Release 1 (9.0.1)
Part Number A87499-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Replication Release 1 (9.0.1) Part Number A87499-02 |
|
![]()
![]()
This chapter explains the concepts and architecture of Oracle's master replication sites in both single master and multimaster replication environments.
This chapter contains these topics:
To understand the architectural details of master replication, you need to understand concepts of master replication. Knowing how and why replication is used provides you with a greater understanding of how the individual architectural elements work together to create a multimaster replication environment.
Oracle has two types of master replication: single master replication and multimaster replication. Multimaster replication includes multiple master sites, where each master site operates as an equal peer. In single master replication, a single master site supporting materialized view replication provides the mechanisms to support potentially hundreds or thousands of materialized view sites. A single master site that supports one or more materialized view sites can also participate in a multiple master site environment, creating a hybrid replication environment (combination of multimaster and materialized view replication).
Materialized views can be based on master tables at master sites or on materialized views at materialized view sites. When materialized views are based on materialized views, you have a multitier materialized view environment. In such an environment, materialized views that have other materialized views based on them are called master materialized views.
|
See Also:
Chapter 3, "Materialized View Concepts and Architecture" for more information about multitier materialized views |
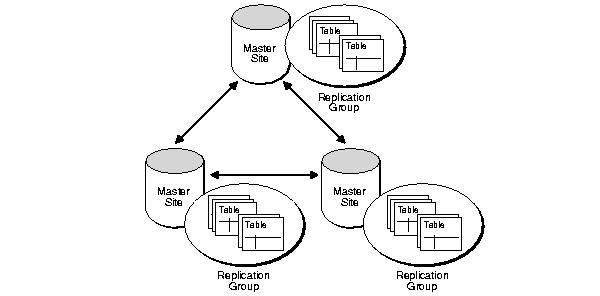
Multimaster replication, also known as peer-to-peer or n-way replication, is comprised of multiple master sites equally participating in an update-anywhere model. Updates made to an individual master site are propagated (sent) to all other participating master sites. Figure 2-1 illustrates a multimaster replication system.
Oracle database servers operating as master sites in a multimaster replication environment automatically work to converge the data of all table replicas, and ensure global transaction consistency and data integrity. Conflict resolution is independently handled at each of the master sites. Multimaster replication provides complete replicas of each replicated table at each of the master sites.
If the replication environment is a hybrid environment (it has multiple master sites supporting one or more materialized view sites), then the target master site propagates any of the materialized view updates to all other master sites in the multimaster replication environment. Then each master site propagates changes to their materialized views when the materialized views refresh.
A single master site can also function as the target master site for one or more materialized view sites. Unlike multimaster replication, where updates to a single site are propagated to all other master sites, materialized views update only their target master site.
Conflict resolution is handled only at master sites or master materialized view sites. Materialized view replication can contain complete or partial replicas of the replicated table.
|
See Also:
Chapter 3, "Materialized View Concepts and Architecture" for more information about materialized view replication with a master site |
A master site can be both a node in a multimaster replication environment and the master for one or more materialized view sites in a single master or multimaster replication environment. The replicated objects are stored at the master site and are available for user access.
In a multimaster replication environment, one master site operates as the master definition site for a master group. This particular site performs many of the administrative and maintenance tasks for the multimaster replication environment.
Each master group can have only one master definition site, though the master definition site can be any of the master sites in the multimaster environment. Additionally, the master definition site can be changed to a different master site if necessary.
A single master site supporting materialized view replication is by default the master definition site.
From a very basic point of view, replication is used to make sure that data is available when and where you need it. The following sections describe several different environments that have different information delivery requirements. Your replication environment may have one or more of the following requirements.
Multimaster replication can be used to protect the availability of a mission critical database. For example, a multimaster replication environment can replicate data in your database to establish a failover site should the primary site become unavailable due to system or network outages. Such a failover site also can serve as a fully functional database to support application access when the primary site is concurrently operational.
You can use Oracle Net to configure automatic connect-time failover, which enables Oracle Net to fail over to a different master site if the first master site fails. You configure automatic connect-time failover in your tnsnames.ora file by setting the FAILOVER_MODE parameter to on and specifying multiple connect descriptors.
|
See Also:
Oracle9i Net Services Administrator's Guide for more information about configuring connect-time failover |
Multimaster replication is useful for transaction processing applications that require multiple points of access to database information for the following purposes:
Applications that have application load distribution requirements commonly include customer service oriented applications.
Materialized view replication enables users to remotely store all or a subset of replicated data from a master site in a disconnected environment. This scenario is typical of sales force automation systems where an individual's laptop (a disconnected device) stores a subset of data related to the individual salesperson.
Master sites operate as the target of the materialized view environment. Master site support can be:
There are two types of multimaster replication: asynchronous and synchronous.
Asynchronous replication, often referred to as store-and-forward replication, captures any local changes, stores them in a queue, and, at regular intervals, propagates and applies these changes at remote sites. With this form of replication, there is a period of time before all sites achieve data convergence.
Synchronous replication, also known as real-time replication, applies any changes or executes any replicated procedures at all sites participating in the replication environment as part of a single transaction. If the data manipulation language (DML) statement or procedure fails at any site, then the entire transaction rolls back. Synchronous replication ensures data consistency at all sites in real-time.
You can change the propagation mode from asynchronous to synchronous or vice versa for a master site. If you change the propagation mode for a master site in a master group, then you must regenerate replication support for all master group objects. When you regenerate replication support, Oracle then activates the internal triggers and regenerates the internal packages to support replication of the objects at all master sites. Also, a multimaster replication environment may contain a mixture of both synchronous and asynchronous replication.
Asynchronous replication independently propagates any DML or replicated procedure execution to all of the other master sites participating in the multimaster replication environment. Propagation occurs in a separate transaction after the DML or replication procedure has been executed locally.
Asynchronous replication is the default mode of replication. Asynchronous replication requires less networking and hardware resources than does synchronous replication, resulting in better availability and performance.
Asynchronous replication, however, means that the data sets at the different master sites in the replication environment may be different for a period of time before the changes have been propagated. Also, data conflicts may occur in an asynchronous replication environment.
The following describes the process of asynchronous replication:
After a table has been set up for replication, any DML that a user commits on the table is captured for replication to all other master sites.
For each row that is inserted, updated, or deleted, an internal trigger creates a deferred remote procedure call (RPC) and places it in the deferred transaction queue. The deferred transaction queue contains all deferred RPCs.
If a procedure has been replicated and its wrapper is executed at a master site, then the procedure call is placed in the deferred transaction queue.
Each transaction in the deferred transaction queue has a list of destinations that define where the deferred transaction should be propagated; this list contains all master sites except for the originating site. There is one deferred transaction queue for each site, and this one queue can be used by multiple replication groups.
At scheduled intervals or on-demand, the deferred transactions in the deferred transaction queue are propagated to the target destinations. Each destination may have a different interval.
As a deferred transaction is being propagated to a target destination, each deferred RPC is applied at the destination site by calling an internal package. If the deferred transaction cannot be successfully applied at the destination site, then it is resent and placed into the error queue at the destination site, where the DBA can fix the error condition and re-apply the deferred transaction.
When a deferred transaction queue entry is applied at the remote destination, Oracle checks for data conflicts. If a conflict is detected, then it is logged at the remote location and, optionally, a conflict resolution method is invoked.
Synchronous replication propagates any changes made at a local site to other synchronously linked masters in a replication environment during the same transaction as the initial change. If the propagation fails at any of the master sites, then the entire transaction, including the initial change at the local master site, rolls back. This strict enforcement ensures data consistency across the replication environment. Unlike asynchronous replication, there is never a period of time when the data at any of the master sites does not match.
|
See Also:
"Understanding Mixed-Mode Multimaster Systems" for a discussion on using both synchronous and asynchronous replication in a single environment |
Synchronous replication also ensures that no data conflicts are introduced into the replication environment. These benefits have the cost of requiring many hardware and networking resources with no flexibility for downtime. For example, if a single master site of a six node multimaster environment is unavailable, then a transaction cannot be completed at any master site.
