




|
|
A clustered ALSB domain provides high availability. A highly available deployment has recovery provisions in the event of hardware or network failures, and provides for the transfer of control to a backup component when a failure occurs.
The following sections describe clustering and high availability for a ALSB deployment:
For a cluster to provide high availability, it must be able to recover from service failures. WebLogic Server supports failover for clustered objects and services pinned to servers in a clustered environment. For information about how WebLogic Server handles such failover scenarios, see Communications in a Cluster in Using WebLogic Server Clusters.
The basic components of a highly available ALSB environment include the following:
| Note: | For information about availability and performance considerations associated with the various types of JDBC drivers, see “Configure Database Connectivity” in Configure JDBC in WebLogic Server Administration Console Online Help. |
A full discussion of how to plan the network topology of your clustered system is beyond the scope of this section. For information about how to fully utilize inbound load balancing and failover features for your ALSB configuration by organizing one or more WebLogic Server clusters in relation to load balancers, firewalls, and Web servers, see Cluster Architectures in Using WebLogic Server Clusters. For information on configuring outbound load balancing, see “To Add a Business Service - Transport Configuration” in “Adding a Business Service” in Business Services in Using the AquaLogic Service Bus Console.
For a simplified view of a cluster, showing the HTTP load balancer, highly available database and multi-ported file system, see the following figure.
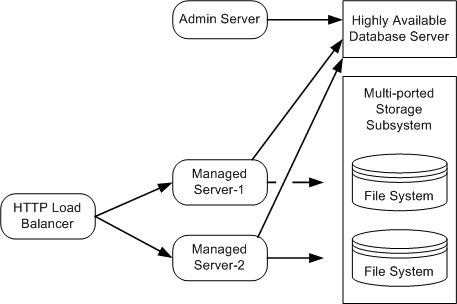
The default ALSB domain configuration uses a file store for JMS persistence to store collected metrics for monitoring purposes and alerts. The configuration shown relies on a highly available multi-ported disk that can be shared between managed servers to optimize performance. This will typically perform better than a JDBC store.
For information about configuring JMS file stores, see Using the WebLogic Persistent Store in Configuring WebLogic Server Environments.
A server can fail due to software or hardware problems. The following sections describe the processes that occur automatically in each case and the manual steps that must be taken in these situations.
If a software fault occurs, the Node Manager (if configured to do so) will restart the WebLogic Server. For more information about Node Manager, see Using Node Manager to Control Servers in Managing Server Startup and Shutdown. For information about how to prepare to recover a secure installation, see “Directory and File Back Ups for Failure Recovery” in Avoiding and Recovering from Server Failure in Managing Server Startup and Shutdown.
If a hardware fault occurs, the physical machine may need to be repaired and could be out of operation for an extended period. In this case, the following events occur:
ALSB leverages WebLogic Server’s whole server migration functionality to enable transparent failover of managed servers from one system to another. For detailed information regarding WebLogic Server whole server migration, see the following topics in the WebLogic Server documentation set:
The Message Reporting Purger for the JMS Message Reporting Provider is deployed in a single managed server in a cluster (see AquaLogic Service Bus Deployment Resources.).
If the managed server that hosts the Message Reporting Purger application fails, you must select a different managed server for the Message Reporting Purger and its associated queue (wli.reporting.purge.queue) to resume normal operation.
Any pending purging requests in the managed server that failed are not automatically migrated. You must perform a manual migration. Otherwise, target the Message Reporting Purger application and its queue to a different managed server and send the purging request again.
In addition to the high availability features of WebLogic Server, ALSB has failure and recovery characteristics that are based on the implementation and configuration of your ALSB solution. The following sections discuss specific ALSB failure and recovery topics:
ALSB provides transparent reconnection to external servers and services when they fail and restart. If ALSB sends a message to a destination while the connection is unavailable, you may see one or more runtime error messages in the server console.
Transparent reconnection is provided for the following types of servers and services:
ALSB Console also provides monitoring features that enable you to view the status of services and to establish a system of SLAs and alerts to respond to service failures. For more information, see Monitoring in Using the AquaLogic Service Bus Console.
Most business services in production environments will be configured to point to a number of EIS instances for load balancing purposes and high availability. If you expect that an EIS instance failure will have an extended duration or a business service points to a single, failed EIS instance, you can reconfigure the business service to point at an alternate, operational EIS instance. This change can be made dynamically.
