Release 10.1.3.4
Part Number E12187-01
Contents
Previous
Next
| Oracle Business Intelligence Publisher Report Designer's Guide Release 10.1.3.4 Part Number E12187-01 | Contents | Previous | Next |
This chapter covers the following topics:
An eText template is an RTF-based template that is used to generate text output for Electronic Funds Transfer (EFT) and Electronic Data Interchange (EDI). At runtime, BI Publisher applies this template to an input XML data file to create an output text file that can be transmitted to a bank or other customer. Because the output is intended for electronic communication, the eText templates must follow very specific format instructions for exact placement of data.
Note: An EFT is an electronic transmission of financial data and payments to banks in a specific fixed-position format flat file (text).
EDI is similar to EFT except it is not only limited to the transmission of payment information to banks. It is often used as a method of exchanging business documents, such as purchase orders and invoices, between companies. EDI data is delimiter-based, and also transmitted as a flat file (text).
Files in these formats are transmitted as flat files, rather than printed on paper. The length of a record is often several hundred characters and therefore difficult to layout on standard size paper.
To accommodate the record length, the EFT and EDI templates are designed using tables. Each record is represented by a table. Each row in a table corresponds to a field in a record. The columns of the table specify the position, length, and value of the field.
These formats can also require special handling of the data from the input XML file. This special handling can be on a global level (for example, character replacement and sequencing) or on a record level (for example, sorting). Commands to perform these functions are declared in command rows. Global level commands are declared in setup tables.
At runtime, BI Publisher constructs the output file according to the setup commands and layout specifications in the tables.
This section is intended for users who are familiar with EDI and EFT transactions audience for this section preparers of eText templates will require both functional and technical knowledge. That is, functional expertise to understand bank and country specific payment format requirements and sufficient technical expertise to understand XML data structure and eText specific coding syntax commands, functions, and operations.
There are two types of eText templates: fixed-position based (EFT templates) and delimiter-based (EDI templates). The templates are composed of a series of tables. The tables define layout and setup commands and data field definitions. The required data description columns for the two types of templates vary, but the commands and functions available are the same. A table can contain just commands, or it can contain commands and data fields.
The following graphic shows a sample from an EFT template to display the general structure of command and data rows:
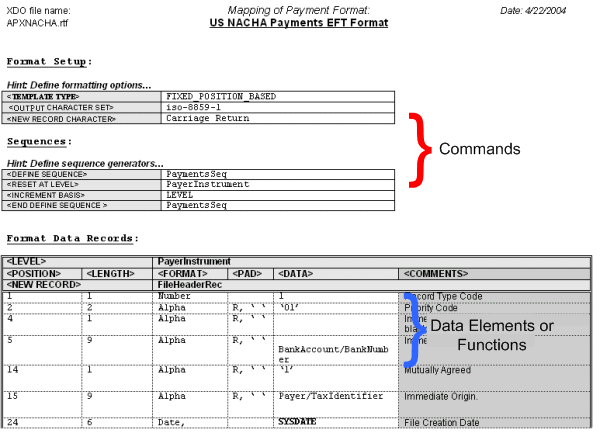
Commands that apply globally, or commands that define program elements for the template, are "setup" commands. These must be specified in the initial table(s) of the template. Examples of setup commands are Template Type and Character Set.
In the data tables you provide the source XML data element name (or static data) and the specific placement and formatting definitions required by the receiving bank or entity. You can also define functions to be performed on the data and conditional statements.
The data tables must always start with a command row that defines the "Level." The Level associates the table to an element from the XML data file, and establishes the hierarchy. The data fields that are then defined in the table for the Level correspond to the child elements of the XML element.
The graphic below illustrates the relationship between the XML data hierarchy and the template Level. The XML element "RequestHeader" is defined as the Level. The data elements defined in the table ("FileID" and "Encryption") are children of the RequestHeader element.
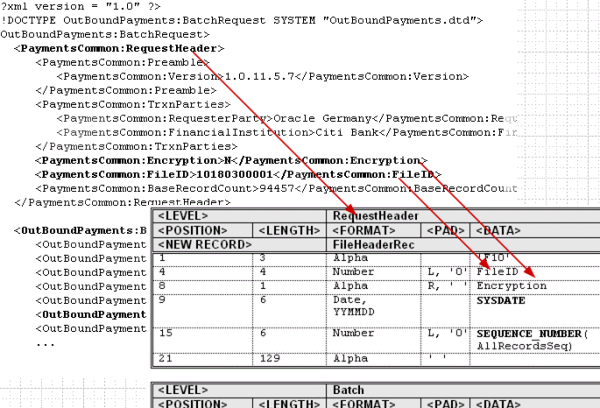
The order of the tables in the template determines the print order of the records. At runtime the system loops through all the instances of the XML element corresponding to a table (Level) and prints the records belonging to the table. The system then moves on to the next table in the template. If tables are nested, the system will generate the nested records of the child tables before moving on to the next parent instance.
The following figure shows the placement of Command Rows, Data Rows, and Data Column Header Rows:

Command rows are used to specify commands in the template. Command rows always have two columns: command name and command parameter. Command rows do not have column headings. The commands control the overall setup and record structures of the template.
Blank rows can be inserted anywhere in a table to improve readability. Most often they are used in the setup table, between commands. Blank rows are ignored by BI Publisher when the template is parsed.
Data column headers specify the column headings for the data fields (such as Position, Length, Format, Padding, and Comments). A column header row usually follows the Level command in a table (or the sorting command, if one is used). The column header row must come before any data rows in the table. Additional empty column header rows can be inserted at any position in a table to improve readability. The empty rows will be ignored at runtime.
