Release 9.2
Part Number A96518-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle Text Reference Release 9.2 Part Number A96518-01 |
|
This chapter describes the various elements you can use to create your Oracle Text index.
The following topics are discussed in this chapter:
When you use CREATE INDEX to create an index or ALTER INDEX to manage an index, you can optionally specify indexing preferences, stoplists, and section groups in the parameter string. Specifying a preference, stoplist, or section group answers one of the following questions about the way Oracle indexes text:
This chapter describes how to set each preference. You enable an option by creating a preference with one of the types described in this chapter.
For example, to specify that your documents are stored in external files, you can create a datastore preference called mydatastore using the FILE_DATASTORE type. You specify mydatastore as the datastore preference in the parameter clause of CREATE INDEX.
To create a datastore, lexer, filter, wordlist, or storage preference, you use the CTX_DDL.CREATE_PREFERENCE procedure and specify one of the types described in this chapter. For some types, you can also set attributes with the CTX_DDL.SET_ATTRIBUTE procedure.
To create a stoplists, use CTX_DDL.CREATE_STOPLIST. You can add stopwords to a stoplist with CTX_DDL.ADD_STOPWORD.
To create section groups, use CTX_DDL.CREATE_SECTION_GROUP and specify a section group type. You can add sections to section groups with CTX_DDL. ADD_ZONE_SECTION or CTX_DDL.ADD_FIELD_SECTION.
Use the datastore types to specify how your text is stored. To create a datastore preference, you must use one of the following datastore types:
Use the DIRECT_DATASTORE type for text stored directly in the text column, one document per row. DIRECT_DATASTORE has no attributes.
The following columns types are supported: CHAR, VARCHAR, VARCHAR2, BLOB, CLOB, BFILE, or XMLType.
|
Note: If your column is a |
The following example creates a table with a CLOB column to store text data. It then populates two rows with text data and indexes the table using the system-defined preference CTXSYS.DEFAULT_DATASTORE.
create table mytable(id number primary key, docs clob); insert into mytable values(111555,'this text will be indexed'); insert into mytable values(111556,'this is a direct_datastore example'); commit; create index myindex on mytable(docs) indextype is ctxsys.context parameters ('DATASTORE CTXSYS.DEFAULT_DATASTORE');
Use this datastore when your text is stored in more than one column. During indexing, the system concatenates the text columns and indexes the text as a single document.
MULTI_COLUMN_DATASTORE has the following attributes:
To index, you must create a dummy column to specify in the CREATE INDEX statement. This column's contents are not made part of the virtual document, unless its name is specified in the columns attribute.
The index is synchronized only when the dummy column is updated. You can create triggers to propagate changes if needed.
Only CTXSYS is allowed to create preferences for the MULTI_COLUMN_DATASTORE type. Any other user who attempts to create a MULTI_COLUMN_DATASTORE preference receives an error.
Oracle makes this restriction because when the columns attribute contains a function call, the call is made by the CTXSYS schema. The potential exists for a malicious CTXAPP users to execute arbitrary functions for which they do not have execute permission.
If this is too restrictive, you can create a stored procedure under CTXSYS to create MULTI_COLUMN_DATASTORE preferences. The effective user is CTXSYS, who creates and owns the preferences. However, you can call this procedure from any schema as CTXSYS.
The following example creates a multi-column datastore preference called my_multi with three text columns:
begin ctx_ddl.create_preference('my_multi', 'MULTI_COLUMN_DATASTORE'); ctx_ddl.set_attribute('my_multi', 'columns', 'column1, column2, column3');end;
During indexing, the system creates a virtual document for each row. The virtual document is composed of the contents of the columns concatenated in the listing order with column name tags automatically added. For example:
create table mc(id number primary key, name varchar2(10), address varchar2(80)); insert into mc values(1, 'John Smith', '123 Main Street'); exec ctx_ddl.create_preference('mymds', 'MULTI_COLUMN_DATASTORE'); exec ctx_ddl.set_attibute('mymds', 'columns', 'name, address');
This produces the following virtual text for indexing:
<NAME> John Smith </NAME> <ADDRESS> 123 Main Street </ADDRESS>
The system indexes the text between the tags, ignoring the tags themselves.
To index these tags as sections, you can optionally create field sections with the BASIC_SECTION_GROUP.
|
Note: No section group is created when you use the |
When you use expressions or functions, the tag is composed of the first 30 characters of the expression unless a column alias is used.
For example, if your expression is as follows:
exec ctx_ddl.set_attibute('mymds', 'columns', '4 + 17');
then it produces the following virtual text:
<4 + 17> 21 </4 + 17>
If your expression is as follows:
exec ctx_ddl.set_attibute('mymds', 'columns', '4 + 17 col1');
then it produces the following virtual text:
<col1> 21 <col1>
The tags are in uppercase unless the column name or column alias is in lowercase and surrounded by double quotes. For example:
exec ctx_ddl.set_attibute('mymds', 'COLUMNS', 'foo');
produces the following virtual text:
<FOO> content of foo </FOO>
For lowercase tags, use the following:
exec ctx_ddl.set_attibute('mymds', 'COLUMNS', 'foo "foo"');
This expression produces:
<foo> content of foo </foo>
Use the DETAIL_DATASTORE type for text stored directly in the database in detail tables, with the indexed text column located in the master table.
DETAIL_DATASTORE has the following attributes:
Changes to the detail table do not trigger re-indexing when you synchronize the index. Only changes to the indexed column in the master table triggers a re-index when you synchronize the index.
You can create triggers on the detail table to propagate changes to the indexed column in the master table row.
This example illustrates how master and detail tables are related to each other.
Master tables define the documents in a master/detail relationship. You assign an identifying number to each document. The following table is an example master table, called my_master:
Detail tables contain the text for a document, whose content is usually stored across a number of rows. The following detail table my_detail is related to the master table my_master with the article_id column. This column identifies the master document to which each detail row (sub-document) belongs.
| Column Name | Column Type | Description |
|---|---|---|
|
article_id |
NUMBER |
Document ID that relates to master table |
|
seq |
NUMBER |
Sequence of document in the master document defined by article_id |
|
text |
VARCHAR2 |
Document text |
In this example, the DETAIL_DATASTORE attributes have the following values:
| Attribute | Attribute Value |
|---|---|
|
binary |
TRUE |
|
detail_table |
my_detail |
|
detail_key |
article_id |
|
detail_lineno |
seq |
|
detail_text |
text |
You use CTX_DDL.CREATE_PREFERENCE to create a preference with DETAIL_DATASTORE. You use CTX_DDL.SET_ATTRIBUTE to set the attributes for this preference as described earlier. The following example shows how this is done:
begin ctx_ddl.create_preference('my_detail_pref', 'DETAIL_DATASTORE'); ctx_ddl.set_attribute('my_detail_pref', 'binary', 'true'); ctx_ddl.set_attribute('my_detail_pref', 'detail_table', 'my_detail'); ctx_ddl.set_attribute('my_detail_pref', 'detail_key', 'article_id'); ctx_ddl.set_attribute('my_detail_pref', 'detail_lineno', 'seq'); ctx_ddl.set_attribute('my_detail_pref', 'detail_text', 'text');end;
To index the document defined in this master/detail relationship, you specify a column in the master table with CREATE INDEX. The column you specify must be one of the allowable types.
This example uses the body column, whose function is to allow the creation of the master/detail index and to improve readability of the code. The my_detail_pref preference is set to DETAIL_DATASTORE with the required attributes:
CREATE INDEX myindex on my_master(body) indextype is ctxsys.context parameters('datastore my_detail_pref');
In this example, you can also specify the title or author column to create the index. However, if you do so, changes to these columns will trigger a re-index operation.
The FILE_DATASTORE type is used for text stored in files accessed through the local file system.
FILE_DATASTORE has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
path |
path1:path2: :pathn |
Specify the full directory path name of the files stored externally in a file system. When you specify the full directory path as such, you need only include file names in your text column.
You can specify multiple paths for path, with each path separated by a colon (:). File names are stored in the text column in the text table.
If you do not specify a path for external files with this attribute, Oracle requires that the path be included in the file names stored in the text column.
This example creates a file datastore preference called COMMON_DIR that has a path of /mydocs:
begin ctx_ddl.create_preference('COMMON_DIR','FILE_DATASTORE'); ctx_ddl.set_attribute('COMMON_DIR','PATH','/mydocs'); end;
When you populate the table mytable, you need only insert filenames. The path attribute tells the system where to look during the indexing operation.
create table mytable(id number primary key, docs varchar2(2000)); insert into mytable values(111555,'first.txt'); insert into mytable values(111556,'second.txt'); commit;
Create the index as follows:
create index myindex on mytable(docs) indextype is ctxsys.context parameters ('datastore COMMON_DIR');
Use the URL_DATASTORE type for text stored:
You store each URL in a single text field.
