| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|






|
View PDF |
| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|
|
View PDF |
The I/O subsystem is a vital component of an Oracle database. This chapter introduces fundamental I/O concepts, discusses the I/O requirements of different parts of the database, and provides sample configurations for I/O subsystem design.
This chapter includes the following topics:
The performance of many software applications is inherently limited by disk I/O. Applications that spend the majority of CPU time waiting for I/O activity to complete are said to be I/O-bound.
Oracle is designed so that if an application is well written, its performance should not be limited by I/O. Tuning I/O can enhance the performance of the application if the I/O system is operating at or near capacity and is not able to service the I/O requests within an acceptable time. However, tuning I/O cannot help performance if the application is not I/O-bound (for example, when CPU is the limiting factor).
Consider the following database requirements when designing an I/O system:
Many I/O designs plan for storage and availability requirements with the assumption that performance will not be an issue. This is not always the case. Optimally, the number of disks and controllers to be configured should be determined by I/O throughput and redundancy requirements. Then, the size of disks can be determined by the storage requirements.
For any database, the I/O subsystem is critical for system availability, performance, and data integrity. A weakness in any of these areas can render the database system unstable, unscalable, or untrustworthy.
All I/O subsystems use magnetic disk drives. Conventional magnetic disk drives contain moving parts. Because these moving parts have a design life, they are subject to tolerances in manufacturing that make their reliability and performance inconsistent. Not all drives that are theoretically identical perform the same, and they can break down over time. When assembling a large disk configuration, you need only to look at the mean time between failures (MTBF) of disk drives and the number of disks to see that disk failures are a common occurrence. This is unfortunate, because the core assets of any system (the data) reside on the disks.
The main component of any I/O subsystem, the disk drive, has barely changed over the last few years. The only changes are the increase in drive capacity from under 1 gigabyte to over 50 gigabytes, and small improvements in disk access time (rpm) and, hence, throughput. Improvements made in CPUs, on the other hand, have doubled their performance every 18 months.
There is a disk drive paradox that says that if you size the number of disks required by disk capacity, then you need fewer and fewer disks over time, because the disks increase in size. However, if you size the number of disks by performance, then you must double the number of disks for each CPU every 18 months. Dealing with this paradox has proved to be a problem in many system configurations, especially those designed to be cheaper by using fewer disks.
In addition to the size of the actual disks manufactured, the way disk subsystems are connected has changed. On smaller systems, in general, disk drives are connected individually to the host machine by small computer system interfaces (SCSI) through one of a number of disk controllers. For high-end systems, disk mirroring and striping are essential for performance and availability. These requirements lead to hundreds of disks connected through complex wiring configurations.
However, although disk technology itself has not greatly changed, I/O subsystems have evolved into disk arrays that overcome many of the described problems. The systems perform disk mirroring, provide hot swapping of disks, and in many cases, provide simpler connections to the host by fiber interfaces. The more sophisticated disk arrays are, in fact, small computers themselves with their own CPU, battery-backed memory cache for high-performance resilient writes, dial-home diagnostics, and proxy backup to allow backup without going through the host operating system.
Disk contention occurs when multiple processes try to access the same disk simultaneously. Most disks have limits on both the number of accesses (I/O operations each second) and the amount of data they can transfer each second (I/O data rate, or throughput). When these limits are reached, processes must wait to access the disk.
A performance engineer's goal is to distribute the I/O load evenly across the available devices. This is known as load balancing or distributing I/O. Historically, load balancing had to be performed manually. Database administrators would determine the I/O requirements and characteristics of each datafile and design the I/O layout based on which files could be placed together on a single disk to distribute the activity evenly over all disks.
If a particular table or index was I/O-intensive, then to further distribute the I/O load, DBAs also had the option of manually distributing, or striping, the data. This was achieved by splitting the object's extents over separate datafiles, then distributing the datafiles over devices.
Fundamentally, striping divides data into small portions and stores these portions in separate files on separate disks. This allows multiple processes to access different portions of the data concurrently without disk contention. Operating systems, hardware vendors, and third-party software vendors provide the tools for striping a heavily used file across many physical devices simply, thus making the job of balancing I/O significantly easier for DBAs.
Striping is helpful both in OLTP environments, to optimize random access to tables with many rows, and also in DSS environments, to allow parallel operations to scan large volumes of data quickly. Striping techniques are productive when the load redistribution eliminates or reduces some form of queue. Striping files can also improve RMAN backup and restore performance.
If the concurrent load is too heavy for the available hardware, then striping does not alleviate the problem.