The required data column header rows vary depending on the template type. See Structure of the Data Row.
Data rows contain the data fields to correspond to the column header rows.
The content of the data rows varies depending on the template type. See Structure of the Data Row.
The data tables contain a combination of command rows and data field rows. Each data table must begin with a Level command row that specifies its XML element. Each record must begin with a New Record command that specifies the start of a new record, and the end of a previous record (if any).
The required columns for the data fields vary depending on the Template Type.
The command rows always have two columns: command name and command parameter. The supported commands are:
Level
New record
Sort ascending
Sort descending
Display condition
The usage for each of these commands is described in the following sections.
The level command associates a table with an XML element. The parameter for the level command is an XML element. The level will be printed once for each instance the XML element appears in the data input file.
The level commands define the hierarchy of the template. For example, Payment XML data extracts are hierarchical. A batch can have multiple child payments, and a payment can have multiple child invoices. This hierarchy is represented in XML as nested child elements within a parent element. By associating the tables with XML elements through the level command, the tables will also have the same hierarchical structure.
Similar to the closing tag of an XML element, the level command has a companion end-level command. The child tables must be defined between the level and end-level commands of the table defined for the parent element.
An XML element can be associated with only one level. All the records belonging to a level must reside in the table of that level or within a nested table belonging to that level. The end-level command will be specified at the end of the final table.
Following is a sample structure of an EFT file record layout:
FileHeaderRecordA
BatchHeaderRecordA
BatchHeaderRecordB
PaymentRecordA
PaymentRecordB
InvoiceRecordA
Batch FooterRecordC
BatchFooterRecordD
FileFooterRecordB
Following would be its table layout:
| <LEVEL> | RequestHeader |
| <NEW RECORD> | FileHeaderRecordA |
| Data rows for the FileHeaderRecordA |
| <LEVEL> | Batch |
| <NEW RECORD> | BatchHeaderRecordA |
| Data rows for the BatchHeaderRecordA | |
| <NEW RECORD> | BatchHeaderRecordB |
| Data rows for the BatchHeaderRecordB |
| <LEVEL> | Payment |
| <NEW RECORD> | PaymentRecordA |
| Data rows for the PaymentRecordA | |
| <NEW RECORD> | PaymentRecordB |
| Data rows for the PaymentRecordB |
| <LEVEL> | Invoice |
| <NEW RECORD> | InvoiceRecordA |
| Data rows for the InvoiceRecordA | |
| <END LEVEL> | Invoice |
| <END LEVEL> | Payment |
| <LEVEL> | Batch |
| <NEW RECORD> | BatchFooterRecordC |
| Data rows for the BatchFooterRecordC | |
| <NEW RECORD> | BatchFooterRecordD |
| Data rows for the BatchFooterRecordD | |
| <END LEVEL> | Batch |
| <LEVEL> | RequestHeader |
| <NEW RECORD> | FileFooterRecordB |
| Data rows for the FileFooterRecordB | |
| <END LEVEL> | RequestHeader |
Multiple records for the same level can exist in the same table. However, each table can only have one level defined. In the example above, the BatchHeaderRecordA and BatchHeaderRecordB are both defined in the same table. However, note that the END LEVEL for the Payment must be defined in its own separate table after the child element Invoice. The Payment END LEVEL cannot reside in the same table as the Invoice Level.
Note that you do not have to use all the levels from the data extract in your template. For example, if an extract contains the levels: RequestHeader > Batch > Payment > Invoice, you can use just the batch and invoice levels. However, the hierarchy of the levels must be maintained.
The table hierarchy determines the order that the records are printed. For each parent XML element, the records of the corresponding parent table are printed in the order they appear in the table. The system loops through the instances of the child XML elements corresponding to the child tables and prints the child records according to their specified order. The system then prints the records of the enclosing (end-level) parent table, if any.
For example, given the EFT template structure above, assume the input data file contains the following:
Batch1
Payment1
Invoice1
Invoice2
Payment2
Invoice1
Batch2
Payment1
Invoice1
Invoice2
Invoice3
This will generate the following printed records:
| Record Order | Record Type | Description |
|---|---|---|
| 1 | FileHeaderRecordA | One header record for the EFT file |
| 2 | BatchHeaderRecordA | For Batch1 |
| 3 | BatchHeaderRecordB | For Batch1 |
| 4 | PaymentRecordA | For Batch1, Payment1 |
| 5 | PaymentRecordB | For Batch1, Payment1 |
| 6 | InvoiceRecordA | For Batch1, Payment1, Invoice1 |
| 7 | InvoiceRecordA | For Batch1, Payment1, Invoice2 |
| 8 | PaymentRecordA | For Batch1, Payment2 |
| 9 | PaymentrecordB | For Batch1, Payment2 |
| 10 | InvoiceRecordA | For Batch1, Payment2, Invoice1 |
| 11 | BatchFooterRecordC | For Batch1 |
| 12 | BatchFooterRecordD | For Batch1 |
| 13 | BatchHeaderRecordA | For Batch2 |
| 14 | BatchHeaderRecordB | For Batch2 |
| 15 | PaymentRecordA | For Batch2, Payment1 |
| 16 | PaymentRecordB | For Batch2, Payment1 |
| 17 | InvoiceRecordA | For Batch2, Payment1, Invoice1 |
| 18 | InvoiceRecordA | For Batch2, Payment1, Invoice2 |
| 19 | InvoiceRecordA | For Batch2, Payment1, Invoice3 |
| 20 | BatchFooterRecordC | For Batch2 |
| 21 | BatchFooterRecordD | For Batch2 |
| 22 | FileFooterRecordB | One footer record for the EFT file |
The new record command signifies the start of a record and the end of the previous one, if any. Every record in a template must start with the new record command. The record continues until the next new record command, or until the end of the table or the end of the level command.