However, in asynchronous replication, the deferred transaction is held at the originating site until the downed site becomes available. Meanwhile, the transaction can be successfully propagated and applied at other replication sites.
Additionally, while query performance remains high because they are performed locally with synchronous replication, updates are slower because of the two-phase commit protocol that ensures that any updates are successfully propagated and applied to the remote destination sites.
The following describes the process of synchronous replication:
After a table has been set up for replication, any DML that a user commits on the target table is captured for replication to all other master replication sites.
If a procedure has been replicated and its wrapper is executed at a master site, then the procedure call is captured for replication.
The internal trigger captures any DML and immediately propagates these actions to all other master sites in the replication environment. The internal trigger applies these actions in the security context of the propagator's database link and uses an internal RPC to apply these actions at the destination site.
Like an internal trigger, a wrapper for a replicated procedure immediately propagates the procedure call to all other master sites in the replication environment.
If the transaction fails at any one of the master replication sites, then the transaction is rolled back at all master sites. This methodology ensures data consistency across all master replication sites. Because of the need to roll back a transaction if any site fails, synchronous replication is extremely dependent on highly-available networks, databases, and the associated hardware.
When Oracle replicates a table, any DML applied to the replicated table at any replication site (either master or materialized view site) that causes a data conflict at a destination site is automatically detected by the Oracle server at the destination site. Any data conflicts introduced by a materialized view site are detected and resolved at the target master site or master materialized view site of the materialized view.
For example, if the following master group is scheduled to propagate changes once an hour, then consider what happens when:
If the time between propagations is considered an interval and two or more sites update the same row during a single interval, then a conflict occurs.
In addition to the update conflict described above, there are insert and delete conflicts. Consider the following summaries of each type of conflict. Each conflict occurs when the conflicting actions occur within the same interval.
|
See Also:
Chapter 5, "Conflict Resolution Concepts and Architecture" for more information about the different types of data conflicts |
After a data conflict is detected, the following actions occur:
When a data conflict is logged in the error queue, then the database administrator is responsible for resolving the data conflict manually.
If you choose to use Oracle-supplied or user-defined conflict resolution methods, then the Oracle server automatically tries to resolve the data conflict. The conflict resolution methods that you implement should conform to the business rules defined for your replication environment and should work to guarantee data convergence. You may need to modify tables to meet the needs of the conflict resolution methods you implement. For example, the latest timestamp conflict resolution method requires a timestamp column in the table on which it is implemented.
Oracle object types are user-defined datatypes that make it possible to model complex real-world entities such as customers and orders as single entities, called objects, in the database. You create object types using the CREATE TYPE ... AS OBJECT statement. You can replicate object types and objects between master sites in a multimaster replication environment.
An Oracle object that occupies a single column in a table is called a column object. Typically, tables that contain column objects also contain other columns, which may be built-in datatypes, such as VARCHAR2 and NUMBER. An object table is a special kind of table in which each row represents an object. Each row in an object table is a row object.
You can also replicate collections. Collections are user-defined datatypes that are based on VARRAY and nested table datatypes. You create varrays with the CREATE TYPE ... AS VARRAY statement, and you create nested tables with the CREATE TYPE ... AS TABLE statement.
|
See Also:
Oracle9i Application Developer's Guide - Object-Relational Features for detailed information about user-defined types, column objects, object tables, and collections. This section assumes a basic understanding of the information in that book. |
User-defined types include all types created using the CREATE TYPE statement, including object, nested table, and VARRAY. To replicate schema objects based on user-defined types, the user-defined types themselves must exist, and must be exactly the same, at all replication sites.
When replicating user-defined types and the schema objects on which they are based, the following conditions apply:
CREATE TYPE cust_address_typ AS OBJECT (street_address VARCHAR2(40), postal_code VARCHAR2(10), city VARCHAR2(30), state_province VARCHAR2(10), country_id CHAR(2)); /
At all replication sites, street_address must be the first attribute for this type and must be VARCHAR2(40), postal_code must be the second attribute and must be VARCHAR2(10), city must be the third attribute and must be VARCHAR2(30), and so on.
DBA_TYPE_VERSIONS data dictionary view.
To ensure that a user-defined type is exactly the same at all replication sites, you must create the user-defined type in one of the following ways:
Oracle Corporation recommends that you use the replication management API to create, modify, or drop any replicated object at a replication site, including user-defined types. If you do not use the replication management API for these actions, then replication errors may result. For example, to add a user-defined type that meets the conditions described previously to all replication sites in a master group, create the type at the master definition site and then use the CREATE_MASTER_REPOBJECT procedure in the DBMS_REPCAT package to add the type to a master group.
You can use a CREATE TYPE statement at a replication site to create the type. It may be necessary to do this if you want to precreate the type at all replication sites and then add it to a replication group.
If you choose this option, then you must ensure the following:
You can find the object identifier for a type by querying the DBA_TYPES data dictionary view. For example, to find the object identifier (OID) for the cust_address_typ, enter the following query:
SELECT TYPE_OID FROM DBA_TYPES WHERE TYPE_NAME = 'CUST_ADDRESS_TYP'; TYPE_OID -------------------------------- 6F9BC33653681B7CE03400400B40A607
Or, if you are creating a new type at a number of different replication sites, then you may want to specify the same OID at each site during type creation. In this case, you can identify a globally unique OID by running the following query:
SELECT SYS_GUID() OID FROM DUAL;
When you know the OID for the type, complete the following steps to create the type at the replication sites where it does not exist:
CREATE TYPE statement and specify the OID:
CREATE TYPE oe.cust_address_typ OID '6F9BC33653681B7CE03400400B40A607' AS OBJECT ( street_address VARCHAR2(40), postal_code VARCHAR2(10), city VARCHAR2(30), state_province VARCHAR2(10), country_id CHAR(2)); /
The type is now ready for use at the replication site.
You can use the Export and Import utilities to maintain type agreement between replication sites. When you export object tables based on user-defined types, or tables containing column objects based on user-defined types, the user-defined types are also exported automatically, if the user performing the export has access to these types. When you import these tables at another replication site, the user-defined types are exactly the same as the ones at the site where you performed the export.
Therefore, you can use export/import to precreate your replication tables at new replication sites, and then specify the use existing object option when you add these tables to a replication group. This practice will ensure type agreement at your replication sites.
When you replicate object tables, the following conditions apply:
You can meet these conditions by using the replication management API to add object tables to a replication group, modify object tables, and drop object tables from a replication group. For example, if you use the CREATE_MASTER_REPOBJECT procedure in the DBMS_REPCAT package to add an object table to a master group, then Oracle ensures that these conditions are met. You can also use export/import to precreate object tables at replication sites to meet these conditions.
Another option is to specify the OID for an object table when you create the object table at multiple replication sites. Complete the following steps if you want to use this option:
DUAL view for a globally unique OID:
SELECT SYS_GUID() OID FROM DUAL; OID -------------------------------- 81D98C325D4A45D0E03408002074B239
categories_tab object table with the OID returned in Step 1 at each replication site:
CREATE TABLE categories_tab5 OF category_typ OID '81D98C325D4A45D0E03408002074B239' (category_id PRIMARY KEY);
Collection columns are columns based on VARRAY and nested table datatypes. Oracle supports the replication of collection columns. When you add a table with a collection column to a replication group, the data in the collection column is replicated automatically. If the collection column is a varray, then varrays larger than four kilobytes are stored as BLOBs.
If the collection column is a nested table, then Oracle performs row-level replication for each row in the nested table's storage table. For example, changes in five rows of a storage table result in five distinct remote procedure calls (RPCs), and five distinct conflict detection and optional resolution phases. The storage table can be stored as an index-organized table.
In addition, DML on a row that contains a nested table results in separate RPCs for the parent table and for each affected row in the nested table's storage table. Oracle does not perform referential integrity checks between the rows in the parent table and the rows in the storage table unless you explicitly specified integrity constraints during the creation of the parent table. Oracle Corporation recommends that you specify such constraints for replicated tables to detect all conflicts.