For information about using the ALSB Console to change an endpoint URI for a business service, see “Viewing and Changing Business Services” in Business Services in Using the AquaLogic Service Bus Console.
File, FTP, and Email are poller based transports. Since these protocols are not transactional, to increase reliability and high availability, an additional JMS-based framework has been created to allow these transports to recover from failure. These transports use the JMS framework to ensure that the processing of a message is done at least once. However, if the processing is done, but the server crashes or the server is restarted before the transaction is complete, the same file may be processed again. The number of retires depends on the redelivery limit that is set for the poller transport for the domain.
New messages from the target (a directory in case of File and FTP transports and server account in case of Email transport) are copied to the download (stage) directory at the time of polling or pipeline processing.
| Note: | For FTP transport, a file is renamed as <name>.stage in the remote directory. It is copied to the stage directory only at the time of pipeline processing, |
For File and FTP transports, a JMS task is created corresponding to each new file in the target directory. For Email transport, an e-mail message is stored in a file in the download directory and a JMS task is created corresponding to each of these files.
These JMS task messages are enqueued to a JMS queue which is pre-configured for these transports when the ALSB domain is created.
The following poller transport specific JMS queues are configured for AquaLogic Service Bus domains:
A domain-wide message-driven bean (MDB) receives the JMS task. Once the MDB receives the message, it invokes the pipeline in an XA transaction. If the message processing fails in the pipeline due to an exception in the pipeline or server crash, the XA transaction also fails and the message is again enqueued to the JMS queue. This message is re-delivered to the MDB based on the redelivery limit parameter set with the queue. By default, the redelivery limit is 1 (the message is sent once and retried once). If the redelivery limit is exhausted without successfully delivering the message, the message is moved to the error directory. You can change this limit from WebLogic Server Console. For more information, see
JMS Topic: Configuration: Delivery Failure in Administration Console Online Help.
| Note: | For a single ALSB domain transport, the redelivery limit value is global across the domain. For example, within a domain, it is not possible to have an FTP proxy with a redelivery limit of 2 and another FTP proxy with a redelivery limit of 5. |
For clusters, the JMS queue associated with each of these poller based transport is a distributed queue (each Managed Server has a local JMS queue, which is a member of the distributed queue). The JMS queue for a transport is domain-wide. The task message is enqueued to the distributed queue, which is passed on to the underlying local queues on the Managed Server. The MDB deployed on the Managed Server picks up the message and then invokes the pipeline in a transaction for actual message processing.
Since the JMS queues are distributed queues in cluster domains, high availability is achieved by utilizing the WebLogic Server distributed queue functionality. Instead of all Managed Servers polling for messages, only one of the Managed Servers in a cluster is assigned the job of polling the messages. At the time of proxy service configuration, one of the Managed Servers is configured to poll for new files or e-mail messages. For more information, see “Adding a Proxy Service” in Proxy Services in Using the AquaLogic Service Bus Console.
The poller server polls for new messages and puts them to the uniform distributed queue associated with the respective poller transport. From this queue, the message is passed on the local queue on the Managed Server. The Managed Servers receive the messages through MDBs deployed on all the servers through these local queues.
| Note: | There is a uniform distributed queue with a local queue on all the Managed Servers for each of these poller based transports. |
If the managed servers crashes after the distributed queue delivers the message to the local queue, you need to do manual migration. For more information, see Server Migration.
When a cluster is created, the uniform distributed queue is created with local queue members - on all the Managed Servers. However, when a new Managed Server is added to an existing cluster, these local queues are not automatically created. You have to manually create the local queues and make them a part of a uniform distributed queue.
| Note: | The JNDI name of the distributed queue is wlsb.internal.transport.task.queue.file (for File transport), wlsb.internal.transport.task.queue.ftp (for FTP transport) and wlsb.internal.transport.task.queue.email (for Email transport). |
Since we use distributed JMS queues, messages are distributed to the Managed Servers based on the load balancing algorithm associated with the distributed queue. By default, the JMS framework uses round-robin load balancing. You can change the algorithm using the JMS module in WebLogic Server Console. For more information, see Load Balancing for JMS in Using WebLogic Server Clusters. If one of the Managed Servers fails, the remaining messages are processed by any of the remaining active Managed Servers.
| Note: | The poller server should always be running. If the poller server fails, the message processing will also stop. |


|