A record is a construct for the organization of the elements belonging to a level. The record name is not associated with the XML input file.
A table can contain multiple records, and therefore multiple new record commands. All the records in a table are at the same hierarchy level. They will be printed in the order in which they are specified in the table.
The new record command can have a name as its parameter. This name becomes the name for the record. The record name is also referred to as the record type. The name can be used in the COUNT function for counting the generated instances of the record. See COUNT function, for more information.
Consecutive new record commands (or empty records) are not allowed.
Use the sort ascending and sort descending commands to sort the instances of a level. Enter the elements you wish to sort by in a comma-separated list. This is an optional command. When used, it must come right after the (first) level command and it applies to all records of the level, even if the records are specified in multiple tables.
The display condition command specifies when the enclosed record or data field group should be displayed. The command parameter is a boolean expression. When it evaluates to true, the record or data field group is displayed. Otherwise the record or data field group is skipped.
The display condition command can be used with either a record or a group of data fields. When used with a record, the display condition command must follow the new record command. When used with a group of data fields, the display condition command must follow a data field row. In this case, the display condition will apply to the rest of the fields through the end of the record.
Consecutive display condition commands are merged as AND conditions. The merged display conditions apply to the same enclosed record or data field group.
The output record data fields are represented in the template by table rows. In FIXED_POSITION_BASED templates, each row has the following attributes (or columns):
Position
Length
Format
Pad
Data
Comments
The first five columns are required and must appear in the order listed.
For DELIMITER_BASED templates, each data row has the following attributes (columns):
Maximum Length
Format
Data
Tag
Comments
The first three columns are required and must be declared in the order stated.
In both template types, the Comments column is optional and ignored by the system. You can insert additional information columns if you wish, as all columns after the required ones are ignored.
The usage rules for these columns are as follows:
Specifies the starting position of the field in the record. The unit is in number of characters. This column is only used with FIXED_POSITION_BASED templates.
Specifies the length of the field. The unit is in number of characters. For FIXED_POSITION_BASED templates, all the fields are fixed length. If the data is less than the specified length, it is padded. If the data is longer, it is truncated. The truncation always occurs on the right.
For DELIMITER_BASED templates, the maximum length of the field is specified. If the data exceeds the maximum length, it will be truncated. Data is not padded if it is less than the maximum length.
Specifies the data type and format setting. There are three accepted data types:
Alpha
Number
Date
Refer to Field Level Key Words for their usage.
Numeric data has three optional format settings: Integer, Decimal, or you can define a format mask. Specify the optional settings with the Number data type as follows:
Number, Integer
Number, Decimal
Number, <format mask>
For example:
Number, ###,###.00
The Integer format uses only the whole number portion of a numeric value and discards the decimal. The Decimal format uses only the decimal portion of the numeric value and discards the integer portion.
The following table shows examples of how to set a format mask. When specifying the mask, # represents that a digit is to be displayed when present in the data; 0 represents that the digit placeholder is to be displayed whether data is present or not.
When specifying the format mask, the group separator must always be "," and the decimal separator must always be "." To alter these in the actual output, you must use the Setup Commands NUMBER THOUSANDS SEPARATOR and NUMBER DECIMAL SEPARATOR. See Setup Command Tables for details on these commands.
The following table shows sample Data, Format Specifier, and Output. The Output assumes the default group and decimal separators.
| Data | Format Specifier | Output |
|---|---|---|
| 123456789 | ###,###.00 | 123,456,789.00 |
| 123456789.2 | ###.00 | 123456789.20 |
| 1234.56789 | ###.000 | 1234.568 |
| 123456789.2 | # | 123456789 |
| 123456789.2 | #.## | 123456789.2 |
| 123456789 | #.## | 123456789 |
The Date data type format setting must always be explicitly stated. The format setting follows the SQL date styles, such as MMDDYY.
Some EDI (DELIMITER_BASED) formats use more descriptive data types. These are mapped to the three template data types in the following table:
| ASC X12 Data Type | Format Template Data Type |
|---|---|
| A - Alphabetic | Alpha |
| AN -Alphanumeric | Alpha |
| B - Binary | Number |
| CD - Composite data element | N/A |
| CH - Character | Alpha |
| DT - Date | Date |
| FS - Fixed-length string | Alpha |
| ID - Identifier | Alpha |
| IV - Incrementing Value | Number |
| Nn - Numeric | Number |
| PW - Password | Alpha |
| R - Decimal number | Numer |
| TM - Time | Date |
Now assume you have specified the following setup commands:
| NUMBER THOUSANDS SEPARATOR | . |
| NUMBER DECIMAL SEPARATOR | , |
The following table shows the Data, Format Specifier, and Output for this case. Note that the Format Specifier requires the use of the default separators, regardless of the setup command entries.
| Data | Format Specifier | Output |
|---|---|---|
| 123456789 | ###,###.00 | 123.456.789,00 |
| 123456789.2 | ###.00 | 123456789,20 |
| 1234.56789 | ###.000 | 1234,568 |
| 123456789.2 | # | 123456789 |
| 123456789.2 | #.## | 123456789,2 |
| 123456789 | #.## | 123456789 |
This applies to FIXED_POSITION_BASED templates only. Specify the padding side (L = left or R = right) and the character. Both numeric and alphanumeric fields can be padded. If this field is not specified, Numeric fields are left-padded with "0"; Alpha fields are right-padded with spaces.
Example usage:
To pad a field on the left with a "0", enter the following in the Pad column field:
L, '0'
To pad a field on the right with a space, enter the following the Pad column field:
R, ' '
Specifies the XML element from the data extract that is to populate the field. The data column can simply contain the XML tag name, or it can contain expressions and functions. For more information, see Expressions, Control Structure, and Functions.
