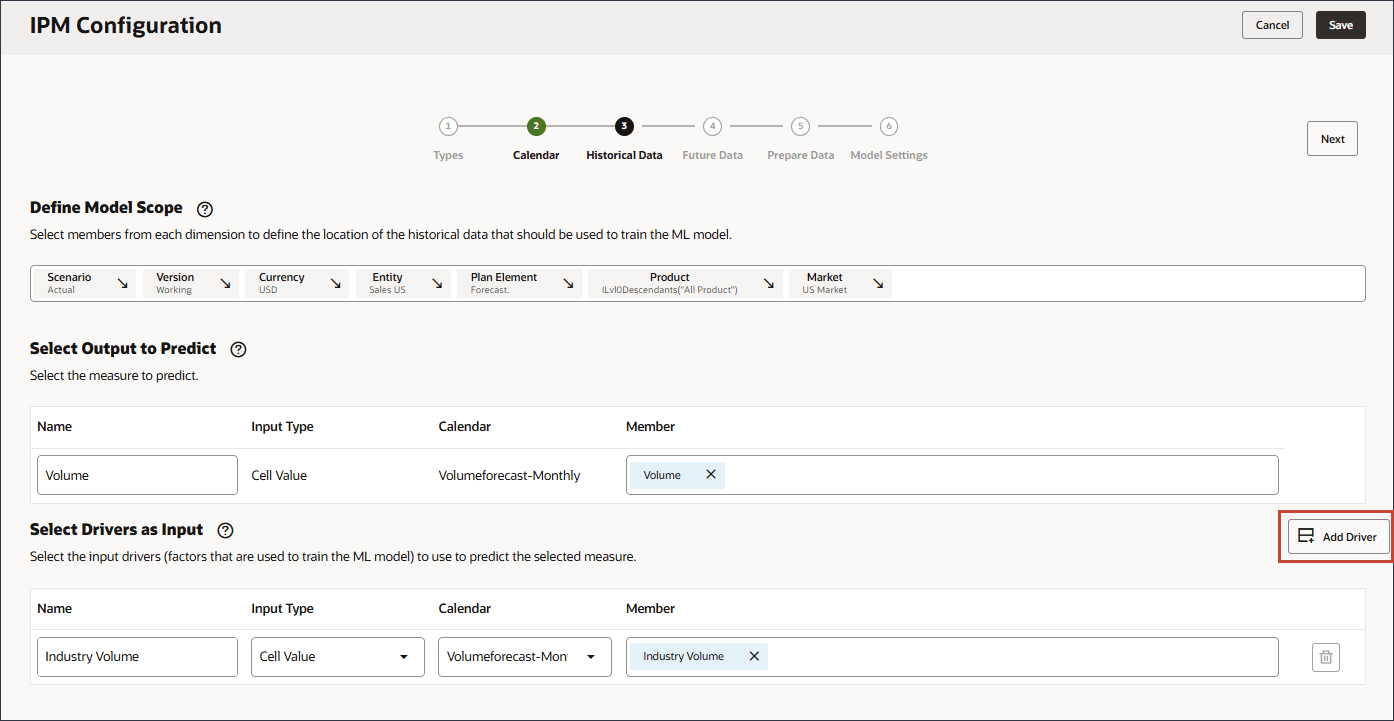
- 在“名称”中,输入广告和促销;对于“广告和促销”,在“成员”中,单击行业数量。
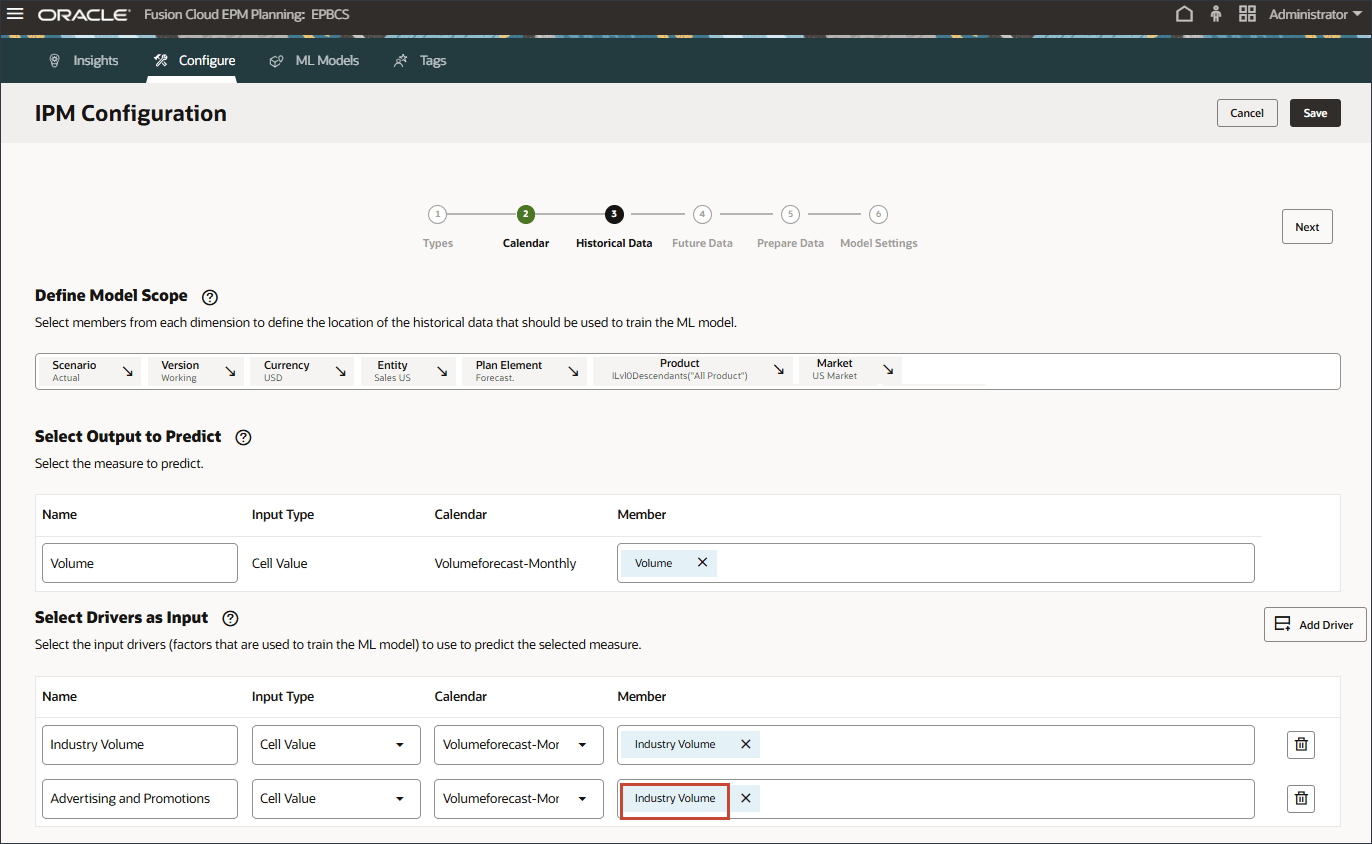
- 选择广告和促销,然后单击确定。
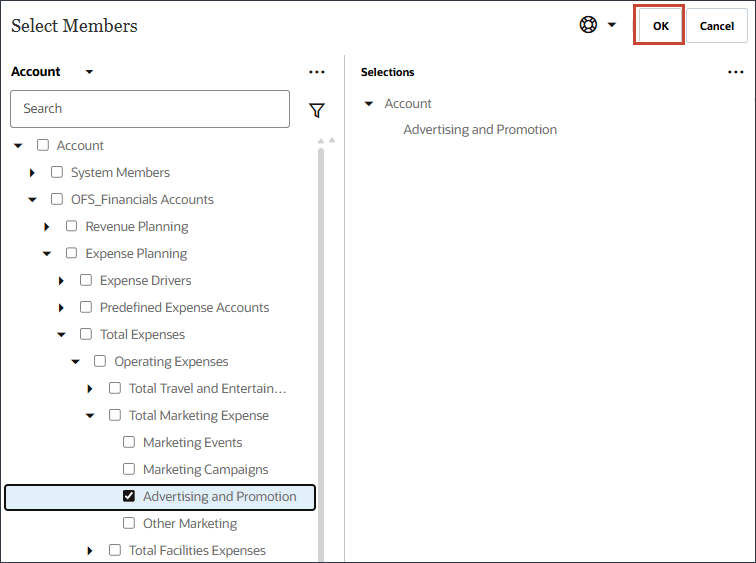
提示:
确保选择成员名称为 "OFS_Advertising and Promotion" 的成员。别名是“广告和促销”。 - 单击添加驱动程序。
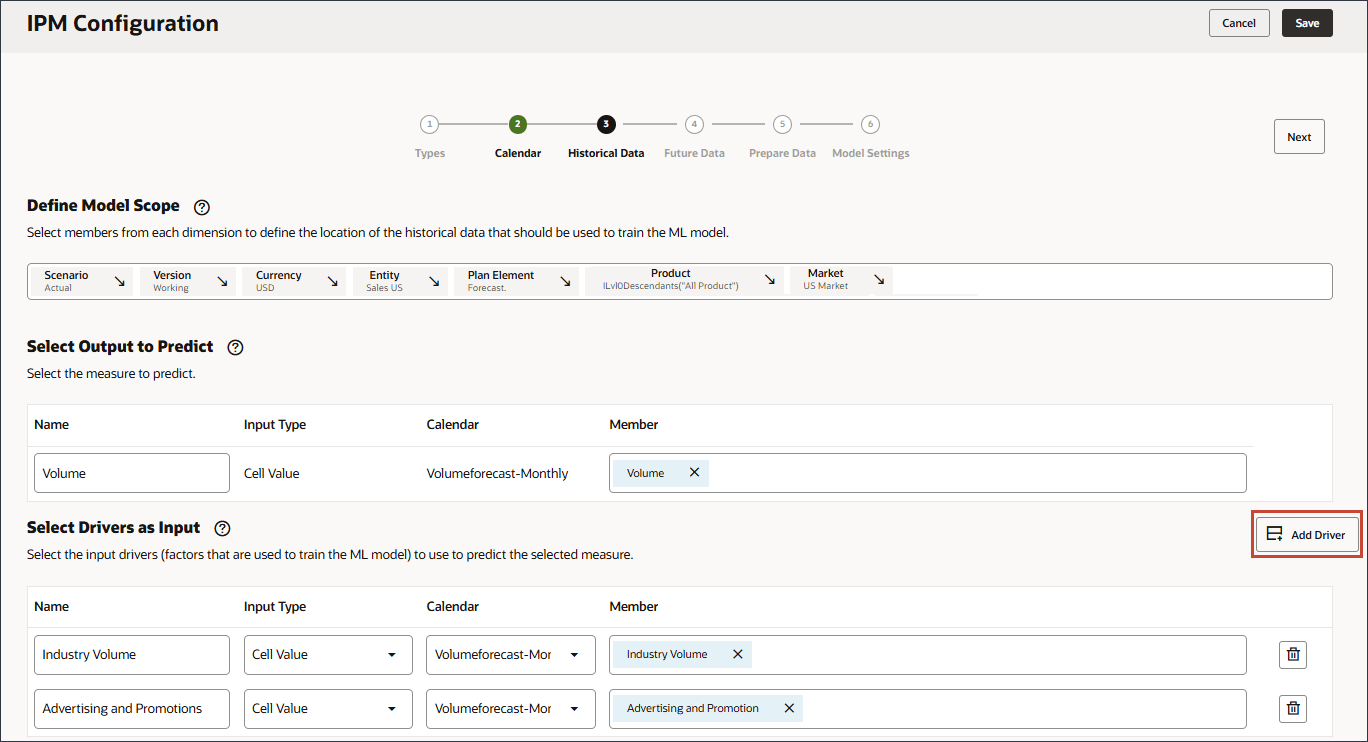
- 在“名称”中,输入平均销售价格,对于“平均销售价格”,在“成员”中,单击行业数量。
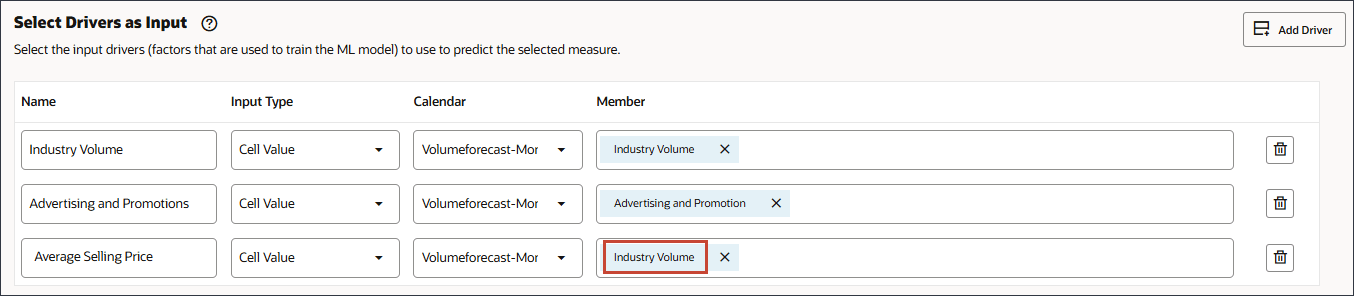
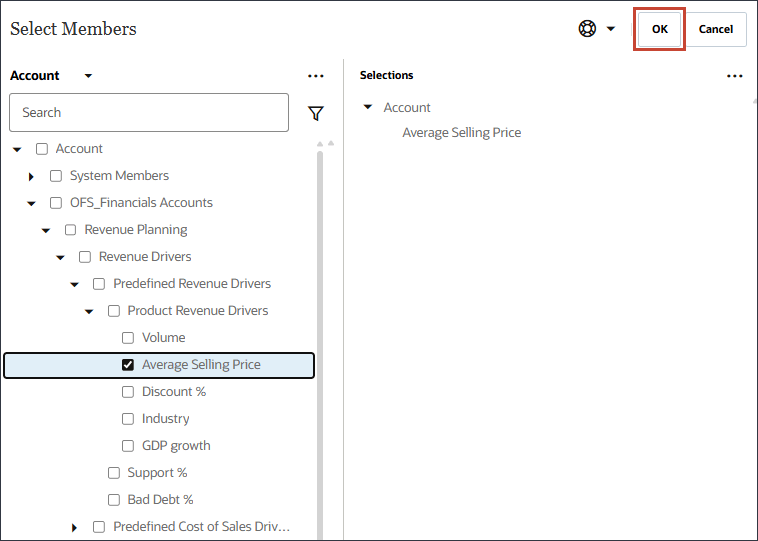
- 选择平均销售价格,然后单击确定。
提示:
请确保选择成员名称为 "OFS_Ave Selling Price" 的成员。别名是“平均销售价格”。 - 单击添加驱动程序。

- 在“名称”中,输入经济指标,在“经济指标”中,单击行业量。
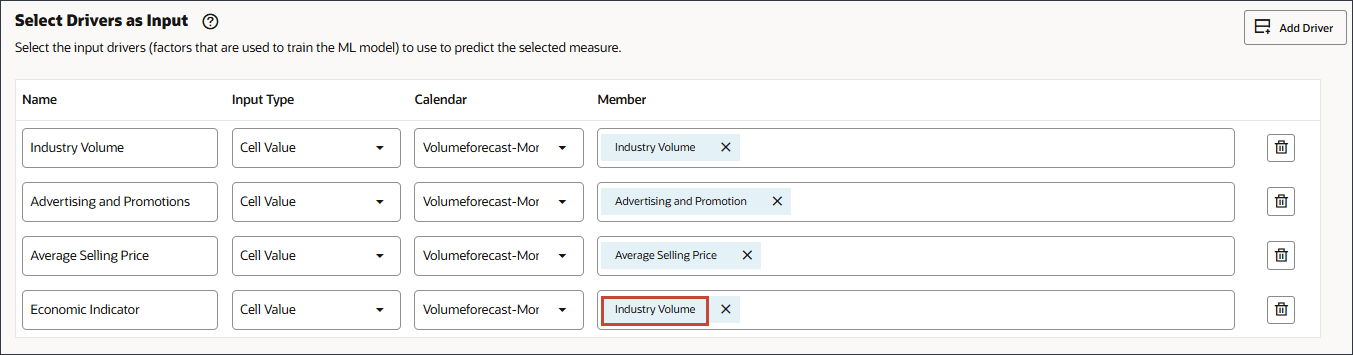
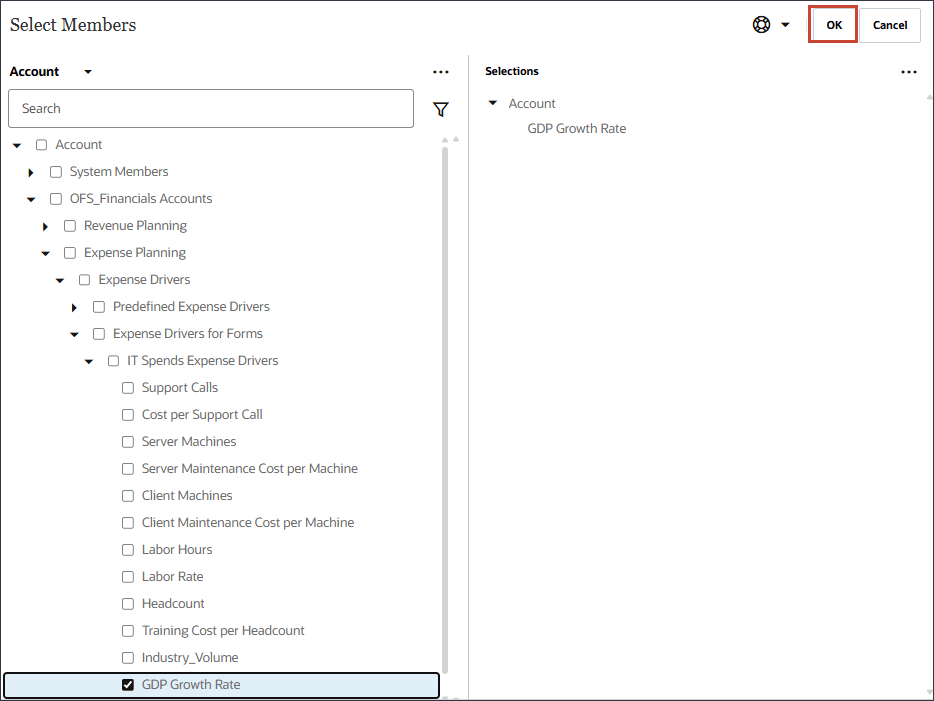
- 选择 GDP 增长率,然后单击确定。
注意:
请确保您选择了正确的帐户。此账户的成员名称是“经济指标”,而别名是“GDP 增长率”。成员“经济指标”映射到“GDP 增长率”。
- 对于经济指标,对于日历,单击 Volumeforecast-Monthly ,然后选择 GDPCal 。
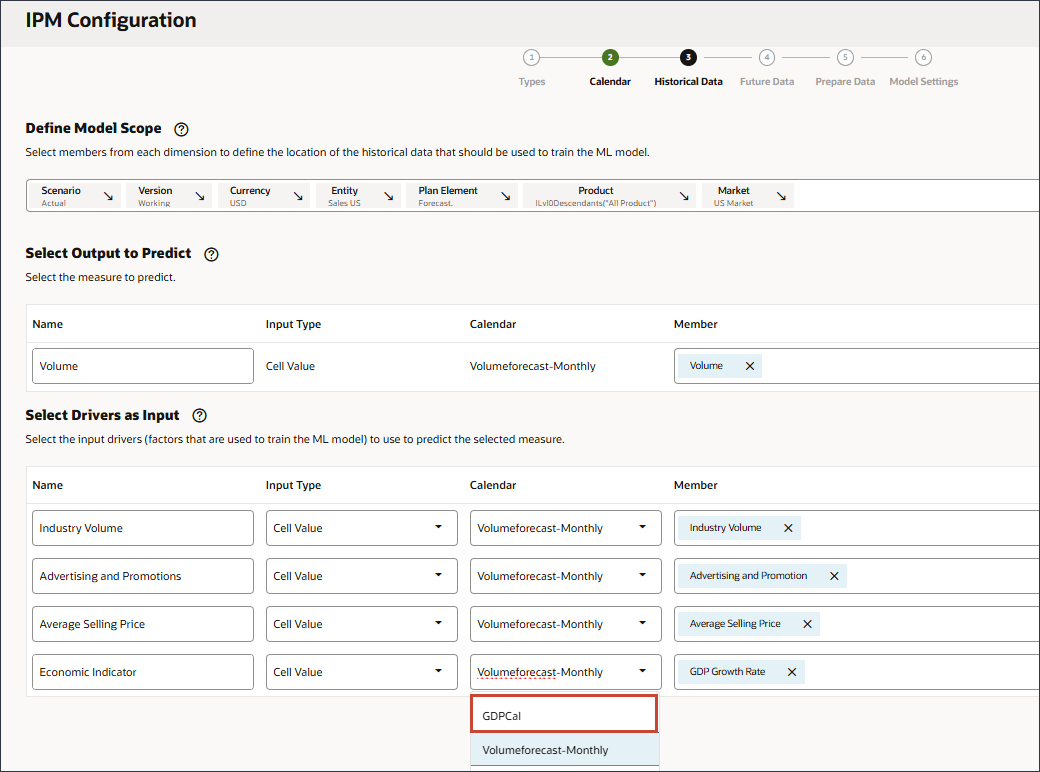
- 单击添加驱动程序。
- 在“名称”中,输入个人消费支出,对于“个人消费支出”,在“成员”中,单击行业数量。
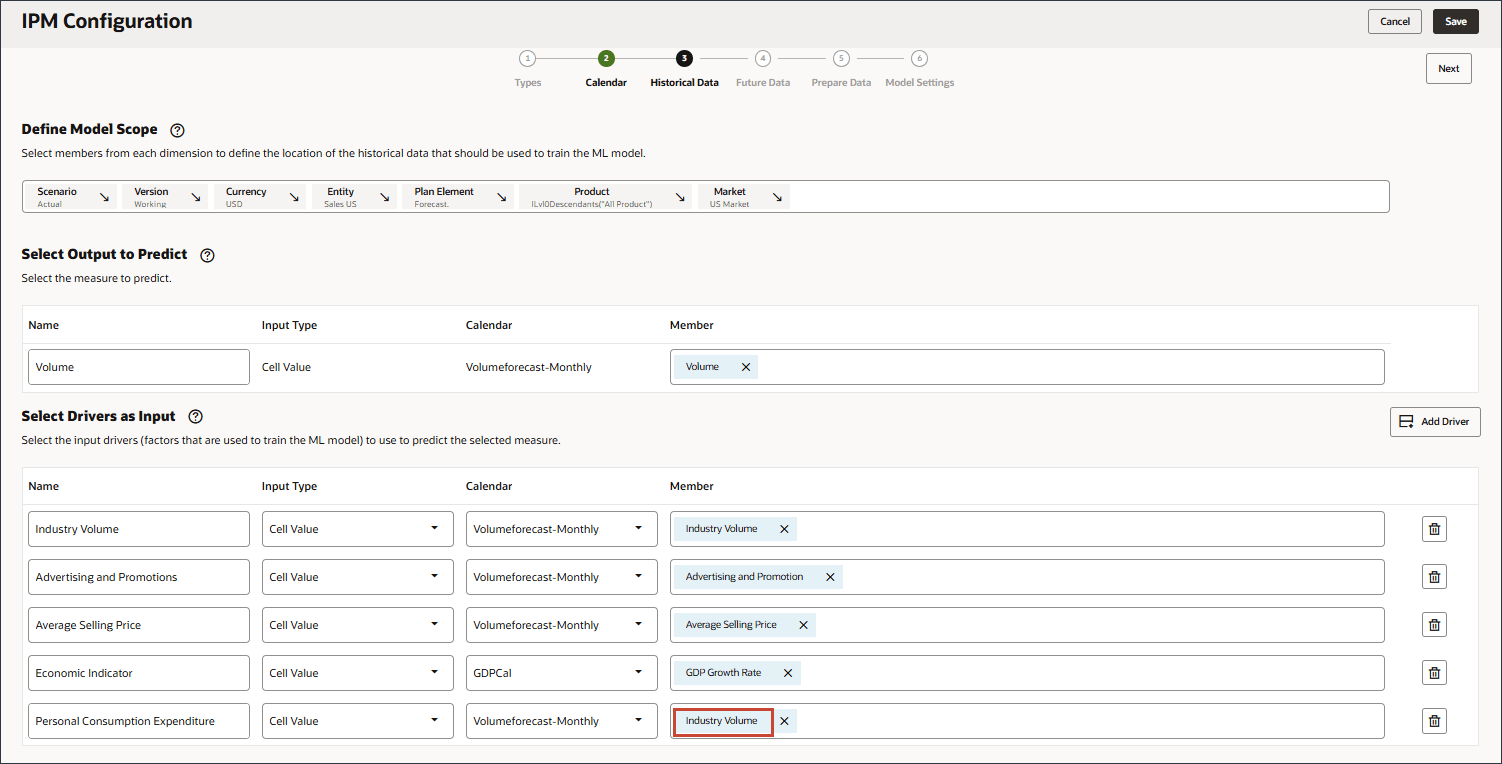
- 选择个人消费支出(耐用品),然后单击确定。
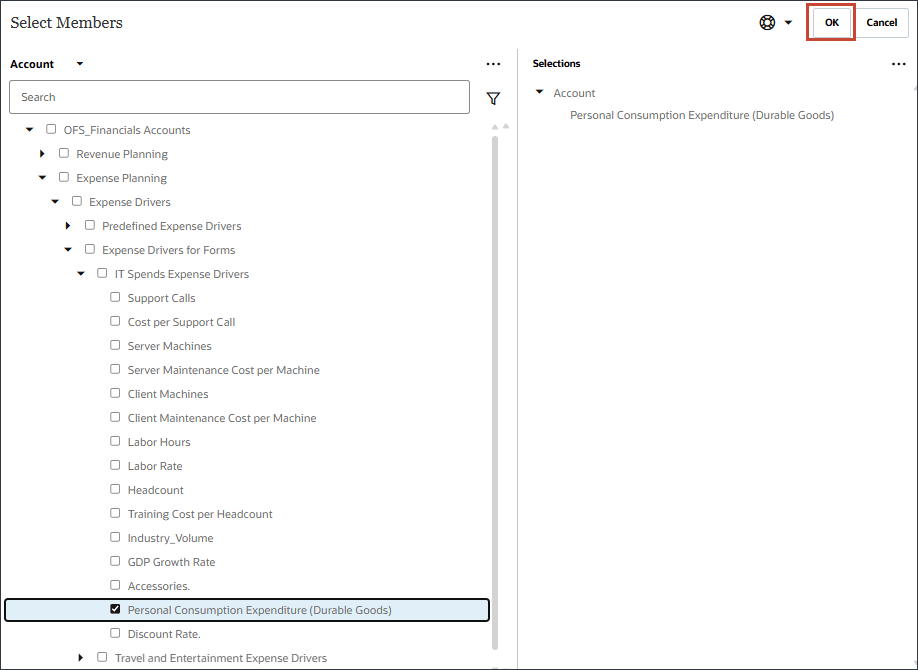
提示:
请务必选择成员名为“个人消费支出(耐用品)”的成员。该会员的别名是“个人消费支出(耐用品)”。 - 单击添加驱动程序。
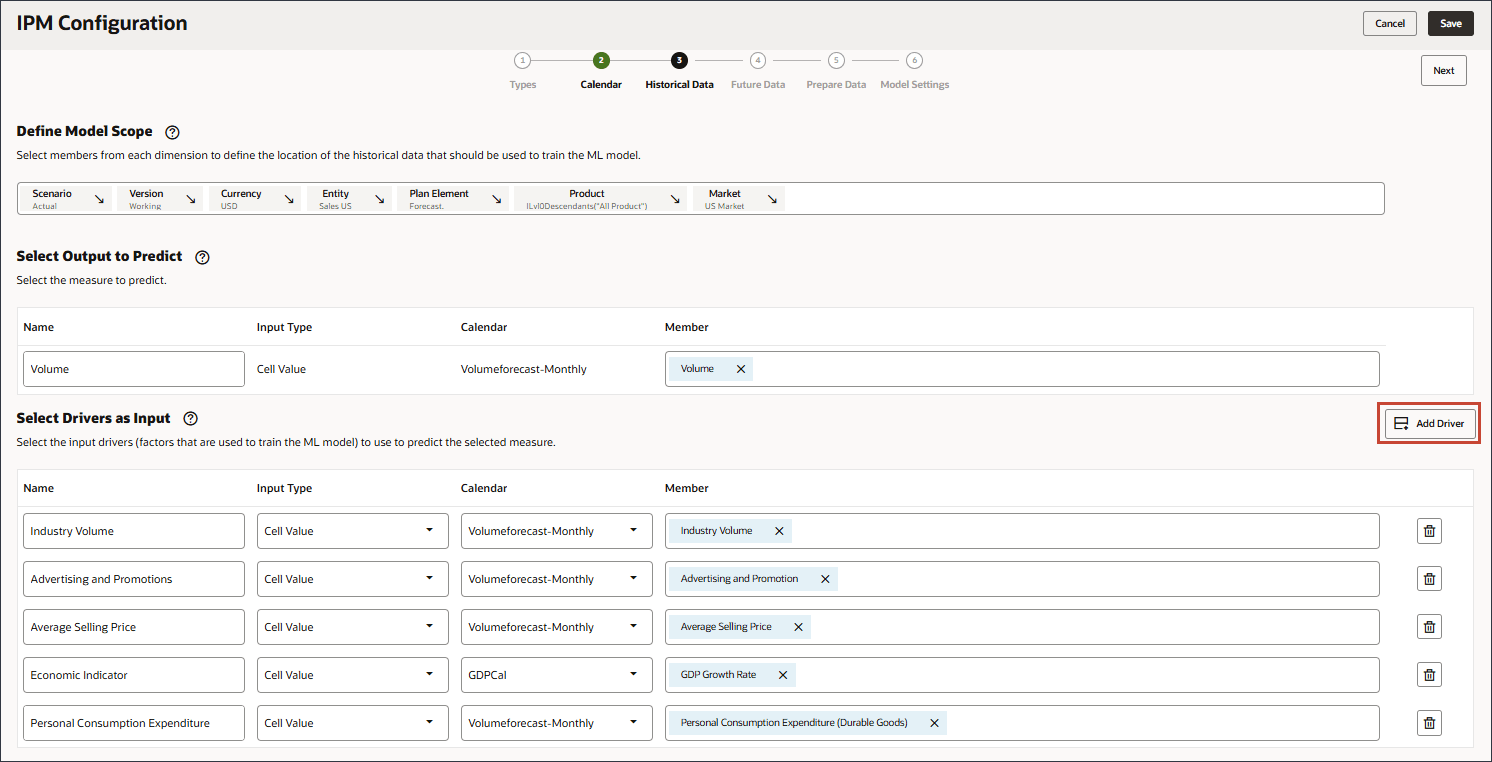
- 在“名称”中,输入折扣率,对于“折扣率”,在“成员”中,单击行业数量。
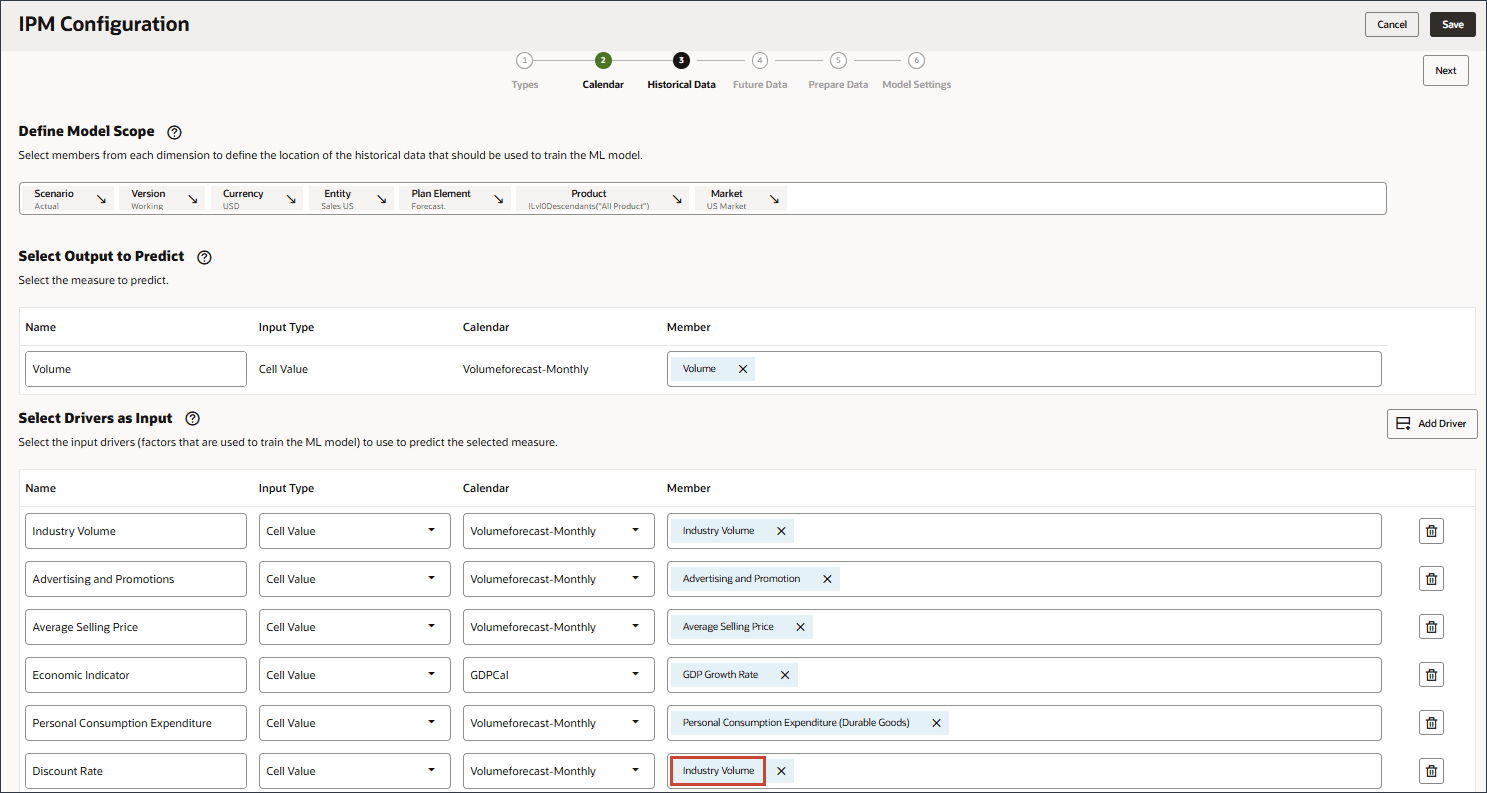
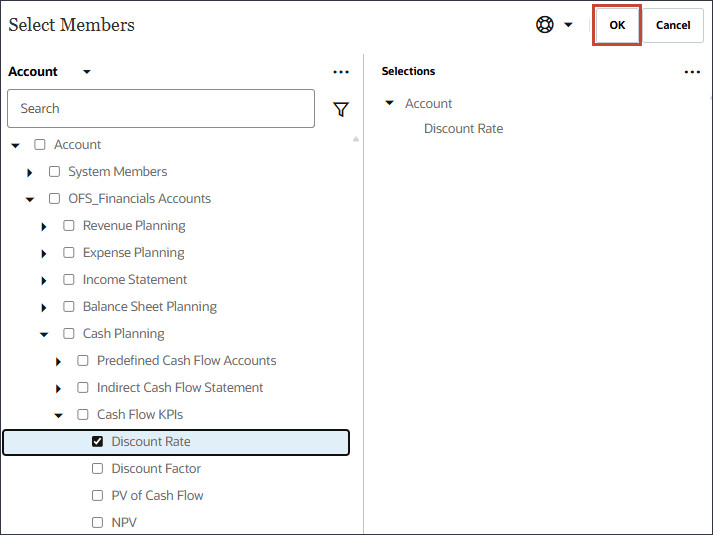
- 选择折扣率,然后单击确定。
提示:
请务必选择成员名称为 "OFS_Discount Rate" 的成员。此成员的别名是“折扣率”,名称中没有句点。 - 单击添加驱动程序。
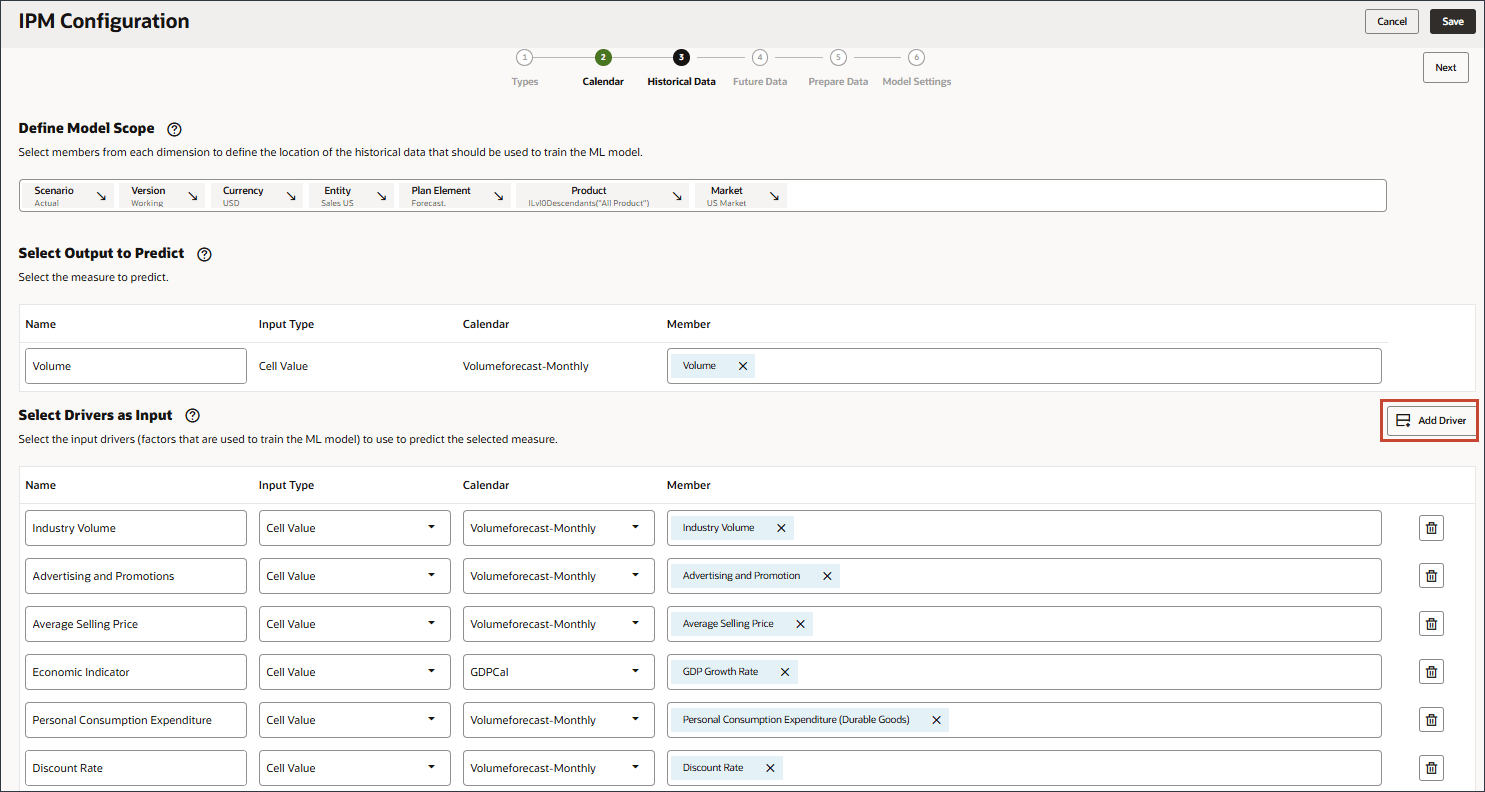
- 在“名称”中,输入附件,在“输入类型”中单击单元格值,然后选择智能列表。
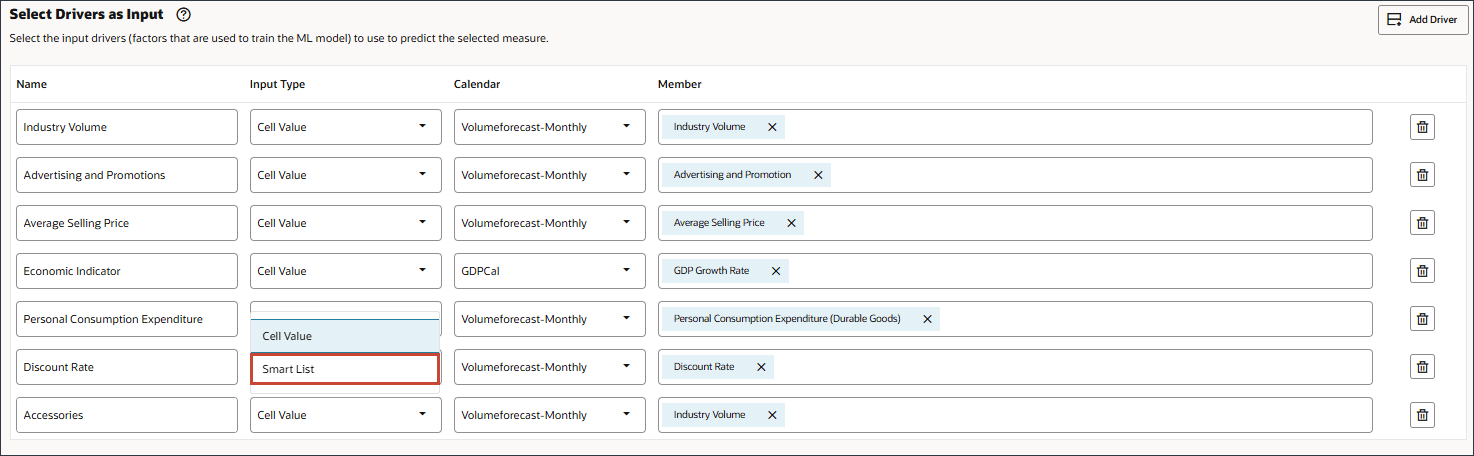
- 对于附件,请在成员中单击行业卷。
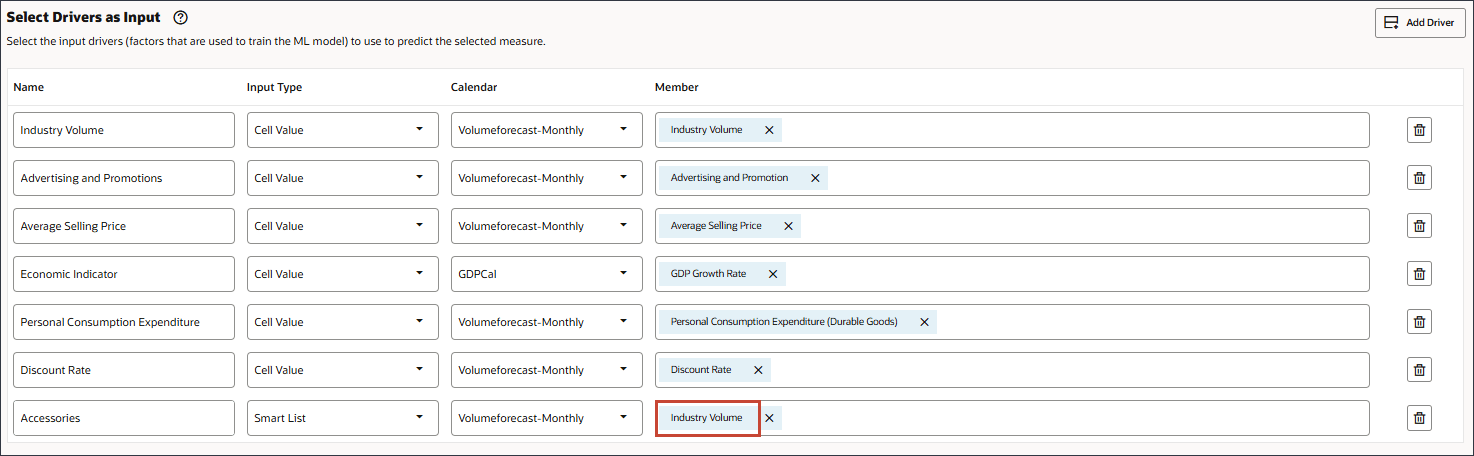
- 选择 Accessories(附件)。,然后单击 OK(确定)。
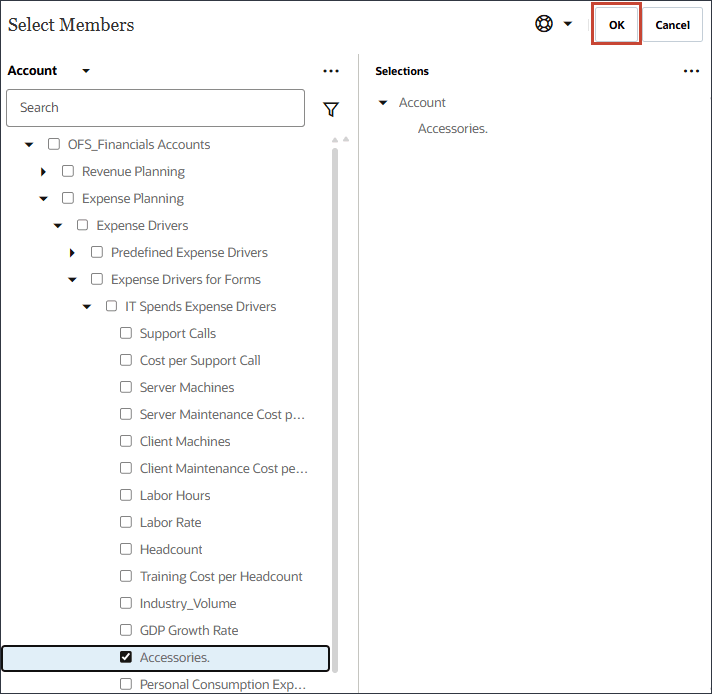
提示:
确保选择成员名称为“附件”的成员。成员名称和别名都相同,并且对于这两个名称都包括一个句点。 - 向上滚动并单击下一步。
为将来数据选择时段定义
