Release 2 (9.0.3)
Part Number B10064-01
Home |
Solution Area |
Contents |
Index |
| Oracle9iAS TopLink Foundation Library Guide Release 2 (9.0.3) Part Number B10064-01 |
|
A database session represents an application's dialog with a relational database. This chapter is a comprehensive reference for database sessions in TopLink. It describes the fundamental concepts required to connect to the database and to perform queries as well as optional and advanced session and query properties. It discusses
You should have a good command of the topics in this chapter and the Descriptors and Mappings chapters before using TopLink in an application.
A complete listing of the TopLink application programming interface (API) is provided in HTML format. It is located in the Java Docs directory where TopLink was installed. Refer to this document for more information on the complete TopLink API.
A session represents the connection between an application and the relational database that stores its persistent objects. TopLink provides several different session objects that all implement the same Session interface. The simplest session is the DatabaseSession, which can be used for single user/single database applications. All of the following examples use DatabaseSession.
TopLink also provides a ServerSession, ClientSession, RemoteSession, UnitOfWork and SessionBroker. For more information on these sessions, refer to Chapter 2, "Developing Enterprise Applications".
An application must create an instance of the DatabaseSession class. A DatabaseSession class stores the following information:
Project and DatabaseLogin, which stores database login and configuration information
DatabaseAccessor, which wraps the JDBC connection and handles database access
The session is created from an instance of Project, which contains the database connection parameters.
A typical application then reads from the database using the TopLink query framework, and writes to the database using a unit of work. A well-designed application then logs out of the database when it is finished accessing the persistent objects in the database.
Instances of DatabaseSession must be created from a Project instance. Initialize this project with all of the appropriate database login parameters, such as the JDBC driver and the database URL. Refer to "Understanding Database sessions" for more information on reading the TopLink Mapping Workbench project file.
If the application uses descriptors created with the TopLink Mapping Workbench tool, the project adds its descriptors automatically. If multiple projects are used, the additional projects must use the addDescriptors(Project) method to register their descriptors with the session. Refer to "Understanding Database sessions" for more information on reading the TopLink Mapping Workbench project file.
If the application does not use a TopLink Mapping Workbench project, register a Vector of descriptors using the addDescriptors(Vector) method.
Descriptors can be registered after the session logs in, but they should be independent of any descriptors already registered. This allows self-contained sub-systems to be loaded after connecting.
It is also possible to re-register descriptors that have already been loaded. If this is done, ensure that all related descriptors are re-registered at the same time. Changes to one descriptor may affect the initialization of other descriptors.
After the descriptors have been registered, the DatabaseSession can connect to the database using the login() method. If the login parameters in the DatabaseLogin class are incorrect, or if the connection cannot be established, a DatabaseException is thrown.
After a connection is established, the application is free to use the session to access the database. The isConnected() method returns true if the session is connected to the database.
The application can interact with the database using the session's querying methods or by executing query objects. The interactions between the application and the database are collectively called the query framework. Refer to "Using the query framework" for more information on querying.
Database sessions have an identity map, which maintains object identity and acts as a cache. When an object is read from the database it is instantiated and stored in the identity map. If the application queries for the same object, TopLink returns the object in the cache rather than reading the object from the database again.
The initializeIdentityMaps() method can be called to flush all objects from the cache.
The identity map can be customized for performance reasons. Refer to the Oracle9iAS TopLink Mapping Workbench Reference Guide for more information on using the identity map and caching.
The session can log out using the logout() method. Since logging in to the database can be time consuming, log out only when all database interactions are complete.
When the logout() method is called, the session is disconnected from the relational database, and its identity maps are flushed. Applications that log out do not have to register the descriptors again when they log back in to the database.
TopLink accesses the database by generating SQL strings. TopLink handles all SQL generation internally, and applications that use the session methods or query objects do not have to deal with SQL. For debugging purposes, programmers who are familiar with SQL may wish to keep a record of the SQL used to access the database.
The DatabaseSession class provides methods to allow the SQL generated to be logged to a writer. SQL and message logging is disabled by default, but can be enabled using the logMessages() method on the session. The default writer is a stream writer to System.out, but the writer can be changed using the setLog() method of the session.
The session can log:
printIdentityMaps() and printRegisteredObjects() methods.
and any other output sent to the system log.
TopLink provides a higher level of logging called the Profiler. Instead of logging raw SQL statements, the profiler can be enabled to log a summary of each query that is executed. This summary includes a performance breakdown of the query to easily identify performance bottlenecks and has been extended to provide more granularity with regards to the query information provided. A report that summarizes the querying performance for an entire session can also be logged from the profiler.
TopLink also provides a GUI browser for profiles that can be accessed through the session console.
Refer to Appendix B, "TopLink Development Tools" for more information on the profiler and session console.
When a session is connected or descriptors are added to a session after it is connected, TopLink initializes and validates the descriptor's information. The integrity checker allows for the validation process to be customized.
By default, the integrity checker reports all errors discovered with the descriptors during initialization. The integrity checker can be configured to:
session.getIntegrityChecker().checkDatabase(); session.getIntegrityChecker().catchExceptions(); session.getIntegrityChecker().dontCheckInstantiationPolicy(); session.login();
Exception handlers can be used on the session to handle database exceptions. An implementor of the ExceptionHandler interface can be registered with the session. When a database exception occurs during the execution of a query, the exception is passed to the exception handler instead of being thrown. The exception handler can then decide to handle the exception, retry the query, or throw an unchecked exception. Exception handlers are typically used to handle connection timeouts or database failures. See Oracle9iAS TopLink Troubleshooting for more information on exceptions.
session.setExceptionHandler(newExceptionHandler(){ public Object handleException(RuntimeException exception) { if ((exception instanceof DatabaseException) && (exception.getMessage().equals("connection reset by peer."))) { DatabaseException dbex = (DatabaseException) exception; dbex.getAccessor().reestablishConnection (dbex.getSession()); return dbex.getSession().executeQuery(dbex.getQuery()); } return null; } });
For detailed information on Java Transaction Service (JTS) and external transaction controllers, see Java Transaction Service (JTS) .
import oracle.toplink.tools.workbench.*; import oracle.toplink.sessions.* // Create the project object. Project project = ProjectXMLReader.read("C:\TopLink\example.xml"); DatabaseLogin loginInfo = project.getLogin(); loginInfo.setUserName("scott"); loginInfo.setPassword("tiger"); //Create a new instance of the session and login. DatabaseSession session = project.createDatabaseSession(); try { session.login(); } catch (DatabaseException exception) { throw new RuntimeException("Database error occurred at login: " + exception.getMessage()); System.out.println("Login failed"); } // Do any database interaction using the query framework, transactions or units of work. ... // Log out when database interaction is over. session.logout(); Creating and using a session from coded descriptors import oracle.toplink.sessions.*; //Create the project object. DatabaseLogin loginInfo = new DatabaseLogin(); loginInfo.useJDBCODBCBridge(); loginInfo.useSQLServer(); loginInfo.setDataSourceName("MS SQL Server"); loginInfo.setUserName("scott"); loginInfo.setPassword("tiger"); Project project = new Project(loginInfo); //Create a new instance of the session, register the descriptors, and login. DatabaseSession session = project.createDatabaseSession(); session.addDescriptors(this.buildAllDescriptors()); try { session.login(); } catch (DatabaseException exception) { throw new RuntimeException("Database error occurred at login: " + exeption.getMessage()); System.out.println("Login failed"); } //Do any database interaction using the query framework, transactions or units of work. ... //Log out when database interaction is over. session.logout();
Table 1-1 summarizes the most common public methods for the DatabaseSession class:
For a complete description of all available methods for the DatabaseSession class, see the TopLink JavaDocs.
TopLink uses a class called the ConversionManager to convert database types to Java types. This class, found in the oracle.toplink.internal.helper package, is the central location for type conversion, and as such can provide the expert developer with a mechanism for using custom types within TopLink.
To use custom types, create a subclass of the ConversionManager. Do one of the following:
public Object convertObject(Object sourceObject, Class javaClass) method to call the conversion method that is written in the subclass for the custom type.
The conversion method, protected ClassX convertObjectToClassX(Object sourceObject) throws ConversionException must be implemented to convert incoming object to the required class.
Once the class has been written, assign it to TopLink. There are two common ways to accomplish this:
(getSession().getPlatform().setConversionManager(ConversionManager)) platform.
setDefaultManager(ConversionManager). By setting this before any session are logged in, all TopLink sessions created in a particular VM will use the custom Conversion Manager. See the ConversionManager class JavaDocs for examples.
The Conversion Manager loads the classes included in a mapping project, as well as classes throughout the library. TopLink provides storage of a class loader within the Conversion Manager to facilitate this. The class loader in the Conversion Manager is set to the System class loader by default.
There are cases, particularly when TopLink is deployed within an application server, when other class loaders are used for the deployed classes. In these cases, a ClassNotFound exceptions may be thrown. To resolve this problem, do one of the following:
public void setShouldUseClassLoaderFromCurrentThread
(boolean useCurrentThread) on the default Conversion Manager before logging in any sessions. This resolves the problem for most application servers, and ensures that TopLink uses the correct ClassLoader.
getSession() call, which sets the required class loader on the Conversion Manager.
public static void setDefaultLoader
(ClassLoader classLoader) on the default Conversion Manager before any sessions are logged in, passing in the ClassLoader that contains the deployed classes.
Java applications that access a database log in to the database through a JDBC driver. To login successfully, the database typically requires a valid username and password. In a TopLink application, this login information is stored in the DatabaseLogin class. All sessions must have a valid DatabaseLogin instance before logging in to the database.
This section describes the basic login properties and also the various advanced configuration options available on DatabaseLogin. The advanced options are normally not required unless the JDBC driver being used is not fully JDBC compliant.
The Project class you create must include a login object to access the database used by the project. The most basic login mechanism involves creating an instance of DatabaseLogin through its default constructor, as follows:
Databaselogin login = new Databaselogin ...
The Project class provides the getLogin() instance method to return the project's login. This method returns an instance of DatabaseLogin. The DatabaseLogin object can then be used directly or be provided with more information before logging in.
However, if you create the project in the TopLink Mapping Workbench, the login object is created automatically for you. In this case, you should only access the login from your Project instance. This ensures that login information set in TopLink Mapping Workbench, such as sequencing information, is used by the session, and also prevents you from inadvertently over-writing the login information already included in the project
The DatabaseLogin method assumes that the database being accessed is a generic JDBC-compliant database. TopLink also provides custom support for most database platforms. To take advantage of this support, you can call the useXDriver() method for your specific platform along with the getLogin() instance method:
project.getLogin().useOracle();
The DatabaseLogin class has several helper methods, such as useJConnectDriver(), that set the driver class, driver URL prefix, and database information for common drivers. If one of these helper methods is used, only the database instance-specific part of the JDBC driver URL needs to be specified, using the setDatabaseURL() method. These helper methods also set any additional settings required for that driver, such as binding byte arrays or using native SQL. They are recommended for specifying your driver information. For example:
project.getLogin().useOracleThinJDBCDriver(); project.getLogin().setDatabaseURL("dbserver:1521:orcl");
By default, new DatabaseLogin objects use the Sun JDBC-ODBC bridge. However, if you require a different driver, you can specify a different connection mechanism.
If you are using the Sun JDBC-ODBC bridge, only the ODBC datasource name is required. Call setDataSourceName() to specify it. A list of your installed data sources can be found from the "ODBC Administrator" in your Windows control panel. For example:
project.getLogin().useJDBCODBCBridge();project.getLogin().useOracle(); project.getLogin().setDataSourceName("Oracle");
If you require a driver other than the Sun JDBC-ODBC bridge, you can specify a different connection mechanism by calling the setDriverClass() and setConnectionString() methods to indicate which driver to use.
For example:
project.getLogin().setDriverClass(oracle.jdbc.driver.OracleDriver.class); project.getLogin().setConnectionString("jdbc:oracle:thin:@dbserver:1521:orcl");
If the database requires user and password information, the application must call setUserName() and setPassword(). This must be done after the driver has been specified. This is normally required when using the login from your TopLink Mapping Workbench project, as the Mapping Workbench does not store the password by default.
project.getLogin().setUserName("userid"); project.getLogin().setPassword("password");
Properties such as the database name and the server name may be specified through the setServerName() and setDatabaseName() methods. Most JDBC drivers do not require the database and server name properties because they are part of the database URL. Specifying them can cause connection failures, so avoid setting them unless using JDBC-ODBC. Only some JDBC-ODBC bridges require these properties to be set. They are usually set from the ODBC Data Source Administrator, so they are normally not required.
Some JDBC drivers require additional properties that are not mentioned here. The additional properties can be specified through the setProperty() method. Also, some drivers fail to connect if properties are specified when not required. If a connection always fails, check to make sure the properties are correct.
The setTableQualifier() method can be used to prepend a given string to all tables accessed by the session. This is useful for setting the name of the table creator, or owner, for databases such as Oracle and DB2. This should be used when a common user such as DBA defined the entire schema. If some tables have a different creator, the table name must be fully qualified with the creator in the descriptor.
By default, TopLink accesses the database using JDBC SQL. The JDBC syntax uses "{" escape clauses to print dates and binary data. If your driver does not support this syntax you will get an error on execution of SQL that contains dates.
