| Oracle® Database 2日でReal Application Clustersガイド 11gリリース2(11.2) B56291-07 |
|


 前 |
 次 |
Oracle Real Application Clusters(Oracle RAC)データベースにおけるパフォーマンス・チューニングは、単一インスタンスのデータベースでのパフォーマンス・チューニングと非常に類似しています。また、単一インスタンスのOracle Databaseで実行する多くのチューニング・タスクによって、Oracle RACデータベースのパフォーマンスを向上させることもできます。この章では、Oracle RACに固有のパフォーマンス・チューニングと監視タスクについて説明します。
この章の内容は次のとおりです。
|
参照:
|
Oracle Enterprise Manager Database ControlとOracle Enterprise Manager Grid Controlはいずれも、クラスタを認識し、クラスタ・データベースを集中管理するためのコンソールを提供します。
「クラスタ・データベース: ホーム」ページから、次のすべての操作を実行できます。
クラスタ内にあるノードの数や現在のステータスなど、全体的なシステム・ステータスの表示。この高レベルの表示機能を利用することで、包括的で集計的な情報のみを確認する場合に、個々のデータベース・インスタンスにアクセスして詳細を確認する必要がなくなります。
すべてのインスタンスから集計されたアラート・メッセージと各アラート・メッセージのソースのリストの表示。アラート・メッセージとは、特定のメトリックの条件に一致したことを表すインジケータです。メトリックとは、システムの状態の報告に使用される測定の単位です。
クラスタ全体に影響している問題および個々のインスタンスに影響している問題を確認します。
クラスタ・キャッシュ一貫性の統計を監視して、処理の傾向の識別やOracle RAC環境のパフォーマンスの最適化に役立てます。キャッシュ一貫性の統計によって、複数のインスタンスのキャッシュ内にあるデータがどの程度適切に同期化されているかが測定されます。データ・キャッシュが相互に完全に同期化されていると、いずれのインスタンスのキャッシュでメモリーの場所を読み取った場合にも、その場所に対して任意のインスタンスのキャッシュから書き込まれた最新のデータが戻されます。
クラスタ・データベースのサービスに、可用性の問題があるかどうかを確認します。あるサービスがすべての優先インスタンス上で実行しない場合、レスポンス時間のしきい値が条件を満たしていない場合などに、そのサービスが問題であると判断されます。「クラスタ・データベース: ホーム」ページでリンクをクリックすると、「クラスタ管理データベース・サービス」ページが表示され、サービスを管理できます。
未処理のクラスタウェア・インターコネクトのアラートを確認します。
また、Oracle RAC環境の監視についての次の点にも注意してください。
自動ワークロード・リポジトリ(AWR)やStatspackなどのパフォーマンス監視機能は、Oracle RAC対応です。
|
