|
|
This chapter presents the redundancy, load balancing and high availability functionality in Oracle Communications Services Gatekeeper. Oracle Communications Services Gatekeeper uses both software and hardware components to support these important capabilities:
Oracle Communications Services Gatekeeper’s high-availability mechanisms are supported by the clustering mechanisms made available by Oracle WebLogic Server. For general information about Oracle WebLogic Server and clustering, see Oracle WebLogic Server Using Clusters at http://download.oracle.com/docs/cd/E12840_01/wls/docs103/cluster/.
For both high-availability and security reasons, Oracle Communications Services Gatekeeper is split into two tiers: the Access Tier and the Network Tier.
| Note: | Applications using the native SMPP communication service connect directly to the Network Tier. |
Each tier consists of at least one cluster, with at least two server instances per cluster, and all server instances run in active mode, independently of each other. The servers in all clusters are, in the context of Oracle WebLogic Server, Managed Servers. Together the clusters make up a single WebLogic Server administrative domain, controlled through an Administration Server.
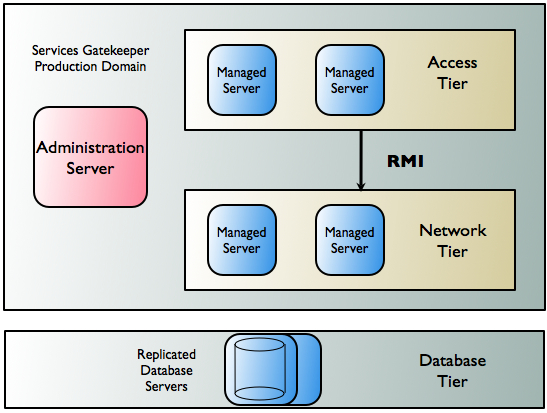
Communication between the Access Tier and the Network Tier takes place using Java RMI. Application requests are load balanced between the Access Tier and the Network Tier and failover mechanisms are present between the two. See Traffic Management Inside Oracle Communications Services Gatekeeper for more information on these mechanisms in application-initiated and network-triggered traffic flows.
There is an additional tier containing the database. Within the cluster, data is made highly available using a cluster-aware storage service which ensures that all state data is made available across all Network Tier instances.
Potential failure is possible at many stages in traffic workflow in Gatekeeper. The following sections detail, tier by tier, how Oracle Communications Services Gatekeeper deals with problems that might arise in both application-initiated and network-triggered traffic.
Application-initiated traffic consists of all requests that travel from applications through Oracle Communications Services Gatekeeper to underlying network nodes.
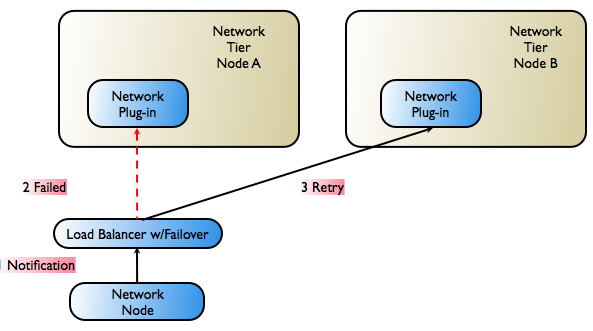
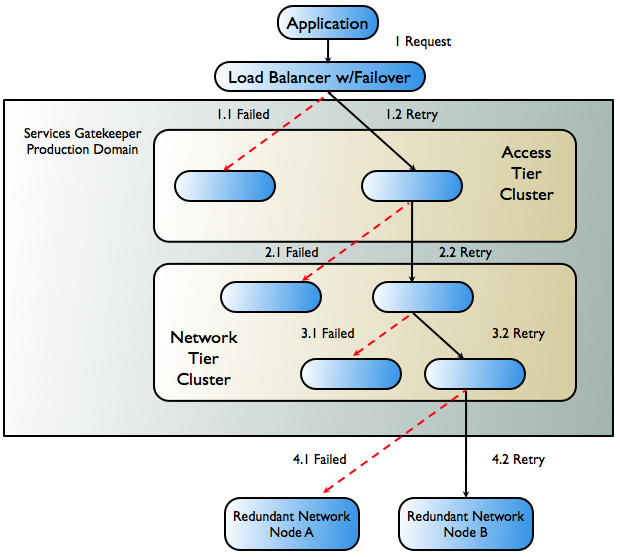
Figure 9-2 below follows the worst-case scenario for application-initiated traffic as it passes through Oracle Communications Services Gatekeeper and the failover mechanisms that attempt to keep the request alive.
| Note: | In addition to the mechanisms described above, Oracle Communications Services Gatekeeper also allows the creation of multiple instances of a single SMPP plug-in type, with multiple binds, which can set up redundant connections to one or more network nodes. Such mechanisms can also increase throughput, and help optimize traffic to SMSCs with small transport windows. |
Network-triggered traffic can consist of the following:
For network-triggered traffic, Oracle Communications Services Gatekeeper relies on internal mechanisms in concert with the capabilities of the telecom network node or other external artifacts such as load-balancers with failover capabilities to do failover.
