Release 1 (9.0.1)
Part Number A88808-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Data Guard Concepts and Administration Release 1 (9.0.1) Part Number A88808-01 |
|
![]()
![]()
Many organizations today depend on continuous access to data and computing resources. The interruption of computing services due to hardware failures, software failures, or human errors can result in the interruption of database access for primary business functions. When business data is unavailable, the consequences can range from merely inconveniencing certain users, to more severe effects like harming the financial health of the organization.
Oracle9i Data Guard provides a complete set of data protection and disaster recovery features to help you to survive mistakes, corruptions, and disasters that can destroy a database.
This chapter explains Oracle9i Data Guard concepts. It includes the following topics:
Oracle9i Data Guard works with standby databases to protect your data against errors, failures, and corruptions that might otherwise destroy your database. It protects critical data by automating the creation, management, and monitoring aspects of a standby database environment. It automates the otherwise manual process of maintaining a transactionally consistent copy of an Oracle production database for the purpose of recovering from the loss or damage of the production database.
Without Oracle9i Data Guard, the database administrator (DBA) must copy archived redo logs to the remote host and apply them so that the primary database and standby database remain synchronized. Oracle9i Data Guard automates the tasks involved in setting up and managing the Data Guard environment, including one or more standby databases, the log transport services, log apply services, role management services, and related applications.
Generally, redo logs are transferred from the primary database to the standby database as they are archived. However, Oracle9i Data Guard provides the DBA with great flexibility when defining archive destinations, archive completion requirements, I/O failure handling, and automated transmission restart capability.
For example:
You can perform administrative tasks using the Oracle9i Data Guard Manager graphical user interface, the Data Guard command-line interface, or SQL statements.
Figure 1-1 shows an example of a Data Guard configuration that allows failover to occur to either of two standby systems. If the primary site becomes unavailable, the workload can fail over to either standby site.
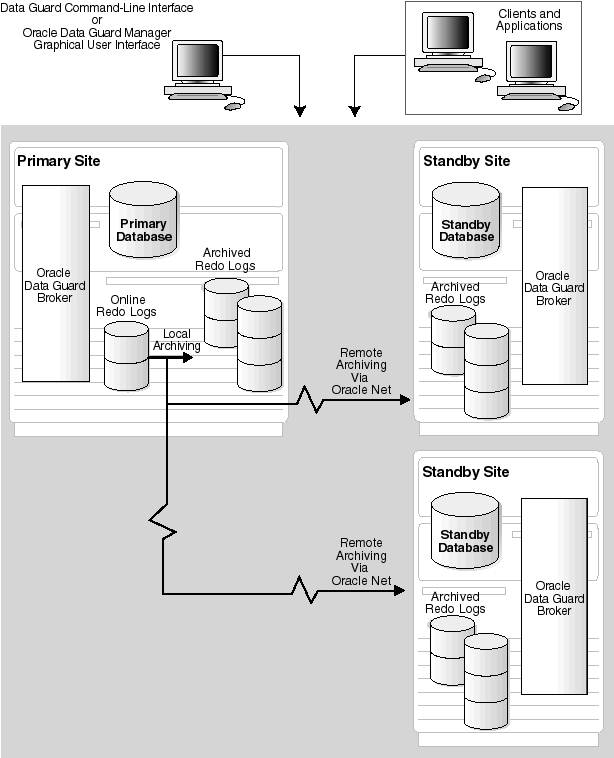
Oracle9i Data Guard helps you survive events that might otherwise destroy your database by:
An Oracle9i Data Guard configuration consists of a collection of loosely connected systems, called sites, that combine the primary database and the physical standby databases into a single, easily managed disaster recovery solution. Often, the sites in a Data Guard configuration are dispersed geographically and are connected by Oracle Net.
The Oracle9i Data Guard broker is the component that helps you to configure database resources into a single unit of failover across a Data Guard configuration. The broker provides two optional interfaces: the Oracle9i Data Guard Manager graphical user interface and the Oracle9i Data Guard command-line interface.
Use the broker to create the database and to manage the database. One site is designated a primary site, where the database is available to applications and from where Oracle Data Guard log transport services automatically transfer the data in the form of archived redo logs. You can configure and instantiate from one to nine additional server sites to serve as standby systems to the primary site. The standby sites accept redo logs archived from the primary site and apply changes to their copies of the database.
The failover and switchover capabilities allow you to determine how the role of the primary database site should migrate in a failure. With the broker, you can define and automate the primary role migration by implementing an n-way failover system with replicated data across all of the server nodes.