To ensure conflict detection between a nested table and its storage table, Oracle Corporation recommends that you define a deferrable foreign key constraint between them. Without a deferrable foreign key constraint, a conflict may insert rows in the storage table that cannot be accessed. A deferrable foreign key constraint causes an error to be raised in these situations so that the conflict is detected. You use the DEFERRED clause of the SET CONSTRAINTS statement to defer a constraint.
The following actions are not allowed directly on the storage table of a nested table in a replicated table:
These actions can occur indirectly when they are performed on the parent table of the storage table. In addition, you cannot replicate a subset of the columns in a storage table.
A REF is an Oracle built-in datatype that is a logical "pointer" to a row object in an object table. A scoped REF is a REF that can only contain references to a specified object table, while an unscoped REF can contain references to any object table in the database. A scoped REF requires less storage space and provides more efficient access than an unscoped REF. Oracle supports the replication of tables with REFs.
If a table with a scoped REF is replicated and the object table referenced by a REF is not replicated, then you must create the referenced object table at the sites where it does not exist before you begin replicating the table containing the scoped REF. Otherwise, replicating this table results in an error when the scoped REF cannot find the referenced object table. Typically, in this situation, it is best to replicate the referenced object table as well because it may become out of sync at the various replication sites if it is not replicated.
If a table with an unscoped REF is replicated and the object table referenced by the REF is not replicated, then a dangling REF may result at replicated sites if the REF cannot find the referenced object. For a replicated REF to be valid, the referenced object table must exist at each replication site.
If the WITH ROWID option is specified for a REF column, then Oracle maintains a hint for the rowid of the row object referenced in the REF. Oracle can find the object referenced directly using the rowid contained in the REF, without the need to fetch the rowid from the OID index. The WITH ROWID option is not supported for scoped REFs.
Replicating a REF created using the WITH ROWID option results in an incorrect rowid hint at each replication site, except the site where the REF was first created or modified. The ROWID information in the REF is meaningless at the other sites, and Oracle does not correct the rowid hint automatically. Invalid rowid hints can cause performance problems. In this case, you must use the ANALYZE statement to correct rowid hints at each replication site where they are incorrect.
Although you can build a replication environment by following the procedures and examples described in the online help for the Replication Management tool and in the Oracle9i Replication Management API Reference, understanding the architecture of replication gives you valuable information for setting up your database environment to support replication, tuning your replication environment, and troubleshooting your replication environment when necessary. This section describes the architecture of replication in terms of mechanisms and processes.
To support a replication environment, Oracle uses the following mechanisms at each master site that is participating in either a multimaster replication or single master replication environment. Some of the following master site mechanisms are required only in special circumstances.
Depending on your security requirements, the following three roles may be consolidated into a single replication administrator. In fact, most multimaster replication environments use a single user to perform the replication administration, propagation, and receiving roles. If you have more stringent security requirements, then you may assign the following roles to different users.
The replication administrator performs all of the administrative functions relating to a master site in a replication environment. In general, it is preferable to have a single replication administrator for a replication environment. In addition to preparing a database to support replication, the replication administrator has the following responsibilities:
The default username for this administrator is repadmin, but you can use any username you wish.
The propagator performs the task of propagating each transaction contained in the deferred transaction queue to the transaction's destinations. There is a single propagator for the database. In other words, it is possible for you to have multiple replication administrators to manage different schemas, but there can only be a single propagator for each database.
The receiver is responsible for receiving and applying the deferred transactions from the propagator. If the receiver does not have the appropriate privileges to apply a call in the deferred transaction, then the entire deferred transaction is placed in the error queue at the destination. You can register the receiver by using the REGISTER_USER_REPGROUP procedure in the DBMS_REPCAT_ADMIN package.
Database links provide the conduit to replicate data between master sites and materialized view sites. In a multimaster environment, there is a database link from each individual master site to all other master sites. Another way to look at the configuration of database links is that there are N - 1 database links for each master site, where N is the total number of master sites.
In Figure 2-3, each master site has two database links to the other master sites (N-1 or in this case 3 - 1 = 2). This configuration ensures the bi-directional communication channels between master sites needed for multimaster replication. Notice that for a materialized view site, only a link from the materialized view site to the master site is required. The master site does not need a database link to the materialized view site.
The most basic setup has a database link from the replication administrator at the individual master site to the replication administrators at the other participating master replication sites.
A common approach, however, adds an additional set of database links to your replication environment. Before creating any replication administrator database links, you create public database links between all of the participating master sites, without specifying a CONNECT TO clause. The public database links specify the target of each database link with the USING clause, which specifies the service name of a remote database.
After creating the public database links, you can create the private replication administrator database links. When creating private database links, you specify the CONNECT TO clause, but the associated public database link eliminates the need to specify a USING clause.
The approach of using both public and private database links reduces the amount of administration needed to manage database links. Consider the following advantages:
tnsnames.ora file entry for the target database. Remember that the USING clause specifies the service name for the remote target database. All private database links for the same target point to the destination defined in the USING clause in the public database link.
For example, if a database is moved to a different server but keeps the same service name, then you can update the tnsnames.ora file entry for the remote database at each replication site, and you do not need to re-create the database link.
As previously described, the replication administrator usually performs the tasks of administration and propagation in a multimaster environment. Because a single user performs these tasks, only one set of private database links must be created for the replication administrator.
However, in multimaster replication environments where propagation is performed by users other than the replication administrator, the appropriate set of private database links must be created for each of these alternate users.
If you use the Setup Wizard in the Replication Management tool in Oracle Enterprise Manager to set up your replication sites, then, by default, the Setup Wizard creates database links with a USING clause that contains the description of the service name in the tnsnames.ora file or the Oracle Management Server.
For example, suppose the tnsnames.ora file entry for a site is the following:
HQ.MYCOMPANY.COM = '(DESCRIPTION= (ADDRESS=(PROTOCOL=TCP)(HOST=server1)(PORT=1521)) (CONNECT_DATA=(SID=hqdb)(SERVER=DEDICATED)))'
Here, the service name is HQ.MYCOMPANY.COM and the description is the text after the first equal sign. The following statement shows an example of a database link to the HQ.MYCOMPANY.COM site created by the Setup Wizard:
CREATE PUBLIC DATABASE LINK "HQ.MYCOMPANY.COM" USING '(DESCRIPTION= (ADDRESS=(PROTOCOL=TCP)(HOST=server1)(PORT=1521)) (CONNECT_DATA=(SID=hqdb)(SERVER=DEDICATED)))'
The Setup Wizard uses the description of the service name and not the service name itself because different sites may have different information in their tnsnames.ora files. For example, if the Setup Wizard only used the service name and not the service name description, then the user would be required to ensure that the same service name exists and has the same information in the tnsnames.ora file at all sites, because there is no way for the Replication Management tool to check for this requirement.
By using the description for the service name, the Setup Wizard ensures that the database link is valid for all replication sites. The drawback to this type of database link is that, in the rare cases when service name description of a database changes, you must drop and re-create the database link. If the database link is created only with the service name and not the description, then you could change the tnsnames.ora file at all sites and retain the same database link.
Connection qualifiers allow several database links pointing to the same remote database to establish connections using different paths. For example, a database named ny can have two public database links named ny.world that connect to the remote database using different paths.
ny.world@ethernet, a link that connects to ny using an ethernet link
ny.world@modem, another link that connects to ny using a modem link
For the purposes of replication, connection qualifiers can also enable you to more closely control the propagation characteristics for multiple master groups. Consider, if each master site contains three separate master groups and you are not using connection qualifiers, then the scheduling characteristics for the propagation of the deferred transaction queue is the same for all master groups. This may be costly if one master group propagates deferred transactions once an hour while the other two master groups propagate deferred transactions once a day.
Associating a connection qualifier with a master group gives you the ability to define different scheduling characteristics for the propagation of the deferred transaction queue on a master group level versus on a database level as previously described.