Some network nodes can handle the registration of multiple callback interfaces. In such cases, Oracle Communications Services Gatekeeper registers one primary and one secondary callback interface. If the node is unable to send a request to the network plug-in registered as the primary callback interface, it is responsible for retrying the request by sending it to the plug-in that is registered as the secondary callback interface. This plug-in resides in another Network Tier instance. The plug-ins themselves are responsible for communicating with each other and making sure that both callback interfaces are registered. See When the Network Node Supports Primary and Secondary Notification for more information.
In the case of communication services using SMPP, all Oracle Communications Services Gatekeeper plug-ins can function equally as receivers for any transmission from the network node.
Finally, for HTTP-based protocols, such as MM7, MLP, and PAP, Oracle Communications Services Gatekeeper relies on an HTTP load balancer with failover functionality between the telecom network node and Oracle Communications Services Gatekeeper. See When the Network Node Supports Only Single Notification for more information.
If a telecom network protocol does not support load balancing and high availability, a single point of failure is unavoidable. In this case, all traffic associated with a specific application is routed through the same Network Tier server and each plug-in has one single connection to one telecom network node.
The worst-case scenario for network-triggered traffic for medium life span notifications using a network node that supports primary and secondary callback interfaces is described in Figure 9-3.
| Note: | If, however, the failure occurs after processing has begun in the Access Tier, failover does not occur and an error is reported to the network node. |
Before applications can receive network-triggered traffic, or notifications, they must register their interest in doing so with Oracle Communications Services Gatekeeper, either by sending a request or having the operator set the notification up using OAM methods. In turn, these notifications must be registered with the underlying network node that will be supplying them. The form of this registration is dependent on the capabilities of that node.
If registration for notifications is supported by the underlying network node protocol, the communication service’s network plug-in is responsible for performing it, whether the registration is the result of an application-initiated registration request or an online provisioning step in Oracle Communications Services Gatekeeper. For example, all OSA/Parlay Gateway interfaces support such registration for notifications.
| Note: | Some network protocols support some, but not all registration types. For example, in MM7 an application can register to receive notifications for delivery reports on messages sent from the application, but not to receive notifications on messages sent to the application from the network. In this case, registration for such notifications can be done as an off-line provisioning step in the MMSC. |
Whether the plug-in sets up the notification in the network or it is done using OAM, Oracle Communications Services Gatekeeper is responsible for correlating all network-triggered traffic with its corresponding application.
Notifications are placed into three categories, based on the expected life span of the notification. These categories determine the failover strategies used:
These notifications have an expected life span of a few seconds. Typically these are delivery acknowledgements for hand-off of the request to the network node, where the response to the request is reported asynchronously. For this category, a single plug-in, the originating one, is deemed sufficient to handle the response from the network node.
These notifications have an expected life span of minutes up to a few days. Typically these are delivery acknowledgements for message delivery to an end-user terminal. For this category, the delivery notification criteria that have been registered are replicated to exactly one additional instance of the network protocol plug-in. The plug-in that receives the notification is responsible for registering a secondary notification with the network node, if possible.
These notifications have an expected life span of more than a a few days. Typically these are registrations for notifications for network-triggered SMS and MMS messages or calls that need to be handled by an application. For this category, the delivery notification criteria are replicated to all instances of the network plug-in. Each plug-in that receives the notification is responsible for registering an interface with the network node.
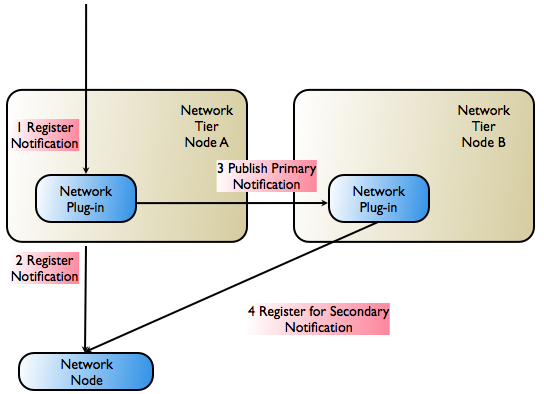
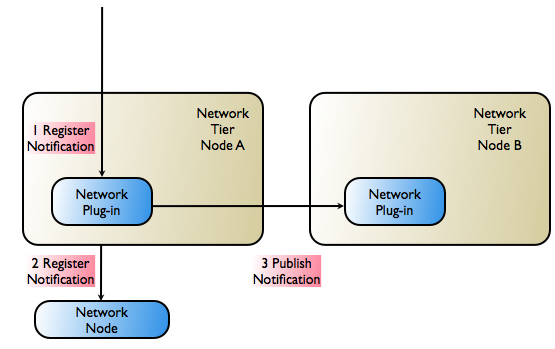
Figure 9-4 illustrates how Oracle Communications Services Gatekeeper registers both primary and secondary notifications with network nodes that support it. This capability must be supported by the network protocol in the abstract and in the implementation of the protocol as it exists in both the network node and the communication service’s network plug-in.