Acts as a comment column for DELIMITER_BASED templates. It specifies the reference tag in EDIFACT formats, and the reference IDs in ASC X12.
Use this column to note any free form comments to the template. Usually this column is used to note the business requirement and usage of the data field.
A template always begins with a table that specifies the setup commands. The setup commands define global attributes, such as template type and output character set and program elements, such as sequencing and concatenation.
The setup commands are:
Template Type
Output Character Set
New Record Character
Invalid Characters
Replace Characters
Number Thousands Separator
Number Decimal Separator
Define Level
Define Sequence
Define Concatenation
Some example setup tables are shown in the following figures:


This command specifies the type of template. There are two types: FIXED_POSITION_BASED and DELIMITER_BASED.
Use the FIXED_POSITION_BASED templates for fixed-length record formats, such as EFTs. In these formats, all fields in a record are a fixed length. If data is shorter than the specified length, it will be padded. If longer, it will be truncated. The system specifies the default behavior for data padding and truncation. Examples of fixed position based formats are EFTs in Europe, and NACHA ACH file in the U.S.
In a DELIMITER_BASED template, data is never padded and only truncated when it has reached a maximum field length. Empty fields are allowed (when the data is null). Designated delimiters are used to separate the data fields. If a field is empty, two delimiters will appear next to each other. Examples of delimited-based templates are EDI formats such as ASC X12 820 and UN EDIFACT formats - PAYMUL, DIRDEB, and CREMUL.
In EDI formats, a record is sometimes referred to as a segment. An EDI segment is treated the same as a record. Start each segment with a new record command and give it a record name. You should have a data field specifying the segment name as part of the output data immediately following the new record command.
For DELIMITER_BASED templates, you insert the appropriate data field delimiters in separate rows between the data fields. After every data field row, you insert a delimiter row. You can insert a placeholder for an empty field by defining two consecutive delimiter rows.
Empty fields are often used for syntax reasons: you must insert placeholders for empty fields so that the fields that follow can be properly identified.
There are different delimiters to signify data fields, composite data fields, and end of record. Some formats allow you to choose the delimiter characters. In all cases you should use the same delimiter consistently for the same purpose to avoid syntax errors.
In DELIMITER_BASED templates, the <POSITION> and <PAD> columns do not apply. They are omitted from the data tables.
Some DELIMITER_BASED templates have minimum and maximum length specifications. In those cases Oracle Payments validates the length.
Some formats require specific additional data levels that are not in the data extract. For example, some formats require that payments be grouped by payment date. Using the Define Level command, a payment date group can be defined and referenced as a level in the template, even though it is not in the input extract file.
When you use the Define Level command you declare a base level that exists in the extract. The Define Level command inserts a new level one level higher than the base level of the extract. The new level functions as a grouping of the instances of the base level.
The Define Level command is a setup command, therefore it must be defined in the setup table. It has three subcommands:
Base Level Command - defines the level (XML element) from the extract that the new level is based on. The Define Level command must always have one and only one base level subcommand.
Grouping Criteria - defines the XML extract elements that are used to group the instances of the base level to form the instances of the new level. The parameter of the grouping criteria command is a comma-separated list of elements that specify the grouping conditions.
The order of the elements determines the hierarchy of the grouping. The instances of the base level are first divided into groups according to the values of the first criterion, then each of these groups is subdivided into groups according to the second criterion, and so on. Each of the final subgroups will be considered as an instance of the new level.
Group Sort Ascending or Group Sort Descending - defines the sorting of the group. Insert the <GROUP SORT ASCENDING> or <GROUP SORT DESCENDING> command row anywhere between the <DEFINE LEVEL> and <END DEFINE LEVEL> commands. The parameter of the sort command is a comma-separated list of elements by which to sort the group.
For example, the following table shows five payments under a batch:
| Payment Instance | PaymentDate (grouping criterion 1) | PayeeName (grouping criterion 2) |
|---|---|---|
| Payment1 | PaymentDate1 | PayeeName1 |
| Payment2 | PaymentDate2 | PayeeName1 |
| Payment3 | PaymentDate1 | PayeeName2 |
| Payment4 | PaymentDate1 | PayeeName1 |
| Payment5 | PaymentDate1 | PayeeName3 |
In the template, construct the setup table as follows to create a level called "PaymentsByPayDatePayee" from the base level "Payment" grouped according to PaymentDate and Payee Name. Add the Group Sort Ascending command to sort ea:
| <DEFINE LEVEL> | PaymentsByPayDatePayee |
| <BASE LEVEL> | Payment |
| <GROUPING CRITERIA> | PaymentDate, PayeeName |
| <GROUP SORT ASCENDING> | PaymentDate, PayeeName |
| <END DEFINE LEVEL> | PaymentsByPayDatePayee |
The five payments will generate the following four groups (instances) for the new level:
| Payment Group Instance | Group Criteria | Payments in Group |
|---|---|---|
| Group1 | PaymentDate1, PayeeName1 | Payment1, Payment4 |
| Group2 | PaymentDate1, PayeeName2 | Payment3 |
| Group3 | PaymentDate1, PayeeName3 | Payment5 |
| Group4 | PaymentDate2, PayeeName1 | Payment2 |
The order of the new instances is the order that the records will print. When evaluating the multiple grouping criteria to form the instances of the new level, the criteria can be thought of as forming a hierarchy. The first criterion is at the top of the hierarchy, the last criterion is at the bottom of the hierarchy.
