Release 2 (9.2)
Part Number A96579-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Directory Service Integration and Deployment Guide Release 2 (9.2) Part Number A96579-01 |
|
This chapter lays a foundation for understanding LDAP-compliant directories. It begins by describing the function of directories--be they paper based or electronic--proceeds through a definition of the LDAP protocol, version 3, and ends by identifying the fundamental components of an online directory.
The chapter covers the following topics:
A directory is an index or list that helps people find information. The directories most familiar to us are offline, usually paper based, resources like telephone books and yellow pages, merchandise catalogs, card catalogs in libraries, and dictionaries.
Online directories are computer databases that serve much the same function that offline directories do, but add the following benefits.
Online directories can organize data in many different ways, allowing users to specify different search criteria.
Online directories centralize data, making it easier to manage and to restrict access to it.
Dynamism
Online directories can be updated frequently.
Online directories enable you to globally store user profiles, the color settings on your personal computer, for instance.
These added benefits make online directories ideal for storing critical information at large companies. Typical entries in an online directory include employee names, enterprise roles, e-mail addresses, and information about printers, conference rooms and other company resources.
It is easy to confuse a directory with a relational database, because a directory is, after all, a special kind of database. But there are some significant differences between the two, as Table 2-1 shows.
A directory is sometimes read 1,000 to 10,000 times more than it is written. That is because it stores information that is updated infrequently, but accessed constantly--information such as user IDs, e-mail addresses, and catalog data. Relational databases by contrast serve as repositories for data that changes frequently, such sales orders, salaries, and student grades. As a result, they are written to frequently, but read infrequently.
Directory objects are generally small because they must be representable in an attribute format--for example, surname=hay. This feature optimizes the directory for searching. Databases by contrast can accommodate large objects.
Directory applications expect at all times to see the same information throughout the deployment environment--regardless of which server they are querying. If a queried server does not store the information locally, then it must either retrieve the information or point the client application to it transparently. A relational database, while it can be distributed, usually resides on a particular server.
Just as the small size of directory objects optimizes the directory for searching, so too does the way the objects are stored. Represented as a discrete entry in a directory information tree, each piece of directory data can be retrieved quickly. A database search operation, on the other hand, is more suitable for relational transactions--that is, transactions that encompass several pieces of data and several tables.
Common directory applications include the following:
These might serve as a repository not only for phone numbers, but for e-mail addresses and employee names.
E-mail servers, for instance, require access to e-mail addresses, user names, mailbox locations, and routing and protocol information. These data categories are all suitable for directory storage.
These require detailed information about people, information that is easily stored in a directory. This information consists of employee identification numbers, birth dates, salary levels, hire dates, and job titles.
The primary benefit of online directories is that they can centralize the storage of information. This feature is critical in a distributed database environment, and it cannot be accomplished without a common standard that governs how enterprise applications interact with directories. Without such a standard, large companies might have to deploy hundreds of application-specific directories, all equipped with their own protocols. Collectively, these application-specific directories pose three major problems:
These problems become apparent when, for example, an employee leaves a company or transfers to another department. When this happens, network administrators might have to disable multiple accounts on multiple databases.The time required to effect these changes and the difficulty involved in synchronizing them across databases is an administrative burden and also a security risk.
Fortunately, Lightweight Directory Access Protocol (LDAP) eases the burden of managing application-specific directories.
LDAP is a standard, extensible directory access protocol that enables directory clients and servers to interact using a common language. LDAP, as the name suggests, is a lightweight implementation the X.500 Directory Access Protocol (DAP), first published in 1990. The X.500 protocol grew out of a need for a directory model that bridged applications and operating systems. However, it proved cumbersome, partly because it runs over the OSI networking stack. LDAP by contrast runs directly over TCP/IP, which is popular, fast, simple, and relatively inexpensive to implement.
This section contains the following topics:
LDAP simplifies directory management in the following ways.
The most recent version of the LDAP protocol is version 3, which in December 1997 was approved as an Internet standard. Version 3 improves on version 2 in fìve ways.
LDAP version 3 supports UTF-8, an encoding of Unicode, the 16-bit encoding standard used to store and retrieve information in any language.
LDAP 3 supports knowledge references, LDAP URLs that refer users to other directory servers if the requested information does not reside on the server being queried. This feature enables a directory to be partitioned--that is, distributed across different servers.
LDAP version 3 supports SASL (Simple Authentication and Security Layer), an Internet standard that enables clients to choose the authentication protocols that they want to use. It also supports Transport Layer Security (TLS), a standardized version of Secure Sockets Layer (SSL), which encrypts data that passes between client and server.
LDAP version 3 enables new LDAP operations to be defined, uses mechanisms called controls to modify existing operations, and permits new authentication methods through SASL.
