



|
|
These sections briefly review the different Enterprise JavaBean (EJB) types and the functions they can serve in an application, and describe how they work with other application objects and WebLogic Server.
It is assumed the reader is familiar with Java programming and EJB 2.x concepts and features.
These sections describe the purpose and capabilities of each bean type.
Session beans implement business logic. A session bean instance serves one client at a time. There are two types of session beans: stateful and stateless.
A stateless session bean does not store session or client state information between invocations—the only state it might contain is not specific to a client, for instance, a cached database connection or a reference to another EJB. At most, a stateless session bean may store state for the duration of a method invocation. When a method completes, state information is not retained. Any instance of a stateless session bean can serve any client—any instance is equivalent. Stateless session beans can provide better performance than stateful session beans, because each stateless session bean instance can support multiple clients, albeit one at a time.
Example: An Internet application that allows visitors to click a “Contact Us” link and send an email could use a stateless session bean to generate the email, based on the to and from information gathered from the user by a JSP.
Stateful session beans maintain state information that reflects the interaction between the bean and a particular client across methods and transactions. A stateful session bean can manage interactions between a client and other enterprise beans, or manage a workflow.
Example: A company Web site that allows employees to view and update personal profile information could use a stateful session bean to call a variety of other beans to provide the services required by a user, after the user clicks “View my Data” on a page:
An entity bean represents a set of persistent data, usually rows in a database, and provides methods for maintaining or reading that data. An entity bean is uniquely identified by a primary key, and can provide services to multiple clients simultaneously. Entity beans can participate in relationships with other entity beans. The relationships between entity beans are a function of the real-world entities that the entity beans model. An entity bean’s fields and its relationships to other entity beans are defined in an object schema, which is specified in the bean’s ejb-jar.xml deployment descriptor.
An entity bean can have other bean types, such as message-driven or session beans, as clients, or be directly accessed by Web components. The client uses the entity bean to access data in a persistent store. An entity bean encapsulates the mechanics of database access, isolating that complexity from its clients and de-coupling physical database details from business logic.
Example: The stateful session bean in the previous example, which orchestrates services for an employee accessing personal profile information on a company intranet, could use an entity bean for getting and updating the employee’s profile.
A message-driven bean implements loosely coupled or asynchronous business logic in which the response to a request need not be immediate. A message-driven bean receives messages from a JMS Queue or Topic, and performs business logic based on the message contents. It is an asynchronous interface between EJBs and JMS.
Throughout its lifecycle, an MDB instance can process messages from multiple clients, although not simultaneously. It does not retain state for a specific client. All instances of a message-driven bean are equivalent—the EJB container can assign a message to any MDB instance. The container can pool these instances to allow streams of messages to be processed concurrently.
The EJB container interacts directly with a message-driven bean—creating bean instances and passing JMS messages to those instances as necessary. The container creates bean instances at deployment time, adding and removing instances during operation based on message traffic.
Example: In an on-line shopping application, where the process of taking an order from a customer results in a process that issues a purchase order to a supplier, the supplier ordering process could be implemented by a message-driven bean. While taking the customer order always results in placing a supplier order, the steps are loosely coupled because it is not necessary to generate the supplier order before confirming the customer order. It is acceptable or beneficial for customer orders to “stack up” before the associated supplier orders are issued.
These sections briefly describe classes required for each bean type, the EJB run-time environment, and the deployment descriptor files that govern a bean’s run-time behavior.
The composition of a bean varies by bean type. Table 2-1 defines the classes that make up each type of EJB, and defines the purpose of the class type.
An EJB container is a run-time container for beans that are deployed to an application server. The container is automatically created when the application server starts up, and serves as an interface between a bean and run-time services such as:
The structure of a bean and its run-time behavior are defined in one or more XML deployment descriptor files. Programmers create deployment descriptors during the EJB packaging process, and the descriptors become a part of the EJB deployment when the bean is compiled.
WebLogic Server EJBs have three deployment descriptors:
ejb-jar.xml—The standard J2EE deployment descriptor. All beans must be specified in an ejb-jar.xml. An ejb-jar.xml can specify multiple beans that will be deployed together. weblogic-ejb-jar.xml—WebLogic Server-specific deployment descriptor that contains elements related to WebLogic Server features such as clustering, caching, and transactions. This file is required if your beans take advantage of WebLogic Server-specific features. Like ejb-jar.xml, weblogic-ejb-jar.xml can specify multiple beans that will be deployed together. For details, see weblogic-ejb-jar.xml Deployment Descriptor Reference.weblogic-cmp-jar.xml—WebLogic Server-specific deployment descriptor that contains elements related to container-managed persistence for entity beans. Entity beans that use container-managed persistence must be specified in a weblogic-cmp-jar.xml file. For details, see weblogic-cmp-jar.xml Deployment Descriptor Reference.
