|
|
A first step in creating data services for the BEA Aqualogic Data Services Platform is to obtain metadata from physical data needed by your application.
This chapter describes this process, including the following topics:
Metadata is simply information about the structure of a data source. For example, a list of the tables and columns in a relational database is metadata. A list of operations in a Web service is metadata.
In AquaLogic Data Services Platform, a physical data service is based almost entirely on the introspection of physical data sources.
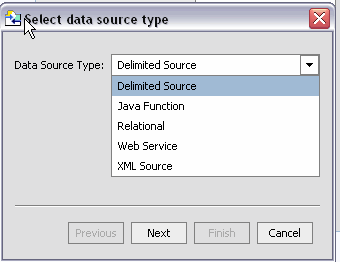
Table 3-2 list the types of sources from which AquaLogic Data Services Platform can create metadata.
When information about physical data is developed using the Metadata Import Wizard two things happen:
.ds) is created in your AquaLogic Data Services Platform-based project.extension.xsd), is created. This schema describes quite exactly the XML type of the data service. Such schemas are placed in a directory named schemas which is a sub-directory of your newly created data service.You can import metadata on the data sources needed by your application using the AquaLogic Data Services Platform Metadata Import wizard. This wizard introspects available data sources and identifies data objects that can be rendered as data services and functions. Once created, physical data services become the building-blocks for queries and logical data services.
Data source metadata can be imported as AquaLogic Data Services Platform functions or procedures. For example, the following source resulted from importing a Web service operation:
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="read" nativeName="getCustomerOrderByOrderID" nativeLevel1Container="ElecDBTest" nativeLevel2Container="ElecDBTestSoap" style="docu ment"/>::)
declare function f1:getCustomerOrderByOrderID($x1 as element(t1:getCustomerOrderByOrderID)) as schema-element(t1:getCustomerOrderByOrderIDResponse) external;
Notice that the imported Web service is described as a "read" function in the pragma. "External" refers to the fact that the schema is in a separate file. You can find a detailed description of source code annotations in "Understanding AquaLogic Data Services Platform Annotations" in the XQuery Reference Guide.
For some data sources such as Web services imported metadata represents functions which typically return void (in other words, these functions perform operations rather than returning data). Such routines are classified as side-effecting functions or, more formally, as AquaLogic Data Services Platform procedures. You also have the option of marking routines imported from certain data sources as procedures. (See Identifying AquaLogic Data Services Platform Procedures.)
The following source resulted from importing Web service metadata that includes an operation that has been identified as a side-effecting procedure:
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="hasSideEffects" nativeName="setCustomerOrder" style="document"/>::)
declare function f1:setCustomerOrder($x1 as element(t3:setCustomerOrder)) as schema-element(t3:setCustomerOrderResponse) external;
In the above pragma the function is identified as "hasSideEffects".
| Note: | AquaLogic Data Services Platform procedures are only associated with physical data services and can only be created through the metadata import process. So, for example, attempting to add procedures to a logical data service through Source View will result in an error condition. |
When you import source metadata for Web services, relational stored procedures, or Java functions you have an opportunity to identify the metadata that represents side-effecting routines. A typical example is a Web service that creates a new customer record. From the point of view of the data service such routines are procedures.
Procedures are not standalone; they always are part of a data service from the same data source.
When importing data from such sources the Metadata Import wizard automatically categorizes routines that return void as procedures. The reason for this is simply: if a routine does not return data it cannot inter-operate with other data service functions.
There are, however, routines that both return data and have side-effects; it is these routines which you need to identify as procedures during the metadata import process. Identification of such procedures provides the application developer with two key benefits:
Table 3-4 lists common AquaLogic Data Services Platform operations, identifying which operations are available or unavailable for data service procedures.
Procedures greatly simplify the process of updating non-relational back-end data sources by providing an invokeProcedure( ) API. This API encapsulates the operational logic necessary to invoke relational stored procedures, Web services, or Java functions. In such cases update logic can be built into a back-end data source routine which, in turn, updates the data.
For information on updating non-relational sources and other special cases see Handling Updates Through Data Services.
For an example showing how you can identify side-effecting procedures during the metadata import process see Importing Web Services Metadata.
You can obtain metadata on any relational data source available to the BEA WebLogic Platform. For details see the BEA Platform document entitled How Do I Connect a Database Control to a Database Such as SQL Server or Oracle.
Four types of metadata can be obtained from a relational data source:
| Note: | When using an XA transaction driver you need to mark your data source's connection pool to allow LocalTransaction in order for single database reads and updates to succeed. |
| Note: | For additional information in XA transaction adaptor settings see "Developing Adaptors" in BEA WebLogic Integration documentation: http://download.oracle.com/docs/cd/E13214_01/wli/docs81/devadapt/dbmssamp.html |
To create metadata on relational tables and views follow these steps:
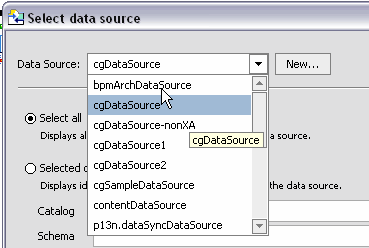
For information on creating a new data source see Creating a New Data Source.
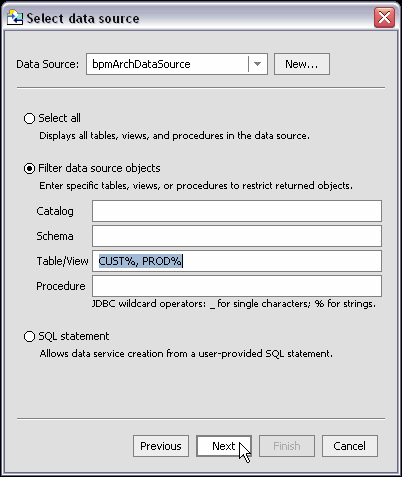
If you choose to select from an existing data source, several options are available (Figure 3-6).
If you choose to select all, a table will appear containing all the tables, views, and stored procedures in your data source organized by catalog and schema.
Sometimes you know exactly the objects in your data source that you want to turn into data services. Or your data source may be so large that a filter is needed. Or you may be looking for objects with specific naming characteristics (such as %audit2003%, a string which would retrieve all objects containing the enclosed string).
In such cases you can identify the exact parts of your relational source that you want to become data service candidates using standard JDBC wildcards. An underscore (_) creates a wildcard for an individual character. A percentage sign (%) indicates a wildcard for a string. Entries are case-sensitive.
For example, you could search for all tables starting with CUST with the entry: CUST%. Or, if you had a relational schema called ELECTRONICS, you could enter that term in the Schema field and retrieve all the tables, views, and stored procedure that are a part of that schema.
CUST%, PAY%
entered in the Tables/Views field retrieves all tables and views starting with either CUST or PAY.
| Note: | If no items are entered for a particular field, all matching items are retrieved. For example, if no filtering entry is made for the Procedure field, all stored procedures in the data object will be retrieved. |
For relational tables and views you should choose either the Select all option or Selected data source objects.
You can also use wildcards to support importing metadata on internal stored procedures. For example, entering the following string as a stored procedure filter:
%TRIM%
retrieves metadata on the system stored procedure:
STANDARD.TRIM
In such a situation you would also want to make a nonsense entry in the Table/View field to avoid retrieving all tables and views in the database.
For details on stored procedures see Importing Stored Procedure-Based Metadata.
Allows you to enter an SQL statement that is used as the basis for creating a data service. See Using SQL to Import Metadata for details.
Most often you will work with existing data sources. However, if you choose New... the WLS DataSource Viewer appears (Figure 3-7). Using the DataSource Viewer you can create new data pools and sources.
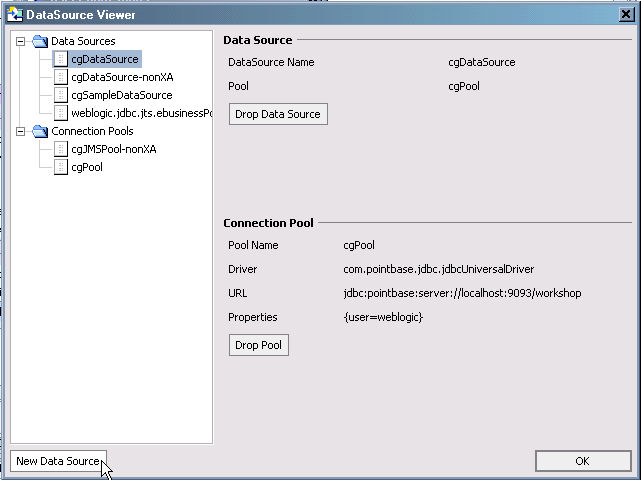
For details on using the DataSource Viewer see Configuring a Data Source in WebLogic Workshop documentation.
Only data sources that have set up through the BEA WebLogic Administration Console are available to a AquaLogic Data Services Platform application or project. In order for the BEA WebLogic Server used by AquaLogic Data Services Platform to access a particular relational data source you need to set up a JDBC connection pool and a JDBC data source.
