|
Siebel Business Analytics Server Administration Guide > Creating and Administering the Physical Layer in a Repository > Setting Up Connection Pools >
Creating or Changing Connection Pools
You must create a database object before you create a connection pool. Typically, the database object and connection pool are created automatically when you import the physical schema. You create or change a connection pool in the Physical layer of the Administration Tool. CAUTION: It is strongly recommend that customers use OCI for connecting to Oracle. ODBC should only be used to import from Oracle.
This section contains the following topics:
About Connection Pools for Initialization Blocks
It is recommended that you create a dedicated connection pool for initialization blocks. This connection pool should not be used for queries. Additionally, it is recommended that you isolate the connections pools for different types of initialization blocks. This also makes sure that authentication and login-specific initialization blocks do not slow down the login process. The following types should have separate connection pools: - All Authentication and login-specific initialization blocks such as language, externalized strings, and group assignments.
- All initialization blocks that set session variables.
- All initialization blocks that set repository variables. These initialization blocks should always be run using the system administrator user login.
Be aware of the number of these initialization blocks, their scheduled refresh rate, and when they are scheduled to run. Typically, it would take an extreme case for this scenario to affect resources. For example, refresh rates set in minutes, greater than 15 initialization blocks that refresh concurrently, and a situation in which either of these scenarios could occur during prime user access time frames. To avoid straining the available resources, you might want to disable query logging for the default Analytics Server administrator.
Initialization blocks should be designed so that the maximum number of Analytics Server variables may be assigned by each block. For example, if you have five variables, it is more efficient and less resource intensive to construct a single initialization block containing all five variables. When using one initialization block, the values will be resolved with one call to the back end tables using the initialization string. Constructing five initialization blocks, one for each variable, would result in five calls to the back end tables for assignment. Setting Up General Properties For Connection Pools
Use this section to complete the General tab. To set up general properties for connection pools
- In the Physical layer of the Administration Tool, right-click a database and choose New Object > Connection Pool, or double-click an existing connection pool.
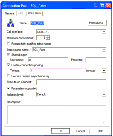
The following is an illustration of the General tab in the Connection Pool dialog box.
- In the Connection Pool dialog box, click the General tab, and then complete the fields using information in Table 11.
Properties that are specific to a multidimensional data sources can be found in Table 13.
Table 11. Connection Pool General Properties
|
|
Call interface |
The application program interface (API) with which to access the data source. Some databases may be accessed using native APIs, some use ODBC, and some work both ways. If the call interface is XML, the XML tab is available but options that do not apply to XML data sources are not available. |
Data source name |
The drop-down list shows the User and System DSNs configured on your system. A data source name that is configured to access the database to which you want to connect. The data source name needs to contain valid logon information for a data source. If the information is invalid, the database logon specified in the DSN will fail. |
Enable connection pooling |
Allows a single database connection to remain open for the specified time for use by future query requests. Connection pooling saves the overhead of opening and closing a new connection for every query. If you do not select this option, each query sent to the database opens a new connection. |
Execute on Connect |
Allows the Analytics Server administrator to specify a command to be executed each time a connection is made to the database. The command may be any command accepted by the database. For example, it could be used to turn on quoted identifiers. In a mainframe environment, it could be used to set the secondary authorization ID when connecting to DB2 to force a security exit to a mainframe security package such as RACF. This allows mainframe environments to maintain security in one central location. |
Execute queries asynchronously |
Indicates whether the data source supports asynchronous queries. |
Isolation level |
For ODBC and DB2 gateways, the value sets the transaction isolation level on each connection to the back-end database. The isolation level setting controls the default transaction locking behavior for all statements issued by a connection. Only one of the options can be set at a time. It remains set for that connection until it is explicitly changed. The following is a list of the options: Committed Read. Specifies that shared locks are held while the data is read to avoid dirty reads. However, the data can be changed before the end of the transaction, resulting in non repeatable reads or phantom data. Dirty Read. Implements dirty read (isolation level 0 locking). When this option is set, it is possible to read uncommitted or dirty data, change values in the data, and see rows appear or disappear in the data set before the end of the transaction. This is the least restrictive of the isolation levels. Repeatable Read. Places locks on all data that is used in a query, preventing other users from updating the data. However, new phantom rows can be inserted into the data set by another user and are included in later reads in the current transaction. Serializable. Places a range lock on the data set, preventing other users from updating or inserting rows into the data set until the transaction is complete. This is the most restrictive of the four isolation levels. Because concurrency is lower, use this option only if necessary. |
Maximum connections |
The maximum number of connections allowed for this connection pool. The default is 10. This value should be determined by the database make and model and the configuration of the hardware box on which the database runs as well as the number of concurrent users who require access. NOTE: For deployments with Intelligence Dashboard pages, consider estimating this value at 10% to 20% of the number of simultaneous users multiplied by the number of requests on a dashboard. This number may be adjusted based on usage. The total number of all connections in the repository should be less than 800. To estimate the maximum connections needed for a connection pool dedicated to an initialization block, you might use the number of users concurrently logged on during initialization block execution.