To use native SQL for database interaction, call the useNativeSQL() method. This is required only if your JDBC driver does not support the JDBC standard SQL syntax, such as Sybase JConnect 2.x. Because native SQL is database-specific, ensure that you have set your database platform to the correct database.
project.getLogin().useSybase(); project.getLogin().useNativeSQL();
You can specify sequencing information in the DatabaseLogin by using the following methods:
setSequenceCounterFieldName()
setSequenceNameFieldName()
setSequencePreallocationSize()
setSequenceTableName()
useNativeSequencing()
If your application uses native sequencing rather than a sequence table, call the useNativeSequencing() method. TopLink supports native sequencing on Oracle, Sybase, SQL Server and Informix. The database platform must have been specified to use native sequencing.
project.getLogin().useOracle(); project.getLogin().useNativeSequencing(); project.getLogin().setSequencePreallocationSize(1);
Refer to the Oracle9iAS TopLink Mapping Workbench Reference Guide for more information on sequence numbers.
By default, TopLink prints data inlined into the SQL it generates and does not use parameterized SQL. The difference between parameter binding and printing data is that some drivers have limits on the size of data that can be printed. Also, parameterized SQL allows for the prepared statement to be cached to improve performance. Many JDBC drivers do not fully support parameter binding or have size or type limits. Refer to your database documentation for more information on binding and binding size limits.
TopLink can be configured to use parameter binding for large binary data with the useByteArrayBinding() method. Some JDBC drivers function better if large binary data is read through streams. For this purpose, TopLink can also be configured to use streams for binding by calling the useStreamsForBinding() method. Binding can also be configured for large string data through the useStringBinding() method.
TopLink supports full parameterized SQL and prepared statement caching, both of which are configured through the bindAllParameters(), cacheAllStatements() and setStatementCacheSize()methods. Refer to Chapter 6, "Performance Optimization" for more information on parameterized SQL.
project.getLogin().useByteArrayBinding(); project.getLogin().useStreamsForBinding(); project.getLogin().useStringBinding(50); project.getLogin().bindAllParameters(); project.getLogin().cacheAllStatements(); project.getLogin().setStatementCacheSize(50);
Batch writing can be enabled on the login with the useBatchWriting() method. Batch writing allows for groups of insert/update/delete statements to be sent to the database in a single batch, instead of one at a time. This can be a huge performance benefit. TopLink supports batch writing for selected databases and for JDBC 2.0 batch compliant drivers in JDK 1.2.
Some JDBC 2.0 drivers do not support batch writing. TopLink can be configured to support batch writing directly with the dontUseJDBCBatchWriting() method.
For more information, see Chapter 6, "Performance Optimization".
project.getLogin().useBatchWriting();project.getLogin().dontUseJDBCBatchWriting();
By default, TopLink optimizes data access from JDBC, through avoiding double conversion by accessing the data from JDBC in the format that the application requires. For example, longs are retrieved directly from JDBC instead of having the driver return a BigDecimal that TopLink would then have to convert into a long.
Dates are also accessed as strings and converted directly to the date or Calendar type used by the application. Some JDBC drivers cannot convert the data correctly themselves so this optimization may have to be disabled. For example, some of the WebLogic JDBC drivers cannot convert dates to strings in the correct format.
Oracle's JDBC drivers were found to lose precision on floats in certain cases.
By default, concurrency is optimized and the cache is not locked more than required during reads or writes. The default settings allow for virtual concurrent reading and writing and should never cause any problems. If the application uses no form of locking then the last unit of work to merge changes wins. This feature allows for the isolation level of changes to the cache to be configured for severe situations only. It is not recommended that the default isolation level be changed.
Isolation settings are
ConcurrentReadWrite: default
SynchronizedWrite: allow only a single unit of work to merge into the cache at once
SynchronizedReadOnWrite: do not allow reading or other unit of work merge while a unit of work is merging
Sybase JConnect 2.x had problems with the JDBC auto-commit being used for transactions. This could prevent the execution of some stored procedures.
The handleTransactionsManuallyForSybaseJConnect() method gives a workaround to this problem. This problem may have been fixed in more recent versions of Sybase JConnect.
TopLink supports integration with an application server's JTS driver and connection pooling. This support is enabled on the login. For more information, see Chapter 2, "Developing Enterprise Applications".
By default, TopLink uses the JDBC 1.0 standard technique for loading a JDBC driver and connecting to a database. That is, TopLink first loads and initializes the class by calling java.lang.Class.forName(), then obtains a connection to the database by calling java.sql.DriverManager.getConnection(). Some drivers do not support this technique for connecting to a database. As a result, TopLink can be configured in several ways to support these drivers.
Some drivers (for example, Castanet drivers) do not support using the java.sql.DriverManager to connect to a database. TopLink instantiates these drivers directly, using the driver's default constructor, and obtains a connection from the new instance. To configure TopLink to use this direct instantiation technique, use the useDirectDriverConnect() method.
project.getLogin().useDirectDriverConnect("com.foo.barDriver", "jdbc:foo:", "server");
The JDBC 2.0 specification recommends using a Java Naming and Directory Interface (JNDI) naming service to acquire a connection to a database. TopLink supports acquiring a database connection in this fashion. To take advantage of this feature, construct and configure an instance of oracle.toplink.jndi.JNDIConnector and pass it to the project login object using the setConnector() method.
import oracle.toplink.sessions.*; import oracle.toplink.jndi.*;javax.naming.Context context = new javax.naming.InitialContext(); Connector connector = new JNDIConnector(context, "customerDB"); project.getLogin().setConnector(connector);
TopLink also allows you to develop your own class that TopLink can use to obtain a connection to a database. The class must implement the oracle.toplink.sessions.Connector interface. This requires the class to implement three methods:
java.lang.Object clone() -- The object must be "cloneable."
java.sql.Connection connect(java.util.Properties properties) -- This method receives a dictionary of properties (including the user name and password) and must return a valid connection to the appropriate database.
void toString(PrintWriter writer) -- This method is used to print out any helpful information on the TopLink log.
After this class is implemented, it can be instantiated and passed to the project login object, using the setConnector() method.
import oracle.toplink.sessions.*; Connector connector = new MyConnector(); project.getLogin().setConnector(connector);
The following examples illustrate database login.
import oracle.toplink.tools.workbench.*; import oracle.toplink.sessions.*; Project project = XMLProjectReader.read("C:\TopLink\example.xml"); project.getLogin().setUserName("userid"); project.getLogin().setPassword("password"); DatabaseSession session = project.createDatabaseSession();session.login();
import oracle.toplink.sessions.*; Project project = new ACMEProject(); project.getLogin().setUserName("userid"); project.getLogin().setPassword("password"); DatabaseSession session = project.createDatabaseSession(); session.login();
import oracle.toplink.sessions.*; DatabaseLogin login = new DatabaseLogin(); login.useJConnectDriver(); login.setDatabaseURL("dbserver:5000:acme"); login.setUserName("userid"); login.setPassword("password"); Project project = new Project(login); DatabaseSession session = project.createDatabaseSession(); session.login();
Table 1-2 summarizes the most common public methods for the DatabaseLogin:
For a complete description of all available methods for the DatabaseLogin, see the TopLink JavaDocs.
The term query framework describes the mechanisms used to read and write to the database. There are three ways to access the database.
TopLink provides methods for the DatabaseSession class that read and write at the object level. Session queries are the simplest way to access the database.
TopLink provides query object classes that encapsulate the database operations. Query objects support more options than the session queries, allowing complex operations to be performed.
TopLink internally generates SQL strings to access the database. The application can also call SQL directly or use SQL to build query objects. Use of custom SQL is discouraged in favor of session queries and query objects, but applications can always use SQL to customize the TopLink session queries or call stored procedures.
The DatabaseSession class provides direct support for reading and modifying the database by providing read, write, insert, update and delete operations. Each of these operations can be performed by calling the appropriate session method. The session queries are very easy to use and are flexible enough to perform most database operations.
The UnitOfWork class can also be used to modify objects. Using a UnitOfWork is the preferred and optimal approach when modifications to the database are being made. The UnitOfWork has been optimized to keep track of changes that are being made to objects using object change sets. This enhancement allows the application to access change sets describing modifications made to an object within the unit of work or through event modification. Now, applications can check if any changes occurred before deciding to commit or release the unit of work. The application checks for changes by sending the hasChanged() message to the unit of work. Any changes are committed to the database by calling the UnitOfWork's commit method.
The UnitOfWork's `commit and merge' algorithm has also been optimized to improve performance.
The application can create query objects to perform more complex querying criteria than the session queries allow, if required. An application can create query objects by instantiating the appropriate query object and providing it with querying criteria. These criteria can be Expression objects or raw SQL strings.
Query objects can be used in one of four ways:
executeQuery() method on the DatabaseSession.
An application can also execute raw SQL strings and stored procedure calls. This is useful for calling stored procedures in the database and for accessing raw data.
Custom SQL strings and stored procedure calls can be used in one of three ways.
executeSelectingCall() and executeNonSelectingCall() session methods
executeQuery() method on the DatabaseSession.
If an error is encountered during a database operation, a TopLink exception of type DatabaseException is thrown. Interaction with the database should be performed within a try-catch block to catch these exceptions.
try { Vector employees = session.readAllObjects(Employee.class); } catch (DatabaseException exception) { // Handle exception }
Refer to Oracle9iAS TopLink Troubleshooting for more information on handling TopLink exceptions.
Write operations can also throw an OptimisticLockException on a write, update or delete operation if optimistic locking is enabled.
For information on optimistic locking, see the Oracle9iAS TopLink Mapping Workbench Reference Guide.
When querying on a class that is part of an inheritance hierarchy, the session checks the descriptor to determine the type of the class.
If the descriptor has been configured to read subclasses, which is the default, the query returns instances of the class and its subclasses.
If the descriptor has been configured not to read subclasses, the query returns only instances of the queried class. It does not return any instances of the subclasses.
If neither of these conditions apply, the class is a leaf class, and does not have any subclasses. The query returns instances of the queried class.
TopLink supports querying on an interface
Session queries enables you to read and write objects in a database.
The Session class and its subclasses, such as DatabaseSession and UnitOfWork, provide methods to retrieve objects stored in a database. These methods are called query methods, and allow queries to be made in terms of the object model rather than the relational model.
The session provides the following methods to access the database:
readObject() methods to read a single object from the database.
readAllObjects() methods to read multiple objects from the database.
refreshObject() method to refresh the object with data from the database.
When looking for a specific object, it is preferable to use the readObject() methods rather than the readAllObjects() method, because a read operation based on the primary key may be able to find an instance in the cache and avoid going to the database. A read all operation does not know how many objects are to be retrieved, so even if it finds matching objects in the cache, it goes to the database to find any others.
The readObject() methods retrieve a single object from the database. The application must specify the class of object to read. If no object matching the criteria is found, null is returned.
For example, the simplest reading operation would be:
session.readObject(MyDomainObject.class);
This example returns the first instance of MyDomainObject found in the table used for MyDomainObject.
Querying for the first instance of a class is not very useful. TopLink provides the Expression class to specify querying parameters for a specific object.
The readAllObjects() methods retrieve a Vector of objects from the database. The application must specify the class to read. An expression can be supplied to provide query parameters to identify specific objects within the collection. If no objects matching the criteria are found, an empty Vector is returned.
The readAllObjects() method returns the objects unordered.
The refreshObject() method causes TopLink to update the object in memory with any new data from the database. This operation refreshes any privately owned objects as well.
import oracle.toplink.sessions.*; import oracle.toplink.expressions.*; // Use an expression to read in the Employee whose last name is Smith. Create an expression using the Expression Builder and use it as the selection criterion of the search. Employee employee = (Employee) session.readObject(Employee.class, new ExpressionBuilder().get("lastName").equal("Smith"));
// Returns a Vector of employees whose employee salary > 10000.
Vector employees = session.readAllObjects(Employee.class,new ExpressionBuilder.get("salary").greaterThan(10000));
Applications need a flexible way to specify which objects are to be retrieved by a read query. Specifying query parameters using SQL would require application programmers to deal with relational storage mechanisms rather than the object model. Also, querying using strings is static and inflexible.
TopLink provides a querying mechanism called an expression that allows queries based on the object model. TopLink translates these queries into SQL and converts the results of the queries into objects.
Expression support is provided by two public classes. The Expression class represents an expression, which can be anything from a single constant to a complex clause with boolean logic. Expressions can be manipulated, grouped together and integrated in very flexible ways. The ExpressionBuilder serves as the factory for constructing new expressions.
A simple expression normally consists of three parts:
The attribute represents a mapped attribute or query key of the persistent class. The operator is an expression method that implements some sort of boolean logic, such as between, greaterThanEqual or like. The constant refers to the value used to select the object.
In the code fragment
expressionBuilder.get("lastName").equal("Smith");
the attribute is lastName, the operator is equal() and the constant is the string "Smith". The ExpressionBuilder is a stand-in for the object(s) to be read from the database; in this case, employees.