在本节中,选择要将预测输出存储到的分片定义。默认情况下,您为历史数据设置的配置将结转到“将来数据”页面。您可以修改特定成员以定义未来数据的存在位置以及预测的存储位置。
- 在 POV 中,单击方案。
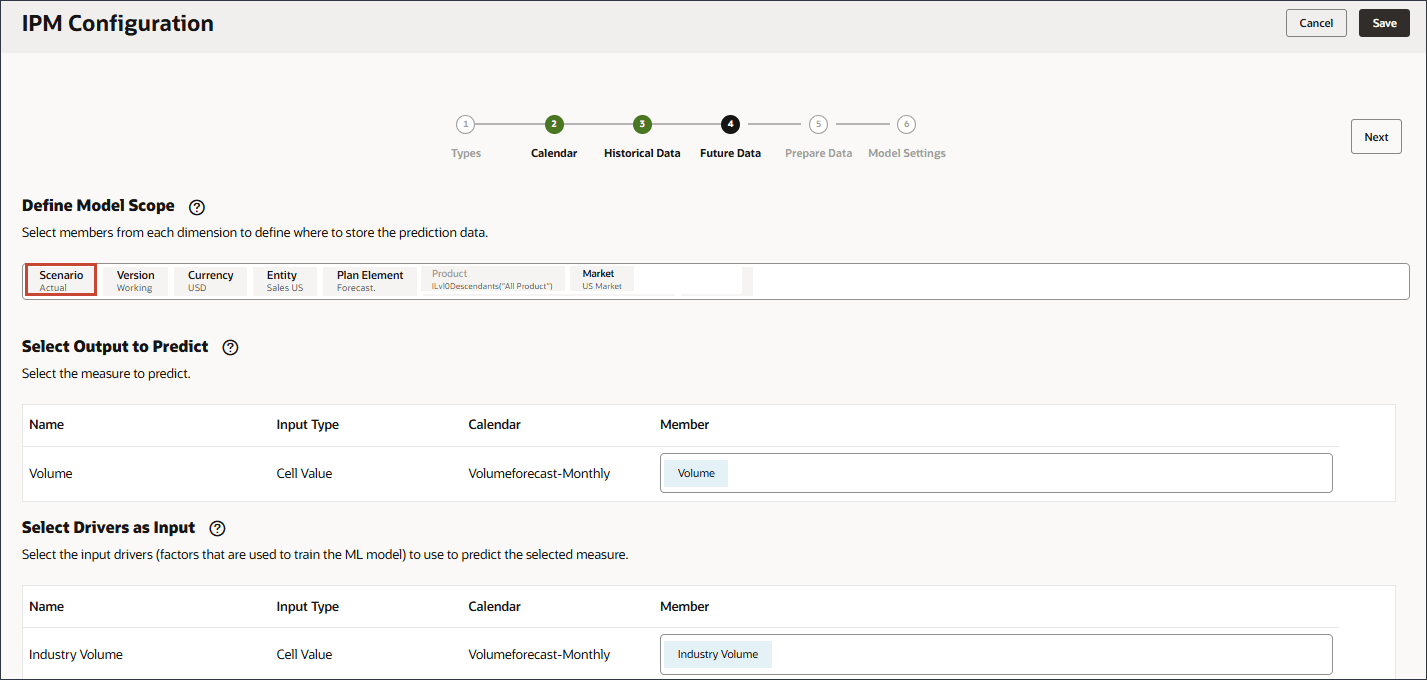
- 选择预测,然后单击确定。
不需要进行其他更改。输入和输出驱动程序相同
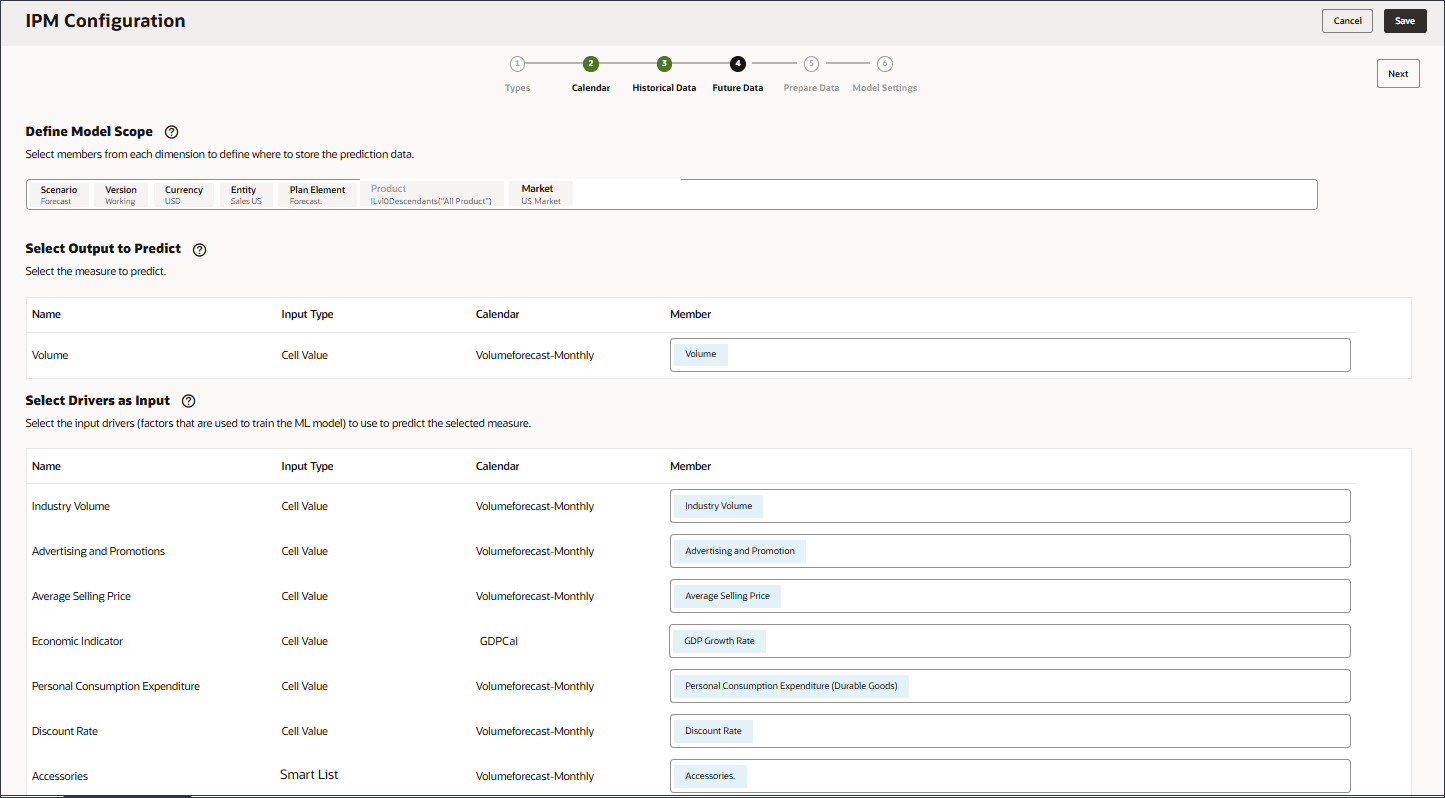
预测输出可以转至“预测”方案或要存储预测的任何方案。
- 单击下一步。
定义用于处理数据质量问题的方法
在数据准备阶段,您可以选择如何处理缺少的输入动因值。之前,您查看了输入动因,并注意到产品‘ eReader ’未来的动因数据值。
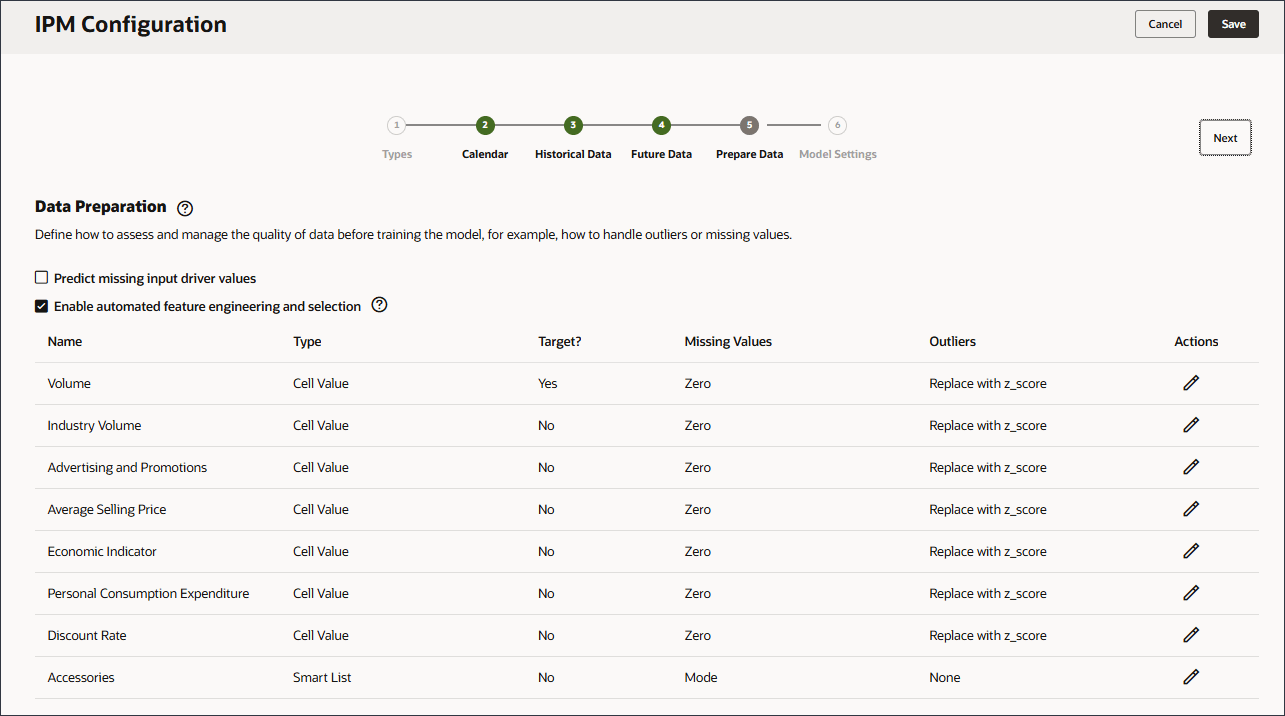
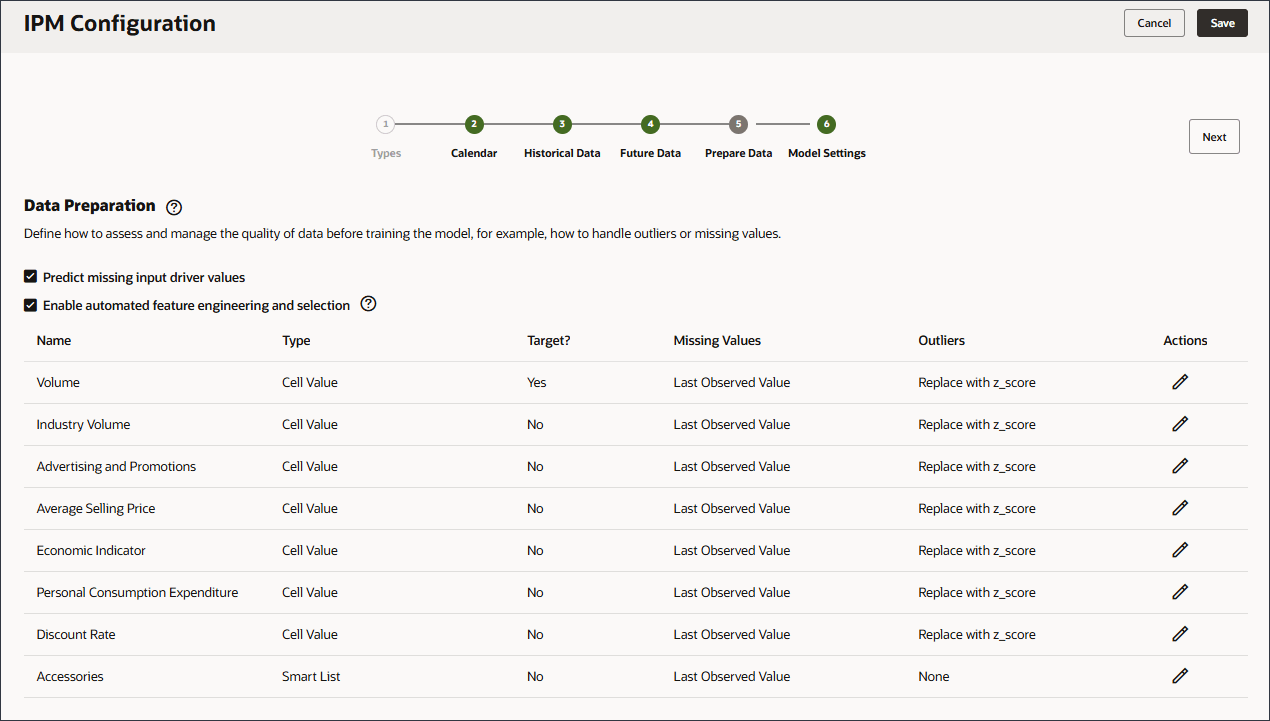
数据准备包括驱动程序名称、类型、目标、缺失值、异常值和操作列。
在训练模型之前,定义如何评估和管理数据质量,例如,如何处理离群值或缺少的值。
用于将值预测为缺失值的历史数据十分常见。数据可能由于一些原因而缺少值,包括测量失败、格式化问题、人为错误或缺少要记录的信息。提供了不同的填充选项来处理目标预测和相关数据集中的缺失值。填充是向数据集中缺少的条目添加标准值的过程。
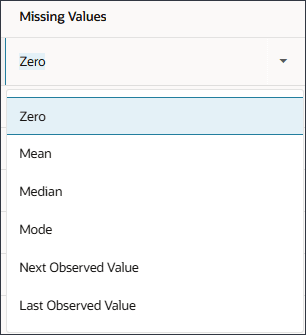
可以从以下选项中进行选择以替换缺少的值:
- 无:不执行任何操作(按原样发送数据)。
- 零:将任何列缺少的值替换为零。
- 用平均值替换(数字数据):在历史系列中替换为平均值。
- 替换为中位数(数字数据):替换为历史系列的中位数点。
- 替换为模式(数字和分类数据):替换为历史数据中最常用的值。
- 替换为下一个观察值:将缺少的值替换为下一个期间观察到的值。
- 替换为上次观察值:将缺少的值替换为上一期间观察到的值。
对于非正常值,定义系统是应将其替换为零、均值、z 分还是无。
可以选择以下选项来替换异常值:
- 无:没有要执行的异常处理。
- 替换为零:替换为 0。
- 替换为均值:替换为 K 个最接近值的均值。
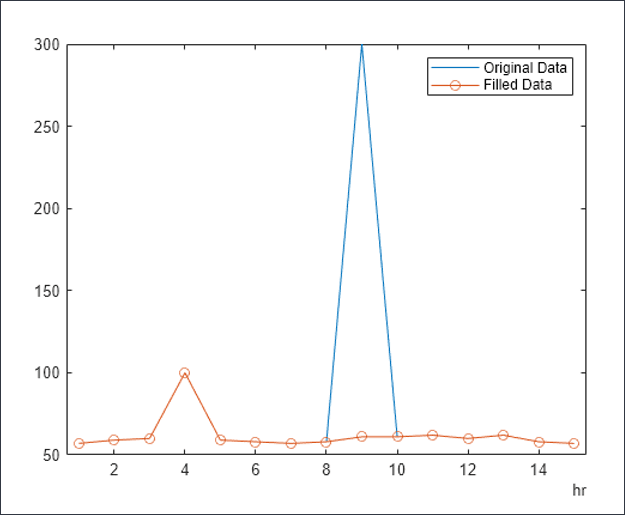
- 用 Z 分数替换:对于任何数值列,任何超出平均值 +/- 3* 标准偏差(标准偏差)的值都将视为异常值。小于 'mean - 3*std dev' 的值将替换为 'mean -3*std dev'。同样,大于 'mean + 3*std dev' 的值将替换为 'mean + 3*std dev'。
下图是用规范化值标识和替换的异常值的示例。
- 启用预测缺少的输入动因值。
通过启用“预测缺少的输入动因值”,将使用统计预测来预测值,即如果这些度量没有数据,则使用单变量预测来预测值。
- 对于缺少的值,请注意选项列表。
如果要修改缺失值的选择,请在“操作”列的驱动程序行中单击
 (操作)。
(操作)。 - 对于每个动因行,在“操作”中单击 (操作),然后在选项列表中,选择上次观察值。
- 对于非正常值,请注意选项列表。
如果要修改“异常值”的选择,请在“操作”列的驱动程序行中单击
(操作)。
提示:
更改每行的“缺少值”选项后,可以单击所有动因的缺失值均设置为“上次观察值”。
启用功能工程
在本节中,您将确保启用功能工程。
在高级预测中,使用特征工程查找输入动因与预测输出之间的隐藏关系。由预测任务自动创建的精心设计的功能,使模型能够捕获更相关的信息,从而提高模型性能和更好的预测。
功能工程是通过转换现有功能或创建新功能以提高模型性能来为机器学习准备数据的过程。
智能功能工程可根据定义的驱动程序创建功能。
借助功能工程,可以推导其他信息,从而实现更准确的预测。