Once you have selected a data source, you need to choose how you want to develop your metadata — by selecting all objects in the database, by filtering database objects, or by entering a SQL statement. (see Figure 3-6).
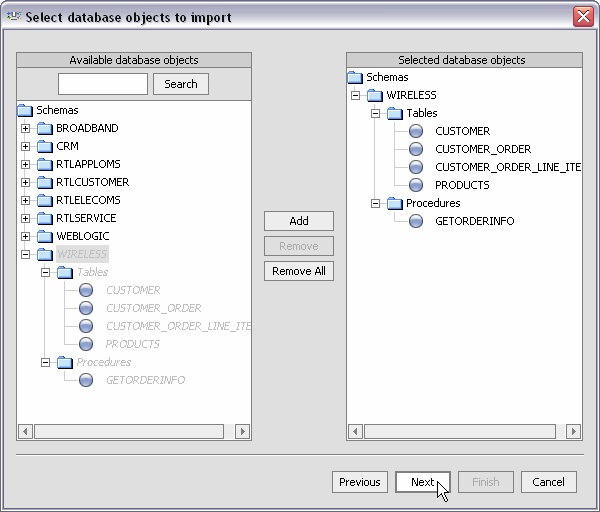
Once you have selected a data source and any optional filters, a list of available database objects appears.
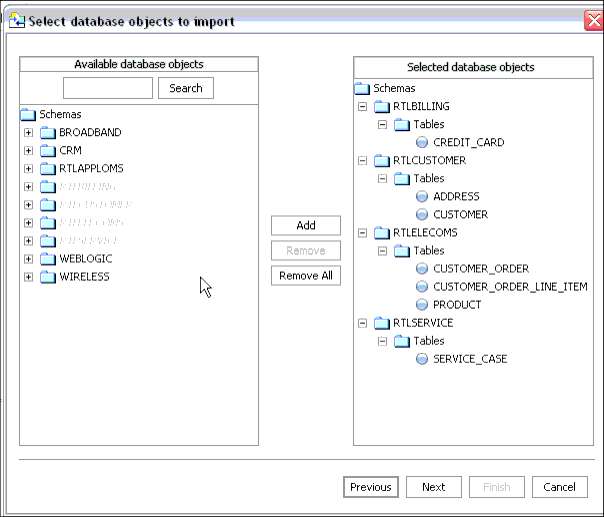
Using standard dialog commands you can add one or several tables to the list of selected data objects. To deselect a table, select that table in the right-hand column and click Remove.
A Search field is also available. This is useful for data sources which have many objects. Enter a search string, then click Search repeatedly to move through your list.
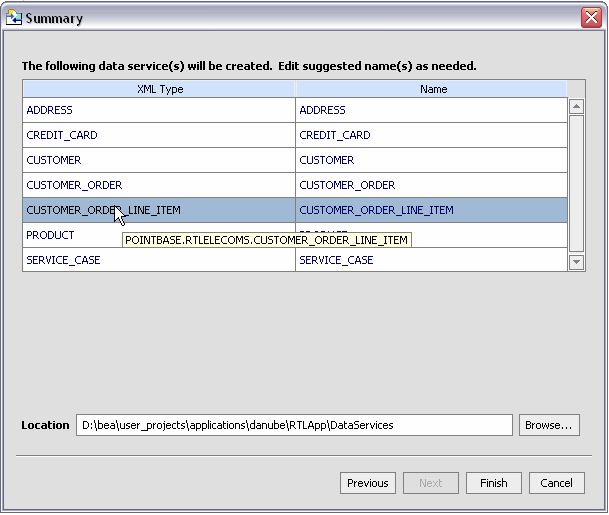
The imported data summary screen:
Alternatively, choose Remove All to return to the initial, nothing-is-selected state.
Database vendors variously support database catalogs and schemas. Table 3-11 describes this support for several major vendors.
When a source name is encountered that does not fit within XML naming conventions, default generated names are converted according to rules described by the SQLX standard. Generally speaking, an invalid XML name character is replaced by its hexadecimal escape sequence (having the form _xUUUU_).
For additional details see section 9.1 of the W3C draft version of this standard:
Once you have created your data services you are ready to start constructing logical views on your physical data. See Designing Data Services. and Modeling Data Services.
Many DBMS systems utilize stored procedures to improve query performance, manage and schedule data operations, enhance security, and so forth. For specifically supported vendors you can import metadata based on stored procedures. Each stored procedure becomes a data service.
| Note: | See Supported Configurations in AquaLogic Data Services Platform Release Notes. For details on creating and managing stored procedures see the documentation for the particular DBMS. |
Stored procedures are essentially database objects that logically group a set of SQL and native database programming language statements together to perform a specific task.
Table 3-12 defines some commonly used terms as they apply to this discussion of stored procedures.
Imported stored procedure metadata is quite similar to imported metadata for relational tables and views. The initial three steps for importing stored procedures are the same as importing any relational metadata (described under Importing Relational Table and View Metadata).
| Note: | If a stored procedure has only one return value and the value is either simple type or a RowSet which is mapping to an existing schema, no schema file created. |

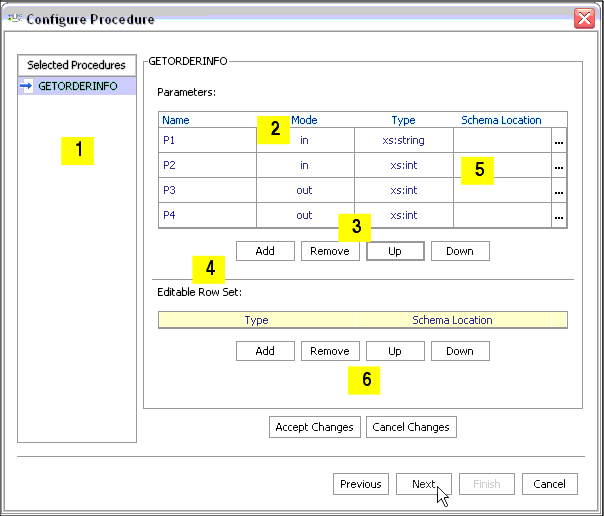
You can select any combination of database tables, views, and stored procedures. If you select one or several stored procedures, the Metadata Import wizard will guide you through the additional steps required to turn a stored procedure into a data service. These steps are:
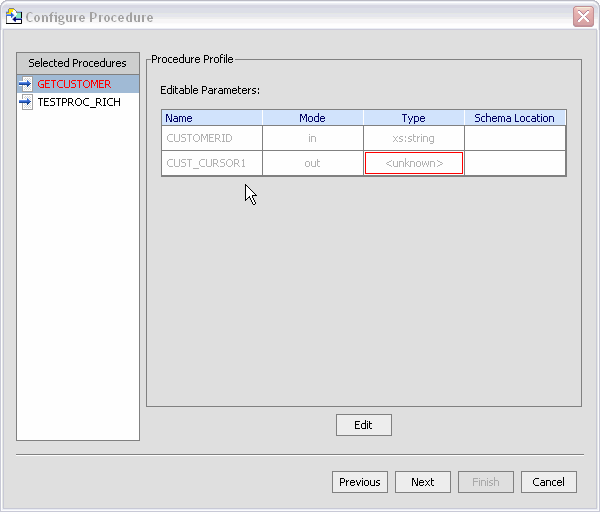
Data objects in the stored procedure that cannot be identified by the Metadata Import wizard will appear in red, without a datatype. In such cases you need to enter Edit mode (click the Edit button) to identify the data type.
Your goal in correcting an "<unknown>" condition associated with a stored procedure (Figure 3-14) is to bring the metadata obtained by the import wizard into conformance with the actual metadata of the stored procedure. In some cases this will be by correcting the location of the return type. In others you will need to adjust the type associated with an element of the procedure or add elements that were not found during the initial introspection of the stored procedure.
You need to complete information for each selected stored procedure before you can move to the next step. In particular, any stored procedures shown in red must be addressed.
Details for each section of the stored procedure import dialog box appear below.
Each element in a stored procedure is associated with a type. If the item is a simple type, you can simply choose from the pop-up list of types.
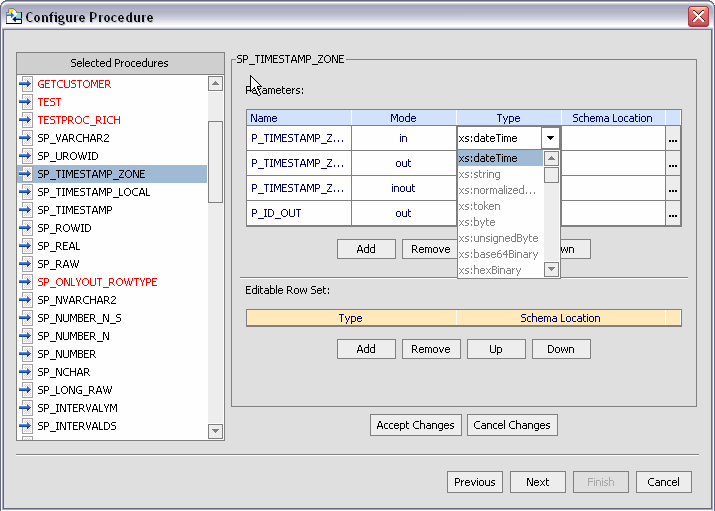
If the type is complex, you may need to supply an appropriate schema. Click on the schema location button and either enter a schema path name or browse to a schema. The schema must reside in your application.
