使用 Oracle Autonomous Database 和 Property Graph 查詢語言建立知識圖表
簡介
本教學課程探討圖表理論、知識圖表的概念,以及如何使用 Oracle Autonomous Database with Property Graph Query Language (PGQL) 導入圖表。同時也說明 Python 實作,用於使用 LLM 從文件中擷取關係,並將其儲存為 Oracle 中的圖表結構。
什麼是圖表?
Graph 是數學與電腦科學的領域,專注於塑造物件之間的關係模型。圖表包含:
-
頂點 (節點):代表實體。
-
邊緣 (連結):代表實體之間的關係。
圖表廣泛用於在社交網路、語意網路、知識圖表等方面呈現資料結構。
什麼是知識圖表?
知識圖表是以圖形方式呈現真實世界知識,其中:
-
節點代表人員、地點、產品等實體。
-
邊緣代表語意關係。例如,工作地點、部分等等。
知識圖表可增強語意搜尋、建議系統及問答應用程式。
為何要將 Oracle Autonomous Database 與 PGQL 搭配使用?
Oracle 提供完全受管理的環境來儲存及查詢特性圖表:
-
PGQL 與 SQL 類似,專為查詢複雜的圖表樣式而設計。
-
Oracle Autonomous Database 允許使用特性圖表功能 (包括建立、查詢和視覺化) 以原生方式執行圖表查詢。
-
與 LLM 整合可自動從非結構化資料 (例如 PDF) 擷取圖表結構。
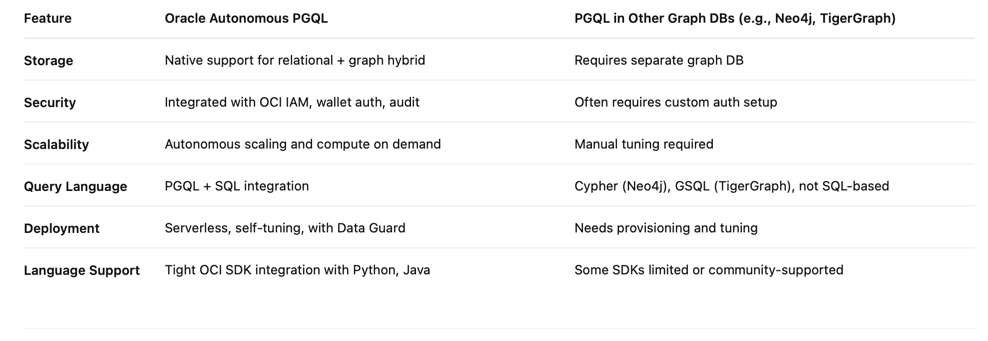
與其他圖表查詢語言比較

Oracle Autonomous Database 與 PGQL 相較於傳統圖形資料庫的優點
目標
- 使用 Oracle Autonomous Database 和 PGQL 建立知識圖表。
必備條件
- 安裝 Python
version 3.10或更新版本和 Oracle Cloud Infrastructure 命令行介面 (OCI CLI)。
作業 1:安裝 Python 套裝軟體
Python 程式碼需要使用特定程式庫來使用 Oracle Cloud Infrastructure (OCI) Generative AI。執行下列指令以安裝必要的 Python 套裝軟體。您可以從此處下載檔案:requirements.txt 。
pip install -r requirements.txt
工作 2:建立 Oracle Database 23ai (永遠免費)
在這項任務中,我們將瞭解如何以永遠免費模式佈建 Oracle Database 23ai。此版本提供完全受管理的環境,適用於開發、測試和學習,無須額外付費。
-
登入 OCI 主控台,導覽至 Oracle Database Autonomous Database ,然後按一下建立 Autonomous Database 執行處理。
-
請輸入下列資訊。
- 資料庫名稱:輸入執行處理的識別名稱。
- 工作負載類型:根據您的需求選取資料倉儲或交易處理。
- 區間: 選取適當的區間以組織您的資源。
-
選取永遠免費,確定已免費佈建此執行處理。
-
為
ADMIN使用者建立安全密碼,此密碼將用於存取資料庫。 -
複查設定值,然後按一下建立 Autonomous Database 。等待幾分鐘的時間,讓執行處理可佈建並可供使用。
如果您不熟悉連線至 Oracle Autonomous Database 的程序,請依照這些連結瞭解並正確設定您的程式碼。
注意:您必須使用 Wallet 方法,連線到 Python 程式碼內的資料庫。
工作 3:下載和瞭解程式碼
Graph 非常常見的使用案例是將其作為與 LLM 和知識庫 (例如 PDF 檔案) 一起運作的其中一個元件。
我們將使用此教學課程:使用 OCI Generative AI 以自然語言分析 PDF 文件作為我們的基礎,使用所有提及的元件。但就本文件而言,我們將聚焦於將 Oracle Database 23ai 與 Graph 搭配使用。基本上,基本材料中的 Python 程式碼 (main.py) 只會在使用 Oracle Database 23ai 的部分中修改。
這些是在此服務上執行的處理作業:
-
建立圖形結構。
-
使用 LLM 擷取實體與關係。
-
將資料插入 Oracle。
-
建立屬性圖。
請從以下網址下載與 Oracle Database 23ai 相容的更新 Python 圖表程式碼:main.py 。
-
create_knowledge_graph:def create_knowledge_graph(chunks): cursor = oracle_conn.cursor() # Creates graph if it does not exist try: cursor.execute(f""" BEGIN EXECUTE IMMEDIATE ' CREATE PROPERTY GRAPH {GRAPH_NAME} VERTEX TABLES (ENTITIES KEY (ID) LABEL ENTITIES PROPERTIES (NAME)) EDGE TABLES (RELATIONS KEY (ID) SOURCE KEY (SOURCE_ID) REFERENCES ENTITIES(ID) DESTINATION KEY (TARGET_ID) REFERENCES ENTITIES(ID) LABEL RELATIONS PROPERTIES (RELATION_TYPE, SOURCE_TEXT)) '; EXCEPTION WHEN OTHERS THEN IF SQLCODE != -55358 THEN -- ORA-55358: Graph already exists RAISE; END IF; END; """) print(f"🧠 Graph '{GRAPH_NAME}' created or already exists.") except Exception as e: print(f"[GRAPH ERROR] Failed to create graph: {e}") # Inserting vertices