Release 2 (9.2)
Part Number A96520-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Warehousing Guide Release 2 (9.2) Part Number A96520-01 |
|
This chapter explains some of the hardware and I/O issues in a data warehousing environment and includes the following topics:
Data warehouses are normally very concerned with I/O performance. This is in contrast to OLTP systems, where the potential bottleneck depends on user workload and application access patterns. When a system is constrained by I/O capabilities, it is I/O bound, or has an I/O bottleneck. When a system is constrained by having limited CPU resources, it is CPU bound, or has a CPU bottleneck.
Database architects frequently use RAID (Redundant Arrays of Inexpensive Disks) systems to overcome I/O bottlenecks and to provide higher availability. RAID can be implemented in several levels, ranging from 0 to 7. Many hardware vendors have enhanced these basic levels to lessen the impact of some of the original restrictions at a given RAID level. The most common RAID levels are discussed later in this chapter.
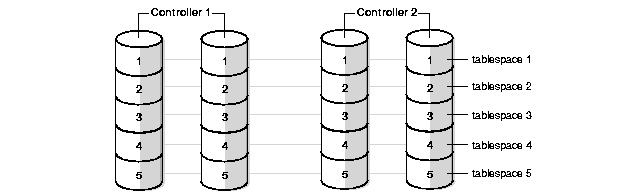
To avoid I/O bottlenecks during parallel processing or concurrent query access, all tablespaces accessed by parallel operations should be striped. Striping divides the data of a large table into small portions and stores them on separate datafiles on separate disks. As shown in Figure 4-1, tablespaces should always stripe over at least as many devices as CPUs. In this example, there are four CPUs, two controllers, and five devices containing tablespaces.
| See Also:
Oracle9i Database Concepts for further details about disk striping |
You should stripe tablespaces for tables, indexes, rollback segments, and temporary tablespaces. You must also spread the devices over controllers, I/O channels, and internal buses. To make striping effective, you must make sure that enough controllers and other I/O components are available to support the bandwidth of parallel data movement into and out of the striped tablespaces.
You can use RAID systems or you can perform striping manually through careful data file allocation to tablespaces.
The striping of data across physical drives has several consequences besides balancing I/O. One additional advantage is that logical files can be created that are larger than the maximum size usually supported by an operating system. There are disadvantages however. Striping means that it is no longer possible to locate a single datafile on a specific physical drive. This can cause the loss of some application tuning capabilities. Also, it can cause database recovery to be more time-consuming. If a single physical disk in a RAID array needs recovery, all the disks that are part of that logical RAID device must be involved in the recovery.
Automatic striping is usually flexible and easy to manage. It supports many scenarios such as multiple users running sequentially or as single users running in parallel. Two main advantages make automatic striping preferable to manual striping, unless the system is very small or availability is the main concern:
DB_BLOCK_SIZE * MULTIBLOCK_READ_COUNT), which should enable this operation to reach the maximum I/O throughput for your platform. This maximum is in general limited by the number of controllers or I/O buses of the platform, not by the number of disks (unless you have a small configuration or are using large disks).Oracle Corporation recommends using a large stripe size of at least 64 KB. Stripe size must be at least as large as the I/O size. If stripe size is larger than I/O size by a factor of two or four, then trade-offs may arise. The large stripe size can be advantageous because it lets the system perform more sequential operations on each disk; it decreases the number of seeks on disk. Another advantage of large stripe sizes is that more users can work on the system without affecting each other. The disadvantage is that large stripes reduce the I/O parallelism, so fewer disks are simultaneously active. If you encounter problems, increase the I/O size of scan operations (for example, from 64 KB to 128 KB), instead of changing the stripe size. The maximum I/O size is platform-specific (in a range, for example, of 64 KB to 1 MB).
With automatic striping, from a performance standpoint, the best layout is to stripe data, indexes, and temporary tablespaces across all the disks of your platform. This layout is also appropriate when you have little information about system usage. To increase availability, it may be more practical to stripe over fewer disks to prevent a single disk value from affecting the entire data warehouse. However, for better performance, it is crucial to stripe all objects over multiple disks. In this way, maximum I/O performance (both in terms of throughput and in number of I/Os per second) can be reached when one object is accessed by a parallel operation. If multiple objects are accessed at the same time (as in a multiuser configuration), striping automatically limits the contention.
You can use manual striping on all platforms. To do this, add multiple files to each tablespace, with each file on a separate disk. If you use manual striping correctly, your system's performance improves significantly. However, you should be aware of several drawbacks that can adversely affect performance if you do not stripe correctly.