After selecting a schema, both the path to the schema file and the URI appear. For example:
http://temp.openuri.org/schemas/Customer.xsd}CUSTOMER
The Metadata Import wizard, working through JDBC, also identifies any stored procedure parameters. This includes the name, mode (input [in], output [out], or bidirectional [inout]) and data type. The out mode supports the inclusion of a schema.
Complex type is only supported under three conditions:
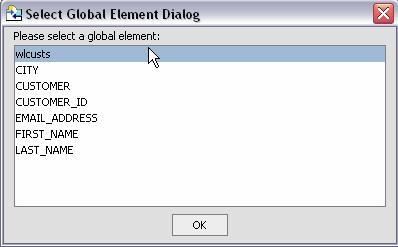
Not all databases support rowsets. In addition, JDBC does not report information related to defined rowsets. In order to create data services from stored procedures that use rowset information, supply the correct ordinal (matching number) and a schema. If the schema has multiple global elements, you can select the one you want from the Type column. Otherwise the type will be the first global element in your schema file.
The order of rowset information is significant; it must match the order in your data source. Use the Move Up / Move Down commands to adjust the ordinal number assigned to the rowset.
Complete the importation of your procedures by reviewing and accepting items in the Summary screen (see step 4 in Importing Relational Table and View Metadata for details).
| Note: | XML types in data services generated from stored procedures do not display native types. However, you can view the native type in the Source View pragma (see Working with XQuery Source). |
Handling Stored Procedure Rowsets
A rowset type is a complex type. The name of the rowset type can be:
The rowset type contains a sequence of a repeatable elements (for example called CUSTOMER) with the fields of the rowset.
| Note: | All rowset-type definitions must conform to this structure. |
In some cases the Metadata Import wizard can automatically detect the structure of a rowset and create an element structure. However, if the structure is unknown, you will need to provide it through the wizard.
It is often convenient to leverage independent routines as part of managing enterprise information through a data service. An obvious example would be to leverage standalone update or security functions through data services. Such functions have noXML type; in fact they typically return nothing (or void). Instead the data service knows that they have side-effects and are associated as procedures with a data service of the same data source.
Stored procedures are very often side-effecting from the perspective of the data service, since they perform internal operations on data. In such cases all you need to do is identify the stored procedures as a data service procedure during the metadata import process.
After you have identified the stored procedures that you want to add to your data service or XML file library (XFL), you also have an opportunity to identify which of these should be identified as data service procedures.
| Note: | Data service procedures based around atomic (simple) types are collected in an identified XML function library (XFL) file. Other procedures need to be associated with a data service that is local to your AquaLogic Data Services Platform-enabled project. |
You can import metadata for an internal stored procedures. See Filter Data Source Objects for details.
Only the most recent version of a stored procedure can be imported into AquaLogic Data Services Platform. For this reason you cannot identify a version number when importing a stored procedure through the Metadata Import wizard. Similarly, adding a version number to AquaLogic Data Services Platform source will result in a query exception.
If you know that an input parameter of a stored procedure is nullable (can accept null values), you can change the signature of the function in Source View to make such parameters optional by adding a question mark at end of the parameter. For example (question-mark shown in bold):
function myProc($arg1 as xs:string) ...
function myProc($arg1 as xs:string?) ...For additional information on Source View see Working with XQuery Source.
Each database vendor approaches stored procedures differently. XQuery support limitations are, in general, due to JDBC driver limitations.
AquaLogic Data Services Platform does not support rowset as an input parameter.
Table 3-18 summarizes AquaLogic Data Services Platform support for Oracle database procedures.
For a list of database types supported by AquaLogic Data Services Platform see Relational Data Types to XQuery Data Types.
|
|||
|
Table 3-19 summarizes AquaLogic Data Services Platform support for Sybase SQL Server database procedures.
For the complete list of database types supported by AquaLogic Data Services Platform see
Relational Data Types to XQuery Data Types.
|
|
|
|
|
Table 3-20 summarizes AquaLogic Data Services Platform support for IBM DB2 database procedures.
|
|
For the complete list of database types supported by AquaLogic Data Services Platform see
Relational Data Types to XQuery Data Types.
|
|
Float, double, and decimal data types are not supported as input/output parameters. |
Table 3-21 summarizes AquaLogic Data Services Platform support for Microsoft SQL Server database procedures.
One of the relational import metadata options (see Figure 3-6) is to use an SQL statement to customize introspection of a data source. If you select this option the SQL Statement dialog appears.
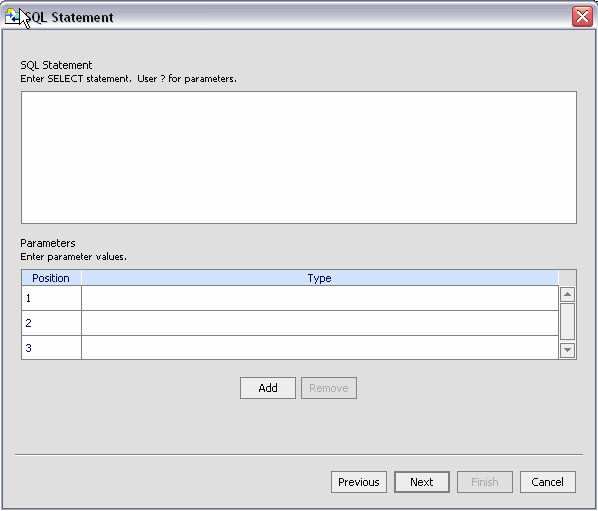
You can type or paste your SELECT statement into the statement box (Figure 3-22), indicating parameters with a "?" question-mark symbol. Using one of the AquaLogic Data Services Platform data samples, the following SELECT statement can be used:
SELECT * FROM RTLCUSTOMER.CUSTOMER WHERE CUSTOMER_ID = ?
RTLCUSTOMER is a schema in the data source, CUSTOMER is, in this case, a table.
For the parameter field, you would need to select a data type. In this case, CHAR or VARCHAR.
The next step is to assign a data service name.
When you run your query under Test View, you will need to supply the parameter in order for the query to run successfully.
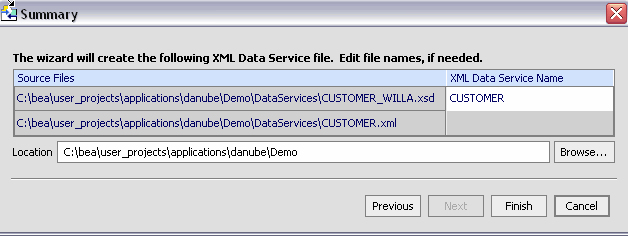
Once you have entered your SQL statement and any required parameters click Next to change or verify the name and location of your new data service.

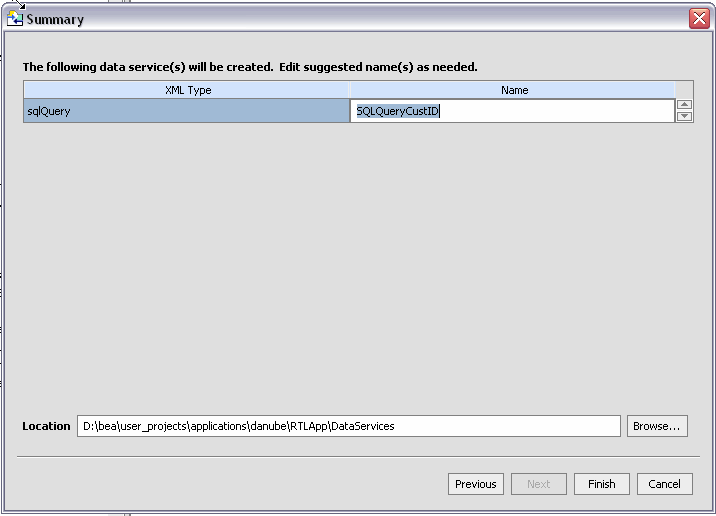
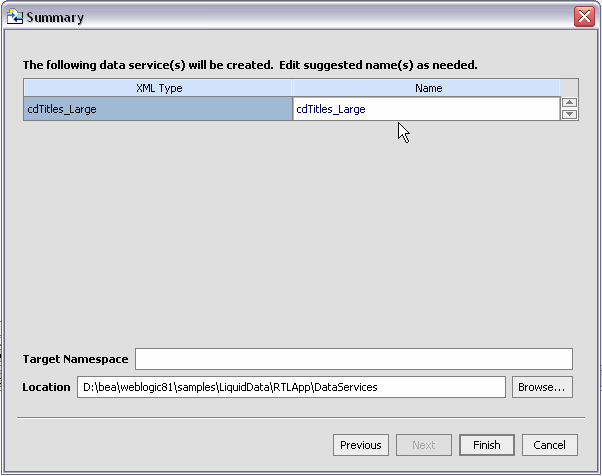
The imported data summary screen identifies a proposed name for your new data service.
