| Oracle® High Availability Architecture and Best Practices 10g Release 1 (10.1) Part Number B10726-01 |
|






|
View PDF |
| Oracle® High Availability Architecture and Best Practices 10g Release 1 (10.1) Part Number B10726-01 |
|
|
View PDF |
This chapter describes how to restore redundancy to your environment after a failure. It includes the following topics:
Whenever a component within an HA architecture fails, then the full protection, or fault tolerance, of the architecture is compromised and possible single points of failure exist until the component is repaired. Restoring the HA architecture to full fault tolerance to reestablish full RAC, Data Guard, or MAA protection requires repairing the failed component. While full fault tolerance may be sacrificed during a scheduled outage, the method of repair is well understood because it is planned, the risk is controlled, and it ideally occurs at times best suited for continued application availability. However, for unscheduled outages, the risk of exposure to a single point of failure must be clearly understood.
This chapter describes the steps needed to restore database fault tolerance. It includes the following topics:
For RAC environments:
For Data Guard and MAA environments:
Ensuring that application services fail over quickly and automatically within a RAC cluster, or between primary and secondary sites, is important when planning for both scheduled and unscheduled outages. It is also important to understand the steps and processes for restoring failed instances or nodes within a RAC cluster or databases between sites, to ensure that the environment is restored to full fault tolerance after any errors or issues are corrected.
Adding a failed node back into the cluster or restarting a failed RAC instance is easily done after the core problem that caused the specific component to originally fail has been corrected. However, the following are additional considerations.
How an application runs within a RAC environment (similar to initial failover) also dictates how to restore the node or instance, as well as whether to perform other processes or steps.
After the problem that caused the initial node or instance failure has been corrected, a node or instance can be restarted and added back into the RAC environment at any time. However, there may be some performance impact on the current workload when rejoining the node or instance. Table 11-1 summarizes the performance impact of restarting or rejoining a node or instance.
Therefore, it is important to consider the following when restoring a node or RAC instance:
See Also:
|
The rest of this section includes the following topics:
After a failed node has been brought back into the cluster and its instance has been started, RAC's Cluster Ready Services (CRS) automatically manages the virtual IP address used for the node and the services supported by that instance automatically. A particular service may or may not be started for the restored instance. The decision by CRS to start a service on the restored instance depends on how the service is configured and whether the proper number of instances are currently providing access for the service. A service is not relocated back to a preferred instance if the service is still being provided by an available instance to which it was moved by CRS when the initial failure occurred. CRS restarts services on the restored instance if the number of instances that are providing access to a service across the cluster is less than the number of preferred instances defined for the service. After CRS restarts a service on a restored instance, CRS notifies registered applications of the service change.
For example, suppose the HR service is defined with instances A and B as preferred and instances C and D as available in case of a failure. If instance B fails and CRS starts up the HR service on C automatically, then when instance B is restarted, the HR service remains at instance C. CRS does not automatically relocate a service back to a preferred instance.
Suppose a different scenario in which the HR service is defined with instances A, B, C, and D as preferred and no instances defined as available, spreading the service across all nodes in the cluster. If instance B fails, then the HR service remains available on the remaining three nodes. CRS automatically starts the HR service on instance B when it rejoins the cluster because it is running on fewer instances than configured. CRS notifies the applications that the HR service is again available on instance B.
After a RAC instance has been restored, additional steps may be required, depending on the current resource utilization and performance of the system, the application configuration, and the network load balancing that has been implemented.
Existing connections (which may have failed over or started as a new session) on the surviving RAC instances, are not automatically redistributed or failed back to an instance that has been restarted. Failing back or redistributing users may or may not be necessary, depending on the current resource utilization and the capability of the surviving instances to adequately handle and provide acceptable response times for the workload. If the surviving RAC instances do not have adequate resources to run a full workload or to provide acceptable response times, then it may be necessary to move (disconnect and reconnect) some existing user connections to the restarted instance.
New connections are started as they are needed, on the least-used node, assuming connection load balancing has been configured. Therefore, the new connections are automatically load-balanced over time.
An application service can be:
This is valuable for modularizing application and database form and function while still maintaining a consolidated data set. For the cases where an application is partitioned or has a combination of partitioning and non-partitioning, the response time and availability aspects for each service should be considered. If redistribution or failback of connections for a particular service is required, then you can rebalance workloads manually with the DBMS_SERVICE.disconnect_session PL/SQL procedure. You can use this procedure to disconnect sessions associated with a service while the service is running.