For physical standby databases, the risk of physical corruptions is reduced, because the code path and devices where a primary-side physical corruption begins are unlikely to propagate through the archived redo logs that are transported to the standby site.
You can set up the standby database to achieve the following levels of data protection:
Using log apply services, you can control whether you maintain the standby database in managed recovery mode or in open read-only mode.
Besides automating the complex task of configuration, the broker automates the management and operational tasks a DBA must perform across the multiple sites in a Data Guard configuration. The broker monitors and controls all of the systems within a single standby database configuration.
Note the following operational requirements for maintaining a standby database:
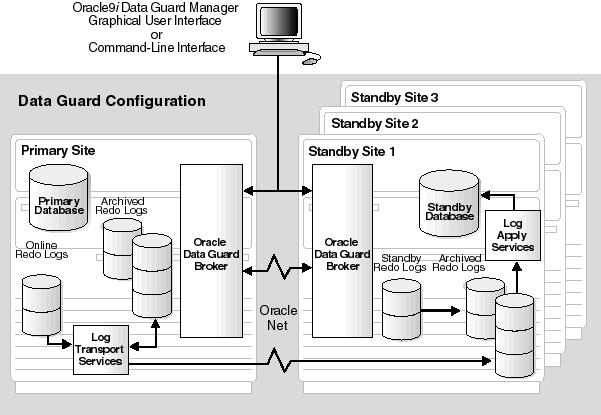
The Oracle9i Data Guard architecture consists of the following components:
A primary database is a production database. The primary database is used to create a standby database. Every standby database is associated with one and only one primary database. A single primary database can, however, support multiple standby databases.
The redo logs associated with the primary database are archived to a standby destination to be applied to the standby database.
A physical standby database is a database replica created from a backup of a primary database.
Log transport services control the automated transfer of archived redo logs from the primary database to one or more standby sites or destinations.
The primary database is connected to one or more remote standby databases through Oracle Net.
Log apply services apply the archived redo logs to the standby database.
Role management services control the changing of database roles from primary to standby and back to primary. The services include switchover and switchback, as well as database failover.
Data Guard broker is the management and monitoring component that helps you create, control, and monitor a primary database protected by one or more physical standby databases. The broker automates the previously manual process of configuration. Once it has created the Data Guard configuration, the broker monitors the activity, health, and availability for all systems in the Data Guard configuration.
Figure 1-2 shows the Data Guard architecture.
The log transport services component of Oracle9i Data Guard controls the automated archival of archived redo logs from the primary site to one or more standby sites or destinations.
You can use log transport services to set up the following:
This is a physical copy of the primary database.
This is a standalone standby control file. This type of destination allows off-site archival of redo logs.
In a Real Application Clusters environment, each instance directs its archived redo logs to a single instance of the cluster. This instance, known as the recovery instance, is typically the instance where managed recovery is performed. The recovery instance typically has a tape drive available for RMAN backup and restore support.
Log transport services provide control of different log archiving mechanisms, log archiving, error handling, reporting, and re-archiving logs after a system failure.
You set up a Data Guard configuration such that the databases are running on each site:
You create a standby database initially by copying the primary database. As redo log files are generated on the primary database, log transport services automatically archive them to each standby database. Log apply services apply the redo log files to each standby database. Log transport services and log apply services allow each standby database to be synchronized with the primary database with minimum latency.
You can customize log transport services for a variety of standby database configurations.
Log apply services maintain the standby database in either a managed recovery mode or an open read-only mode. The managed recovery mode automatically maintains and applies archived redo logs to maintain transactional synchronization with the primary database, and allows transactionally consistent read-only access to the data.
In a Data Guard environment, the log apply services component coordinates its activities with the log transport services component.
Role management services provide the means to change database roles from a primary role to a standby role and back to a primary role. Database role transition includes database switchover and database switchback, as well as database failover.
Role management services operate in conjunction with the log transport services and log apply services to provide many options for the recovery of primary database modifications if the primary database is unavailable due to an unplanned shutdown. Role management services provide database failover options that may not require reinstantiation of other standby databases.
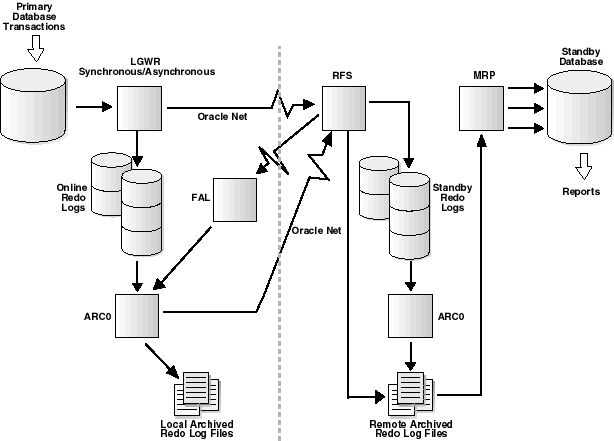
The physical standby component of Oracle Data Guard uses several processes to achieve the automation necessary for disaster recovery and high availability.