Using expressions to access the database has many advantages over using SQL.
emp.getAddress().getStreet().equal("Meadowlands");
To use an expression to get the street name of an employee's address from the database, write:
emp.get("address").get("street")
.equal("Meadowlands");
ExpressionBuilder emp = new ExpressionBuilder();
Expression exp = emp.get("address").get("street") .equal("Meadowlands Drive"); Vector employees = session.readAllObjects (Employee.class, exp.and(emp.get("salary") .greaterThan(10000)));
TopLink automatically generates the appropriate SQL from that code:
SELECT t0.VERSION, t0.ADDR_ID, t0.F_NAME, t0.EMP_ID, t0.L_NAME, t0.MANAGER_ ID, t0.END_DATE, t0.START_DATE, t0.GENDER, t0.START_TIME, t0.END_TIME, t0.SALARY FROM EMPLOYEE t0, ADDRESS t1 WHERE (((t1.STREET = 'Meadowlands') AND (t0.SALARY > 10000)) AND (t1.ADDRESS_ID = t0.ADDR_ID))
Expressions use standard boolean operators such as AND, OR and NOT. Multiple expressions can be combined to form more complex expressions. For example, the following code fragment queries for projects managed by a selected person, with a budget greater than or equal to $1,000,000.
ExpressionBuilder project = new ExpressionBuilder(); Expression hasRightLeader, bigBudget, complex; Employee selectedEmp = someWindow.getSelectedEmployee(); hasRightLeader = project.get("teamLeader").equal(selectedEmp); bigBudget = project.get("budget").greaterThanEqual(1000000); complex = hasRightLeader.and(bigBudget); Vector projects = session.readAllObjects(Project.class, complex);
TopLink supports a wide variety of database functions and operators, including like(), notLike(), toUpperCase(), toLowerCase(), toDate(), rightPad() and so on. Database functions allow you to define more flexible queries. For example, the following code fragment would match "SMITH", "Smith" and "smithers":
emp.get("lastName").toUpperCase().like("SM%")
Most functions are accessed through methods such as toUpperCase on the Expression class, but mathematical methods are accessed through the ExpressionMath class. This avoids over-complicating the Expression class with too many functions, while supporting mathematical functions similar to Java's java.lang.Math. For example:
ExpressionMath.abs(ExpressionMath.subtract(emp.get("salary"),emp.get("spouse").g et("salary")).greaterThan(10000)
You may want to use a function in your database that TopLink does not support directly. For simple functions, use the getFunction() operation, which treats its argument as the name of a unary function and applies it. For example, the expression
emp.get("lastName").getFunction("FOO").equal(42)
would produce the SQL
SELECT . . . WHERE FOO(EMP.LASTNAME) = 42
You can also create more complex functions and add them to TopLink. See "Platform and user-defined functions" .
Expressions can also use an attribute that has a one-to-one relationship with another persistent class. A one-to-one relation translates naturally into an SQL join that returns a single row. For example, to access fields from an employee's address:
emp.get("address").get("country").like("S%")
This example corresponds to joining the EMPLOYEE table to the ADDRESS table based on the "address" foreign key and checking for the country name. These relationships can be nested infinitely, so it is possible to ask for:
project.get("teamLeader").get("manager").get("manager").get("address").get("stre et")
More complex relationships can also be queried, but this introduces additional complications, because they do not map directly into joins that yield a single row per object.
TopLink allows queries across one-to-many and many-to-many relationships, using the anyOf operation. As its name suggests, this operation supports queries where any of the items on the "many" side of the relationship satisfy the query criteria.
For example:
emp.anyOf("managedEmployees").get("salary").lessThan(0);
returns employees where at least one of the employees who they manage (a one-to-many relationship) has a negative salary.
Similarly, we can query across a many-to-many relationship using:
emp.anyOf("projects").equal(someProject)
These queries translate into SQL and join the relevant tables, using a DISTINCT clause to remove duplicates. For example:
SELECT DISTINCT . . . FROM EMP t1, EMP t2 WHERE t2.MANAGER_ID = t1.EMP_ID AND t2.SALARY < 0
Expression objects should always be created by calling get() or its related methods on an Expression or ExpressionBuilder. The ExpressionBuilder acts as a stand-in for the objects being queried. A query is constructed by sending it messages that correspond to the attributes of the objects. ExpressionBuilder objects are typically named according to the type of objects that they are used to query against.
Expression have been extended to support subqueries (SQL subselects) and parallel selects. A SubQuery can be created using an ExpressionBuilder and Parallel Selects allow for multiple heterogeneous expression builders to be used in defining a single query. In this way, joins are allowed to be specified for unrelated objects at the object level.
Parallel selects and sub-queries are discussed in more detail later in this chapter.
This example uses the query key "lastName" defined in the descriptor to reference the field name "L_NAME".
Expression expression = new ExpressionBuilder().get("lastName").equal("Young");
ExpressionBuilder emp = new ExpressionBuilder();Expression exp1, exp2; exp1 = emp.get("firstName").equal("Ken"); exp2 = emp.get("lastName").equal("Young"); return exp1.and(exp2);
Expression expression = new ExpressionBuilder().get("lastName").notLike("%ung");
Occasionally queries need to make comparisons based on the results of sub-queries. SQL supports this through sub-selects. Expressions provide the notion of sub-queries to support sub-selects.
Sub-queries allow for Report Queries to be included in comparisons inside expressions. A report query is the most SQL complete type of query in TopLink. It queries data at the object level based on a class and expression selection criteria. Report queries also allow for aggregation and group-bys.
Sub-queries allow for sophisticated expressions to be defined to query on aggregated values (counts, min, max) and unrelated objects (exists, in, comparisons). A sub-query is obtained through passing an instance of a report query to any expression comparison operation, or through using the subQuery operation on expression builder. The sub-query can have the same, or a different reference class and must use a different expression builder. Sub-queries can be nested or used in parallel. Sub-queries can also make use of custom SQL.
For expression comparison operations that accept a single value (equal, greaterThan, lessThan) the sub-query's result must return a single value. For expression comparison operations that accept a set of values (in, exists) the sub-query's result must return a set of values.
This example queries all employees that have more than 5 managed employees.
ExpressionBuilder emp = new ExpressionBuilder(); ExpressionBuilder managedEmp = new ExpressionBuilder(); ReportQuery subQuery =new ReportQuery(Employee.class, managedEmp); subQuery.addCount(); subQuery.setSelectionCriteria(managedEmp.get("manager") .equal(emp)); Expression exp = emp.subQuery(subQuery).greaterThan(5);
This example queries the employee with the maximum salary in Ottawa.
ExpressionBuilder emp = new ExpressionBuilder(); ExpressionBuilder ottawaEmp = new ExpressionBuilder(); ReportQuery subQuery = new ReportQuery(Employee.class, ottawaEmp); subQuery.addMax("salary"); subQuery.setSelectionCriteria(ottawaEmp.get("address").get("city").equal("Ottawa ")); Expression exp = emp.get("salary").equal(subQuery).and(emp.get("address").get("city").equal("Otta wa"));
This example queries all employees that have no projects.
ExpressionBuilder emp = new ExpressionBuilder(); ExpressionBuilder proj = new ExpressionBuilder(); ReportQuery subQuery = new ReportQuery(Project.class, proj); subQuery.addAttribute("id"); subQuery.setSelectionCriteria(proj.equal(emp.anyOf("projects")); Expression exp = emp.notExists(subQuery);
Occasionally queries need to make comparisons on unrelated objects. Expressions provide the notion of parallel expressions to support these types of queries. The concept of parallel queries is similar to sub-queries in that multiple expression builders are used. However a report query is not required.
The parallel expression must have its own expression builder and the constructor for expression builder that takes a class as an argument must be used. The class can be the same or different for the parallel expression and multiple parallel expressions can be used in a single query. Only one of the expression builders will be considered the primary expression builder for the query. This primary builder will make use of the zero argument expression constructor and its class will be obtained from the query.
This example queries all employees with the same last name as another employee of different gender (possible spouse).
ExpressionBuilder emp = new ExpressionBuilder(); ExpressionBuilder spouse = new ExpressionBuilder(Employee.class); Expression exp = emp.get("lastName").equal(spouse.get("lastName")).and(emp.get("gender").notEqual (spouse.get("gender")).and(emp.notEqual(spouse));
Expressions can also create comparisons based on variables instead of constants. This technique is useful for:
In TopLink, a relationship mapping is very much like a query. It needs to know how to retrieve an object or collection of objects based on its current context. For example, a one-to-one mapping from Employee to Address needs to query the database for an address based on foreign key information from the table of the Employee. Each mapping contains a query, which in most cases is constructed automatically based on the information provided in the mapping. You can also specify these expressions yourself, using the mapping customization mechanisms described in the Oracle9iAS TopLink Mapping Workbench Reference Guide.
The difference from a regular query is that these are used to retrieve data for many different objects. TopLink allows these queries to be specified with arguments whose values are supplied each time the query is executed. We also need a way to refer directly to the potential values in the target database row without going through the object accessing mechanism.
The following two lower-level mechanisms are provided by the methods getParameter() and getField().
Returns an expression representing a parameter to the query. The parameter is the fully qualified name of the field from the descriptor's row, or a generic name for the argument. This method is used to construct user defined queries with parameters or to construct the selection criteria for a mapping. It does not matter which Expression object this message is sent to, because all parameters are global to the current query.
Returns an expression representing a database field with the given name. Normally used to construct the selection criteria for a mapping. The argument is the fully qualified name of the field. This method must be sent to an expression that represents the table from which this field is derived. See also "Data-level queries" .
This example builds a simple one-to-many mapping from class PolicyHolder to Policy. In this example, the SSN field of the POLICY table is a foreign key to the SSN field of the HOLDER table.
OneToManyMapping mapping = new OneToManyMapping();
mapping.setAttributeName("policies");
mapping.setGetMethodName("getPolicies");
mapping.setSetMethodName("setPolicies");
mapping.setReferenceClass(Policy.class);
// Build a custom expression here rather than using the defaults
ExpressionBuilder policy = new ExpressionBuilder();
mapping.setSelectionCriteria(policy.getField("POLICY.SSN")).equal(policy.getPara
meter("HOLDER.SSN")));
ExpressionBuilder address = new ExpressionBuilder(); Expression exp = address.getField("ADDRESS.EMP_ ID").equal(address.getParameter("EMPLOYEE.EMP_ID")); exp = exp.and(address.getField("ADDRESS.TYPE").equal(null));
The following example demonstrates how custom query is able to find an Employee if it is given the employee's first name.
ExpressionBuilder emp = new ExpressionBuilder(); Expression firstNameExpression; firstNameExpression = emp.get("firstName").equal emp.getParameter("firstName")); ReadObjectQuery query = new ReadObjectQuery(); query.setReferenceClass(Employee.class); query.setSelectionCriteria(firstNameExpression); query.addArgument("firstName"); Vector v = new Vector(); v.addElement("Sarah"); Employee e = (Employee) session.executeQuery(query, v);
The following example demonstrates how custom query is able to find all employees living in the same city as a given employee.
ExpressionBuilder emp = new ExpressionBuilder(); Expression addressExpression; addressExpression = emp.get("address").get("city").equal(emp.getParameter("employee").get("address") .get("city")); ReadObjectQuery query = new ReadObjectQuery(Employee.class); query.setName("findByCity"); query.setReferenceClass(Employee.class); query.setSelectionCriteria(addressExpression); query.addArgument("employee"); Vector v = new Vector(); v.addElement(employee); Employee e = (Employee) session.executeQuery(query, v);
Different databases provide different functions and sometimes implement the same functions in different ways. For example, indicating that an order by clause is ascending might be ASC or ASCENDING. TopLink supports this by allowing functions and other operators that vary according to the relational database.
While most platform-specific operators already exist in TopLink, it is possible to add your own. For this, you must be aware of the ExpressionOperator class.
An ExpressionOperator has a selector and a Vector of strings. The selector is the identifier (id) by which users refer to the function. The strings are the constant strings that are used in printing this function. These strings are printed in alternation with the function arguments. In addition, you can specify whether the operator should be prefix or postfix. In a prefix operator, the first constant string prints before the first argument; in a postfix, it prints afterwards.
ExpressionOperator toUpper = new ExpressionOperator(); toUpper.setSelector(-1); Vector v = new Vector(); v.addElement("UPPER("); v.addElement(")"); toUpper.printAs(v); toUpper.bePrefix();// To add this operator for all databaseExpressionOperator.addOperator(toUpper);// To add to a specific platformDatabasePlatform platform = session.getLogin().getPlatform(); platform.addOperator(toUpper);
ReadObjectQuery query = new ReadObjectQuery(Employee.class); expression functionExpression = new ExpressionBuilder().get("firstName").getFunction(ExpressionOperator.toUpper).equ al("FOO"); query.setSelectionCriteria(functionExpression); session.executeQuery(query);
In TopLink, expressions are used for internal queries as well as for user-level queries. TopLink mappings build expressions internally and use them to retrieve database results. The expressions are, necessarily, at the data level rather than the object level, because they are part of what defines the object level.
It is also possible to build arbitrary data-level queries using TopLink. The main operations to be aware of are getField() and getTable(). You can call getTable to create a new table. You can either hold onto that table expression or subsequently call getTable() with the table name to fetch it.
Note that tables are specific to the particular expression to which getTable() was originally sent. The getField() message can be sent to expressions representing either tables or objects. In either case, the field must be part of a table represented by that object; otherwise, you will get an exception when executing the query.
In an object-level expression, you refer to attributes of objects, which may in turn refer to other objects. In a data-level expression, you refer to tables and their fields. You can also combine data-level and object-level expressions within a single query.