For load-balancing application services across multiple RAC instances, Oracle Net connect-time failover and connection load balancing are recommended. This feature does not require changes or modifications for failover or restoration. It is also possible to use hardware-based load balancers. However, there may be limitations in distinguishing separate application services (which is understood by Oracle Net Services) and restoring an instance or a node. For example, when a node or instance is restored and available to start receiving new connections, a manual step may be required to include the restored node or instance in the hardware-based load balancer logic, whereas Oracle Net Services does not require manual reconfiguration.
Table 11-2 summarizes the considerations for new and existing connections after an instance has been restored. The considerations differ depending on whether the application services are partitioned, nonpartitioned, or have a combination of each type. The actual redistribution of existing connections may or may not be required depending on the resource utilization and response times.
Figure 11-1 shows a 2-node partitioned RAC database. Each instance services a different portion of the application (HR and Sales). Client processes connect to the appropriate instance based on the service they require.
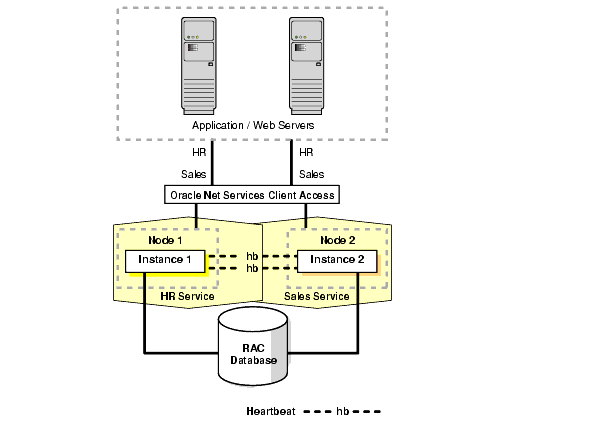
Text description of the illustration maxav015.gif
Figure 11-2 shows what happens when one RAC instance fails.
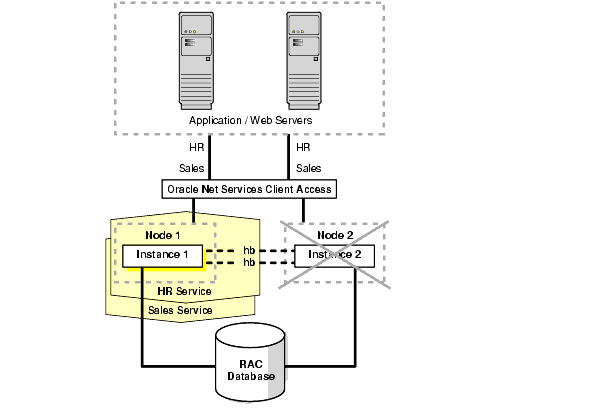
Text description of the illustration maxav016.gif
If one RAC instance fails, then the service and existing client connections can be automatically failed over to another RAC instance. In this example, the HR and Sales services are both supported by the remaining RAC instance. In addition, new client connections for the Sales service can be routed to the instance now supporting this service.
After the failed instance has been repaired and restored to the state shown in Figure 11-1 and the Sales service is relocated to the restored instance failed-over clients and any new clients that had connected to the Sales service on the failed-over instance may need to be identified and failed back. New client connections, which are started after the instance has been restored, should automatically connect back to the original instance. Therefore, over time, as older connections disconnect, and new sessions connect to the Sales service, the client load migrates back to the restored instance. Rebalancing the load immediately after restoration depends on the resource utilization and application response times.
Figure 11-3 shows a nonpartitioned application. Services are evenly distributed across both active instances. Each instance has a mix of client connections for both HR and Sales.
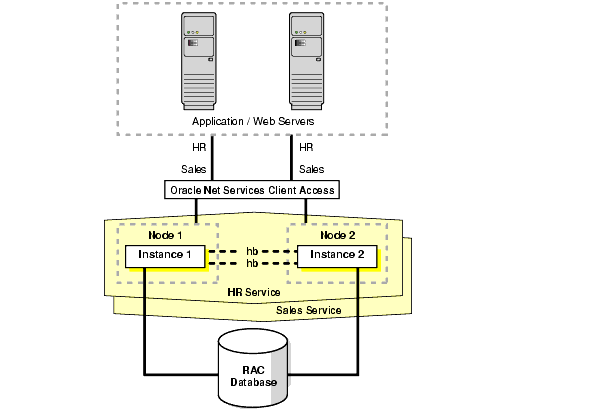
Text description of the illustration maxav017.gif
If one RAC instance fails, then CRS moves the services that were running on the failed instance. In addition, new client connections are routed only to the available RAC instances that offer that service.
After the failed instance has been repaired and restored to the state shown in Figure 11-3, some clients may need to be moved back to the restored instance. For nonpartitioned applications, identifying appropriate services is not required for rebalancing the client load among all available instances. Also, this is necessary only if a single instance is not able to adequately service the requests.