You must also consider the recoverability requirements of each particular system. Configurations with redundant arrays of inexpensive disks (RAID) provide improved data reliability, while offering the option of striping. The RAID level chosen should depend on performance and cost. Different RAID levels are suited to different types of applications, depending on their I/O characteristics.
The following list provides a brief overview of the most popular RAID configurations used for database files, along with the applications that best suit them. These descriptions are very general. Consult with your hardware and software vendors for details about implementing a specific configuration:
Files are striped across many physical disks. This configuration provides read and write performance, but not reliability.
Physical disks are used to store a specified number n of concurrently maintained copies of a file. The number of disks required is n times m, where m is the number of disks required to store the original files. RAID 1 provides good reliability and good read rates. Sometimes, writes can be costly, because n writes are required to maintain n copies.
This level combines the technologies of RAID 0 and RAID 1. It is widely used because it provides good reliability and better read and write performance than RAID 1.
RAID 5 striping is similar to striping in RAID 0. Recoverability of lost data due to disk failure is achieved by storing parity data regarding all disks in a stripe, with storage uniform throughout disks in the group. Compared to RAID 1, the benefit is the saving in disk cost. RAID 5 provides good reliability. Sequential reads benefit the most, while write performance can suffer. This configuration might not be ideal for write-intensive applications.
Recent RAID 5 implementations avoid many of the traditional RAID 5 limits by installing large amounts of battery-backed memory (NVRAM). The cache offsets the performance penalty in two ways:
The drawbacks are:
The choice of I/O subsystem and how to design the layout is an exercise in balancing budget, performance, and availability. It is essential to be able to expand the I/O subsystem as throughput requirements grow and more I/O is performed. To achieve a scalable I/O system, the chosen system must be able to evolve over time, with a minimum of downtime. In many cases, this involves configuring the system to achieve 95% optimal performance, forsaking 5% performance for ease of configuration and eventual upgrades.
This section describes the basic information to be gathered and decisions to be made when defining a system's I/O configuration. You want to keep the configuration as simple as possible, while maintaining the required availability, recoverability, and performance. The more complex a configuration becomes, the more difficult it is to administer, maintain, and tune.
This section describes the basic I/O characteristics and requirements that must be determined. These I/O characteristics influence decisions on the type of technology required and how to configure that technology. I/O requirements include the performance, space, and recoverability needs specific to the site.
To design an efficient I/O subsystem, you need the following information:
When defining a system's I/O configuration, you need to take into account the maximum load that will be generated by parallel operations such as parallel index creation and parallel scans. You only get one chance to configure your disks, and if enough load distribution is not built in, then parallel operations will not scale. This is especially important for log and archive disks.
The read rate is the number of reads each second. The write rate is the number of writes each second. The sum of the read rate and the write rate is the I/O rate (the number of I/O operations each second). For a system that performs well, your application's I/O rate should be a significant factor when determining the absolute minimum number of disks and controllers required.
A system that has a high write rate might also benefit from the following configuration options:
I/O concurrency measures the number of distinct processes that simultaneously have I/O requests to the I/O subsystem. From an Oracle perspective, I/O concurrency is considered the number of processes concurrently issuing I/O requests. A high degree of I/O concurrency implies that there are many distinct processes simultaneously issuing I/O requests. A low degree of concurrency implies that few processes are simultaneously issuing I/O requests.
|
Note: High I/O rate systems are typified by high concurrency and small block requests. High data rate systems are typified by low concurrency and large block requests. |
I/O size is the size of the I/O request from Oracle's perspective. The minimum I/O size is the operating system block size, while the maximum is typically a factor of the Oracle block size multiplied by the multiblock read count.
Although the I/O size can vary depending on the type of operation, there are some reasonable, general estimates that can be made, depending on the nature of the application.
DB_BLOCK_SIZE.DB_BLOCK_SIZE.In an Oracle system, the various files have different requirements of the disk subsystem. The requirements are distinguished by the rate of reading and writing of data and by the concurrency of these operations. High rates are relatively easily sustained by the disk subsystem when the concurrency is low. It is important that design of the disk subsystem take the following factors into consideration:
TEMP tablespace than a site that performs predominantly small, in-memory sorts.
Table 15-1 shows the read and write rate and concurrency for a theoretical installation. The example describes a high-query, high-update OLTP application that performs predominantly in-memory sorts, with indexes that remain cached in the buffer cache.
Site-specific availability requirements impose additional specifications on the disk storage technology and layout. Typical considerations include the appropriate RAID technology to meet recoverability requirements and any Oracle-specific safety measures, such as mirroring of redo logs, archive logs, and control files.