| Note: | The scenario assumes that the network node supports registration for notifications with overlapping criteria (primary/secondary). |
| Note: | The concept of primary/secondary notification is not necessarily ordered. The most recently registered notification may, for example, be designated the primary notification. |
When a network-triggered request that matches the criteria in a previously registered notification reaches the telecom network node, the node first tries the network plug-in that registered the primary notification. If that request fails, the network node has the responsibility of retrying, using the plug-in that registered the secondary notification. The secondary plug-in will have all necessary information to propagate the request through Oracle Communications Services Gatekeeper and on to the correct application.
Figure 9-5 illustrates the registration step in Oracle Communications Services Gatekeeper if the underlying network node does not support primary/secondary notification registration.
| Note: | The scenario assumes that the network node does not support registration for notifications with overlapping criteria. Only one notification for a given criteria is allowed. |
There are two possibilities for high-availability and failover support in this case:
| Note: | Whether or not this is possible depends on the network protocol, because the load-balancer must be protocol aware. |
The general structure of a production Oracle Communications Services Gatekeeper installation is also designed to support redundancy and high availability. A typical installation consists of a number of UNIX/Linux servers connected through duplicated switches. Each server has redundant network cards connected to separate switches. The servers are organized into clusters, with the number of servers in the cluster determined by the needed capacity.
As described previously, Oracle Communications Services Gatekeeper is deployed on an Access Tier, which manages connections to applications, and a Network Tier, which manages connections to the underlying telecom network. For security, the Network Tier is usually connected only to Access Tier servers, the appropriate underlying network nodes, and the Oracle WebLogic Server Administration Server, which manages the domain. A third tier hosts the database. This tier should be hosted on dedicated, redundant servers. For physical storage, a Network Attached Storage using fibre channel controller cards is an option.
Because the different tiers perform different tasks, their servers should be optimized with different physical profiles, including amount of RAM, disk-types, and CPUs. Each tier scales individually, so the number of servers in a specific tier can be increased without affecting the other tiers.
A sample configuration is shown in Figure 9-7. Smaller systems in which the Access Tier and the Network Tier are co-located in the same physical servers are possible but only for non-production systems. Particular hardware configurations depend on the specific deployment requirements and are worked out in the dimensioning and capacity planning stage.
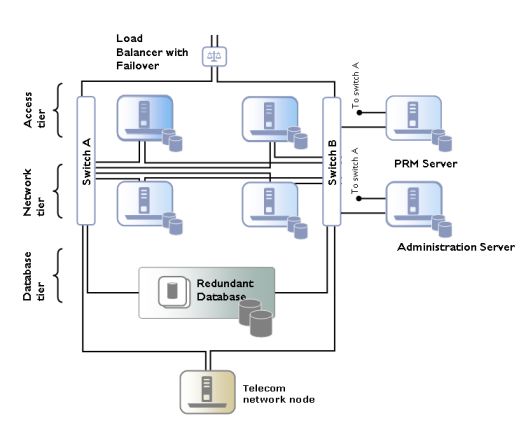
In high-availability mode, all hardware components are duplicated, eliminating single point of failure. This means that there are at least two servers executing the same software modules, that each server has two network cards, and that each server has a fault-tolerant disk system, as, for example, RAID.
The administration server may have duplicate network cards, connected to each switch.
For security reasons, the servers used for the Access Tier can be separated from the Network Tier servers using firewalls. The Access Tier servers reside in a Demilitarized Zone (DMZ) while the Network Tier servers are in a trusted environment.
All Oracle Communications Services Gatekeeper modules in production systems are deployed in clusters to ensure high availability. This prevents single points of failure in general usage. Within a cluster, a Budget Service cluster-local master regulates the enforcement of SLAs. The enforcement service is highly available and is migrated to another server should the cluster-local master node fail. See “Managing and Configuring Budgets” in System Administrator’s Guide for more information on this mechanism.