The syntax of a URL you store in a text field is as follows (with brackets indicating optional parameters):
[URL:]<access_scheme>://<host_name>[:<port_number>]/[<url_path>]
The access_scheme string you specify can be either ftp, http, or file. For example:
http://mymachine.us.oracle.com/home.html
As this syntax is partially compliant with the RFC 1738 specification, the following restriction holds for the URL syntax:
URL_DATASTORE has the following attributes:
Specify the length of time, in seconds, that a network operation such as a connect or read waits before timing out and returning a timeout error to the application. The valid range for timeout is 15 to 3600 and the default is 30.
|
Note: Since timeout is at the network operation level, the total timeout may be longer than the time specified for timeout. |
Specify the maximum number of threads that can be running at the same time. The valid range for maxthreads is 1 to 1024 and the default is 8.
Specify the maximum length, in bytes, that the URL data store supports for URLs stored in the database. If a URL is over the maximum length, an error is returned. The valid range for urlsize is 32 to 65535 and the default is 256.
|
Note: The product values specified for maxurls and urlsize cannot exceed 5,000,000. In other words, the maximum size of the memory buffer (maxurls * urlsize) for the URL is approximately 5 megabytes. |
Specify the maximum number of rows that the internal buffer can hold for HTML documents (rows) retrieved from the text table. The valid range for maxurls is 32 to 65535 and the default is 256.
|
Note: The product values specified for maxurls and urlsize cannot exceed 5,000,000. In other words, the maximum size of the memory buffer (maxurls * urlsize) for the URL is approximately 5 megabytes. |
Specify the maximum size, in bytes, that the URL datastore supports for accessing HTML documents whose URLs are stored in the database. The valid range for maxdocsize is 1 to 2,147,483,647 (2 gigabytes), and the default is 2,000,000.
Specify the fully qualified name of the host machine that serves as the HTTP proxy (gateway) for the machine on which Oracle Text is installed. You can optionally specify port number with a colon in the form hostname:port.
You must set this attribute if the machine is in an intranet that requires authentication through a proxy server to access Web files located outside the firewall.
Specify the fully-qualified name of the host machine that serves as the FTP proxy (gateway) for the machine on which Oracle Text is installed. You can optionally specify a port number with a colon in the form hostname:port.
This attribute must be set if the machine is in an intranet that requires authentication through a proxy server to access Web files located outside the firewall.
Specify a string of domains (up to sixteen, separate by commas) which are found in most, if not all, of the machines in your intranet. When one of the domains is encountered in a host name, no request is sent to the machine(s) specified for ftp_proxy and http_proxy. Instead, the request is processed directly by the host machine identified in the URL.
For example, if the string us.oracle.com, uk.oracle.com is entered for no_proxy, any URL requests to machines that contain either of these domains in their host names are not processed by your proxy server(s).
This example creates a URL_DATASTORE preference called URL_PREF for which the http_proxy, no_proxy, and timeout attributes are set. The defaults are used for the attributes that are not set.
begin ctx_ddl.create_preference('URL_PREF','URL_DATASTORE'); ctx_ddl.set_attribute('URL_PREF','HTTP_PROXY','www-proxy.us.oracle.com'); ctx_ddl.set_attribute('URL_PREF','NO_PROXY','us.oracle.com'); ctx_ddl.set_attribute('URL_PREF','Timeout','300'); end;
Create the table and insert values into it:
create table urls(id number primary key, docs varchar2(2000)); insert into urls values(111555,'http://context.us.oracle.com'); insert into urls values(111556,'http://www.sun.com'); commit;
To create the index, specify URL_PREF as the datastore:
create index datastores_text on urls ( docs ) indextype is ctxsys.context parameters ( 'Datastore URL_PREF' );
Use the USER_DATASTORE type to define stored procedures that synthesize documents during indexing. For example, a user procedure might synthesize author, date, and text columns into one document to have the author and date information be part of the indexed text.
The USER_DATASTORE has the following attributes:
Specify the name of the procedure that synthesizes the document to be indexed. This specification must be in the form PROCEDURENAME or PACKAGENAME.PROCEDURENAME. The schema owner name is constrained to CTXSYS, so specifying owner name is not necessary.
The procedure you specify must have two arguments defined as follows:
procedure (r IN ROWID, c IN OUT NOCOPY <output_type>)
The first argument r must be of type ROWID. The second argument c must be of type output_type. NOCOPY is a compiler hint that instructs Oracle to pass parameter c by reference if possible.
|
Note:: The procedure name and its arguments can be named anything. The arguments r and c are used in this example for simplicity. |
The stored procedure is called once for each row indexed. Given the rowid of the current row, procedure must write the text of the document into its second argument, whose type you specify with output_type.
The following constraints apply to procedure:
CTXSYSCOMMITIf you change or edit the stored procedure, indexes based upon it will not be notified, so you must manually re-create such indexes. So if the stored procedure makes use of other columns, and those column values change, the row will not be re-indexed. The row is re-indexed only when the indexed column changes.
Specify the datatype of the second argument to procedure. You can use either CLOB, BLOB, CLOB_LOC, BLOB_LOC, or VARCHAR2.
Consider a table in which the author, title, and text fields are separate, as in the articles table defined as follows:
create table articles( id number, author varchar2(80), title varchar2(120), text clob );
The author and title fields are to be part of the indexed document text. Assume user appowner writes a stored procedure with the user datastore interface that synthesizes a document from the text, author, and title fields:
create procedure myproc(rid in rowid, tlob in out clob) is begin for c1 in (select author, title, text from articles where rowid = rid) loop dbms_lob.writeappend(tlob, length(c1.title), c1.title); dbms_lob.writeappend(tlob, length(c1.author), c1.author); dbms_lob.writeappend(tlob, length(c1.text), c1.text);end loop; end;
This procedure takes in a rowid and a temporary CLOB locator, and concatenates all the article's columns into the temporary CLOB. The for loop executes only once.
Only procedures owned by CTXSYS are allowed for the user datastore. Therefore, CTXSYS must wrap the user procedure (owned by appowner) with a CTXSYS owned procedure as follows:
create procedure s_myproc(rid in rowid, tlob in out clob) is begin appowner.myproc(rid, tlob); end;
The CTXSYS user must make sure that the index owner can execute the stub procedure by granting execute privileges as follows:
grant execute on s_myproc to appowner ;
The user appowner creates the preference, setting the procedure attribute to the name of the ctxsys stub procedure as follows:
begin ctx_ddl.create_preference('myud', 'user_datastore'); ctx_ddl.set_attribute('myud', 'procedure', 's_myproc'); ctx_ddl.set_attribute('myud', 'output_type', 'CLOB');end;
When appowner creates the index on articles(text) using this preference, the indexing operation sees author and title in the document text.
The following procedure might be used with OUTPUT_TYPE BLOB_LOC:
procedure myds(rid in rowid, dataout in out nocopy blob) is l_dtype varchar2(10); l_pk number; begin select dtype, pk into l_dtype, l_pk from mytable where rowid = rid; if (l_dtype = 'MOVIE') then select movie_data into dataout from movietab where fk = l_pk; elsif (l_dtype = 'SOUND') then select sound_data into dataout from soundtab where fk = l_pk; end if; end;
Because only procedures owned by CTXSYS are allowed for the user datastore, CTXSYS must wrap the user procedure (owned by appowner) with a CTXSYS owned procedure as follows:
create procedure s_myproc(rid in rowid, tlob in out blob) is begin appowner.myds(rid, tlob); end;
The CTXSYS user must make sure that the index owner can execute the stub procedure by granting execute privileges as follows:
grant execute on s_myproc to appowner ;
The user appowner creates the preference, setting the procedure and output_type attributes to correspond to the ctxsys stub procedure as follows:
begin ctx_ddl.create_preference('myud', 'user_datastore'); ctx_ddl.set_attribute('myud', 'procedure', 's_myproc'); ctx_ddl.set_attribute('myud', 'output_type', 'blob_loc');end;
Use the nested datastore type to index documents stored as rows in a nested table.
When using the nested table datastore, you must index a dummy column, because the extensible indexing framework disallows indexing the nested table column. See the example.
DML on the nested table is not automatically propagated to the dummy column used for indexing. For DML on the nested table to be propagated to the dummy column, your application code or trigger must explicitly update the dummy column.
Filter defaults for the index are based on the type of the nested_text column.
During validation, Oracle checks that the type exists and that the attributes you specify for nested_lineno and nested_text exist in the nested table type. Oracle does not check that the named nested table column exists in the indexed table.