注意: オラクル社では、Statspackではなく、より高度なOracle Database 11gのDiagnostics PackおよびTuning Packの管理および監視機能を使用することをお薦めします。これらのパックには、AWRが含まれています。 |
複数のインスタンスにわたる統計の表示には、グローバル動的パフォーマンス・ビュー(GV$ビュー)を使用できます。これらのビューは、単一インスタンスのV$ビューに基づいています。
この項の内容は次のとおりです。
自動データベース診断モニター(ADDM)はOracle Databaseに組み込まれている自己診断エンジンです。ADDMで自動ワークロード・リポジトリ(AWR)に取得されたデータが調査および分析され、Oracle Databaseに発生する可能性のあるパフォーマンスの問題を判別します。その後、ADDMはパフォーマンスの問題の根本的な原因を含む場所を特定し、問題修正のための推奨事項を提示し、予測されるメリットを定量化します。ADDMでは、データベースおよびインスタンス・レベルの両方でパフォーマンスの問題についてのAWRデータを分析します。
ADDM分析は、各AWRスナップショットが生成されるとき(デフォルトでは1時間ごと)に実行されます。結果はデータベースに保存され、Oracle Enterprise Managerを使用して表示できます。パフォーマンスに問題がある場合は常に、ADDM分析の結果を最初に確認する必要があります。ADDM分析は、トップダウンで実行され、最初に症状を識別し、根本的な原因が判明するまで分析を精製し、最後に問題の改善策を提供します。
クラスタ全体の分析の場合、Oracle Enterprise Managerによって次の2種類の結果がレポートされます。
データベース結果: クラスタ・データベース内のすべてのインスタンスで共有されるリソースに関する問題、または複数のインスタンスに影響を与える問題。データベース結果の例には、共有記憶域として使用されるディスク・システム上でのI/Oの競合があります。
インスタンス結果: 1つのインスタンスのみで使用可能なハードウェアまたはソフトウェアに関する問題、または単一のインスタンスにのみ影響を与える一般的な問題。インスタンス結果の例には、CPUの高負荷やメモリー割当ての不足があります。

ADDMでは、重要な結果、またはインスタンスまたはデータベースの処理時間の大部分を占める結果のみが報告されます。インスタンス処理時間は、単一のインスタンスのパフォーマンスの問題のためのリソース使用時間で、データベース処理時間は、Oracle Automatic Storage Management (Oracle ASM)インスタンスを除くデータベースのすべてのインスタンスのパフォーマンスの問題のためのリソース使用時間の合計です。
インスタンス結果が大量のデータベース時間に関連する場合、データベース結果として報告されることがあります。たとえば、1つのインスタンスでCPUが900分間使用され、そのクラスタ・データベースのCPU使用時間の合計が1040分間である場合、1つのインスタンスでの使用時間がデータベース時間の大部分を占めているため、データベース結果として報告されます。