On the primary site, log transport services use the following processes:
The log writer process (LGWR) collects transaction redo and updates the online redo logs. The LGWR process can also create local archived redo logs and transmit online redo to standby databases.
The archiver process (ARCn), or a SQL session performing an archival operation, creates a copy of the online redo logs, either locally or remotely for standby databases.
The fetch archive log (FAL) client is a background Oracle database server process. The initialization parameter for the FAL client is set on the standby site. The FAL client pulls archived redo log files from the primary site and initiates and requests the transfer of archived redo log files automatically when it detects an archive gap on the standby database.
The fetch archive log (FAL) server is a background Oracle database server process. The initialization parameter for the FAL server is set on the standby site. The FAL server runs on the primary database and services the fetch archive log (FAL) requests coming from the FAL client. For example, servicing a FAL request might include queuing requests (to send archived redo log files to one or more standby databases) to an Oracle database server that runs the FAL server. Multiple FAL servers can run on the same primary database at any point in time, with a separate FAL server created for each incoming FAL request.
On the standby database, log apply services use the following processes:
The remote file server (RFS) process receives archived redo logs from the primary database.
The ARCn process archives the standby redo logs to be applied by the managed recovery process (MRP).
The MRP applies archived redo log information to the standby database.
Figure 1-3 identifies the relationships of these processes to the operations they perform and the database objects on which they operate.
You can configure standby databases in a variety of ways in a Data Guard environment, including the following:
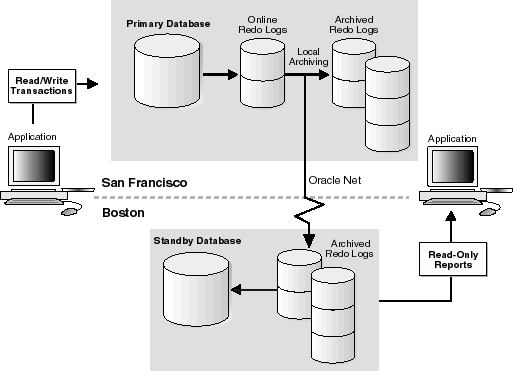
A typical two-site Data Guard environment consists of a primary database and a standby database on a remote host connected by a network. Figure 1-4 shows a typical two-site Data Guard environment.
Data divergence is the temporary state of the primary database that occurs when a standby database becomes inaccessible. While in the data divergence state, the primary database is able to commit transactions whose data modifications are not immediately available on the standby database. Data divergence also occurs when you use the LGWR or ARCn process for asynchronous standby database archival operations.
Data loss occurs when you fail over to a standby database whose corresponding primary database is in the data divergence state. To prevent primary database data divergence if network connectivity fails, use the guaranteed protection mode.
The primary database protection modes are failure policies that dictate how to manage the primary database if a standby database becomes inaccessible. There are four primary database protection modes:
Guaranteed protection mode dictates that the primary database modifications must always be available on at least one standby database; data divergence is prohibited by terminating the primary instance if it loses network connectivity to the last standby database.
Instant protection mode dictates that the primary database modifications always be available on at least one standby database. Unlike guaranteed protection mode, data divergence is not prohibited by the instant protection mode. Data divergence exists for the duration that standby database connectivity is unavailable, and can be resolved when network connectivity to the primary database is reestablished.
Rapid protection mode indicates that primary database modifications are available to the standby database as soon as possible with minimal effect on primary database performance.
Delayed protection mode indicates that primary database modifications will ultimately be available on the standby site, as long as the network is active. Both the rapid and delayed protection modes allow the primary database to diverge from all standby databases, even when network connectivity is available. The degree of data divergence is equivalent to the data contained in the unarchived primary database online redo logs.
On a standby database, no-data-loss failover is possible only when the corresponding primary database is operating in a data protection mode that provides no-data-divergence semantics, such as guaranteed and instant protection mode. This means that all primary database archived redo logs necessary for no-data-loss failover are available. However, it is possible that the archived redo logs have not yet been applied to the standby database. No-data-loss failover requires that all archived redo logs are first applied. If the archived redo logs are not applied, failover to a standby database will result in data loss relative to the primary database.