Dedicating separate disks to mirroring redo log files is an important safety precaution. This ensures that the datafiles and the redo log files cannot both be lost in a single disk failure.
| See Also:
Oracle9i User-Managed Backup and Recovery Guide for more information on recoverability |
With the large disks available today, if the performance and availability requirements are satisfied, then in most cases the storage needs have already been met. If, however, the system stores voluminous data online, and the data does not have high concurrency or throughput requirements, then you can fall short of storage requirements. In such cases, you need to consider the following methods of maximizing storage space:
Depending on the hardware and software available, you should determine the following system characteristics during the I/O layout phase:
To maximize performance, the goal of system configuration should be to distribute the I/O load for the database as evenly as possible over the available disks.
In addition to distributing I/O, other configuration concerns should include the expected growth on the system and the required recoverabilty.
You should be aware of the capabilities of the I/O system. This information is available by reviewing hardware and software documentation (if applicable), and also by performing tests at your site. Tests can include varying any of the following factors:
Performing this type of research can provide insight into potential configurations that can be used for the final design.
If you have a benchmark that simulates the load placed on the I/O system by the application, or if there is an existing production system, then look at the Oracle statistics to determine the I/O rates for each file and for the database as a whole.
| See Also:
Oracle9i Database Performance Planning for more information on operating system I/O statistics |
To determine the Oracle file I/O statistics, look at the following:
V$FILESTAT.PHYRDS)V$FILESTAT.PHYWRTS)Assuming that the Oracle buffer cache is adequately sized, the physical reads and physical writes statistics are useful.
Another important statistic is the average number of I/Os each second. To determine this number, sample the V$FILESTAT data over an interval, add the physical reads and writes, and then divide this total by the elapsed time in seconds. The general formula is as follows:
Average I/O per second = (physical reads + physical writes) / elapsed seconds
| See Also:
Chapter 24, "Dynamic Performance Views for Tuning" for details on how to calculate the delta information in |
To estimate the I/O requirements, scale the I/O statistics with the expected workload on the new system. Comparing the scaled data with the disk capabilities can potentially identify whether there will be a mismatch between the I/O requirements of the new application and the capabilities of the I/O system.
Also identify any I/O-intensive operations that are not part of the typical load and have I/O rates that greatly peak over the average. Ensure that your system is able to sustain these rates. Operations such as index builds, data loads, and batch processing fall into this category.
| See Also:
Chapter 24, "Dynamic Performance Views for Tuning" for details on how to calculate the delta information in |
With Oracle9i Release 2 (9.2), you can use the FILESYSTEMIO_OPTIONS initialization parameter to enable or disable asynchronous I/O or direct I/O on file system files. This parameter is platform-specific and has a default value that is best for a particular platform. It can be dynamically changed to update the default setting.
If your operating system has LVM software or hardware-based striping, then it is possible to distribute I/O using these tools. Decisions to be made when using an LVM or hardware striping include stripe depth and stripe width.
Choose these values wisely so that the system is capable of sustaining the required throughput. For an Oracle database, reasonable stripe depths range from 256 KB to 4 MB. Different types of applications benefit from different stripe depths. The optimal stripe depth and stripe width depend on the following:
Table 15-2 lists the Oracle and operating system parameters that you can use to set I/O size:
In addition to I/O size, the degree of concurrency also helps in determining the ideal stripe depth. Consider the following when choosing stripe width and stripe depth:
In a system with a high degree of concurrent small I/O requests, such as in a traditional OLTP environment, it is beneficial to keep the stripe depth large. Using stripe depths larger than the I/O size is called coarse grain striping. In high-concurrency systems, the stripe depth can be
n * DB_BLOCK_SIZE
where n is greater than 1.
Coarse grain striping allows a disk in the array to service several I/O requests. In this way, a large number of concurrent I/O requests can be serviced by a set of striped disks with minimal I/O setup costs. Coarse grain striping strives to maximize overall I/O throughput. Multiblock reads, as in full table scans, will benefit when stripe depths are large and can be serviced from one drive. Parallel query in a DSS environment is also a candidate for coarse grain striping. This is because there are many individual processes, each issuing separate I/Os. If coarse grain striping is used in systems that do not have high concurrent requests, then hot spots could result.
In a system with a few large I/O requests, such as in a traditional DSS environment or a low-concurrency OLTP system, then it is beneficial to keep the stripe depth small. This is called fine grain striping. In such systems, the stripe depth is
n * DB_BLOCK_SIZE
where n is smaller than the multiblock read parameters (such as DB_FILE_MULTIBLOCK_READ_COUNT).