Generally there are two kinds of format-specific data grouping scenarios in EFT formats. Some formats print the group records only; others print the groups with the individual element records nested inside groups. Following are two examples for these scenarios based on the five payments and grouping conditions previously illustrated.
First Scenario: Group Records Only
EFT File Structure:
BatchRec
PaymentGroupHeaderRec
PaymentGroupFooterRec
| Record Sequence | Record Type | Description |
|---|---|---|
| 1 | BatchRec | |
| 2 | PaymentGroupHeaderRec | For group 1 (PaymentDate1, PayeeName1) |
| 3 | PaymentGroupFooterRec | For group 1 (PaymentDate1, PayeeName1) |
| 4 | PaymentGroupHeaderRec | For group 2 (PaymentDate1, PayeeName2) |
| 5 | PaymentGroupFooterRec | For group 2 (PaymentDate1, PayeeName2) |
| 6 | PaymentGroupHeaderRec | For group 3 (PaymentDate1, PayeeName3) |
| 7 | PaymentGroupFooterRec | For group 3 (PaymentDate1, PayeeName3) |
| 8 | PaymentGroupHeaderRec | For group 4 (PaymentDate2, PayeeName1) |
| 9 | PaymentGroupFooterRec | For group 4 (PaymentDate2, PayeeName1) |
Scenario 2: Group Records and Individual Records
EFT File Structure:
BatchRec
PaymentGroupHeaderRec
PaymentRec
PaymentGroupFooterRec
Generated output:
| Record Sequence | Record Type | Description |
|---|---|---|
| 1 | BatchRec | |
| 2 | PaymentGroupHeaderRec | For group 1 (PaymentDate1, PayeeName1) |
| 3 | PaymentRec | For Payment1 |
| 4 | PaymentRec | For Payment4 |
| 5 | PaymentGroupFooterRec | For group 1 (PaymentDate1, PayeeName1) |
| 6 | PaymentGroupHeaderRec | For group 2 (PaymentDate1, PayeeName2) |
| 7 | PaymentRec | For Payment3 |
| 8 | PaymentGroupFooterRec | For group 2 (PaymentDate1, PayeeName2) |
| 9 | PaymentGroupHeaderRec | For group 3 (PaymentDate1, PayeeName3) |
| 10 | PaymentRec | For Payment5 |
| 11 | PaymentGroupFooterRec | For group 3 (PaymentDate1, PayeeName3) |
| 12 | PaymentGroupHeaderRec | For group 4 (PaymentDate2, PayeeName1) |
| 13 | PaymentRec | For Payment2 |
| 14 | PaymentGroupFooterRec | For group 4 (PaymentDate2, PayeeName1) |
Once defined with the Define Level command, the new level can be used in the template in the same manner as a level occurring in the extract. However, the records of the new level can only reference the base level fields that are defined in its grouping criteria. They cannot reference other base level fields other than in summary functions.
For example, the PaymentGroupHeaderRec can reference the PaymentDate and PayeeName in its fields. It can also reference thePaymentAmount (a payment level field) in a SUM function. However, it cannot reference other payment level fields, such as PaymentDocName or PaymentDocNum.
The Define Level command must always have one and only one grouping criteria subcommand. The Define Level command has a companion end-define level command. The subcommands must be specified between the define level and end-define level commands. They can be declared in any order.
The define sequence command define a sequence that can be used in conjunction with the SEQUENCE_NUMBER function to index either the generated EFT records or the extract instances (the database records). The EFT records are the physical records defined in the template. The database records are the records from the extract. To avoid confusion, the term "record" will always refer to the EFT record. The database record will be referred to as an extract element instance or level.
The define sequence command has four subcommands: reset at level, increment basis, start at, and maximum:
The reset at level subcommand defines where the sequence resets its starting number. It is a mandatory subcommand. For example, to number the payments in a batch, define the reset at level as Batch. To continue numbering across batches, define the reset level as RequestHeader.
In some cases the sequence is reset outside the template. For example, a periodic sequence may be defined to reset by date. In these cases, the PERIODIC_SEQUENCE keyword is used for the reset at level. The system saves the last sequence number used for a payment file to the database. Outside events control resetting the sequence in the database. For the next payment file run, the sequence number is extracted from the database for the start at number (see start at subcommand).
The increment basis subcommand specifies if the sequence should be incremented based on record or extract instances. The allowed parameters for this subcommand are RECORD and LEVEL.
Enter RECORD to increment the sequence for every record.
Enter LEVEL to increment the sequence for every new instance of a level.
Note that for levels with multiple records, if you use the level-based increment all the records in the level will have the same sequence number. The record-based increment will assign each record in the level a new sequence number.
For level-based increments, the sequence number can be used in the fields of one level only. For example, suppose an extract has a hierarchy of batch > payment > invoice and you define the increment basis by level sequence, with reset at the batch level. You can use the sequence in either the payment or invoice level fields, but not both. You cannot have sequential numbering across hierarchical levels.
However, this rule does not apply to increment basis by record sequences. Records can be sequenced across levels.
For both increment basis by level and by record sequences, the level of the sequence is implicit based on where the sequence is defined.
Use the define concatenation command to concatenate child-level extract elements for use in parent-level fields. For example, use this command to concatenate invoice number and due date for all the invoices belonging to a payment for use in a payment-level field.
The define concatenation command has three subcommands: base level, element, and delimiter.
The base level subcommand specifies the child level for the operation. For each parent-level instance, the concatenation operation loops through the child-level instances to generate the concatenated string.
The item subcommand specifies the operation used to generate each item. An item is a child-level expression that will be concatenated together to generate the concatenation string.
The delimiter subcommand specifies the delimiter to separate the concatenated items in the string.
