| Oracle® High Availability Architecture and Best Practices 10g Release 1 (10.1) Part Number B10726-01 |
|






|
View PDF |
| Oracle® High Availability Architecture and Best Practices 10g Release 1 (10.1) Part Number B10726-01 |
|
|
View PDF |
Oracle has introduced the Hardware Assisted Resilient Data (HARD) Initiative, which is a program designed to prevent data corruptions before they happen. Data corruptions are very rare, but when they happen, they can have a catastrophic effect on a database, and therefore a business.
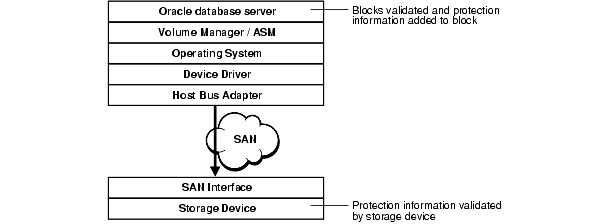
Under the HARD Initiative, Oracle continues to work with selected system and storage vendors to build operating system and storage components that can detect corruptions early and prevent corrupted data from being written to disk. The kay approach is block checking where the storage subsystem validates the Oracle block contents. Implementation of this feature is transparent to the end user or DBA, regardless of the hardware vendor.
To use HARD validation, all datafiles and log files are placed on HARD-compliant storage. The user must also enable the HARD validation feature on the storage, using the vendor-provided interface. When Oracle writes data to the storage, the storage system validates the data. If it appears to be corrupted, then the write is rejected with an error.
Text description of the illustration maxav029.gif
Data corruption may occur due to many reasons: a bit-flip on a disk; a software bug in a database, an operating system, a storage area network (SAN), or a storage system. If not prevented or repaired, data corruptions can bring down a database or cause key business data to be lost.
Oracle provides sophisticated techniques for detecting data corruptions and recoverying from them. These techniques include block-level recovery, automated backup and restore, tablespace point-in-time recovery, remote standby databases, and transactional recovery. However, recovering from a corruption can take a long time. Furthermore, corruptions to critical data can cause the entire database to fail. It is better to prevent the data corruption in the first place. HARD provides the mechanism that prevents business data from becoming corrupted
Oracle's Maximum Availability Architecture (MAA) describes an infrastructure that reduces the impact of outages using Oracle RAC, Oracle Data Guard, and HARD.
The HARD program defines multiple levels of protection. Oracle storage partners may choose to implement firmware or hardware checks that can prevent the following types of corruptions:
Data that is corrupted by some intervening operating system or hardware component after the data was written by Oracle and before it reaches the disk. These components might include the operating system, file system, the volume manager, device driver, the host bus adapter, and the SAN switching fabric. Though Oracle can detect the corruption when reading the data back, Oracle may not read the data until days or months later. By then, a good backup for recovering the data may no longer be available.
Oracle issues a write to a specific location on disk. Somehow the operating system or storage system writes the blocks to the wrong location. This can cause two corruptions: corrupting valid data on the disk and losing the data from the committed transaction.
Oracle datafiles might be overwritten by non-Oracle applications. A non-Oracle process or program may accidentally overwrite the contents of an Oracle datafile. This can be either because of a bug in the application software, operating system, or human error (for example, accidentally copying a normal operating system file over an Oracle datafile).
Data corruptions can occur when backups are copied to tape. This type of corruption is particularly pernicious because the backups are used to repair data corruptions. So if the backups are also corrupted, then there is no way to recover any lost data. This is especially true for third-party backups (in which the disk storage unit directly copies data to the backup device without going through Oracle.)
In a storage system where the Oracle HARD functionality is implemented, the Oracle server can validate the Oracle block structure, block integrity, and block location with numerous checks. If a block fails validation when it is written, then the storage rejects the write and thereby protects the integrity of the data. The HARD validation checks can also be selectively disabled during system management operations that may temporarily leave data in an inconsistent state.
The following Oracle objects can be validated during I/O writes:
DBAs and system administrators using HARD should be aware that a HARD error will be reported back through to the ORACLE instance as an I/O error. System administrators must carefully check the system log to check for HARD-enabled storage before starting any recovery actions.
Automatic storage management (ASM) rebalancing is currently not supported with HARD implementations. ASM rebalancing moves the complete disk block, which may be larger than the datablock and have spurious characters not covered by HARD checking. This would cause a false HARD validation error.
Storage vendors may choose to implement some or all of the checks in their implementation. Also, each vendor's implementation is unique and their control interfaces may have different features. Please check with the HARD Initiative page for the latest vendor and implementation information.
http://otn.oracle.com/deploy/availability/index.html
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