This example reads a many-to-many relationship using a link table and also checks an additional field in the link table. Note the combination of object-level and data-level queries, as we use the employee's manager as the basis for the data-level query. Also note the parameterization for the ID of the project.
ExpressionBuilder emp = new ExpressionBuilder(); Expression manager = emp.get("manager"); Expression linkTable = manager.getTable("PROJ_EMP"); Expression empToLink = emp.getField("EMPLOYEE.EMP_ ID").equal(linkTable.getField("PROJ_EMP.EMP_ID"); Expression projToLink = linkTable.getField("PROJ_EMP.PROJ_ ID").equal(emp.getParameter("PROJECT.PROJ_ID")); Expression extra = linkTable.getField("PROJ_EMP.TYPE").equal("W"); query.setSelectionCriteria((empToLink.and(projToLink)).and(extra));
When querying, TopLink often uses joins to check values from other objects or other tables within the same object. This works well under most circumstances, but sometimes it is necessary to use a different type of join, known as an "outer join".
The most common circumstance is with a one-to-one relationship where one side of the relationship may not be present. For example, Employee objects may have an Address object, but if the Address is unknown, it is null at the object level, and has a null foreign key at the database level.
Outer joins can also be used for one-to-many and many-to-many relationships for cases where the relationship is empty.
At the object level this works fine, but when issuing a read that traverses the relationship, objects may be missing. Consider the expression:
(emp.get("firstName").equal("Homer")).or(emp.get("address"). get("city").equal("Ottawa"))
In this case, employees with no address do not appear in the list, regardless of their first name. While non-intuitive at the object level, this is fundamental to the nature of relational databases and not easily changed. One way around the problem on some databases is to use an outer join. In this example, employees with no address show up in the list with null values in the result set for each column in the ADDRESS table, which gives the correct result. We specify that an outer join is to be used by using getAllowingNull() or anyOfAllowingNone() instead of get() or anyOf().
For example:
(emp.get("firstName").equal("Homer")).or(emp.getAllowingNull ("address").get("city").equal("Ottawa"))
Outer joins are useful but do have limitations. Support for them varies widely between databases and database drivers, and the syntax is not standardized. TopLink currently supports outer joins for Sybase, SQL Server, Oracle, DB2, Access, SQL Anywhere and the JDBC outer join syntax. Of these, only Oracle supports the outer join semantics in `or' clauses. Outer joins are also used with ordering (see "Ordering for read all queries" ) and for joining (see Chapter 6, "Performance Optimization").
Table 1-3 and Table 1-4 summarize the most common public methods for ExpressionBuilder and Expression.
For a complete description of all available methods for the ExpressionBuilder and Expression, see the TopLink JavaDocs.
TopLink's advanced expression framework queries can now be defined through providing example instances of the application's object model. This allows for highly dynamic queries to be easily defined through using the application's own object model. Query forms can be rapidly built through wiring an object model instance to the query form and passing the instance directly to the TopLink query. Query by example also provides a way for non-TopLink aware clients to define dynamic queries.
Query by example builds an expression from an instance by comparing each attribute to the current value in the instance. All types of direct mappings are supported as well as most relationship mappings, so the instance's related objects can also be queried. A policy object can also be used with the query. The policy can specify
Although a DatabaseSession can write objects to the database directly, the UnitOfWork is the preferred approach when writing to the database in TopLink.
The writeObject() method should be called when a significant change to the object has occurred. It should also be called after the creation and initialization of new application objects so that the new objects are found in subsequent database queries.
The writeObject() method can be used on both new and existing instances stored in the database. It determines whether to perform an insert or an update by performing a does exist check. In essence, a `does exist' check determines whether the object already exists in the database. If the object already exists, an update operation is performed. If it does not already exist, an insert operation is performed.
Privately owned objects are also written in the correct order to maintain referential integrity.
The application can write multiple objects using the writeAllObjects() method. It performs the same `does exist' check as the writeObject() method and then performs the appropriate insert or update operations.
The insertObject() method should be called only when dealing with new objects. When using insertObject() instead of writeObject(), the `does exist' check to the database is bypassed.
This method assumes that the object is a new instance and does not already exist in the database. If the object already exists in the database, an exception occurs when insertObject() is executed.
The updateObject() method should be called only when dealing with existing objects. When using updateObject() instead of writeObject(), the `does exist' check to the database is bypassed.
This method assumes that the object already exists in the database. If the object does not already exist in the database, an exception occurs when updateObject() is executed.
To delete a TopLink object from its table, call the method deleteObject() and pass a reference to the object to delete.
An object must be loaded to be deleted. Any privately-owned data is also deleted when a deleteObject() operation is performed.
The following examples show how to implement write and write all operations in Java code.
//Create an instance of employee and write it to the database.Employee susan = new Employee(); susan.setName("Susan"); ...//Initialize the susan object with all other instance variables.session.writeObject(susan);
// Read a Vector of all of the current employees in the database. Vector employees = (Vector) session.readAllObjects(Employee.class); ...//Modify any employee data as necessary.//Create a new employee and add it to the list of employees.Employee susan = new Employee(); ...//Initialize the new instance of employee.employees.add(susan);//Write all employees to the database. The new instance of susan which is not currently in the database will be inserted. All of the other employees which are currently stored in the database will be updated.session.writeAllObjects(employees);
A transaction is a set of database session operations that can either be committed or rolled back as a single operation.
If one operation in a transaction fails, all operations in the transaction fail. Transactions allow database operations to be performed in a controlled manner, in which the database is modified only when all transaction operations have been successful.
Transactions are closely related to the concept of a unit of work. If using a unit of work, transactions do not have to be used.
TopLink provides the following methods to support transaction processing:
beginTransaction() - marks the beginning of a transaction
commitTransaction() - signals the end of a transaction, and is used to commit the set of transaction operations and modify the database
rollbackTransaction() - once a transaction has been committed, there is no way to undo it; however, if an error occurs during a transaction, the rollbackTransaction() method can be used to undo the entire transaction set.
TopLink allows nested transactions but uses a single transaction in the database because JDBC does not support nested transactions. The inner transactions are counted and ignored.
beginTransaction() at the start of the transaction set.
rollbackTransaction() if a database exception is thrown.
commitTransaction() at the end of the transaction set.
/** Updates the group of employee records*/
void writeEmployees(Vector employees, Session session)
{
Employee employee;
Enumeration employeeEnumeration = employees.elements();
try {
session.beginTransaction();
while (employeeEnumeration.hasMoreElements())
{
employee=(Employee) employeeEnumeration.nextElement();
session.writeObject(employee);
}
session.commitTransaction();
} catch (DatabaseException exception) {
// A database exception has been thrown, indicating that at least one
operation has failed. Roll back the Transaction if the application requires
that all operations must succeed or all must fail.
session.rollbackTransaction();
}
}
A unit of work is a session that simplifies the transaction process and stores transaction information for its registered persistent objects. The unit of work enhances database commit performance by updating only the changed parts of an object.
Units of work are the preferred method of writing to a database in TopLink. The unit of work:
To use a unit of work, the application typically acquires an instance of UnitOfWork from the session and registers the persistent objects that are to change. The registering process returns clones that can be modified.
After changes are made to the clones, the application uses the commit() method to commit an entire transaction. The unit of work inserts new objects or updates changed objects in the database according to the changes made to the clones.
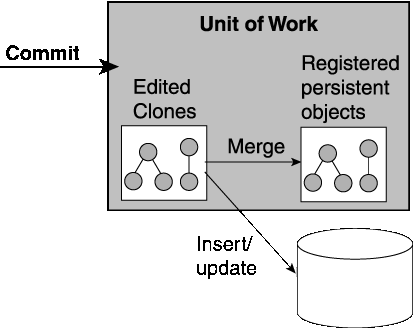
When writing the objects to the database:
DatabaseException is thrown and the unit of work is rolled back to its original state.
// The application reads a set of objects from the database.Vector employees = session.readAllObjects(Employee.class);// The application decides that a specific employee will be edited.. . . Employee employee = (Employee) employees.elementAt(index) try {// Acquire a unit of work from the session.UnitOfWork uow = session.acquireUnitOfWork() // Register the object that is to be changed. The unit of work returns a clone of the object. We make the changes to the clone. The unit of work also makes a back-up copy of the original employee. Employee employeeClone = (Employee)uow.registerObject(employee) // We make changes to the employee clone by adding a new phoneNumber. If a new object is referred to by a clone, then it does not have to be registered. The unit of work determines that it is a new object at commit time. PhoneNumber newPhoneNumber = newPhoneNumber("cell","212","765-9002"); employeeClone.addPhoneNumber(newPhoneNumber); // We commit the transaction. This causes the unit of work to compare the employeeClone with the back-up copy of the employee, begin a transaction, and update the database with the changes. // If all goes well, then the transaction is committed and the changes in employeeClone are merged into employee. // If there is an error updating the database, then the transaction is rolled back and the changes are not merged into the original employee object. uow.commit(); } catch (DatabaseException ex) { // The commit has failed. The database was not changed. The unit of work should be thrown away and application-specific action taken. } // After the commit, the unit of work is no longer valid. It should not be used further.
To create a unit of work for a given session, call the acquireUnitOfWork() method on the DatabaseSession class. The unit of work is valid until the application calls the commit() or release() methods.
Registering objects tells the unit of work that the application will change those objects. During registration, the unit of work creates and returns clones of the original objects given. All changes are made by the application on those clones. The original objects are left unchanged. If the commit() is successful, then the changes made to the clones are merged into the original objects.
You should use units of work to keep track of only those objects that are going to be changed. By registering objects that will not change, the unit of work is needlessly performing cloning and other processing.
The unit of work maintains object identity on the registered clones. If the same object is registered twice, the identical clone is returned.
When an object is read from the database using the unit of work, it is automatically registered with that unit of work, and therefore should not be re-registered.
Only root-level objects should be registered. New objects that are referred to by a clone do not have to be registered. At commit time, the unit of work determines that these are new objects, and takes appropriate action.
The unit of work has two methods to explicitly register objects:
registerObject(Object) -- returns a clone of the object
registerAllObjects(Vector) -- returns a Vector of clones
When objects are registered, the unit of work determines if they are new or existing (using the object's descriptor's "does exist" setting). If the objects are known to exist the registerExistingObject() method can be used to eliminate the need for the "does exist" check to be performed.
A unit of work is a Session and can be used for all database access during its lifetime. It uses the same methods to read from the database that a session uses, such as readObject() and readAllObjects(). These methods automatically register the objects read in the unit of work and return clones, so the registerObject() and registerAllObjects() methods do not have to be called.
New objects can be included in a unit of work. Unless a registered clone points to them, the application must register these new objects so that they are written to the database at commit time.
The registration is done in the same way that you register other objects, by using the registerObject() call. If you do not register a newly created object, the commit() call does not write that object to the database, because the unit of work has no way of knowing that the new object exists.
The order that registerObject is called on a new object does not affect the order in which objects are inserted. When the unit of work calculates its commit order, it uses the foreign key information in one-to-one and one-to-many mappings. If you are having constraint problems during insertion, make sure that your one-to-one mappings are defined correctly.
All updates and inserts on the database are done inside the call to the UnitOfWork's commit() method. It is not valid to perform write, insert, and update operations on a unit of work. The commit() method updates the database with the changes to the cloned objects. Only those clones that have changed since they were registered are updated or inserted into the database.
If an error occurs when writing the objects to the database, a DatabaseException is thrown and the database is rolled back to its original state. If no database errors occur, the original objects are updated with the new values from the clones.
Successfully committing to the database ends the unit of work. The unit of work should not be used after a commit has been done.
Deleting objects in a unit of work is done using the deleteObject() or deleteAllObjects() method. If an object being deleted has not been registered, then it is registered automatically.
When an object is deleted, its privately-owned parts are also deleted, because privately-owned parts cannot exist without their owner. At commit time, SQL is generated to delete the objects, taking database constraints into account.
If an object is deleted, then the object model must take the deletion of that object into account. References to the object being deleted must be set to null.
// Acquire a unit of work.UnitOfWork uow = session.acquireUnitOfWork(); Project project = (Project) uow.readObject(Project.class); Employee leader = project.getTeamLeader();// Because we are deleting the Employee who is currently the team leader, we must set the Project's teamLeader to be null. Otherwise, the object model will be corrupted and the Project will be referring to a non-existent Employee.// If the team leader is not set to null, then a QueryException will be thrown during the merge. It is also likely that this would violate a database constraint and a DatabaseException would be thrown during the commit.project.setTeamLeader(null);// Delete the leader employee at commit time.uow.deleteObject(leader); uow.commit();
Normally when a unit of work is committed, the clones of the registered objects become invalid. If another edit is started, the objects must be re-registered in a new unit of work and the new clones must be edited.
The unit of work also supports resuming, through the commitAndResume()and commitAndResumeOnFailure() methods. The changes in the unit of work are committed to the database; however, the unit of work is not invalidated. The same unit of work and clones of registered objects can continue to be used for subsequent edits and commits. If resume on failure is used and the unit of work commit fails, the unit of work can still be used and the commit re-tried.
Reverting a unit of work with the revert() method essentially puts the unit of work back in a state where all of the objects that were registered are still registered but no changes have been made yet.