Use the SUBSTR function to break down concatenated strings into smaller strings that can be placed into different fields. For example, the following table shows five invoices in a payment:
| Invoice | InvoiceNum |
|---|---|
| 1 | car_parts_inv0001 |
| 2 | car_parts_inv0002 |
| 3 | car_parts_inv0003 |
| 4 | car_parts_inv0004 |
| 5 | car_parts_inv0005 |
Using the following concatenation definition:
| <DEFINE CONCATENATION> | ConcatenatedInvoiceInfo |
| <BASE LEVEL> | Invoice |
| <ELEMENT> | InvoiceNum |
| <DELIMITER> | ',' |
| <END DEFINE CONCATENATION> | ConcatenatedInvoiceInfo |
You can reference ConcatenatedInvoiceInfo in a payment level field. The string will be:
car_parts_inv0001,car_parts_inv0002,car_parts_inv0003,car_parts_inv0004,car_parts_inv0005
If you want to use only the first forty characters of the concatenated invoice info, use either TRUNCATE function or the SUBSTR function as follows:
TRUNCATE(ConcatenatedInvoiceInfo, 40)
SUBSTR(ConctenatedInvoiceInfo, 1, 40)
Either of these statements will result in:
car_parts_inv0001,car_parts_inv0002,car_
To isolate the next forty characters, use the SUBSTR function:
SUBSTR(ConcatenatedInvoiceInfo, 41, 40)
to get the following string:
parts_inv0003,car_parts_inv0004,car_par
Some formats require a different character set than the one that was used to enter the data in Oracle Applications. For example, some German formats require the output file in ASCII, but the data was entered in German. If there is a mismatch between the original and target character sets you can define an ASCII equivalent to replace the original. For example, you would replace the German umlauted "a" with "ao".
Some formats will not allow certain characters. To ensure that known invalid characters will not be transmitted in your output file, use the invalid characters command to flag occurrences of specific characters.
To use the replacement characters command, specify the source characters in the left column and the replacement characters in the right column. You must enter the source characters in the original character set. This is the only case in a format template in which you use a character set not intended for output. Enter the replacement characters in the required output character set.
For DELIMITER_BASED formats, if there are delimiters in the data, you can use the escape character "?" to retain their meaning. For example,
First name?+Last name equates to Fist name+Last name
Which source?? equates to Which source?
Note that the escape character itself must be escaped if it is used in data.
The replacement characters command can be used to support the escape character requirement. Specify the delimiter as the source and the escape character plus the delimiter as the target. For example, the command entry for the preceding examples would be:
| <REPLACEMENT CHARACTERS> | |
| + | ?+ |
| ? | ?? |
| <END REPLACEMENT CHARACTERS> |
The invalid character command has a single parameter that is a string of invalid characters that will cause the system to error out.
The replacement character process is performed before or during the character set conversion. The character set conversion is performed on the XML extract directly, before the formatting. After the character set conversion, the invalid characters will be checked in terms of the output character set. If no invalid characters are found, the system will proceed to formatting.
Use the new record character command to specify the character(s) to delimit the explicit and implicit record breaks at runtime. Each new record command represents an explicit record break. Each end of table represents an implicit record break. The parameter is a list of constant character names separated by commas.
Some formats contain no record breaks. The generated output is a single line of data. In this case, leave the new record character command parameter field empty.
The default thousands (or group) separator is a comma (",") and the default decimal separator is ".". Use the Number Thousands Separator command and the Number Decimal Separator command to specify separators other than the defaults. For example, to define "." as the group separator and "," as the decimal separator, enter the following:
| NUMBER THOUSANDS SEPARATOR | . |
| NUMBER DECIMAL SEPARATOR | , |
For more information on formatting numbers, see Format Column.
This section describes the rules and usage for expressions in the template. It also describes supported control structures and functions.
Expressions can be used in the data column for data fields and some command parameters. An expression is a group of XML extract fields, literals, functions, and operators. Expressions can be nested. An expression can also include the "IF" control structure. When an expression is evaluated it will always generate a result. Side effects are not allowed for the evaluation. Based on the evaluation result, expressions are classified into the following three categories:
Boolean Expression - an expression that returns a boolean value, either true or false. This kind expression can be used only in the "IF-THEN-ELSE" control structure and the parameter of the display condition command.
Numeric Expression - an expression that returns a number. This kind of expression can be used in numeric data fields. It can also be used in functions and commands that require numeric parameters.
Character Expression - an expression that returns an alphanumeric string. This kind of expression can be used in string data fields (format type Alpha). They can also be used in functions and command that require string parameters.
The only supported control structure is "IF-THEN-ELSE". It can be used in an expression. The syntax is:
IF <boolean_expressionA> THEN
<numeric or character expression1>
[ELSIF <boolean_expressionB THEN
<numeric or character expression2>]
...
[ELSE
<numeric or character expression3]
END IFGenerally the control structure must evaluate to a number or an alphanumeric string. The control structure is considered to a numeric or character expression. The ELSIF and ELSE clauses are optional, and there can be as many ELSIF clauses as necessary. The control structure can be nested.
The IN predicate is supported in the IF-THEN-ELSE control structure. For example:
IF PaymentAmount/Currency/Code IN ('USD', 'EUR', 'AON', 'AZM') THEN
PayeeAccount/FundsCaptureOrder/OrderAmount/Value * 100
ELSIF PaymentAmount/Currency/Code IN ('BHD', 'IQD', 'KWD') THEN
PayeeAccount/FundsCaptureOrder/OrderAmount/Value * 1000
ELSE
PayeeAccount/FundsCaptureOrder/OrderAmount/Value
END IF; Following is the list of supported functions:
SEQUENCE_NUMBER - is a record element index. It is used in conjunction with the Define Sequence command. It has one parameter, which is the sequence defined by the Define Sequence command. At runtime it will increase its sequence value by one each time it is referenced in a record.