应用的转换包括:
- 基于时间的功能。一周中的某一天是否会产生更多影响?
- 滞后效应。业务驱动因素对目标的滞后影响是什么,例如 5 月的市场营销支出对 7 月的销售量的影响?
- 聚合转换。例如,滚动平均值对业务驱动因素(而不是单个数据点)有何影响?
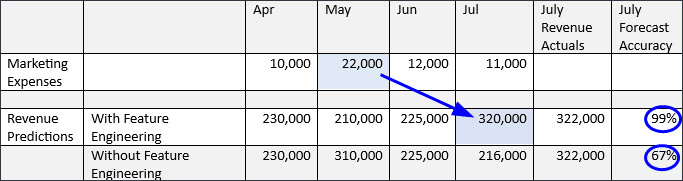
在下面的示例中,您可以看到业务驱动程序对目标的滞后影响。5 月的营销支出会影响 7 月的销售量。如果没有功能工程,7 月收入预测的准确率是 67%,但通过功能工程,7 月收入的准确率是 99%。
滞后效果
缺省情况下启用功能工程处理。
- 确认功能工程已启用。
- 单击下一步。
为模型设置选择算法
在此部分中,您可以为模型设置选择算法。
您可以选择 Oracle AutoML 或特定的算法,例如 Light GBM、XGBoost、Prophet 或 SARIMAX。
Oracle AutoMLx 是一个专有框架,用于执行以下操作:
- 对数据运行各种统计模型和机器学习算法
- 优化并验证模型
- 查找适合您数据的理想模型
- 将您的数据与最佳模型相匹配

您可以选择 Oracle AutoMLx、Light GBM、XGBoost、Prophet 和 SARIMAX 等各种算法之一。这些是可在全球范围内用于模型训练的最佳实践高级预测算法。根据下面的详细信息,AutoMLx 算法具有多个算法。
AutoMLx python 软件包会自动创建、优化和解释机器学习管道和模型。AutoML 管道提供了一个优化的 ML 管道,用于查找给定训练数据集的最佳模型和手头的预测任务。AutoML 具有简单的管道级 Python API,可通过准确优化的模型快速启动数据科学流程。AutoML 支持以下任一任务:
- AutoClassifier :使用表格数据集进行监督的分类或回归预测,其中目标可以分别是简单的二进制值、多类值或表中的实际值列。
- AutoRegressor :图像和文本数据集的监督分类。
- AutoAnomalyDetector :未提供目标或标签的无监督异常检测。
- AutoForecaster :单变量和多变量时间序列预测任务。
AutoML 管道由 ML 管道的五个主要阶段组成:预处理、算法选择、自适应采样、功能选择和模型优化。这些片段很容易组合成一个简单的 AutoML 管道,通过有限的用户输入/交互自动优化整个管道。
EPM 的 Advanced Prediction 在引擎盖下利用 AutoML 的 AutoForecaster 软件包。
AutoForecaster 中的算法列表:
- NaiveForecaster
- ThetaForecaster
- ExpSmoothForecaster
- ETSForecaster
- STLwESForecaster
- STLwARIMAForecaster
- SARIMAXForecaster - 多变量
- ExtraTreesForecaster - 多变量
- XGBForecaster (XG Boost) –多变量
- LGBMForecaster(光梯度提升机)–多变量
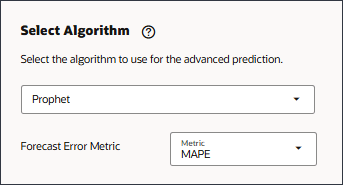
预测错误度量选择使用您选择的错误度量:
- RMSE :均方根误差
- MAPE :平均绝对误差百分比
- MAD :平均绝对偏差
预测错误度量选择错误最小的模型作为最佳模型。
对于最佳模型:
- 生成与输入系列对应的拟合系列。
- 生成展望期的预测。
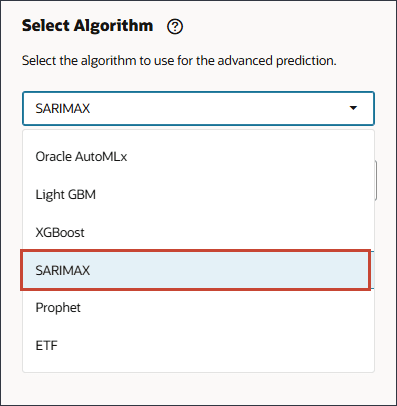
- 在“选择算法”中,单击下拉列表以查看选择,然后选择 SARIMAX 。