In certain circumstances, an application may want to abandon the changes made to the clones in a unit of work, but does not want to abandon the unit of work. The method revertAndResume() exists for this purpose. The revertAndResume() method undoes all the changes made to the clones using the original objects as a guide. It also deregisters all new objects, and removes from the deletion set all of the objects for which deleteObject(Object) was called.
Like a session, a unit of work can execute queries using the executeQuery() method. The results of these queries are automatically registered in the unit of work and clones are returned to the caller.
Modify queries such as InsertObjectQuery or UpdateObjectQuery cannot be executed, because database modification is done only on commit.
An application can have multiple units of work operating in parallel by calling acquireUnitOfWork() multiple times on the session. The units of work operate independently of one another and maintain their own cache.
The application can also nest units of work by calling acquireUnitOfWork() on the parent unit of work. This creates a child unit of work with its own cache.
The child unit of work should be committed or released before its parent. If a child unit of work commits, it updates the parent unit of work rather than the database. If the parent does not commit to the database, the changes made to the child are not updated in the database.
The unit of work keeps track of original objects that are registered with it, the working copy clones and the back-up copy clones that it creates. The working copy clones are returned when an object is registered.
After the user changes the clones and commits the unit of work, the working copy clones are compared to the back-up copy clones. The changes are written to the database. The working copy clones are compared to the back-up copy clone (not to the original object) because another parallel unit of work may have changed the original object. Comparing to the back-up copy clones assures us that only the changes that were made in the current unit of work are written to the database and merged into the parent session's cache. The use of clones in the unit of work allows parallel units of work, which is an absolute requirement to build multi-user three-tier applications.
The creation of clones is highly optimized. When making clones, only mapped attributes are considered. The cloning process stops at indirection objects and continues only if the indirection objects are accessed. The cloning process is configurable using the descriptor's Copy Policy.
The Unit of Work offers a number of advanced features that enable you to optimize certain functions
Within a unit of work, a class can be declared read-only. Declaring a class read-only tells the unit of work that instances of this class will never be modified. The unit of work can save time during registration and merge because instances of read-only classes do not require clones to be created or merged.
When an object is registered, the entire object tree is traversed and registered also. When a read-only object is encountered during the tree traversal, that branch of the tree is not traversed further. Therefore, any objects that are referred to by read-only objects are not registered either.
Read-only classes are normally reference data objects; that is, objects that are not changed in the current application.
An example of a reference data class would be the class Country. An Address can refer to a Country but the Country objects are created, modified, or deleted in another application. When modifying an Address, a Country object can be assigned to the Address where the Country object would have been chosen from a set of Country objects that are already stored in the database.
The user can set classes to be read-only for an individual unit of work immediately after it is acquired. The methods addReadOnlyClass(Class) or addReadOnlyClasses(Vector) can be used to change the set of read-only classes for a specific unit of work.
A default set of read-only classes can be established for the duration of the application by using the Project method setDefaultReadOnlyClasses(Vector). All new units of work acquired after this call will have the Vector set of read-only classes.
Nested units of work have the same set or a super set of read-only classes as their parent. When a nested unit of work is acquired, it inherits the same set as its parent unit of work. If a class is declared read-only, then its subclasses must also be declared read-only.
TopLink's support for read-only classes within a unit of work extends to include descriptors (for information on Read-Only classes, see "Read-only classes" ). When a class is declared as read-only, its descriptors are also flagged as read-only. In addition, you can flag a descriptor as read-only directly, either from within code or from the Mapping Workbench. The functionality is the same as for read-only classes, which improves performance by excluding read-only descriptors/classes from write operations such as inserts, updates, and deletes.
Descriptors can be flagged as read-only by calling the setReadOnly() method on the descriptor as follows:
descriptor.setReadOnly();
You can also flag a descriptor as read-only in the Mapping Workbench by checking the Read Only check box for a specific descriptor.
TopLink's support for conforming queries in the unit of work can now be specified in the descriptors (for information on conforming queries, see "In-memory querying and unit of work conforming" ). Conforming is specified at the query level. This enables the results of the query to conform with any changes to the object made within the unit of work including new objects, deleted objects and changed objects.
A descriptor can be directly flagged to always conform results in the unit of work so that all queries performed on this descriptor will, by default conform its results in the unit of work. This can be specified either within code or from the Mapping Workbench.
You can flag descriptors to always conform in the unit of work by calling the method on the descriptor as follows:
descriptor.setShouldAlwaysConformResultsInUnitOfWork(true);
You can also flag descriptors to always conform from the Mapping Workbench by checking the Conform Results in Unit Of Work check box for a descriptor.
When using the unit of work with a ClientSession in a three-tier application, objects are often returned from the client through some sort of serialization mechanism (for example, RMI or CORBA).
The unit of work is expecting all changes to be made to the "working copy" clone that it returned when the original object was registered.
The changes to the object returned from the client must be propagated to the "working copy" clone of the unit of work before the unit of work is committed. The unit of work provides three methods, where each method takes a clone that was returned from the serialization mechanism and merges the changes into the unit of work's working copy clone:
mergeClone(Object) - merges the clone and all of its privately-owned parts into the unit of work's working copy clone
deepMergeClone(Object) - merges the clone and all of its parts into the unit of work's working copy clone
shallowMergeClone(Object) - merges only the attributes that are mapped with direct mappings
Merge clone can be used with both existing and new objects. New objects can be merged only once within a unit of work, because they are not cached and may not have a primary key. If new objects are required to be merged twice, this can be done through the setShouldNewObjectsBeCached() method and ensuring that the objects have a valid primary key before being registered.
The unit of work validates object references when it commits. Objects registered in a unit of work should not reference objects that have not been registered in the unit of work. Doing this violates object transaction isolation and can lead to corrupting the session's cache. In some cases the application may wish to turn this validation off, or increase the amount of validation. This can be done through the dontPerformValidation() and performFullValidation() methods.
When the unit of work detects an error during the merge, it throws a QueryException stating the invalid object and the reason that it is invalid. In this case, it may still be difficult for the application to figure out the problem, so the unit of work provides the validateObjectSpace() method to allow your application to pinpoint where the problem exists in the object model. The validateObjectSpace() method can be called at any time on the unit of work and provides the full stack of objects traversed to discover the invalid object.
The following examples show some typical units of work.
// Get an employee read from the parent session of the unit of work. Employee employee = (Employee)session.readObject(Employee.class) // Acquire a unit of work. UnitOfWork uow = session.acquireUnitOfWork(); Project project = (Project) uow.readObject(Project.class); // When associating an existing object (read from the session) with a clone, we must make sure we register the existing object and assign its clone into a unit of work. // INCORRECT: Cannot associate an existing object with a unit of work clone. A QueryException will be thrown. project.setTeamLeader(employee); // CORRECT: Instead register the existing object then associate the clone. Employee employeeClone = (Employee)uow.registerObject(employee); project.setTeamLeader(employeeClone); uow.commit();
// Get an employee read from the parent session of the unit of work. Employee manager = (Employee)session.readObject(Employee.class); // Acquire a unit of work. UnitOfWork uow = session.acquireUnitOfWork(); // Register the manager to get its clone Employee managerClone = (Employee)uow.registerObject(manager); // Create a new employee Employee newEmployee = new Employee(); newEmployee.setFirstName("Spike"); newEmployee.setLastName("Robertson"); // INCORRECT: Should not be associating the new employee with the original manager. This would cause a QueryException whenTopLinkdetects this error during the merge. newEmployee.setManager(manager); // CORRECT: associate the new object with the clone. Note that in this example, the setManager method is maintaining the bidirectional managedEmployees // relationship and adding the new employee to its managedEmployees. At commit time, the unit of work will detect that this is a new object and will take the appropriate action. newEmployee.setManager(managerClone); // INCORRECT: Do not register the newEmployee, as this would create two copies. This would cause a QueryException whenTopLinkdetects this error during the merge. // uow.registerObject(newEmployee); // In the call to setManager, above, the managerClone's managedEmployees may not have been maintained through the setManager method. If it were not the case, the registerObject should have been called before the new employee was related to the manager. If the developer was unsure if this was the case, the registerNewObject method could be called to be sure that the newEmployee is registered in the unit of work. The registerNewObject method registers the object, but does not make a clone. uow.registerNewObject(newEmployee); // Commit the unit of work uow.commit();
Table 1-5 summarizes the most common public methods for the UnitOfWork:
For a complete description of all available methods for the UnitOfWork, see the TopLink JavaDocs.
Locking policy is an important component of any multi-user TopLink application. When users share objects in an application, a locking policy ensures that two or more users do not attempt to modify the same object or its underlying data simultaneously. If the object is new, deleted, or changed, normal insert, delete, or update overrides the feature.
Many record locking strategies are employed by relational databases. TopLink includes support for the following locking policies:
All users have read access to the object. When a user attempts to write a change, the application checks to ensure the object has not changed since the last read.
Like an optimistic lock, the optimistic read lock checks to ensure the object has not changed since the last read when the user attempts to write a change. However, the optimistic read lock also forces a read of any related tables that contribute information to the object.
The first user who accesses an object with the purpose of updating locks the object until the update is complete. No other user can read or update the object until the first user releases the lock.
The application does not verify that data is current.
Optimistic locking, also known as write locking, allows unlimited read access to an object. However, a client can only write an object to the database if the object has not changed since the client last read it.
TopLink's support for optimistic record locking uses the descriptor, and can be applied in the following two ways:
UnitOfWork in order to be implemented.
The advantages of optimistic locking are:
The disadvantage of optimistic locking is
There are two types of version locking policies available in TopLink, VersionLockingPolicy and TimestampLockingPolicy. Each of these requires an additional field in the database to operate:
VersionLockingPolicy, add a numeric field to the database.
TimestampLockingPolicy, add a timestamp field to the database.
TopLink records the version as it reads an object from a table. When the client attempts to write the object, the version of the object is compared with the version in the table record. If the versions are the same, the updated object is written to the table, and the version of both the table record and the object are updated. If the versions are different, the write is disallowed and an error is raised.
The two version locking policies have different ways of writing the version fields back to the database:
VersionLockingPolicy increments the value in the version field by one.
TimestampLockingPolicy inserts a new timestamp into the row. The timestamp is configurable to get the time from the server or the local machine.
For both policies, the values of the write lock field can be stored in either the identity map or in a writable mapping within the object.
If the value is stored in the identity map, then by default an attribute mapping is not required for the version field. If the application does map the field, it must make the mappings read-only to allow TopLink to control writing the fields.
TopLink support for field locking policies does not require any additional fields in the database. Field locking policy support includes:
All of these policies compare the current values of certain mapped fields with their previous values. When using these policies, a UnitOfWork must be used for updating the database. Each policy handles its field comparisons in a specific way defined by the policy.
AllFieldsLockingPolicy is updated or deleted, all the fields in that table are compared in the where clause. If any value in that table has been changed since the object was read, the update or delete fails. This comparison is only on a per table basis. If an update is performed on an object that is mapped to multiple tables (including multiple table inheritance), only the changed table(s) appear in the where clause.
ChangedFieldsLockingPolicy is updated, only the modified fields are compared. This allows for multiple clients to modify different parts of the same row without failure. Using this policy, a delete compares only on the primary key.
SelectedFieldsLockingPolicy is updated or deleted, a list of selected fields is compared in the update statement. Updating these fields must be done by the application either manually or though an event.
Whenever any update fails because optimistic locking has been violated, an OptimisticLockException is thrown. This should be handled by the application when performing any database modification operations. The application must refresh the object and reapply its changes.
Use the API to set optimistic locking in code. All of the API is on the descriptor:
useVersionLocking(String) sets this descriptor to use version locking, and increments the value in the specified field name for every update or delete
useTimestampLocking(String) sets this descriptor to use timestamp locking and writes the current server time in the specified field name for every update or delete
useChangedFieldsLocking() tells this descriptor to compare only modified fields for an update or delete
useAllFieldsLocking() tells this descriptor to compare every field for an update or delete
useSelectedFieldsLocking(Vector) tells this descriptor to compare the field names specified in this vector of Strings for an update or delete
The following example illustrates how to implement optimistic locking using the VERSION field of EMPLOYEE table as the version number of the optimistic lock
descriptor.useVersionLocking("VERSION");
This code stores the optimistic locking value in the identity map. If the value should be stored in a non-read only mapping, then the code would be:
descriptor.useVersionLocking("VERSION", false);
The false indicates that the lock value is not stored in the cache but is stored in the object.
TopLink includes the previously described optimistic locking policies, and all of these policies implement the OptimisticLockingPolicy interface. This interface is referenced throughout the TopLink code. It is possible to create more policies by implementing this interface and implementing the methods defined.
Optimistic read lock is an advanced type of optimistic lock that not only checks the version of the object, but also forces optimistic lock checking on an unchanged object by issuing an SQL "UPDATE ... SET VERSION = ? WHERE ... VERSION = ?" statement to the database. Optimistic read locking also allows modification of version field along with optimistic lock checking. An optimistic lock exception is thrown if the "VERSION" field has changed.
This feature is supported in UnitOfWork API as follows:
UnitOfWork.forceUpdateToVersionField(Object cloneFromUOW, boolean shouldModifyVersionField) UnitOfWork.removeForceUpdateToVersionField(Object cloneFromUOW);
This feature can only be used on objects that implement a version locking policy or timestamp locking policy. When an object that implements a version locking policy is updated, the version value is incremented or set to the current timestamp. For more information on version locking policies, see "Version locking policies" .