The following code creates a nested table and a storage table mytab for the nested table:
create type nt_rec as object ( lno number, -- line number ltxt varchar2(80) -- text of line ); create type nt_tab as table of nt_rec; create table mytab ( id number primary key, -- primary key dummy char(1), -- dummy column for indexing doc nt_tab -- nested table ) nested table doc store as myntab;
The following code inserts values into the nested table for the parent row with id equal to 1.
insert into mytab values (1, null, nt_tab()); insert into table(select doc from mytab where id=1) values (1, 'the dog'); insert into table(select doc from mytab where id=1) values (2, 'sat on mat '); commit;
The following code sets the preferences and attributes for the NESTED_DATASTORE according to the definitions of the nested table type nt_tab and the parent table mytab:
begin -- create nested datastore pref ctx_ddl.create_preference('ntds','nested_datastore'); -- nest tab column in main table ctx_ddl.set_attribute('ntds','nested_column', 'doc'); -- nested table type ctx_ddl.set_attribute('ntds','nested_type', 'scott.nt_tab'); -- lineno column in nested table ctx_ddl.set_attribute('ntds','nested_lineno','lno'); --text column in nested table ctx_ddl.set_attribute('ntds','nested_text', 'ltxt'); end;
The following code creates the index using the nested table datastore:
create index myidx on mytab(dummy) -- index dummy column, not nest table indextype is ctxsys.context parameters ('datastore ntds');
The following select statement queries the index built from a nested table:
select * from mytab where contains(dummy, 'dog and mat')>0; -- returns document 1, since it has dog in line 1 and mat in line 2.
Use the filter types to create preferences that determine how text is filtered for indexing. Filters allow word processor and formatted documents as well as plain text, HTML, and XML documents to be indexed.
For formatted documents, Oracle stores documents in their native format and uses filters to build temporary plain text or HTML versions of the documents. Oracle indexes the words derived from the plain text or HTML version of the formatted document.
To create a filter preference, you must use one of the following types:
Use the CHARSET_FILTER to convert documents from a non-database character set to the database character set.
CHARSET_FILTER has the following attribute:
| See Also:
Oracle9i Globalization and National Language Support Guide for more information about the supported Globalization Support character sets. |
If your character set is UTF-16, you can specify UTF16AUTO to automatically detect big- or little-endian data. Oracle does so by examining the first two bytes of the document row.
If the first two bytes are 0xFE, 0xFF, the document is recognized as little-endian and the remainder of the document minus those two bytes is passed on for indexing.
If the first two bytes are 0xFF, 0xFE, the document is recognized as big-endian and the remainder of the document minus those two bytes is passed on for indexing.
If the first two bytes are anything else, the document is assumed to be big-endian and the whole document including the first two bytes is passed on for indexing.
A mixed character set column is one that stores documents of different character sets. For example, a text table might store some documents in WE8ISO8859P1 and others in UTF8.
To index a table of documents in different character sets, you must create your base table with a character set column. In this column, you specify the document character set on a per-row basis. To index the documents, Oracle converts the documents into the database character set.
Character set conversion works with the CHARSET_FILTER. When the charset column is NULL or not recognized, Oracle assumes the source character set is the one specified in the charset attribute.
|
Note: Character set conversion also works with the |
For example, create the table with a charset column:
create table hdocs ( id number primary key, fmt varchar2(10), cset varchar2(20), text varchar2(80) );
Insert plain-text documents and name the character set:
insert into hdocs values(1, 'text', 'WE8ISO8859P1', '/docs/iso.txt'); insert in hdocs values (2, 'text', 'UTF8', '/docs/utf8.txt'); commit;
Create the index and name the charset column:
create index hdocsx on hdocs(text) indextype is ctxsys.context parameters ('datastore ctxsys.file_datastore filter ctxsys.charset_filter format column fmt charset column cset');
The INSO_FILTER is a universal filter that filters most document formats. This filtering technology is licensed from Stellent Chicago, Inc.
Use it for indexing single and mixed-format columns.
| See Also:
For a list of the formats supported by |
The INSO_FILTER has the following attribute:
To index a text column containing formatted documents such as Microsoft Word, use the INSO_FILTER. This filter automatically detects the document format. You can use the CTXSYS.INSO_FILTER system-defined preference in the parameter clause as follows:
create index hdocsx on hdocs(text) indextype is ctxsys.context parameters ('datastore ctxsys.file_datastore filter ctxsys.inso_filter');
A mixed-format column is a text column containing more than one document format, such as a column that contains Microsoft Word, PDF, plain text, and HTML documents.
The INSO_FILTER can index mixed-format columns. However, you might want to have the INSO filter bypass the plain text or HTML documents. Filtering plain text or HTML with the INSO_FILTER is redundant.
The format column in the base table allows you to specify the type of document contained in the text column. The only two types you can specify are TEXT and BINARY. During indexing, the INSO_FILTER ignores any document typed TEXT (assuming the charset column is not specified.)
To set up the INSO_FILTER bypass mechanism, you must create a format column in your base table.
For example:
create table hdocs ( id number primary key, fmt varchar2(10), text varchar2(80) );
Assuming you are indexing mostly Word documents, you specify BINARY in the format column to filter the Word documents. Alternatively, to have the INSO_FILTER ignore an HTML document, specify TEXT in the format column.
For example, the following statements add two documents to the text table, assigning one format as BINARY and the other TEXT:
insert into hdocs values(1, 'binary', '/docs/myword.doc'); insert in hdocs values (2, 'text', '/docs/index.html'); commit;
To create the index, use CREATE INDEX and specify the format column name in the parameter string:
create index hdocsx on hdocs(text) indextype is ctxsys.context parameters ('datastore ctxsys.file_datastore filter ctxsys.inso_filter format column fmt');
If you do not specify TEXT or BINARY for the format column, BINARY is used.
The INSO_FILTER converts documents to the database character set when the document format column is set to TEXT. In this case, the INSO_FILTER looks at the charset column to determine the document character set.
If the charset column value is not an Oracle character set name, the document is passed through without any character set conversion.
If you do specify the charset column and do not specify the format column, the INSO_FILTER works like the CHARSET_FILTER, except that in this case there is no Japanese character set auto-detection.
Oracle does not recommend using INSO_FILTER to index plain text documents.
If your table contains text documents exclusively, use the NULL_FILTER or the USER_FILTER.
If your table contains text documents mixed with formatted documents, Oracle recommends creating a format column and marking the text documents as TEXT to bypass INSO_FILTER. In such cases, Oracle also recommends creating a charset column to indicate the document character set.
However, if you use INSO_FILTER to index nonbinary (text) documents and you specify no format column and no charset column, the INSO_FILTER processes the document. Your indexing process is thus subject to the character set limitations of Inso technology. Specifically, your application must ensure that one of the following conditions is true:
Use the NULL_FILTER type when plain text or HTML is to be indexed and no filtering needs to be performed. NULL_FILTER has no attributes.
If your document set is entirely HTML, Oracle recommends that you use the NULL_FILTER in your filter preference.
For example, to index an HTML document set, you can specify the system-defined preferences for NULL_FILTER and HTML_SECTION_GROUP as follows:
create index myindex on docs(htmlfile) indextype is ctxsys.context parameters('filter ctxsys.null_filter section group ctxsys.html_section_group');
| See Also:
For more information on section groups and indexing HTML documents, see "Section Group Types" in this chapter. |
Use the USER_FILTER type to specify an external filter for filtering documents in a column. USER_FILTER has the following attribute:
| Attribute | Attribute Values |
|---|---|
|
command |
Specify the name of the filter executable. |
Specify the executable for the single external filter used to filter all text stored in a column. If more than one document format is stored in the column, the external filter specified for command must recognize and handle all such formats.
The executable you specify must exist in the $ORACLE_HOME/ctx/bin directory. You must create your user-filter executable with two parameters: the first is the name of the input file to be read, and the second is the name of the output file to be written to.
If all the document formats are supported by INSO_FILTER, use INSO_FILTER instead of USER_FILTER unless additional tasks besides filtering are required for the documents.
The following example perl script to be used as the user filter. This script converts the input text file specified in the first argument to uppercase and writes the output to the location specified in the second argument:
#!/usr/local/bin/perl open(IN, $ARGV[0]); open(OUT, ">".$ARGV[1]); while (<IN>) { tr/a-z/A-Z/; print OUT; } close (IN); close (OUT);
Assuming that this file is named upcase.pl, create the filter preference as follows:
begin ctx_ddl.create_preference ( preference_name => 'USER_FILTER_PREF', object_name => 'USER_FILTER' ); ctx_ddl.set_attribute ('USER_FILTER_PREF','COMMAND','upcase.pl'); end;
Create the index in SQL*Plus as follows:
create index user_filter_idx on user_filter ( docs ) indextype is ctxsys.context parameters ('FILTER USER_FILTER_PREF');
Use the PROCEDURE_FILTER type to filter your documents with a stored procedure. The stored procedure is called each time a document needs to be filtered.
This type has the following attributes:
Specify the name of the stored procedure to use for filtering. The procedure can be a PL/SQL stored procedure. The procedure can be a safe callout or call a safe callout.
The procedure must be owned by CTXSYS and have one of the following signatures:
PROCEDURE(IN BLOB, IN OUT NOCOPY CLOB) PROCEDURE(IN CLOB, IN OUT NOCOPY CLOB) PROCEDURE(IN VARCHAR, IN OUT NOCOPY CLOB) PROCEDURE(IN BLOB, IN OUT NOCOPY VARCHAR2) PROCEDURE(IN CLOB, IN OUT NOCOPY VARCHAR2) PROCEDURE(IN VARCHAR2, IN OUT NOCOPY VARCHAR2) PROCEDURE(IN BLOB, IN VARCHAR2) PROCEDURE(IN CLOB, IN VARCHAR2) PROCEDURE(IN VARCHAR2, IN VARCHAR2)
The first argument is the content of the unfiltered row as passed out by the datastore. The second argument is for the procedure to pass back the filtered document text.
