使用 OKE 改善 Cassandra 和 Spark 活動的資料區域性
簡介
Apache Cassandra 是一個分散式無主控資料庫,每個節點都擁有權杖範圍。Apache Spark 是一種分散式運算引擎,可使用 Spark – Cassandra 連接器從 Cassandra 複本讀取。在 Kubernetes 中,無須瞭解資料在何處,即可排定 Pod,確保資料區域性。
本教學課程示範 OKE 如何使用 Kubernetes 原始類型改善區域性:StatefulSets (Cassandra 的穩定識別)、節點標籤以及關聯性 / 反相關性,以與 Cassandra Pod 共置 Spark 執行器 - 從同一個節點 (理想) 提供讀取,或者最差的情況是將一個躍點提供給共置複本。
目標
- 部署 3 節點 OKE 叢集和堡壘主機 (ORM 或 Terraform)。
- 在兩個具有標籤 + 相關性的節點上共置 Cassandra 和 Spark。
- 對 Cassandra 執行和驗證 Spark 讀取工作。
- 使用 VCN 流程日誌監測跨節點流量。
必備條件
- 具有 VCN、OKE、運算、記錄日誌 (流量日誌) 權限的 OCI 租用戶;選擇性監控。
- 堡壘主機存取的 SSH 金鑰組。
- 基本的 Kubernetes 熟悉度 (節點、標籤、Pod 等)。
工作 1:使用 OCI 資源管理程式 (ORM) 部署環境 (建議)。
-
按一下下方即可在 OCI 主控台中開啟堆疊:

-
遵循引導式流程進行:
-
接受使用條款。
-
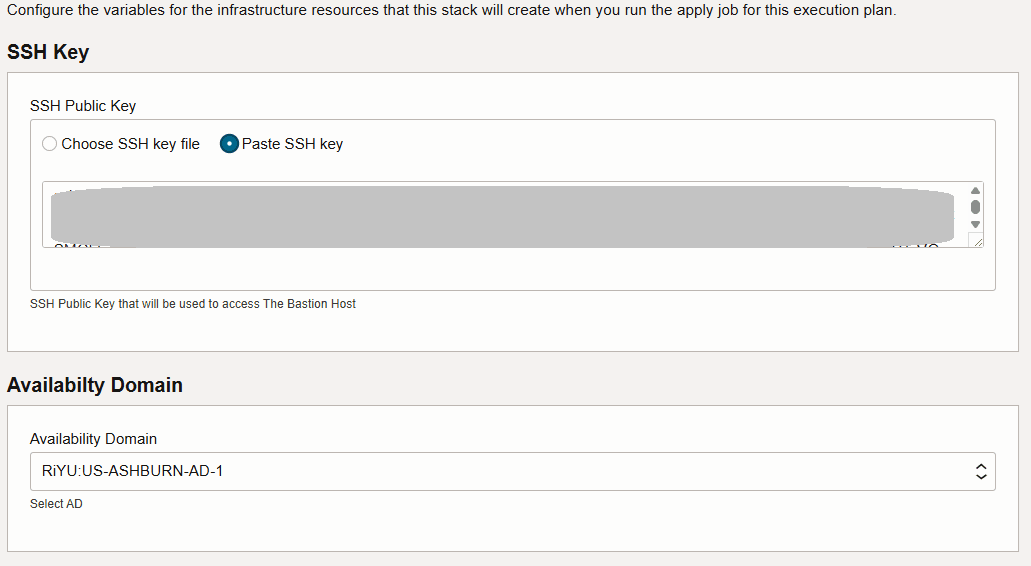
插入 SSH 金鑰並選取可用性網域。
-
您可以將其餘值保留為預設值,以取得部署的 VCN、OKE 叢集和堡壘主機。
-
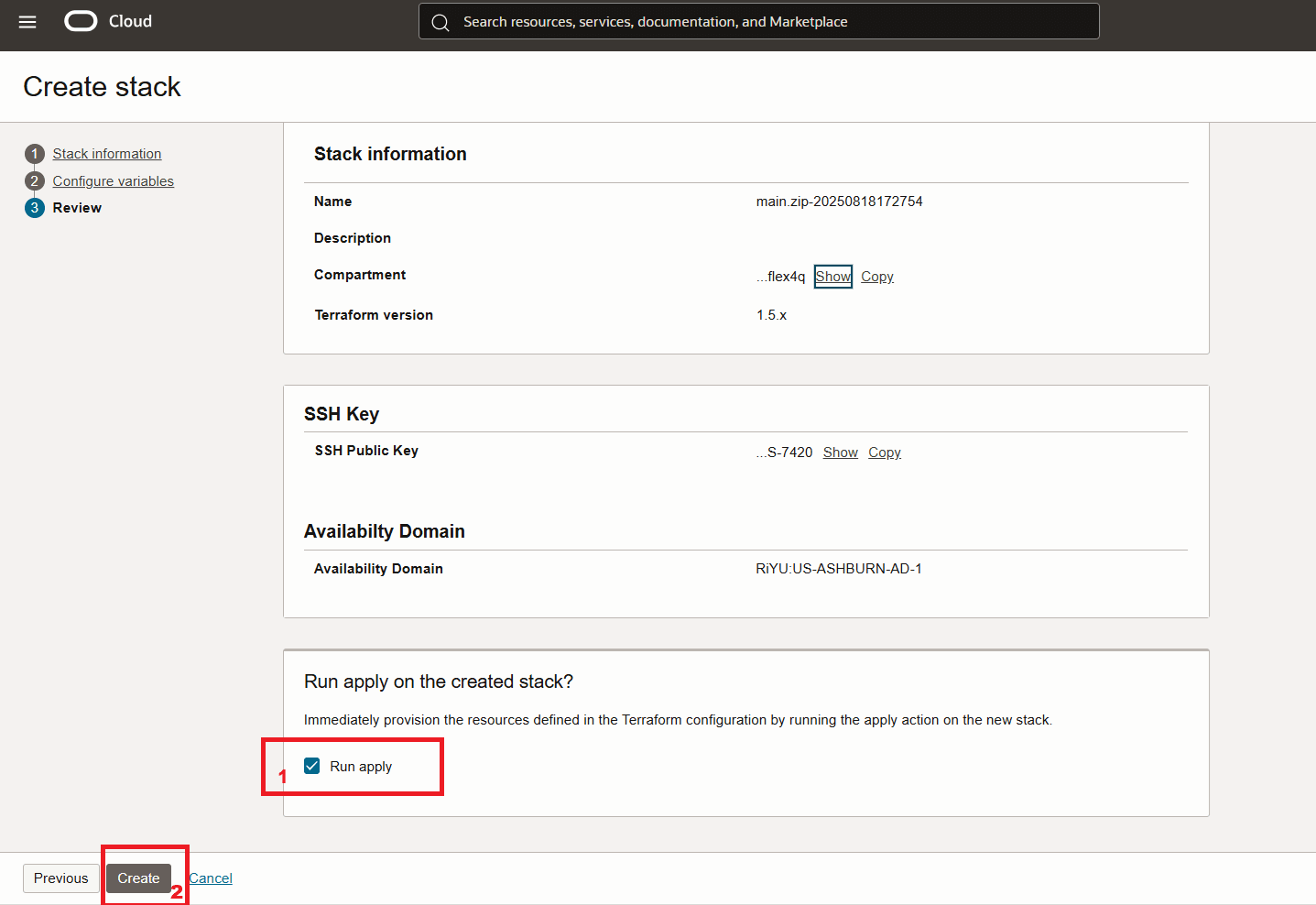