and edges into the tables for doc in chunks: text = doc.page_content source = doc.metadata.get("source", "unknown") if not text.strip(): continue prompt = f""" You are an expert in knowledge extraction. Given the following technical text: {text} Extract key entities and relationships in the format: - Entity1 -[RELATION]-> Entity2 Use UPPERCASE for RELATION types. Return 'NONE' if nothing found. """ try: response = llm_for_rag.invoke(prompt) result = response.content.strip() except Exception as e: print(f"[ERROR] Gen AI call error: {e}") continue if result.upper() == "NONE": continue triples = result.splitlines() for triple in triples: parts = triple.split("-[") if len(parts) != 2: continue right_part = parts[1].split("]->") if len(right_part) != 2: continue raw_relation, entity2 = right_part relation = re.sub(r'\W+', '_', raw_relation.strip().upper()) entity1 = parts[0].strip() entity2 = entity2.strip() try: # Insertion of entities (with existence check) cursor.execute("MERGE INTO ENTITIES e USING (SELECT :name AS NAME FROM dual) src ON (e.name = src.name) WHEN NOT MATCHED THEN INSERT (NAME) VALUES (:name)", [entity1, entity1]) cursor.execute("MERGE INTO ENTITIES e USING (SELECT :name AS NAME FROM dual) src ON (e.name = src.name) WHEN NOT MATCHED THEN INSERT (NAME) VALUES (:name)", [entity2, entity2]) # Retrieve the IDs cursor.execute("SELECT ID FROM ENTITIES WHERE NAME = :name", [entity1]) source_id = cursor.fetchone()[0] cursor.execute("SELECT ID FROM ENTITIES WHERE NAME = :name", [entity2]) target_id = cursor.fetchone()[0] # Create relations cursor.execute(""" INSERT INTO RELATIONS (SOURCE_ID, TARGET_ID, RELATION_TYPE, SOURCE_TEXT) VALUES (:src, :tgt, :rel, :txt) """, [source_id, target_id, relation, source]) print(f"✅ {entity1} -[{relation}]-> {entity2}") except Exception as e: print(f"[INSERT ERROR] {e}") oracle_conn.commit() cursor.close() print("💾 Knowledge graph updated.")-
圖形綱要是使用
CREATE PROPERTY GRAPH、連結ENTITIES(頂點) 和RELATIONS(邊緣) 建立的。 -
只有在實體不存在時,才使用
MERGE INTO來插入新實體 (確保其唯一性)。 -
LLM (Oracle Generative AI) 用於擷取
Entity1 -[RELATION]-> Entity2.格式的三倍 -
所有與 Oracle 的互動都是透過
oracledb和 PL/SQL 匿名區塊來完成。
現在您可以:
-
使用 PGQL 探索及查詢圖表關係。
-
連線至 Graph Studio 以進行視覺化。
-
透過 API REST 或 LangChain 代理程式公開圖表。
-
-
圖表查詢支援功能
在知識圖表上啟用語意搜尋與推理的兩個基本函數:
extract_graph_keywords與query_knowledge_graph。這些元件可讓您使用 Oracle Autonomous Database 上的 PGQL,將問題解譯成有意義的圖表查詢。-