However, to prevent service failure in the face of catastrophic events - natural disasters or massive system outages like power failures - Oracle Communications Services Gatekeeper can also be deployed at two geographically distant sites that are designated as site pairs. Each site, which is a Oracle Communications Services Gatekeeper domain, has another site as its peer. See Figure 9-8 an overview. Application and service provider configuration information, including related SLAs and budget information, is replicated and enforced across sites.
| Note: | Custom, Subscriber, Service Provider Node, and Global Node SLAs cannot be replicated across sites. |
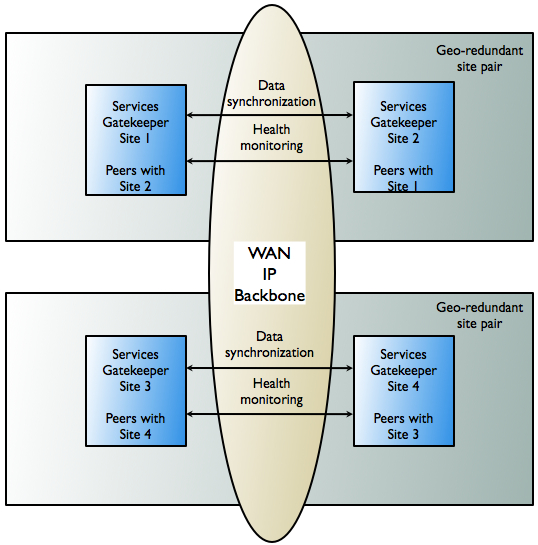
In a geo-redundant setup, all sites have a geographic site name and each site is configured to have a reference to its peer site using that name. The designated set of information is synchronized between these site peers.
One site is defined as the geomaster, the other as the slave. Checks are run periodically between the site pairs to verify data consistency and an alarm is triggered if mismatches are found, at which point the administrator can force the slave to re-sync to the geomaster, using the syncFromGeoMaster operation. Any relevant configuration changes made to either site are written synchronously across the site pairs, so that a failure to write to either the geomaster or the slave causes the write to fail and an alarm to fire.
During the period in which the slave is syncing up with the geomaster, both the geomaster and the slave sites are in read-only mode. No configuration changes can be made. If a slave site becomes unavailable for any reason, the geomaster site becomes read-only either until the slave site is available and has completed all data replication, or until the slave site has been removed from the geomaster site’s configuration, terminating geo-redundancy.
| Note: | If a new site is then added to replace the terminated site, it must be added as a slave site. The site that is designated the geomaster site must remain the geomaster site for the lifetime of the site configuration. |
| Note: | If a geomaster site fails permanently, the failed site should be removed from the configuration using the GeoRedundantService. If a replacement site is added to the configuration, the remaining operating site must be reconfigured to be the geomaster and the replacement site must be added as the slave. |
For applications, geo-redundancy means that their traffic can continue to flow in the face of a catastrophic failure at an operator site. Even applications that normally use only a single site for their traffic can fail over to a peer site while maintaining ongoing SLA enforcement for their accounts. This scenario is particularly relevant for SLA aspects that have longer term impact, such as quotas.
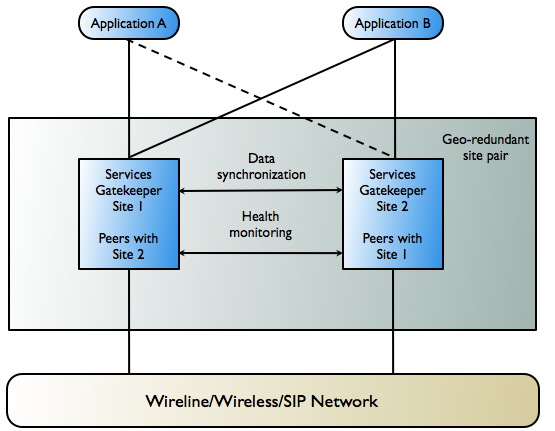
In many respects, the geo-redundancy mechanism is not transparent to applications. There is no single sign-on mechanism across sites, and an application must establish a session with each site it intends to use. In case of site failure, an application must manually fail over to a different site.
While application and service provider budget and configuration information are maintained across sites, state for ongoing conversations is not maintained. Conversations in this sense are defined in terms of the correlation identifiers that are returned to the applications by Oracle Communications Services Gatekeeper or passed into Oracle Communications Services Gatekeeper from the applications. Any state associated with a correlation identifier exists on only a single geographic site and is lost in the event of a site-wide disaster. Conversational state includes, but is not limited to, call state and registration for network-triggered notifications. This type of state is considered volatile, or transient, and is not replicated at the site level.
This means that conversations must be conducted and complete on their site of origin. If an application wishes to maintain conversational state cross-site - for example, to maintain a registration for network-triggered traffic - it must register with each site individually.
| Note: | On the other hand, this type of affinity does allow load balancing between sites for different or new conversations. For example, because each request to send an SMS message constitutes a new conversation, sending SMS messages can be balanced between the sites. |
Below is a high-level outline of the redundancy functionality:


|