Standby database data-loss failover occurs when primary database modifications have not all been applied, or when the corresponding primary database is operating in a data protection mode that allows data divergence semantics, such as rapid and delayed protection modes. This results in standby database data loss relative to the primary database. The amount of data loss can be controlled by primary database archived log destination attributes and the availability of standby redo logs at the standby database.
No data divergence means the primary database will not acknowledge primary database modifications until they have been confirmed as being available on at least one standby database. Data is protected when primary database modifications occur while there is connectivity to the standby database. Data is unprotected when primary database modifications occur while connectivity to the standby database is not available.
The primary and standby databases are synchronized by applying archived redo logs from the primary database to the standby database. Although the goal is to keep the databases identical, the transactions applied to the standby database can sometimes lag behind the primary database.
This lag may occur either because the data has not yet reached the standby site, or it may have reached the standby site, but has not yet been applied to the standby database.
If the data needed to keep the databases synchronized is not yet available on the standby site, and you must fail over, the contents of the databases will diverge, and some of the data will be lost. You can be protected from data loss by ensuring that all the data is available on the standby site. Data divergence will be eliminated once all of the data is ultimately applied.
The amount of primary database data divergence and standby database data loss can be controlled, depending on the level of protection required by your business. By weighing your requirements for availability against user demands for response time and performance, you can determine how tightly you want to synchronize the primary and standby databases and how much data you can afford to lose.
You can set up the primary database to achieve the following levels of data protection:
Guaranteed protection mode indicates that primary database modifications are available to the standby database, up to the last committed transaction, and protected against data loss, even if either site fails. This mode has the greatest effect on primary database performance.
Stock exchanges, currency exchanges, or financial institutions are examples of businesses that require guaranteed protection. When a customer requests a stock be sold at current market price, it must be traded exactly at that price, as the price fluctuates and cannot be executed again later on.
Instant protection mode indicates that primary database modifications are available to the standby database, up to the last committed transaction, as long as both sites are active. This mode has less effect on primary database performance than guaranteed protection mode.
An example of a business that requires instant protection is a manufacturing plant; the risks of having no standby database for a period of time and data divergence are acceptable, as long as no data is lost if failover is necessary.
The loss of standby database network connectivity has the side effect of dynamically changing instant protection mode into delayed protection mode. Once network connectivity to the standby database is reestablished, instant protection mode resumes.
Rapid protection mode indicates that primary database modifications are available to the standby database as soon as possible with minimal effect on primary database performance.
In an order processing system, orders may be reentered if they were written manually, or if a customer calls and says he did not receive the item. Another example is an online auction, where it is more important to be online than to lose a few bids in the case of a failover.
Delayed protection mode indicates that primary database modifications will ultimately be available on the standby site, as long as the network is active. This mode has the least effect on primary database performance.
Table 1-1 summarizes the available data protection modes and their implications for primary database data divergence and standby database switchover and failover.
By default, in managed recovery mode, the standby database automatically applies archived redo logs when they arrive from the primary database. But in some cases, you may want to delay applying the redo logs. A time lag can protect against the application of corrupted or erroneous data from the primary database to the standby database.
|
See Also:
Section 3.4.2.8 and Section 6.11 for detailed information on creating a standby database with a time lag |
You can use a standby database in several different ways, depending on the method for:
For example, in a Data Guard environment, log transport services automatically archive redo logs to the standby database site so long as the standby instance is started.
If the standby database is in managed recovery mode, the log apply services automatically apply logs received from the primary database. At any time you can open the standby database in read-only mode for reporting purposes.
You can operate a standby database in one of the following modes:
For maximum protection against data loss or corruption, maintain the standby database in managed recovery mode. In this mode, the primary database archives logs to the standby site, and the standby database automatically applies these logs.
To use the standby database for reporting purposes, open it in read-only mode. Log apply services cannot apply archived redo logs to the standby database when it is in this mode, but you can still execute queries on the database. The primary database continues to archive to the standby site so long as the standby instance is mounted.
Although the standby database cannot be in more than one mode at the same time, you can change between the modes. For example, you can run in managed recovery mode and then open in read-only mode.
In most implementations of a Data Guard environment, you need to change between managed recovery mode and read-only mode at various times to either:
A database can be in one of two mutually exclusive roles: primary or standby. You can change these roles dynamically as a planned transition or as the result of a failure.
For example, a primary database can change to the standby role, so that its corresponding standby database can change to the primary role. This planned transition occurs without having to reinstantiate either database. This is known as a switchover operation.