啟動堆疊。
-
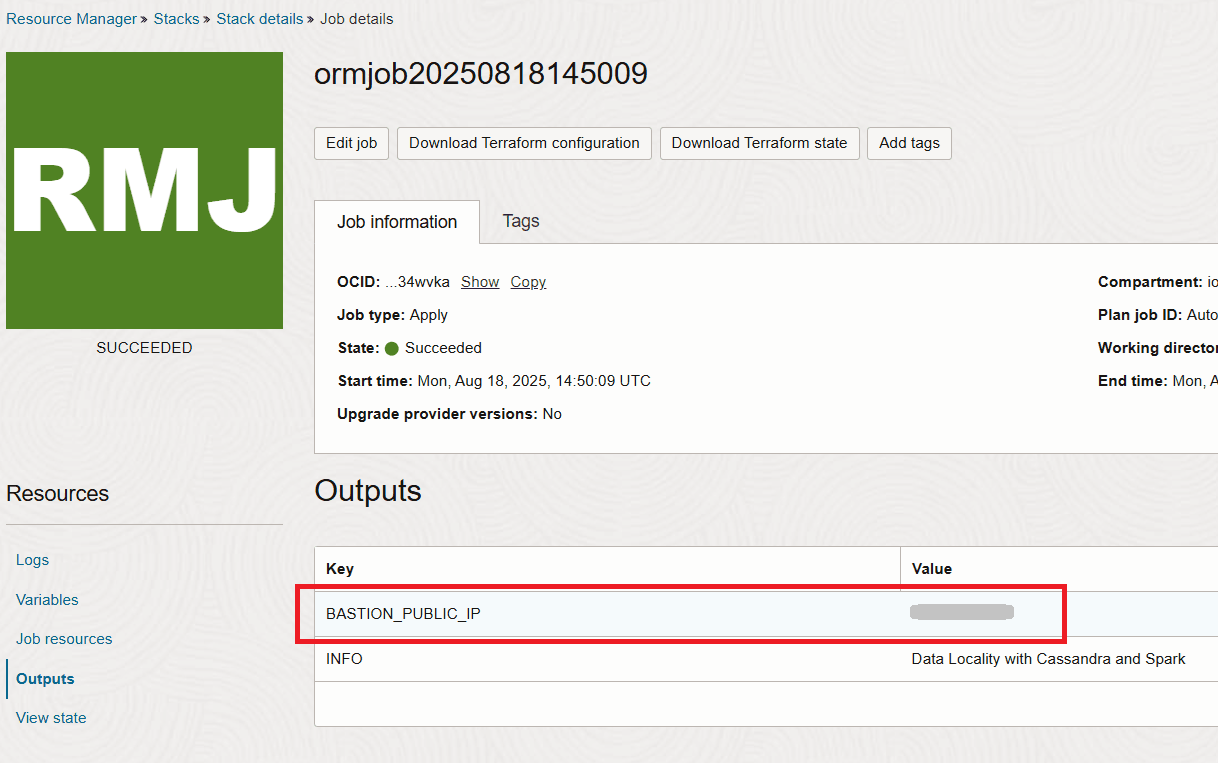
堆疊完成之後,您將會在輸出區段中取得堡壘主機的 IP。
工作 2:連線堡壘主機並驗證部署
初始基礎架構佈建會在 15 分鐘內完成,但完整設定 (透過堡壘主機的 cloud-init) 約需要 20 分鐘的時間來安裝 Helm、部署 Cassandra 和 Spark,然後執行讀取工作。
-
若要監督處理作業,請由 SSH 進入堡壘主機:
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
執行下方命令以監督 cloudinit 命令檔的進度。
tail -f /var/log/oke-automation.log -
當您看到正在讀取的 3 個原始內建值 Cassandra 值和 Cloud-init 完成訊息時,堆疊就會完成。
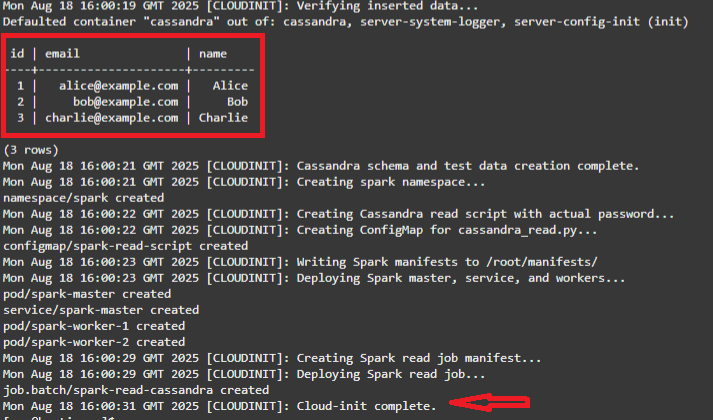
注意:Cloudinit 命令檔已經完成:
- 安裝 kubectl、Helm、OCI CLI (執行處理主體),擷取 kubeconfig。
- 等待職工
- 以
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b為前兩個節點加上標籤 - 安裝 cert-manager 和 k8ssandra-operator (CRD)
- 申請 K8ssandraCluster
- 等待 Cassandra
- 建立 testks.users 並插入 3 列
- 建立 spark 命名空間;使用 /scripts/cassandra_read.py 建立 ConfigMap (讀取 testks.users)
- 部署 Spark 主要服務和兩名工作者 (nodeSelector spark-locality:"true",worker Anti-affinity)