The final steps are no different than you used to create a data service from a table or view.
Relational data types are necessarily mapped to XQuery data types when metadata is obtained. Specific mappings related to core and base support for relational data is described in the XQuery-SQL Mapping Reference in the XQuery Reference Guide.
When you import metadata from relational sources, you can provide logic in your application that maps users to different data sources depending on the user's role. This is accomplished by creating an interceptor and adding an attribute to the RelationalDB annotation for each data service in your application.
The interceptor is a Java class that implements the SourceBindingProvider interface. This class provides the logic for mapping a users, depending on their current credentials, to a logical data source name or names. This makes it possible to control the level of access to relational physical source based on the logical data source names.
For example, you could have the data source names cgDataSource1, cgDataSourc2, and cgDataSource3 defined on your WebLogic Server and define the logic in your class so that an user who is an administrator can access all three data sources, but a normal user only has access to the data source cgDataSource1.
| Note: | All relational, update overrides, stored procedure data services, or stored procedure XFL files that refer to the same relational data source should also use the same source binding provider; that is, if you specify a source binding provider for at least one of the data service (.ds) files, you should set it for the rest of them. |
To implement the interceptor logic, do the following:
com.bea.ld.binds.SourceBindingsProvider and define a getBindings() public method within the class. The signature of this method is:public String getBinding(String genericLocator, boolean isUpdate)
The genericLocator parameter specifies the current logical data source name. The isUpdate parameter indicates whether a read or an update is occurring. A value of true indicates an update. A value of false indicates a read. The string returned is the logical data source name to which the user is to be mapped. Listing 3-1 shows an example SQLInterceptor class.
sourceBindingProviderClassName attribute to the RelationalDB annotation. The attribute must be assigned the name of a valid Java class, which is the name of as your interceptor class. For example (the attribute and Java class are in bold):<relationalDB dbVersion="4" dbType="pointbase" name="cgDataSource" sourceBindingProviderClassName="sql.SQLInterceptor"/>public class SqlProvider implements com.bea.ld.bindings.SourceBindingProvider{
public String getBinding(String dataSourceName, boolean isUpdate) {
weblogic.security.Security security = new weblogic.security.Security();
javax.security.auth.Subject subject = security.getCurrentSubject();
weblogic.security.SubjectUtils subUtils =
new weblogic.security.SubjectUtils();
System.out.println(" the user name is " + subUtils.getUsername(subject));
if (subUtils.getUsername(subject).equals("weblogic"))
dataSourceName = "cgDataSource1"; System.out.println("The data source is " + dataSourceName);
System.out.println("SDO " + (isUpdate ? " YES " : " NO ") );
return dataSourceName;
}
}
A Web service is a self-contained, platform-independent unit of business logic that is accessible through application adaptors, as well as standards-based Internet protocols such as HTTP or SOAP.
Web services greatly facilitate application-to-application communication. As such they are increasingly central to enterprise data resources. A familiar example of an externalized Web service is a frequent-update weather portlet or stock quotes portlet that can easily be integrated into a Web application. Similarly, a Web service can be effectively used to track a drop shipment order from a seller to a manufacturer.
| Note: | Multi-dimensional arrays in RPC mode are not supported. |
Creating a data service based on a Web service definition (schema) is similar to importing relational data source metadata (see Importing Relational Table and View Metadata).
Here are the Web service-specific steps involved:
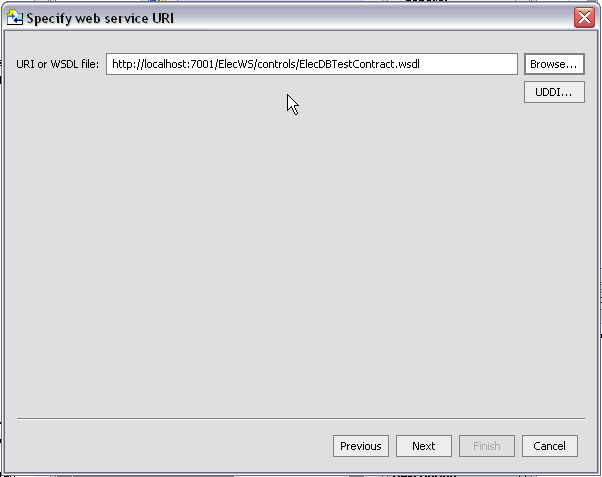
| Note: | For the purpose of showing how to import Web service metadata a WSDL file from the RTLApp sample is used for the remaining steps. If you are following these instructions enter the following into the URI field to access the WSDL included with RTLApp: |
| Note: | http://localhost:7001/ElecWS/controls/ElecDBTestContract.wsdl |
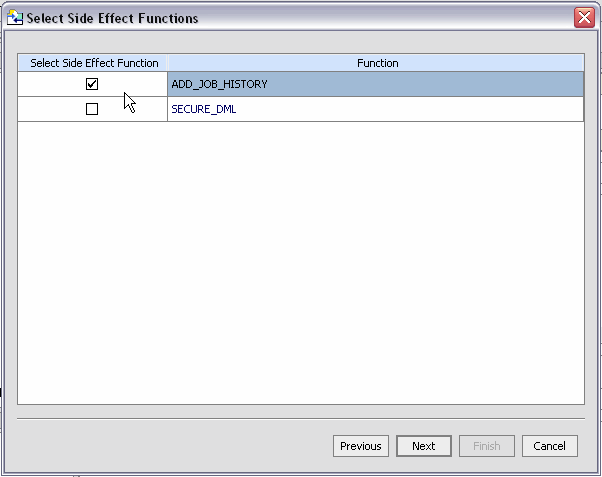
| Note: | Imported operations returning void are automatically imported as AquaLogic Data Services Platform procedures. You can identify other operations as procedures using the Select Side Effect Procedures dialog ( Figure 3-25). |
It is often convenient to leverage side-effecting operations as part of managing enterprise information through a data service. An obvious example would be to manage standalone update or security functions through data services. The data service registers that such operations have side-effects.
Procedures are not standalone; they always are part of a data service from the same data source.
Web services are side-effecting from the perspective of the data service even when they do return data. In such cases, you need to associate the Web service operation with a data service during the metadata import process.
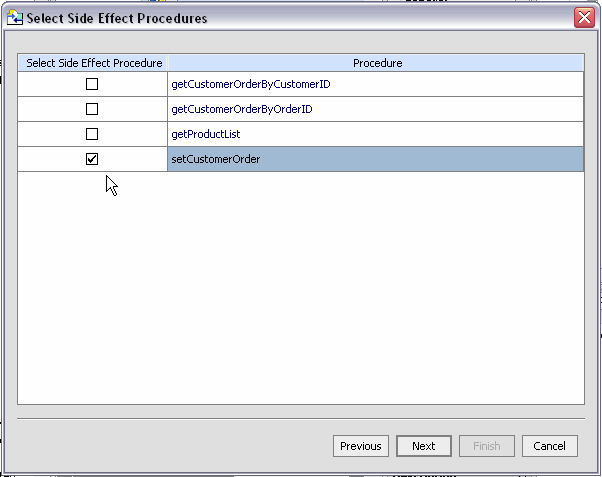
Procedures must be associated with a data service that is local to a AquaLogic Data Services Platform-enabled project.
Using standard dialog editing commands you can select one or several operations to be added to the list of selected Web service operations. To deselect an operation, click on it, then click Remove. Or choose Remove All to return to the initial state.