As described in EJB Deployment Descriptors, a WebLogic Server EJB’s runtime behavior can be controlled by elements in three different descriptor files: ejb-jar.xml, weblogic-ejb-jar.xml, and weblogic-cmp-jar.xml.
Table 2-2 lists the elements whose values should match in each descriptor file. The elements listed in the table are defined in Bean and Resource References and Security Roles.
Each descriptor file contains elements that identify a bean, and the runtime factory resources it uses:
ejb-name—the name used to identify a bean in each deployment descriptor file, independent of the name that application code uses to refer to the bean. ejb-ref-name—the name by which a bean in another JAR is referred to in the referencing bean’s code.res-ref-name—the name by which a resource factory is referred to in the referencing bean’s code.A given bean or resource factory is identified by the same value in each descriptor file that contains it. Table 2-2 lists the bean and resource references elements, and their location in each descriptor file.
For instance, for a container-managed persistence entity bean named LineItem, this line:
Security roles are defined in the role-name element in ejb-jar.xml and weblogic-ejb-jar.xml.
ejb-jar.xml, see
http://java.sun.com/xml/ns/j2ee/ejb-jar_2_1.xsd. weblogic-ejb-jar.xml, see weblogic-ejb-jar.xml Deployment Descriptor Reference. weblogic-cmp-jar.xml, see weblogic-cmp-jar.xml Deployment Descriptor Reference.
Figure 2-1 illustrates how EJBs typically relate to other components of a WebLogic Server application and to clients.
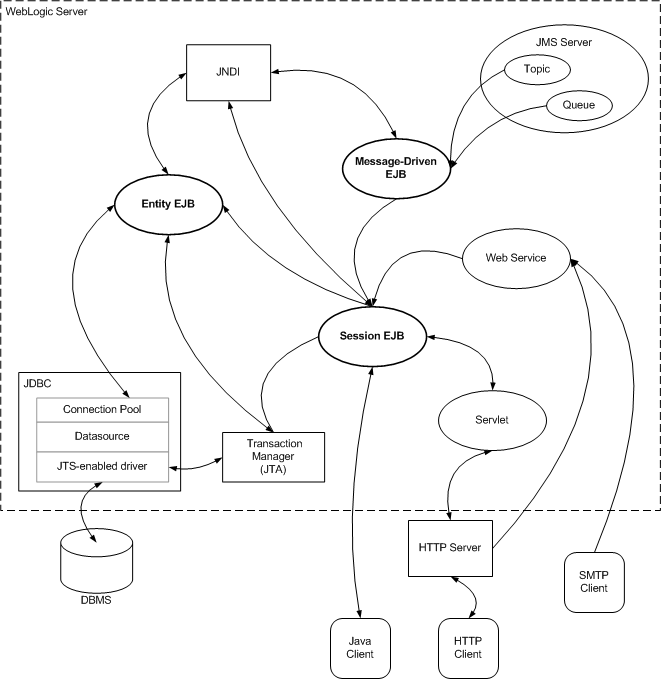
An EJB can be accessed by server-side or client-side objects such as servlets, Java client applications, other EJBs, applets, and non-Java clients.
Any client of an EJB, whether in the same or a different application, accesses it in a similar fashion. WebLogic Server automatically creates implementations of an EJB's home and business interfaces that can function remotely, unless the bean has only a local interface.
All EJBs must specify their environment properties using the Java Naming and Directory Interface (JNDI). You can configure the JNDI namespaces of EJB clients to include the home interfaces for EJBs that reside anywhere on the network—on multiple machines, application servers, or containers.
Most beans do not require a global JNDI name—specified in the jndi-name and local-jndi-name elements of weblogic-ejb-jar.xml. Most beans reference to each other using ejb-links, as described in Using EJB Links.
Because of network overhead, it is more efficient to access beans from a client on the same machine than from a remote client, and even more efficient if the client is in the same application.