- 提交職務 spark-read-cassandra
-
從堡壘主機 VM 確認現有的節點:
kubectl get nodes -
確認地區標籤。預期兩個節點的 spark-locality=true 和 data-locality=enabled 。
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
驗證 Cassandra 位置:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
驗證 Spark 位置:
kubectl -n spark get pods -o wide -
檢查 Spark 讀取工作日誌。您應該會看到來自 testks.users 的 3 筆記錄和成功執行。
kubectl -n spark logs job/spark-read-cassandra --tail=20
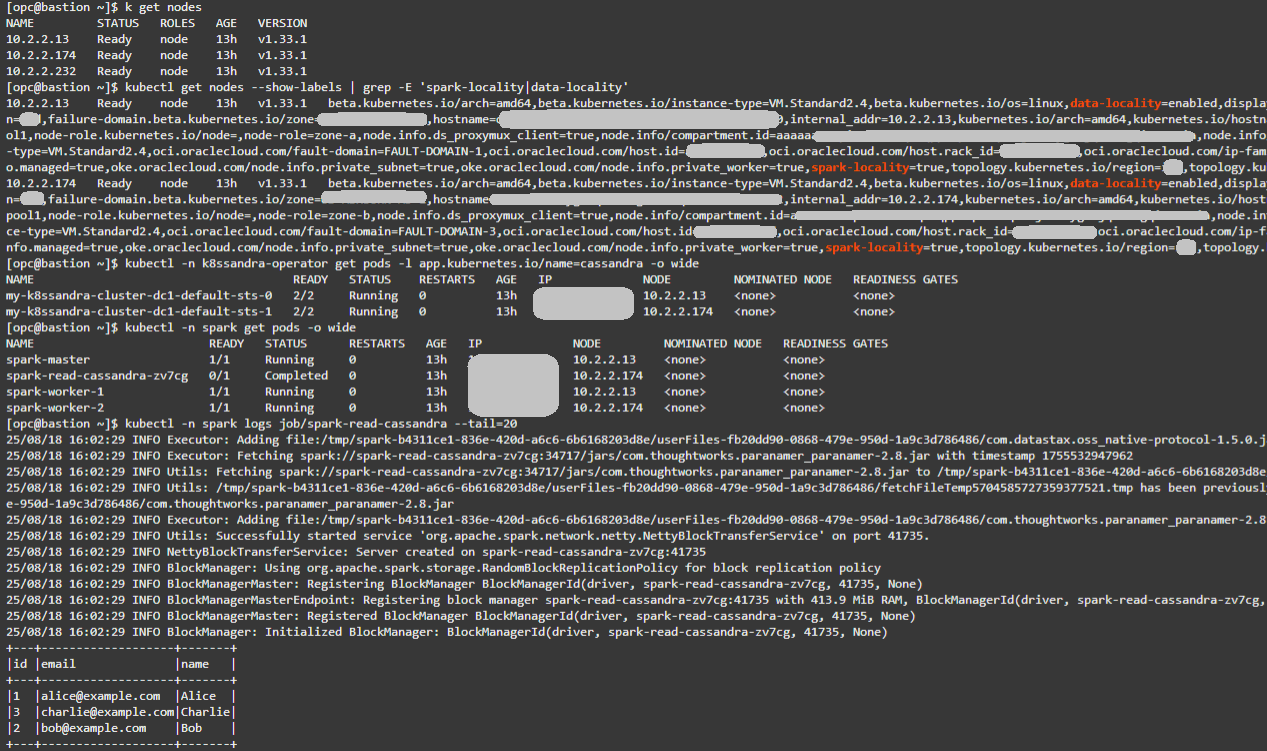
提示:符合 Cassandra 和 Spark Pod 的 NODE 值,可確認共置和理想的地區條件。如需更多結論的「流程日誌」結果,請使用 cqlsh 將其他資料列插入 testks.users。較大的資料集將產生更多讀取流量,讓地區與非地區性的影響更容易觀察。
您可以在下方看到上述指令的範例輸出:
工作 3:使用 VCN 流程日誌監測網路效果
使用 VCN 流量日誌瞭解 Cassandra 流量在 Spark 讀取期間的流量。目前的自動化使用 Flannel (VXLAN),這會影響「流量日誌」可以查看的內容。
CNI 的變更內容
- Flannel (VXLAN,此實驗室):
- 同節點 Pod 流量會停留在主機橋接器 → 沒有 VCN 流量日誌項目。