The procedure attribute is mandatory and has no default.
Specify the type of the input argument of the filter procedure. You can specify one of the following:
The input_type attribute is not mandatory. If not specified, BLOB is the default.
Specify the type of output argument of the filter procedure. You can specify one of the following types:
The output_type attribute is not mandatory. If not specified, CLOB is the default.
When you specify TRUE, the rowid of the document to be filtered is passed as the first parameter, before the input and output parameters.
For example, with INPUT_TYPE BLOB, OUTPUT_TYPE CLOB, and ROWID_PARAMETER TRUE, the filter procedure must have the signature as follows:
procedure(in rowid, in blob, in out nocopy clob)
This attribute is useful for when your procedure requires data from other columns or tables. This attribute is not mandatory. The default is FALSE.
When you specify TRUE, the value of the format column of the document being filtered is passed to the filter procedure before input and output parameters, but after the rowid parameter, if enabled.
You specify the name of the format column at index time in the parameters string, using the keyword 'format column <columnname>'. The parameter type must be IN VARCHAR2.
The format column value can be read via the rowid parameter, but this attribute allows a single filter to work on multiple table structures, because the format attribute is abstracted and does not require the knowledge of the name of the table or format column.
FORMAT_PARAMETER is not mandatory. The default is FALSE.
When you specify TRUE, the value of the charset column of the document being filtered is passed to the filter procedure before input and output parameters, but after the rowid and format parameter, if enabled.
You specify the name of the charset column at index time in the parameters string, using the keyword 'charset column <columnname>'. The parameter type must be IN VARCHAR2.
CHARSET_PARAMETER attribute is not mandatory. The default is FALSE.
ROWID_PARAMETER, FORMAT_PARAMETER, and CHARSET_PARAMETER are all independent. The order is rowid, the format, then charset, but the filter procedure is passed only the minimum parameters required.
For example, assume that INPUT_TYPE is BLOB and OUTPUT_TYPE is CLOB. If your filter procedure requires all parameters, the procedure signature must be:
(id IN ROWID, format IN VARCHAR2, charset IN VARCHAR2, input IN BLOB, output IN OUT NOCOPY CLOB)
If your procedure requires only the ROWID, then the procedure signature must be:
(id IN ROWID,input IN BLOB, ouput IN OUT NOCOPY CLOB)
In order to create an index using a PROCEDURE_FILTER preference, the index owner must have execute permission on the procedure.Oracle checks this at index time, which is similar to the security measures for USER_DATASTORE.
The filter procedure can raise any errors needed through the normal PL/SQL raise_application_error facility. These errors are propagated to the CTX_USER_INDEX_ERRORS view or reported to the user, depending on how the filter is invoked.
Consider a filter procedure CTXSYS.NORMALIZE that you define with the following signature:
PROCEDURE NORMALIZE(id IN ROWID, charset IN VARCHAR2, input IN CLOB, output IN OUT NOCOPY VARCHAR2);
To use this procedure as your filter, set up your filter preference as follows:
begin ctx_ddl.create_preference('myfilt', 'procedure_filter'); ctx_ddl.set_attribute('myfilt', 'procedure', 'normalize'); ctx_ddl.set_attribute('myfilt', 'input_type', 'clob'); ctx_ddl.set_attribute('myfilt', 'output_type', 'varchar2'); ctx_ddl.set_attribute('myfilt', 'rowid_parameter', 'TRUE'); ctx_ddl.set_attribute('myfilt', 'charset_parameter', 'TRUE'); end;
Use the lexer preference to specify the language of the text to be indexed. To create a lexer preference, you must use one of the following lexer types:
Use the BASIC_LEXER type to identify tokens for creating Text indexes for English and all other supported whitespace delimited languages.
The BASIC_LEXER also enables base-letter conversion, composite word indexing, case-sensitive indexing and alternate spelling for whitespace delimited languages that have extended character sets.
In English and French, you can use the BASIC_LEXER to enable theme indexing.
BASIC_LEXER supports any database character set.
BASIC_LEXER has the following attributes:
Specify the characters that indicate a word continues on the next line and should be indexed as a single token. The most common continuation characters are hyphen '-' and backslash '\'.
Specify a single character that, when it appears in a string of digits, indicates that the digits are groupings within a larger single unit.
For example, comma ',' might be defined as a numgroup character because it often indicates a grouping of thousands when it appears in a string of digits.
Specify the characters that, when they appear in a string of digits, cause Oracle to index the string of digits as a single unit or word.
For example, period '.' can be defined as numjoin characters because it often serves as decimal points when it appears in a string of digits.
Specify the non alphanumeric characters that, when they appear anywhere in a word (beginning, middle, or end), are processed as alphanumeric and included with the token in the Text index. This includes printjoins that occur consecutively.
For example, if the hyphen '-' and underscore '_' characters are defined as printjoins, terms such as pseudo-intellectual and _file_ are stored in the Text index as pseudo-intellectual and _file_.
Specify the non-alphanumeric characters that, when they appear at the end of a word, indicate the end of a sentence. The defaults are period '.', question mark '?', and exclamation point '!'.
Characters that are defined as punctuations are removed from a token before text indexing. However, if a punctuations character is also defined as a printjoins character, the character is removed only when it is the last character in the token and it is immediately preceded by the same character.
For example, if the period (.) is defined as both a printjoins and a punctuations character, the following transformations take place during indexing and querying as well:
| Token | Indexed Token |
|---|---|
|
.doc |
.doc |
|
dog.doc |
dog.doc |
|
dog..doc |
dog..doc |
|
dog. |
dog |
|
dog... |
dog.. |
In addition, BASIC_LEXER uses punctuations characters in conjunction with newline and whitespace characters to determine sentence and paragraph deliminters for sentence/paragraph searching.
Specify the non-alphanumeric characters that, when they appear within a word, identify the word as a single token; however, the characters are not stored with the token in the Text index.
For example, if the hyphen character '-' is defined as a skipjoins, the word pseudo-intellectual is stored in the Text index as pseudointellectual.
|
Note: printjoins and skipjoins are mutually exclusive. The same characters cannot be specified for both attributes. |
For startjoins, specify the characters that when encountered as the first character in a token explicitly identify the start of the token. The character, as well as any other startjoins characters that immediately follow it, is included in the Text index entry for the token. In addition, the first startjoins character in a string of startjoins characters implicitly ends the previous token.
For endjoins, specify the characters that when encountered as the last character in a token explicitly identify the end of the token. The character, as well as any other startjoins characters that immediately follow it, is included in the Text index entry for the token.
The following rules apply to both startjoins and endjoins:
BASIC_LEXER.Specify the characters that are treated as blank spaces between tokens. BASIC_LEXER uses whitespace characters in conjunction with punctuations and newline characters to identify character strings that serve as sentence delimiters for sentence and paragraph searching.
The predefined default values for whitespace are 'space' and 'tab'. These values cannot be changed. Specifying characters as whitespace characters adds to these defaults.
Specify the characters that indicate the end of a line of text. BASIC_LEXER uses newline characters in conjunction with punctuations and whitespace characters to identify character strings that serve as paragraph delimiters for sentence and paragraph searching.
The only valid values for newline are NEWLINE and CARRIAGE_RETURN (for carriage returns). The default is NEWLINE.
Specify whether characters that have diacritical marks (umlauts, cedillas, acute accents, and so on) are converted to their base form before being stored in the Text index. The default is NO (base-letter conversion disabled).
Specify whether the lexer leaves the tokens exactly as they appear in the text or converts the tokens to all uppercase. The default is NO (tokens are converted to all uppercase).
Specify whether composite word indexing is disabled or enabled for either GERMAN or DUTCH text. The default is DEFAULT (composite word indexing disabled).
Words that are usually one entry in a German dictionary are not split into composite stems, while words that aren't dictionary entries are split into composite stems.
In order to retrieve the indexed composite stems, you must issue a stem query, such as $bahnhof. The language of the wordlist stemmer must match the language of the composite stems.
In your language, you can create a user dictionary to customize how words are decomposed.
You create the user dictionary in the $ORACLE_HOME/ctx/data/<language id> directory. The user dictionary must have the suffix .dct.
For example, the supplied user dictionary file for German is:
$ORACLE_HOME/ctx/data/del/drde.dct
The format for the user dictionary is as follows:
input term <tab> output term
The individual parts of the decomposed word must be separated by the # character. The following example entries are for the German word Hauptbahnhof:
Hauptbahnhof<tab>Haupt#Bahnhof Hauptbahnhofes<tab>Haupt#Bahnhof Hauptbahnhof<tab>Haupt#Bahnhof Hauptbahnhoefe<tab>Haupt#Bahnhof
Specify YES to index theme information in English or French. This makes ABOUT queries more precise. The index_themes and index_text attributes cannot both be NO.
If you use the BASIC_LEXER and specify no value for index_themes, this attribute defaults to NO.