When you create a new master group, you can indicate that you want to use a connection qualifier for all scheduled links that correspond to the group. However, when you use connection qualifiers for a master group, Oracle propagates information only after you have created database links with connection qualifiers at every master site. After a master group is created, you cannot remove, add, or change the connection qualifier for the group.
|
Note:
If you plan to use connection qualifiers, then you probably need to increase the value of the |
The most visible part of your replication environment is the replicated objects themselves. Of these replicated objects, replicated tables are the foundation of your replication environment. The following sections discuss replicating the related database objects. These discussions highlight the benefits and potential limitations of replicating the following types of database objects:
In most cases, replicated tables are the foundation of your replication environment. After a table is selected for replication and has had replication support generated, it is monitored by internal triggers to detect any DML applied to it.
When you replicate a table, you have the option of replicating the table structure and table data to the remote data sites or just the table structure. Additionally, if a table of the same name and structure already exists at the target replication site, then you have the option of using the existing object in your replication environment.
Any index that is used to enforce a constraint in a table is automatically created at the remote destination sites when a table is selected for replication and created at the remote site. Any index that is used for performance reasons, however, must be explicitly selected for replication to be created at the other master sites participating in the replication environment. When an index is replicated to other sites, it operates as if the index was created locally. You do not need to generate replication support for indexes.
Oracle supports the replication of domain indexes. You can replicate the definition of storage tables for domain indexes, but you cannot replicate the storage tables themselves because they typically contain ROWID information.
|
See Also:
|
Selecting packages and package bodies for replication and generating the needed replication support gives you the ability to do procedural replication. Procedural replication can offer performance advantages for large, batch-oriented operations on large numbers of rows that can be run serially within a replication environment.
All parameters for a procedure with replication support must be IN parameters. OUT and IN/OUT modes are not supported. The following datatypes are supported for these parameters:
VARCHAR2
NVARCHAR2
NUMBER
DATE
RAW
ROWID
CHAR
NCHAR
BLOB)
CLOB)
NCLOB)
A replicated procedure must be declared in a package. Standalone procedures cannot have replication support.
|
Note: Similar to the concepts presented in the "Alternative Uses for Table Replication" sidebar, you can select a package and package body for replication but not generate replication support to use replication as an easy way to distribute the object to a remote site, though any calls made to the package are not replicated. |
Procedures and functions not declared as part of a package cannot have replication support. Though you cannot create a procedural replication environment with standalone procedures and functions, you can still use replication to distribute these standalone procedures and functions to the sites in your replication environment. When the standalone procedure or function is created at the remote site using replication, the created object does not have replication support and operates as though the object was created locally.
To replicate schema objects with user-defined types, the user-defined types must exist on all replication sites and be exactly the same at all replication sites.
To make sure that any application or database logic is present at each master site, you can select triggers for replication. An important example of replicating a trigger is replicating a trigger that automatically inserts a timestamp into a table when any DML is applied to the table.
To avoid refiring of the trigger, it is important to insert an API call into the trigger to detect if the trigger is being fired through a local or remote call. This is to avoid the situation where the trigger updates a row that causes the trigger to fire again. Notice line 5 in the following code example:
1) CREATE OR REPLACE TRIGGER hr.insert_time 2) BEFORE 3) INSERT OR UPDATE ON hr.employees FOR EACH ROW 4) BEGIN 5) IF DBMS_REPUTIL.FROM_REMOTE = FALSE THEN 6) :NEW.TIMESTAMP := SYSDATE; 7) END IF;
8) END;
If the DBMS_REPUTIL.FROM_REMOTE function determines that the insert or update was locally initiated, then the defined action (that is, assign timestamp) occurs. If this function determines that the insert or update is from a remote site, then the timestamp value is not assigned.
|
See Also:
Oracle9i Replication Management API Reference for more information about creating replicated triggers |
When you replicate a view, an object view or a synonym, you are simply using replication to distribute these objects to the other master sites that are involved in the replication environment. After the object is replicated to the other sites, it operates as if the object was created locally. No internal trigger or package monitors the object to capture any changes. Because it is a replicated object, though, you can still drop or modify it using either the Replication Management tool or the replication management API.
Oracle supports the replication of indextypes. You must explicitly replicate the type and type body functions that you use to implement an indextype, either using the Replication Management tool or the CREATE_MASTER_REPOBJECT procedure in the DBMS_REPCAT package.
Developers of object-oriented applications can extend the list of built-in relational operators (for example, +, -, /, *, LIKE) with domain specific operators (for example, Contains, Within_Distance, Similar) called user-defined operators. When you replicate a user-defined operator, you are simply using replication to distribute the operator to the other master sites that are involved in the replication environment. After the object is replicated to the other sites, it operates as if the operator was created locally. No internal trigger or package monitors the object to capture any changes. Because it is a replicated object, though, you can still drop or modify it using the replication management API.
Because two sequences at different databases can generate the same value, replicating sequences is not supported.
Three alternatives to replicating sequences guarantee the generation of unique values and avoid any uniqueness data conflicts. You can retrieve a unique identifier by executing the following select statement:
SELECT SYS_GUID() OID FROM DUAL;
This SQL operator returns a 16-byte globally unique identifier. This value is based on an algorithm that uses time and datestamp and machine identifier to generate a globally unique identifier. The globally unique identifier appears in a format similar to the following:
4595EF13AB785E73E03400400B40F58B
An alternate solution to using the sys_guid() function is to create a sequence at each of the master sites and concatenate the site name (or other globally unique value) with the local sequence. This approach helps you to avoid any potential duplicate sequence values and helps in preventing insert conflicts as described in the "Conflict Resolution Concepts" section.
Additionally, you can create a sequence at each of the master sites so that each site generates a unique value in your replication environment. You can accomplish this by using a combination of starting, incrementing, and maximum values in the CREATE SEQUENCE statement. For example, you might configure the following:
| Parameter | Master Site A | Master Site B | Master Site C |
|---|---|---|---|
|
|
1 |
3 |
5 |
|
|
10 |
10 |
10 |
|
Range Example |
1, 11, 21, 31, 41,... |
3, 13, 23, 33, 43,... |
5, 15, 25, 35, 45,... |
Using a similar approach, you can define different ranges for each master site by specifying a START WITH and MAXVALUE that would produce a unique range for each site.
Oracle uses internal triggers to capture and store information about updates to replicated data. Internal triggers build remote procedure calls (RPCs) to reproduce data changes made to the local site at remote replication sites. These deferred RPCs are stored in the deferred transaction queue and are propagated to the other master sites participating in the replication environment. The internal triggers supporting data replication are essentially components within the Oracle server executable. Therefore, Oracle can capture and store updates to replicated data very quickly with minimal use of system resources.
Oracle forwards data replication information by propagating (that is, sending and executing) the RPCs that are generated by the internal triggers described above. These RPCs are stored in the deferred transaction queue. In addition to containing the execution command for the internal procedure at the destination site, each RPC also contains the data to be replicated to the target site. Oracle uses distributed transaction protocols to protect global database integrity automatically and ensure data survivability.
When a deferred RPC created by an internal trigger is propagated to the other master sites participating in a replication environment, an internal procedure at the destination site is used to apply the deferred RPC at the remote site. These internal procedures are activated automatically when you generate replication support for a table. These internal procedures are executed based on the RPCs that are received from the deferred transaction queue of the originating site.
The following queues manage the transactions that are generated by Oracle Replication:
This queue stores the transactions (for example, DML) that are bound for another destination in the master group. Oracle stores RPCs produced by the internal triggers in the deferred transaction queue of a site for later propagation. Oracle also records information about initiating transactions so that all RPCs from a transaction can be propagated and applied remotely as a transaction. Oracle's replication facility implements the deferred transaction queue using Oracle's advanced queuing mechanism.
The error queue stores information about deferred transactions that could not be applied successfully at the local site. The error queue does not display information about errors at other master sites in the replication environment. When the error condition has been resolved, you can either reexecute the transaction or delete the transaction from the error queue.
Oracle manages the propagation process using Oracle's job queue mechanism and deferred transactions. Each server has a local job queue. A server's job queue is a database table storing information about local jobs such as the PL/SQL call to execute for a job, when to run a job, and so on. Typical jobs in a replication environment include jobs to push deferred transactions to remote master sites, jobs to purge applied transactions from the deferred transaction queue, and jobs to refresh materialized view refresh groups.