UnitOfWork considers an object changed when its direct-to-field mapping's attribute or aggregate object mapping's attribute is modified. If an object is added to or removed from the relationship of the source object, or an object in the relationship is changed, UnitOfWork does not consider this a changed in the source object and does not check optimistic locking for the source object when it commits.
Optimistic read lock enables a UnitOfWork to either force an update to the version or leave the version without an update using the forceUpdateToVersionField function as follows:
UnitOfWork.forceUpdateToVersionField(cloneObject, true|false);
Using the true switch causes the version to be incremented, while the false switch leaves the version non-incremented. Whether or not the version should be incremented depends on the circumstances.
Leave the version unmodified when the application logic depends on an unchanged object in the current application but the object may have changed in another application. Forcing optimistic lock checking on the object guarantees the validity of data committed in the current application.
TopLink-generated SQL for this feature typically follows the format "UPDATE ... SET VERSION = 10 WHERE ... VERSION = 10".
In this example, a thread is calculating a mortgage rate based on the current interest rate (the "mortgage rate" thread). If the interest rate used by this thread is adjusted by another thread (the "interest rate" thread) while the calculation is happening. the calculation becomes invalid, because the mortgage rate thread does not take into account the changes made by the interest rate thread. To avoid this, the mortgage rate thread forces optimistic lock checking on the interest rate to guarantee a valid calculation.
The following code calculates the mortgage rate:
try { UnitOfWork uow = session.acquireUnitOfWork(); MortgageRate cloneMortgageRate = (MortgageRate) uow.registerObject(mortgageRate); InterestRate cloneInterestRate = (InterestRate) uow.registerObject(interestRate); cloneMortgageRate.setRate(cloneInterestRate .getRate() - cloneMortgageRate.getDiscount());/* Force optimistic lock checking on interestRate to guarantee a valid calculation, but with no version update*/uow.forceUpdateToVersionField(cloneInterestRate, false); uow.commit(); }(OptimisticLockException exception) {/* Refresh the out-of-date object */session.refreshObject(exception.getObject()); /* Retry... */ }
This code adjusts the interest rate:
try {UnitOfWork uow = session.acquireUnitOfWork(); InterestRate cloneInterestRate = (InterestRate) uow.registerObject(interestRate); cloneInterestRate.setRate(cloneInterestRate}(OptimisticLockException exception) {
.getRate() + 0.005); uow.commit();/* Refresh out-of-date object */session.refreshObject(exception.getObject());/* Retry... */}
This feature is applied in situation where application requires marking an unchanged object as changed when it modifies the object's relationship.
TopLink-generated SQL for this feature typically follows the format "UPDATE ... SET VERSION = 11 WHERE ... VERSION = 10".
A thread (the "bill" thread) is calculating an invoice for a customer. If another thread (the "service" thread) adds a service to the same customer or modifies the current service, the bill thread must be informed so that the changes are reflected on the invoice. This is accomplished as follows:
This code represents the service thread. It adds a service to the customer and updates the version:
try { UnitOfWork uow = session.acquireUnitOfWork(); Customer cloneCustomer = (Customer uow.registerObject(customer); Service cloneService = (Service uow.registerObject(service);/* Add a service to customer */cloneService.setCustomer(cloneCustomer); cloneCustomer.getServices().add(cloneSerVice);/* Modify the customer version to inform other application that the customer has changed */uow.forceUpdateToVersionField(cloneCustomer, true); uow.commit(); } (OptimisticLockException exception) {/* Refresh out-of-date object */session.refreshObject(exception.getObject());/* Retry... */}
Notice that the service thread forces a version update. The following code represents the bill thread, and calculates a bill for the customer. Notice that it does not force an update to the version:
try { UnitOfWork uow = session.acquireUnitOfWork(); Customer cloneCustomer = (Customer) uow.registerObject(customer); Bill cloneBill = (Bill) uow.registerObject(new Bill()); cloneBill.setCustomer(cloneCustomer);/* Calculate services' charge */int total = 0; for(Enumeration enum = cloneCustomer.getServices().elements(); enum.hasMoreElements();) { total += ((Service) enum.nextElement()).getCost(); } cloneBill.setTotal(total);/* Force optimistic lock checking on the customer to guarantee a valid calculation */uow.forceUpdateToVersionField(cloneCustomer, false); uow.commit(); }(OptimisticLockException exception) {/* Refresh the customer and its privately owned parts */// session.refreshObject(cloneCustomer);/* If the customer's services are not private owned then use a ReadObjectQuery to refresh all parts */ReadObjectQuery query = new ReadObjectQuery(customer);/* Refresh the cache with the query's result and cascade refreshing to all parts including customer's services */query.refreshIdentityMapResult(); query.cascadeAllParts();/* Refresh from the database */query.dontCheckCache(); session.executeQuery(query);/* Retry... */}
Pessimistic locking means that objects are locked before they are edited, which ensures that only one client is editing the object at any given time.
Pessimistic locking differs from optimistic locking in that locking violations are detected at edit time, not commit time. The TopLink implementation of pessimistic locking uses database row-level locks. Depending on the database, a lock attempt on a locked row either fails or is blocked until the row is unlocked.
Pessimistic locking, unlike optimistic locking, prevents users from editing data that is being changed. While acquiring a pessimistic lock on an object, the object must be refreshed to reflect it's most recent state, but optimistic locking only requires refreshing objects when a lock violation has been detected. As a result, optimistic locking is typically more efficient.
For information on optimistic locking, see the Oracle9iAS TopLink Mapping Workbench Reference Guide.
The advantages of pessimistic locking are:
The disadvantages of pessimistic locking are that it:
Pessimistic locks exist only for the duration of the current transaction. A database transaction must be held open from the point of the first lock request until the commit. When the transaction is committed or rolled back, all of the locks are released. When using the unit of work, a transaction is automatically started when the first lock is attempted, and committed or rolled back when the unit of work is committed or released. If you are not using the unit of work you must manually begin a transaction on the session.
TopLink offers two methods of locking, WAIT and NO_WAIT. When refreshing an object in WAIT mode, the transaction must wait until the lock on the object is free before obtaining a lock on that object. In NO_WAIT mode, an exception is thrown if the object is being locked.
import oracle.toplink.sessions.*; import oracle.toplink.queryframework.*; ... UnitOfWork uow = session.acquireUnitOfWork(); Employee employee = (Employee) uow.readObject(Employee.class); // Note: This will cause the unit of work to begin a transaction. In a 3-Tier model this will also cause the ClientSession to acquire its write connection from the ServerSession's pool. uow.refreshAndLockObject(employee, ObjectLevelReadQuery.LOCK); // Make changes to object ... uow.commit(); ...
import oracle.toplink.sessions.*; import oracle.toplink.queryframework.*; import oracle.toplink.exceptions.*; ... UnitOfWork uow = session.acquireUnitOfWork(); Employee employee = (Employee) uow.readObject(Employee.class); try { employee = (Employee) uow.refreshAndLockObject(employee, ObjectLevelReadQuery.LOCK_NOWAIT); } catch (DatabaseException dbe) {// Some databases throw an exception instead of returning nothing.employee = null; } if (employee == null) {// Lock could not be obtaineduow.release(); throw new Exception("Locking error."); } else {// Make changes to object... uow.commit(); } ...
import oracle.toplink.sessions.*; import oracle.toplink.queryframework.*; ... UnitOfWork uow = session.acquireUnitOfWork(); ReadObjectQuery query = new ReadObjectQuery(); query.setReferenceClass(Employee.class); query.acquireLocks(); // or acquireLocksWithoutWaiting()query
.refreshIdentityMapResult(); Employee employee = (Employee) uow.executeQuery(query);// Make changes to object... uow.commit(); ... UnitOfWork uow = session.acquireUnitOfWork(); ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setSelectionCriteria(new ExpressionBuilder().get("salary").greaterThan(25000)); query.acquireLocks();// or acquireLocksWithoutWaiting()query
.refreshIdentityMapResult();// NOTE: the objects are registered when they are obtained by using unit of work. TopLink will update all the changes to registered objects when unit of work commit.Vector employees = (Vector) uow.executeQuery(query);// Make changes to objects... uow.commit(); ...
import oracle.toplink.sessions.*; import oracle.toplink.sessions.queryframework.*; ...// It must begin a transaction or the lock request will throw an exceptionsession.beginTransaction(); ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setSelectionCriteria(new ExpressionBuilder().get("salary").greaterThan(25000)); query.acquireLocks();// or acquireLocksWithoutWaiting()query.refreshIdentityMapResult(); Vector employees = (Vector) session.executeQuery(query);// Make changes to objects...// Update objects to reflect changesfor (Enumeration enum = employees.elements(); employees.hasMoreElements(); { session.updateObject(enum.nextElement()); } session.commitTransaction(); ...
Table 1-6 summarizes the most common public methods for Pessimistic Locking:
For a complete description of all available methods for Pessimistic Locking, see the TopLink JavaDocs.
The session event manager handles information about session events. Applications can register with the session event manager to receive session event data.
As with descriptor events, DatabaseSessions, UnitsOfWork, ClientSessions, ServerSessions, and RemoteSessions raise SessionEvents when most session operations are performed. These events are useful when debugging or when coordinating the actions of multiple sessions. For more information on descriptor events, see the Oracle9iAS TopLink Mapping Workbench Reference Guide.
Objects can register as listeners for these events by implementing the SessionEventListener interface and registering with the SessionEventManager using addListener(). Alternatively, objects can subclass SessionEventAdapter and override only the methods for events required by your application. Currently, there is no support in TopLink Mapping Workbench for session events.
Events supported by the SessionEventManager include:
PreExecuteQuery: raised before the execution of every query on the Session
PostExecuteQuery: raised after the execution of every query on the Session
PreBeginTransaction: raised before a database transaction is started
PostBeginTransaction: raised after a database transaction is started
PreCommitTransaction: raised before a database transaction is committed
PostCommitTransaction: raised after a database transaction is committed
PreRollbackTransaction: raised before a database transaction is rolled back
PostRollbackTransaction: raised after a database transaction is rolled back
PreLogin: raised before the Session is initialized and the connections acquired.
PostLogin: raised after the Session is initialized and the connections have been acquired.
The following are raised only on a UnitOfWork:
PostAcquireUnitOfWork: raised after a UnitOfWork is acquired
PreCommitUnitOfWork: raised before UnitOfWork is committed
PrepareUnitOfWork: raised after the UnitOfWork has flushed its SQL but before it has committed its transaction
PostCommitUnitOfWork: raised after UnitOfWork is committed
PreReleaseUnitOfWork: raised on a UnitOfWork before it is released
PostReleaseUnitOfWork: raised on a UnitOfWork after it is released
PostResumeUnitOfWork: raised on a unitOfWork after resuming
The following are three-tier events and are raised only in client/server sessions:
PostAcquireClientSession: raised after a client session has been acquired
PreReleaseClientSession: raised before releasing a client session
PostReleaseClientSession: raised after releasing a client session
PostConnect: raised after a new connection is established with the database
PostAcquireConnection: raised after a connection is acquired
PreReleaseConnection: raised before a connection is released
The following are database access events:
OutputParametersDetected: raised after a stored procedure call with output parameters is executed, allowing for a result set and output parameters to be retrieved from a single stored procedure
MoreRowsDetected: raised when a ReadObjectQuery detects more than one row returned from the database; you may want to raise this as a possible error condition in your application
The following examples show how to use the session event manager.
public void addSessionEventListener(SessionEventListener listener)
{
// Register specified listener to receive events from mySession
mySession.getEventManager().addListener(listener);
}
. . .SessionEventAdapter myAdapter = new SessionEventAdapter() {// Listen for PostCommitUnitOfWork eventspublic void postCommitUnitOfWork(SessionEvent event) {// Call my handler routineunitOfWorkCommitted(); } }; mySession.getEventManager().addListener(myAdapter); . . .
Table 1-7 summarizes the most common public methods for the SessionEventManager class and Table 1-8 the SessionEvent class:
For a complete description of all available methods for the SessionEventManager and the SessionEvent class, see the TopLink JavaDocs.
| Element | Default | Method Names |
|---|---|---|
|
Listener registration |
not applicable |
addListener(SessionEventListener listener) removeListener(SessionEventListener listener) |
| Element | Default | Method Names |
|---|---|---|
|
All events |
|
getSession() getEventCode() |
|
Query events |
|
getQuery() getResult() |
|
Output parameters event |
|
getProperty("call") |
Applications normally query and modify the database using session methods such as readObject(), or unit of work methods such as commit(). Internally, these session methods simply create a query object, initialize it with the given parameters, and use it to access the database. Query objects are Java abstractions of SQL calls.
The application can also create custom query objects to use with the session or the descriptor's query manager. Custom query objects can be used to:
readObject() and writeObject()
These techniques are useful for improving application performance or for creating complex queries.