See Programming Client Access to EJBs for information on programming client access to an EJB.
An EJB with a remote interface is an RMI object. An EJB’s remote interface extends java.rmi.remote. For more information on WebLogic RMI, see Programming WebLogic RMI
java.net.URL resource connection factory. For more information, see Configuring EJBs to Send Requests to a URL.You can specify the attributes of the network connection an EJB uses by binding the EJB to a WebLogic Server custom network channel. For more information, see Configuring Network Communications for an EJB.
In this release of WebLogic Server, you can use logical message destinations to map a logical message destination, defined in ejb-jar.xml, to an actual message destination, defined in weblogic-ejb-jar.xml, as described in Configuring EJBs to Use Logical Message Destinations.
If a message destination reference cannot be resolved during deployment, a warning is issued but the deployment will succeed. MDBs linked to unavailable message destinations periodically attempt to connect to the message destination. Until the message destination is available, attempts to look up message-destination-references declared in ejb-jar.xml fail with a javax.naming.NamingException. When the message destination becomes available, the MDBs will connect to it and service messages from it.
This section describes key WebLogic Server features that ease the process of EJB development, and enhance the performance, reliability, and availability of EJB applications.
WebLogic Server supports pooling, caching, and other features that improve the response time and performance of EJBs. In a production environment, these features can reduce the time it takes for a client to obtain an EJB instance and access and maintain persistent data.
WebLogic Server maintains a free pool of ready-to-use EJB instances for stateless session beans, message-driven beans, and entity beans. The EJB container creates a configurable number of bean instances at startup, so that a new instance does not have to be created for every request. When a client is done with an EJB instance, the container returns it to the pool for reuse. For more information see:
In this release of WebLogic Server, Administrators can initialize EJB pools on demand via the Administration Console. When an EJB’s pool is initialized, it is reset to the state it was immediately after the EJB was deployed. For more information, see Initialize the idle bean cache and pool of an EJB in Administration Console Online Help.
WebLogic Server supports caching for stateful session beans and entity beans.
An inactive cached bean instance can be passivated—removed from the cache and written to disk—and restored to memory later as necessary. Passivating bean instances optimizes use of system resources.
You can configure the size of the cache, and related behaviors such as rules for removing beans from the cache. Caching is supported for entity EJBs, whether they use container-managed or bean-managed persistence.
Additionally, in this release of WebLogic Server, Administrators can initialize EJB caches on demand via the Administration Console. When an EJB’s cache is initialized, it is reset to the state it was in immediately after the EJB was deployed. For more information, see Initialize the idle bean cache and pool of an EJB in Administration Console Online Help.
Additional caching features are available for EJBs that use container-managed persistence, as described in the following section.
WebLogic Server provides these caching capabilities for entity beans that use container managed persistence:
A group specifies a set of persistent attributes of an entity bean. A field-group represents a subset of the container-managed persistence (CMP) and container-managed relation (CMR) fields of a bean. You can put related fields in a bean into groups that are faulted into memory together as a unit. You can associate a group with a query or relationship, so that when a bean is loaded as the result of executing a query or following a relationship, only the fields mentioned in the group are loaded. For more information, see Specifying Field Groups.
You can configure the behavior of the ejbLoad() and ejbStore() methods to enhance performance, by avoiding unnecessary calls to ejbStore(). As appropriate, you can ensure that WebLogic Server calls ejbStore() after each method call, rather than at the conclusion of the transaction. For more information, see Understanding ejbLoad() and ejbStore() Behavior.
WebLogic Server allows you to batch and order multiple database operations so that they can be completed in a single database “round-trip”. This allows you to avoid the bottlenecks that might otherwise occur when multiple entity instances are affected by a single transaction. For more information, see Ordering and Batching Operations.
In this release of WebLogic Server, for CMP 2.0 entity beans, the setXXX() method does not write the values of unchanged primitive and immutable fields to the database. This optimization improves performance, especially in applications with a high volume of database updates.
For EJB data that is only occasionally updated, you can create a “read-mostly pattern” by implementing a combination of read-only and read-write EJBs. If you use the read-mostly pattern, you can use multicast invalidation to maintain data consistency—an efficient mechanism for invalidating read-only cached data after updates. Use of the invalidate() method after the transaction update has completed invalidates the local cache and results in a multicast message sent to the other servers in the cluster to invalidate their cached copies. For more information, see Using the Read-Mostly Pattern.