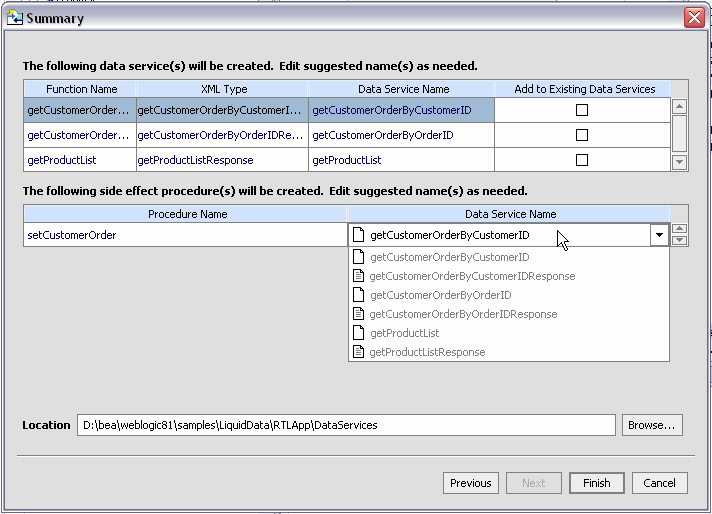
The summary screen shown in Figure 3-27:
Even if there are no name conflicts you may want to change a data service name for clarity. Simply click on the name of the data service and enter the new name.
| Note: | Web Service functions identified as side-effecting procedures must be associated with a data service based on the same WSDL. |
| Note: | When importing a Web service operation that itself has one or more dependent (or referenced) schemas, the Metadata Import wizard creates second-level schemas according to internal naming conventions. If several operations reference the same secondary schemas, the generated name for the secondary schema may change if you re-import or synchronize with the Web service. |
If you are interested in trying the Metadata Import wizard with an internet Web service URI, the following page (available as of this writing) provides sample URIs:
http://www.strikeiron.com/BrowseMarketplace.aspx?c=14&m=1Simply select a topic and navigate to a page showing the sample WSDL address such as:
http://ws.strikeiron.com/SwanandMokashi/StockQuotes?WSDL
Copy the string into the Web service URI field and click Next to select the operations want to turn into sample data services or procedures.
Another external Web service that can be used to test metadata import can be located at:
http://www.whitemesa.net/wsdl/std/echoheadersvc.wsdl
When you import metadata from web services for AquaLogic Data Services Platform, you can create SOAP handler for intercepting SOAP requests and responses. The handler will be invoked when a web service method is called. You can chain handlers that are invoked one after another in a specific sequence by defining the sequence in a configuration file.
To create and chain handlers, follow these two steps:
package WShandler;
import java.util.Iterator;
import javax.xml.rpc.handler.MessageContext;
import javax.xml.rpc.handler.soap.SOAPMessageContext;
import javax.xml.soap.SOAPElement;
import javax.xml.rpc.handler.HandlerInfo;
import javax.xml.rpc.handler.GenericHandler;
import javax.xml.namespace.QName;
/**
* Purpose: Log all messages to the Server console
*/
public class WShandler extends GenericHandler
{
HandlerInfo hinfo = null;
public void init (HandlerInfo hinfo) {
this.hinfo = hinfo;
System.out.println("*****************************");
System.out.println("ConsoleLoggingHandler r: init");
System.out.println(
"ConsoleLoggingHandler : init HandlerInfo" + hinfo.toString());
System.out.println("*****************************");
}
/**
* Handles incoming web service requests and outgoing callback requests
*/
public boolean handleRequest(MessageContext mc) {
logSoapMessage(mc, "handleRequest");
return true;
}
/**
* Handles outgoing web service responses and
* incoming callback responses
*/
public boolean handleResponse(MessageContext mc) {
this.logSoapMessage(mc, "handleResponse");
return true;
}
/**
* Handles SOAP Faults that may occur during message processing
*/
public boolean handleFault(MessageContext mc){
this.logSoapMessage(mc, "handleFault");
return true;
}
public QName[] getHeaders() {
QName [] qname = null;
return qname;
}
/**
* Log the message to the server console using System.out
*/
protected void logSoapMessage(MessageContext mc, String eventType){
try{
System.out.println("*****************************");
System.out.println("Event: "+eventType);
System.out.println("*****************************");
}
catch( Exception e ){
e.printStackTrace();
}
}
/**
* Get the method Name from a SOAP Payload.
*/
protected String getMethodName(MessageContext mc){
String operationName = null;
try{
SOAPMessageContext messageContext = (SOAPMessageContext) mc;
// assume the operation name is the first element
// after SOAP:Body element
Iterator i = messageContext.
getMessage().getSOAPPart().getEnvelope().getBody().getChildElements();
while ( i.hasNext() )
{
Object obj = i.next();
if(obj instanceof SOAPElement)
{
SOAPElement e = (SOAPElement) obj;
operationName = e.getElementName().getLocalName();
break;
}
}
}
catch(Exception e){
e.printStackTrace();
}
return operationName;
}
}
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema targetNamespace="http://www.bea.com/2003/03/wlw/handler/config/" xmlns="http://www.bea.com/2003/03/wlw/handler/config/" xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" attributeFormDefault="unqualified">
<xs:element name="wlw-handler-config">
<xs:complexType>
<xs:sequence>
<xs:element name="handler-chain" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="handler">
<xs:complexType>
<xs:sequence>
<xs:element name="init-param"
minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description"
type="xs:string" minOccurs="0"/>
<xs:element name="param-name" type="xs:string"/>
<xs:element name="param-value" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="soap-header"
type="xs:QName" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="soap-role"
type="xs:string" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="handler-name"
type="xs:string" use="optional"/>
<xs:attribute name="handler-class"
type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="name" type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
The following is an example of the handler chain configuration. In this configuration, there are two chains. One is named LoggingHandler. The other is named SampleHandler. The first chain invokes only one handler named AuditHandler. The handler-class attribute specifies the fully qualified name of the handler.
<?xml version="1.0"?>
<hc:wlw-handler-config name="sampleHandler" xmlns:hc="http://www.bea.com/2003/03/wlw/handler/config/">
<hc:handler-chain name="LoggingHandler">
<hc:handler
handler-name="handler1"handler-class="WShandler.AuditHandler"/>
</hc:handler-chain>
<hc:handler-chain name="SampleHandler">
<hc:handler
handler-name="TestHandler1" handler-class="WShandler.WShandler"/>
<hc:handler handler-name="TestHandler2"
handler-class="WShandler.WShandler"/>
</hc:handler-chain>
</hc:wlw-handler-config>
xquery version "1.0" encoding "WINDOWS-1252";
(::pragma xds <x:xds xmlns:x="urn:annotations.ld.bea.com"
targetType="t:echoStringArray_return"
xmlns:t="ld:SampleWS/echoStringArray_return">
<creationDate>2005-05-24T12:56:38</creationDate>
<webService targetNamespace=
"http://soapinterop.org/WSDLInteropTestRpcEnc"
wsdl="http://webservice.bea.com:7001/rpc/WSDLInteropTestRpcEncService?WSDL"/></x:xds>::)
declare namespace f1 = "ld:SampleWS/echoStringArray_return";
import schema namespace t1 = "ld:AnilExplainsWS/echoStringArray_return" at "ld:SampleWS/schemas/echoStringArray_param0.xsd";
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="read" nativeName="echoStringArray" nativeLevel1Container="WSDLInteropTestRpcEncService" nativeLevel2Container="WSDLInteropTestRpcEncPort" style="rpc">
<params>
<param nativeType="null"/>
</params>
<interceptorConfiguration aliasName="LoggingHandler" fileName="ld:SampleWS/handlerConfiguration.xml" />
</f:function>::)
declare function f1:echoStringArray($x1 as element(t1:echoStringArray_param0)) as schema-element(t1:echoStringArray_return) external;
<interceptorConfiguration aliasName="LoggingHandler" fileName="ld:testHandlerWS/handlerConfiguration.xml">
Here the aliasName attribute specifies the name of the handler chain to be invoked and the fileName attribute specifies the location of the configuration file.
You can create metadata based on custom Java functions. When you use the Metadata Import wizard to introspect a .class file, metadata is created around both complex and simple types. Complex types become data services while simple Java routines are converted into XQueries and placed in an XQuery function library (XFL). In Source View (see Working with XQuery Source) a pragma is created that defines the function signature and relevant schema type for complex types such as Java classes and elements.
In the RTLApp DataServices/Demo directory there is a sample that can be used to illustrate Java function metadata import.

Your Java file can contains two types of functions. These are described in Table 3-28:
Before you can create metadata on a custom Java function you must create a Java class containing both schema and function information. A detailed example is described in Creating XMLBean Support for Java Functions.
Importing Java function metadata is similar to importing relational data source metadata (see Importing Relational Table and View Metadata). Here are the Java function-specific steps involved:
.class file from your .java function and place it in your application's library..class file must be in your BEA WebLogic application. You can browse to your file or enter a fully-qualified path name starting from the root directory of your AquaLogic Data Services Platform-based project.It is often convenient to leverage independent routines as part of managing enterprise information through a data service. An obvious example would be to leverage standalone update or security functions through data services. Such functions have noXML type; in fact they typically return nothing (or void). Instead the data service knows that the routine has side-effects, but those effects are not transparent to the service. AquaLogic Data Services Platform procedures can also be thought of as side-effecting functions.
Java functions are "side-effecting" from the perspective of the data service when they perform internal operations on data.