You can set this parameter to TRUE for any indextype including CTXCAT. To issue an ABOUT query with CATSEARCH, use the query template with CONTEXT grammar.
Specify YES to prove themes. Theme proving attempts to find related themes in a document. When no related themes are found, parent themes are eliminated from the document.
While theme proving is acceptable for large documents, short text descriptions with a few words rarely prove parent themes, resulting in poor recall performance with ABOUT queries.
Theme proving results in higher precision and less recall (less rows returned) for ABOUT queries. For higher recall in ABOUT queries and possibly less precision, you can disable theme proving. Default is YES.
The prove_themes attribute is supported for CONTEXT and CTXRULE indexes.
Specify which knowledge base to use for theme generation when index_themes is set to YES. When index_themes is NO, setting this parameter has no effect on anything.
You can specify any Globalization Support language or AUTO. You must have a knowledge base for the language you specify. This release provides a knowledge base in only English and French. In other languages, you can create your own knowledge base.
The default is AUTO, which instructs the system to set this parameter according to the language of the environment.
Specify the stemmer to use for stem indexing.Tokens are stemmed to a single base form at index time in addition to the normal forms. Indexing stems enables better query performance for stem ($) queries, such as $computed.
Specify YES to index word information. The index_themes and index_text attributes cannot both be NO.
The default is NO.
Specify either GERMAN, DANISH, or SWEDISH to enable the alternate spelling in one of these languages. Enabling alternate spelling allows you to query a word in any of its alternate forms.
By default, alternate spelling is enabled in all three languages. You can specify NONE for no alternate spelling.
| See Also:
For more information about the alternate spelling conventions Oracle uses, see Appendix E, "Alternate Spelling Conventions". |
The following example sets printjoin characters and disables theme indexing with the BASIC_LEXER:
begin ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); ctx_ddl.set_attribute ( 'mylex', 'index_themes', 'NO'); ctx_ddl.set_attribute ( 'mylex', 'index_text', 'YES'); end;
To create the index with no theme indexing and with printjoins characters set as described, issue the following statement:
create index myindex on mytable ( docs ) indextype is ctxsys.context parameters ( 'LEXER mylex' );
Use MULTI_LEXER to index text columns that contain documents of different languages. For example, you can use this lexer to index a text column that stores English, German, and Japanese documents.
This lexer has no attributes.
You must have a language column in your base table. To index multi-language tables, you specify the language column when you create the index.
You create a multi-lexer preference with the CTX_DDL.CREATE_PREFERENCE. You add language-specific lexers to the multi-lexer preference with the CTX_DDL.ADD_SUB_LEXER procedure.
During indexing, the MULTI_LEXER examines each row's language column value and switches in the language-specific lexer to process the document.
When you use the MULTI_LEXER, you can also use a multi-language stoplist for indexing.
| See Also:
Multi-Language Stoplists in this chapter. |
Create the multi-language table with a primary key, a text column, and a language column as follows:
create table globaldoc ( doc_id number primary key, lang varchar2(3), text clob );
Assume that the table holds mostly English documents, with the occasional German or Japanese document. To handle the three languages, you must create three sub-lexers, one for English, one for German, and one for Japanese:
ctx_ddl.create_preference('english_lexer','basic_lexer'); ctx_ddl.set_attribute('english_lexer','index_themes','yes'); ctx_ddl.set_attribute('english_lexer','theme_language','english'); ctx_ddl.create_preference('german_lexer','basic_lexer'); ctx_ddl.set_attribute('german_lexer','composite','german'); ctx_ddl.set_attribute('german_lexer','mixed_case','yes'); ctx_ddl.set_attribute('german_lexer','alternate_spelling','german'); ctx_ddl.create_preference('japanese_lexer','japanese_vgram_lexer');
Create the multi-lexer preference:
ctx_ddl.create_preference('global_lexer', 'multi_lexer');
Since the stored documents are mostly English, make the English lexer the default using CTX_DDL.ADD_SUB_LEXER:
ctx_ddl.add_sub_lexer('global_lexer','default','english_lexer');
Now add the German and Japanese lexers in their respective languages with CTX_DDL.ADD_SUB_LEXER procedure. Also assume that the language column is expressed in the standard ISO 639-2 language codes, so add those as alternate values.
ctx_ddl.add_sub_lexer('global_lexer','german','german_lexer','ger'); ctx_ddl.add_sub_lexer('global_lexer','japanese','japanese_lexer','jpn');
Now create the index globalx, specifying the multi-lexer preference and the language column in the parameter clause as follows:
create index globalx on globaldoc(text) indextype is ctxsys.context parameters ('lexer global_lexer language column lang');
At query time, the multi-lexer examines the language setting and uses the sub-lexer preference for that language to parse the query. If the language is not set, then the default lexer is used.
Otherwise, the query is parsed and run as usual. The index contains tokens from multiple languages, so such a query can return documents in several languages. To limit your query to a given language, use a structured clause on the language column.
The CHINESE_VGRAM_LEXER type identifies tokens in Chinese text for creating Text indexes. It has no attributes.
You can use this lexer if your database character set is one of the following:
The CHINESE_LEXER type identifies tokens in traditional and simplified Chinese text for creating Text indexes. It has no attributes.
This lexer offers the following benefits over the CHINESE_VGRAM_LEXER:
Because the CHINESE_LEXER uses a new algorithm to generate tokens, indexing time is longer than with CHINESE_VGRAM_LEXER.
You can use this lexer if your database character is one of the Chinese or Unicode character sets supported by Oracle.
The JAPANESE_VGRAM_LEXER type identifies tokens in Japanese for creating Text indexes. It has no attributes.
You can use this lexer if your database character set is one of the following:
The JAPANESE_LEXER type identifies tokens in Japanese for creating Text indexes. It has no attributes.
This lexer offers the following benefits over the JAPANESE_VGRAM_LEXER:
Because the JAPANESE_LEXER uses a new algorithm to generate tokens, indexing time is longer than with JAPANESE_VGRAM_LEXER.
The JAPANESE_LEXER supports the following character sets:
When you specify JAPANESE_LEXER for creating text index, the JAPANESE_LEXER resolves a sentence into words.
For example, the following compound word (natural language institute)

Text description of the illustration jap_befo.gif
is indexed as three tokens:

Text description of the illustration jap_afte.gif
In order to resolve a sentence into words, the internal dictionary is referenced. When a word cannot be found in the internal dictionary, Oracle uses the JAPANESE_VGRAM_LEXER to resolve it.
The KOREAN_LEXER type identifies tokens in Korean text for creating Text indexes.
|
Note: This lexer is supported for backward compatibility with older versions of Oracle Text that supported only this Korean lexer. If you are building a new application, Oracle recommends that you use the KOREAN_MORPH_LEXER. |
You can use this lexer if your database character set is one of the following:
When you use the KOREAN_LEXER, you can specify the following boolean attributes:
Sentence and paragraph sections are not supported with the Korean lexer.
The KOREAN_MORPH_LEXER type identifies tokens in Korean text for creating Oracle Text indexes. The KOREAN_MORPH_LEXER lexer offers the following benefits over KOREAN_LEXER:
The KOREAN_MORPH_LEXER uses four dictionaries:
The grammar, user-defined, and stopword dictionaries are text format KSC 5601. You can modify these dictionaries using the defined rules. The system dictionary must not be modified.
You can add unregistered words to the user-defined dictionary file. The rules for specifying new words are in the file.
You can use KOREAN_MORPH_LEXER if your database character set is one of the following:
When you use the KOREAN_MORPH_LEXER, you can specify the following attributes:
Sentence and paragraph sections are not supported with the Korean lexer.
You can use the composite attribute to control how composite nouns are indexed.
When you specify NGRAM for the composite attribute, composite nouns are indexed with all possible component tokens. For example, the following composite noun (information processing institute):
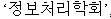
Text description of the illustration 1.jpg
is indexed as six tokens:
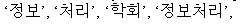
Text description of the illustration 2.jpg
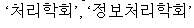
Text description of the illustration 3.jpg
You can specify NGRAM indexing as follows:
begin ctx_ddl.create_preference('korean_lexer','KOREAN_MORPH_LEXER'); ctx_ddl.set_attribute('korean_lexer','COMPOSITE','NGRAM'); end
To create the index:
create index koreanx on korean(text) indextype is ctxsys.context parameters ('lexer korean_lexer');
When you specify COMPONENT_WORD for the composite attribute, composite nouns and their components are indexed. For example, the following composite noun (information processing institute):
Text description of the illustration 1.jpg
is indexed as four tokens:
Text description of the illustration 1.jpg
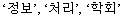
Text description of the illustration comp.jpg
You can specify COMPONENT_WORD indexing as follows:
begin ctx_ddl.create_preference('korean_lexer','KOREAN_MORPH_LEXER'); ctx_ddl.set_attribute('korean_lexer','COMPOSITE','COMPONENT_WORD'); end
To create the index:
create index koreanx on korean(text) indextype is ctxsys.context parameters ('lexer korean_lexer');
Use USER_LEXER to plug in your own language specific lexing solution. This enables you to define lexers for languages that are not supported by Oracle Text or to define a new lexer for a language that is supported but inappropriate for your application.