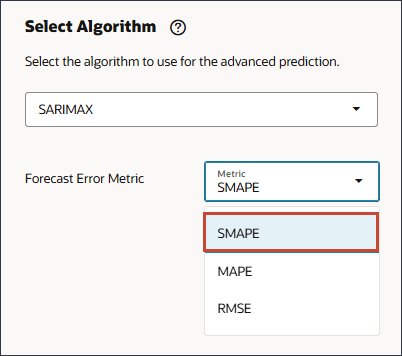
- 对于“预测错误度量”,对于“度量”,选择 SMAPE 。
为模型设置选择置信区间
在此部分中,您将选择要优化的置信区间和度量。
根据置信区间设置,系统会生成多个高级预测方案,并根据在此模型设置中提供的方案存储结果。
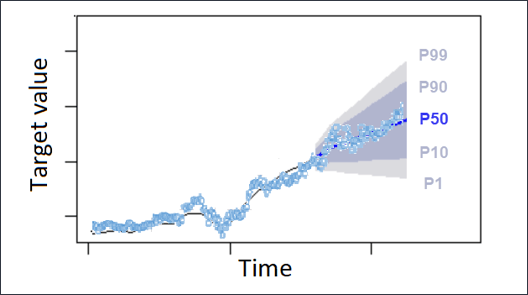
- 预测的置信区间可以为预测的输出值提供上限和下限。
- 例如,使用 10% (P10) 和 90% (P90) 的置信区间可提供称为 80% 置信区间的值范围。观察到的值预计低于 P10 值 10% 的时间,而 P90 值预计高于 90% 的时间观察到的值。
- 通过在 P10 和 P90 生成预测,可以预期真实值会在 80% 的时间范围内。此值范围由下图中 P10 和 P90 之间的阴影区域描述。
- 在“模型设置”页的“置信区间”中,选择生成置信区间。
- 对于“预测间隔”,保留“最佳情况”、“最差情况”和“拟合”值预测的默认设置。
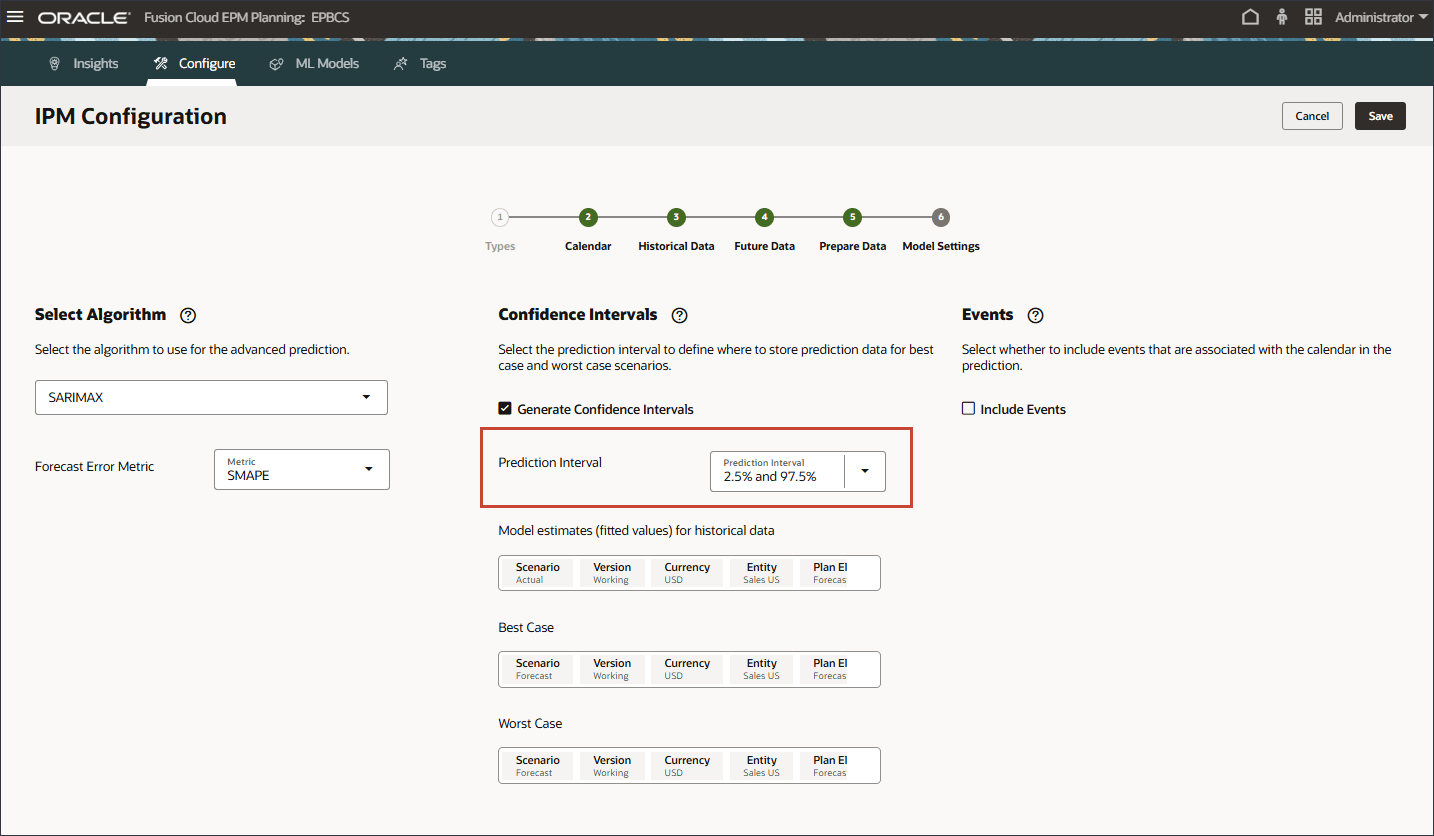
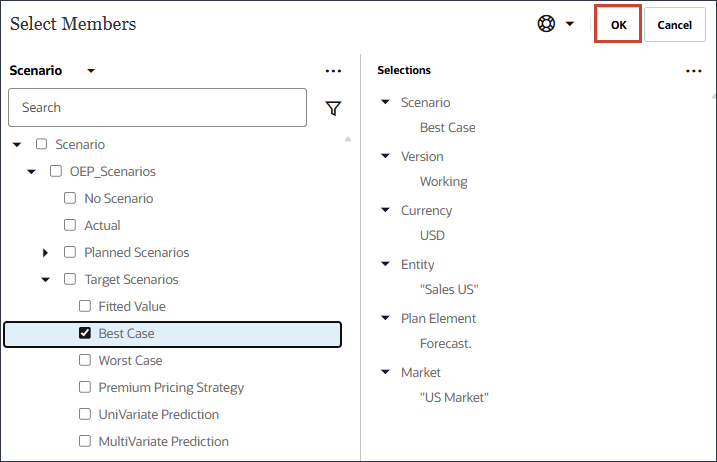
- 在历史数据的模型估计(拟合值)中,单击方案。
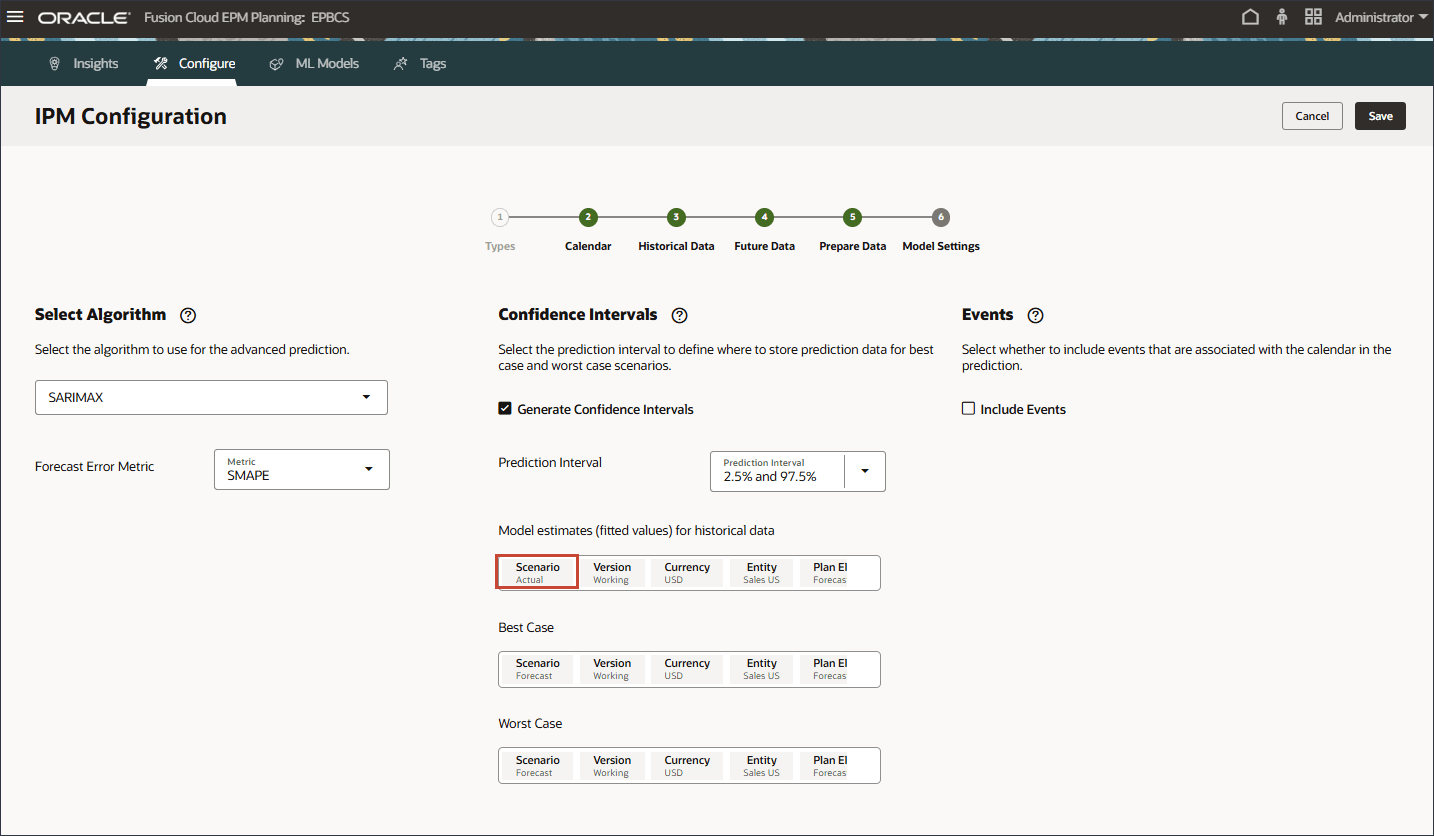
- 对于方案,选择拟合值,然后单击确定。
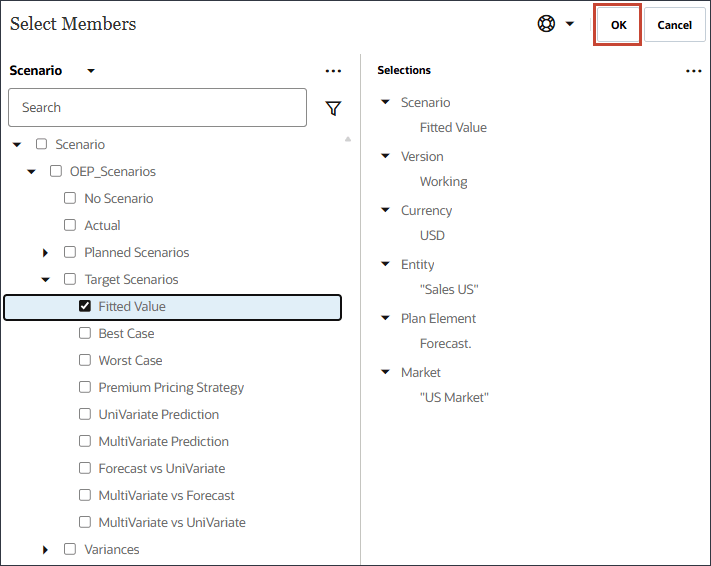
- 在“最佳情况”中,单击方案。
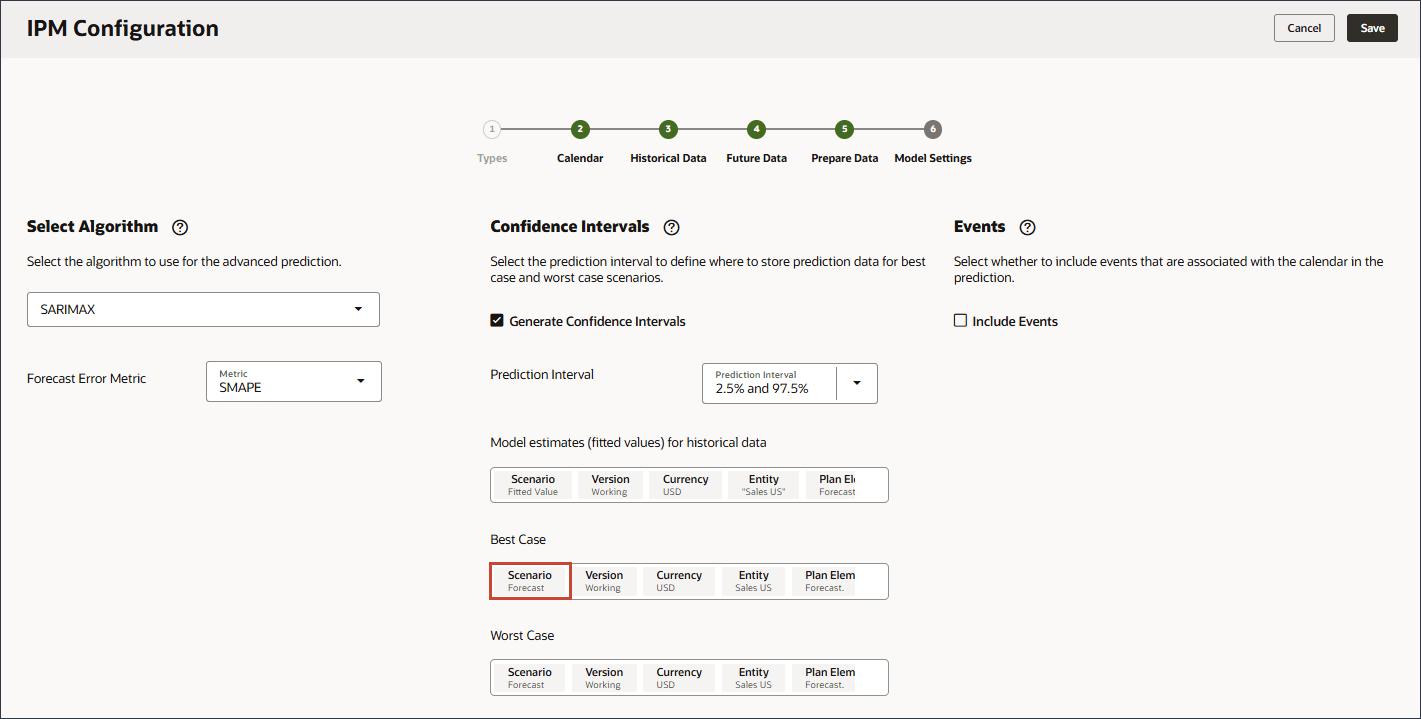
- 对于方案,选择最佳情况,然后单击确定。
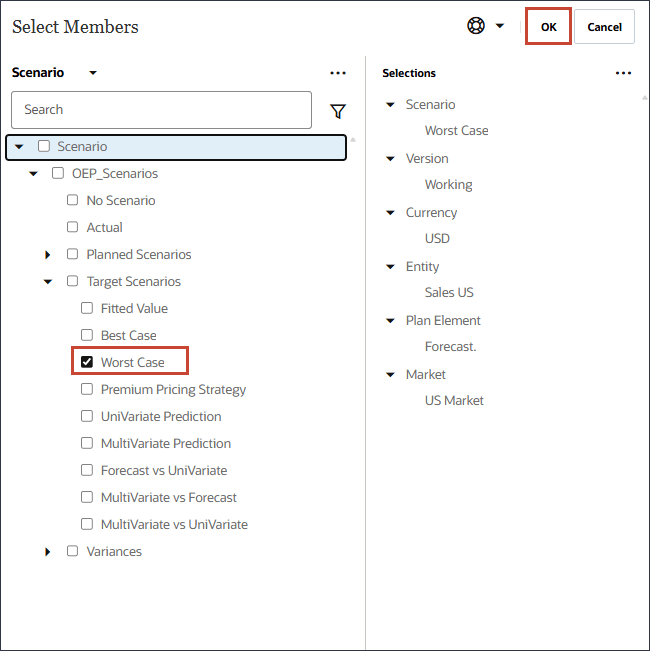
- 在“最差情况”中,单击方案。
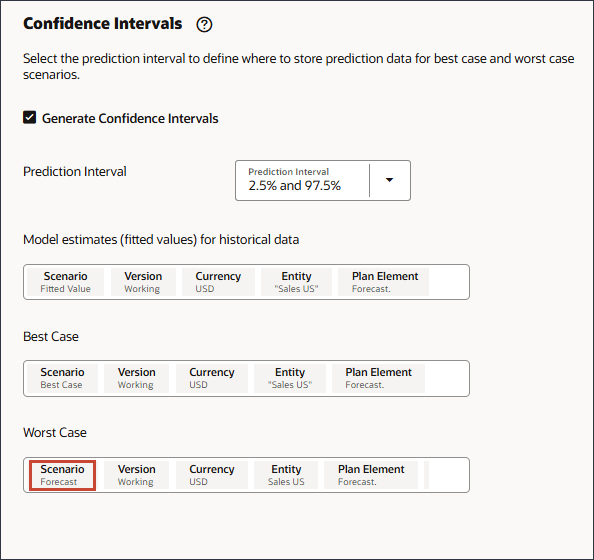
- 对于方案,选择最坏情况,然后单击确定。
选择事件
在此部分中,您可以选择是否在预测中包括事件。
您可以在预测中包括事件。如果您希望将发生并影响过去数据的某些事件考虑为预测,可以使用事件进行高级调优并提高准确性。这些事件可以包括:
- 同一期间(例如圣诞节)的重复事件
- 不同时期的重复事件,如斋月
- 一次性事件,如飓风
- 跳过疫情等事件
- 在右侧的“事件”下,选择包括事件。
- 单击保存。
此时将显示一条信息消息。

- 单击取消。
此时将显示新的高级预测作业。
添加事件
在此部分中,您将为 5 月 22 日、7 月 23 日和 9 月 24 日期间添加新的营销活动事件。虽然 May-22 和 Jul-23 是实际期间,但 Sep-24 是计划进行营销活动的未来预测期间。这一事件基本上表明,前几年 5 月和 7 月发生的同一事件也计划在未来一年 9 月发生。
- 单击事件选项卡。
- 单击 Add Event(添加事件)。
- 对于新事件,输入或选择以下信息:
列 值 名称 商业活动 说明 商业活动 类型 重复 日历 批量预测 - 每月 持续时间 1 “营销活动”事件的类型为“重复”,它基于“批量预测 - 每月”日历。

- 对于发生次数,单击
 (事件发生次数)。
(事件发生次数)。
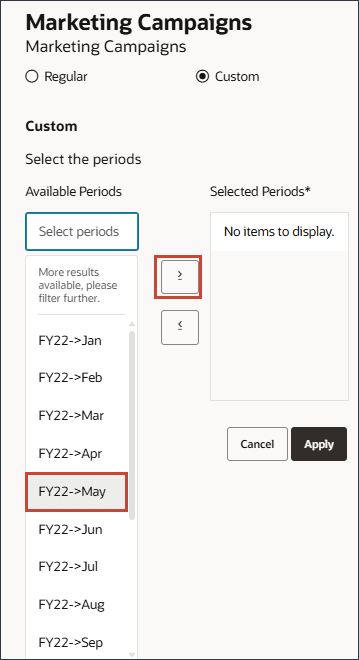
- 选择自定义,然后单击选择期间。
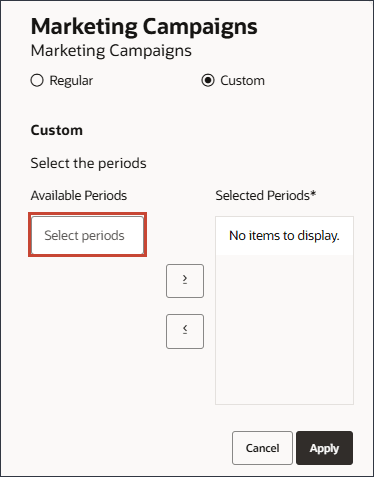
- 对于期间,选择 May FY22 ,然后将其移至选定的期间。
- 在左侧,单击期间区域,然后键入 FY23 。
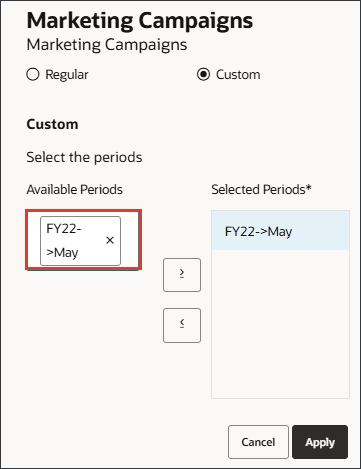
此时将显示一个搜索框。
