Release 9.0.1
Part Number A90121-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle Text Reference Release 9.0.1 Part Number A90121-01 |
|
![]()
![]()
![]()
Indexing, 5 of 11
Use the lexer preference to specify the language of the text to be indexed. To create a lexer preference, you must use one of the following lexer types:
Use the BASIC_LEXER type to identify tokens for creating Text indexes for English and all other supported whitespace delimited languages.
The BASIC_LEXER also enables base-letter conversion, composite word indexing, case-sensitive indexing and alternate spelling for whitespace delimited languages that have extended character sets.
In English and French, you can use the BASIC_LEXER to enable theme indexing.
BASIC_LEXER supports any database character set.
BASIC_LEXER has the following attributes:
Specify the characters that indicate a word continues on the next line and should be indexed as a single token. The most common continuation characters are hyphen '-' and backslash '\'.
Specify a single character that, when it appears in a string of digits, indicates that the digits are groupings within a larger single unit.
For example, comma ',' might be defined as a numgroup character because it often indicates a grouping of thousands when it appears in a string of digits.
Specify the characters that, when they appear in a string of digits, cause Oracle to index the string of digits as a single unit or word.
For example, period '.' can be defined as numjoin characters because it often serves as decimal points when it appears in a string of digits.
Specify the non alphanumeric characters that, when they appear anywhere in a word (beginning, middle, or end), are processed as alphanumeric and included with the token in the Text index. This includes printjoins that occur consecutively.
For example, if the hyphen '-' and underscore '_' characters are defined as printjoins, terms such as pseudo-intellectual and _file_ are stored in the Text index as pseudo-intellectual and _file_.
Specify the non-alphanumeric characters that, when they appear at the end of a word, indicate the end of a sentence. The defaults are period '.', question mark '?', and exclamation point '!'.
Characters that are defined as punctuations are removed from a token before text indexing. However, if a punctuations character is also defined as a printjoins character, the character is removed only when it is the last character in the token and it is immediately preceded by the same character.
For example, if the period (.) is defined as both a printjoins and a punctuations character, the following transformations take place during indexing and querying as well:
| Token | Indexed Token |
|---|---|
|
.doc |
.doc |
|
dog.doc |
dog.doc |
|
dog..doc |
dog..doc |
|
dog. |
dog |
|
dog... |
dog.. |
In addition, BASIC_LEXER uses punctuations characters in conjunction with newline and whitespace characters to determine sentence and paragraph deliminters for sentence/paragraph searching.
Specify the non-alphanumeric characters that, when they appear within a word, identify the word as a single token; however, the characters are not stored with the token in the Text index.
For example, if the hyphen character '-' is defined as a skipjoins, the word pseudo-intellectual is stored in the Text index as pseudointellectual.
For startjoins, specify the characters that when encountered as the first character in a token explicitly identify the start of the token. The character, as well as any other startjoins characters that immediately follow it, is included in the Text index entry for the token. In addition, the first startjoins character in a string of startjoins characters implicitly ends the previous token.
For endjoins, specify the characters that when encountered as the last character in a token explicitly identify the end of the token. The character, as well as any other startjoins characters that immediately follow it, is included in the Text index entry for the token.
The following rules apply to both startjoins and endjoins:
Specify the characters that are treated as blank spaces between tokens. BASIC_LEXER uses whitespace characters in conjunction with punctuations and newline characters to identify character strings that serve as sentence delimiters for sentence and paragraph searching.
The predefined default values for whitespace are 'space' and 'tab'. These values cannot be changed. Specifying characters as whitespace characters adds to these defaults.
Specify the characters that indicate the end of a line of text. BASIC_LEXER uses newline characters in conjunction with punctuations and whitespace characters to identify character strings that serve as paragraph delimiters for sentence and paragraph searching.
The only valid values for newline are NEWLINE and CARRIAGE_RETURN (for carriage returns). The default is NEWLINE.
Specify whether characters that have diacritical marks (umlauts, cedillas, acute accents, and so on) are converted to their base form before being stored in the Text index. The default is NO (base-letter conversion disabled).
|
Note: In German, if alternate spelling is set with base letter conversion, Oracle reduces word queries to their alternate spelling forms. |
Specify whether the lexer leaves the tokens exactly as they appear in the text or converts the tokens to all uppercase. The default is NO (tokens are converted to all uppercase).
Specify whether composite word indexing is disabled or enabled for either GERMAN or DUTCH text. The default is DEFAULT (composite word indexing disabled).
In your language, you can create a user dictionary to customize how words are decomposed.
