



|
|
This section describes data services, the fundamental components of the BEA AquaLogic Data Services Platform integration layer. The following topics are covered:
A data service gives data users access to any information in the enterprise through a single access layer. Typically, a data service models a unit of information, such as a customer, sales order, or product. The set of data services collectively comprise the data integration layer in an IT environment.
In concrete terms, a data service is a file with a .ds extension that contains XML Query Language instructions for querying and transforming data. In many ways, a data service is similar to a Web service. It is modular and reusable. It has a contract made up of public functions and procedures for accessing its services. It conceals the details of the service implementation — generally involving data acquisition and transformation — from the user.
However, unlike a conventional Web service, at the core of each data service is an XML data type (shown in the Design View in Figure 3-1). When AquaLogic Data Services Platform acquires and integrates data in response to a request, it is returned in the shape defined by the XML data type, it concrete terms, its schema.
A service consumer — a client application, process, or another data service — uses read functions defined in the data service to get its information. It can also call a navigation function to get information from a related data service, typically passing an instance of the current data service as an argument. Another facility available from data services are procedures. These routines can invoke external processes that have side effects rather than return data. A data service can have any number of read functions, procedures, and navigation functions.
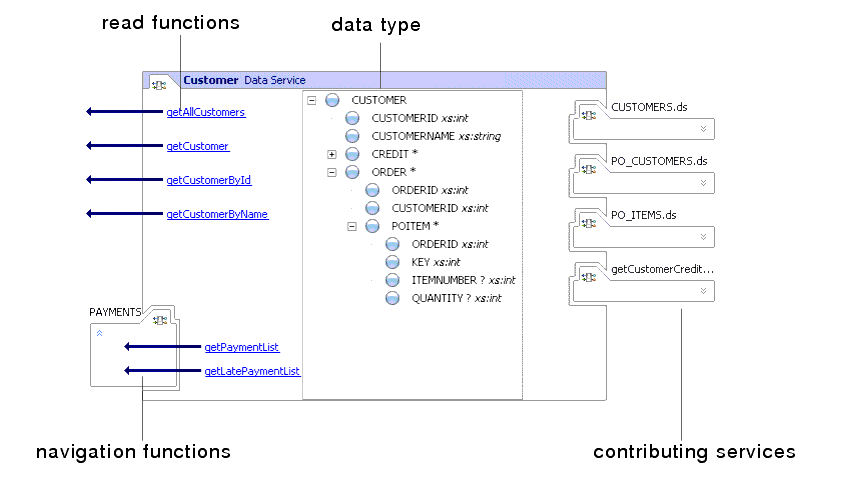
In addition to forming returned data as prescribed by its target XML schema, a data service can operate on data in other ways as well. It can through build-in XQuery functions perform mathematical calculations on numeric data, for example, or concatenate text strings.
It is through data service functions that client applications, controls, and processes obtain enterprise data. The data service interface consists of the public functions of the data service, which can be of several types:
It is important to keep in mind that — in accord with the goals of SOA — data services in general (and AquaLogic Data Services Platform functions in particular) provide "course grain" access to data. Coarse grain access relieves clients from the drudgery of identifying and aggregating information that collectively makes up a distinct business entity.
In addition to public interfaces, a data service can have private functions. Private functions can be used only by other functions within the data service. They generally contain common processing logic, that is, operations for use in more than one function in the data service.
There is also a facility for providing auxiliary functions across multiple data services. These are called XQuery Function Library (.xfl) files.
Read functions on a data service can be defined to return information in various ways. For example, the data service may define read functions for getting all customers, customers by region, or customers with a minimum order amount.
However, data users often want to access information in ways that are not entirely pre-specified or limited by the design of a data service. The filtering and ordering API allow client applications to control further what data is returned by a data service read function call based on conditions specified at runtime. Instead of having to create a read function for every possible client requirement, the service designer can create generalized read function against which clients can apply their own filtering or ordering conditions at runtime. It is left to the service architect to decide whether to create a set of narrowly-defined read functions, with access conditions built into the interface, or to create more generic read functions and allow the client to specify filtering conditions.
Between acquiring data from back-end systems and presenting that data to clients, a data service often transforms the data in some way. The nature of the transformation is determined by the XQuery body of the called function.
Transformations can involve simple element mappings, more general shape transformations, data joins, or value modifications by string operators, mathematical operators, or date operators. The structure and data in a transformation can be controlled by logical constructs such as if-then-else statements. The transformation may join data from multiple sources or filter data.
The XQuery Editor (shown in Figure 3-2) enables you to create a transformational query by dragging and dropping nodes between source and target schemas. A target schema is the XML type of the data service, that is, the shape of the data returned in response to service requests.
The internal language of a data service, XQuery (short for XML Query Language), is the emerging standard for querying XML-based information. XQuery has many features in common with SQL, such as where clauses. However, unlike SQL, which was intended for working with simple two-dimensional data format (rows and columns), XQuery is designed to work with the richer, Web service data that uses the nested structure approach of XML.
The XQuery functions in a data service determine what data is acquired by the service and how it is transformed. But the transformation is not limited to the format of the data; it can also affect the data value itself, for example, by concatenating strings or calculating mathematical operations on numeric values.
A significant challenge for enterprises is not only in integrating disparate data sources, but in advertising the availability of data in a consistent, reliable manner. If potential users of a data source do not know it exists, the data is effectively non-existent. Once a developer has gone to the trouble of creating a unified Customer data service, for example, other developers need to be able to discover and reuse it for their own work.
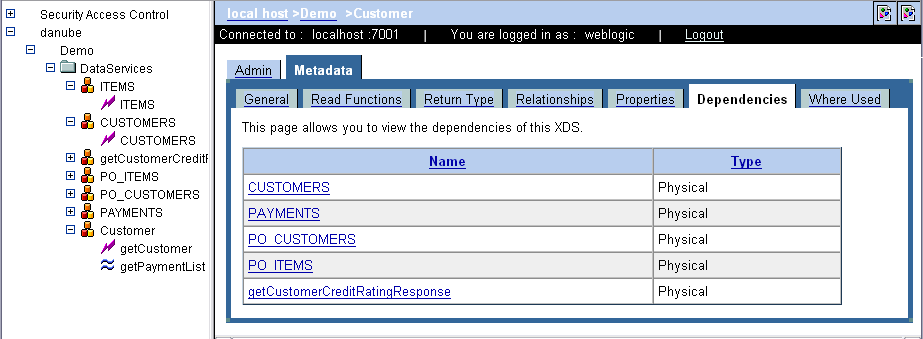
AquaLogic Data Services Platform uses a set of data service descriptors (or metadata) to supply enterprise-wide information on data services and their component functions and procedures. The metadata describes the data services — what information they provide and where the information comes from (that is, its lineage).
In addition to documenting services for potential consumers, metadata helps administrators determine what services are affected when inevitable changes occur in the data source layer. If a database changes, the administrator can easily tell which data services are affected by the change.
When changes do occur, a metadata synchronization wizard helps you to absorb data source level changes into the data services layers. The wizard, which is launched from Workshop, detects disparities between the schema of the data source and the physical data services. It highlights differences and allows them to be incorporated with a few clicks.
Those interested in metadata can access it in several ways. The metadata browser (shown in Figure 3-3) provides an HTML interface for browsing and searching metadata. Also, a Metadata API provides programmatic access to the same information.


|