The user-defined lexer you register with Oracle Text is composed of two routines that you must supply:
The following features are not supported with the USER_LEXER:
The USER_LEXER has the following attributes:
This callback stored procedure is called by Oracle Text as needed to tokenize a document or a stop word found in the stoplist object.
This procedure can be a PL/SQL stored procedure.
This stored procedure must be owned by user CTXSYS and the index owner must have EXECUTE privilege on it.
This stored procedure must not be replaced or dropped after the index is created. You can replace or drop this stored procedure after the index is dropped.
Two different interfaces are supported for the user-defined lexer indexing procedure:
This procedure must not perform any of the following operations:
The child elements of the root element tokens of the XML document returned must be in the same order as the tokens occur in the document or stop word being tokenized.
The behavior of this stored procedure must be deterministic with respect to all parameters.
Two different interfaces are supported for the User-defined lexer indexing procedure. One interface allows the document or stop word and the corresponding tokens encoded as XML to be passed as VARCHAR2 datatype whereas the other interface uses the CLOB datatype. This attribute indicates the interface implemented by the stored procedure specified by the INDEX_PROCEDURE attribute.
Table 2-1 describes the interface that allows the document or stop word from stoplist object to be tokenized to be passed as VARCHAR2 from Oracle Text to the stored procedure and for the tokens to be passed as VARCHAR2 as well from the stored procedure back to Oracle Text.
Your user-defined lexer indexing procedure should use this interface when all documents in the column to be indexed are smaller than or equal to 32512 bytes and the tokens can be represented by less than or equal to 32512 bytes. In this case the CLOB interface given in Table 2-2 can also be used, although the VARCHAR2 interface will generally perform faster than the CLOB interface.
This procedure must be defined with the following parameters:
Table 2-1Table 2-2 describes the CLOB interface that allows the document or stop word from stoplist object to be tokenized to be passed as CLOB from Oracle Text to the stored procedure and for the tokens to be passed as CLOB as well from the stored procedure back to Oracle Text.
The user-defined lexer indexing procedure should use this interface when at least one of the documents in the column to be indexed is larger than 32512 bytes or the corresponding tokens are represented by more than 32512 bytes.
Table 2-2| Parameter Position | Parameter Mode | Parameter Datatype | Description |
|---|---|---|---|
|
1 |
IN |
CLOB |
Same as Table 2-1, "VARCHAR2 Interface for INDEX_PROCEDURE". |
|
2 |
IN OUT |
CLOB |
Same as Table 2-1, "VARCHAR2 Interface for INDEX_PROCEDURE". The IN value will always be a truncated CLOB. |
|
3 |
IN |
BOOLEAN |
Same as Table 2-1, "VARCHAR2 Interface for INDEX_PROCEDURE". |
The first and second parameters are temporary CLOBS. Avoid assigning these CLOB locators to other locator variables. Assigning the formal parameter CLOB locator to another locator variable causes a new copy of the temporary CLOB to be created resulting in a performance hit.
This callback stored procedure is called by Oracle Text as needed to tokenize words in the query. A space-delimited group of characters (excluding the query operators) in the query will be identified by Text as a word.
This procedure can be a PL/SQL stored procedure.
This stored procedure must be owned by user CTXSYS and the index owner must have EXECUTE privilege on it.
This stored procedure must not be replaced or be dropped after the index is created. You can replace or drop this stored procedure after the index is dropped.
This procedure must not perform any of the following operations:
The child elements of the root element tokens of the XML document returned must be in the same order as the tokens occur in the query word being tokenized.
The behavior of this stored procedure must be deterministic with respect to all parameters.
Table 2-3 describes the interface for the user-defined lexer query procedure:
Table 2-3The sequence of tokens returned by your stored procedure must be represented as an XML 1.0 document. The XML document must be valid with respect to the XML Schemas given in the following sections.
To boost performance of this feature, the XML parser in Oracle Text will not perform validation and will not be a full-featured XML compliant parser. This implies that only minimal XML features will be supported. The following XML features are not supported:
This section describes additional constraints imposed on the XML document returned by the user-defined lexer indexing procedure when the third parameter is FALSE. The XML document returned must be valid with respect to the following XML Schema:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="tokens"> <xsd:complexType> <xsd:sequence> <xsd:choice minOccurs="0" maxOccurs="unbounded"> <xsd:element name="eos" type="EmptyTokenType"/> <xsd:element name="eop" type="EmptyTokenType"/> <xsd:element name="num" type="xsd:token"/> <xsd:group ref="IndexCompositeGroup"/> </xsd:choice> </xsd:sequence> </xsd:complexType> </xsd:element> <!-- Enforce constraint that compMem element must be preceeded by word element or compMem element for indexing --> <xsd:group name="IndexCompositeGroup"> <xsd:sequence> <xsd:element name="word" type="xsd:token"/> <xsd:element name="compMem" type="xsd:token" minOccurs="0" maxOccurs="unbounded"/> </xsd:sequence> </xsd:group> <!-- EmptyTokenType defines an empty element without attributes --> <xsd:complexType name="EmptyTokenType"/> </xsd:schema>
Here are some of the constraints imposed by this XML Schema:
Table 2-4 describes the element names defined in the preceding XML Schema.
Document: Vom Nordhauptbahnhof und aus der Innenstadt zum Messegelände.
Tokens:
<tokens> <word> VOM </word> <word> NORDHAUPTBAHNHOF </word> <compMem> HAUPT </compMem> <compMem> HAUPTBAHNHOF </compMem> <compMem> NORD </compMem> <word> UND </word> <word> AUS </word> <word> DER </word> <word> INNENSTADT </word> <word> ZUM </word> <word> MESSEGELÄNDE </word> <eos/> </tokens>
Document: Oracle9i Release 2
Tokens:
<tokens> <word> ORACLE9I</word> <word> RELEASE </word> <num> 2 </num> </tokens>
Document: WHERE salary<25000.00 AND job = 'F&B Manager'
Tokens:
<tokens> <word> WHERE </word> <word> salary<2500.00 </word> <word> AND </word> <word> job </word> <word> F&B </word> <word> Manager </word> </tokens>
This section describes additional constraints imposed on the XML document returned by the user-defined lexer indexing procedure when the third parameter is TRUE. The XML document returned must be valid w.r.t to the following XML schema:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="tokens"> <xsd:complexType> <xsd:sequence> <xsd:choice minOccurs="0" maxOccurs="unbounded"> <xsd:element name="eos" type="EmptyTokenType"/> <xsd:element name="eop" type="EmptyTokenType"/> <xsd:element name="num" type="DocServiceTokenType"/> <xsd:group ref="DocServiceCompositeGroup"/> </xsd:choice> </xsd:sequence> </xsd:complexType> </xsd:element> <!-- Enforce constraint that compMem element must be preceeded by word element or compMem element for document service --> <xsd:group name="DocServiceCompositeGroup"> <xsd:sequence> <xsd:element name="word" type="DocServiceTokenType"/> <xsd:element name="compMem" type="DocServiceTokenType"/> </xsd:sequence> </xsd:group> <!-- EmptyTokenType defines an empty element without attributes --> <xsd:complexType name="EmptyTokenType"/> <!-- DocServiceTokenType defines an element with content and mandatory attributes --> <xsd:complexType name="DocServiceTokenType"> <xsd:simpleContent> <xsd:extension base="xsd:token"> <xsd:attribute name="off" type="OffsetType" use="required"/> <xsd:attribute name="len" type="xsd:unsignedShort" use="required"/> </xsd:extension> </xsd:simpleContent> </xsd:complexType> <xsd:simpleType name="OffsetType"> <xsd:restriction base="xsd:unsignedInt"> <xsd:maxInclusive value="2147483647"/> </xsd:restriction> </xsd:simpleType> </xsd:schema>
Some of the constraints imposed by this XML Schema are as follows:
off and len. Oracle Text will normalize the content of these elements as follows: convert whitespace characters to space characters, collapse adjacent space characters to a single space character, remove leading and trailing spaces, perform entity reference replacement, and truncate to 64 bytes.off attribute value must be an integer between 0 and 2147483647 inclusive.len attribute value must be an integer between 0 and 65535 inclusive.Table 2-4, "Element names" describes the element types defined in the preceding XML Schema.
Table 2-5, "Attributes" describes the attributes defined in the preceding XML Schema.
Sum of off attribute value and len attribute value must be less than or equal to the total number of characters in the document being tokenized. This is to ensure that the document offset and characters being referenced are within the document boundary.
Example
Document: User-defined Lexer.