|
Name |
The name for the connection pool. If you do not type a name, the Administration Tool generates a name. For multidimensional and XML data sources, this is prefilled. |
Parameters supported |
If the database features table supports parameters and the connection pool check box property for parameter support is unchecked, then special code executes that allows the Analytics Server to push filters (or calculations) with parameters to the database. The Analytics Server does this by simulating parameter support within the gateway/adapter layer by sending extra SQLPrepare calls to the database. |
Permissions |
Assigns permissions for individual users or groups to access the connection pool. You can also set up a privileged group of users to have its own connection pool. |
Require fully qualified table names |
Select this check box, if the database requires it. When this option is selected, all requests sent from the connection pool use fully qualified names to query the underlying database. The fully qualified names are based on the physical object names in the repository. If you are querying the same tables from which the physical layer metadata was imported, you can safely check the option. If you have migrated your repository from one physical database to another physical database that has different database and schema names, the fully qualified names would be invalid in the newly migrated database. In this case, if you do not select this option, the queries will succeed against the new database objects. For some data sources, fully qualified names might be safer because they guarantee that the queries are directed to the desired tables in the desired database. For example, if the RDBMS supports a master database concept, a query against a table named foo first looks for that table in the master database, and then looks for it in the specified database. If the table named foo exists in the master database, that table is queried, not the table named foo in the specified database. |
Shared logon |
Select the Shared logon check box if you want all users whose queries use the connection pool to access the underlying database using the same user name and password. If this option is selected, then all connections to the database that use the connection pool will use the user name and password specified in the connection pool, even if the user has specified a database user name and password in the DSN (or in the Siebel user configuration). If this option is not selected, connections through the connection pool use the database user ID and password specified in the DSN or in the Siebel user profile. |
Timeout (Minutes) |
Specifies the amount of time, in minutes, that a connection to the data source will remain open after a request completes. During this time, new requests use this connection rather than open a new one (up to the number specified for the maximum connections). The time is reset after each completed connection request. If you set the timeout to 0, connection pooling is disabled; that is, each connection to the data source terminates immediately when the request completes. Any new connections either use another connection pool or open a new connection. |
Setting Up Write-Back Properties
Use this section to complete the Write Back tab in the Connection Pool dialog box. To set up write-back properties for connection pools
- In the Physical layer of the Administration Tool, right-click a database and select New Object > Connection Pool, or double-click an existing connection pool.
- In the Connection Pool dialog box, click the Write Back tab.
- In the Write Back tab, complete the fields using Table 12 as a guide.
Table 12. Field Descriptions for Write Back Tab
|
|
Owner |
Table owner name used to qualify a temporary table name in a SQL statement, for example to create the table owner.tablename. If left blank, the user name specified in the writeable connection pool is used to qualify the table name and the Shared Logon field on the General tab should also be set. |
Prefix |
When the Analytics Server creates a temporary table, these are the first two characters in the temporary table name. The default value is TT. |
Database Name |
Database where the temporary table will be created. This property applies only to IBM OS/390 because IBM OS/390 requires database name qualifier to be part of the CREATE TABLE statement. If left blank, OS/390 will default the target database to a system database for which the users may not have Create Table privileges. |
Tablespace Name |
Tablespace where the temporary table will be created. This property applies to OS/390 only as OS/390 requires tablespace name qualifier to be part of the CREATE TABLE statement. If left blank, OS/390 will default the target database to a system database for which the users may not have Create Table privileges. |
Bulk Insert Buffer Size (KB) |
Used for limiting the number of bytes each time data is inserted in a database table. |
Bulk Insert Transaction Boundary |
Controls the batch size for an insert in a database table. |
Unicode Database Type |
Select this check box when working with columns of an explicit Unicode data type, such as NCHAR, in an Unicode database. This makes sure that the binding is correct and data will be inserted correctly. Different database vendors provide different character data types and different levels of Unicode support. Use the following general guidelines to determine when to set this check box: - On a database where CHAR data type supports Unicode and there is no separate NCHAR data type, do not select this check box.
- On a database where NCHAR data type is available, it is recommended to select this check box.
- On a database where CHAR and NCHAR data type are configured to support Unicode, selecting this check box is optional.
NOTE: Unicode and non-Unicode datatypes cannot coexist a single non-Unicode database. For example, mixing the CHAR and NCHAR data types in a single non-Unicode database environment is not supported.
|
|