LDAP version 3 servers publish the versions of the LDAP protocol that they support and their schemas in a directory entry called the root DSE (directory server-specific entry). This feature facilitates interaction with other LDAP clients and servers.
.| See Also:
RFCs (Request for Comments) 2251-2256 on the IETF Web site at |
The C LDAP API, introduced with LDAP version 2, provides a standard API for accessing and modifying directory entries from the command line. The API offers the programmer of an LDAP-enabled application a set of functions that covers every LDAP protocol operation.
APIs for the Java and Perl programming languages are also available.
See Also:
|
Lightweight Directory Interchange Format (LDIF) is a text-based format used to describe and modify--change, add, and delete--directory entries. In the latter capacity, it provides input to command-line utilities.
The two LDIF files immediately following represent a directory entry for a printer. The string in the first line of each entry is the entry's name, called a distinguished name. The difference between the files is that the first describes the entry--that is, the format is an index of the information that the entry contains. The second, when used as input to the command-line utility ldapmodify, adds information about the speed of the printer.
Description
dn: cn=LaserPrinter1, ou=Devices, dc=acme,dc=comobjectclass: topobjectclass: printerobjectclass: epsonPrintercn: LaserPrinter1resolution: 600description: In room 407
Modification
dn: cn=LaserPrinter1, ou=Devices, dc=acme, dc=comchangetype: modifyadd: pagesPerMinutepagesPerMinute: 6
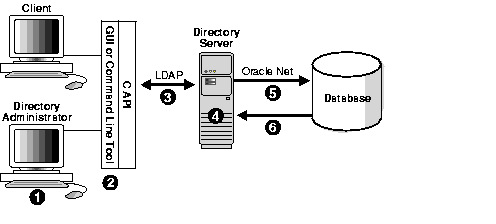
To visualize how information is retrieved from an LDAP-compliant directory, consider how the process works in Oracle Internet Directory:
Figure 2-1 illustrates the process.
This section describes the information that a directory contains. It explains how this information is organized and who gains access to it. The section contains the following topics:
In a directory, each collection of information about an object is called an entry. This object may be a person, but it can also be a printer or other shared resource, a department within a company, or even the company itself.
To name it and to identify its location in the directory hierarchy, each entry is assigned a unique distinguished name (DN). The DN of an entry consists of the entry itself, known as the relative distinguished name (RDN), and its parent entries, connected in ascending order, from the entry itself up to the root (top) entry in the tree. Collectively, these entries form a directory information tree (DIT) such as the one shown in Figure 2-2. A directory server uses this tree to determine what information to extract from a relational, or other, database.
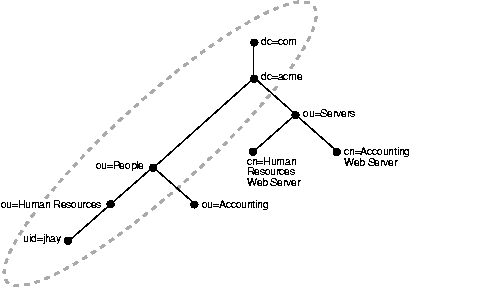
Figure 2-2 represents a portion of a DIT belonging to the company acme, designated by the entry dc (domain component) =acme, dc=com. The highlighted DN uid=jhay, ou=Human Resources, ou=People, dc=acme, dc=com is an entry within the DIT.
This entry represents the user ID (uid) for a person belonging to the organizational unit (ou) Human Resources in the company acme.
The format of a DN places the lowest hierarchical component of the name, the RDN, to the extreme left. In the example, this RDN is uid=jhay.
An entry consists of a set of attributes, each describing a unique feature of the entry. An attribute consists of two components, an attribute type and one, or sometimes more, values. Table 2-2 lists, in LDIF notation, some of the attributes that the entry uid=jhay, ou=Human Resources, ou=People, dc=acme, dc=com might contain.
| Attribute Type | Attribute Value |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Note that LDAP permits some of the attributes listed to be abbreviated. The attribute cn could just as easily have been written as commonName, and the attribute sn as surname.
Attributes take two forms: user and operational. The former are application specific and can be retrieved and modified by the user. The latter are used to control directory operations and are generally not available to the user. Examples of user attributes include commonName, surname, telephoneNumber, and mail. Examples of operational attributes include the following:
modifyTimeStamp--the date and time an entry was last changedmodifiersName--the DN that last made the changesupportedLDAPVersion--the LDAP versions supported by the directory server.Under LDAP rules, each attribute type must conform to a particular syntax and associated matching rule. A syntax determines the form that an attribute value takes. A matching rule specifies how attribute values are compared in directory searches.