Tokens:
<tokens> <word off="0" len="4"> USE </word> <word off="5" len="7"> DEF </word> <word off="13" len="5"> LEX </word> <eos/> </tokens>
This section describes additional constraints imposed on the XML document returned by the user-defined lexer query procedure. The XML document returned must be valid with respect to the following XML Schema:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="tokens"> <xsd:complexType> <xsd:sequence> <xsd:choice minOccurs="0" maxOccurs="unbounded"> <xsd:element name="num" type="QueryTokenType"/> <xsd:group ref="QueryCompositeGroup"/> </xsd:choice> </xsd:sequence> </xsd:complexType> </xsd:element> <!-- Enforce constraint that compMem element must be preceeded by word element or compMem element for query --> <xsd:group name="QueryCompositeGroup"> <xsd:sequence> <xsd:element name="word" type="QueryTokenType"/> <xsd:element name="compMem" type="QueryTokenType"/> </xsd:sequence> </xsd:group> <!-- QueryTokenType defines an element with content and with an optional attribute --> <xsd:complexType name="QueryTokenType"> <xsd:simpleContent> <xsd:extension base="xsd:token"> <xsd:attribute name="wildcard" type="WildcardType" use="optional"/> </xsd:extension> </xsd:simpleContent> </xsd:complexType> <xsd:simpleType name="WildcardType"> <xsd:restriction base="WildcardBaseType"> <xsd:minLength value="1"/> <xsd:maxLength value="64"/> </xsd:restriction> </xsd:simpleType> <xsd:simpleType name="WildcardBaseType"> <xsd:list> <xsd:simpleType> <xsd:restriction base="xsd:unsignedShort"> <xsd:maxInclusive value="378"/> </xsd:restriction> </xsd:simpleType> </xsd:list> </xsd:simpleType> </xsd:schema>
Here are some of the constraints imposed by this XML Schema:
Table 2-4, "Element names" describes the element types defined in the preceding XML Schema.
Table 2-6, "Attribute for XML Schema: Query Procedure" describes the attribute defined in the preceding XML Schema.
Table 2-6 Attribute for XML Schema: Query ProcedureQuery word: pseudo-%morph%
Tokens:
<tokens> <word> PSEUDO </word> <word wildcard="1 7"> %MORPH% </word> </tokens>
Query word: <%> Tokens: <tokens> <word wildcard="5"> <%> </word> </tokens>
Use the wordlist preference to enable the query options such as stemming, fuzzy matching for your language. You can also use the wordlist preference to enable substring and prefix indexing which improves performance for wildcard queries with CONTAINS and CATSEARCH.
To create a wordlist preference, you must use BASIC_WORDLIST, which is the only type available.
Use BASIC_WORDLIST type to enable stemming and fuzzy matching or to create prefix indexes with Text indexes.
| See Also:
For more information about the stem and fuzzy operators, see Chapter 3, "CONTAINS Query Operators". |
BASIC_WORDLIST has the following attributes:
Specify the stemmer used for word stemming in Text queries. When you do not specify a value for stemmer, the default is ENGLISH.
Specify AUTO for the system to automatically set the stemming language according to the language setting of the session. When there is no stemmer for a language, the default is NULL. With the NULL stemmer, the stem operator is ignored in queries.
Specify which fuzzy matching routines are used for the column. Fuzzy matching is currently supported for English, Japanese, and, to a lesser extent, the Western European languages.
|
Note: The fuzzy_match attribute values for Chinese and Korean are dummy attribute values that prevent the English and Japanese fuzzy matching routines from being used on Chinese and Korean text. |
The default for fuzzy_match is GENERIC.
Specify AUTO for the system to automatically set the fuzzy matching language according to language setting of the session.
Specify a default lower limit of fuzzy score. Specify a number between 0 and 80. Text with scores below this below this number are not returned. The default is 60.
Fuzzy score is a measure of how close the expanded word is to the query word. The higher the score the better the match. Use this parameter to limit fuzzy expansions to the best matches.
Specify the maximum number of fuzzy expansions. Use a number between 0 and 5000. The default is 100.
Setting a fuzzy expansion limits the expansion to a specified number of the best matching words.
Specify TRUE for Oracle to create a substring index. A substring index improves performance for left-truncated or double-truncated wildcard queries such as %ing or %benz%. The default is false.
Substring indexing has the following impact on indexing and disk resources:
substring_index enabled requires more rollback segments during index flushes than with substring index off. Oracle recommends that you do either of the following when creating a substring index:
Specify yes to enable prefix indexing. Prefix indexing improves performance for right truncated wildcard searches such as TO%. Defaults to NO.
Prefix indexing chops up tokens into multiple prefixes to store in the $I table.For example, words TOKEN and TOY are normally indexed like this in the $I table:
| Token | Type | Information |
|---|---|---|
|
TOKEN |
0 |
DOCID 1 POS 1 |
|
TOY |
0 |
DOCID 1 POS 3 |
With prefix indexing, Oracle indexes the prefix substrings of these tokens as follows with a new token type of 6:
| Token | Type | Information |
|---|---|---|
|
TOKEN |
0 |
DOCID 1 POS 1 |
|
TOY |
0 |
DOCID 1 POS 3 |
|
T |
6 |
DOCID 1 POS 1 POS 3 |
|
TO |
6 |
DOCID 1 POS 1 POS 3 |
|
TOK |
6 |
DOCID 1 POS 1 |
|
TOKE |
6 |
DOCID 1 POS 1 |
|
TOKEN |
6 |
DOCID 1 POS 1 |
|
TOY |
6 |
DOCID 1 POS 3 |
Wildcard searches such as TO% are now faster because Oracle does no expansion of terms and merging of result sets. To obtain the result, Oracle need only examine the (TO,6) row.
Specify the minimum length of indexed prefixes. Defaults to 1.
For example, setting prefix_length_min to 3 and prefix_length_max to 5 indexes all prefixes between 3 and 5 characters long.
|
Note: A wildcard search whose pattern is below the minimum length or above the maximum length is searched using the slower method of equivalence expansion and merging. |
Specify the maximum length of indexed prefixes. Defaults to 64.
For example, setting prefix_length_min to 3 and prefix_length_max to 5 indexes all prefixes between 3 and 5 characters long.
|
Note: A wildcard search whose pattern is below the minimum length or above the maximum length is searched using the slower method of equivalence expansion and merging. |
Specify the maximum number of terms in a wildcard (%) expansion. Use this parameter to keep wildcard query performance within an acceptable limit. Oracle returns an error when the wildcard query expansion exceeds this number.
The following example enables stemming and fuzzy matching for English. The preference STEM_FUZZY_PREF sets the number of expansions to the maximum allowed. This preference also instructs the system to create a substring index to improve the performance of double-truncated searches.
begin ctx_ddl.create_preference('STEM_FUZZY_PREF', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('STEM_FUZZY_PREF','FUZZY_MATCH','ENGLISH'); ctx_ddl.set_attribute('STEM_FUZZY_PREF','FUZZY_SCORE','0'); ctx_ddl.set_attribute('STEM_FUZZY_PREF','FUZZY_NUMRESULTS','5000'); ctx_ddl.set_attribute('STEM_FUZZY_PREF','SUBSTRING_INDEX','TRUE'); ctx_ddl.set_attribute('STEM_FUZZY_PREF','STEMMER','ENGLISH'); end;
To create the index in SQL, issue the following statement:
create index fuzzy_stem_subst_idx on mytable ( docs ) indextype is ctxsys.context parameters ('Wordlist STEM_FUZZY_PREF');
The following example sets the wordlist preference for prefix and sub-string indexing. For prefix indexing, it specifies that Oracle create token prefixes between 3 and 4 characters long:
begin ctx_ddl.create_preference('mywordlist', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('mywordlist','PREFIX_INDEX','TRUE'); ctx_ddl.set_attribute('mywordlist','PREFIX_MIN_LENGTH',3); ctx_ddl.set_attribute('mywordlist','PREFIX_MAX_LENGTH', 4); ctx_ddl.set_attribute('mywordlist','SUBSTRING_INDEX', 'YES');end
Use the wildcard_maxterms attribute to set the maximum allowed terms in a wildcard expansion.
--- create a sample table drop table quick ; create table quick ( quick_id number primary key, text varchar(80) ); --- insert a row with 10 expansions for 'tire%' insert into quick ( quick_id, text ) values ( 1, 'tire tirea tireb tirec tired tiree tiref tireg tireh tirei tirej') ; commit; --- create an index using wildcard_maxterms=100 begin Ctx_Ddl.Create_Preference('wildcard_pref', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('wildcard_pref', 'wildcard_maxterms', 100) ; end; / create index wildcard_idx on quick(text) indextype is ctxsys.context parameters ('Wordlist wildcard_pref') ; --- query on 'tire%' - should work fine select quick_id from quick where contains ( text, 'tire%' ) > 0; --- now re-create the index with wildcard_maxterms=5 drop index wildcard_idx ; begin Ctx_Ddl.Drop_Preference('wildcard_pref'); Ctx_Ddl.Create_Preference('wildcard_pref', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('wildcard_pref', 'wildcard_maxterms', 5) ; end; / create index wildcard_idx on quick(text) indextype is ctxsys.context parameters ('Wordlist wildcard_pref') ; --- query on 'tire%' gives "wildcard query expansion resulted in too many terms" select quick_id from quick where contains ( text, 'tire%' ) > 0;
Use the storage preference to specify tablespace and creation parameters for tables associated with a Text index. The system provides a single storage type called BASIC_STORAGE:
| type | Description |
|---|---|
|
BASIC_STORAGE |
Indexing type used to specify the tablespace and creation parameters for the database tables and indexes that constitute a Text index. |
The BASIC_STORAGE type specifies the tablespace and creation parameters for the database tables and indexes that constitute a Text index.
