使用 OKE 改善 Cassandra 和 Spark 活动的数据局部性
简介
Apache Cassandra 是一个分布式无主数据库,每个节点都拥有令牌范围。Apache Spark 是一个分布式计算引擎,可以使用 Spark – Cassandra 连接器从 Cassandra 副本中读取数据。在 Kubernetes 中,云池是在不了解数据所在位置的情况下调度的,因此无法保证数据位置。
本教程展示了 OKE 如何利用 Kubernetes 基元来提高本地性:StatefulSets(Cassandra 的稳定身份)、节点标签以及与 Cassandra pod 协同定位 Spark 执行器的关联性/反关联性—因此,从同一节点(理想)或最坏的情况下,从一个跃点到同一位置的副本。
目标
- 部署三节点 OKE 集群和堡垒(ORM 或 Terraform)。
- 将 Cassandra 和 Spark 共同定位在具有标签 + 关联性的两个节点上。
- 对 Cassandra 运行并验证 Spark 读取作业。
- 使用 VCN 流日志观察跨节点流量。
Prerequisites
- 具有 VCN、OKE、计算、日志记录(流日志)权限的 OCI 租户;可选监视。
- 用于堡垒访问的 SSH 密钥对。
- 基本的 Kubernetes 熟悉度(节点、标签、pod 等)。
任务 1:使用 OCI 资源管理器 (ORM) 部署环境(推荐)。
-
单击下方可在 OCI 控制台中打开堆栈:

-
按照引导流进行操作,以便:
-
接受使用条件。
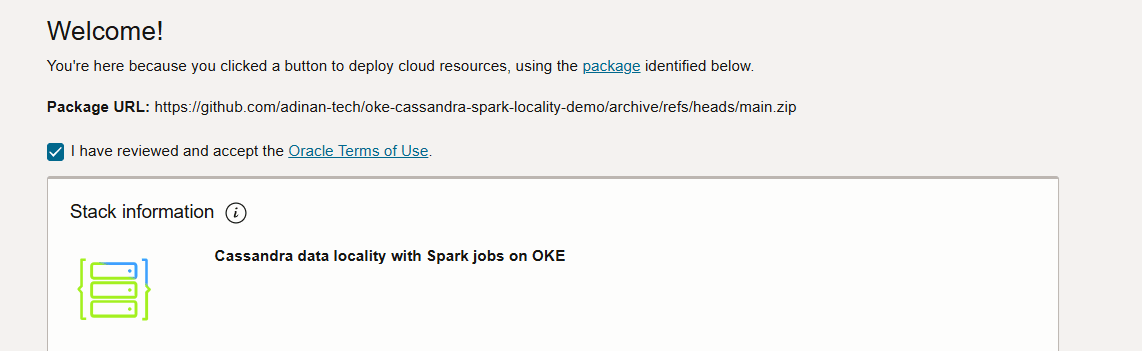
-
插入 SSH 密钥并选择可用性域。
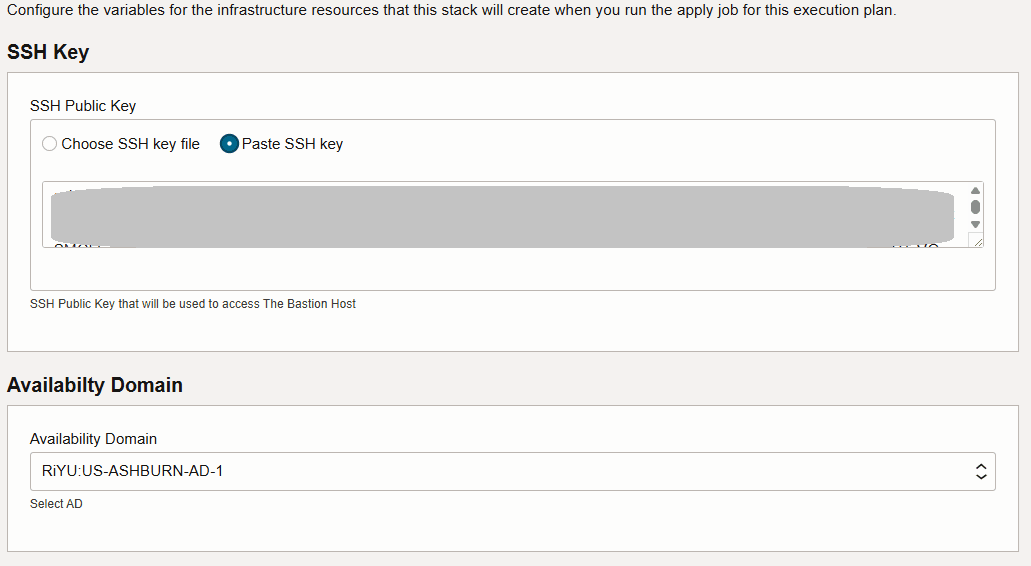
-
您可以将其余值保留为默认值,以便部署 VCN、OKE 集群和堡垒。