When using manual striping, the degree of parallelism (DOP) is more a function of the number of disks than of the number of CPUs. First, it is necessary to have one server process for each datafile to drive all the disks and limit the risk of experiencing I/O bottlenecks. Second, manual striping is very sensitive to datafile size skew, which can affect the scalability of parallel scan operations. Third, manual striping requires more planning and set-up effort than automatic striping.
|
Note: Oracle Corporation recommends that you choose automatic striping unless you have a clear reason not to. |
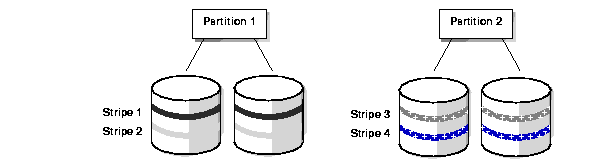
Local striping, which applies only to partitioned tables and indexes, is a form of non-overlapping, disk-to-partition striping. Each partition has its own set of disks and files, as illustrated in Figure 4-2. Disk access does not overlap, nor do files.
An advantage of local striping is that if one disk fails, it does not affect other partitions. Moreover, you still have some striping even if you have data in only one partition.
A disadvantage of local striping is that you need many disks to implement it--each partition requires multiple disks of its own. Another major disadvantage is that when partitions are reduced to a few or even a single partition, the system retains limited I/O bandwidth. As a result, local striping is not optimal for parallel operations. For this reason, consider local striping only if your main concern is availability, rather than parallel execution.
Global striping, illustrated in Figure 4-3, entails overlapping disks and partitions.
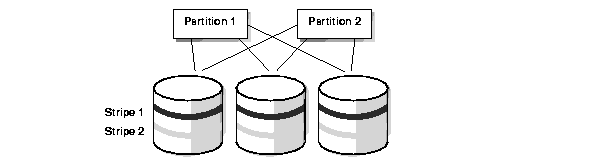
Global striping is advantageous if you have partition pruning and need to access data in only one partition. Spreading the data in that partition across many disks improves performance for parallel execution operations. A disadvantage of global striping is that if one disk fails, all partitions are affected if the disks are not mirrored.
| See Also:
Oracle9i Database Concepts for information on disk striping and partitioning. For MPP systems, see your operating system specific Oracle documentation regarding the advisability of disabling disk affinity when using operating system striping |
Two considerations arise when analyzing striping issues for your applications. First, consider the cardinality of the relationships among the objects in a storage system. Second, consider what you can optimize in your striping effort: full table scans, general tablespace availability, partition scans, or some combinations of these goals. Cardinality and optimization are discussed in the following section.
To analyze striping, consider the relationships illustrated in Figure 4-4.

Figure 4-4 shows the cardinality of the relationships among objects in a typical Oracle storage system. For every table there may be:
You can stripe an object across devices to achieve one of three goals:
To attain both Goals 1 and 2 (having the table reside on many devices, with the highest possible availability), maximize the number of partitions p and minimize the number of partitions for each tablespace s.
To maximize Goal 1 but with minimal intra-partition parallelism, place each partition in its own tablespace. Do not used striped files, and use one file for each tablespace.
To minimize Goal 2 and thereby minimize availability, set f and n equal to 1. When you minimize availability, you maximize intra-partition parallelism. Goal 3 conflicts with Goal 2 because you cannot simultaneously maximize the formula for Goal 3 and minimize the formula for Goal 2. You must compromise to achieve some of the benefits of both goals.
Striping Goal 1: Optimize Full Table Scans
Having a table reside on many devices ensures scalable full table scans.
To calculate the optimal number of devices for each table, use this formula:
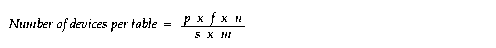
You can do this by having t partitions, with every partition in its own tablespace, if every tablespace has one file, and these files are not striped.

If the table is not partitioned, but is in one tablespace in one file, stripe it over n devices.

There are a maximum of t partitions, every partition in its own tablespace, f files in each tablespace, each tablespace on a striped device:

Striping Goal 2: Optimize Availability
Restricting each tablespace to a small number of devices and having as many partitions as possible helps you achieve high availability.
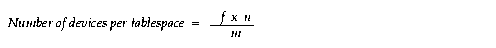
Availability is maximized when f = n = m = 1 and p is much greater than 1.
Striping Goal 3: Optimize Partition Scans
Achieving intra-partition parallelism is advantageous because partition scans are scalable. To do this, place each partition on many devices.
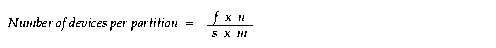
Partitions can reside in a tablespace that can have many files. You can have either a striped file or many files for each tablespace.