TopLink uses query objects to store information about a database query. The query object stores the following information:
Read queries can be performed using the following query objects:
ReadAllQuery: reads a collection of objects from the database
ReadObjectQuery: reads a single object from the database
ReportQuery: reads information about objects from the database
Write queries can be performed using the following query objects:
DeleteObjectQuery: removes an object from the database
InsertObjectQuery: inserts new objects into the database
UpdateObjectQuery: updates existing objects in the database
WriteObjectQuery: writes either a new or existing object to the database, determining whether to perform an insert or an update
Raw SQL can be performed using the following query objects:
ValueReadQuery: return a single data value; can be used for querying the size of a cursored stream
DirectReadQuery: return a collection of column values; can be used for direct collection queries
DataReadQuery: execute a selecting raw SQL string
DataModifyQuery: execute a non-selecting raw SQL string
Query objects are created by instantiating the object and calling either the setSelectionCriteria(), setSQLString(), or setCall() method to describe how the query is performed. The setSelectionCriteria() method passes an expression to the query object, the setSQLString() method passes raw SQL to the query object, and the setCall() method passes a database call to the query object.
When the application calls executeQuery() to use a query object, it can pass arguments to the query object. The arguments describe which objects should be returned by the query. Arguments can be added to a query using addArgument(). The arguments must be added in the same order that they are passed into the executeQuery() method.
After initialization, the query object may be registered with the session using the addQuery() method. The query must be named when it is registered. Once registered, the application can execute the query using its name.
To execute a query, the Session method executeQuery() is used with optional arguments. This method is overloaded to provide support for up to three arguments or a vector of arguments.
Queries executed with the executeQuery(Query) method do not have to be registered with the session or descriptor.
// Define two expressions that map to the first and last name of the employee.ExpressionBuilder emp = new ExpressionBuilder(); firstNameExpression = emp.get("firstName").equal(emp.getParameter("firstName")); lastNameExpression = emp.get("lastName").equal(emp.getParameter("lastName"));// Create the appropriate query and add the arguments.ReadObjectQuery query = new ReadObjectQuery(); query.setReferenceClass(Employee.class); query.setSelectionCriteria(firstNameExpression.and(lastNameExpression)); query.addArgument("firstName"); query.addArgument("lastName");// Add the query to the session.session.addQuery("getEmployeeWithName", query);// The query can now be executed by referencing its name and providing a first and last name argument.Employee employee = (Employee) session.executeQuery("getEmployeeWithName", "Bob", "Smith");
TopLink supports setting timeout on query objects. A query timeout value can be set in seconds to force a hung or long executing query to abort after the specified time has elapsed. A DatabaseException is thrown following the timeout.
// Create the appropriate query and set timeout limitsReadAddQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setQueryTimeout(2); try{ Vector employees = (Vector) session.executeQuery(query); } catch (DatabaseException ex) {// timeout occurs}
TopLink provides two different query classes for reading objects from the database. ReadAllQuery and ReadObjectQuery objects return persistent classes from the database:
setReferenceClass() method to specify what class should be read from the database.
setSelectionCriteria() to specify an Expression that gives the criteria for the read.
// Returns a Vector of employees whose employee ID is > 100. ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setSelectionCriteria(new ExpressionBuilder.get("id").greaterThan(100)); Vector employees = (Vector) session.executeQuery(query);
// Create the appropriate query and add the arguments. ReadObjectQuery query = new ReadObjectQuery(); query.setReferenceClass(Employee.class); // Add the query to the session. session.addQuery("getAnEmployee", query); // Query for the first employee in the database. Employee employee = (Employee) session.executeQuery("getAnEmployee");
Parameterized SQL can be enabled on individual queries. This is done through the bindAllParameters() and cacheStatement() methods. This causes TopLink to use a prepared statement, binding all of the SQL parameters and caching the prepared statement. If this query is re-executed, the SQL prepare can be avoided (which can improve performance). For more information, see Chapter 6, "Performance Optimization".
After a ReadAllQuery, the resulting collection of objects can be ordered using the addOrdering(), addAscendingOrdering(), and addDescendingOrdering() methods. Attribute names or query keys and expressions can be used to order on.
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.addAscendingOrdering ("lastName"); query.addAscendingOrdering ("firstName"); Vector employees = (Vector) session.executeQuery(query);
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); ExpressionBuilder emp = new ExpressionBuilder(); query.addOrdering (emp.getAllowingNull("address").get("street")); query.addOrdering (emp.getAllowingNull("address").get("city").toUpperCase().descending()); query.addOrdering(emp.getAllowingNull("manager").get("lastName")); Vector employees = (Vector) session.executeQuery(query);
|
Note:
The use of |
By default, a ReadAllQuery returns its result objects in a Vector. The results can be returned in any collection class that implements the Collection or Map interface. For more information, see the Oracle9iAS TopLink Mapping Workbench Reference Guide .
The ReadAllQuery class has a number of methods for cursored stream and scrollable cursor support. For more information, see "Cursored streams and scrollable cursors" .
TopLink supports both joining and batch reading as ways to optimize database reads. Using these techniques, you can dramatically decrease the number of times the database is accessed during a read operation. The methods addJoinedAttribute() and addBatchReadAttribute() are used to configure query optimization. See Chapter 6, "Performance Optimization" for more information.
A maximum rows size can be set on any read query to limit the size of the result set so that, at most, the specified number of objects is returned. This can be used to catch queries that could return an excessive number of objects.
ReadAllQuery query = new ReadObjectQuery(); query.setReferenceClass(Employee.class); query.setMaxRows(5); Vector employees = (Vector) session.executeQuery(query);
TopLink supports querying partial objects. Any read query can return just a subset of the object's attributes instantiated. This can improve read performance when the full object is not required.
Because the partial objects are not full objects, they cannot be cached or edited. In addition, TopLink does not automatically include the primary key information in the partially populated object, so it must be explicitly specified as a partial attribute if you want to re-query or edit the object.
The addPartialAttribute() method is used to configure partial object reading. For more information, see Chapter 6, "Performance Optimization".
A query can also use the refreshIdentityMapResult() method to force the identity map to refresh with the results of the query.
ReadAllQuery query = new ReadObjectQuery();query.setReferenceClass(Employee.class); query.setSelectionCriteria(new ExpressionBuilder().get("lastName").equal("Smith")); query.refreshIdentityMapResult(); Employee employee = (Employee) session.executeQuery(query);
Read query classes that refresh the identity map can also configure the refresh operations to cascade to the object's privately owned parts or all the object's parts. When the refreshObject() method is called on the session, it refreshes the object and all of its privately owned parts. When a read query is created and refreshing is used, only the object's attributes are refreshed; the privately owned parts are not refreshed. To make the read query also refresh the object's parts, the cascadePrivateParts()or cascadeAllParts() methods should be called. Normally, an object should not be refreshed without refreshing its privately owned parts because if its privately owned parts have changed on the database, the object is inconsistent within the database.
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.refreshIdentityMapResult(); query.cascadePrivateParts(); Vector employees = (Vector) session.executeQuery(query);
In-memory querying can be configured at the query level for both read object and read all queries.
Not all expression features are supported in memory. The following in-memory query features are supported:
checkCacheByPrimaryKey() -- default; if a read object query contains an expression that compares more than the primary key, a cache hit can still be obtained through processing the expression against the object in memory
checkCacheThenDatabase() -- any read object query can be configured to query the cache completely before resorting to accessing the database
checkCacheOnly() -- any read object or read all query can be configured to query only the cache and return the result from the cache without accessing the database
conformResultsInUnitOfWork() -- any read object or read all query within the context of a unit of work can be configured to conform the results with the changes to the object made within the unit of work; includes new objects, deleted objects and changed objects
In-memory querying enables you to perform queries on the cache rather than the database. In-memory querying supports the following relationships:
The following table identifies the supported options:
| Type | Supported | Unsupported |
|---|---|---|
|
Comparators |
in(...) |
like(..) |
|
Logical operators |
and(..) |
|
|
Joining |
anyOfAllowingNone(..) |
|
Query results can be conformed in the unit of work across one-to-many as well as a combination of one-to-one and one-to-many relationships. The following is an example of a query across two levels of relationships - one-to-many and one-to-one.
Expression exp = bldr.anyOf("managedEmployees").get("address").get("city").equal("Perth");
In-memory queries may fail for a number of reasons, the most common being that the query expression is too complex to be executed in memory. Other reasons include untriggered valueholders where indirection is being used. All object models using indirection should first trigger valueholders before conforming on the relevant objects. When in-memory queries fail, they generate exceptions.
Exceptions thrown by the conform feature are masked by default. However, TopLink includes an API that allows for exceptions to be thrown rather than masked. The API is:
uow.setShouldThrowConformExceptions(ARGUMENT)
ARGUMENT is an integer with one of the following values:
0 Do not throw conform exceptions (default)
1 Throw only valueholder exceptions
2 Throw all conform exceptions
You can disable the identity map cache update normally performed by a read query by calling the dontMaintainCache() method. This is typically done for performance reasons, such as reading objects that will not be needed later by the application.
This example demonstrates how code reads Employee objects from the database and writes the information to a flat file.
// Reads objects from the employee table and writes them to an employee file. void writeEmployeeTableToFile(String filename, Session session) { Vector employeeObjects; ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setSelectionCriteria(new ExpressionBuilder.get("id").greaterThan(100)); query.dontMaintainCache(); Vector employees = (Vector) session.executeQuery(query); // Write all of the employee data to a file. Employee.writeToFile(filename, employees); }
Read query objects can maintain an internal cache of the objects previously returned by the query. This internal cache is disabled by default. Use the cacheQueryResults() method to enable the internal cache.
ReadObjectQuery query = new ReadObjectQuery(); query.setReferenceClass(Employee.class); query.cacheQueryResults(); // Will read from the database. Employee employee = (Employee) session.executeQuery(query); // Will not read from the database a second time; will read from the query object's cache instead. Employee employee = (Employee) session.executeQuery(query);
A write query can be executed using a WriteObjectQuery instance instead of using the writeObject() method of the session. Likewise, the DeleteObjectQuery, UpdateObjectQuery and InsertObjectQuery objects can be used instead of the respective Session methods.
WriteObjectQuery writeQuery = new WriteObjectQuery(); writeQuery.setObject(domainObject); session.executeQuery(writeQuery);
InsertObjectQuery insertQuery= new InsertObjectQuery(); insertQuery.setObject(domainObject2); session.executeQuery(insertQuery); UpdateObjectQuery updateQuery= new UpdateObjectQuery(); updateQuery.setObject(domainObject2); session.executeQuery(updateQuery); DeleteObjectQuery deleteQuery = new DeleteObjectQuery(); deleteQuery.setObject(domainObject2); session.executeQuery(deleteQuery);
By default, all write queries also write all privately owned parts. To write the object without its privately owned parts, call the dontCascadeParts() method. This is useful for optimization if it is known that only the object's direct attributes have changed. It can also be used to resolve referential integrity dependencies when writing large groups of independent newly-created objects. This is not required if a unit of work is used, because the unit of work internally resolves referential integrity.
// theEmployee is an existing employee read from the database. theEmployee.setFirstName("Bob"); UpdateObjectQuery query = new UpdateObjectQuery(); query.setObject(theEmployee); query.dontCascadeParts(); session.executeQuery(query);
A write query can be configured not to update the identity map cache by calling the dontMaintainCache() method. This is typically done for performance reasons, such as inserting objects that will not be needed later by the application.
The code reads all the objects from a flat file and writes new copies of the objects into a table.
// Reads objects from an employee file and writes them to thevoid createEmployeeTable(String filename, Session session) { Vector employeeObjects; Enumeration employeeEnumeration; Employee employee; InsertObjectQuery query;
employee table.// Read the employee data file.employeeObjects = Employee.parseFromFile(filename); employeeEnumeration = employeeObjects.elements(); while (employeeEnumeration.hasMoreElements()) { employee = (Employee) employeeEnumeration.nextElement(); query = new InsertObjectQuery(); query.setObject(employee); query.dontMaintainCache(); session.executeQuery(query); } }
TopLink provides default querying behavior for each of the read and write operations. This default behavior is sufficient for most applications. If the application requires custom query behavior for a particular persistent class, it can provide its own query objects that are used when one of the database operations is performed. See the Oracle9iAS TopLink Mapping Workbench Reference Guide, for more information.
Applications can define their own custom queries in addition to using the standard read and write operations. If the custom query is specific to a persistent class, it should be registered with that class' descriptor. If the custom query is not specific to a particular class, it should be registered with the session. Registered queries are then executed by calling one of the executeQuery() methods of DatabaseSession or UnitOfWork.
You can combine query redirectors with the TopLink query framework to perform very complex operations, including operations that might not otherwise be possible within the query framework. To create a redirector, implement the oracle.toplink.queryframework interface. The
.QueryRedirectorObject invokeQuery(DatabaseQuery query, DatabaseRow arguments, Session session) method is executed by the query mechanism, which then waits for appropriate results for the Query type to be returned. This method is invoked each time the query is executed.
TopLink provides one pre-implemented redirector, the MethodBasedQueryRedirector. To use this redirector, create a static invoke method on a class, and use the setMethodName(String) API to instruct the query on what method to invoke to get the results for the query.
Table 1-10 and Table 1-11 summarize the most common public methods for query object:
For a complete description of all available methods for query object, see the TopLink JavaDocs.
Query by example allows for queries to be specified by providing sample instances of the persistent objects to be queried. Query by example is an intuitive form of expressing a query, but limited in the complexity of queries that can be defined.
To define a query by example, a Read Object or a Read All Query is provided with a sample persistent object instance and an optional Query By Example Policy. The sample instance contains the data to be queried on and the query by example policy contains optional configuration settings (such as which operators to use and which attributes to ignore or consider).