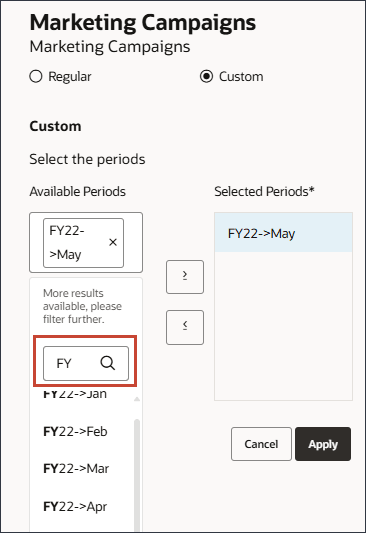
- 选择 7 月 FY23 日。
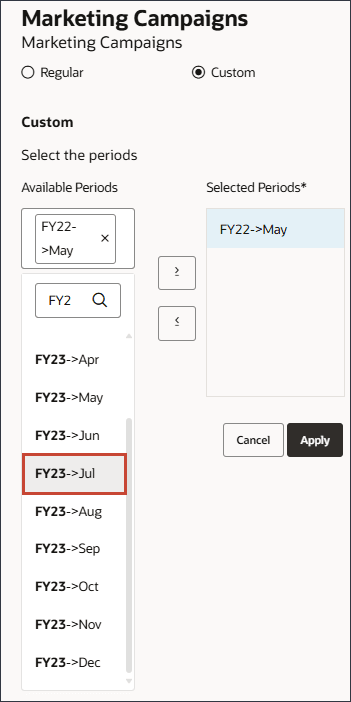
- 单击“可用期间”区域,然后键入 FY24 ,然后选择 9 月 FY24 。
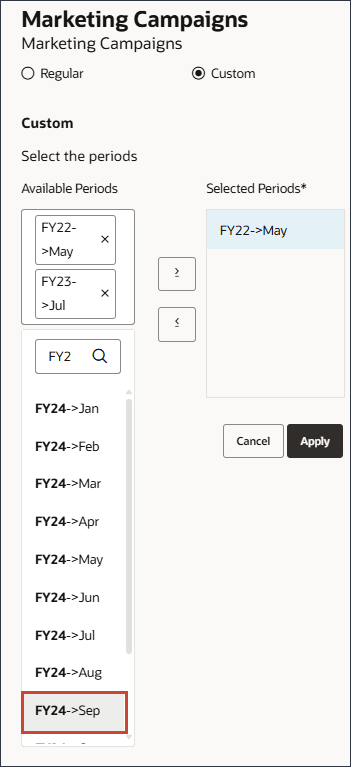
- 将所有期间移至选定的期间。
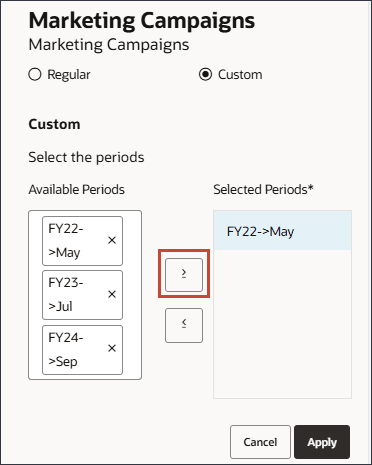
- 单击应用。
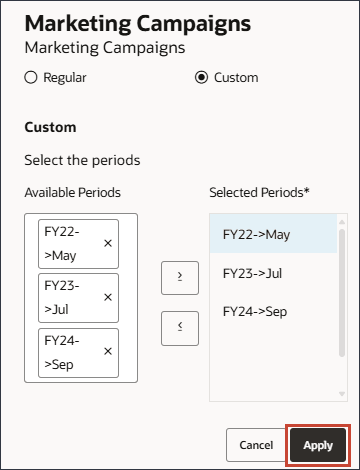
- 在新事件行右侧,单击
 (保存)。
(保存)。
- 单击 (主页)以返回到主页。
查看广告和促销成本及销售量
在本节中,您将查看 2022 年 5 月和 2023 年 7 月广告和促销成本和销售量的实际数据,以了解动因与输出之间的相关性。您还将查看未来的 2024 年 9 月驱动程序数据。
- 在主页上,依次单击高级预测和批量预测。
- 选择输入驱动程序选项卡。
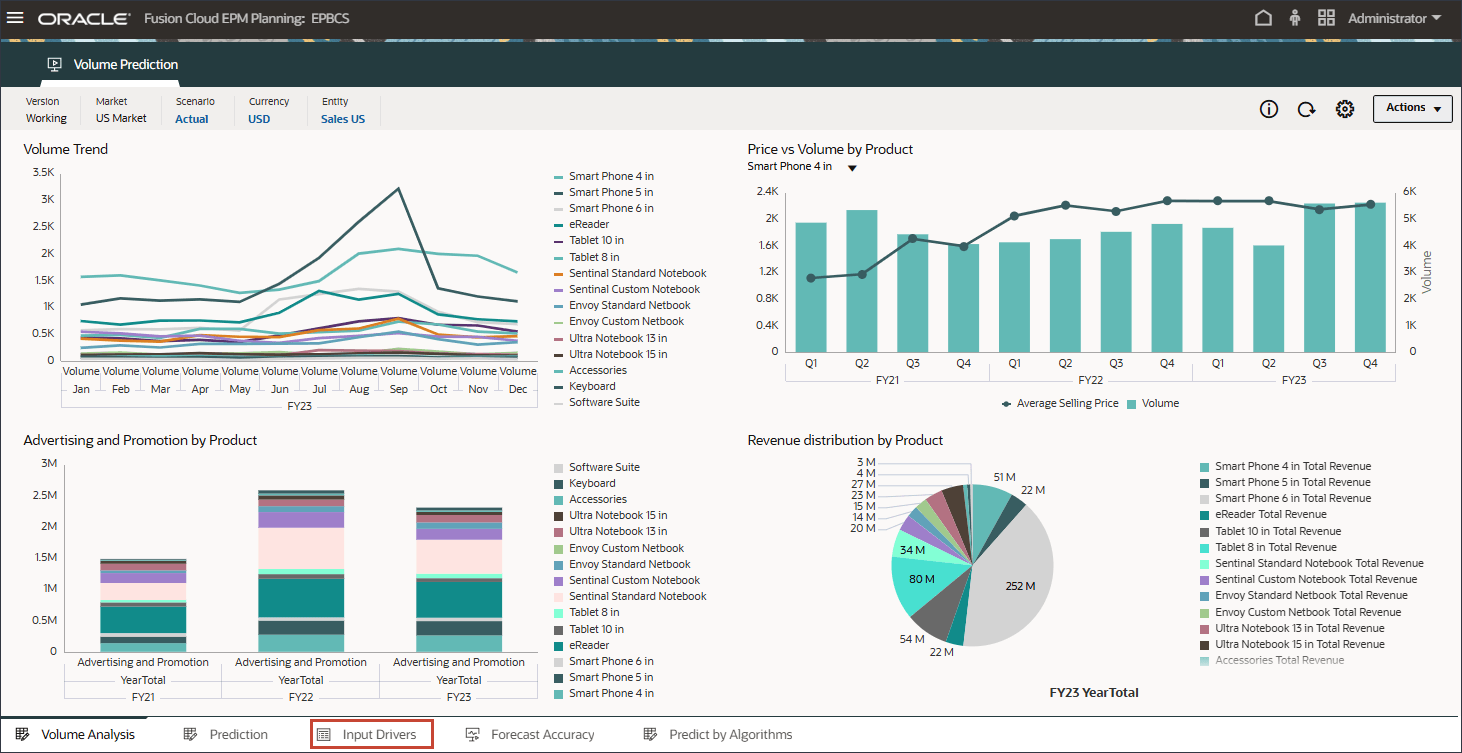
- 在 POV 中,单击帐户,然后选择广告和促销。
- 对于 5 月 22 日和 7 月 23 日,数据将累计到这些月份。
对于将来的 2024 年 9 月数据,系统应自动提升预测结果,因为配置作业中启用了事件。
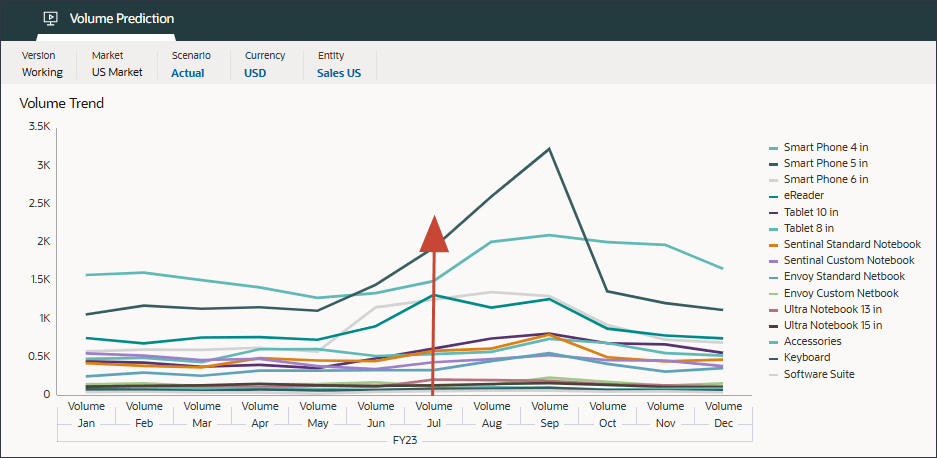
- 在页面底部,单击批量分析选项卡。
“数量”分析图表显示,由于市场营销活动事件,2023 年 7 月的数量数据被累计。
- 单击 (主页)以返回到主页。
运行高级预测作业
在此部分中,您将运行“高级预测”作业以生成预测。
- 在主页上,单击 IPM ,然后选择配置。
- 在底部,选择 IPM 选项卡。
- 对于销售量预测,在右侧单击 (操作),然后选择运行。
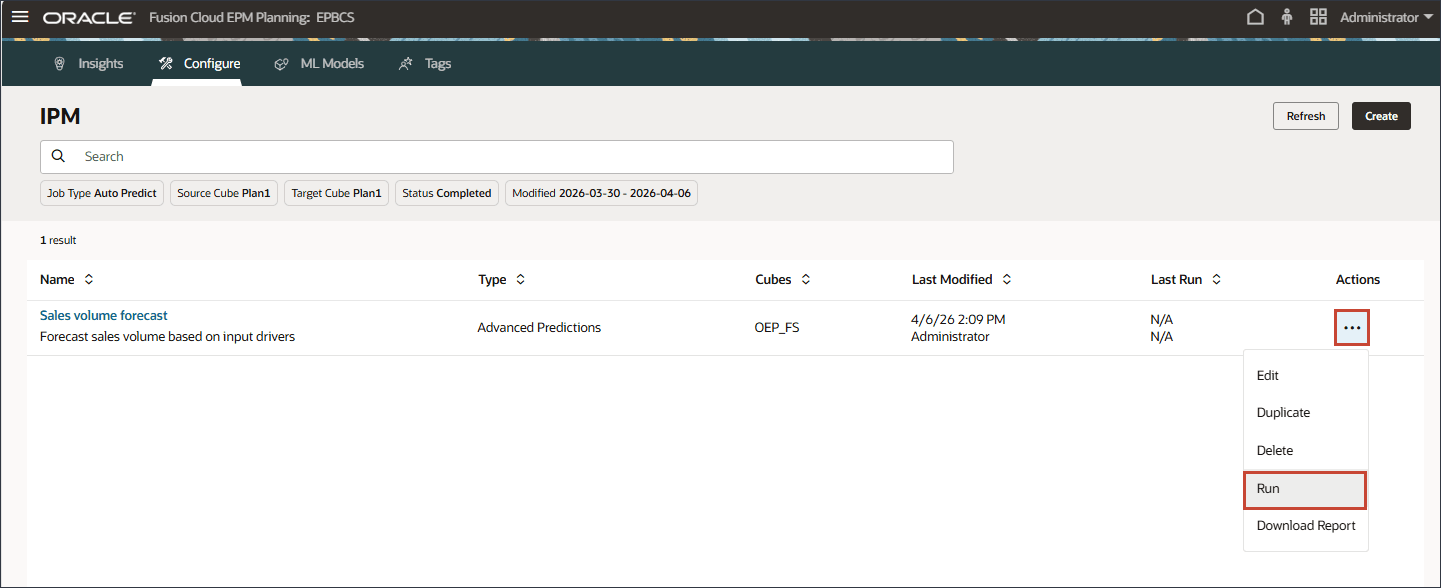
在 "IPM" 页面上,您可以运行高级预测作业、监视作业的状态、查看错误日志并根据需要对配置进行更改。
- 运行作业后,将显示一条信息消息,通知您作业已成功启动。

在具有日期和时间的“上次运行”列中,可以查看当前状态。提交作业后,"Processing"(正在处理)将显示状态。
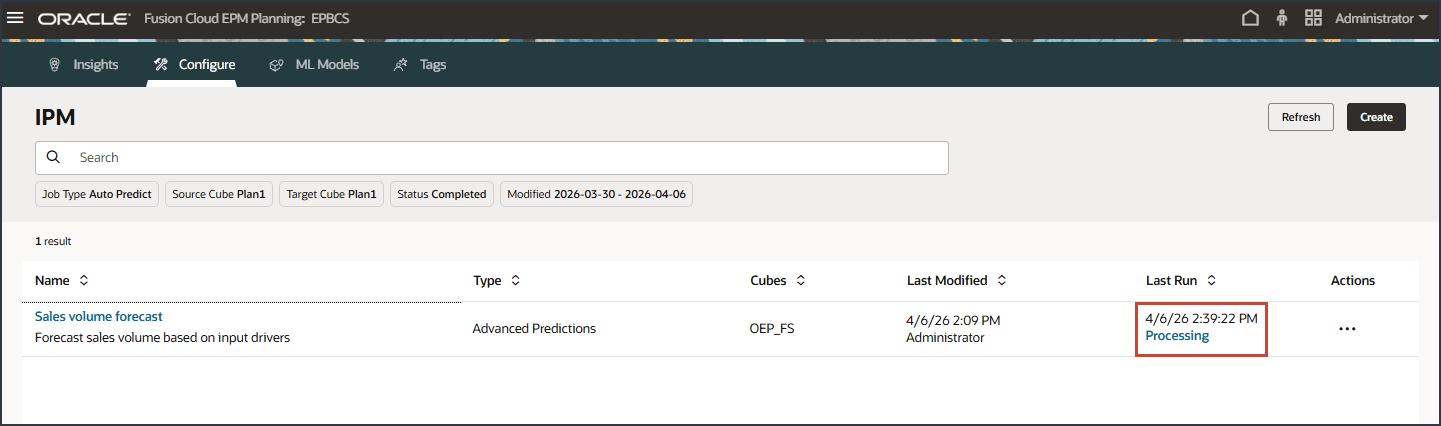
- 在 "IPM" 页面上,单击刷新以更新作业状态。
- 单击
 (导航器),然后在“Application(应用程序)”下单击 Jobs(作业)。
(导航器),然后在“Application(应用程序)”下单击 Jobs(作业)。
- 在“作业”页上,单击销售量预测。

在内部触发了多个作业以生成预测。
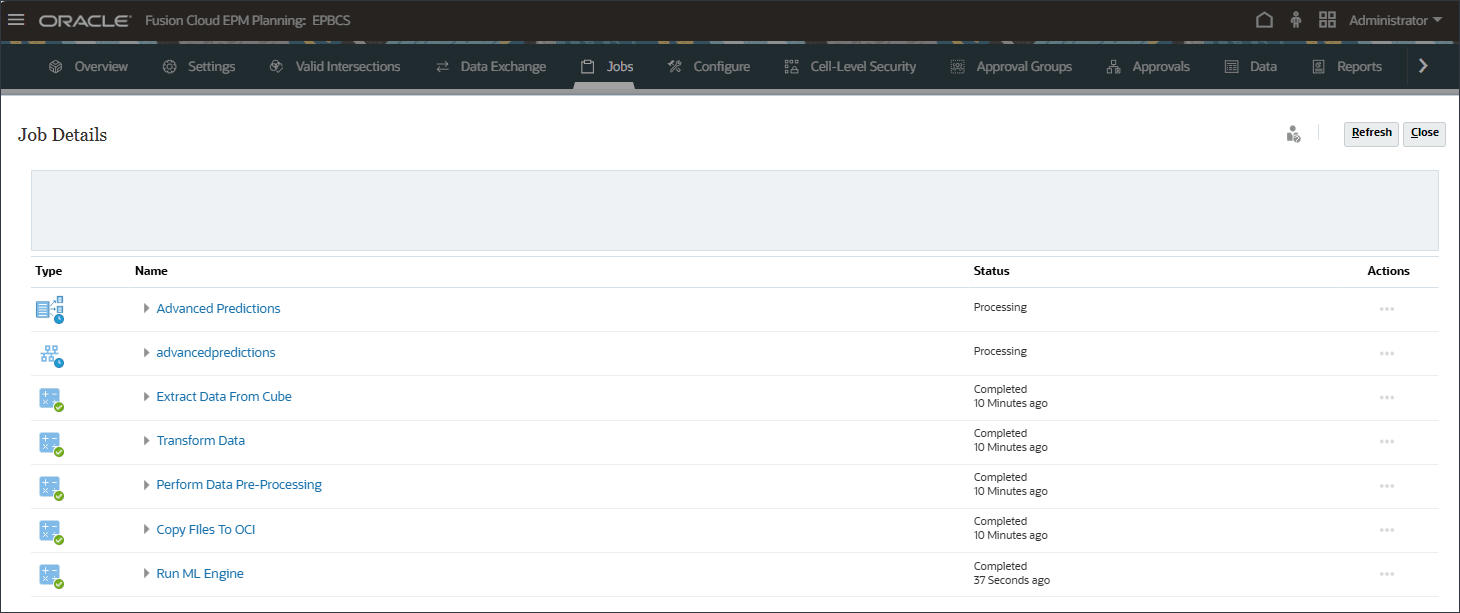
只需单击一下,系统即可测试多种算法,包括指数平滑、ARIMA 和回归模型,然后显示最准确的统计预测。这使计划员能够在几秒钟内生成数据驱动的预测,从而取代了数小时的人工分析。
- 等待所有高级预测作业成功完成,然后单击关闭。
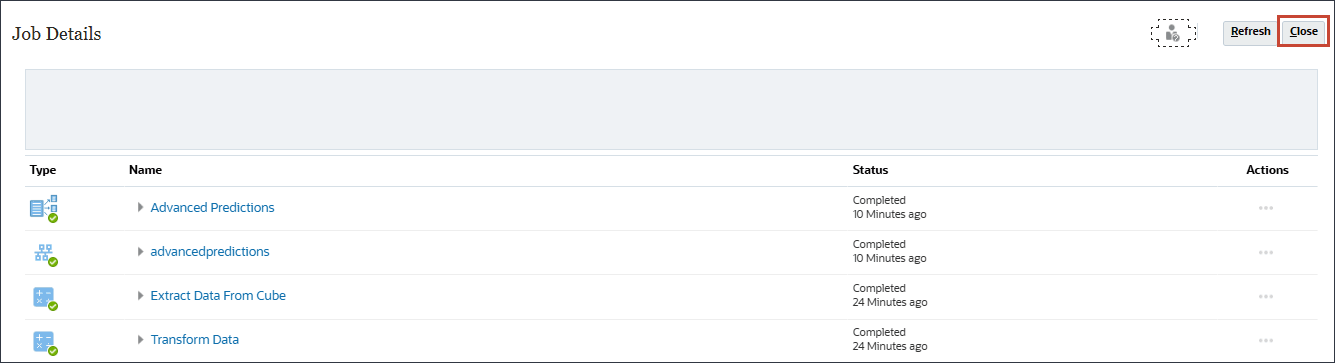
- 单击刷新。
- 单击 (导航器),然后在 IPM 下单击配置。
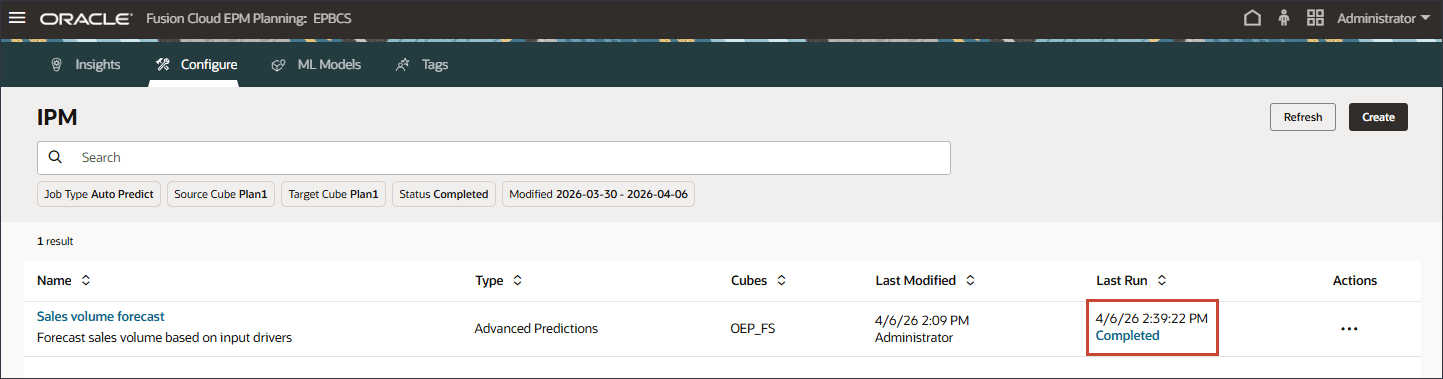
已成功完成销售量预测。
- 作业成功完成后,您可以下载报表并查看预测结果。对于销售量预测,单击右侧的 (操作),然后选择下载报告。
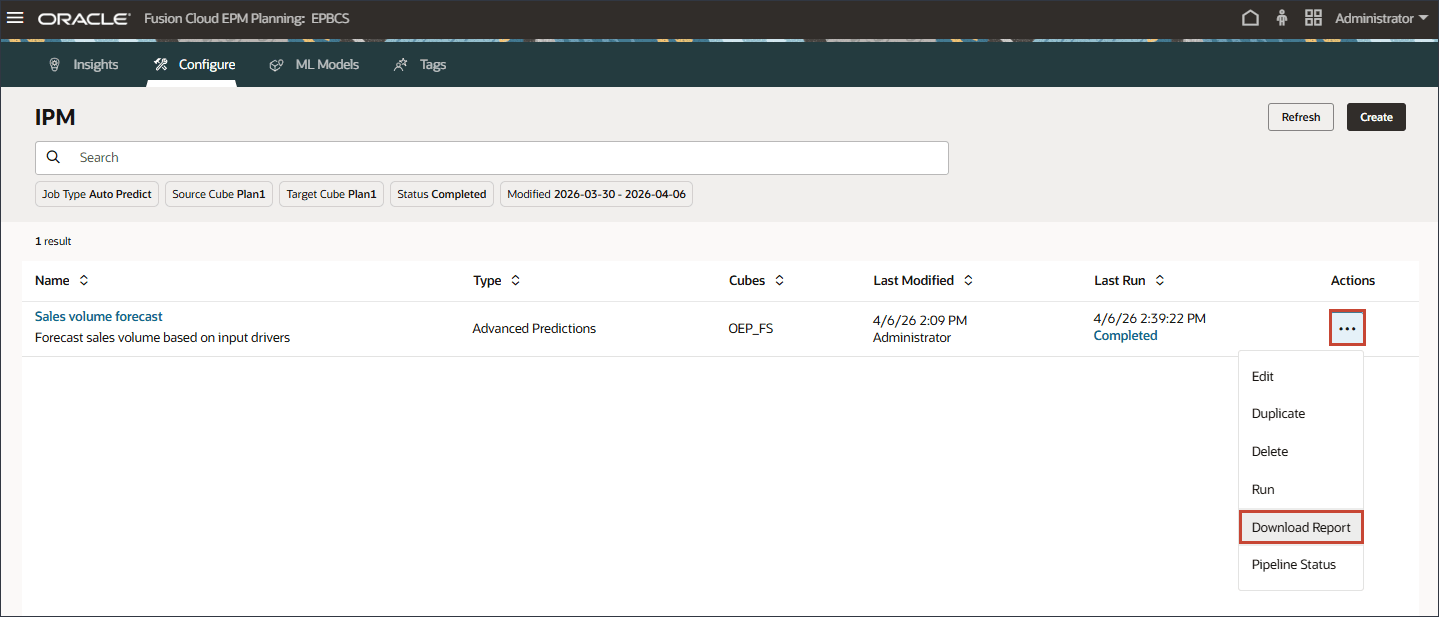
下载报告是一个 zip 文件,其中包含一个 .csv 文件,其中包含与高级预测作业相关的所有详细信息。您可以查看此示例销售量预测报表。