The clause you specify is added to the internal CREATE TABLE (CREATE INDEX for the i_index _clause) statement at index creation. You can specify most allowable clauses, such as storage, LOB storage, or partitioning. However, you cannot specify an index organized table clause.
| See Also:
For more information about how to specify |
BASIC_STORAGE has the following attributes:
By default, BASIC_STORAGE attributes are not set. In such cases, the Text index tables are created in the index owner's default tablespace. Consider the following statement, issued by user IUSER, with no BASIC_STORAGE attributes set:
create index IOWNER.idx on TOWNER.tab(b) indextype is ctxsys.context;
In this example, the text index is created in IOWNER's default tablespace.
The following examples specify that the index tables are to be created in the foo tablespace with an initial extent of 1K:
begin ctx_ddl.create_preference('mystore', 'BASIC_STORAGE'); ctx_ddl.set_attribute('mystore', 'I_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'K_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'R_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'N_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'I_INDEX_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'P_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); end;
In order to issue WITHIN queries on document sections, you must create a section group before you define your sections. You specify your section group in the parameter clause of CREATE INDEX.
To create a section group, you can specify one of the following group types with the CTX_DDL.CREATE_SECTION_GROUP procedure:
The following statement creates a section group called htmgroup with the HTML group type.
begin ctx_ddl_create_section_group('htmgroup', 'HTML_SECTION_GROUP'); end;
You can optionally add sections to this group using the CTX_DDL.ADD_SECTION procedure. To index your documents, you can issue a statement such as:
create index myindex on docs(htmlfile) indextype is ctxsys.context parameters('filter ctxsys.null_filter section group htmgroup');
The following statement creates a section group called xmlgroup with the XML_SECTION_GROUP group type.
begin ctx_ddl_create_section_group('xmlgroup', 'XML_SECTION_GROUP'); end;
You can optionally add sections to this group using the CTX_DDL.ADD_SECTION procedure. To index your documents, you can issue a statement such as:
create index myindex on docs(htmlfile) indextype is ctxsys.context parameters('filter ctxsys.null_filter section group xmlgroup');
The following statement creates a section group called auto with the AUTO_SECTION_GROUP group type. This section group automatically creates sections from tags in XML documents.
begin ctx_ddl_create_section_group('auto', 'AUTO_SECTION_GROUP');end; CREATE INDEX myindex on docs(htmlfile) INDEXTYPE IS ctxsys.context PARAMETERS('filter ctxsys.null_filter section group auto');
This section describes the classifier type used to create a preference for CTX_CLS.TRAIN.
Use the RULE_CLASSIFIER type for creating preferences for the rule generating procedure, CTX_CLS.TRAIN.
This type has the following attributes:
Stoplists identify the words in your language that are not to be indexed. In English, you can also identify stopthemes that are not to be indexed. By default, the system indexes text using the system-supplied stoplist that corresponds to your database language.
Oracle Text provides default stoplists for most languages including English, French, German, Spanish, Dutch, and Danish. These default stoplists contain only stopwords.
| See Also:
For more information about the supplied default stoplists, see Appendix D, "Supplied Stoplists". |
You can create multi-language stoplists to hold language-specific stopwords. A multi-language stoplist is useful when you use the MULTI_LEXER to index a table that contains documents in different languages, such as English, German, and Japanese.
To create a multi-language stoplist, use the CTX_DLL.CREATE_STOPLIST procedure and specify a stoplist type of MULTI_STOPLIST. You add language specific stopwords with CTX_DDL.ADD_STOPWORD.
At indexing time, the language column of each document is examined, and only the stopwords for that language are eliminated. At query time, the session language setting determines the active stopwords, like it determines the active lexer when using the multi-lexer.
You can create your own stoplists using the CTX_DLL.CREATE_STOPLIST procedure. With this procedure you can create a BASIC_STOPLIST for single language stoplist, or you can create a MULTI_STOPLIST for a multi-language stoplist.
When you create your own stoplist, you must specify it in the parameter clause of CREATE INDEX.
The default stoplist is always named CTXSYS.DEFAULT_STOPLIST. You can use the following procedures to modify this stoplist:
CTX_DDL.ADD_STOPWORDCTX_DDL.REMOVE_STOPWORDCTX_DDL.ADD_STOPTHEMECTX_DDL.ADD_STOPCLASSWhen you modify CTXSYS.DEFAULT_STOPLIST with the CTX_DDL package, you must re-create your index for the changes to take effect.
You can add stopwords dynamically to a default or custom stoplist with ALTER INDEX. When you add a stopword dynamically, you need not re-index, because the word immediately becomes a stopword and is removed from the index.
|
Note: Even though you can dynamically add stopwords to an index, you cannot dynamically remove stopwords. To remove a stopword, you must use |
When you install Oracle Text, some indexing preferences are created. You can use these preferences in the parameter clause of CREATE INDEX or define your own.
The default index parameters are mapped to some of the system-defined preferences described in this section.
| See Also:
For more information about default index parameters, see "Default Index Parameters" . |
System-defined preferences are divided into the following categories:
This preference uses the DIRECT_DATASTORE type. You can use this preference to create indexes for text columns in which the text is stored directly in the column.
This preference uses the FILE_DATASTORE type.
This preference uses the URL_DATASTORE type.
This preference uses the NULL_FILTER type.
This preference uses the INSO_FILTER type.
The default lexer depends on the language used at install time. The following sections describe the default settings for CTXSYS.DEFAULT_LEXER for each language.
If your language is English, this preference uses the BASIC_LEXER with the index_themes attribute disabled.
If your language is Danish, this preference uses the BASIC_LEXER with the following option enabled:
If your language is Dutch, this preference uses the BASIC_LEXER with the following options enabled:
If your language is German, this preference uses the BASIC_LEXER with the following options enabled:
mixed_case attribute enabled)composite attribute set to GERMAN)alternate_spelling attribute set to GERMAN)If your language is Finnish, Norwegian, or Swedish, this preference uses the BASIC_LEXER with the following option enabled:
If you language is Japanese, this preference uses the JAPANESE_VGRAM_LEXER.
If your language is Korean, this preference uses the KOREAN_MORPH_LEXER. All attributes for the KOREAN_MORPH_LEXER are enabled.
If your language is Simplified or Traditional Chinese, this preference uses the CHINESE_VGRAM_LEXER.
For all other languages not listed in this section, this preference uses the BASIC_LEXER with no attributes set.
| See Also:
To learn more about these options, see BASIC_LEXER . |
This preference uses the BASIC_LEXER.
This preference uses the NULL_SECTION_GROUP type.
This preference uses the HTML_SECTION_GROUP type.
This preference uses the AUTO_SECTION_GROUP type.
This preference uses the PATH_SECTION_GROUP type.
This stoplist preference defaults to the stoplist of your database language.
| See Also:
For a complete list of the stop words in the supplied stoplists, see Appendix D, "Supplied Stoplists". |
This stoplist has no words.
This storage preference uses the BASIC_STORAGE type.
This preference uses the language stemmer for your database language. If your language is not listed in Table 2-7, this preference defaults to the NULL stemmer and the GENERIC fuzzy matching attribute.
This section describes the Oracle Text system parameters. They fall into the following categories:
When you install Oracle Text, in addition to the system-defined preferences, the following system parameters are set:
| System Parameter | Description |
|---|---|
|
|
This is the maximum indexing memory that can be specified in the parameter clause of |
|
|
This is the default indexing memory used with |
|
|
This is the directory for |
|
|
This is the default input key type, either See also: CTX_DOC. SET_KEY_TYPE. |
You can view system defaults by querying the CTX_PARAMETERS view. You can change defaults using the CTX_ADM.SET_PARAMETER procedure.
This section describes the index parameters you can use when you create context and ctxcat indexes.
The following default parameters are used when you do not specify preferences in the parameter clause of CREATE INDEX when you create a context index. Each default parameter names a system-defined preference to use for data storage, filtering, lexing, and so on.
The following default parameters are used when you create a CTXCAT index with CREATE INDEX and do not specify any parameters in the parameter string. The CTXCAT index supports only the index set, lexer, storage, stoplist, and wordlist parameters. Each default parameter names a system-defined preference.
The following default parameters are used when you create a CTXRULE index with CREATE INDEX and do not specify any parameters in the parameter string. The CTXRULE index supports only the lexer, storage, stoplist, and wordlist parameters. Each default parameter names a system-defined preference.
You can view system defaults by querying the CTX_PARAMETERS view. For example, to see all parameters and values, you can issue:
SQL> SELECT par_name, par_value from ctx_parameters;
You can change a default value using the CTX_ADM.SET_PARAMETER procedure to name another custom or system-defined preference to use as default.
|
 Copyright © 1998, 2002 Oracle Corporation. All Rights Reserved. |
|