Fine grain striping allows a single I/O request to be serviced by multiple disks. Fine grain striping strives to maximize performance for individual I/O requests or response time.
On some Oracle ports, an Oracle block boundary may not align with the stripe. If your stripe depth is the same size as the Oracle block, then a single I/O issued by Oracle might result in two physical I/O operations.
This is not optimal in an OLTP environment. To ensure a higher probability of one logical I/O resulting in no more than one physical I/O, the minimum stripe depth should be at least twice the Oracle block size. Table 15-3 shows recommended minimum stripe depth for random access and for sequential reads.
The transfer rate for a disk drive is not the same for all portions of a disk. The outer sectors of a disk drive move the disk head faster than the inner sectors, leading to a faster transfer rate for the outer sectors.
The outside portions of a disk drive hold more data than the inside portions.
The transfer rate of a disk drive can vary by a factor of two from the inner edge of the drive to the outer edge. It is therefore beneficial to place frequently accessed data toward the outer edge of a disk drive.
With an LVM, the simplest configuration to manage is one with a single striped volume over all available disks. In this case, the stripe width encompasses all available disks. All database files reside within that volume, effectively distributing the load evenly. This single-volume layout provides adequate performance in most situations.
A single-volume configuration is viable only when used in conjunction with RAID technology that allows easy recoverability, such as RAID 1. Otherwise, losing a single disk means losing all files concurrently and, hence, performing a full database restore and recovery.
In addition to performance, there is a manageability concern: the design of the system must allow disks to be added simply, to allow for database growth. The challenge is to do so while keeping the load balanced evenly.
For example, an initial configuration can involve the creation of a single striped volume over 64 disks, each disk being 16 GB. This is total disk space of 1 terabyte (TB) for the primary data. Sometime after the system is operational, an additional 80 GB (that is, five disks) must be added to account for future database growth.
The options for making this space available to the database include creating a second volume that includes the five new disks. However, an I/O bottleneck might develop, if these new disks are unable to sustain the I/O throughput required for the files placed on them.
Another option is to increase the size of the original volume. LVMs are becoming sophisticated enough to allow dynamic reconfiguration of the stripe width, which allows disks to be added while the system is online. This begins to make the placement of all files on a single striped volume feasible in a production environment.
If your LVM is unable to support dynamically adding disks to the stripe, then it is likely that you need to choose a smaller, more manageable stripe width. Then, when new disks are added, the system can grow by a stripe width.
In the preceding example, eight disks might be a more manageable stripe width. This is only feasible if eight disks are capable of sustaining the required number of I/Os each second. Thus, when extra disk space is required, another eight-disk stripe can be added, keeping the I/O balanced across the volumes.
If your system does not have an LVM or hardware striping, then I/O must be manually balanced across the available disks by distributing the files according to each file's I/O requirements. In order to make decisions on file placement, you should be familiar with the I/O requirements of the database files and the capabilities of the I/O system. If you are not familiar with this data and do not have a representative workload to analyze, you can make a first guess and then tune the layout as the usage becomes known.
To stripe disks manually, you need to relate a file's storage requirements to its I/O requirements.
One popular approach to manual I/O distribution suggests separating a frequently used table from its index. This is not correct. During the course of a transaction, the index is read first, and then the table is read. Because these I/Os occur sequentially, the table and index can be stored on the same disk without contention. It is not sufficient to separate a datafile simply because the datafile contains indexes or table data. The decision to segregate a file should be made only when the I/O rate for that file affects database performance.
Regardless of whether you use operating system striping or manual I/O distribution, if the I/O system or I/O layout is not able to support the I/O rate required, then you need to separate files with high I/O rates from the remaining files. You can identify such files either at the planning stage or after the system is live.
The decision to segregate files should only be driven by I/O rates, recoverability concerns, or manageability issues. (For example, if your LVM does not support dynamic reconfiguration of stripe width, then you might need to create smaller stripe widths to be able to add n disks at a time to create a new stripe of identical configuration.)
Before segregating files, verify that the bottleneck is truly an I/O issue. The data produced from investigating the bottleneck identifies which files have the highest I/O rates.
If the files with high I/O are datafiles belonging to tablespaces that contain tables and indexes, then identify whether the I/O for those files can be reduced by tuning SQL or application code.
If the files with high-I/O are datafiles that belong to the TEMP tablespace, then investigate whether to tune the SQL statements performing disk sorts to avoid this activity, or to tune the sorting.
After the application has been tuned to avoid unnecessary I/O, if the I/O layout is still not able to sustain the required throughput, then consider segregating the high-I/O files.