下面是报表中的示例。
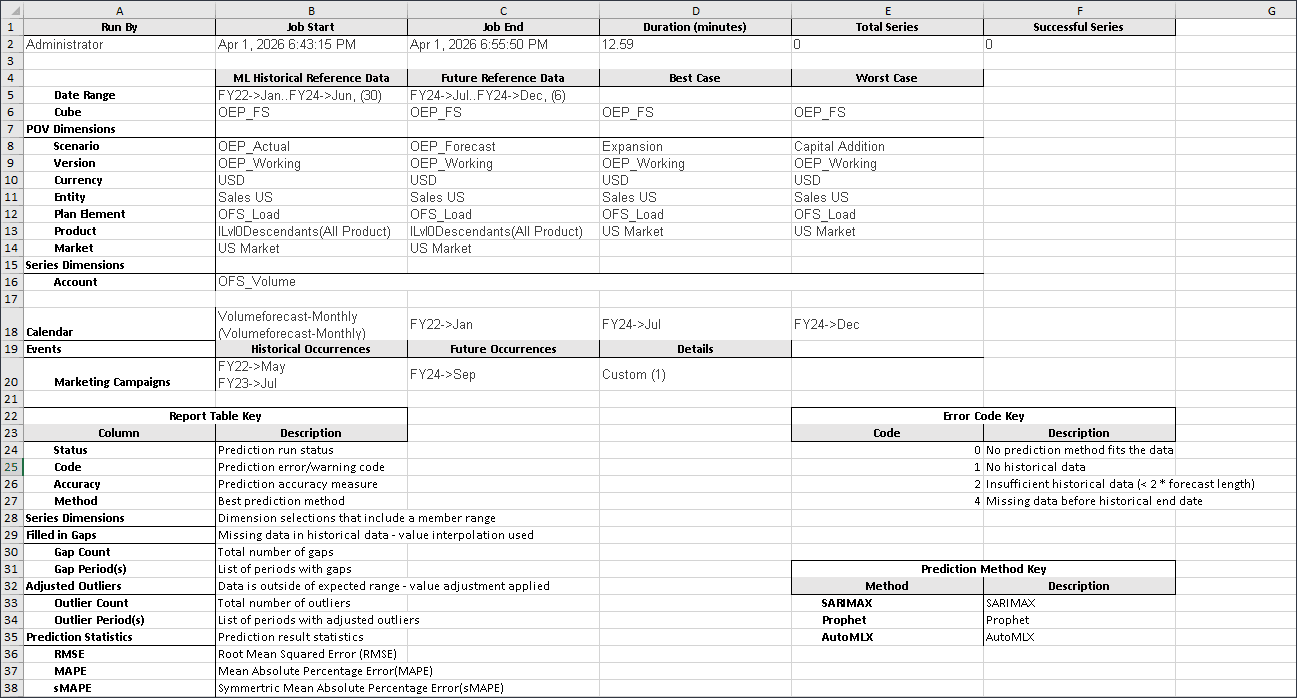
- 单击 (主页)以返回到主页。
注意:
这项工作需要几分钟才能完成。注意:
这项工作需要几分钟才能完成。主作业已成功完成。
检查高级预测结果
检查批量预测预测结果
在此部分中,您将查看批量预测预测结果。您希望确保使用“输入”功能“预测所有输入动因账户的缺少输入动因值”预测 eReader 产品类别未来值。
- 在主页上,单击 Advanced Predictions(高级预测),然后选择 Volume Prediction(批量预测)。
- 在底部,单击输入驱动程序选项卡。
- 在 POV 中,对于帐户,选择行业卷。
- 向右滚动。
在高级预测作业中使用估算功能(“预测缺少输入动因值”)预测未来行业数据量(7 月至 12 月 FY24)。
- 在 POV 中,对于帐户,选择广告和促销。
广告和促销数据(7 月至 12 月,FY24)是使用高级预测作业中的置入功能(“预测缺少输入驱动程序值”)进行预测的。
- 在 POV 中,为帐户选择平均销售价格。
在高级预测作业中使用置换功能(“Predict missing input driver values”)预测平均销售价格(7 月至 12 月 FY24)。
- 在 POV 中,为帐户选择个人消耗量支出(耐用品)。
在“高级”预测作业中使用置换功能(“预测缺少输入动因值”)预测了个人消耗量支出(耐用品)(7 月至 12 月 FY24)。
- 在 POV 中,对于帐户,选择折扣率。
折扣率(7 月至 12 月,FY24)是使用高级预测作业中的估算功能(“预测缺少输入动因值”)进行预测的。
- 在 POV 中,对于帐户,选择附件。
附件(7 月至 12 月,FY24)是使用高级预测作业中的置入功能(“预测缺少输入驱动程序值”)进行预测的。
查看目标变量的预测结果
在此部分中,您将查看目标变量的预测结果,即产品销售量。您还可以查看可解释性,并查看功能重要性。

- 在底部,单击预测选项卡。
此时将显示 "Volume Prediction" 仪表盘。
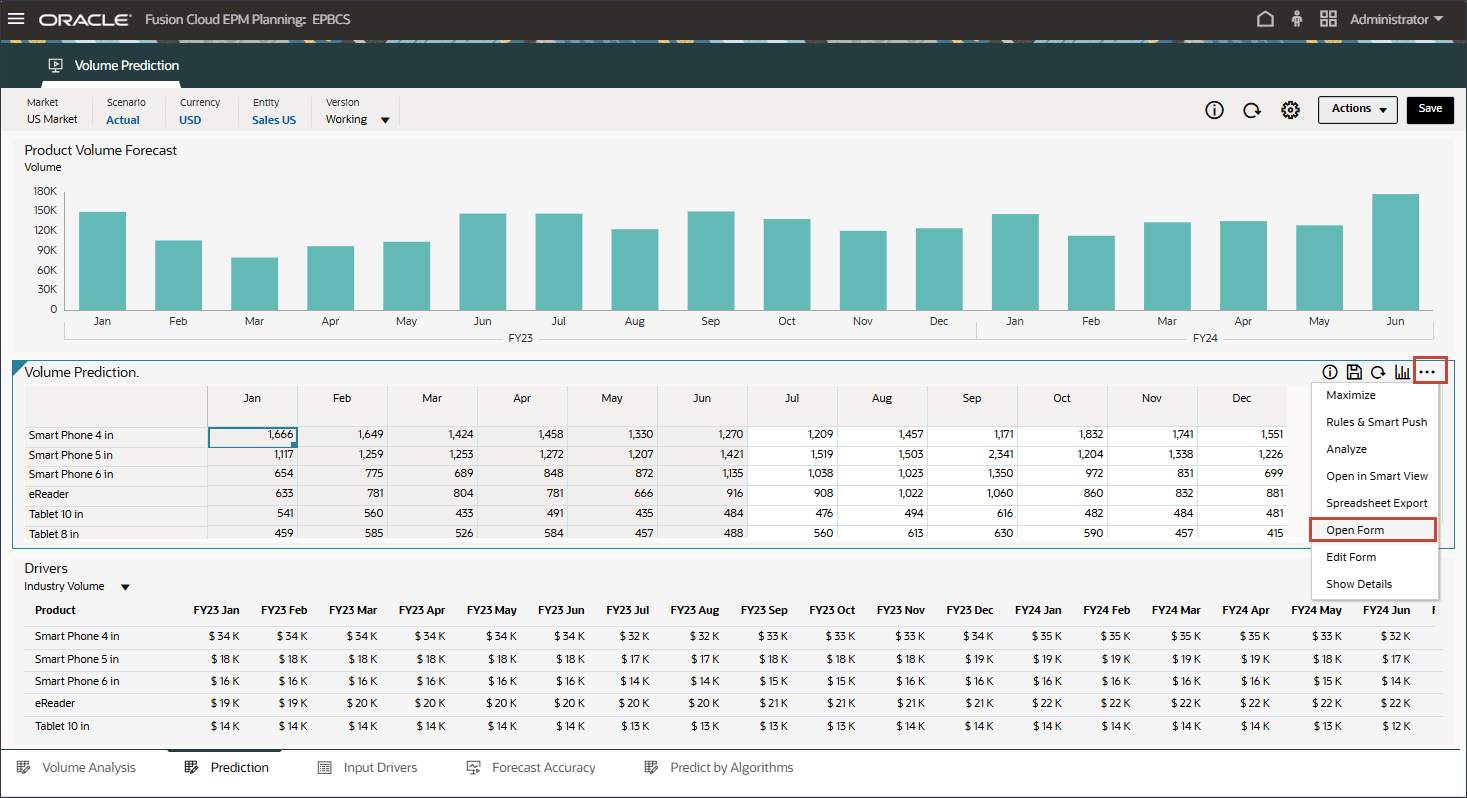
- 在“卷预测”表单的中间,单击 (操作),然后选择打开表单。
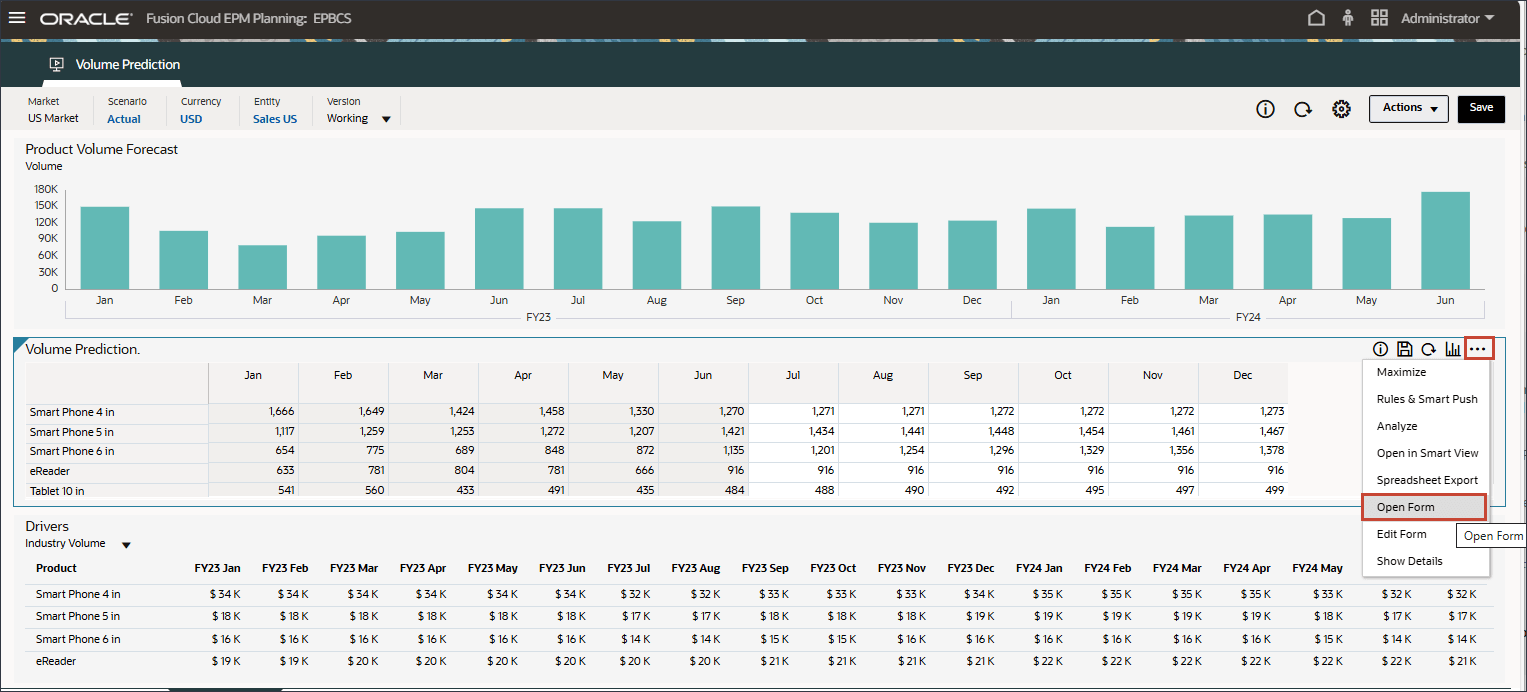
高级预测结果使用在 IPM 作业中配置的 SARIMAX 算法在 2024 财年 7 月至 12 月生成。
- 在 POV 中,单击实际。
- 在 OEP_Scenarios and Planned Scenarios 下,选择预测,然后单击确定。
此时将显示预测数据。
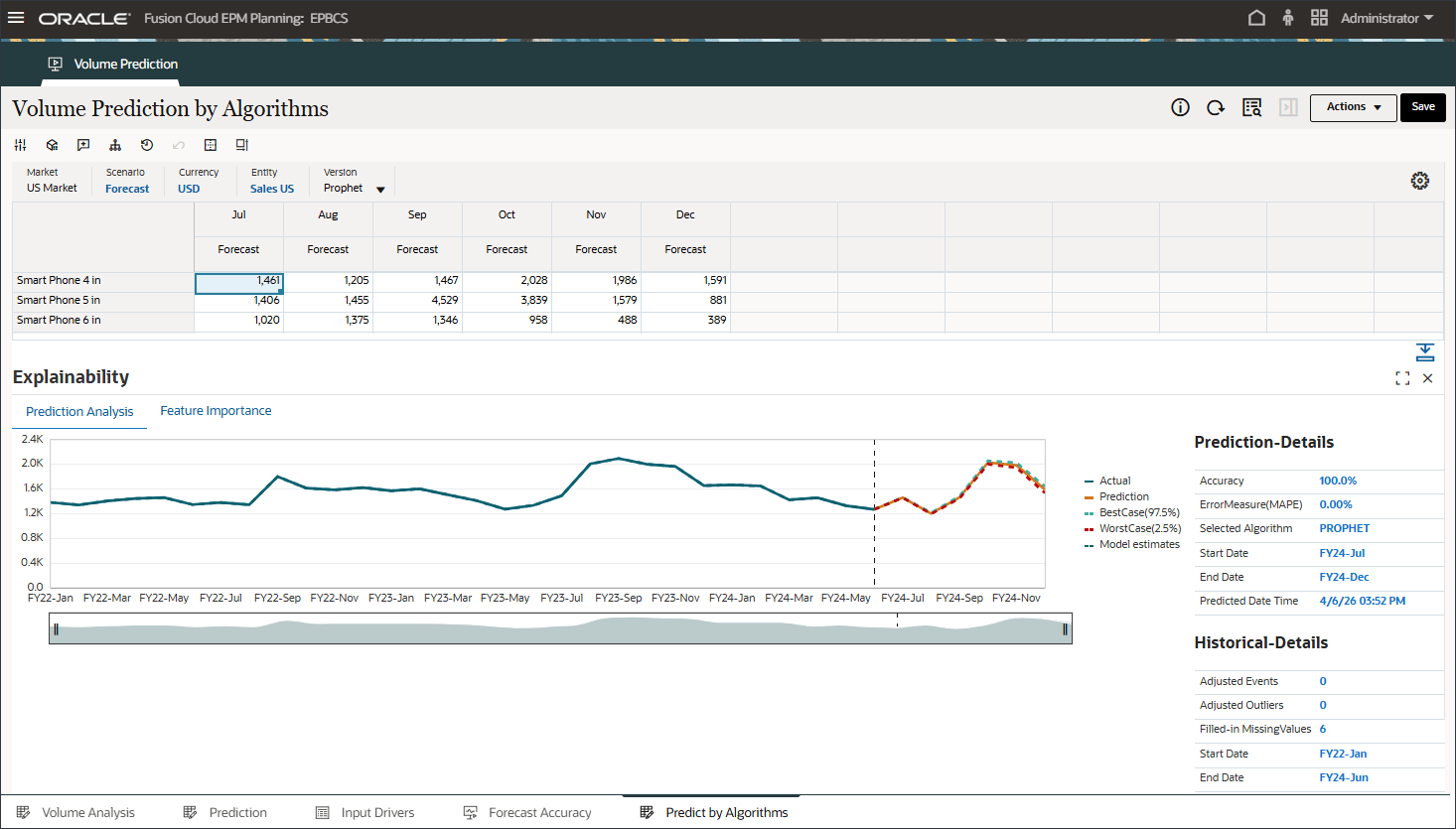
- 要查看更多详细信息并查看预测结果的说明,请在任意期间(例如 7 月 5 日)右键单击,然后选择解释预测。
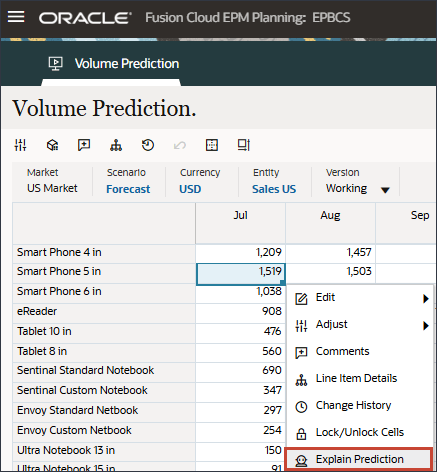
选择“解释预测”时,您可以查看在两个选项卡上具有信息的可解释性。
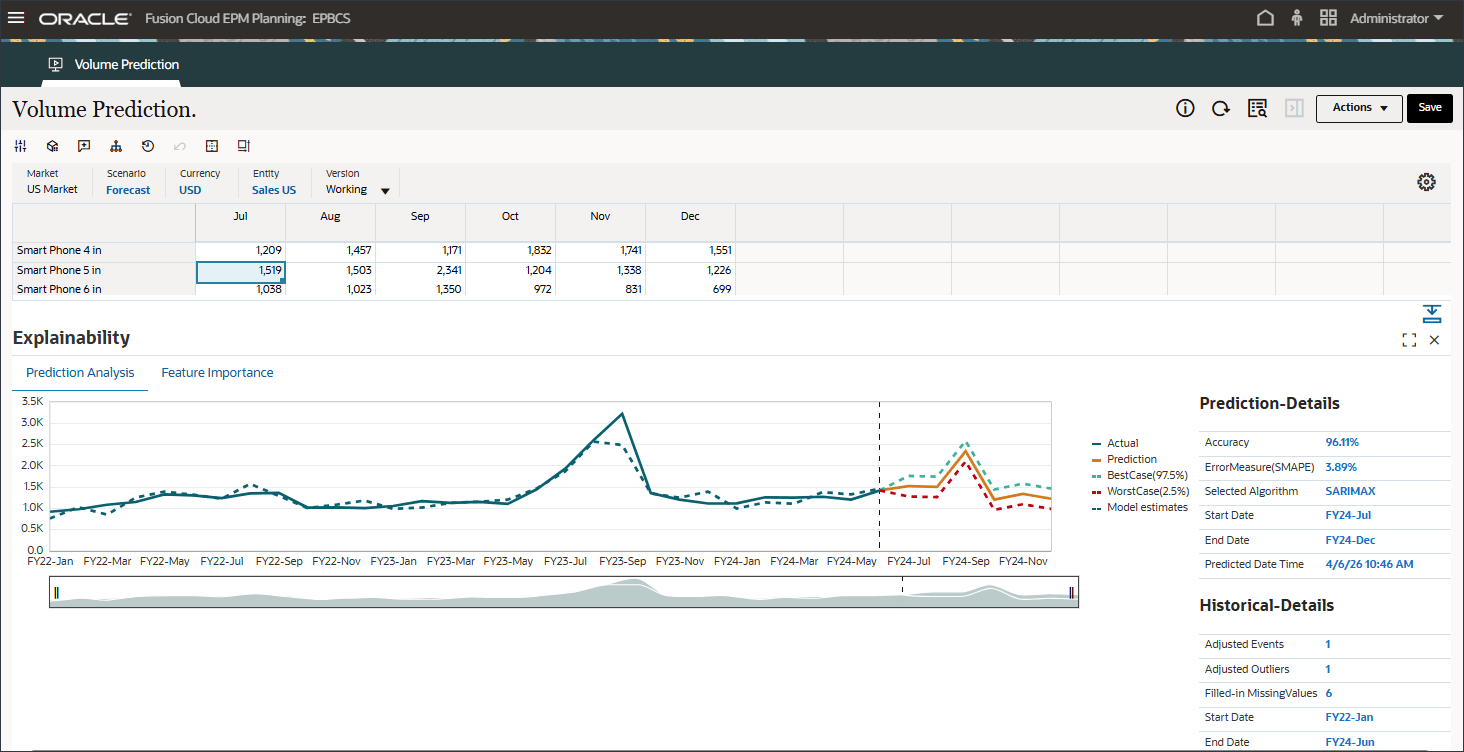
在“预测分析”选项卡上,将显示包含历史趋势和预测结果的线形图,其中考虑最佳情况、最差情况、最有可能的情况。还提供了其他预测详细信息,如准确度百分比、误差度量 (SMAPE)、用于生成预测结果的算法、预测开始日期和结束日期。
- 做出其他选择,例如 9 月的智能手机 6 英寸。
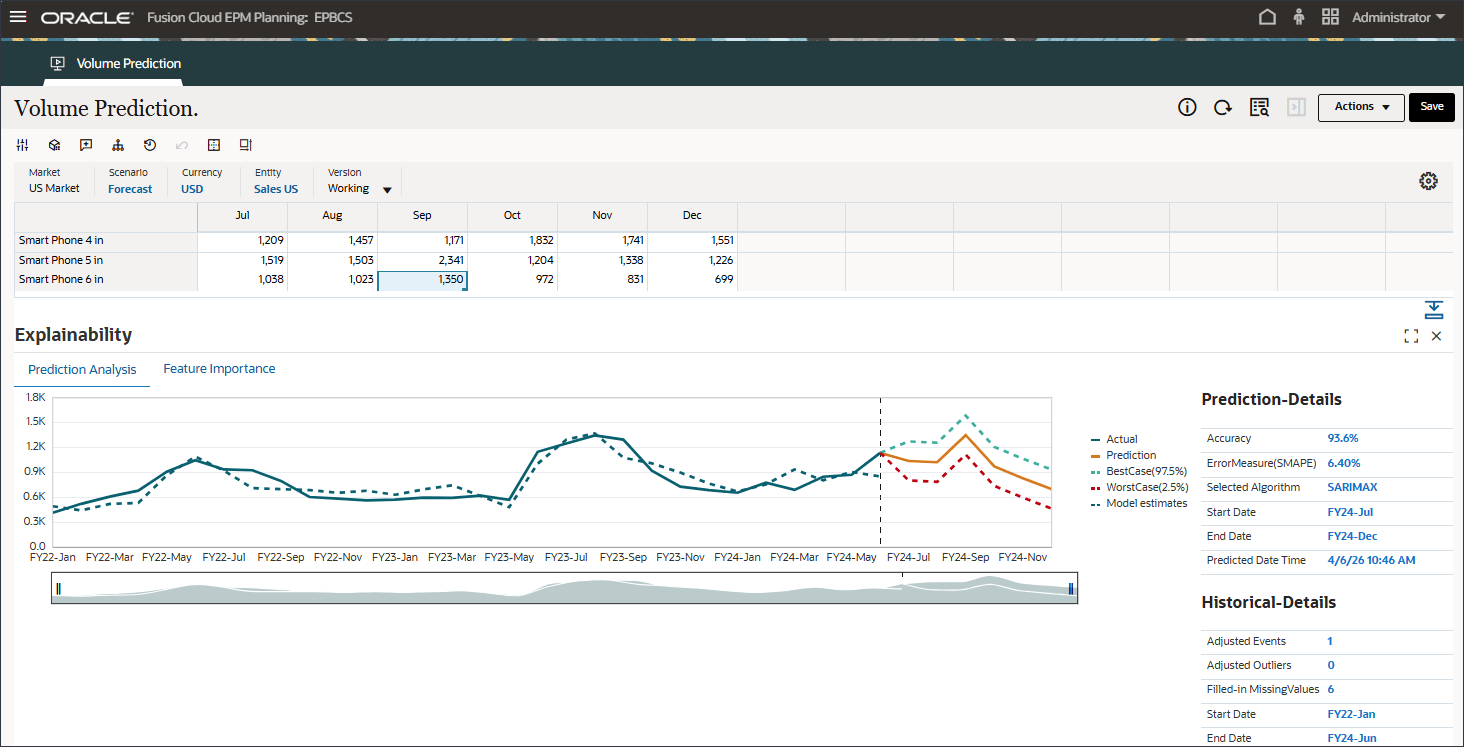
请注意,FY22-May、FY23-Jul 和 FY24-Sep 预测结果中显示的事件的影响。