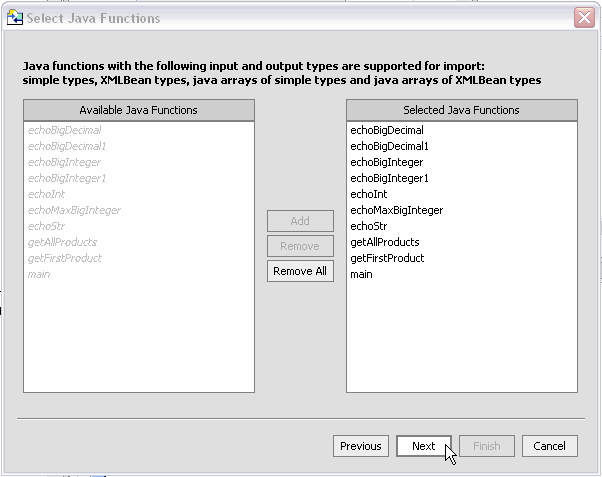
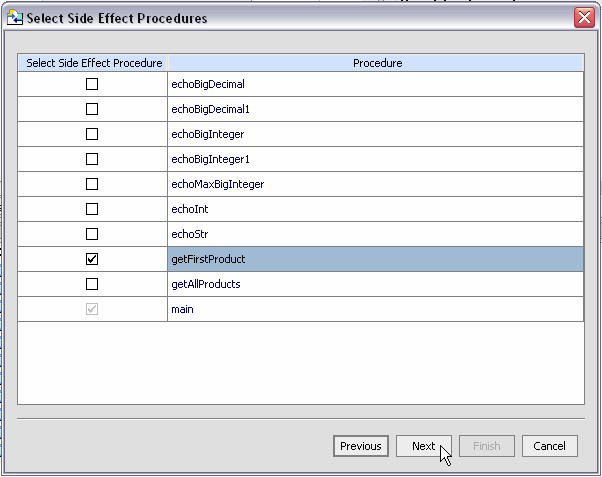
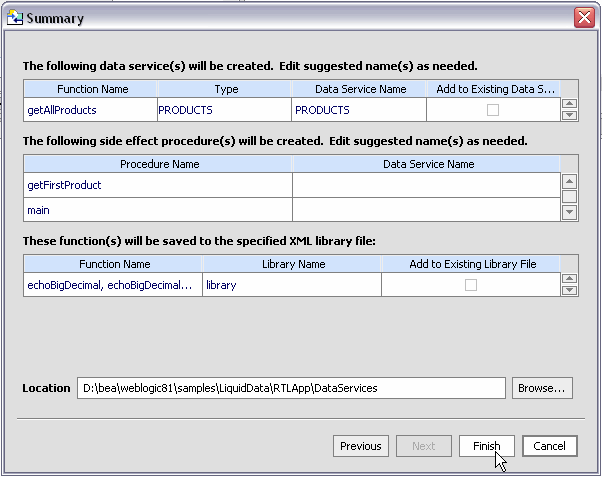
After you have identified the Java functions that you want to add to your project, you can also identify which, if any, of these should be treated as AquaLogic Data Services Platform procedures (Figure 3-32). In the case of main(), the Metadata Import wizard detects that it returns void so it is already marked as a procedure.
Functions based around atomic (simple) types are collected in an identified XML function library (XFL) file.
| Note: | Side-effecting procedures must to be associated with a data service that is from the same data source. In this case, the source is your Java file. In other words, in order to specify a Java function as a procedure, a function in the same file that returns a complex element must either be created at the same time or already exist in your project. |
You can edit the proposed data service name either for clarity or to avoid conflicts with other existing or planned data services. All functions returning complex data types will be in the same data service. Click on the proposed data service name to change it.
Procedures must be associated with a data service that draws data from the same data source (Java file). In the sample shown in Figure 3-33, the only available data service is PRODUCTS (or whatever name you choose).
If there are existing XFL files in your project you have the option of adding atomic functions to that library or creating a new library for them. All the Java file atomic functions are located in the same library.
Before you can import Java function metadata, you need to create a .class file that contains XMLBean classes based on global elements and compiled versions of your Java functions. To do this, you first create XMLBean classes based on a schema of your data. There are several ways to accomplish this. In the example in this section you create a WebLogic Workshop project of type Schema.
Generally speaking, the process involves:
.xsd file) representing the shape of the global elements invoked by your function..class file, if under a AquaLogic Data Services Platform-based project, or you can add the JAR file from a Java project to the Library folder of your application..class file.| Note: | The Java function import wizard requires that all the complex parameter or return types used by the functions correspond to XMLBean global element types whose content model is an anonymous type. Thus only functions referring to a top level element are importend. |
In the following example there are a number of custom functions in a .java file called FuncData.java. In the RTLApp this file can be found at:
ld:DataServices/Demo/Java/FuncData.java
Some functions in this file return primitive data types, while others return a complex element (Table 3-34). The complex element representing the data to be introspected is in a schema file called FuncData.xsd.
The schema file can be found at:
ld:DataServices/Demo/Java/schema/FuncData.xsd
To simplify the example a small data set is included in the .java file as a string.
The following steps will create a data service from the Java functions in FuncData.java:
FuncData.xsd for import.Importing a schema file into a schema project automatically starts the project build process.
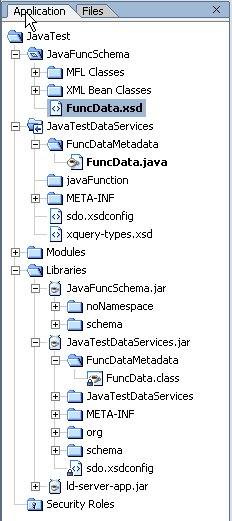
When successful, XMLBean classes are created for each function in your Java file and placed in a JAR file called JavaFunctSchema.jar
The JAR file is located in the Libraries section of your application.
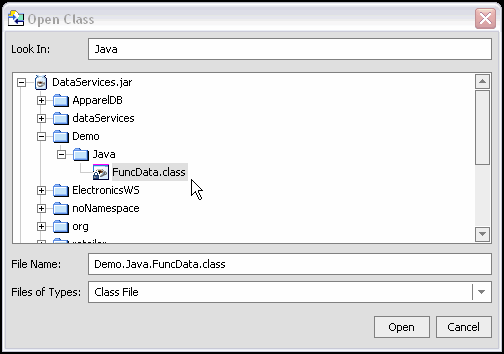
ld:DataServices/Demo/Java folder in the RTLApp and select FuncData.java for import. Click Import.
The JAR file named for your AquaLogic Data Services Platform-based project is updated to include a.class file named FuncData.class; It is this file that can be introspected by the Metadata Import wizard. The file is located in a folder named JavaFuncMetadata in the Library section of your application.
The .java file used in this example contains both functions and data. More typically, your routine will access data through a data import function.
The first function in Listing 3-4 simply retrieves the first element in an array of PRODUCTS. The second returns the entire array.
public class JavaFunc {
...
public static noNamespace.PRODUCTSDocument.PRODUCTS getFirstProduct(){
noNamespace.PRODUCTSDocument.PRODUCTS products = null;
try{
noNamespace.DbDocument dbDoc = noNamespace.DbDocument.Factory.parse(testCustomer);
products = dbDoc.getDb().getPRODUCTSArray(1);
//return products;
}catch(Exception e){
e.printStackTrace();
}
return products;
}
public static noNamespace.PRODUCTSDocument.PRODUCTS[] getAllProducts(){
noNamespace.PRODUCTSDocument.PRODUCTS[] products = null;
try{
noNamespace.DbDocument dbDoc = noNamespace.DbDocument.Factory.parse(testCustomer);
products = dbDoc.getDb().getPRODUCTSArray();
//return products;
}catch(Exception e){
e.printStackTrace();
}
return products;
}
}
The schema used to create XMLBeans is shown in Listing 3-5. It simply models the structure of the complex element; it could have been obtained by first introspecting the data directly.
<xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="db">
<xs:complexType>
<xs:sequence>
<xs:element ref="PRODUCTS" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="AVERAGE_SERVICE_COST" type="xs:decimal"/>
<xs:element name="LIST_PRICE" type="xs:decimal"/>
<xs:element name="MANUFACTURER" type="xs:string"/>
<xs:element name="PRODUCTS">
<xs:complexType>
<xs:sequence>
<xs:element ref="PRODUCT_NAME"/>
<xs:element ref="MANUFACTURER"/>
<xs:element ref="LIST_PRICE"/>
<xs:element ref="PRODUCT_DESCRIPTION"/>
<xs:element ref="AVERAGE_SERVICE_COST"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="PRODUCT_DESCRIPTION" type="xs:string"/>
<xs:element name="PRODUCT_NAME" type="xs:string"/>
</xs:schema>
Java functions require that an element returned (as specified in the return signature) come from a valid XML document. A valid XML document has a single root element with zero or more children, and its content matches the schema referred.
public static noNamespace.PRODUCTSDocument.PRODUCTS getNextProduct(){
// create the dbDocument (the root)
noNamespace.DbDocument dbDoc = noNamespace.DbDocument.Factory.newInstance();
// the db element from it
noNamespace.DbDocument.Db db = dbDoc.addNewDb();
// get the PRODUCTS element
PRODUCTS product = db.addNewPRODUCTS();
//.. create the children
product.setPRODUCTNAME("productName");
product.setMANUFACTURER("Manufacturer");
product.setLISTPRICE(BigDecimal.valueOf((long)12.22));
product.setPRODUCTDESCRIPTION("Product Description");
product.setAVERAGESERVICECOST(BigDecimal.valueOf((long)122.22));
// .. update children of db
db.setPRODUCTSArray(0,product);
// .. update the document with db
dbDoc.setDb(db);
//.. now dbDoc is a valid document with db and is children.