問題の検出結果を推奨事項のリストに関連付けて、パフォーマンスの問題による影響を軽減できます。各推奨事項には、推奨事項を実現した場合に節約できるデータベース時間の一部を見積りできるという利点があります。同じ問題を解決するにあたって、推奨事項のリストに様々な代替方法が示されることもあります(必ずしも推奨事項を適用する必要はありません)。
推奨は、アクションおよび論理で構成されます。ある推奨で推定されるベネフィットを得るには、その推奨のすべてのアクションを適用する必要があります。論理では、アクションが推奨される理由が説明され、提案される推奨を実装するための追加情報が提供されます。
|
参照:
|
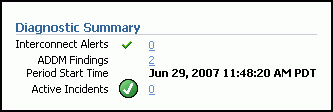
デフォルトでは、ADDMは毎時間実行され期間中にAWRによって作成されるスナップショットを分析します。データベースがパフォーマンスの問題を検出した場合、分析の結果が「クラスタ・データベース: ホーム」ページの「診断サマリー」に表示されます。「ADDM結果」リンクは、直近のADDM分析で検出されたADDM結果がいくつあるかを示しています。
Oracle Enterprise Managerでは、次の方法でOracle RACのADDMにアクセスできます。
「クラスタ・データベース: ホーム」ページの「診断サマリー」で、「ADDM結果」リンクをクリックします。
「クラスタ・データベース: パフォーマンス」ページで、「アクティブ・セッション」グラフの下にあるカメラ・アイコンをクリックします。
「クラスタ・データベース: ホーム」ページまたは「パフォーマンス」ページの「関連リンク」セクションで、「アドバイザ・セントラル」をクリックします。「アドバイザ・セントラル」ページで、「ADDM」を選択します。「過去のパフォーマンスを分析するには、ADDMを実行してください」オプションを選択し、適切な間隔を指定して「OK」をクリックします。
「クラスタ・データベース: ホーム」ページからADDM結果を表示するには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページの「診断サマリー」の下にある「ADDM結果」の横に0(ゼロ)以外の数値が表示されている場合は、このリンクをクリックします。
また、「クラスタ・データベース: ホーム」ページで「インスタンス」表を表示することによって、インスタンスごとにADDM結果を表示することもできます。
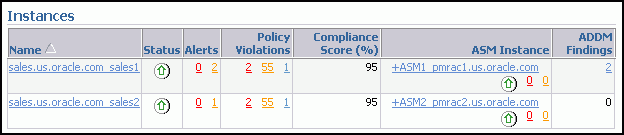
「ADDM結果」の番号を選択すると、そのクラスタ・データベースの「自動データベース診断モニター(ADDM)」ページが表示されます。
ADDM実行結果を確認します。
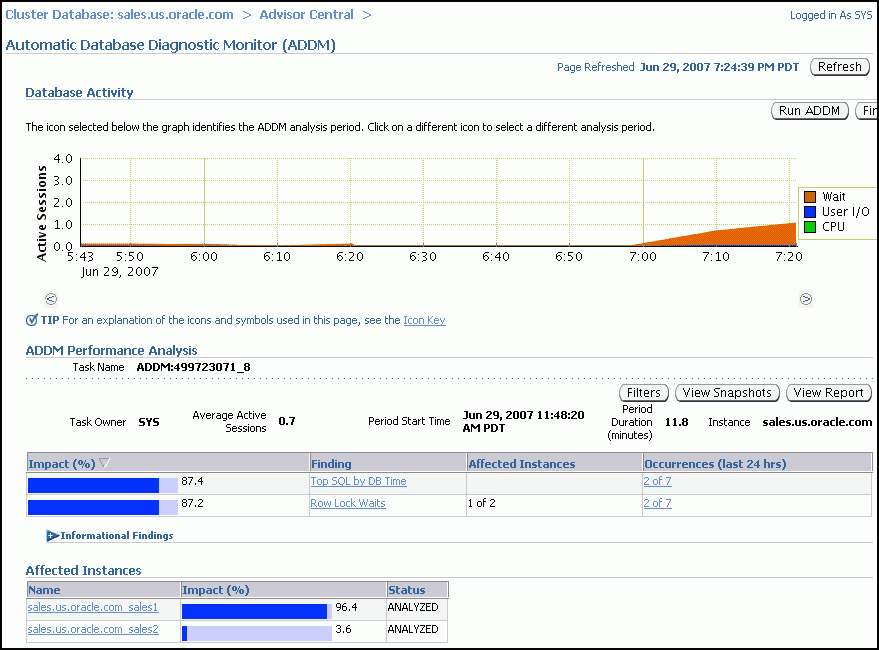
「自動データベース診断モニター(ADDM)」ページの「データベース・アクティビティ」グラフでは、ADDM分析期間中のデータベース・アクティビティが表示されます。データベース・アクティビティのタイプは、グラフで対応する色に基づいて凡例で定義されています。グラフの下にある各アイコンは異なったADDMタスクを表し、各ADDMタスクはワークロード・リポジトリに保存されている個々のOracle Databaseスナップショットのペアに対応します。