Several mechanisms are required to handle the administrative tasks that are often performed to support a replication environment. These mechanisms allow you to turn on and off a replication environment, as well as monitor the administrative tasks that are generated when you build or modify a replication environment.
There are three modes of operation for a replication environment.
A replication environment in the normal mode allows replication to occur. The replication environment is "running" in this mode. Any transaction against a replicated object is allowed and is appropriately propagated.
Quiescing is the mode that transfers a replication environment from the normal mode to the quiesced mode. While a replication environment is quiescing, the user is no longer able to execute a transaction against a replicated object, but any existing deferred transactions are propagated. Queries against a quiescing table are allowed. When all deferred transactions have been successfully propagated to their respective destinations, the replication environment proceeds to the quiesced mode.
A quiesced replication environment can be considered disabled for normal replication use and is used primarily for administrative purposes (such as adding and removing replicated objects). Replication is "stopped" in this mode. A quiesced state prevents users from executing any transactions against a replicated object in the quiesced master group unless they turn off replication, which can result in divergent data after replication is resumed. Transactions include DML against a replicated table or the execution of a wrapper for a replicated procedure. If master tables are quiesced, then materialized views based on those master tables cannot propagate their changes to the target master tables, but local changes to the materialized view can continue.
A replication environment is quiesced on a master group level. All master sites participating in the master group are affected. When a master group reaches a quiesced state, you can be certain that any transactions in the deferred transaction queue have been successfully propagated to the other master sites or put into the error queue. Users can still query tables that belong to a quiesced master group.
Quiescing one master group does not affect other master groups. A master group in normal mode can continue to process updates while other master groups are quiesced.
Though there are three modes of replication operation, there are only two mechanisms to control these modes (recall that the quiescing mode is a transition from a normal to quiesced mode).
Executing the suspend mechanism begins the quiescing mode that transfers the mode of replication operation for a master group from normal to quiesced. When the deferred transaction queue has no unpropagated deferred transactions for the master group, the replication environment proceeds to the quiesced mode.
The suspend mechanism can only be executed when the replication environment is in normal mode. Execute suspend when you need to modify the replication environment.
The resume mechanism transfers a master group from the quiesced replication mode to the normal mode. If you have been performing administrative work on your replication environment (for example, adding replicated objects), then you should verify that the administrative request queue (DBA_REPCATLOG) is empty before executing the resume mechanism.
To configure and manage a replication environment, each participating server uses Oracle's replication management API. A server's replication management API is a set of PL/SQL packages encapsulating procedures and functions administrators can use to configure Oracle's replication features. The Replication Management tool also uses the procedures and functions of each site's replication management API to perform work.
An administrative request is a call to a procedure or function in Oracle's replication management API. For example, when you use the Replication Management tool to create a new master group, the tool completes the task by making a call to the DBMS_REPCAT.CREATE_MASTER_REPGROUP procedure. Some administrative requests generate additional replication management API calls to complete the request.
When you use the Replication Management tool or make a call to a procedure in the DBMS_REPCAT package to administer a replication system, Oracle uses its internal mechanisms to broadcast the request synchronously. If a synchronous broadcast fails for any reason, then Oracle returns an error message and rolls back the encompassing transaction.
When an Oracle server receives an administrative request, it records the request in the DBA_REPCATLOG view and the corresponding DDL statement in a child table of the DBA_REPCATLOG view. When you view administrative requests for a master group at a master site, you might observe requests that are waiting for a callback from another master site. These requests are called AWAIT_CALLBACK requests. Master replication activity cannot resume until all of the administrative requests in the DBA_REPCATLOG view have been applied and any errors resolved.
Whenever you use the Replication Management tool to create an administrative request for a replication group, Oracle automatically inserts a job into the local job queue, if one does not already exist for the group. This job periodically executes the DBMS_REPCAT.DO_DEFERRED_REPCAT_ADMIN procedure. Whenever you synchronously broadcast a request, Oracle attempts to start this job immediately in order to apply the replicated changes at each master site.
Assuming that Oracle does not encounter any errors, DO_DEFERRED_REPCAT_ ADMIN is run whenever a background process is available to execute the job. Oracle automatically determines how often the background process wakes up. You may experience a delay if you do not have enough background processes available to execute the outstanding jobs.
|
See Also:
"Initialization Parameters" and the Oracle9i Database Reference for information about |
For each call of DO_DEFERRED_REPCAT_ADMIN at a master site, the site checks the DBA_REPCATLOG view to see if there are any requests that need to be performed. When one or more administrative requests are present, Oracle applies the request and updates any local views as appropriate. This event can occur asynchronously at each master site.
DO_DEFERRED_REPCAT_ADMIN executes the local administrative requests in the proper order. When DO_DEFERRED_REPCAT_ADMIN is executed at a master that is not the master definition site, it does as much as possible. Some asynchronous activities, such as populating a replicated table, require communication with the master definition site. If this communication is not possible, then DO_DEFERRED_REPCAT_ADMIN stops executing administrative requests to avoid executing requests out of order. Some communication with the master definition site, such as the final step of updating or deleting an administrative request at the master definition site, can be deferred and will not prevent DO_DEFERRED_REPCAT_ADMIN from executing additional requests.
The success or failure of an administrative request at each master site is noted in the DBA_REPCATLOG view at each site. For each master group, the Replication Management tool displays the corresponding status of each administrative request. Ultimately, each master site propagates the status of its administrative requests to the master definition site. If a request completes successfully at a master site, then Oracle removes the callback for the site from the DBA_REPCATLOG view at the master definition site.
If a request completes successfully at all sites, then all entries in the DBA_REPCATLOG view at all sites, including the master definition site, are removed. If a request at a non master definition site fails, then Oracle removes the request at the master site and updates the corresponding AWAIT_CALLBACK request at the master definition site with ERROR status and the reason for the failure.
By synchronously broadcasting the change, Oracle ensures that all sites are aware of the change, and thus are capable of remaining synchronized. By allowing the change to be applied at the site at a future point in time, Oracle provides you with the flexibility to choose the most appropriate time to apply changes at a site.
If an object requires replication support, then you must regenerate replication support after altering the object. Oracle then activates the internal triggers and regenerates the packages to support replication of the altered object at all master sites.
Any materialized view sites that are affected by a DDL change are updated the next time you perform a refresh of the materialized view site. While all master sites can communicate with one another, materialized view sites can communicate only with their associated master site.
If you must alter the shape of a materialized view as the result of a change to its master, then you must drop and re-create the materialized view.
Often referred to as the administrative request queue, the DBA_REPCATLOG view stores administrative requests that manage and modify your replication environment. Some DBMS_REPCAT procedures that are executed are listed in the administrative request queue. For example, if you wanted to add an additional replicated table to an existing master group, then you would see a request naming the DBMS_REPCAT.CREATE_MASTER_REPOBJECT procedure.
You can view the administrative request queue by querying the DBA_REPCATLOG view or view the Administrative Requests dialog box in the Replication Management tool.
Each request has a status that displays the state of the request. Here are the possible states:
READY: The READY state indicates that the request is ready to be executed. If you monitor the administrative request queue and a request remains in the READY state for a long time, then a request in front of the ready request may be waiting for a callback. Typically, administrative requests in the READY state are waiting for a job to execute them. You can execute them manually by using the DO_DEFERRED_REPCAT_ADMIN procedure in the DBMS_REPCAT package.
AWAIT_CALLBACK: The AWAIT_CALLBACK state indicates that the request is waiting for a request to be executed at another site and is waiting for confirmation of the request execution. After the request receives the callback, the request is either removed or has its status changed. The request is removed from the queue if it was applied successfully, or its status is changed to ERROR if it failed. This state is only possible at the master definition site.
ERROR: If a request cannot be successfully executed, then it is placed in the ERROR state. The error number appears in the ERRNUM column and the error message appears in the MESSAGE column of the administrative request queue (it is in the Error column when using the Replication Management tool).