// we are interested in PRODUCTS which is a child of db.
// Hence always create a valid document before processing the
children.
// Just creating the child element and returning it, is not
// enough, since it does not mean the document is valid.
// The child needs to come from a valid document, which is created
// for the global element only.
return dbDoc.getDb().getPRODUCTSArray(0);
}In AquaLogic Data Services Platform, user-defined functions are typically Java classes. The following are supported:
In order to support this functionality, the Metadata Import wizard supports marshalling and unmarshalling so that token iterators in Java are converted to XML and vice-versa.
Functions you create should be defined as static Java functions. The Java method name when used in an XQuery will be the XQuery function name qualified with a namespace.
Table 3-36 shows the casting algorithms for simple Java types, schema types and XQuery types.
Java functions can also consume variables of XMLBean type that are generated by processing a schema via XMLBeans. The classes generated by XMLBeans can be referred in a Java function as parameters or return types.
The elements or types referred to in the schema should be global elements because these are the only types in XMLBeans that have static parse methods defined.
The next section provides additional code samples that illustrate how Java functions are used by the Metadata Import wizard to create data services.
In order to create data services or members of an XQuery function library, you would first start with a Java function.
As an example, the Java function getListGivenMixed( ) can be defined as:
public static float[] getListGivenMixed(float[] fpList, int size) {
int listLen = ((fpList.length > size) ? size : fpList.length);
float fpListop = new float[listLen];
for (int i =0; i < listLen; i++)
fpListop[i]=fpList[i];
return fpListop;
}After the function is processed through the wizard the following metadata information is created:
xquery version "1.0" encoding "WINDOWS-1252";
(::pragma xfl <x:xfl xmlns:x="urn:annotations.ld.bea.com">
<creationDate>2005-06-01T14:25:50</creationDate>
<javaFunction class="DocTest"/>
</x:xfl>::)
declare namespace f1 = "lib:testdoc/library";
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" nativeName="getListGivenMixed">
<params>
<param nativeType="[F"/>
<param nativeType="int"/>
</params>
</f:function>::)
declare function f1:getListGivenMixed($x1 as xsd:float*, $x2 as xsd:int) as xsd:float* external;
Here is the corresponding XQuery for executing the above function:
declare namespace f1 = "ld:javaFunc/float";
let $y := (2.0, 4.0, 6.0, 8.0, 10.0)
let $x := f1:getListGivenMixed($y, 2)
return $x
Consider that you have a schema called Customer (customer.xsd), as shown below:
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema targetNamespace="ld:xml/cust:/BEA_BB10000" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="CUSTOMER">
<xs:complexType>
<xs:sequence>
<xs:element name="FIRST_NAME" type="xs:string" minOccurs="1"/>
<xs:element name="LAST_NAME" type="xs:string" minOccurs="1"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
If you want to generate a list conforming to the CUSTOMER element you could process the schema via XMLBeans and obtain xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER. Now you can use the CUSTOMER element as shown:
public static xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER[]
getCustomerListGivenCustomerList(
xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER[] ipListOfCust)
throws XmlException {
xml.cust.beaBB10000.CUSTOMERDocument.CUSTOMER [] mylocalver =
ipListOfCust;
return mylocalver;
}
Then the metadata information produced by the wizard will be:
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" kind="datasource" access="public">
<params>
<param nativeType="[Lxml.cust.beaBB10000.CUSTOMERDocument$CUSTOMER;"/>
</params>
</f:function>::)
declare function f1:getCustomerListGivenCustomerList($x1 as element(t1:CUSTOMER)*) as element(t1:CUSTOMER)* external;
The corresponding XQuery for executing the above function is:
declare namespace f1 = "ld:javaFunc/CUSTOMER";
let $z := (
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>),
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>),
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>),
validate(<n:CUSTOMER xmlns:n="ld:xml/cust:/BEA_BB10000"><FIRST_NAME>John2</FIRST_NAME><LAST_NAME>Smith2</LAST_NAME>
</n:CUSTOMER>))
for $zz in $z
return
f1:getCustomerListGivenCustomerList($z)
The following restrictions apply to Java functions:
Spreadsheets offer a highly adaptable means of storing and manipulating information, especially information which needs to be changed quickly. You can easily turn such spreadsheet data in a data services.
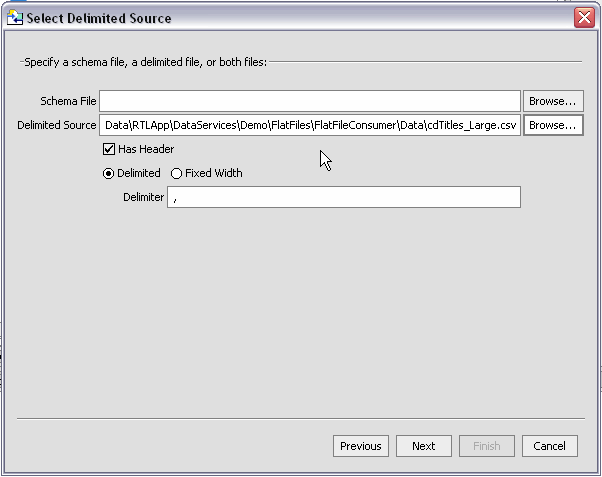
Spreadsheet documents are often referred to as CSV files, standing for comma-separated values. Although CSV is not a typical native format for spreadsheets, the capability to save spreadsheets as CSV files is nearly universal.
Although the separator field is often a comma, the Metadata Import wizard supports any ASCII character as a separator, as well as fixed-length fields.
| Note: | Delimited files in a single server must share the same encoding format. This encoding can be specified through the system property ld.csv.encoding and set through the JVM command-line directly or via a script such as startWebLogic.cmd (Windows) or startWebLogic.sh (UNIX). |
| Note: | Here is the format for this command: |
-Dld.csv.encoding=<encoding format>
If no format is specified through ld.csv.encoding, then the format specified in the file.encoding system property is used.
In the RTLApp DataServices/Demo directory there is a sample that can be used to illustrate delimited file metadata import.

There are several approaches to developing metadata around delimited information, depending on your needs and the nature of the source.
| Note: | The generated schema takes the name of the source file. |
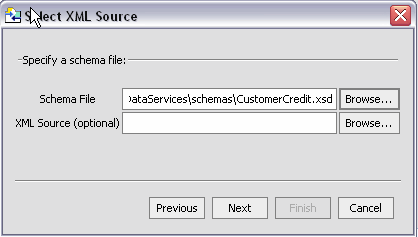
Importing XML file information is similar to importing a relational data source metadata (see Importing Relational Table and View Metadata). Here are the steps that are involved:
file:///
For example, on Windows systems you can access an XML file such as Orders.xml from the root C: directory using the following URI:
file:///<c:/home>/Orders.csv
On a UNIX system, you would access such a file with the URI:
file:///<home>/Orders.csv
,).You can edit the data service name either to clarify the name or to avoid conflicts with other existing or planned data services. Any name conflicts are displayed in red. To change the name, double click on the name of the data service to activate the line editor.
.ds file) will be created with your schema as its XML type. | Note: | When importing CSV-type data there are several things to keep in mind: |
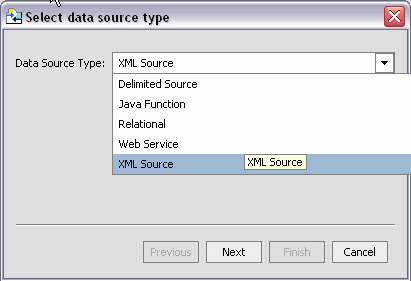
XML files are a convenient means of handling hierarchical data. XML files and associated schemas are easily turned into data services.
Importing XML file information is similar to importing a relational data source metadata (see Importing Relational Table and View Metadata).
The Metadata Import wizard allows you to browse for an XML file anywhere in your application. You can also import data from any XML file on your system using an absolute path prepended with the following:
file:///
For example, on Windows systems you can access an XML file such as Orders.xml from the root C: directory using the following URI:
file:///c:/Orders.xml
On a UNIX system, you would access such a file with the URI:
file:///home/Orders.xml
In the RTLApp DataServices/Demo directory there is a sample that can be used to illustrate XML file metadata import.
You can edit the data service name either to clarify the name or to avoid conflicts with other existing or planned data services. Conflicts are shown in red. Simply click on the name of the data service to change its name. Then click Next.
When you create metadata for an XML data source but do not supply a data source name, you will need to identify the URI of your data source as a parameter when you execute the data service's read function (various methods of accessing data service functions are described in detail in the Client Application Developer's Guide).