Table 2-3 lists common syntaxes and associated matching rules defined by the X.500 standard.
|
Note: Your directory might use different names for syntaxes and matching rules depending upon the kind of schema format that it uses to describe entries. |
Suppose that you are searching the directory for an employee named Kit Karston. Following X.500 rules, the syntax used to represent this name is DirectoryString. The matching rule can be either caseIgnoreMatch or caseExactMatch. If it is the former, you might enter the name as (cn=kit karston) or (cn=kitKarston) or even (cn= kit karston). In all cases, the directory returns the name.
In addition to containing multiple values, attributes can store language codes. This feature is useful for accessing text in the many languages that LDAP supports. For example, the attribute cn;lang-ja represents a common name in Japanese. Note that a semicolon separates the attribute type and the value.
You can also specify that the directory return attributes in a given dialect. For example, the language code lang-en-GB, returns attribute values in British English.
An object class is a collection of attributes that you use to define an entry. Some of these attributes are mandatory; others are optional.
If, for example, you assign the LDAP-defined object class organizationalPerson to the entry uid=jhay, ou=Human Resources, ou=People, dc=acme, dc=com, you must include commonName (cn) and surname (sn) as attributes for the entry. Rules for the object class organizationalPerson also allow you to include the attributes telephoneNumber, uid, and userPassword, but these are not required.
Excluding optional attributes, the entry preceding might look something like this in LDIF notation:
dn: uid=jhay, ou=Human Resources, ou=People, dc=acme, dc=comobjectclass: topobjectclass: personobjectclass: organizationalPersoncn: John Haycn: Jack Haysn: Hay
Note that three object classes are present in the entry, an indication that object subclasses are represented. In this case, organizationalPerson is a subclass of the object class person, which is a subclass of the object class, top.
In addition to defining the attributes of an entry, object classes provide a way of locating a related group of entries. To restrict your directory search to printers housed in a certain area of your organization, for instance, your directory access GUI might construct an LDAP search filter that uses an AND operator to combine the object class printer with the attribute description, which might contain a value for the location of the printers.
| See Also:
"Creating New Object Classes and Redefining Old Ones", for a discussion of object subclasses |
Object classes take three forms:
Most of the object classes in a directory are structural, because they define what an entry is. They also impose rules on the entries that are stored beneath them. For example, the object class organization (o) might require that all objects stored beneath it belong to the object class organizational units (ou). Other examples of structural object classes are person, printer, and groupOfNames.
LDAP rules require each entry to belong to one, and only one, structural class, but an entry can also belong to one or more auxiliary classes. An auxiliary class, as its name suggests, is used to add attributes to entries that are already defined by a structural object class. Note that an auxiliary class cannot stand on its own in an entry. The entry must also contain a structural object class. Unlike structural object classes, auxiliary classes place no restrictions on where an entry is stored.
The third type of object class, abstract, is a class whose primary function is to determine the structure of an LDAP directory. The object class top, for example, is the root object class from which all structural object classes are derived. It contains one mandatory attribute, objectClass, and because all entries inherit its attributes, it ensures that these entries are defined by an object class. An abstract object class cannot stand alone in an entry. The entry must also contain a structural object class.
|
Note: Some directory vendors may not distinguish between object class types and therefore may not enforce structure rules. |
LDAP enables you to create entirely new structural object classes and attributes to accommodate new objects in a directory. The challenge in creating new object classes is to come up with unique names because object class and attribute namespaces are flat.
A far more common--and easier--practice is to create subclasses of existing classes, which then become superclasses. This feature provides a way of adding mandatory, as well as optional attributes to a predefined object class. A subclass inherits all of the attributes of a superclass, and because an entry can contain more than one object class, it can inherit numerous attributes.
The object class printer, for example, might have the object class epsonPrinter as a subclass to provide information about a specific kind of printer that an organization uses.
Auxiliary object classes provide the easiest, most flexible method for redefining existing directory entries because you are not required to subclass them to specific object classes and can use them to add attributes to any number of entries. An object class that can be used to add uniform resource locaters (URLs) to any directory entry is a good example of an auxiliary object class.
A naming context is a DIT that resides entirely on one server. It can consist of a single entry, a subtree, or even the entire DIT. Any directory entry can serve as the root of a naming context as long as the entries below it are contiguous with it. These subordinate entries can be either leaf entries or naming contexts in their own right.
Some, but not all, of the naming and non-naming contexts in Figure 2-3 are highlighted. Naming contexts are indicated by solid-line circles, non-naming contexts by dotted-line circles.
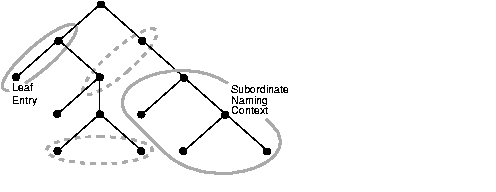
To enable you to specify specific naming contexts as search targets, LDAP enables you to publish them in a directory's root DSE (directory server-specific entry). You publish a naming context by assigning the root, or topmost entry, of the context as a value to an attribute called namingContexts.