New client connections that are started after the instance has been restored should automatically connect back to the restored instance because it has a smaller load. Therefore, over time, as older connections disconnect and new sessions connect to the restored instance, the client load will again evenly balance across all available RAC instances. Rebalancing the load immediately after restoration depends on the resource utilization and application response times.
Following an unplanned production database outage that requires a failover, full fault tolerance is compromised until the physical or logical standby database is reestablished. Full database protection should be restored as soon as possible. Steps for restoring fault tolerance differ slightly for physical and logical standby databases.
Standby databases do not need to be reinstantiated because of Oracle's Flashback Database feature. Flashback Database:
This section includes the following topics:
The following steps are required to restore a physical standby database after a failover. The steps assume that archived redo logs and sufficient flashback log data are available.
From the new production database, execute the following query:
SELECT TO_CHAR(STANDBY_BECAME_PRIMARY_SCN) FROM V$DATABASE;
Use this SCN to convert the previous production database to a standby database.
Log on to the previous production database and execute the following statements:
SHUTDOWN IMMEDIATE; /*if necessary */ STARTUP MOUNT; FLASHBACK DATABASE TO SCN standby_became_primary_scn;
If there is insufficient flashback data, then see Oracle Data Guard Concepts and Administration about creating a new standby database.
Mounting the new standby database requires the following substeps:
ALTER DATABASE FLASHBACK OFF;
ALTER DATABASE CREATE STANDBY CONTROLFILE AS controlfile_name; SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
LSNRCTL STAT list_name;
Before the new standby database was created, the current production remote standby archive destination probably stopped with an error and is no longer shipping files to the remote destination. To restart remote archiving, you may have to reenable the standby archive destination.
Query the V$ARCHIVE_DEST_STATUS view to see the current state of the archive destinations.
SELECT DEST_ID, DEST_NAME, STATUS, PROTECTION_MODE, DESTINATION, ERROR, SRL FROM V$ARCHIVE_DEST_STATUS;
Enable the remote archive destination.
ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_n=ENABLE;
Switch a redo log file and verify that it was sent successfully.
ALTER SYSTEM SWITCH LOGFILE; SELECT DEST_ID, DEST_NAME, STATUS, PROTECTION_MODE, DESTINATION, ERROR, SRL FROM V$ARCHIVE_DEST_STATUS;
Shipping the archived redo log from the new production database notifies the standby database of the new production database incarnation number.
Start managed recovery or real-time apply managed recovery with one of the following statements:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT;
or
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT;
Ensure that recovery is applying the archived redo logs.
SELECT * FROM V$MANAGED_STANDBY;
The managed recovery process (MRP) stops after it encounters the end-of-redo marker that demarcates when the Data Guard failover was completed in the redo stream. This is not an error. Restart MRP, and it will continue with no problem.
The following steps are required to restore a logical standby database after a failover:
On the new production database, query for the SCN at which the previous standby database became the new production database.
SELECT VALUE AS TO_CHAR(STANDBY_BECAME_PRIMARY_SCN) FROM DBA_LOGSTDBY_PARAMETERS WHERE NAME = 'END_PRIMARY_SCN';
You can create a new logical standby database by mounting the previous production database, flashing it back to STANDBY_BECAME_PRIMARY_SCN, and then enabling the previous guard level setting.
SHUTDOWN IMMEDIATE; STARTUP MOUNT; FLASHBACK DATABASE TO SCN standby_became_primary_scn; ALTER DATABASE GUARD [ALL | STANDBY | NONE];
ALTER DATABASE OPEN RESETLOGS; ALTER DATABASE START LOGICAL STANDBY APPLY NEW PRIMARY dblink;
You need to create a database link from the new logical standby database to the new production database if it does not already exist. Use the following syntax:
CREATE PUBLIC DATABASE LINK dblink CONNECT TO system IDENTIFIED BY password USING 'service_name_of_new_primary_database';
The following steps are required to restore full fault tolerance after a scheduled secondary site or clusterwide outage:
You may have to restore the standby database from local backups, local tape backups, or from the primary site backups if the data in the secondary site has been damaged. Re-create the standby database from the new production database by following the steps for creating a standby database in Oracle Data Guard Concepts and Administration.
After the standby database has been reestablished, start the standby database.
| Type of Standby Database | SQL Statement |
|---|---|
|
Physical |
|
|
Logical |
|
| Type of Standby Database | SQL Statement |
|---|---|
|
Physical |
|
|
Logical |
|
You may have to reenable the production database remote archive destination. Query the V$ARCHIVE_DEST_STATUS view first to see the current state of the archive destinations:
SELECT DEST_ID, DEST_NAME, STATUS, PROTECTION_MODE, DESTINATION, ERROR, SRL FROM V$ARCHIVE_DEST_STATUS; ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_n=ENABLE; ALTER SYSTEM SWITCH LOGFILE;
Verify log transport services between the production and standby databases by checking for errors. Query V$ARCHIVE_DEST and V$ARCHIVE_DEST_STATUS views.