「ADDMパフォーマンス分析」セクションで、ADDM結果は影響の高いものから降順でリストされます。「情報の結果」セクションでは、パフォーマンスに影響がなく、情報目的のみの領域をリストします。
「影響を受けるインスタンス」グラフは、各インスタンスがこれらの結果によって受ける影響の程度を示しています。
(オプション)「ズーム」アイコンをクリックすると、グラフに表示されている分析期間を短縮、または拡大できます。
(オプション)レポートにADDMの検出結果を表示するには、「レポートの表示」をクリックします。
「レポートの表示」ページが表示されます。
「ファイルに保存」をクリックして、後のアクセスのレポートを保存できます。
「ADDM」ページの「影響を受けるインスタンス」表で、「影響」に最大値が示されているADDM結果に関連するインスタンスのリンクをクリックします。
そのインスタンスの「自動データベース診断モニター(ADDM)」ページが表示されます。
「ADDMパフォーマンス分析」セクションで、結果の名前を選択します。
「パフォーマンス結果の詳細」ページが表示されます。
パフォーマンスの問題を解決するために使用可能な「推奨」を表示します。SQLチューニング・アドバイザを実行し、そのパフォーマンス結果の原因となっているSQL文をチューニングします。
|
参照:
|
クラスタ・データベース・パフォーマンス・ページには、データベースのパフォーマンス統計が表示されます。Enterprise Managerでは、指定した期間中の各インスタンスからデータが累積され、収集ベース・データと呼ばれます。また、リアルタイム・データと呼ばれる各インスタンスからの現行データも提供しています。
統計は、クラスタ・データベース内のすべてのインスタンスにわたってロールアップされます。グラフの横にあるリンクを使用すると、詳細を表示したり、次のタスクを実行することができます。
パフォーマンスの問題の原因の特定
リソースを追加または再分散する必要があるかどうかの判別
SQLプランおよびスキーマのチューニングによる最適化
パフォーマンスの問題の解決
次のスクリーンショットは、「クラスタ・データベース: パフォーマンス」ページの一部を示しています。このページにアクセスするには、「クラスタ・データベース: ホーム」ページの「パフォーマンス」タブをクリックします。
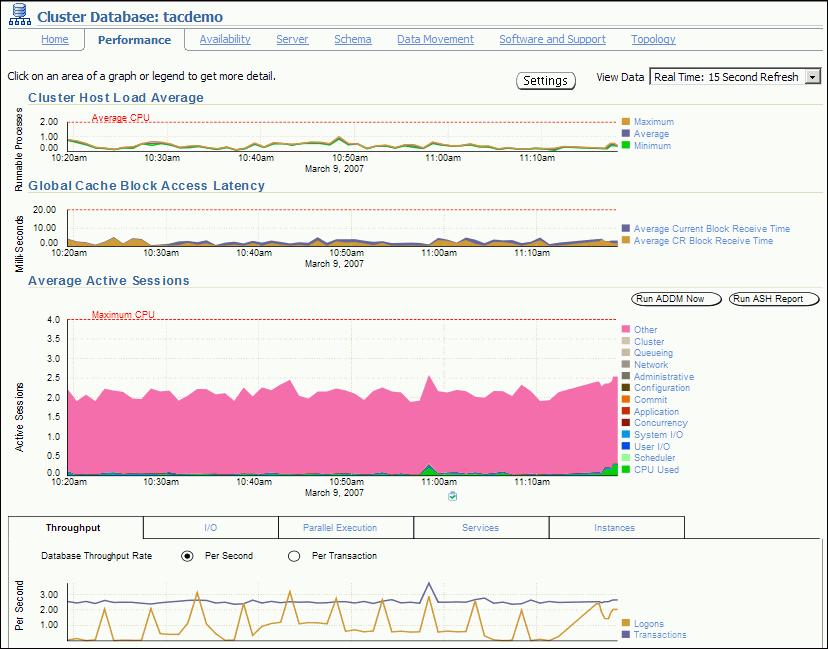
「パフォーマンス」ページのグラフは次の項で説明します。
各クラスタ・データベース・インスタンスには、そのシステム・グローバル領域(SGA)に独自のバッファ・キャッシュがあります。Oracle RAC環境では、キャッシュ・フュージョンを使用して、各インスタンスのバッファ・キャッシュを論理的に結合し、論理的に結合された単一キャッシュ上にあるかのようにデータベース・インスタンスでデータを処理できるようにします。