WebLogic Server provides a variety of value-added database access features for entity beans that use container-managed persistence:
WebLogic Server supports multiple methods to automatically generate simple primary key for CMP entity EJBs, including use of an Oracle SEQUENCE (which can be automatically generated by WebLogic Server). For more information, see Automatically Generating Primary Keys.
You can configure the EJB container to automatically change the underlying table schema as entity beans change, ensuring that tables always reflect the most recent object-relationship mapping. For more information, see Automatic Table Creation (Development Only).
WebLogic Server allows you to construct and execute EJB-QL queries programmatically in your application code. This allows you to create and execute new queries without having to update and deploy an EJB. It also reduces the size and complexity of the EJB deployment descriptors. For more information, see Choosing a Concurrency Strategy.
WebLogic Server EJBs can be deployed to a cluster, allowing support for load balancing, and failover for remote clients of an EJB. EJBs must be deployed to all clustered servers.
A WebLogic Server cluster consists of multiple WebLogic Server server instances running simultaneously and working together to provide increased scalability and reliability. A cluster appears to clients as a single WebLogic Server instance. The server instances that constitute a cluster can run on the same machine, or be located on different machines.
Failover and load balancing for EJBs are handled by replica-aware stubs, which can locate instances of the object throughout the cluster. Replica-aware stubs are created for EJBs as a result of the object compilation process. EJBs can have two different replica-aware stubs: one for the EJBHome interface and one for the EJBObject interface. This allows some bean types to take advantage of load balancing and failover features at the home level when a client looks up an EJB object using the EJBHome stub and at the method level when a client makes method calls against the EJB using the EJBObject stub.
Table , , on page 2-16 summarizes the load balancing and failover support (method level and home level) for each EJB type.
The bean stub contains the load balancing algorithm (or the call routing class) used to load balance method calls to the object. On each call, the stub can employ its load algorithm to choose which replica to call.
WebLogic Server clusters support multiple algorithms for load balancing clustered EJBs; the default is the round-robin method. For more information, see “Load Balancing in a Cluster” in Using WebLogic Server Clusters.
All bean types support load balancing at the home level. All bean types, except read-write entity beans, support load balancing at the method level.
| Note: | WebLogic Server does not always load-balance an object's method calls. In most cases, it is more efficient to use a replica that is collocated with the stub itself, rather than using a replica that resides on a remote server. |
Failover for EJBs is accomplished using the EJBHome stub or, when supported, the EJBObject stub. When a client makes a call through a stub to a service that fails, the stub detects the failure and retries the call on another replica.
EJB failover requires that bean methods must be idempotent, and configured as such in weblogic-ejb-jar.xml. For more information see
“Replication and Failover for EJBs and RMIs” in Using WebLogic Server Clusters.
Table 2-3 summarizes failover and load balancing features for clustered EJBs.
The
EJBObject stub maintains the location of the EJB’s primary and secondary states. Secondary server instances are selected using the same rules defined in
“Using Replication Groups” in Using WebLogic Clusters.
Stateless session EJB clustering behaviors are configured in
weblogic-ejb-jar.xml. See
“WebLogic-Specific Configurable Behaviors for Stateless Session EJBs”.
|
|||
Stateful session EJB clustering behaviors are configured in
weblogic-ejb-jar.xml. See WebLogic-Specific Configurable Behaviors for Session Beans.
|
|||
|
Failover is not supported during method execution, only after method completion, or if the method fails to connect to a server instance.
|
|||
WebLogic Java Messaging Service (JMS) supports clustering of JMS servers. For more information, see
“JMS and Clustering” in Using WebLogic Server Clusters.
|
|||
For more information, see “Replication and Failover for EJBs and RMIs” and “Load Balancing for EJBs and RMI Objects” in Using WebLogic Server Clusters.
Using WebLogic Server security features, you control both access to your EJBs (authorization) and verification of an EJB's identity when it interacts with other application components and other EJBs (authentication).
WebLogic Server enables application developers to build security into their EJB applications using J2EE and WebLogic Server deployment descriptors, or allows system administrators to control security on EJB applications from the WebLogic Server Administration Console. The latter option frees developers from having to code security, and provides administrators with a centralized tool for defining security policies on: entire enterprise applications (EARs); an EJB JAR containing multiple EJBs; a particular EJB within that JAR; or a single method within that EJB.
For more information about security and EJBs:


|