SELECT STATUS, TARGET, LOG_SEQUENCE, TYPE, PROCESS, REGISTER, ERROR FROM V$ARCHIVE_DEST; SELECT * FROM V$ARCHIVE_DEST_STATUS WHERE STATUS!='INACTIVE';
For a physical standby database, verify that there are no errors from the managed recovery process and that the recovery has applied the archived redo logs.
SELECT MAX(SEQUENCE#), THREAD# FROM V$LOG_HISTORY GROUP BY THREAD; SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, CLIENT_PROCESS FROM V$MANAGED_STANDBY;
For a logical standby database, verify that there are no errors from the logical standby process and that the recovery has applied the archived redo logs.
SELECT THREAD#, SEQUENCE# SEQ# FROM DBA_LOGSTDBY_LOG LOG, DBA_LOGSTDBY_PROGRESS PROG WHERE PROG.APPLIED_SCN BETWEEN LOG.FIRST_CHANGE# AND LOG.NEXT_CHANGE# ORDER BY NEXT_CHANGE#;
If you had to change the protection mode of the production database from maximum protection to either maximum availability or maximum performance because of the standby database outage, then change the production database protection mode back to maximum protection depending on your business requirements.
ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE [PROTECTION | AVAILABILITY];
Following an unplanned outage of the standby database that requires a full or partial datafile restoration (such as data or media failure), full fault tolerance is compromised until the standby database is brought back into service. Full database protection should be restored as soon as possible. Note that using a Hardware Assisted Resilient Database configuration can prevent this type of problem.
The following steps are required to restore full fault tolerance after data failure of the standby database:
The root cause of the outage should be investigated and action taken to prevent the problem from occurring again.
Only the affected datafiles need to be restored on to the standby site.
Archived redo log files may need to be restored to recover the restored data files up to the configured lag.
For physical standby databases:
For logical standby databases, initiate complete media recovery for the affected files. Consider the following:
After the standby database has been reestablished, start the standby database.
| Type of Standby Database | SQL Statement |
|---|---|
|
Physical |
|
|
Logical |
|
| Type of Standby Database | SQL Statement |
|---|---|
|
Physical |
|
|
Logical |
|
Verify log transport services on the new production database by checking for errors when querying V$ARCHIVE_DEST and V$ARCHIVE_DEST_STATUS.
SELECT STATUS, TARGET, LOG_SEQUENCE, TYPE, PROCESS, REGISTER, ERROR FROM V$ARCHIVE_DEST; SELECT * FROM V$ARCHIVE_DEST_STATUS WHERE STATUS != 'INACTIVE';
For a physical standby database, verify that there are no errors from the managed recovery process and that the recovery has applied archived redo logs.
SELECT MAX(SEQUENCE#), THREAD# FROM V$LOG_HISTORY GROUP BY THREAD; SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, CLIENT_PROCESS FROM V$MANAGED_STANDBY;
For a logical standby database, verify that there are no errors from the logical standby process and that the recovery has applied archived redo logs.
SELECT THREAD#, SEQUENCE# SEQ# FROM DBA_LOGSTDBY_LOG LOG, DBALOGSTDBY_PROGRESS PROG WHERE PROG.APPLIED_SCN BETWEEN LOG.FIRST_CHANGE# AND LOG.NEXT_CHANGE# ORDER BY NEXT_CHANGE#;
If you had to change the protection mode of the production database from maximum protection to either maximum availability or maximum performance because of the standby database outage, then change the production database protection mode back to maximum protection depending on your business requirements.
ALTER DATABASE SET STANDBY DATABASE TO MAXIMIZE [PROTECTION | AVAILABILITY];
If the production database is activated because it was flashed back to correct a logical error or because it was restored and recovered to a point in time, then the corresponding standby database may require additional maintenance. No additional work is required if the production database did complete recovery with no resetlogs.
After activating the production database, execute the queries in the following table.
| Database | Action |
|---|---|
|
Physical standby database |
|
|
Logical standby database |
|
If a dual failure affecting both the standby and production databases occurs, then you need to re-create the production database first. Because the sites are identical, the production database can be created wherever the most recent backup resides.
Table 11-3 summarizes the recovery strategy depending on the type of backups that are available.
After the production database is re-created, follow the steps for creating a new standby database that are described in Oracle Data Guard Concepts and Administration.
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