If the high-I/O files are redo log files, then consider splitting the redo log files from the other files. Possible configurations can include the following:
Redo log files are written sequentially by the Log Writer (LGWR) process. This operation can be made faster if there is no concurrent activity on the same disk. Dedicating a separate disk to redo log files usually ensures that LGWR runs smoothly with no further tuning necessary. If your system supports asynchronous I/O but this feature is not currently configured, then test to see if using this feature is beneficial. Performance bottlenecks related to LGWR are rare.
If the archiver is slow, then it might be prudent to prevent I/O contention between the archiver process and LGWR by ensuring that archiver reads and LGWR writes are separated. This is achieved by placing logs on alternating drives.
For example, suppose a system has four redo log groups, each group with two members. To create separate-disk access, the eight log files should be labeled 1a, 1b, 2a, 2b, 3a, 3b, 4a, and 4b. This requires at least four disks, plus one disk for archived files.
Figure 15-1 illustrates how redo members should be distributed across disks to minimize contention.
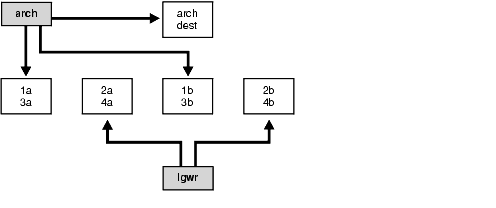
In this example, LGWR switches out of log group 1 (member 1a and 1b) and writes to log group 2 (2a and 2b). Concurrently, the archiver process reads from group 1 and writes to its archive destination. Note how the redo log files are isolated from contention.
Because redo logs are written serially, drives dedicated to redo log activity generally require limited head movement. This significantly accelerates log writing.
This section contains three high-level examples of configuring I/O systems. These examples include sample calculations that define the disk topology, stripe depths, and so on.
The simplest approach to I/O configuration is to build one giant volume, striped across all available disks. To account for recoverability, the volume is mirrored (RAID 1). The striping unit for each disk should be larger than the maximum I/O size for the frequent I/O operations. This provides adequate performance for most cases.
If archive logs are striped on the same set of disks as other files, then any I/O requests on those disks could suffer when redo logs are being archived. Moving archive logs to separate disks provides the following benefits:
The number of disks for archive logs is determined by the rate of archive log generation and the amount of archive storage required.
In high-update OLTP systems, the redo logs are write-intensive. Moving the redo log files to disks that are separate from other disks and from archived redo log files has the following benefits:
The number of disks for redo logs is mostly determined by the redo log size, which is generally small compared to current technology disk sizes. Typically, a configuration with two disks (possibly mirrored to four disks for fault tolerance) is adequate. In particular, by having the redo log files alternating on two disks, writing redo log information to one file does not interfere with reading a completed redo log for archiving.
For systems where a file system can be used to contain all Oracle data, database administration is simplified by using Oracle-managed files. Oracle internally uses standard file system interfaces to create and delete files as needed for tablespaces, temp files, online logs, and control files. Administrators only specify the file system directory to be used for a particular type of file. You can specify one default location for datafiles and up to five multiplexed locations for the control and online redo log files.
Oracle ensures that a unique file is created and then deleted when it is no longer needed. This reduces corruption caused by administrators specifying the wrong file, reduces wasted disk space consumed by obsolete files, and simplifies creation of test and development databases. It also makes development of portable third-party tools easier, because it eliminates the need to put operating-system specific file names in SQL scripts.
New files can be created as managed files, while old ones are administered in the old way. Thus, a database can have a mixture of Oracle-managed and manually managed files.
Several points should be considered when tuning Oracle-managed files.
| See Also:
Oracle9i Database Administrator's Guide for detailed information on using Oracle-managed files |
This section lists considerations when choosing database block size for optimal performance.
Regardless of the size of the data, the goal is to minimize the number of reads required to retrieve the desired data.
For high-concurrency OLTP systems, consider appropriate values for INITRANS, MAXTRANS, and FREELISTS when using a larger block size. These parameters affect the degree of update concurrency allowed within a block. However, you do not need to specify the value for FREELISTS when using automatic segment-space management.
If you are uncertain about which block size to choose, then try a database block size of 8 KB for most systems that process a large number of transactions. This represents a good compromise and is usually effective. Only systems processing LOB data need more than 8 KB.
Figure 15-2 illustrates the suitability of various block sizes to OLTP or DSS applications.

| See Also:
The Oracle documentation specific to your operating system for information on the minimum and maximum block size on your platform |
Table 15-4 lists the advantages and disadvantages of different block sizes.
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