-
启动堆栈。
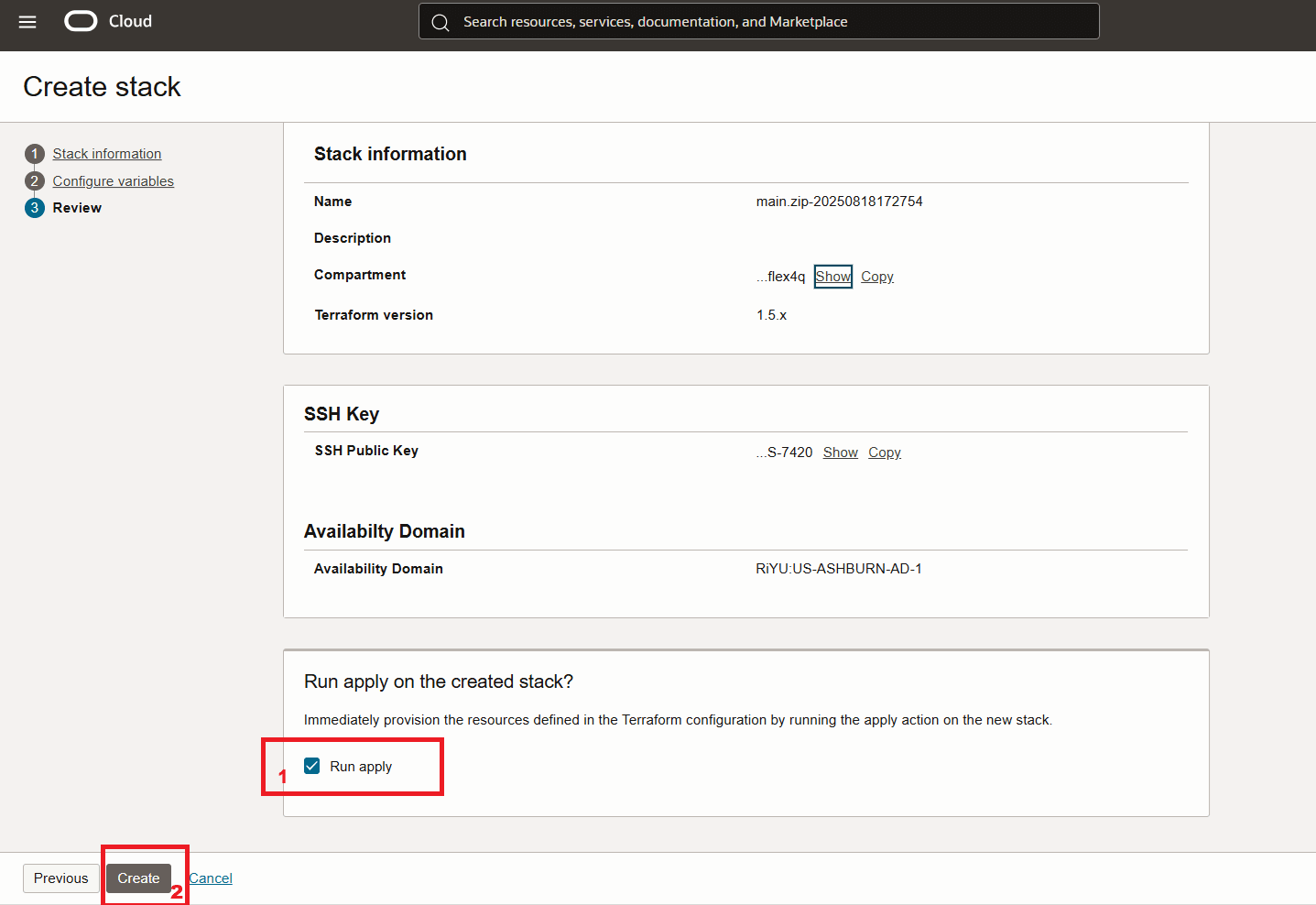
-
堆栈完成后,您将在输出部分中获取堡垒的 IP。
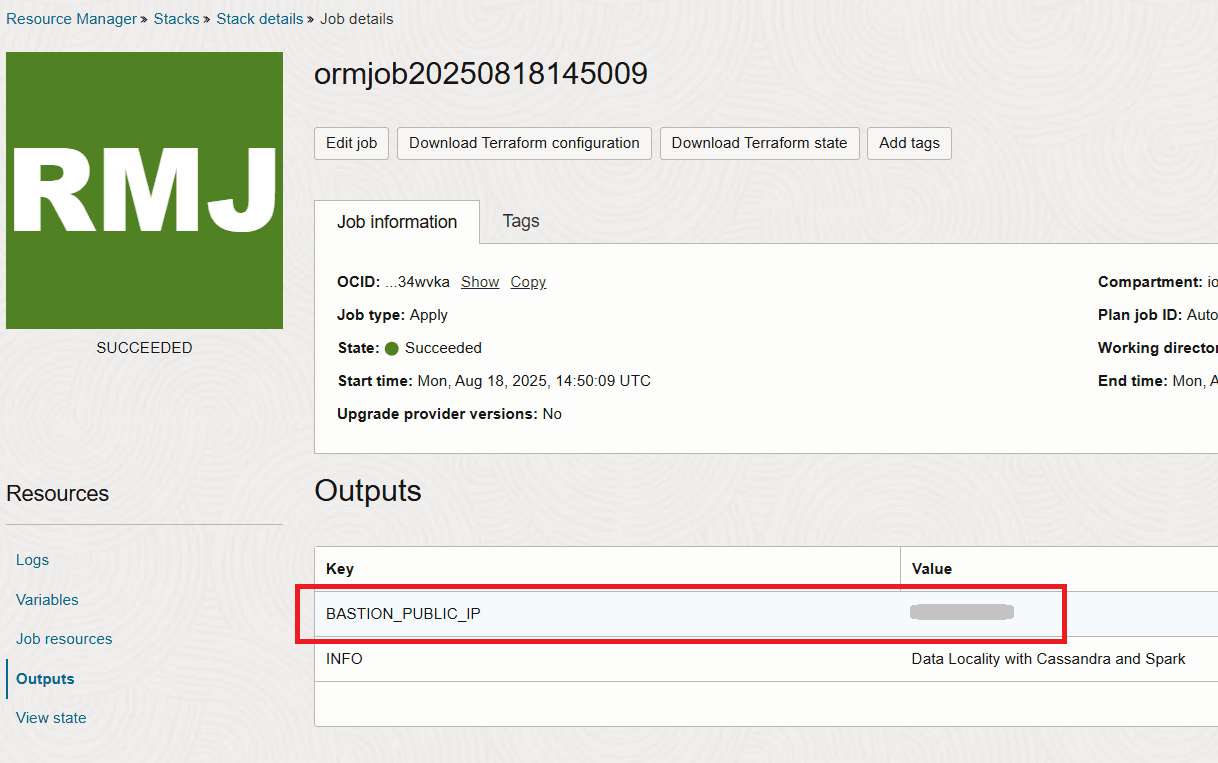
任务 2:连接到堡架并验证部署
初始基础结构预配在大约 15 分钟内完成,但完整设置(通过堡垒上的 cloud-init)需要大约 20 分钟的时间来安装 Helm、部署 Cassandra 和 Spark 并运行读取作业。
-
要监视进程,请通过 SSH 进入堡垒:
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
运行以下命令以监视 cloudinit 脚本的进度。
tail -f /var/log/oke-automation.log -
当您看到正在读取的 3 种种子 Cassandra 值和 Cloud-init complete 消息时,堆栈将完成。
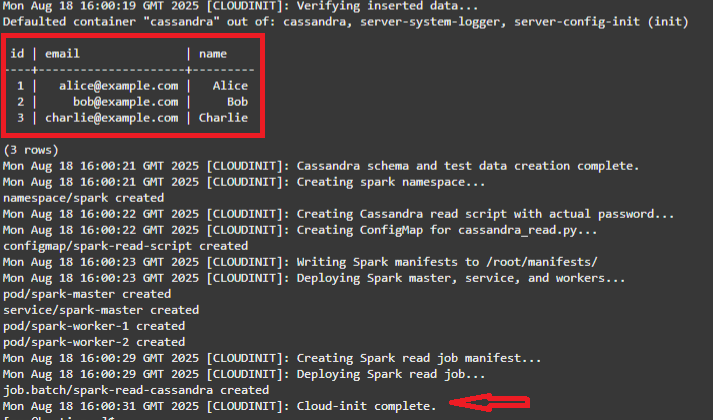
注意:Cloudinit 脚本执行了以下操作:
- 安装 kubectl、Helm、OCI CLI(实例主用户),提取 kubeconfig。
- 等待员工
- 将前两个节点标记为:
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - 安装 cert-manager 和 k8ssandra 操作员 (CRD)
- 应用 K8ssandraCluster
- 等待 Cassandra
- 创建 testks.users 并插入 3 行
- 创建 spark 名称空间;使用 /scripts/cassandra_read.py 构建 ConfigMap(读取 testks.users)