- 跨節點 Pod 流量會封裝為 UDP
(VXLAN)。依預設,Flannel 會使用連接埠 8472,但如果該連接埠無法使用,則可以選取另一個高 UDP 連接埠。確切的連接埠會依部署而有所不同。
- VCN 原生 Pod 連線 (NPN):
- Pod 會取得 VCN IP,流量則會在 L3 遞送,不會產生重疊。
- 「流量日誌」會顯示實際的應用程式連接埠 (Cassandra:TCP 9042)。
-
在工作者子網路上啟用流量日誌。
在 OCI 主控台中,啟用 OKE 工作節點子網路的流量日誌。重新執行 (或等待) Spark 讀取工作以產生流量。
-
查詢流程日誌 (選擇符合您叢集的路徑)
如果使用此自動化 (Flannel/VXLAN):使用類似下列的進階查詢:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
將
- Pod 與 Pod 流量會在工作者節點 IP (而非 Cassandra 連接埠 9042) 之間,以 UDP
封裝。 - 相同節點讀取:沒有 VCN 流程日誌項目 (流量會保留在本機)。
- 跨節點讀取:如下圖所示,UDP 14789 在工作節點 IP 之間流動。
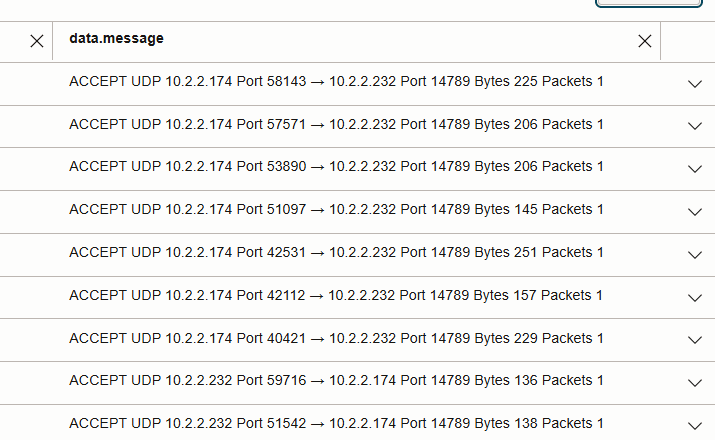
- 比較 UDP 14789 上的封包計數,突顯了資料區域性與非位置的影響。
如果您的叢集使用 NPN:
- 直接在 Pod/ 工作者 IP 之間篩選 TCP dstPort = 9042。
- 您應該將 Cassandra CQL 讀取 / 寫入為 9042 流程。(特別小)
注意:流程日誌可能需要幾分鐘的時間才能擷取新項目。
關鍵考量
-
節點大於 3 的叢集:
區域性比叢集大小增加更重要。若無位置規則,Spark 執行器可以在沒有本機複本的節點上執行,因而導致許多遠端讀取。共置可確保讀取是本機讀取,或最糟糕的是,單一跳躍到另一個複本。