The schema of a directory comprises the metadata that determine what objects a directory can store. The metadata of a directory are its object classes, attribute types, attribute syntaxes, and matching rules.
The schema of a directory typically amounts to dozens of object classes, hundreds of attributes, and a dozen or fewer syntaxes.
To facilitate directory navigation and modification, LDAP version 3 requires directories to publish their schema in an operational attribute called subschemaSubentry, located in a directory server's root DSE (directory server-specific entry). This attribute is analogous to the data dictionary of a relational database. It is in the entry subschemaSubentry that you add new object classes and attributes and redefine existing object classes.
| See Also:
Appendix A, "Oracle-Specific LDAP Schema Extensions" |
Gaining access to a directory is a two-part process that consists of using one or more authentication methods to establish the identity of a directory client and then using access control lists (ACLs) to determine what kind of information clients can access and what they can do with it once they have accessed it.
LDAP version 3 supports four levels of authentication:
Users log in without providing a user name and password, but once they are logged on, they may have limited privileges.
Clients supply a user name, in the form of a DN, and an unprotected password--that is, a password sent in clear text.
Users supply a user name and a password, which is protected using Secure Sockets Layer (SSL), a public key encryption technology.
This method provides maximum protection because it supplements public key encryption with certificates that clients use to authenticate themselves. Because they are issued by a certificate authority, certificates provide a considerable degree of certainty about a client's identity.
Once you gain access to a directory, a mechanism called an access control list (ACL) determines what kind of information you are able to retrieve and modify.
An ACL consists of one or more operational attributes called ACIs (access control items). These ACIs specify permissions for an entry. Theoretically, you can place an ACL anywhere in the directory hierarchy, down to the level of an entry. In reality, ACL placement is subject to whatever restrictions your directory software imposes. An ACL specifies three things:
The following example shows the format of an ACL that is constructed using the command line tool ldapmodify. This ACL is based on the Oracle Internet Directory attribute orclEntryLevelACI, which sets access control rules for one entry only.
dn: uid=jhay, ou=Human Resources, ou=People, dc=acme, dc=comchangetype: modifyreplace: orclentrylevelaci:orclentrylevelaci: access to entryby dn= "cn=directory manager, dc=acme, dc=com" (browse, add, delete)by * (browse, noadd, nodelete)orclentrylevelaci: access to attr=(*)by dn= "cn=directory manager, dc=acme, dc=com" (search, read, write, compare)by * (search, read, nowrite, nocompare)
The ACL above consists of two ACIs (in boldface) that set access control rules for the entry uid=jhay, ou=Human Resources, ou=People, dc=acme, dc=com. These ACIs give directory managers falling within the domain dc=acme, dc=com read and modify privileges over the entry and its attributes. They give all other users, designated by the wildcard "*" read but not write privileges. The entity assigned privileges by an ACI can be a privilege group as well as an individual.
A directory stores all information pertaining to Oracle software under one or more entries called an Oracle Context, which has an RDN of cn=OracleContext. You can create an Oracle Context under any entry in the DIT. To help you, Oracle Net Configuration Assistant, an Oracle tool for configuring directory access, displays a list of published entries as suggested locations. If you are using Oracle Internet Directory, a starter Oracle Context is created when the directory is installed.
A starter Oracle Context, as Figure 2-4 illustrates, is a directory subtree that, at the top level, consists of four containers--Products, Groups, Services, and Computers--and entries for three of the administrative groups applicable to the entire context. The only product-related entries installed at this stage are entries for enterprise user security and Enterprise Security Manager, a GUI tool.
After using Oracle Net Configuration Assistant to configure access to a directory, you can use another tool, Database Configuration Assistant, to register databases. Registration adds entries for database servers and their associated Oracle Net connect descriptors.
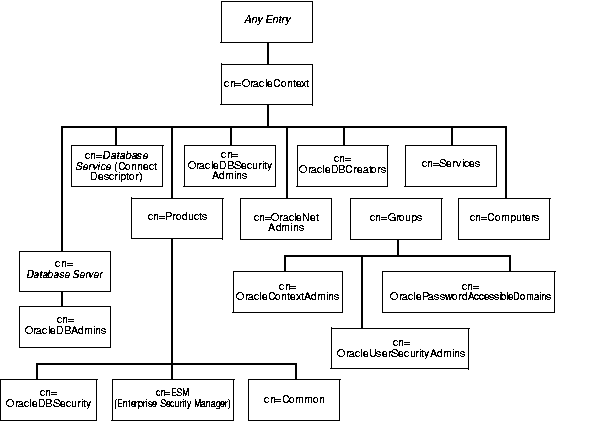
Table 2-4 shows the contents of the four containers represented in Figure 2-4.
See Also:
|
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|