You create the user dictionary in the $ORACLE_HOME/ctx/data/<language id> directory. The user dictionary must have the suffix .dct.
For example, the supplied user dictionary file for German is:
$ORACLE_HOME/ctx/data/del/drde.dct
The format for the user dictionary is as follows:
input term <tab> output term
The individual parts of the decomposed word must be separated by the # character. The following example entries are for the German word Hauptbahnhof:
Hauptbahnhof<tab>Haupt#Bahnhof Hauptbahnhofes<tab>Haupt#Bahnhof Hauptbahnhof<tab>Haupt#Bahnhof Hauptbahnhoef<tab>Haupt#Bahnhof
Specify YES to index theme information in English or French. This makes ABOUT queries more precise. The index_themes and index_text attributes cannot both be NO.
If you use the BASIC_LEXER and specify no value for index_themes, this attribute defaults to NO.
Specify YES to prove themes. Theme proving attempts to find related themes in a document. When no related themes are found, parent themes are eliminated from the document.
While theme proving is acceptable for large documents, short text descriptions with a few words rarely prove parent themes, resulting in poor recall performance with ABOUT queries.
Theme proving results in higher precision and less recall (less rows returned) for ABOUT queries. For higher recall in ABOUT queries and possibly less precision, you can disable theme proving. Default is YES.
The prove_themes attribute is supported for CONTEXT and CTXRULE indexes.
Specify which knowledge base to use for theme generation when index_themes is set to YES. When index_themes is NO, setting this parameter has no effect on anything.
You can specify any NLS supported language or AUTO. You must have a knowledge base for the language you specify. This release provides a knowledge base in only English and French. In other languages, you can create your own knowledge base.
The default is AUTO, which instructs the system to set this parameter according to the language of the environment.
Specify YES to index word information. The index_themes and index_text attributes cannot both be NO.
The default is NO.
Specify either GERMAN, DANISH, or SWEDISH to enable the alternate spelling in one of these languages. Enabling alternate spelling allows you to query a word in any of its alternate forms.
By default, alternate spelling is enabled in all three languages. You can specify NONE for no alternate spelling.
|
Note: In German, if alternate spelling is set with base letter conversion, Oracle reduces word queries to their alternate spelling forms. |
|
See Also:
For more information about the alternate spelling conventions Oracle uses, see Appendix E, "Alternate Spelling Conventions". |
The following example sets printjoin characters and disables theme indexing with the BASIC_LEXER:
begin ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); ctx_ddl.set_attribute ( 'mylex', 'index_themes', 'NO'); ctx_ddl.set_attribute ( 'mylex', 'index_text', 'YES'); end;
To create the index with no theme indexing and with printjoins characters set as above, issue the following statement:
create index myindex on mytable ( docs ) indextype is ctxsys.context parameters ( 'LEXER mylex' );
Use MULTI_LEXER to index text columns that contain documents of different languages. For example, you can use this lexer to index a text column that stores English, German, and Japanese documents.
This lexer has no attributes.
You must have a language column in your base table. To index multi-language tables, you specify the language column when you create the index.
You create a multi-lexer preference with the CTX_DDL.CREATE_PREFERENCE. You add language-specific lexers to the multi-lexer preference with the CTX_DDL.ADD_SUB_LEXER procedure.
During indexing, the MULTI_LEXER examines each row's language column value and switches in the language-specific lexer to process the document.
When you use the MULTI-LEXER, you can also use a multi-language stoplist for indexing.
Create the multi-language table with a primary key, a text column, and a language column as follows:
create table globaldoc ( doc_id number primary key, lang varchar2(3), text clob );
Assume that the table holds mostly English documents, with the occasional German or Japanese document. To handle the three languages, you must create three sub-lexers, one for English, one for German, and one for Japanese:
ctx_ddl.create_preference('english_lexer','basic_lexer'); ctx_ddl.set_attribute('english_lexer','index_themes','yes'); ctx_ddl.set_attribute('english_lexer','theme_language','english'); ctx_ddl.create_preference('german_lexer','basic_lexer'); ctx_ddl.set_attribute('german_lexer','composite','german'); ctx_ddl.set_attribute('german_lexer','mixed_case','yes'); ctx_ddl.set_attribute('german_lexer','alternate_spelling','german'); ctx_ddl.create_preference('japanese_lexer','japanese_vgram_lexer');
Create the multi-lexer preference:
ctx_ddl.create_preference('global_lexer', 'multi_lexer');
Since the stored documents are mostly English, make the English lexer the default using CTX_DDL.ADD_SUB_LEXER:
ctx_ddl.add_sub_lexer('global_lexer','default','english_lexer');
Now add the German and Japanese lexers in their respective languages with CTX_DDL.ADD_SUB_LEXER procedure. Also assume that the language column is expressed in the standard ISO 639-2 language codes, so add those as alternate values.