To create a sample instance (example object), any valid constructor can be used. Only the attributes on which the query is to be based should be set. All other attributes must be not set, or set to null. A default set of values other than null is ignored; these include zero, empty string, and false. To configure other values to be ignored or to force attributes to be included, you must use a query by example policy.
Any attribute that uses a direct mapping can be queried on. One-to-one relationships can also be queried on, including nesting. However, other relationship mappings cannot be queried on. The query is composed using AND to tie the attribute comparisons together.
ReadObjectQuery query = new ReadObjectQuery(); Employee employee = new Employee(); employee.setFirstName("Bob"); employee.setLastName("Smith"); query.setExampleObject(employee); Employee result = (Employee) session.executeQuery(query);
ReadAllQuery query = new ReadAllQuery(); Employee employee = new Employee(); Address address = new Address(); address.setCity("Ottawa"); employee.setAddress(address); query.setExampleObject(employee); Vector results = (Vector) session.executeQuery(query);
Providing a sample instance (example object) allows for a large set of queries to be defined, but is limited to using equals and only ignoring null and default primitive values. The query by example policy allows for a larger set of queries to be defined.
The query by example policy provides the following options:
isNull or notNull for attribute values
To specify a query by example policy, an instance of QueryByExamplePolicy is provided to the query.
ReadAllQuery query = new ReadAllQuery(); Employee employee = new Employee(); employee.setFirstName("B%"); employee.setLastName("S%"); employee.setSalary(0); query.setExampleObject(employee); QueryByExamplePolicy policy = new QueryByExamplePolicy(); policy.addSpecialOperation(String.class, "like"); policy.alwaysIncludeAttribute(Employee.class, "salary"); query.setQueryByExamplePolicy(policy); Vector results = (Vector) session.executeQuery(query);
ReadAllQuery query = new ReadAllQuery(); Employee employee = new Employee(); employee.setFirstName("bob joe fred"); employee.setLastName("smith mc mac"); employee.setSalary(-1); query.setExampleObject(employee); QueryByExamplePolicy policy = new QueryByExamplePolicy(); policy.addSpecialOperation(String.class, "containsAnyKeyWords"); policy.excludeValue(-1); query.setQueryByExamplePolicy(policy); Vector results = (Vector) session.executeQuery(query);
Query by example can be combined with expressions to gain added complexity in the breadth of queries that can be defined. This is done through giving the query both a sample instance (example object) and an expression.
ReadAllQuery query = new ReadAllQuery(); Employee employee = new Employee(); employee.setFirstName("Bob"); employee.setLastName("Smith"); query.setExampleObject(employee); ExpressionBuilder builder = new ExpressionBuilder(); query.setSelectionCriteria(builder.get("salary"). between(100000,200000); Vector results = (Vector) session.executeQuery(query);
Table 1-12 summarizes the most common public methods for query by example:
For a complete description of all available methods for query by example, see the TopLink JavaDocs.
Report query provides developers with a way to access information on a set of objects instead of the objects themselves. It provides the ability to select disperse data from a set of objects and their related objects. Report query supports all database reporting functions and features. Although the report query returns data (not objects), it does allow for this data to be queried and specified at the object level.
The result of a ReportQuery is a collection of ReportQueryResult objects that are similar in structure and behavior to a DatabaseRow or a Hashtable.
Report query features:
ReportQueryResult. This makes it easy to request the real object from a light-weight result
This example reports the total and average salaries for Canadian employees grouped by their city.
import oracle.toplink.queryframework.*; ... ExpressionBuilder emp = new ExpressionBuilder(); ReportQuery query = new ReportQuery(emp); query.setReferenceClass(Employee.class); query.addMaximum("max-salary", emp.get("salary")); query.addAverage("average-salary", emp.get("salary")); query.addAttribute("city", emp.get("address").get("city")); query.setSelectionCriteria(emp.get("address"). get("country").equal("Canada")); query.addOrdering(emp.get("address").get("city")); query.addGrouping(emp.get("address").get("city")); Vector reports = (Vector) session.executeQuery(query);
Table 1-13 summarizes the most common public methods for report query:
For a complete description of all available methods for the report query, see the TopLink JavaDocs.
Working with large collections of persistent objects usually reduces the performance of an application. The two main factors that affect the performance of large collections of persistent objects are:
TopLink provides the CursoredStream and ScrollableCursor classes as a means of dealing more efficiently with large collections returned from queries more efficiently.
CursoredStream is a TopLink version of the standard Java InputStream class and provides forward streaming across a query result of objects.
ScrollableCursor is a TopLink version of the Iterator/ListIterator interface from JDK 1.2. It provides both forward and backward scrolling when used with a JDBC 2.0 compliant driver. ScrollableCursor is best used in JDK 1.2 but can be used in JDK 1.1 and implement the Enumeration interface.
Java streams are used to access files, devices, and collections as a sequence of objects. A stream monitors its internal position; it also provides methods for getting and putting objects at the current position and for advancing the position.
A stream can be thought of as a view of a collection. The collection can be a file, device, or a Vector. A stream provides access to a collection one element at a time, in sequence.
Streams provide access to objects one at a time, making it possible to implement stream classes in which the stream does not contain all of the objects of a collection at the same time. This is a very useful technique you can use to build TopLink applications, because TopLink applications often include queries that generate large which are time-consuming to collect.
Streams allow the query results to be retrieved from tables in smaller numbers as needed, resulting in a performance increase.
Cursored stream support is provided by calling the useCursoredStream() method of the ReadAllQuery class.
CursoredStream stream;ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.useCursoredStream(); stream = (CursoredStream) session.executeQuery(query);
Instead of getting a Vector containing the results of the query, an instance of CursoredStream is returned.
Consider the following two code fragments:
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); Enumeration employeeEnumeration Vector employees = (Vector) session.executeQuery(query); employeeEnumeration = employee.elements(); while (employeeEnumeration.hasMoreElements()) { Employee employee = (Employee) employeeEnumeration.nextElement(); employee.doSomeWork(); }
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.useCursoredStream(); CursoredStream stream = (CursoredStream) session.executeQuery(query); while (! stream.atEnd()) {Employee employee = (Employee) stream.read(); employee.doSomeWork(); stream.releasePrevious();} stream.close();
The first code fragment returns a Vector that contains all the employee objects. If ACME has 10,000 employees, then the Vector contains references to 10,000 Employee objects.
The second code fragment returns a CursoredStream instance rather than a Vector. The CursoredStream collection appears to contain all 10,000 objects, but it initially contains a reference to only the first 10 Employee objects. It will retrieve the rest of the objects of the collection as they are needed. In many cases, the application never needs to read all the objects.
This results in a significant performance increase; most applications start up faster.
The releasePrevious() message is optional. This releases any previously read objects, which frees up system memory. Released read objects are only removed from the cursored stream storage; they are not released from the identity map.
The performance of CursoredStream objects can be customized by providing a threshold and page size to the useCursoredStream(int, int) method.
The threshold specifies the number of objects to initially read into the stream. The default threshold is 10.
The page size specifies the number of elements to be read into the stream when the threshold is reached. Larger page sizes result in faster overall performance, but can introduce delays into the application when each page has to be loaded. The default page size is 5.
A cursored stream used with the dontMaintainCache() option greatly improves performance when dealing with a batch-type operation. A batch operation performs simple operations on large numbers of objects and then discards the objects. Cursored streams create the required objects only as needed, and the dontMaintainCache() option ensures that these transient objects are not cached.
In JDK 1.2, an Iterator interface is defined for iterating over a collection. The ListIterator interface extends the Iterator interface to provide backward scrolling and positioning. ScrollableCursor implements the ListIterator interface to allow scrolling over a large collection result set from the database without requiring to read in all of the data. Scrollable cursors can traverse their contents, both absolutely and relatively. To use the ScrollableCursor object, the underlying JDBC driver must be compatible with JDBC 2.0 specifications.
Scrollable cursored stream support is provided by calling the useScrollableCursor()or the useScrollableCursor method of the
(int threshold)ReadAllQuery class.
ScrollableCursor cursor; ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.useScrollableCursor(); cursor = (ScrollableCursor) session.executeQuery(query);
Instead of getting a Vector containing the results of the query, an instance of ScrollableCursor is returned.
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.useScrollableCursor(); ScrollableCursor cursor = (ScrollableCursor) session.executeQuery(query); while (cursor.hasNext()) {Employee employee = (Employee) cursor.next(); employee.doSomeWork();} cursor.close();
The relative(int i) method advances the row number in relation to the current row by i rows. The absolute(int i) method places the cursor at an absolute row position, 1 being the first row. In addition to the absolute(int i) and relative(int i) methods, scrollable cursors provide several other means of moving through their contents.
// Traversing a scrollable cursor. ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.useScrollableCursor(); ScrollableCursor cursor = (ScrollableCursor) session.executeQuery(query); if (cursor.isAfterLast()) { while (cursor.hasPrevious()) { System.out.println(cursor.previous().toString()); } } cursor.close();
The hasPrevious() and previous() methods are provided to traverse from the last row towards the first and retrieve the object from the row. The afterLast() method places the cursor after the last row in the result set. Therefore, the first call to previous()places the cursor at the last row and returns that object.
TopLink supports generating SQL for all database operations and provides an expression framework that supports defining simple and complex queries at the object level. Occasionally, your application may require a very complex query using custom SQL or the use of a stored procedure on the database. TopLink allows for all database operations to be customized through SQL or stored procedure calls.
The customization of descriptor and mapping database operations is discussed in Chapter 3, "Working with Enterprise JavaBeans", Chapter 5, "SDK for XML and Non-relational Database Access", and Chapter 6, "Performance Optimization".
You can provide an SQL string to any query instead of an expression. In this case, the SQL string must return all of the data required to build an instance of the class being queried. The SQL string can be a complex SQL query, or a stored procedure call. You can invoke SQL queries through the session read methods, or through a read query instance.
Employee employee = (Employee) session.readObject(Employee.class, "SELECT * FROM EMPLOYEE WHERE EMP_ID = 44");
ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setSQLString("EXEC PROC READ_ALL_EMPS"); Vector employees = (Vector) session.executeQuery(query);
TopLink provides the following data-level queries that you can use to query or modify data (not objects) in the database:
DataReadQuery -- used for reading rows of data
DirectReadQuery -- used for reading a single column of data
ValueReadQuery -- used for reading a single value of data
DataModifyQuery -- used for modifying data
Vector rows = session.executeSQL("SELECT USER, SYSDATE FROM DUAL");
DataModifyQuery query = new DataModifyQuery(); query.setSQLString("USE SALESDATABASE"); session.executeQuery(query);
DirectReadQuery query = new DirectReadQuery(); query.setSQLString("SELECT EMP_ID FROM EMPLOYEE"); Vector ids = (Vector) session.executeQuery(query);
You can provide a StoredProcedureCall object to any query instead of an expression or SQL string. The procedure must return all of the data required to build an instance of the class being queried.
Output parameters can be used to define a read object query if they return the correct fields to build the object. The StoredProcedureCall object allows for output parameters to be used. Output parameters allow for additional information to be returned from a stored procedure. Some databases do not support returning result sets from stored procedures, so output parameters are the only way to return data. Sybase and SQL Server do support returning result sets from stored procedures so output parameters are normally not required for these databases.
StoredProcedureCall call = new StoredProcedureCall(); call.setProcedureName("CHECK_VALID_POSTAL_CODE"); call.addNamedArgument("POSTAL_CODE"); call.addNamedOutputArgument("IS_VALID"); ValueReadQuery query = new ValueReadQuery(); query.setCall(call); query.addArgument("POSTAL_CODE"); Vector parameters = new Vector(); parameters.addElement("L5J1H5"); Number isValid = (Number) session.executeQuery(query,parameters);
Oracle does not support returning a result set from a stored procedure, but does support returning a cursor as an output parameter. When using the Oracle JDBC drivers, you can configure a StoredProcedureCall object to pass a cursor to TopLink as a normal result set.
StoredProcedureCall call = new StoredProcedureCall(); call.setProcedureName("READ_ALL_EMPLOYEES"); call.useNamedCursorOutputAsResultSet("RESULT_CURSOR"); ReadAllQuery query = new ReadAllQuery(); query.setReferenceClass(Employee.class); query.setCall(call); Vector employees = (Vector) session.executeQuery(query);
You can use stored procedures for a TopLink operation that does not allow for output parameter to be returned. When the stored procedure returns an error code indicating that the application wants to check for an error condition, TopLink raises the session event OutputParametersDetected to allow the application to process the output parameters.
StoredProcedureCall call = new StoredProcedureCall(); call.setProcedureName("READ_EMPLOYEE"); call.addNamedArgument("EMP_ID"); call.addNamedOutputArgument("ERROR_CODE"); ReadObjectQuery query = new ReadObjectQuery(); query.setCall(call); query.addArgument("EMP_ID"); ErrorCodeListener listener = new ErrorCodeListener(); session.getEventManager().addListener(listener); Vector args = new Vector(); args.addElement(new Integer(44)); Employee employee = (Employee) session.executeQuery(query, args);
Table 1-14 summarizes the most common public methods for the stored procedure call:
For a complete description of all available methods for the stored procedure call, see the TopLink JavaDocs.
|
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|