COUNT - counts the child level extract instances or child level records of a specific type. Declare the COUNT function on a level above the entity to be counted. The function has one argument. If the argument is a level, the function will count all the instances of the (child) level belonging to the current (parent) level instance.
For example, if the level to be counted is Payment and the current level is Batch, then the COUNT will return the total number of payments in the batch. However, if the current level is RequestHeader, the COUNT will return the total number of payments in the file across all batches. If the argument is a record type, the count function will count all the generated records of the (child level) record type belonging to the current level instance.
INTEGER_PART, DECIMAL_PART - returns the integer or decimal portion of a numeric value. This is used in nested expressions and in commands (display condition and group by). For the final formatting of a numeric field in the data column, use the Integer/Decimal format.
IS_NUMERIC - boolean test whether the argument is numeric. Used only with the "IF" control structure.
TRUNCATE - truncate the first argument - a string to the length of the second argument. If the first argument is shorter than the length specified by the second argument, the first argument is returned unchanged. This is a user-friendly version for a subset of the SQL substr() functionality.
SUM - sums all the child instance of the XML extract field argument. The field must be a numeric value. The field to be summed must always be at a lower level than the level on which the SUM function was declared.
MIN, MAX - find the minimum or maximum of all the child instances of the XML extract field argument. The field must be a numeric value. The field to be operated on must always be at a lower level than the level on which the function was declared.
FORMAT_DATE - Formats a date string to any desirable date format. For example:
FORMAT_DATE("1900-01-01T18:19:20", "YYYY/MM/DD HH24:MI:SS")
will produce the following output:
1900/01/01 18:19:20
FORMAT_NUMBER – Formats a number to display in desired format. For example:
FORMAT_NUMBER("1234567890.0987654321", "999,999.99")
produces the following output:
1,234,567,890.10
MESSAGE_LENGTH - returns the length of the message in the EFT message.
RECORD_LENGTH - returns the length of the record in the EFT message.
INSTR – returns the numeric position of a named character within a text field.
SYSDATE, DATE – gets Current Date and Time.
POSITION – returns the position of a node in the XML document tree structure.
REPLACE – replaces a string with another string.
CONVERT_CASE – converts a string or a character to UPPER or LOWER case.
CHR – gets the character representation of an argument, which is an ASCII value.
LPAD, RPAD – generates left or right padding for string values.
AND, OR, NOT – operator functions on elements.
Other SQL functions include the following. Use the syntax corresponding to the SQL function.
TO_DATE
LOWER
UPPER
LENGTH
GREATEST
LEAST
DECODE
CEIL
ABS
FLOOR
ROUND
CHR
TO_CHAR
SUBSTR
LTRIM
RTRIM
TRIM
IN
TRANSLATE
This section lists the reserved key word and phrases and their usage. The supported operators are defined and the rules for referencing XML extract fields and using literals.
There are four categories of key words and key word phrases:
Command and column header key words
Command parameter and function parameter key words
Field-level key words
Expression key words
The following key words must be used as shown: enclosed in <>s and in all capital letters with a bold font.
<LEVEL> - the first entry of a data table. Associates the table with an XML element and specifies the hierarchy of the table.
<END LEVEL> - declares the end of the current level. Can be used at the end of a table or in a standalone table.
<POSITION> - column header for the first column of data field rows, which specifies the starting position of the data field in a record.
<LENGTH> - column header for the second column of data field rows, which specifies the length of the data field.
<FORMAT> - column header for the third column of data field rows, which specifies the data type and format setting.
<PAD> - column header for the fourth column of data field rows, which specifies the padding style and padding character.
<DATA> - column header for the fifth column of data field rows, which specifies the data source.
<COMMENT> - column header for the sixth column of data field rows, which allows for free form comments.
<NEW RECORD> - specifies a new record.
<DISPLAY CONDITION> - specifies the condition when a record should be printed.
<TEMPLATE TYPE> - specifies the type of the template, either FIXED_POSITION_BASED or DELIMITER_BASED.
<OUTPUT CHARACTER SET> - specifies the character set to be used when generating the output.
<NEW RECORD CHARACTER> - specifies the character(s) to use to signify the explicit and implicit new records at runtime.
<DEFINE LEVEL> - defines a format-specific level in the template.
<BASE LEVEL> - subcommand for the define level and define concatenation commands.
<GROUPING CRITERIA> - subcommand for the define level command.
<END DEFINE LEVEL> - signifies the end of a level.
<DEFINE SEQUENCE> - defines a record or extract element based sequence for use in the template fields.
<RESET AT LEVEL> - subcommand for the define sequence command.
<INCREMENT BASIS> - subcommand for the define sequence command.
<START AT> - subcommand for the define sequence command.
<MAXIMUM> - subcommand for the define sequence command.
<MAXIMUM LENGTH> - column header for the first column of data field rows, which specifies the maximum length of the data field. For DELIMITER_BASED templates only.
<END DEFINE SEQUENCE> - signifies the end of the sequence command.
<DEFINE CONCATENATION> - defines a concatenation of child level item that can be referenced as a string the parent level fields.
<ELEMENT> - subcommand for the define concatenation command.
<DELIMITER> - subcommand for the define concatenation command.
<END DEFINE CONCATENATION> - signifies the end of the define concatenation command.
<SORT ASCENDING> - format-specific sorting for the instances of a level.
<SORT DESCENDING> - format-specific sorting for the instances of a level.
These key words must be entered in all capital letters, nonbold fonts.
PERIODIC_SEQUENCE - used in the reset at level subcommand of the define sequence command. It denotes that the sequence number is to be reset outside the template.