RAID systems, also called disk arrays, can be hardware- or software-based systems. The difference between the two is how CPU processing of I/O requests is handled. In software-based RAID systems, the operating system or an application level handles the I/O request, while in hardware-based RAID systems, disk controllers handle I/O requests. RAID usage is transparent to Oracle. All the features specific to a given RAID configuration are handled by the operating system and Oracle does not need to worry about them.
Primary logical database structures have different access patterns during read and write operations. Therefore, different RAID implementations will be better suited for these structures. The purpose of this chapter is to discuss some of the basic decisions you must make when designing the physical layout of your data warehouse implementation. It is not meant as a replacement for operating system and storage documentation or a consultant's analysis of your I/O requirements.
| See Also:
Oracle9i Database Performance Tuning Guide and Reference for more information regarding RAID |
There are advantages and disadvantages to using RAID, and those depend on the RAID level under consideration and the specific system in question. The most common configurations in data warehouses are:
RAID 0 is a non-redundant disk array, so there will be data loss with any disk failure. If something on the disk becomes corrupted, you cannot restore or recalculate that data. RAID 0 provides the best write throughput performance because it never updates redundant information. Read throughput is also quite good, but you can improve it by combining RAID 0 with RAID 1.
Oracle does not recommend using RAID 0 systems without RAID 1 because the loss of one disk in the array will affect the complete system and make it unavailable. RAID 0 systems are used mainly in environments where performance and capacity are the primary concerns rather than availability.
RAID 1 provides full data redundancy by complete mirroring of all files. If a disk failure occurs, the mirrored copy is used to transparently service the request. RAID 1 mirroring requires twice as much disk space as there is data. In general, RAID 1 is most useful for systems where complete redundancy of data is required and disk space is not an issue. For large datafiles or systems with less disk space, RAID 1 may not be feasible, because it requires twice as much disk space as there is data. Writes under RAID 1 are no faster and no slower than usual. Reading data can be faster than on a single disk because the system can choose to read the data from the disk that can respond faster.
RAID 0+1 offers the best performance of all RAID systems, but costs the most because you double the number of drives. Basically, it combines the performance of RAID 0 and the fault tolerance of RAID 1. You should consider RAID 0+1 for datafiles with high write rates, for example, table datafiles, and online and archived redo log files.
Striping affects media recovery. Loss of a disk usually means loss of access to all objects stored on that disk. If all datafiles in a database are striped over all disks, then loss of any disk stops the entire database. Furthermore, you may need to restore all these database files from backups, even if each file has only a small fraction of its total data stored on the failed disk.
Often, the same system that provides striping also provides mirroring. With the declining price of disks, mirroring can provide an effective supplement to, but not a substitute for, backups and log archives. Mirroring can help your system recover from disk failures more quickly than using a backup, but mirroring is not as robust. Mirroring does not protect against software faults and other problems against which an independent backup would protect your system.
You can effectively use mirroring if you are able to reload read-only data from the original source tapes. If you have a disk failure, restoring data from backups can involve lengthy downtime, whereas restoring from a mirrored disk enables your system to get back online quickly or even stay online while the crashed disk is replaced and resynchronized.
RAID 5 systems provide redundancy for the original data while storing parity information as well. The parity information is striped over all disks in the system to avoid a single disk as a bottleneck during write operations. The I/O throughput of RAID 5 systems depends upon the implementation and the striping size. For a typical RAID 5 system, the throughput is normally lower than RAID 0 + 1 configurations. In particular, the performance for high concurrent write operations such as parallel load can be poor.
Many vendors use memory (as battery-backed cache) in front of the disks to increase throughput and to become comparable to RAID 0+1. Contact your disk array vendor for specific details.
A data warehouse's requirements are at many levels, and resolving a problem at one level can cause problems with another. For example, resolving a problem with query performance during the ETL process can affect load performance. You cannot simply maximize query performance at the expense of an unrealistic load time. If you do, your implementation will fail. In addition, a particular process is dependent upon the warehouse's architecture. If you decide to change something in your system, it can cause performance to become unacceptable in another part of the warehousing process. An example of this is switching from using database files to flat files during the loading process. Flat files can have different read performance.
This chapter is not meant as a replacement for operating system and storage documentation. Your system's requirements will require detailed analysis prior to implementation. Only a detailed data warehouse architecture and I/O analysis will help you when deciding hardware and I/O strategies.
| See Also:
Oracle9i Database Performance Tuning Guide and Reference for details regarding how to analyze I/O requirements |
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