- 同一地點的績效收益:
- 零躍點本機讀取 → 最低延遲。
- 較少的跨節點讀取 → 減少頻寬使用,並降低競爭。
- 以平行方式讀取 Cassandra 的 Spark 工作傳輸量更高。
- 此自動化中使用的機制 :
- StatefulSets → 穩定的 Cassandra Pod 識別。
- 節點標籤 (
spark-locality,data-locality) → 指定共置的節點。 - Pod 相關性 /anti-affinity → 排定在 Cassandra 節點上的 Spark 執行程式,在這些執行節點之間取得平衡。
- K8ssandra 操作員 → 宣告式 Cassandra 部署與管理。
- ConfigMap + Spark 工作 → 驗證 Cassandra 讀取並產生流量。
- VCN 流程日誌 → 觀察並確認區域效果。
- OKE 的範圍 (應用程式層級因子):
- Spark 工作排程和分割區指定。
- Cassandra 複製因子和一致性層次
- 用於選取複本的 Spark – Cassandra 連接器邏輯。
相關連結
提供其他資源的連結。此區段為可選;如有需要請刪除。
確認
- Authors - Adina Nicolescu (首席雲端架構師)
其他學習資源
在 docs.oracle.com/learn 上探索其他實驗室,或在 Oracle Learning YouTube 頻道上存取更多免費學習內容。此外,請造訪 education.oracle.com/learning-explorer 以成為 Oracle Learning Explorer。
如需產品文件,請造訪 Oracle Help Center 。
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53307-01