FIXED_POSITION_BASED, DELIMITER_BASED - used in the template type command, specifies the type of template.
RECORD, LEVEL - used in the increment basis subcommand of the define sequence command. RECORD increments the sequence each time it is used in a new record. LEVEL increments the sequence only for a new instance of the level.
Alpha - in the <FORMAT> column, specifies the data type is alphanumeric.
Number - in the <FORMAT> column, specifies the data type is numeric.
Integer - in the <FORMAT> column, used with the Number key word. Takes the integer part of the number. This has the same functionality as the INTEGER function, except the INTEGER function is used in expressions, while the Integer key word is used in the <FORMAT> column only.
Decimal - in the <FORMAT> column, used with the Number key word. Takes the decimal part of the number. This has the same functionality as the DECIMAL function, except the DECIMAL function is used in expressions, while the Decimal key word is used in the <FORMAT> column only.
Date - in the <FORMAT> column, specifies the data type is date.
L, R- in the <PAD> column, specifies the side of the padding (Left or Right).
Key words and phrases used in expressions must be in capital letters and bold fonts.
IF THEN ELSE IF THEN ELSE END IF - these key words are always used as a group. They specify the "IF" control structure expressions.
IS NULL, IS NOT NULL - these phrases are used in the IF control structure. They form part of boolean predicates to test if an expression is NULL or not NULL.
There are two groups of operators: the boolean test operators and the expression operators. The boolean test operators include: "=", "<>", "<", ">", ">=", and "<=". They can be used only with the IF control structure. The expression operators include: "()", "||", "+", "-", and "*". They can be used in any expression.
| Symbol | Usage |
|---|---|
| = | Equal to test. Used in the IF control structure only. |
| <> | Not equal to test. Used in the IF control structure only. |
| > | Greater than test. Used in the IF control structure only. |
| < | Less than test. Used in the IF control structure only. |
| >= | Greater than or equal to test. Used in the IF control structure only. |
| <= | Less than or equal to test. Used in the IF control structure only. |
| () | Function argument and expression group delimiter. The expression group inside "()" will always be evaluated first. "()" can be nested. |
| || | String concatenation operator. |
| + | Addition operator. Implicit type conversion may be performed if any of the operands are not numbers. |
| - | Subtraction operator. Implicit type conversion may be performed if any of the operands are not numbers. |
| * | Multiplication operator. Implicit type conversion may be performed if any of the operands are not numbers. |
| DIV | Division operand. Implicit type conversion may be performed if any of the operands are not numbers. Note that "/" is not used because it is part of the XPATH syntax. |
| IN | Equal-to-any-member-of test. |
| NOT IN | Negates the IN operator. Not-Equal-to-any-member-of test. |
XML elements can be used in any expression. At runtime they will be replaced with the corresponding field values. The field names are case-sensitive.
When the XML extract fields are used in the template, they must follow the XPATH syntax. This is required so that the BI Publisher engine can correctly interpret the XML elements.
There is always an extract element considered as the context element during the BI Publisher formatting process. When BI Publisher processes the data rows in a table, the level element of the table is the context element. For example, when BI Publisher processes the data rows in the Payment table, Payment is the context element. The relative XPATH you use to reference the extract elements are specified in terms of the context element.
For example if you need to refer to the PayeeName element in a Payment data table, you will specify the following relative path:
Payee/PayeeInfo/PayeeName
Each layer of the XML element hierarchy is separated by a backslash “/”. You use this notation for any nested elements. The relative path for the immediate child element of the level is just the element name itself. For example, you can use TransactionID element name as is in the Payment table.
To reference a parent level element in a child level table, you can use the “../” notation. For example, in the Payment table if you need to reference the BatchName element, you can specify ../BatchName. The “../” will give you Batch as the context; in that context you can use the BatchName element name directly as BatchName is an immediate child of Batch. This notation goes up to any level for the parent elements. For example if you need to reference the RequesterParty element (in the RequestHeader) in a Payment data table, you can specify the following:
../../TrxnParties/RequesterParty
You can always use the absolute path to reference any extract element anywhere in the template. The absolute path starts with a backslash “/”. For the PayeeName in the Payment table example above, you will have the following absolute path: /BatchRequest/Batch/Payment/Payee/PayeeInfo/PayeeName
The absolute path syntax provides better performance.
The identifiers defined by the setup commands such as define level, define sequence and define concatenation are considered to be global. They can be used anywhere in the template. No absolute or relative path is required. The base level and reset at level for the setup commands can also be specified. BI Publisher will be able to find the correct context for them.
If you use relative path syntax, you should specify it relative to the base levels in the following commands:
The element subcommand of the define concatenation command
The grouping criteria subcommand of the define level command
The extract field reference in the start at subcommand of the define sequence command should be specified with an absolute path.
The rule to reference an extract element for the level command is the same as the rule for data fields. For example, if you have a Batch level table and a nested Payment level table, you can specify the Payment element name as-is for the Payment table. Because the context for evaluating the Level command of the Payment table is the Batch.
However, if you skip the Payment level and you have an Invoice level table directly under the Batch table, you will need to specify Payment/Invoice as the level element for the Invoice table.
The XPATH syntax required by the template is very similar to UNIX/LINUX directory syntax. The context element is equivalent to the current directory. You can specify a file relative to the current directory or you can use the absolute path which starts with a “/”.
Finally, the extract field reference as the result of the grouping criteria sub-command of the define level command must be specified in single quotes. This tells the BI Publisher engine to use the extract fields as the grouping criteria, not their values.
![]()
Copyright © 2003, 2008, Oracle and/or its affiliates. All rights reserved.