DO_CALLBACK: If a request at a master site is in the DO_CALLBACK state, then it means that the master site must inform the master definition site about the success or failure of the request. This state is only possible at a master site that is not the master definition site.
The administrative request queue of each master site lists only the administrative requests to be performed at that master site. The master definition site for a master group, however, lists administrative requests to be performed at each of the master sites. The administrative request queue at the master definition site lets the DBA monitor administrative requests of all the master sites in the replication environment.
Oracle uses several organizational mechanisms to organize the previously described master site and administrative mechanisms to create discrete replication groups. Most notable of these organizational mechanisms is the master group. An additional organization mechanism helps to group columns that are used to resolve conflicts for a replicated table.
In a replication environment, Oracle manages replication objects using replication groups. A replication group is a collection of replication objects that are always updated in a transactionally consistent manner.
By organizing related database objects within a replication group, it is easier to administer many objects together. Typically, you create and use a replication group to organize the schema objects necessary to support a particular database application. That is not to say that replication groups and schemas must correspond with one another. Objects in a replication group can originate from several database schemas, and a schema can contain objects that are members of different replication groups. The restriction is that a replication object can be a member of only one group.
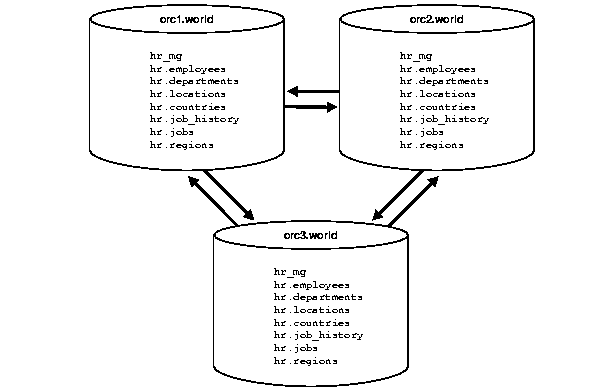
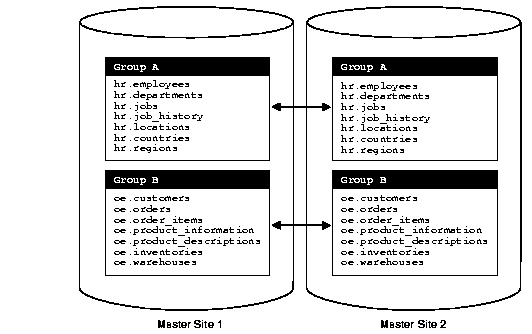
In a multimaster replication environment, the replication groups are called master groups. Corresponding master groups at different sites must contain the same set of replication objects (see "Replication Objects"). Figure 2-4 illustrates that master group hr_mg contains an exact replica of the replicated objects at each master site.
The master group organization at the master site plays an integral role in the organization of replication objects at a materialized view site.
|
See Also:
"Organizational Mechanisms" for more information on the organizational mechanisms at a materialized view site |
Additionally, Figure 2-5 illustrates that each site may contain multiple replication groups, though each group must contain exactly the same set of objects at each master site.
Column groups provide the organizational mechanism to group all columns that are involved in a conflict resolution routine. If a conflict occurs in one of the columns of the group, then the remainder of the group's columns may be used to resolve the conflict. For example, if a column group for a table contains a min_price, list_price, cost_price, and timestamp field and a conflict arises for the list_price field, then the timestamp field may be used to resolve the conflict, assuming that a timestamp conflict resolution routine has been used.
Initially, you might think that you should put all columns in the table into a single column group. Although this makes setup and administration easier, it may decrease the performance of your replicated table and may increase the potential for data conflicts. As you will learn in the "Performance Mechanisms" section, if a conflict occurs in one column group of a table, then the minimum communication feature does not send data from other column groups in the table. Therefore, placing all columns into a single column group may negate the advantages of the minimum communication feature, unless you use the SEND_OLD_VALUES and COMPARE_OLD_VALUES procedures in the DBMS_REPCAT package.
|
See Also:
Chapter 5, "Conflict Resolution Concepts and Architecture" for more information about column groups |
Propagation is the essence of replication because it is the mechanism that sends or distributes any actions to all other master sites in the replication environment.
As the internal trigger captures any DML applied to a replicated table, the DML must be propagated (or sent) to the other master sites in the replication environment. Internal triggers are described in the section "Internal Triggers".
Oracle Replication supports both asynchronous and synchronous replication.
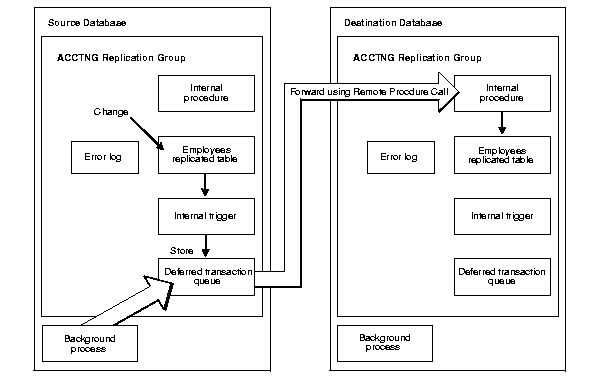
Typical replication configurations use asynchronous data replication. Asynchronous data replication occurs when an application updates a local replica of a table, stores replication information in a local queue, and then forwards the replication information to other replication sites at a later time. Consequently, asynchronous data replication is also called store-and-forward data replication.
As Figure 2-6 shows, Oracle uses its internal triggers, deferred transactions, deferred transaction queues, and job queues to propagate data-level changes asynchronously among master sites in a replication environment, as well as from an updatable materialized view to its master table.
Oracle also supports synchronous data propagation for applications with special requirements. Synchronous data propagation occurs when an application updates a local replica of a table, and within the same transaction also updates at least one other replica of the same table. Consequently, synchronous data replication is also called real-time data replication. Use synchronous replication only when applications require that replicated sites remain continuously synchronized.
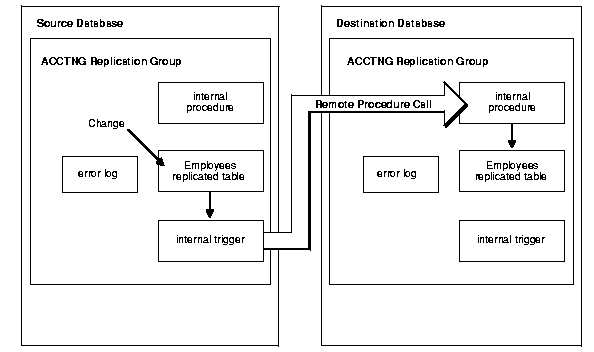
As Figure 2-7 shows, Oracle uses the same internal triggers to generate remote procedure calls (RPCs) that asynchronously replicate data-level changes to other replication sites to support synchronous, row-level data replication. However, Oracle does not defer the execution of such RPCs. Instead, data replication RPCs execute within the boundary of the same transaction that modifies the local replica. Consequently, a data-level change must be possible at all synchronously linked sites that manage a replicated table; otherwise, a transaction rollback occurs.
As shown in Figure 2-8, whenever an application makes a DML change to a local replicated table and the replication group is using synchronous row-level replication, the change is synchronously propagated to the other master sites in the replication environment using internal triggers. When the application applies a local change, the internal triggers issue calls to generated procedures at the remote master sites in the security context of the replication propagator. Oracle ensures that all distributed transactions either commit or rollback in the event of a failure.
|
See Also:
Oracle9i Database Administrator's Guide for more information about distributed transactions |
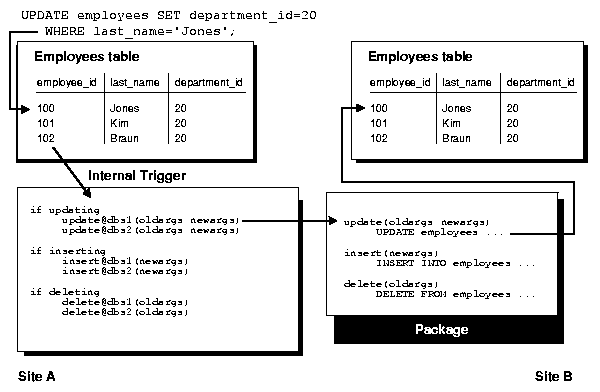
Text description of the illustration rep81030.gif
Because of the locking mechanism used by synchronous replication, deadlocks can occur when the same row is updated at two different sites at the same time. When an application performs a synchronous update to a replicated table, Oracle first locks the local row and then uses an AFTER ROW trigger to lock the corresponding remote row. Oracle releases the locks when the transaction commits at each site.