The identification takes the form of:
<uri>/path/filename.xml
where uri is representative of a path or path alias, path represents the directory and filename.xml represents the filename. The .xml extension is needed.
You can access files using an absolute path prepended with the following:
file:///
For example, on Windows systems you can access an XML file such as Orders.xml from the root C: directory using the following URI:
file:///c:/Orders.xml
On a UNIX system, you would access such a file with the URI:
file:///home/Orders.xml
Figure 3-44 shows how the XML source file is referenced.
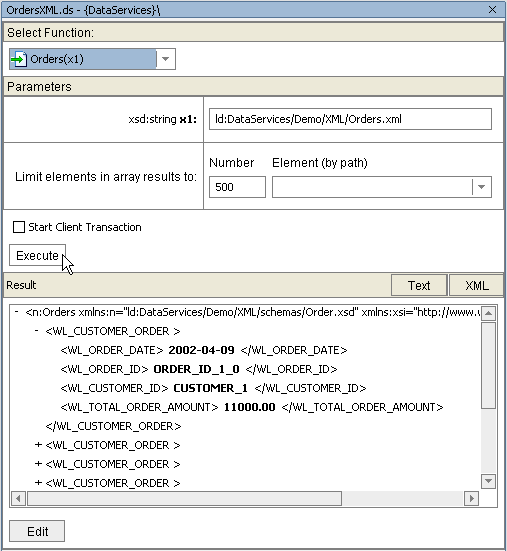
When you first create a physical data service its underlying metadata is, by definition, consistent with its data source. Over time, however, your metadata may become "out of sync" for several reasons:
You can use the Update Source Metadata right-click menu option to identify differences between your source metadata files and the structure of the source data including:
In the case of Source Unavailable, the issue likely relates to connectivity or permissions. In the case of the other types of reports, you can determine when and if to update data source metadata to conform with the underlying data sources.
If there are no differences between your metadata and the underlying source, the Update Source Metadata wizard will report up-to-date for each data service tested.
Source metadata should be updated with care since the operation can have both direct and indirect consequences. For example, if you have added a relationship between two physical data services, updating your source metadata can potentially remove the relationship from both data services. If the relationship appears in a model diagram, the relationship line will appear in red, indicating that the relationship is no longer described by the respective data services.
In many cases the Update Source Metadata Wizard can automatically merge user changes with the updated metadata. See Using the Update Source Metadata Wizard, for details.
Direct effects apply to physical data services. Indirect effects occur to logical data services, since such services are themselves ultimately based — at least in part — on physical data service. For example, if you have created a new relationship between a physical and a logical data service, updating the physical data service can invalidate the relationship. In the case of the physical data service, there will be no relationship reference. The logical data service will retain the code describing the relationship but it will be invalid if the opposite relationship notations is no longer be present.
Thus updating source metadata should be done carefully. Several safeguards are in place to protect your development effort while preserving your ability to keep your metadata up-to-date. See Archival of Source Metadata for information of how your current metadata is preserved as part of the source update.
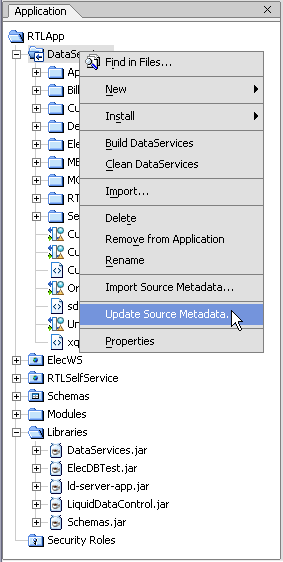
The Update Source Metadata wizard allows you to update your source metadata.
| Note: | Before attempting to update source metadata you should make sure that your build project has no errors. |
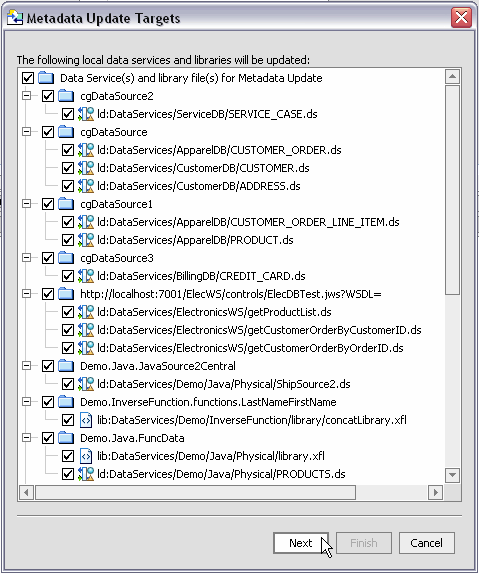
You can verify that your data structure is up-to-date by performing a metadata update on one or multiple physical data services in your AquaLogic Data Services Platform-based project. For example, in Figure 3-45 all the physical data services in the project will be updated.
After you select your target(s), the wizard identifies the metadata that will be verified and any differences between your metadata and the underlying source.
You can select/deselect any data service or XFL file listed in the dialog using the checkbox to the left of the name (Figure 3-46).
Next, an analysis is performed on your metadata by the wizard. The following types of synchronization mismatches are identified:
A update preview screen report (Figure 3-47) is prepared describing these differences both generally and for field-level data.
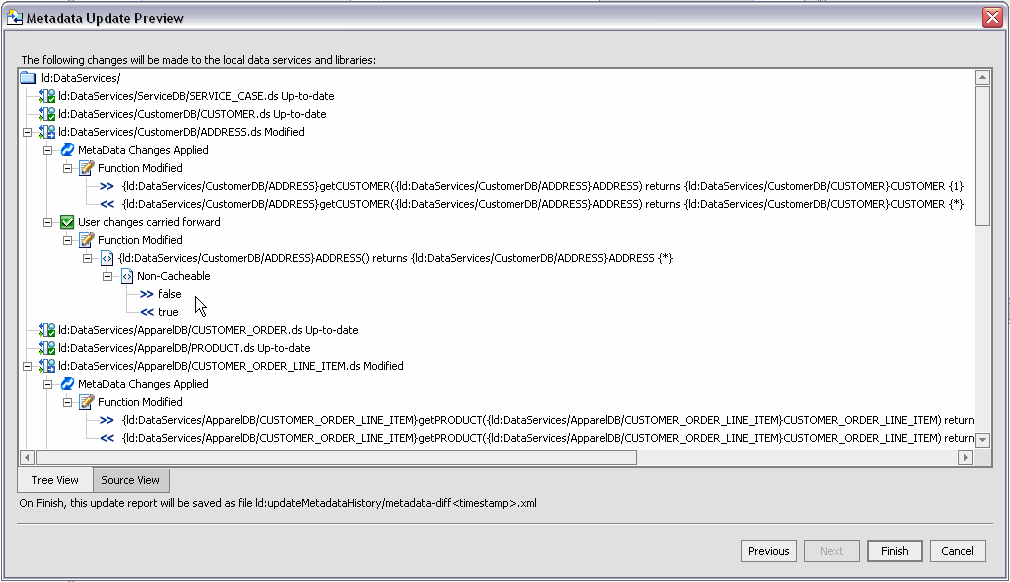
The Metadata Update Preview screen identifies:
Icons differentiate elements as to be added, removed, or changed. Table 3-48 describes the update source metadata message types and color legends.
Under some circumstances the Update Source Metadata wizard flags data service artifacts as changed locally when, in fact, no change was made.
For example, in the case of importing a Web service operation, a schema that is dependent (or referenced) by another schema will be assigned an internally-generated filename. If a second imported Web service operation in your project references the same dependent schema, upon synchronization the wizard may note that the name of the imported secondary schema file has changed. Simply proceed with synchronization; the old second-level schema will automatically be removed.
When you update source metadata two files are created and placed in a special directory in your application:
An update metadata source operations assigns the same timestamp to both generated files.
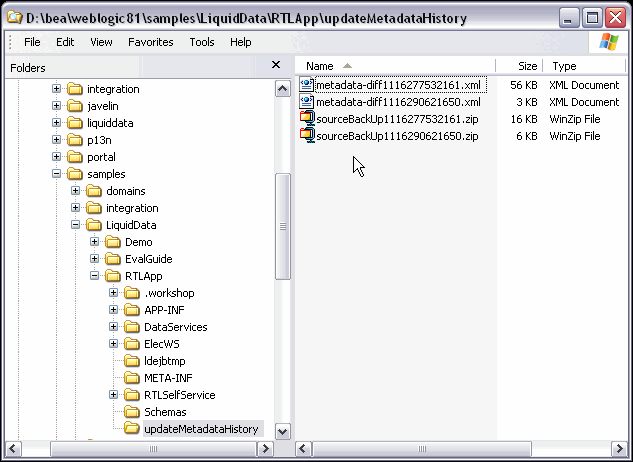
Working with a particular update operations report and source, you can often quickly restore relationships and other changes that were made to your metadata while being assured that your metadata is up-to-date.


|