ctx_ddl.add_sub_lexer('global_lexer','german','german_lexer','ger'); ctx_ddl.add_sub_lexer('global_lexer','japanese','japanese_lexer','jpn');
Now create the index globalx, specifying the multi-lexer preference and the language column in the parameter clause as follows:
create index globalx on globaldoc(text) indextype is ctxsys.context parameters ('lexer global_lexer language column lang');
At query time, the multi-lexer examines the language setting and uses the sub-lexer preference for that language to parse the query. If the language is not set, then the default lexer is used.
Otherwise, the query is parsed and run as usual. The index contains tokens from multiple languages, so such a query can return documents in several languages. To limit your query to a given language, use a structured clause on the language column.
The CHINESE_VGRAM_LEXER type identifies tokens in Chinese text for creating Text indexes. It has no attributes.
You can use this lexer if your database character set is one of the following:
The JAPANESE_VGRAM_LEXER type identifies tokens in Japanese for creating Text indexes. It has no attributes.
You can use this lexer if your database character set is one of the following:
The JAPANESE_LEXER type identifies tokens in Japanese for creating Text indexes. It has no attributes.
This lexer offers the following benefits over the JAPANESE_VGRAM_LEXER:
Because the JAPANESE_LEXER uses a new algorithm to generate tokens, indexing time is longer than with JAPANESE_VGRAM_LEXER.
The JAPANESE_LEXER supports the following character sets:
When you specify JAPANESE_LEXER for creating text index, the JAPANESE_LEXER resolves a sentence into words.
For example, the following compound word (natural language institute)

is indexed as three tokens:

In order to resolve a sentence into words, the internal dictionary is referenced. When a word cannot be found in the internal dictionary, Oracle uses the JAPANESE_VGRAM_LEXER to resolve it.
The KOREAN_LEXER type identifies tokens in Korean text for creating Text indexes.
|
Note: This lexer is supported for backward compatibility with older versions of Oracle Text that supported only this Korean lexer. If you are building a new application, Oracle recommends that you use the KOREAN_MORPH_LEXER. |
You can use this lexer if your database character set is one of the following:
When you use the KOREAN_LEXER, you can specify the following boolean attributes:
Sentence and paragraph sections are not supported with the Korean lexer.
The KOREAN_MORPH_LEXER type identifies tokens in Korean text for creating Oracle Text indexes. The KOREAN_MORPH_LEXER lexer offers the following benefits over KOREAN_LEXER:
The KOREAN_MORPH_LEXER uses four dictionaries:
The grammar, user-defined, and stopword dictionaries are text format KSC 5601. You can modify these dictionaries using the defined rules. The system dictionary must not be modified.
You can add unregistered words to the user-defined dictionary file. The rules for specifying new words are in the file.
You can use KOREAN_MORPH_LEXER if your database character set is one of the following:
When you use the KOREAN_MORPH_LEXER, you can specify the following attributes:
Sentence and paragraph sections are not supported with the Korean lexer.
You can use the composite attribute to control how composite nouns are indexed.
When you specify NGRAM for the composite attribute, composite nouns are indexed with all possible component tokens. For example, the following composite noun (information processing institute):
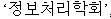
is indexed as six tokens:
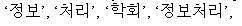
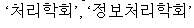
You can specify NGRAM indexing as follows:
begin ctx_ddl.create_preference('korean_lexer','KOREAN_MORPH_LEXER'); ctx_ddl.set_attribute('korean_lexer','COMPOSITE','NGRAM'); end
To create the index:
create index koreanx on korean(text) indextype is ctxsys.context parameters ('lexer korean_lexer');
When you specify COMPONENT_WORD for the composite attribute, composite nouns and their components are indexed. For example, the following composite noun (information processing institute):
is indexed as four tokens:
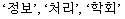
You can specify COMPONENT_WORD indexing as follows:
begin ctx_ddl.create_preference('korean_lexer','KOREAN_MORPH_LEXER'); ctx_ddl.set_attribute('korean_lexer','COMPOSITE','COMPONENT_WORD'); end
To create the index:
create index koreanx on korean(text) indextype is ctxsys.context parameters ('lexer korean_lexer');
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|