The necessary remote procedure calls to support synchronous replication are included in the internal trigger for each object. When you generate replication support for a replicated object, Oracle activates the triggers at all master sites to add the necessary remote procedure calls for the new site. Conversely, when you remove a master site from a master group, Oracle removes the calls from the internal triggers.
If all sites of a master group communicate synchronously with one another, then applications should never experience replication conflicts. However, if even one site is sending changes asynchronously to another site, then applications can experience conflicts at any site in the replication environment.
If the change is being propagated synchronously, then an error is raised and a rollback is required. If the change is propagated asynchronously, then Oracle automatically detects the conflicts and either logs the conflict in the error queue or, if you designate an appropriate resolution method, resolves the conflict.
In some situations, you might decide to have a mixed-mode environment in which some master sites propagate a master group's changes asynchronously and others propagate changes synchronously. The order in which you add new master sites to a group with different data propagation modes can be important.
For example, suppose that you have three master sites: A, B, and C. If you first create site A as the master definition site, and then add site B with a synchronous propagation mode, then site A sends changes to site B synchronously and site B sends changes to site A synchronously. There is no need to concern yourself with the scheduling of links at either site, because neither site is creating deferred transactions.
Now suppose that you create master site C with an asynchronous propagation mode. The propagation modes are now as illustrated in Figure 2-9.
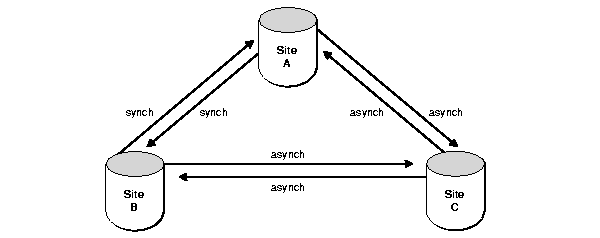
Text description of the illustration rep81040.gif
You must now schedule propagation of the deferred transaction queue from site A to site C, from site B to site C, and from site C to sites A and B.
As another example, consider what would happen if you created site A as the master definition site, then added site C with an asynchronous propagation mode, then added site B with a synchronous propagation mode. Now the propagation modes would be as shown in Figure 2-10.
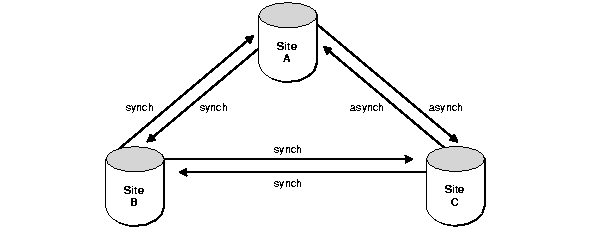
Text description of the illustration rep81041.gif
Each time that you add a new master site to a mixed-mode multimaster system, consider how the addition affects the data propagation modes to and from existing sites.
When synchronous propagation is used, the propagation of the DML is handled immediately and is automatically initiated. If asynchronous propagation is used, then you can use the following methods to propagate the deferred transactions:
As with any enterprise database solution, performance is always an important issue for the database administrator. Oracle Replication provides several mechanisms to help increase the performance of your replication environment.
With parallel propagation, Oracle asynchronously propagates replicated transactions using multiple, parallel transit streams for higher throughput. When necessary, Oracle orders the execution of dependent transactions to ensure global database integrity.
Parallel propagation uses the pool of available parallel processes. This is the same facility Oracle uses for other parallel operations such as parallel query, parallel load, and parallel recovery. Each server process propagates transactions through a single stream. A parallel coordinator process controls these server processes. The coordinator tracks transaction dependencies, allocates work to the server processes, and tracks their progress.
Parallel processes remain associated with a parallel operation on the server throughout the execution of that operation. When the operation is complete, those server processes become available to process other parallel operations. For example, when Oracle performs a parallel push of the deferred transaction queue to its destination, all parallel processes used to push the queue remain dedicated to the push until it is complete.
To configure a pool of parallel processes for a server properly, you must consider several issues related to the configuration of a replication system.
To configure a database server's pool of parallel query processes, use the following initialization parameters:
For most users, setting the parallel propagation parameter to a value of 1 provides sufficient performance. A setting of 1 enables the optimized data transfer method discussed in the previous section instead of serial propagation. However, some users may want to further tune the parallel propagation value.
The following procedure is the recommended method that should be used to further tune the parallel propagation value:
If you have achieved your performance goals with a parallel propagation value of 1, then you have implemented parallel propagation, and you do not need to complete the remaining steps in this procedure.
In many cases, you will experience propagation throughput degradation with a value of 2. This reduction is due to round-trip delays associated with the coordinator assigning dependent transactions to available slaves and waiting for the necessary commit acknowledgments before assigning additional transactions.
Repeat Steps 3 and 4 with the parallel propagation value set to 4 and again with 8. If throughput still does not improve, then it suggests that the transactions in your environment are highly dependent on each other. Reduce the parallel propagation value to 1 and proceed to Step 5.
|
See Also:
"Tuning Parallel Propagation" to learn about techniques to reduce transaction dependencies |
If your performance did improve with a value of 2, 4, or 8, then it suggests that your transactions have a low degree of interdependence. You may even set your parallel propagation parameter to any value greater than 8. Just be sure to thoroughly test your environment and remain aware of the trade-offs between increased parallelism and the necessary resources to support those extra parallel slaves.
To gain the greatest amount of performance benefits from parallel propagation, reduce the amount of dependent transactions that are created. Remember that a transaction cannot start until all of its dependent transactions have been committed.
When trying to reduce the number of dependent transactions:
To increase the replication performance for tables, be sure to enable the minimum communication setting when generating replication support for a replicated table.
To detect and resolve an update conflict for a row, the propagating site must send a certain amount of data about the new and old versions of the row to the receiving site. Depending on your environment, the amount of data that Oracle propagates to support update conflict detection and resolution can vary.
For example, when you create a replicated table and all participating sites are databases using Oracle release 8.0 or greater, you can choose to minimize the amount of data that must be communicated to detect conflicts for each changed row in the table. In this case, Oracle propagates:
In general, you should choose to minimize data propagation in Oracle release 8.0 or greater replication environments to reduce the amount of data that Oracle transmits across the network. As a result, you can help to improve overall system performance.
Alternatively, when a replication environment uses both Oracle7 and release 8.0 or greater sites, you cannot minimize the communication of row data for update conflict detection. In this case, Oracle must propagate the entire old and new versions of each changed row to perform conflict detection.
|
See Also:
"Performance Mechanisms and Conflict Resolution" for more information about conflict resolution, minimum communication, and additional conflict resolution performance techniques |
Though not directly a performance mechanism, properly configuring the delay_seconds parameter can give you greater control over the timing of your propagation of deferred transactions.
When you are pushing deferred transactions, you set the delay_seconds parameter in the SCHEDULE_PUSH procedure or the PUSH function. When you are purging deferred transactions, you set the delay_seconds parameter in the SCHEDULE_PURGE procedure or the PURGE function. These procedures and functions are in the DBMS_DEFER_SYS package.
The delay_seconds parameter controls how long a job remains aware of the deferred transaction queue. The effects of the delay_seconds parameter can best be illustrated with the following two examples:
If a scheduled job with a 60 minute interval wakes up at 2:30 pm and checks the deferred transaction queue, then any existing deferred transactions are propagated. The propagation takes 2 minutes and therefore the job is complete at 2:32 pm.