- 部署 Spark 主服务器、服务和两个 Worker(nodeSelector spark-locality:“true”,worker 反关联性)
- 提交作业 spark-read-cassandra
-
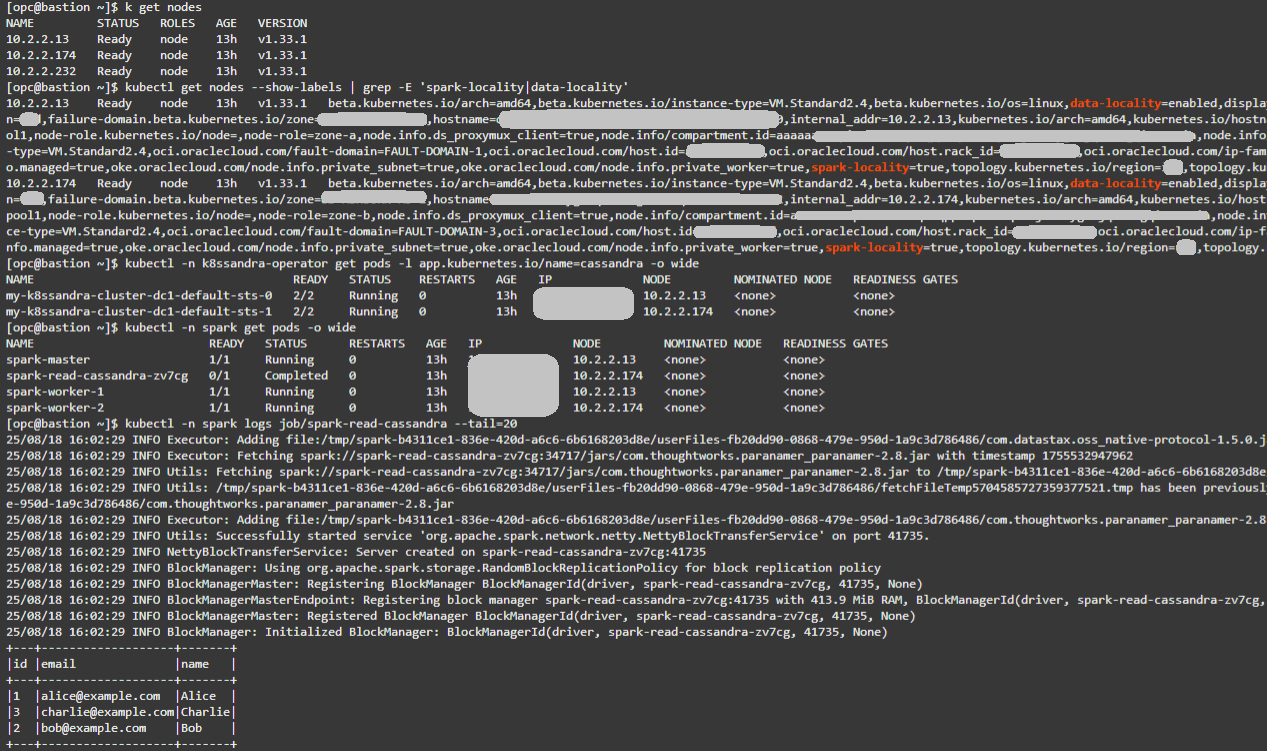
从堡垒 VM 确认现有节点:
kubectl get nodes -
确认地点标签。需要具有 spark-locality=true 和 data-locality=enabled 的两个节点。
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
验证 Cassandra 位置:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
验证 Spark 位置:
kubectl -n spark get pods -o wide -
检查 Spark 读取作业日志。您应看到 testks.users 中的 3 条记录并成功运行。
kubectl -n spark logs job/spark-read-cassandra --tail=20
提示:在 Cassandra 和 Spark 云池中匹配 NODE 值可确认共同定位和理想的位置条件。有关更确凿的流日志结果,请使用 cqlsh 将其他行插入到 testks.users 中。较大的数据集将产生更多的读取流量,使局部性与非局部性影响更容易观察。
下面,您可以看到上述命令的示例输出:
任务 3:使用 VCN 流日志观察网络效果
使用 VCN 流日志了解 Spark 读取期间的 Cassandra 流量流向。当前的自动化使用 Flannel (VXLAN),这会影响流日志可以看到的内容。
CNI 的变化
- Flannel(VXLAN,本实验):
- 同一节点云池流量将保留在主机桥上→没有 VCN 流日志条目。