extract_graph_keywords:def extract_graph_keywords(question: str) -> str: prompt = f""" Based on the question below, extract relevant keywords (1 to 2 words per term) that can be used to search for entities and relationships in a technical knowledge graph. Question: "{question}" Rules: - Split compound terms (e.g., "API Gateway" → "API", "Gateway") - Remove duplicates - Do not include generic words such as: "what", "how", "the", "of", "in the document", etc. - Return only the keywords, separated by commas. No explanations. Result: """ try: resp = llm_for_rag.invoke(prompt) keywords_raw = resp.content.strip() # Additional post-processing: remove duplicates, normalize keywords = {kw.strip().lower() for kw in re.split(r'[,\n]+', keywords_raw)} keywords = [kw for kw in keywords if kw] # remove empty strings return ", ".join(sorted(keywords)) except Exception as e: print(f"[KEYWORD EXTRACTION ERROR] {e}") return ""用途:
-
使用 LLM (
llm_for_rag) 將自然語言問題轉換為適用於圖形的關鍵字清單。 -
提示的設計是要完全擷取與搜尋圖形相關的實體和術語。
為何重要:
-
它可銜接非結構化問題與結構化查詢之間的差距。
-
確保在 PGQL 查詢中僅使用特定的網域相關詞彙進行比對。
LLM 增強的行為:
-
中斷複合技術術語。
-
移除停用詞 (例如什麼、如何等等)。
-
以小寫與去除重複的字詞標準化文字。
範例:
-
輸入:
"What are the main components of an API Gateway architecture?" -
輸出關鍵字:
api, gateway, architecture, components
-
-
query_knowledge_graph:def query_knowledge_graph(query_text): cursor = oracle_conn.cursor() sanitized_text = query_text.lower() pgql = f""" SELECT from_entity, relation_type, to_entity FROM GRAPH_TABLE( {GRAPH_NAME} MATCH (e1 is ENTITIES)-[r is RELATIONS]->(e2 is ENTITIES) WHERE CONTAINS(e1.name, '{sanitized_text}') > 0 OR CONTAINS(e2.name, '{sanitized_text}') > 0 OR CONTAINS(r.RELATION_TYPE, '{sanitized_text}') > 0 COLUMNS ( e1.name AS from_entity, r.RELATION_TYPE AS relation_type, e2.name AS to_entity ) ) FETCH FIRST 20 ROWS ONLY """ print(pgql) try: cursor.execute(pgql) rows = cursor.fetchall() if not rows: return "⚠️ No relationships found in the graph." return "\n".join(f"{r[0]} -[{r[1]}]-> {r[2]}" for r in rows) except Exception as e: return f"[PGQL ERROR] {e}" finally: cursor.close()用途:
- 接受以關鍵字為基礎的字串 (通常由
extract_graph_keywords產生),並建構 PGQL 查詢以從知識圖表擷取關係。
主要機制:
-
GRAPH_TABLE子句使用MATCH將圖表從來源周遊至目標節點。 -
它使用
CONTAINS()來允許節點 / 邊緣屬性 (e1.name、e2.name、r.RELATION_TYPE) 中的部分與模糊搜尋。 -
將結果限制為 20,以避免淹水輸出。
為何要使用 PGQL:
-
PGQL 與 SQL 類似,但專為圖表周遊而設計。
-
Oracle Autonomous Database 支援屬性圖形,可實現關聯式與圖形世界之間的無縫整合。
-
提供符合企業級需求的索引、最佳化和原生圖表搜尋功能。
Oracle 特定備註:
-
GRAPH_TABLE()對 Oracle PGQL 而言是唯一的,可查詢透過關聯式表格定義的圖形邏輯檢視。 -
與 Cypher (Neo4j) 不同,PGQL 會使用 SQL 擴充功能在結構化資料上執行,讓它在 RDBMS 重型環境中更為友善。
- 接受以關鍵字為基礎的字串 (通常由
-
任務 4:執行聊天機器人
執行以下命令以執行聊天機器人。
python main.py
相關連結
確認
- 作者 - Cristiano Hoshikawa (團隊解決方案工程師 Oracle LAD A)
其他學習資源
在 docs.oracle.com/learn 上探索其他實驗室,或在 Oracle Learning YouTube 頻道上存取更多免費學習內容。此外,請造訪 education.oracle.com/learning-explorer 以成為 Oracle Learning Explorer。
如需產品文件,請造訪 Oracle Help Center 。
Create a Knowledge Graph with Oracle Autonomous Database and Property Graph Query Language
G38840-02
Copyright ©2025, Oracle and/or its affiliates.