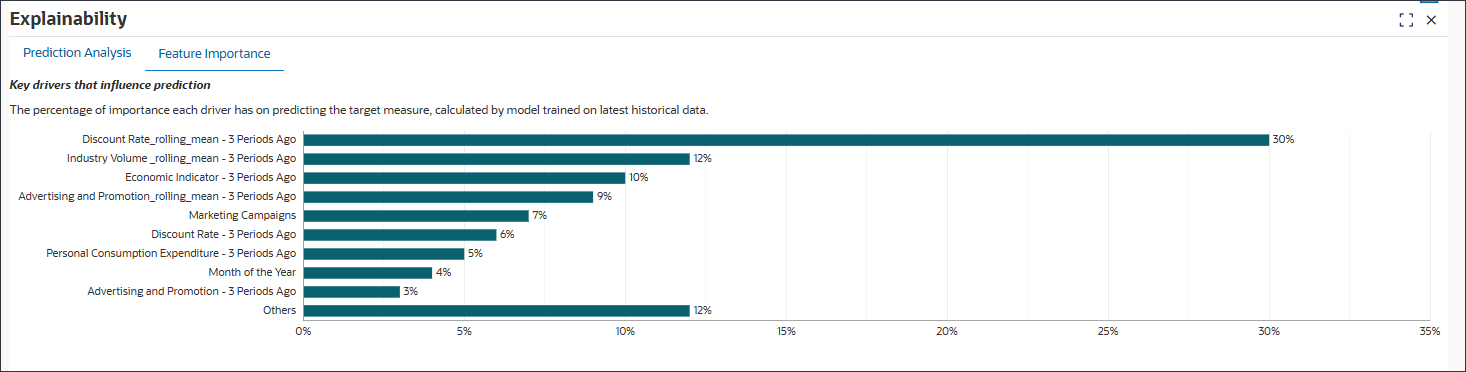
- 选择功能重要性选项卡。
- 确定滞后功能。
滞后功能:
经济指标 - 3 个前期、折扣率 - 3 个前期、个人消费支出 - 3 个前期以及广告和促销 - 3 个前期是滞后功能。
在此示例中,“折扣率 - 3 期间前”作为一项重要功能显示在图表的顶部。这表明,在 3 个月前作出的定价决定对数量有延迟但显著的影响。这是功能工程自动发现的业务洞察。如果没有功能工程,将仅考虑当前期间的折扣率。
滚动平均值:
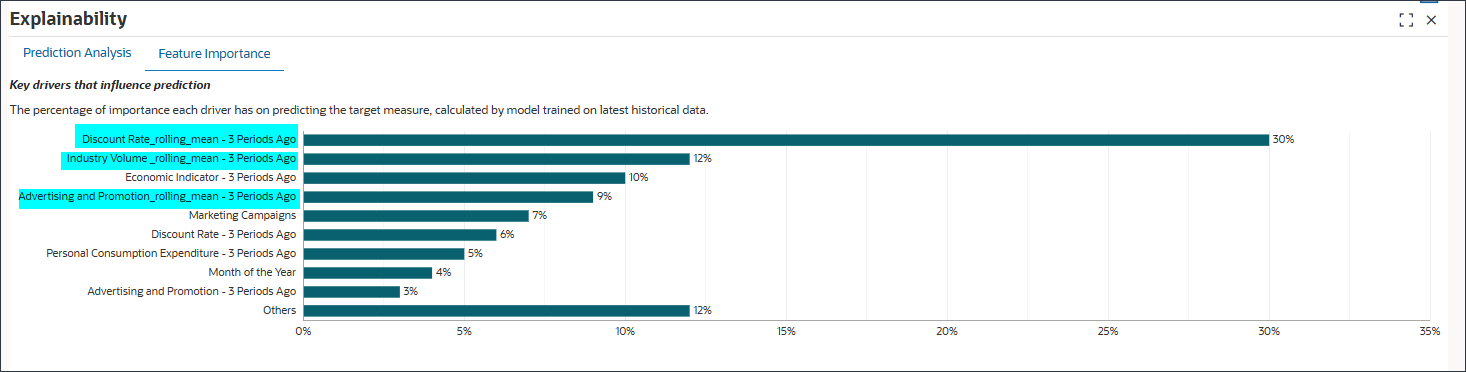
折扣率 _ 滚动 _ 平均值 - 3 个期间前,行业数量 _ 滚动 _ 平均值 - 3 个期间前,广告和促销 _ 滚动 _ 平均值 3 个期间前正在滚动平均值。
滚动意味着通过在多个期间内平均驾驶员值来平滑短期波动。例如,折扣率 _rolling_mean - 3 前期反映了结尾窗口中的平均折扣率,这可能比任何月份的值更代表基本趋势。
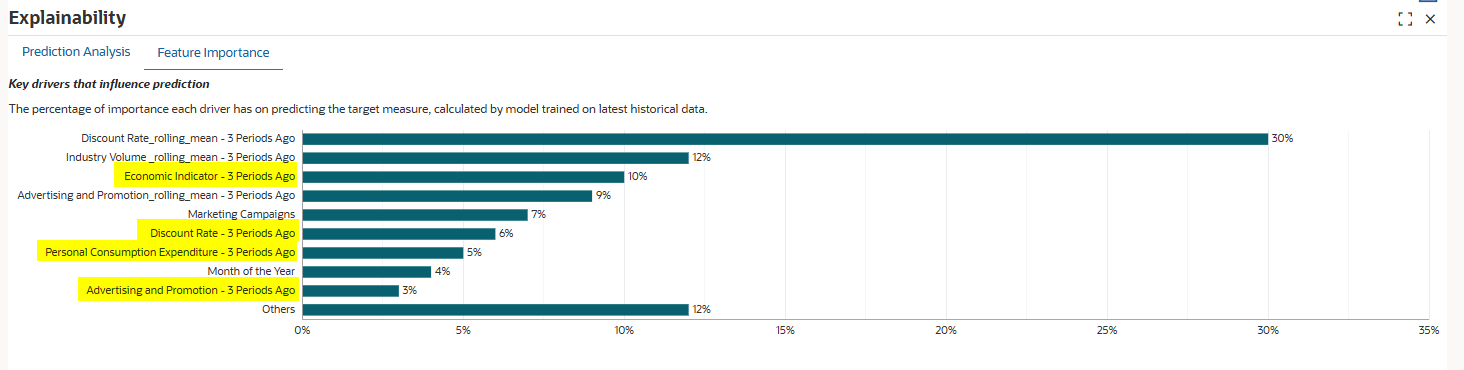
- 了解功能的重要性
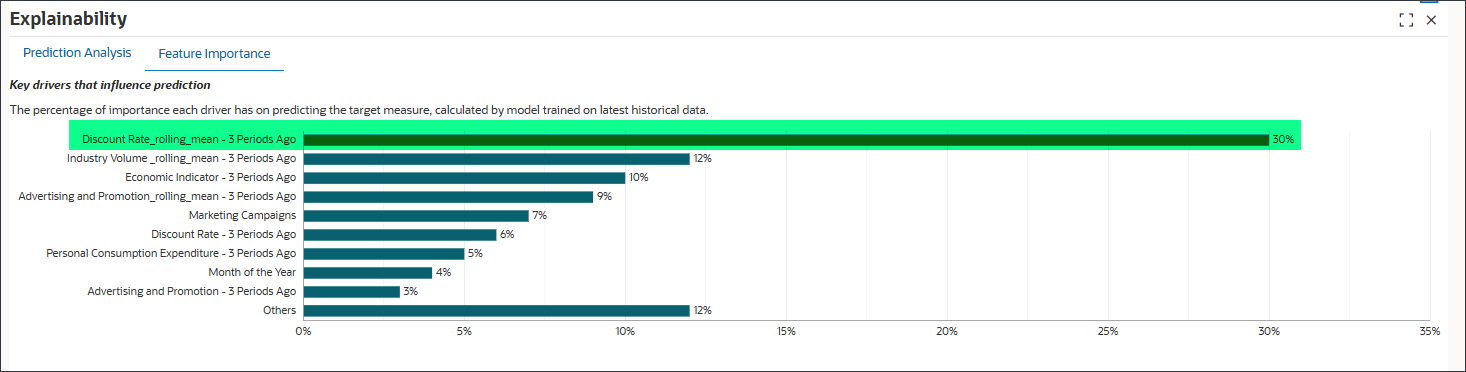
在 30% 时,折扣率 _rolling_mean - 3 个前期对预测目标度量具有最大的重要性。行业数量 _rolling_mean - 3 前期为 12%,经济指标 - 3 前期为 10%。
- 如果要细化输入动因并重新运行高级预测作业,则可以导航到“输入动因”选项卡并编辑动因值。
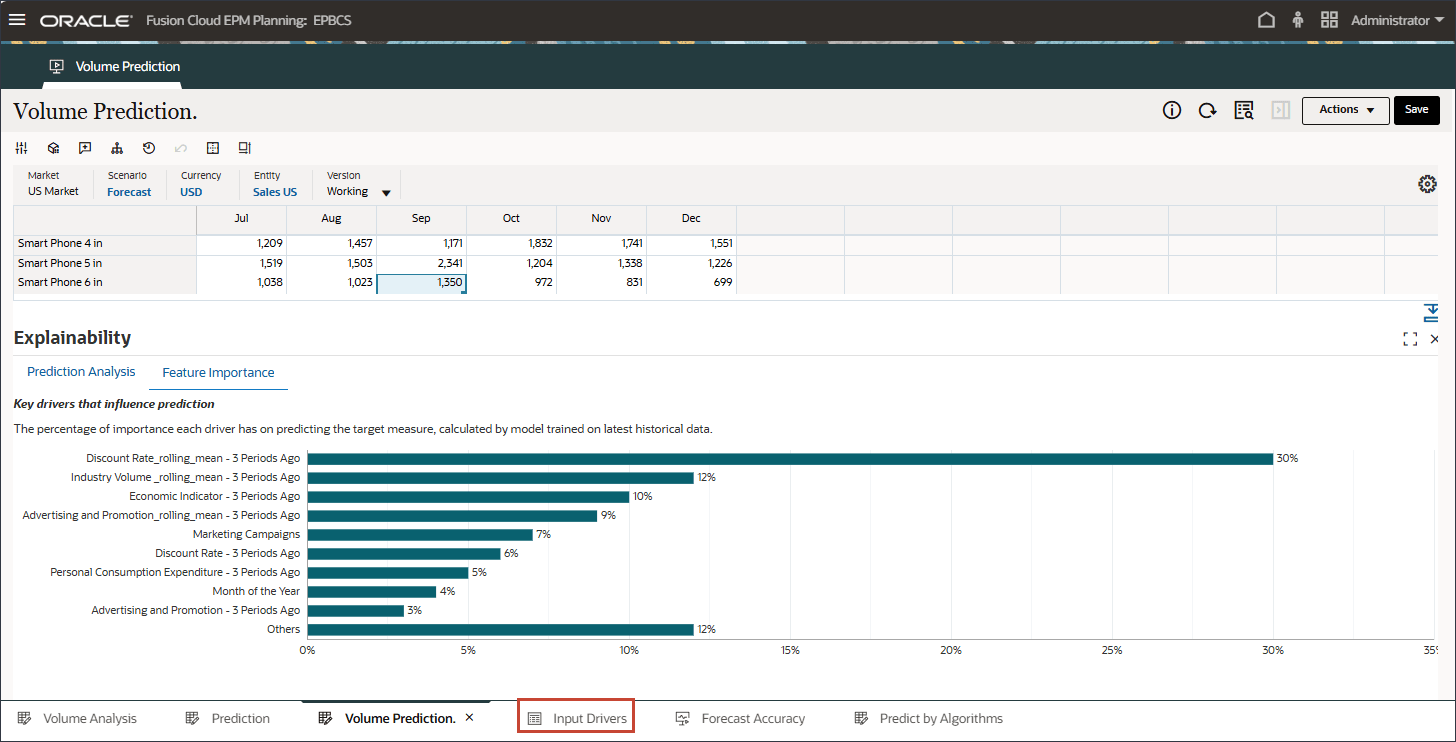
- 单击账户,然后选择一个动因,如广告和促销。然后在再次运行高级预测作业之前,输入并保存更新的值。
- 要运行“高级预测”作业,请按照本教程的“运行高级预测作业”部分中的步骤操作。
- 单击 (主页)以返回到主页。
您可以将拟合值与历史实际数据进行比较,以查看预测模型能够捕捉所提供数据的变化程度。使用历史数据的拟合值对未来趋势进行预测。
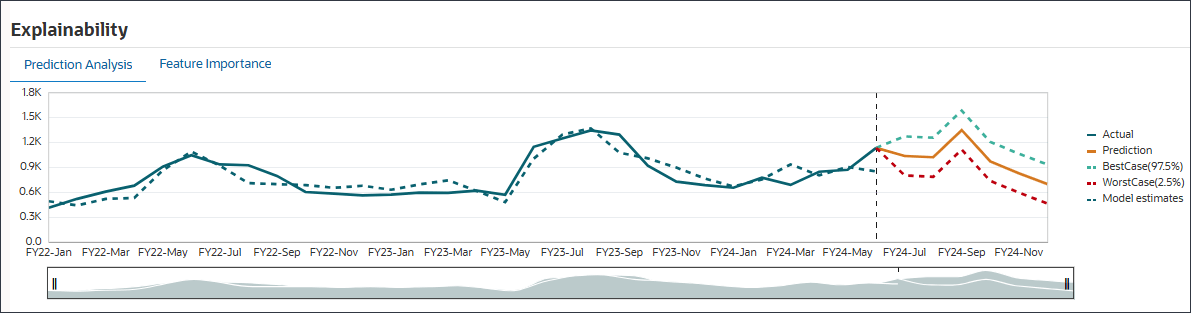
点分线/曲线表示拟合线,即模型根据其对基础逻辑/趋势的学习对历史数据的估计。如果将拟合值与历史实际数据进行比较,则可以查看模型在所提供数据中捕获变量的效果。
功能选择识别影响预测准确性的最相关的业务驱动因素,并筛选出“嘈杂”或低影响变量,以避免过度拟合。它还通过减少复杂性和处理时间来提高性能。它通过根据预测能力对特征进行排名来支持可解释性。
此图表显示前九个特征。所有剩余功能均按其百分比值进行汇总,并分组在“其他”标题下。
更改预测算法
在此部分中,您将更改用于生成预测的算法。您可以复制高级预测作业,并修改详细信息以选择其他预测方法。
- 在主页上,依次单击 IPM 和配置。
- 在销售量预测行中,单击 (操作),然后选择复制。
- 要修改重复作业中的设置,请单击销售量预测 - 复制。
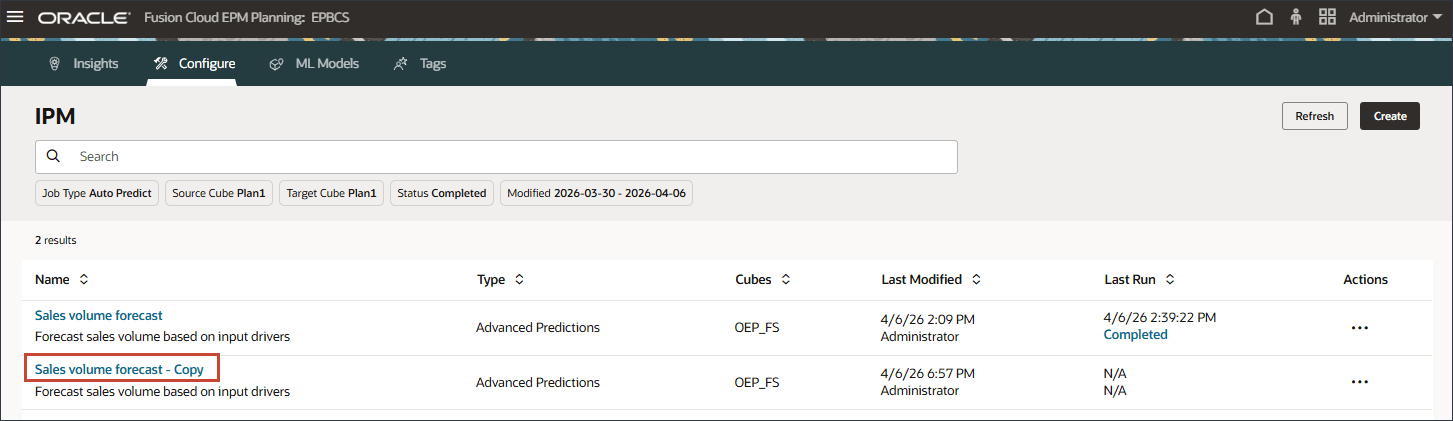
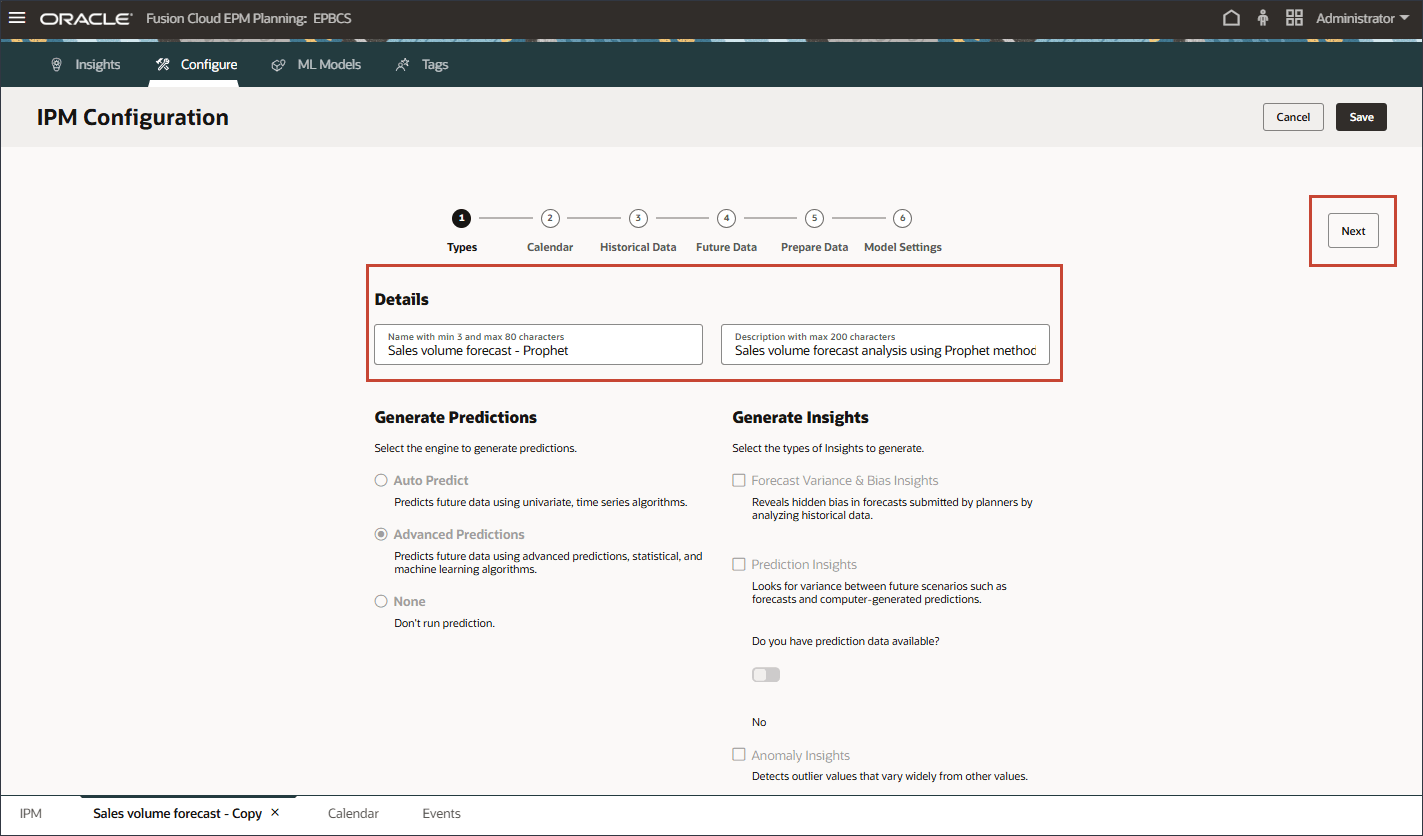
- 在“详细信息”中,将名称更新为销售量预测 - 先知,将说明更新为使用先知方法进行销售量预测分析,然后单击下一步。
- 将日历保持不变,然后单击下一步。
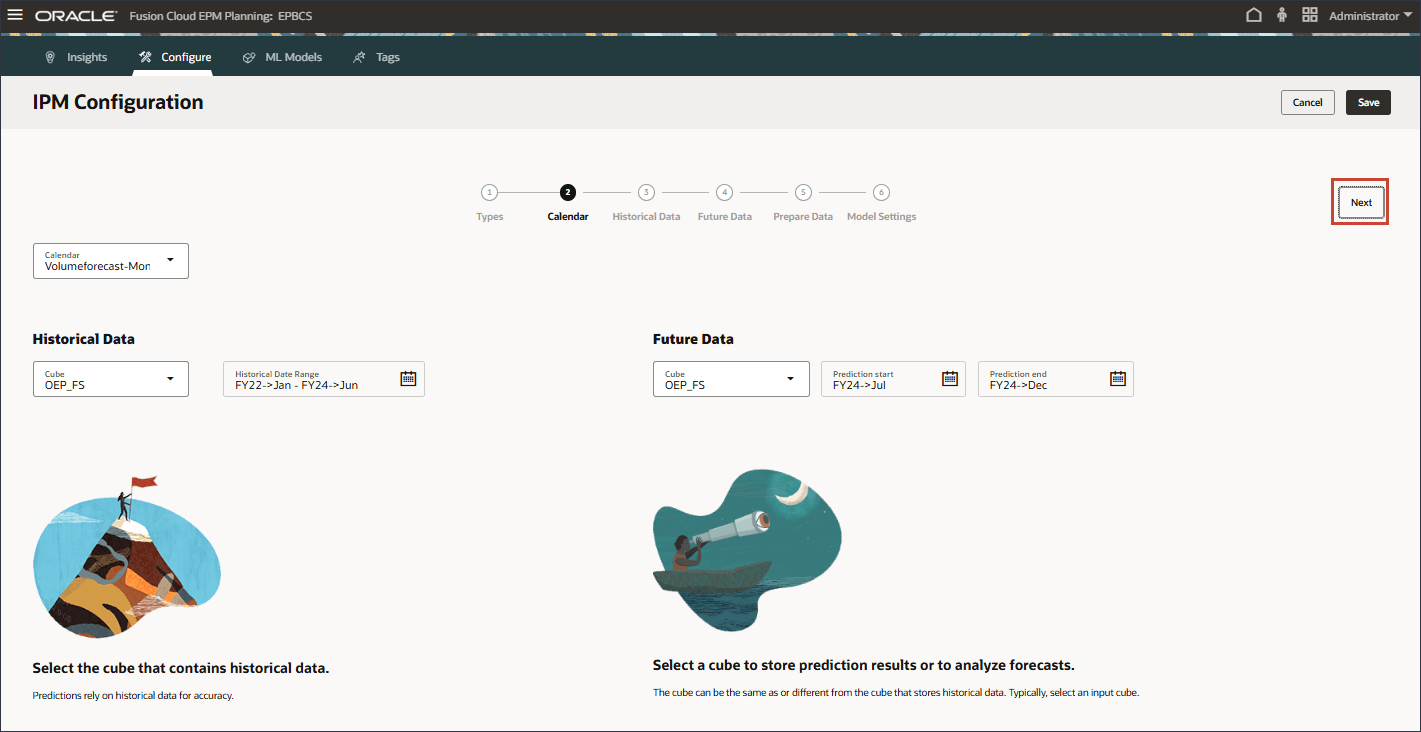
- 将历史数据切片保持不变,然后单击下一步。
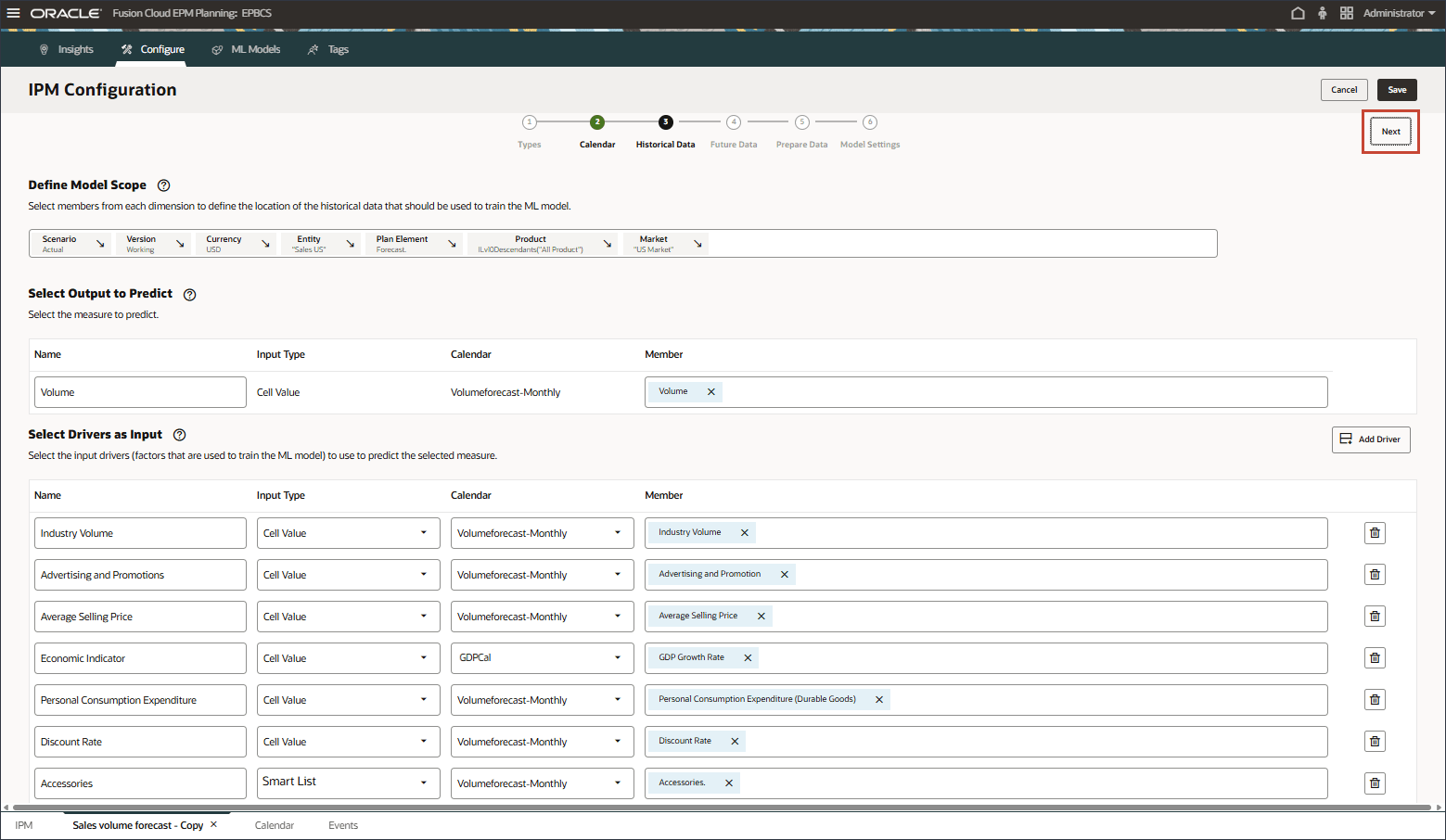
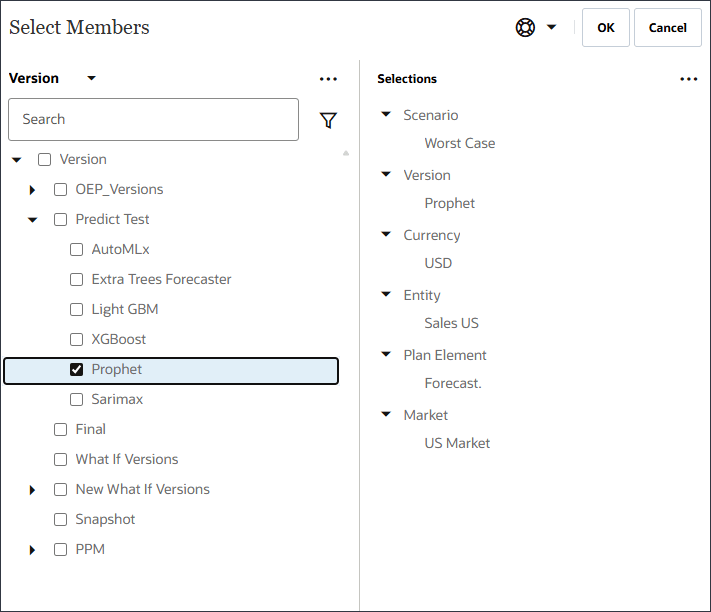
- 对于“将来数据”,在“定义模型范围”中,单击版本。