- 跨节点云池流量封装为 UDP
(VXLAN)。默认情况下,Flannel 使用端口 8472,但如果该端口不可用,则可能选择另一个高 UDP 端口。确切的端口因部署而异。
- VCN-Native Pod Networking (NPN):
- 云池可获取 VCN IP,流量通过 L3 进行路由,而不会覆盖。
- 流日志显示实际的应用程序端口(对于 Cassandra:TCP 9042)。
-
在 worker 子网中启用流日志。
在 OCI 控制台中,为 OKE Worker 子网启用流日志。重新运行(或等待)Spark 读取作业以生成流量。
-
查询流日志(选择与集群匹配的路径)
如果使用此自动化 (Flannel/VXLAN):使用类似于以下内容的高级查询:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
将
- 云池到云池的通信封装在 UDP 中
工作节点 IP 之间(而不是 Cassandra 端口 9042)。 - 相同节点读取:无 VCN 流日志条目(流量保持本地)。
- 跨节点读取:在下图中,UDP 14789 在 worker 节点 IP 之间流动时可见。
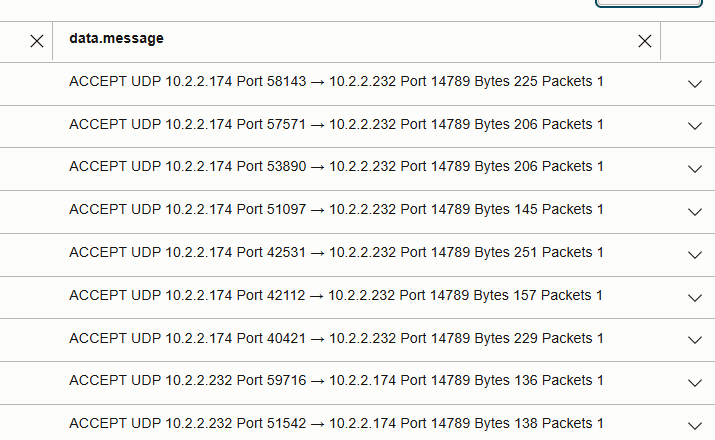
- 比较 UDP 14789 上的数据包计数时,会突出显示数据局部性与非位置性之间的影响。
如果群集使用 NPN:
- 在 pod/worker IP 之间直接过滤 TCP dstPort = 9042。
- 你应该看到 Cassandra CQL 读/写为 9042 流。(理想情况下很少)
注:流日志摄取新条目可能需要几分钟时间。
主要注意事项
-
具有 >3 个节点的集群:
随着集群大小的增长,局部性更重要。如果没有放置规则,Spark 执行程序可以在没有本地副本的节点上运行,从而导致许多远程读取。协同定位可确保读取是本地的,或者最坏的情况是,单个跃点到另一个副本。