If a deferred transaction enters the queue at 2:34 pm, then the deferred transaction is not propagated because the job is complete. In this scenario, the deferred transaction will be propagated at 3:30 pm.
If a scheduled job with a 60 minute interval wakes up at 2:30 pm and checks the deferred transaction queue, then any existing deferred transactions are propagated. The propagation takes 2 minutes and therefore the job is complete at 2:32 pm.
If a deferred transaction enters the queue at 2:34 pm, then the deferred transaction is propagated because the job remains aware of the deferred transaction queue for 300 seconds (5 minutes) after the job has completed propagating whatever was in the queue. In this scenario, the deferred transaction is propagated at 2:34 pm.
Why not just set the job to execute more often? Starting and stopping the job has a greater amount of overhead than starting the job and keeping it aware for a set period of time. In addition to decreasing the overhead associated with starting and stopping these jobs, using the delay_seconds parameter can reduce the amount of redo logging required to support scheduled jobs.
As with most performance features, there is a point of diminishing returns. Keep the length of the delay_seconds parameter in check for the following reasons:
delay_seconds value may keep the parallel process unavailable for other operations. To use parallel propagation, you set the parallelism parameter to 1 or higher in the SCHEDULE_PUSH procedure or the PUSH function.
delay_seconds value causes the open session to "sleep" for the entire length of the delay, providing none of the benefits earlier described. To use serial propagation, you set the parallelism parameter to 0 (zero) in the SCHEDULE_PUSH procedure or the PUSH function.
purge_method_precise method when using the DBMS_DEFER_SYS.PURGE procedure and you have defined a large delay_seconds value, then you may experience performance degradation when performing the specified purge. Using purge_method_precise is more expensive than the alternative (purge_method_quick), but it ensures that the deferred transactions and procedure calls are purged after they have been successfully pushed.
As a general rule of thumb, there are few viewable benefits of setting the delay_seconds parameter to a value greater than 20 minutes (which is 1200 seconds for the parameter setting).
Additionally, if you are using serial propagation by setting the parallelism parameter to 0, then you probably do not want to set a large delay_seconds value. Unlike parallel propagation, serial propagation only checks the queue after the duration of the delay_seconds value has elapsed. If you use serial propagation and set delay_seconds to 20 minutes, then the scheduled job will sleep for the entire 20 minutes, and any deferred transactions that enter the deferred transaction queue during that time are not pushed until 20 minutes have elapsed. Therefore, if you are using serial propagation, then consider setting delay_seconds to a value of 60 seconds or lower.
If you set a value of 20 minutes for parallel propagation, then the parallel push checks once a minute. If you can afford this resource lock, then the relatively high delay_seconds value of 20 minutes is probably most efficient in your environment. If, however, you cannot afford this resource lock, then consider setting the delay_seconds value to 10 or 20 seconds. Although you will need to execute the jobs more often than if the value was set to 1200 seconds, you still gain many of the benefits of the delay_seconds feature (versus the default value of 0 seconds).
In a multimaster replication environment, Oracle ensures that transactions propagated to remote sites are never lost and never propagated more than once, even when failures occur. Oracle protects transactions in the following ways:
In the case of parallel propagation, replication uses a special-purpose distributed transaction protocol optimized for propagation. The remote site keeps track of the transactions that have been propagated successfully and sends this information back to the local site when it is requested. The local site records this information and purges the entries in its local queue that have been propagated to all destination sites. In case of failures, the local site asks the remote site for information on the transactions that have been propagated successfully so that propagation can continue at the appropriate point.
|
See Also:
|
Oracle maintains dependency ordering when propagating replicated transactions to remote sites. For example, consider the following transactions:
Transaction B depends on transaction A because transaction B sees the committed update cancelling the order (transaction A) on the local system.
Oracle propagates transaction B (the refund) after it successfully propagates transaction A (the order cancellation). Oracle applies the updates that process the refund after it applies the cancellation.
When Oracle executes a new transaction on the local system, Oracle completes the following process:
Parallel propagation maintains data integrity in a manner different from that of serial propagation. With serial propagation, Oracle applies all transactions in the same order that they commit on the local system to maintain any dependencies. With parallel propagation, Oracle tracks dependencies and executes them in commit order when dependencies can exist and in parallel when dependencies cannot exist. With both serial and parallel propagation, Oracle preserves the order of execution within a transaction. The deferred transaction executes every remote procedure call at each site in the same order as it was executed within the local transaction.
When you create a table, you can specify the following options for tracking system change numbers (SCN)s:
NOROWDEPENDENCIES, the default, specifies that the SCN is tracked at the data block level.
ROWDEPENDENCIES specifies that the SCN is tracked for each row in the table.
When you use the NOROWDEPENDENCIES clause for a table, the data block SCN tracks the most recent update of a row that is stored in the data block. Other rows that were updated earlier may be stored in the same data block, but information about when these rows were updated is lost when a new SCN is applied at the data block level.
When you use the ROWDEPENDENCIES clause for a table, multiple SCNs can be stored in a single data block. That is, a separate SCN tracks changes for each row that is stored in the data block. If two rows that are stored in the same data block are changed by different transactions, then each row has an SCN that tracks the change. To track the SCN at the row level, each row in the table uses an additional six bytes of storage space.
Using the ROWDEPENDENCIES clause for a table enables parallel propagation to track dependencies and order changes more efficiently when applying the deferred transaction queue. This increased efficiency improves performance and provides greater scalability in replication environments.
You can use the following query to list the tables that are using the ROWDEPENDENCIES clause currently:
SELECT OWNER, TABLE_NAME FROM DBA_TABLES WHERE DEPENDENCIES = 'ENABLED';
|
See Also:
"Row-Level Dependency Tracking" for information about creating a table using the |
If you did not use the ROWDEPENDENCIES clause for some of your replicated tables, then you can improve the performance of parallel propagation for these tables by minimizing transaction dependencies.
In this case, certain application conditions can establish dependencies among transactions that force Oracle to serialize the propagation of deferred transactions. When several unrelated transactions modify the same data block in a replicated table, Oracle serializes the propagation of the corresponding transactions to remote destinations.
To minimize transaction dependencies created at the data block level, avoid situations that concentrate data block modifications into one or a small number of data blocks. For example, when a replicated table experiences a high degree of INSERT activity, you can distribute the storage of new rows into multiple data blocks by creating multiple free lists for the table.
If possible, avoid situations where many transactions all update the same small table. For example, a poorly designed application might employ a small table that transactions read and update to simulate sequence number generation for a primary key. This design forces all transactions to update the same data block. A better solution is to create a sequence and cache sequence numbers to optimize primary key generation and improve parallel propagation performance.
The receiving master site in a replication environment detects update, uniqueness, and delete conflicts as follows:
INSERT or UPDATE of a replicated row.
UPDATE or DELETE statement because the primary key of the row does not exist.
To detect and resolve an update conflict for a row, the propagating site must send a certain amount of data about the new and old versions of the row to the receiving site. For maximum performance, tune the amount of data that Oracle uses to support update conflict detection and resolution. For more information, see "Minimum Communication".
Note:
To detect replication conflicts accurately, Oracle must be able to uniquely identify and match corresponding rows at different sites during data replication. Typically, Oracle's replication facility uses the primary key of a table to uniquely identify rows in the table. When a table does not have a primary key, you must designate an alternate key--a column or set of columns that Oracle can use to uniquely identify rows in the table during data replication.
Oracle provides a mechanism that enables you to define a conflict resolution method that resolves a data conflict when detected. Oracle provides several prebuilt conflict resolution methods:
If the prebuilt Oracle conflict resolution methods do not meet the needs of your replication environment, then you have the option of writing your own conflict resolution method using PL/SQL and implementing it as a user-defined conflict resolution method. See Chapter 5, "Conflict Resolution Concepts and Architecture" to learn how conflict resolution works.
|
See Also:
The online help for the Replication Management tool to learn how to implement conflict resolution with the Replication Management tool, and see the Oracle9i Replication Management API Reference to learn how to implement conflict resolution using the replication management API. |
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|