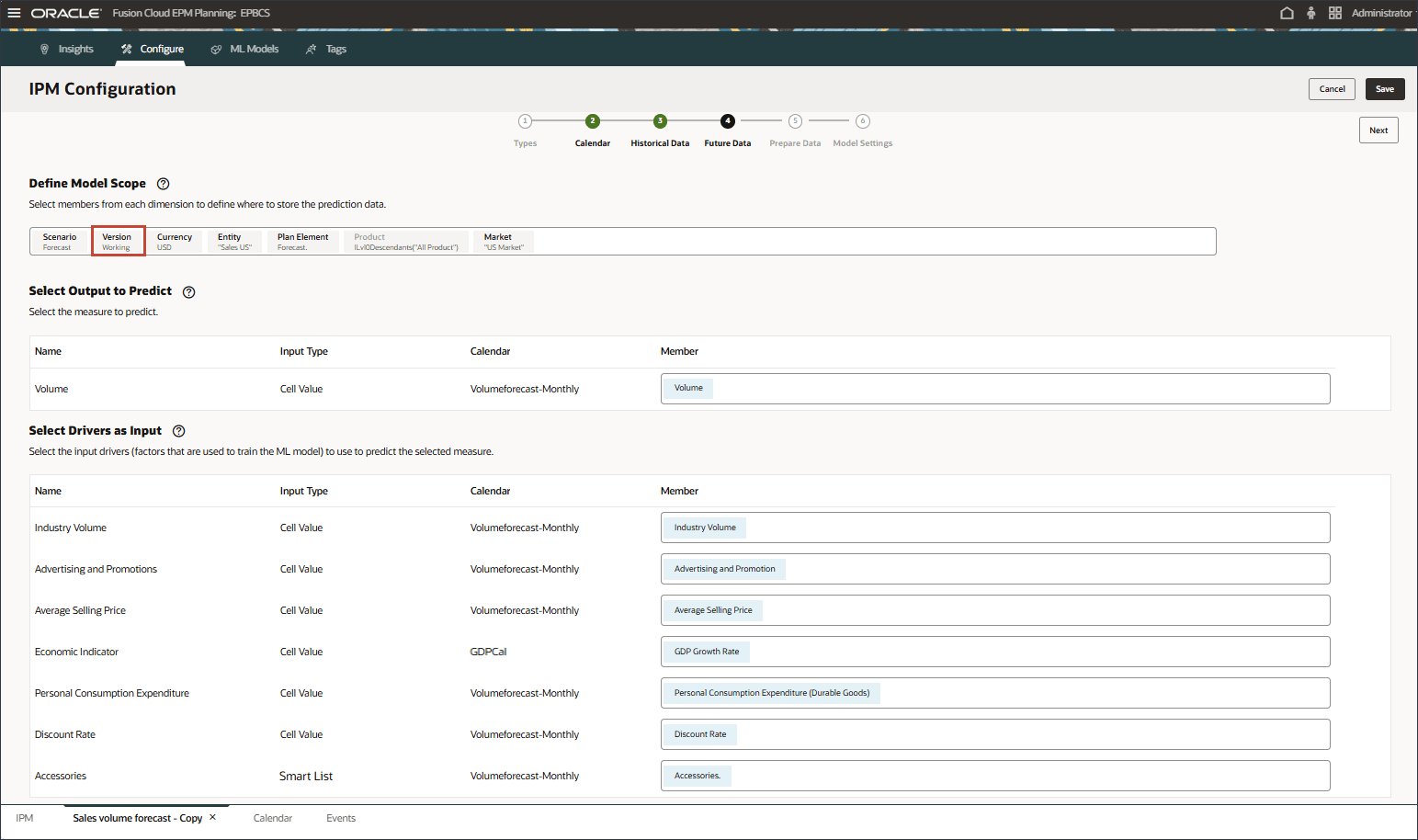
- 选择 Prophet ,然后单击 OK 。
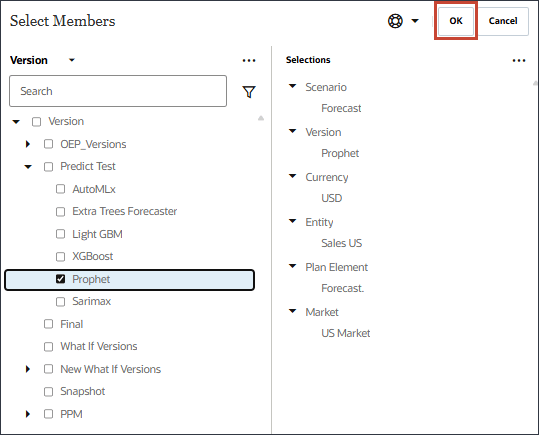
- 请注意更新的模型范围,然后单击下一步。

- 对于“准备数据”步骤,不需要进行任何更改。单击下一步。
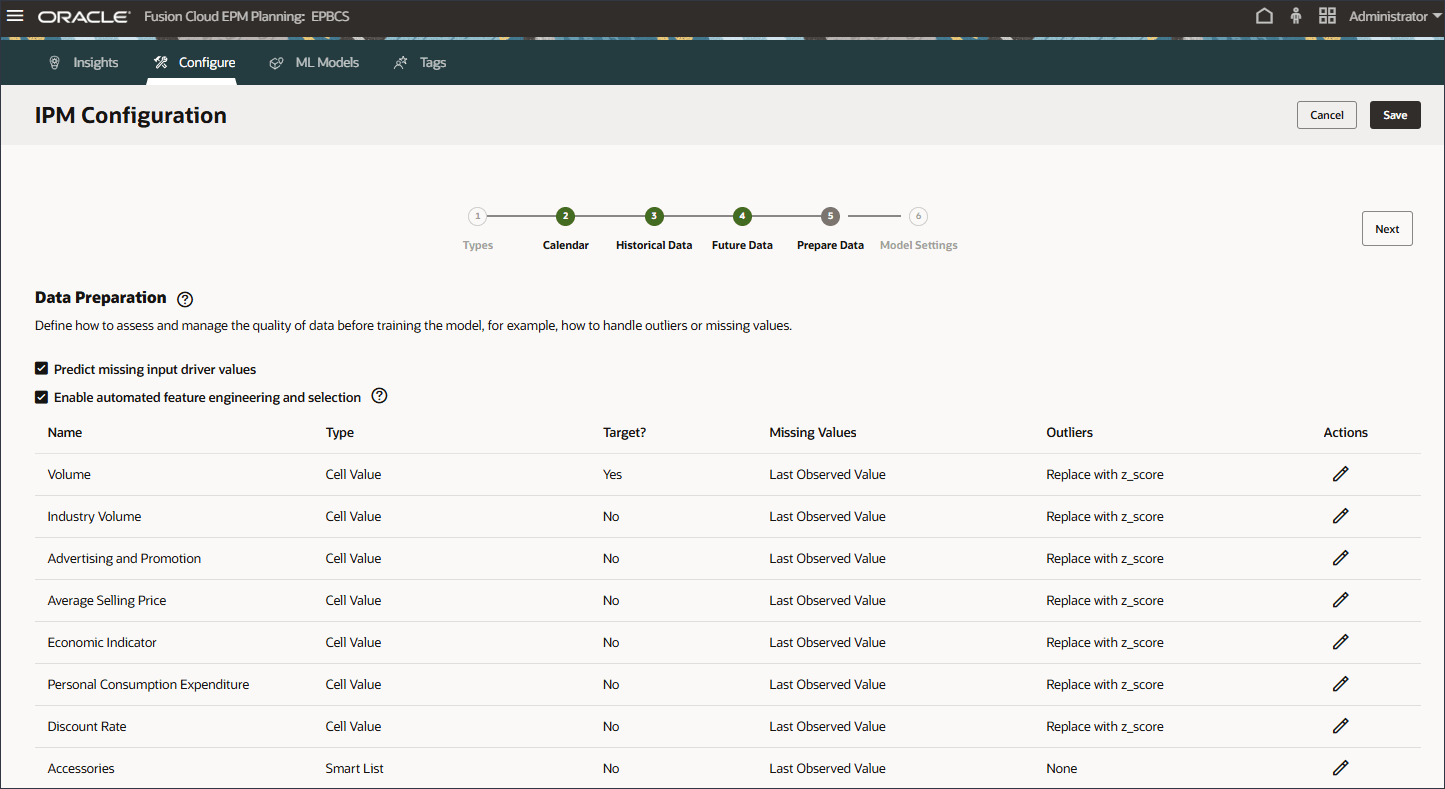
- 在“模型设置”步骤的“选择算法”中,选择先知。
- 对于“预测错误度量”,选择 MAPE 。
- 对于模型估计、最佳情况和最差情况,请将版本更改为 Prophet 。
模型估计、最佳情况和最差情况的版本更改为先知。
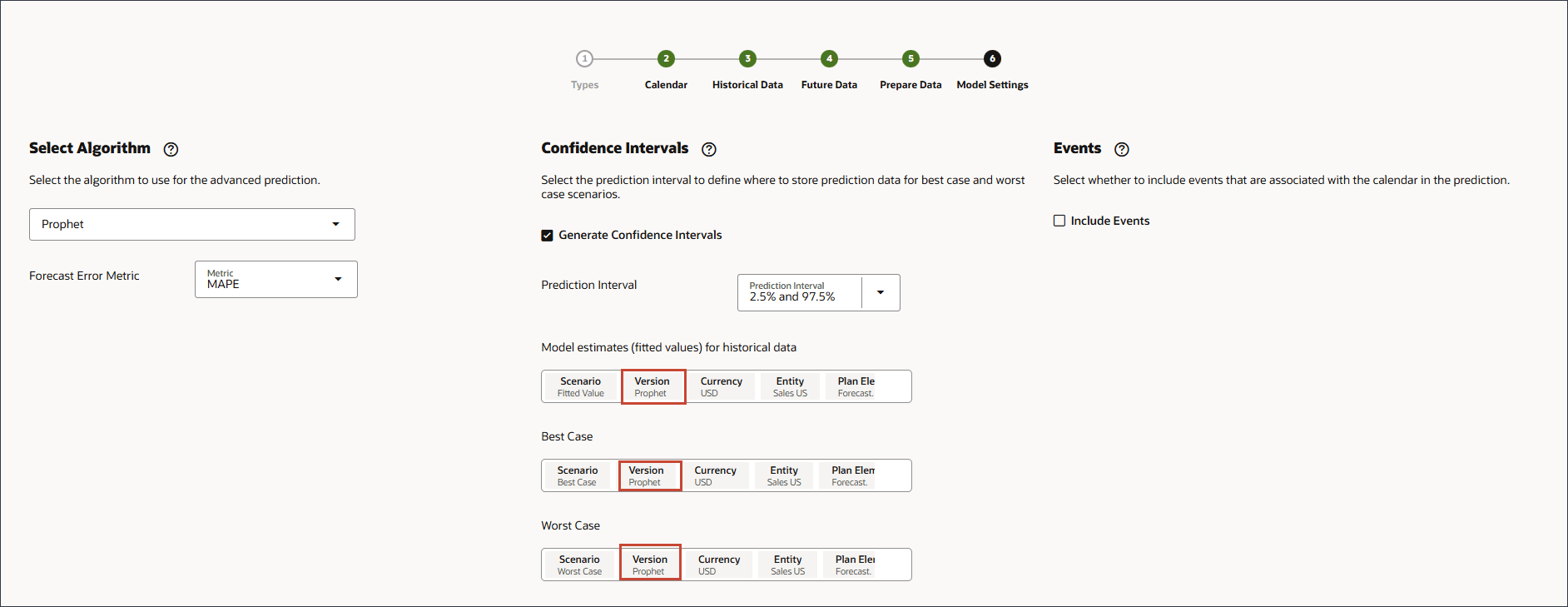
- 在“事件”下,确保选择了包含事件,然后单击保存。
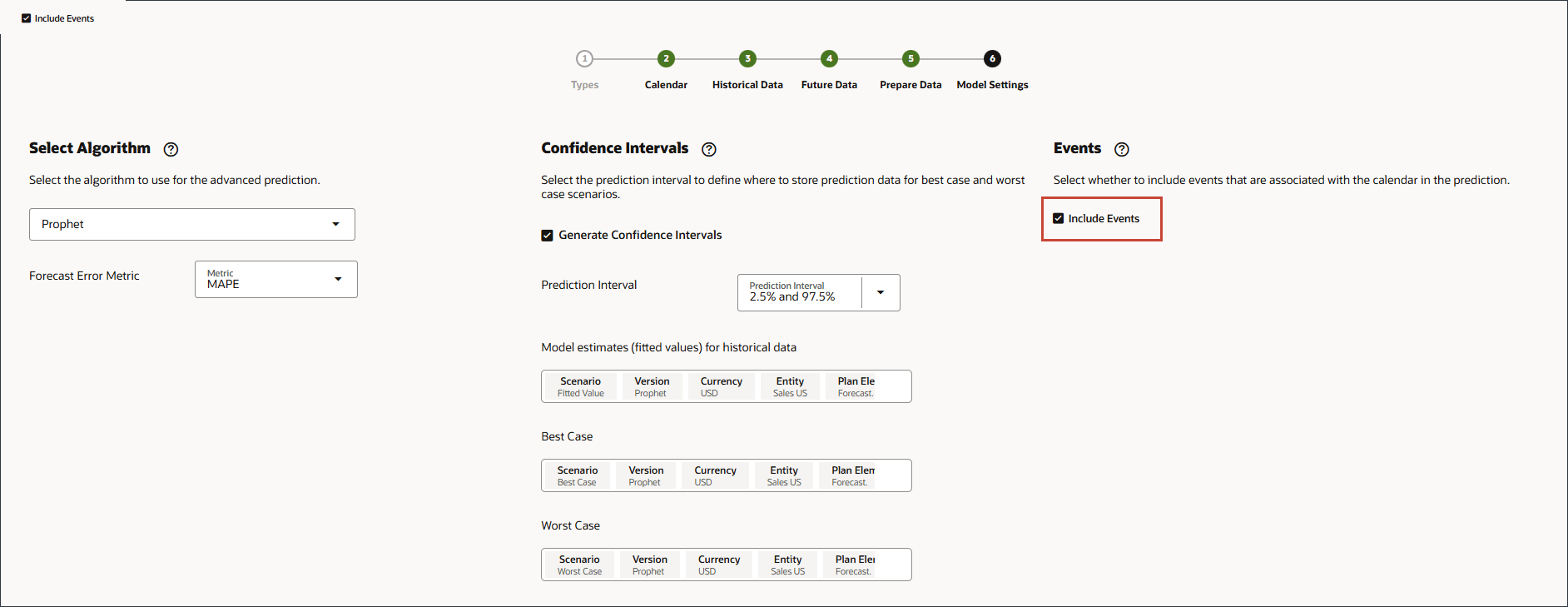
- 单击取消。
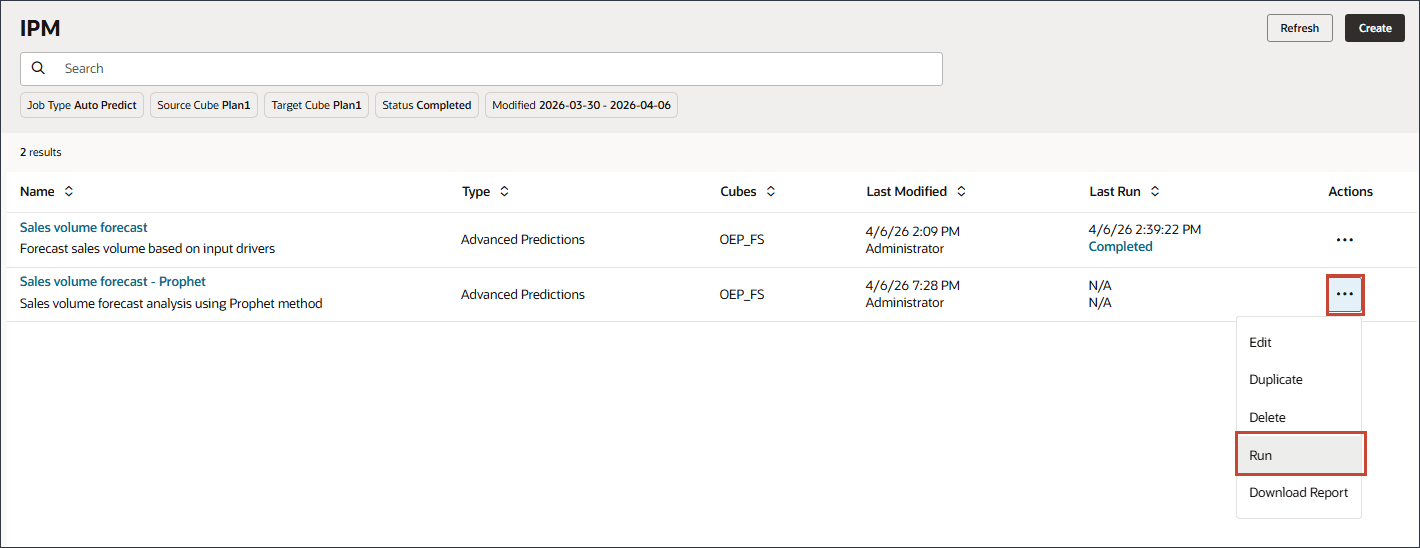
- 对于“销售量预测 - 先知”作业,单击 (操作),然后选择运行。
- 单击刷新,直到作业表明已完成。
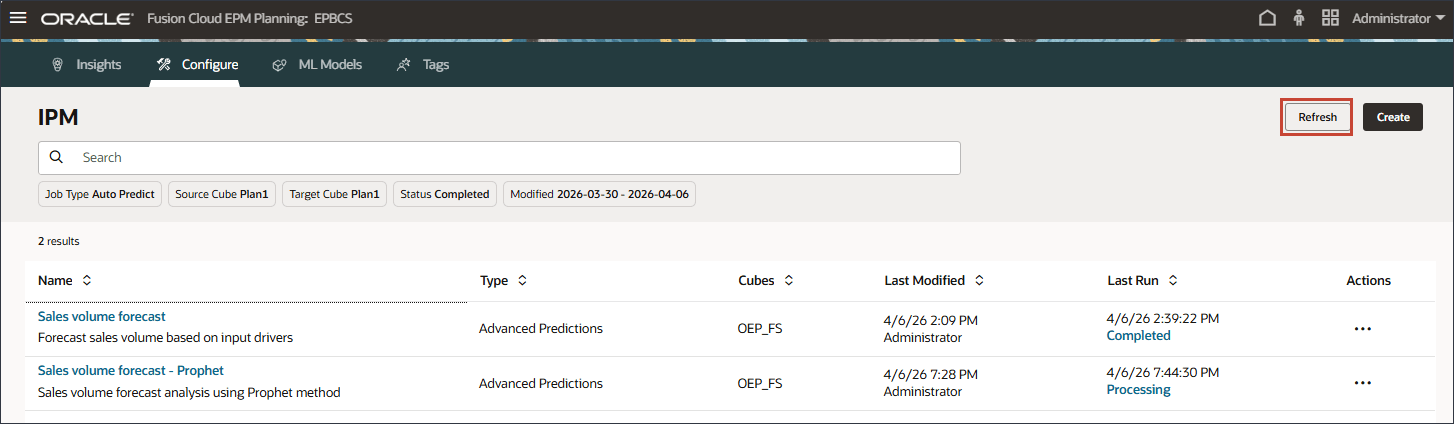
注意:
这项工作需要几分钟才能完成。此任务已完成。
- 单击 (主页)以返回到主页。
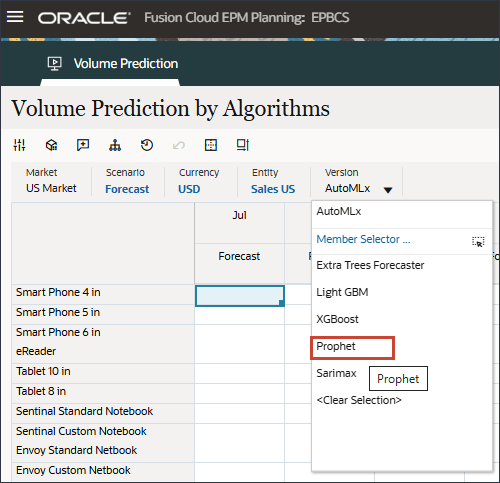
- 在主页上,依次单击高级预测和批量预测。
- 在底部,选择按算法预测选项卡。
- 对于“版本”,选择先知。
- 单击“Explain Prediction(解释预测)”查看预测。右键单击 Smart Phone 4 in 的七月等值,然后选择解释预测。
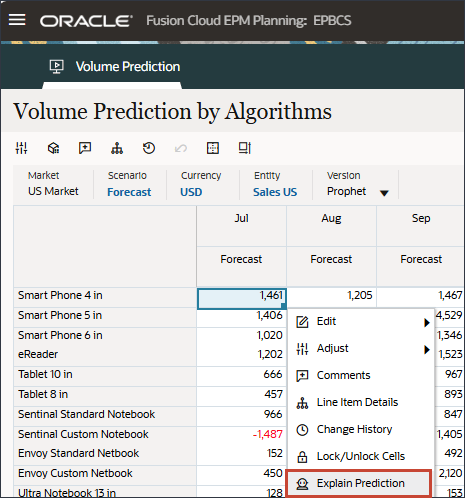
查看可解释性。请注意,对于某些产品系列,先知具有更好的准确性。
预测值 - 添加
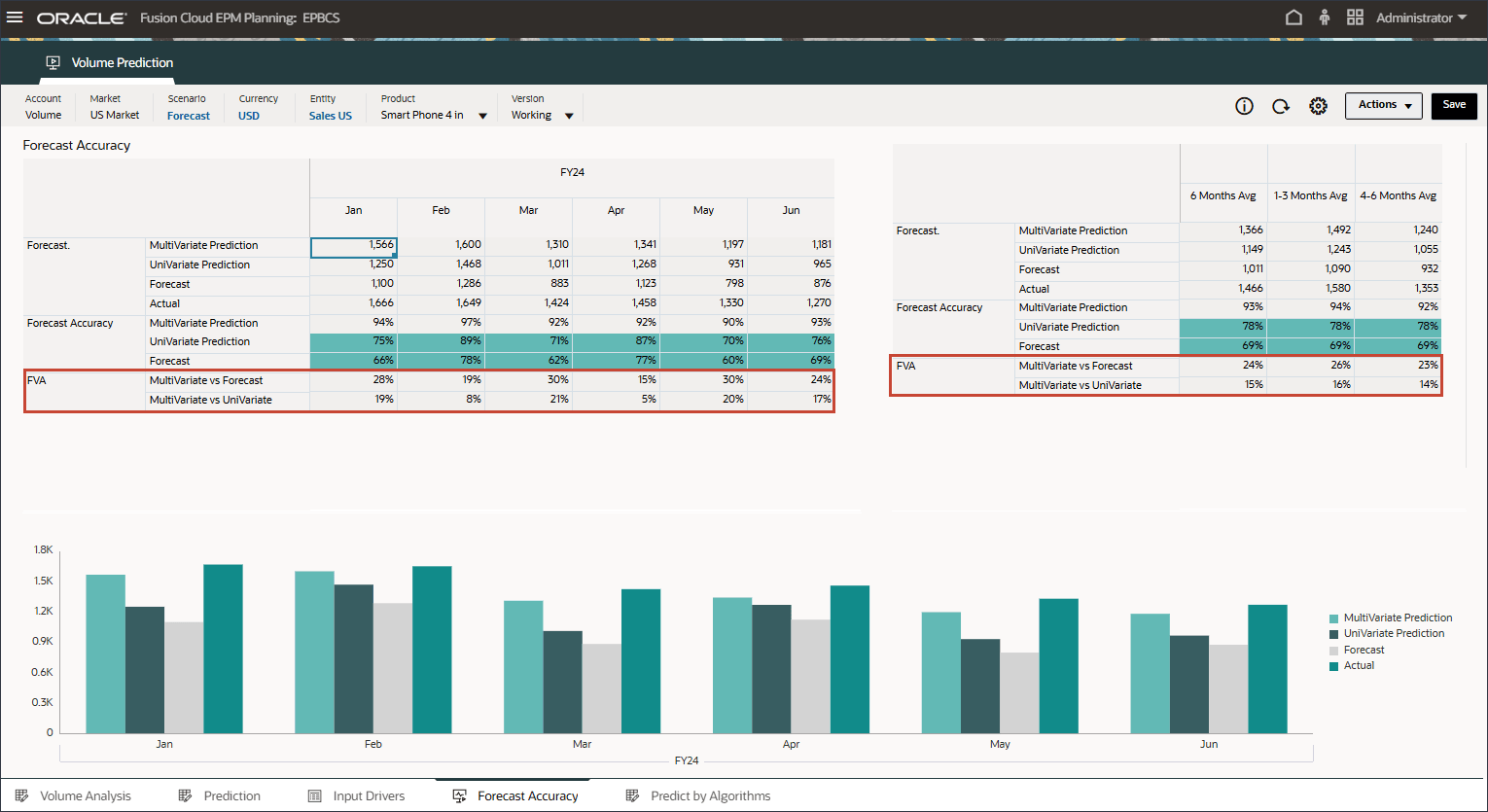
预测增加值 (FVA) 是一种用于预测的度量,用于通过衡量由于预测方法更改而导致的准确性改进(或下降)来评估预测流程的有效性。FVA 有助于确定预测流程中的每个步骤是否与基准(例如天真预测或以前的预测版本)相加的值。
- 在底部,单击预测准确性选项卡。
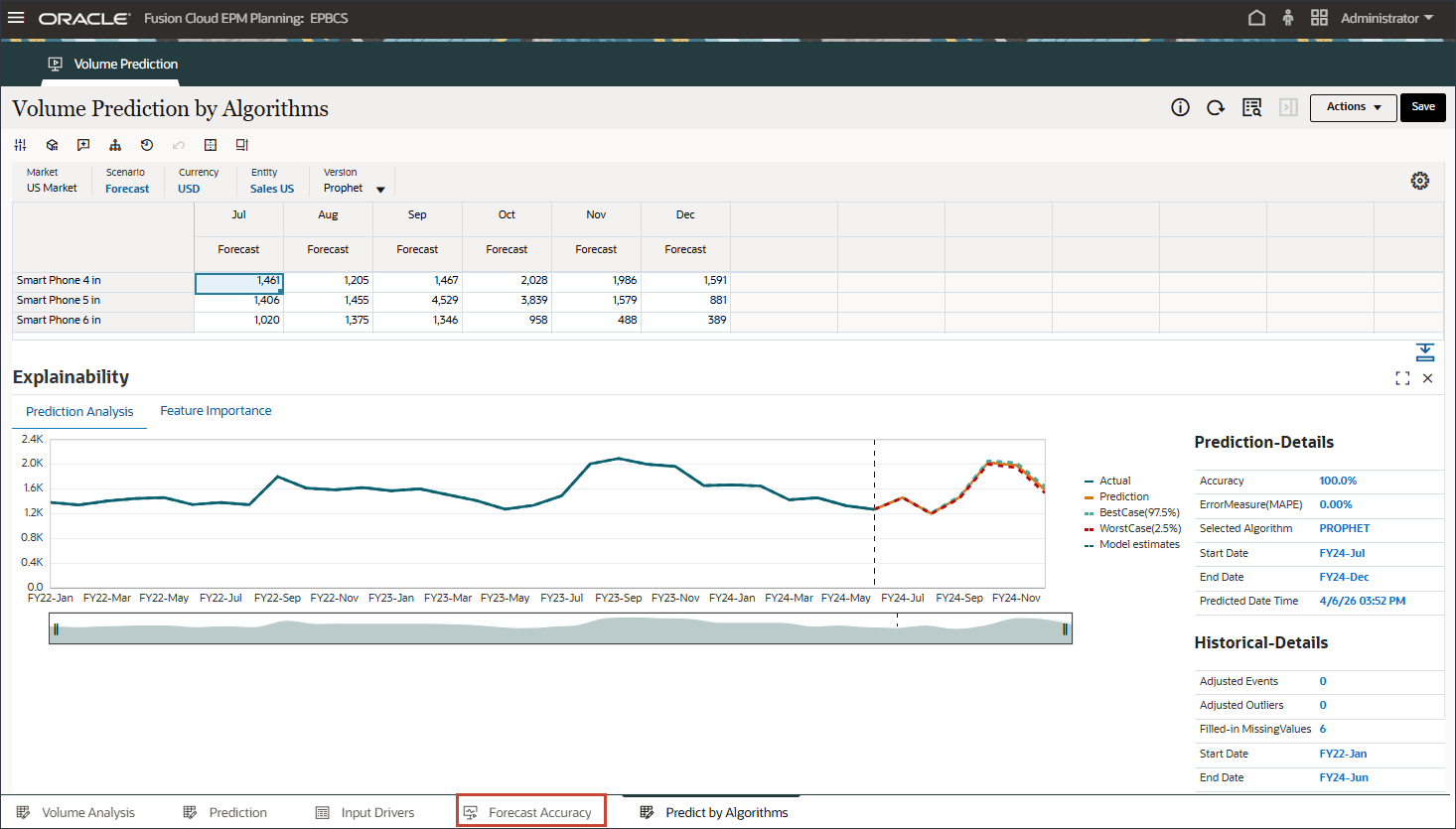
测试是为了测量 1 月 24 日到 6 月 24 日的预测准确度,其中实际数据已可用。您可以比较高级预测结果(多变量预测)、单变量预测和预测,并将这些结果与实际值进行比较,以衡量预测的准确性。
为了计算 FVA,将调整后的预测的准确性与基线的准确性进行比较。如果调整后的预测与基线相比减少了错误,则它具有正 FVA;如果它增加了错误,则 FVA 为负。此指标可帮助预测人员专注于提高准确性的步骤,并消除预测流程中的非增值活动。
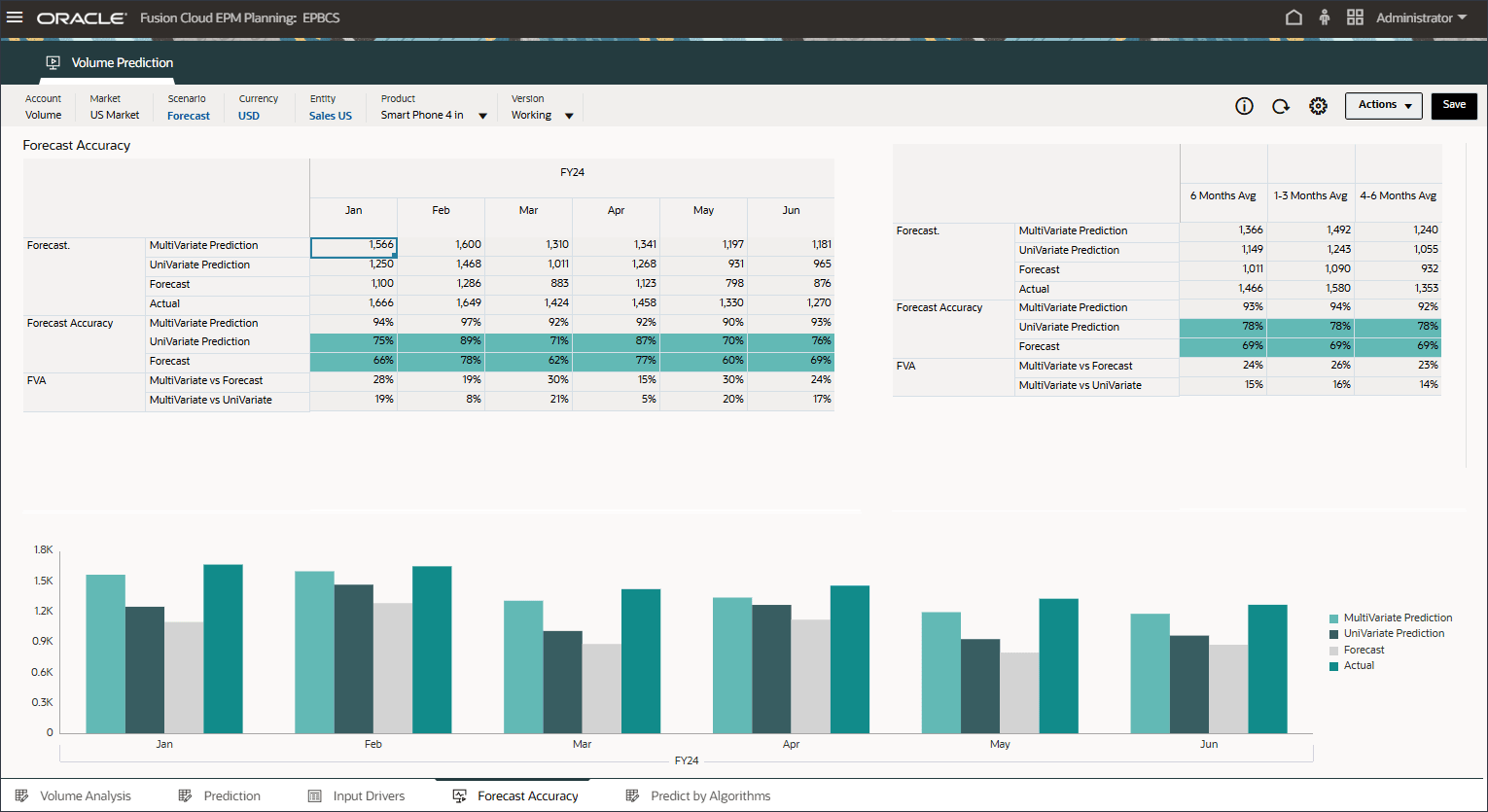
- 查看高级预测 (ML) 的预测值加法,以了解与预测和单变量预测结果相比,预测值加法要好得多。
- 查看用于比较高级预测结果与单变量预测和预测方案的条形图。
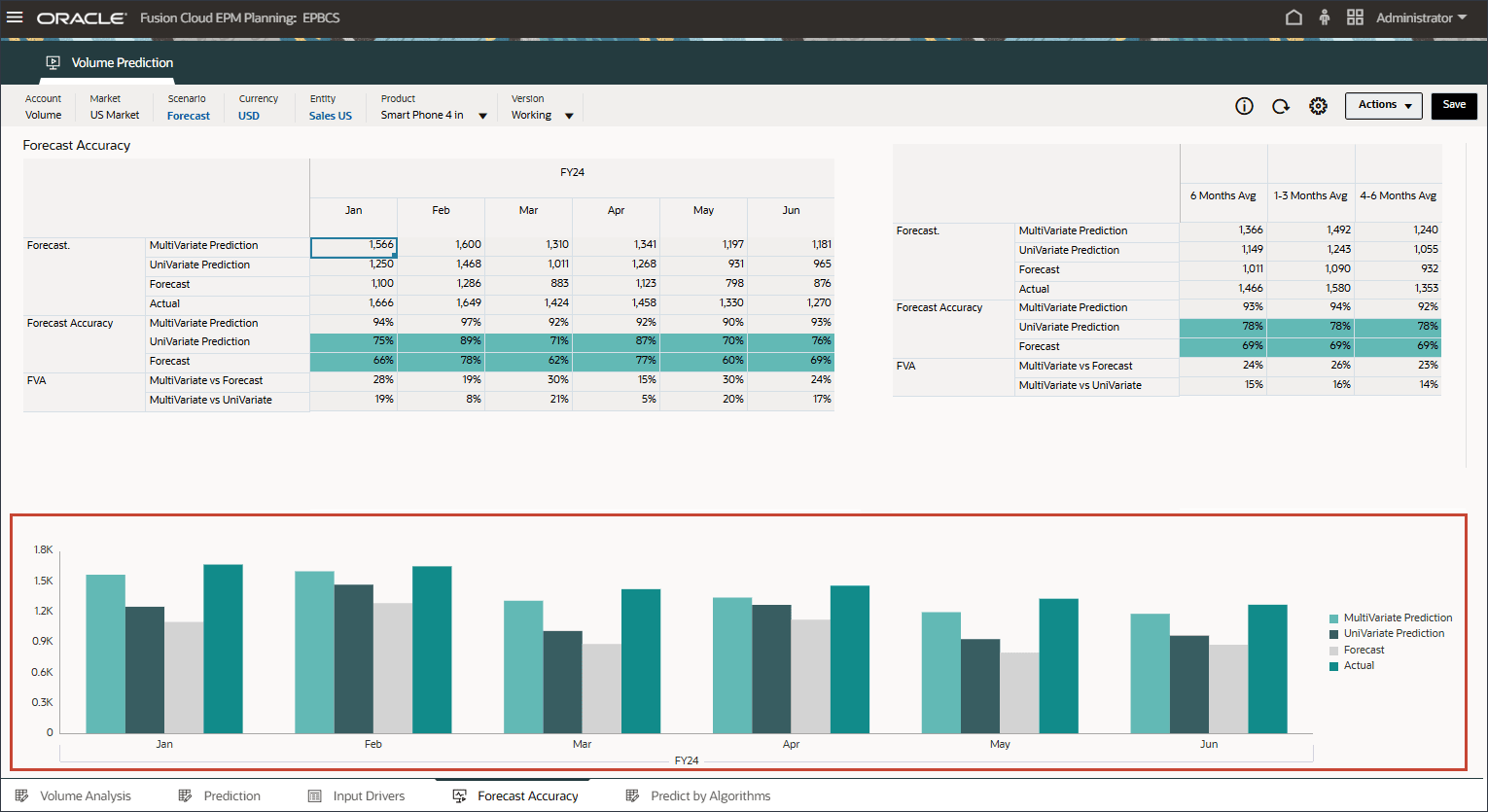
使用机器学习的高级预测更接近实际结果,从而提高规划者使用高级预测方法进行未来计划和预测的信心。
相关链接
更多学习资源
通过 docs.oracle.com/learn 浏览其他实验室,或者通过 Oracle Learning YouTube 频道访问更多免费学习内容。此外,请访问 Oracle University 查看可用的培训资源。
有关产品文档,请访问 Oracle 帮助中心。