- 协同定位带来的绩效收益:
- 零跳本地读取→最低延迟。
- 跨节点读取更少→带宽使用更少,争用更少。
- Spark 作业并行读取 Cassandra 的吞吐量更高。
- 此自动化中使用的机制:
- StatefulSets →稳定的 Cassandra pod 身份。
- 节点标签(
spark-locality、data-locality)→指定要共存的节点。 - 云池关联性/反关联性→安排在 Cassandra 节点上的 Spark 执行程序,并在它们之间进行平衡。
- K8ssandra Operator →声明式 Cassandra 部署和管理。
- ConfigMap + Spark 作业→验证 Cassandra 读取并生成流量。
- VCN 流日志→观察并确认位置影响。
- 超出 OKE 的范围(应用程序级别因素):
- Spark 任务调度和分区分配。
- Cassandra 复制系数和一致性级别。
- 用于选择副本的 Spark – Cassandra 连接器逻辑。
相关链接
提供指向其他资源的链接。此部分是可选的;如果不需要,则删除。
确认
- Authors -Adina Nicolescu(首席云架构师)
更多学习资源
通过 docs.oracle.com/learn 浏览其他实验室,或者通过 Oracle Learning YouTube 频道访问更多免费学习内容。此外,请访问 education.oracle.com/learning-explorer 以成为 Oracle Learning Explorer。
有关产品文档,请访问 Oracle 帮助中心。
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53306-01