In a failure of the primary database, such as a system or software failure, you may need to change the corresponding standby database to the primary role. This unplanned transition may result in the loss of application data. The potential loss of data is dependent on user-defined parameters of the primary database. This type of transition requires you to instantiate a new standby database from the newly activated primary database. This is known as a failover operation.
The active role of a database is more than conceptual; you must also consider physical aspects of the role. For example, a database in the primary role uses a current control file, while a database in the standby role uses a standby control file. Using different physical files, depending on which database role is active, requires careful coordination of the initialization parameter file.
Failover is the operation of taking the primary database offline on one site and bringing one of the standby databases online. This operation occurs due to a system or software failure.
One of the consequences of failover is that the original primary database must be reinstantiated.
With Oracle9i, it is possible to switch over to a standby database without requiring a resetlogs operation. Switchover is the process of intentionally taking database resources offline on one system and bringing them back online on another system. For example, you might use switchover to perform a rolling upgrade (you switch over all of the database resources to one system as you sequentially upgrade hardware on the other system).
The main difference between a switchover process and a failover process is that switchover does not require reinstantiation of the database. This allows the primary database to resume its role as the standby database almost immediately. As a result, scheduled maintenance can be performed more frequently because it is less risky.
For many configurations, you can lessen the frequency of failures by a regular program of preventive maintenance tasks. The switchover capability allows you to schedule time for hardware and software chores such as the following, without interrupting processing:
Figure 1-5 depicts a failover operation from a primary database in San Francisco to a standby database in managed recovery mode in Boston.
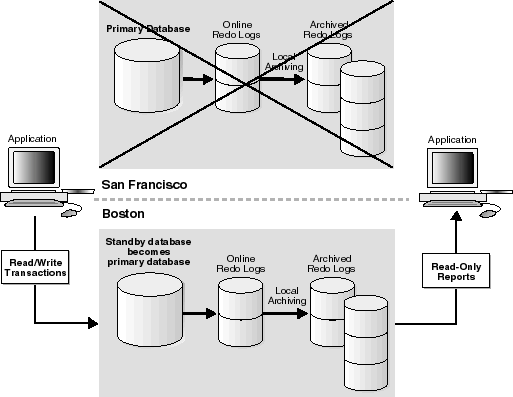
After you fail over to the standby database, it ceases to be a standby database and becomes a fully functional primary database. At this point, you can open the database in read/write or read-only mode and make changes or issue queries as usual.
You can switch a database role from primary over to standby, and from standby back to primary without reinstantiating any of the databases.
Figure 1-6 depicts the environment after switchover.
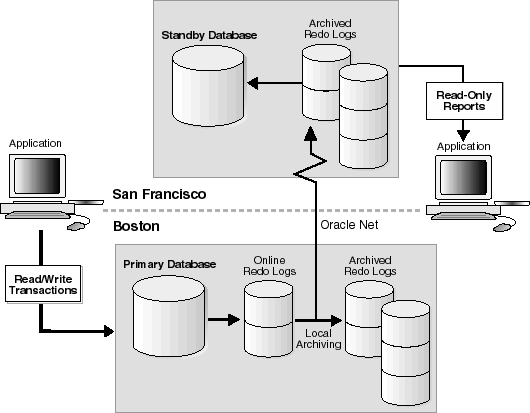
|
See Also:
Section 5.3 for information on switching database roles and Section 6.6 for detailed steps on how to perform a switchover operation |
Once you have performed a database switchover operation, you can switch back to your original Data Guard configuration. A database switchback is performed using the switchover operation, but in the reverse direction. Figure 1-7 depicts the original environment after the switchback operation.
You can use the following to configure, implement, and manage a standby database:
Several SQL statements use a STANDBY keyword to specify operations on a standby database. Other SQL statements do not include standby-specific syntax, but are useful for performing operations on a standby database. Table 9-1 describes the relevant statements.
Several initialization parameters are used to define the Data Guard environment. Table 7-1 describes relevant initialization parameters.
The Oracle9i Data Guard Manager graphical user interface automates many of the tasks involved in configuring and monitoring a Data Guard environment.
The Data Guard command-line interface is an alternative to using the Oracle Data Guard Manager GUI. The command-line interface is useful if you want to manage a Data Guard configuration from batch programs or scripts.
You can use Recovery Manager (RMAN) to create and back up a standby database.
Once you have a primary database, you can create a standby database by using one of the following methods:
Oracle9i Data Guard Broker and the Oracle9i Data Guard Manager online help for information on the Data Guard Manager GUI
See Also:
Oracle9i Recovery Manager User's Guide for the procedures to follow when you use RMAN to create a standby database
See Also:
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|