プロセスがデータ・ブロックへのアクセスを試行する場合、最初に、ローカル・バッファ・キャッシュにあるデータ・ブロックのコピーの検出を試行します。データ・ブロックのコピーがローカル・バッファ・キャッシュ内に見つからない場合、グローバル・キャッシュ操作が開始されます。ディスクからデータ・ブロックを読み取る前に、プロセスは別のインスタンスのバッファ・キャッシュでデータ・ブロックの検索を試行します。データ・ブロックが別のインスタンスのバッファ・キャッシュ内にある場合、キャッシュ・フュージョンでは、一方のデータベース・インスタンスにディスクへのデータ・ブロックの書込みを行わせてもう一方のインスタンスにディスクからのデータ・ブロックの再読取りを要求するのではなく、あるバージョンのデータ・ブロックをローカル・バッファ・キャッシュに転送します。たとえば、orcl1インスタンスがそのバッファ・キャッシュにデータ・ブロックをロードした後、orcl2インスタンスは、ディスクからデータ・ブロックを読み取るのではなく、キャッシュ・フュージョンを使用することで、orcl1インスタンスからより短時間でデータ・ブロックを取得できます。
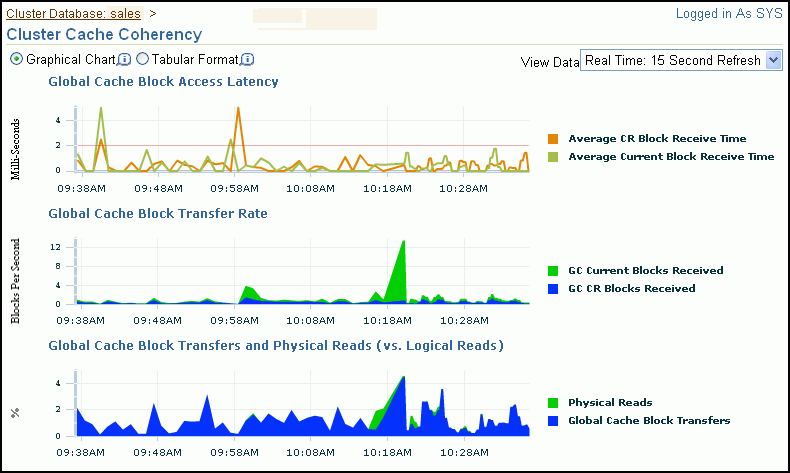
「グローバル・キャッシュ・ブロックのアクセス待機時間」グラフでは、現行ブロックと読取り一貫性(CR)ブロックの2種類のデータ・ブロック・リクエストのデータが示されます。データベースのデータを更新する場合、Oracle Databaseではそのデータを含む最新バージョンのデータ・ブロック(現行ブロック)を検索する必要があります。問合せを実行する場合、その問合せの開始前にコミットされたデータのみが問合せで参照されます。問合せの開始後に変更されたデータ・ブロックはUNDOセグメントのデータから再構築されます。再構築されたデータは読取り一貫性ブロックとして問合せで使用可能になります。
「クラスタ・データベース: パフォーマンス」ページの「グローバル・キャッシュ・ブロックのアクセス待機時間」グラフでは、各タイプのデータ・ブロック・リクエストの待機時間、つまり、読取り一貫性ブロックと現行ブロックを検索してバッファ・キャッシュ間で転送するために費やされた時間が示されます。
「グローバル・キャッシュ・ブロックのアクセス待機時間」グラフに長い待機時間(長い経過時間)が示された場合、次の原因が考えられます。
チューニングされていないSQL文により発生する多数のリクエスト。
キュー内でCPUを待機または遅延をスケジュールしている多数のプロセス。
低速、ビジーまたは問題のあるインターコネクト。これらの場合、ネットワーク接続でパケットのドロップ、再転送または巡回冗長検査(CRC)エラーが発生していないかどうかを確認します。
クラスタ内の共有データに対する同時読取り/書込みアクティビティは、頻繁に発生するアクティビティです。サービス要件にもよりますが、通常、このアクティビティがパフォーマンスの問題を引き起こすことはありません。ただし、グローバル・キャッシュ・リクエストがパフォーマンスの問題を発生させる場合は、SQLプランおよびスキーマを最適化してローカル・バッファ・キャッシュ内でデータ・ブロックが検索される割合を上げてI/Oを最小限に抑えることが、パフォーマンス・チューニングを行う際の確実な方法となります。読取り一貫性ブロックおよび現行ブロックのリクエストの待機時間が10ミリ秒に達している場合は、問題解決の第1ステップとして、「クラスタ・キャッシュ一貫性」ページに移動して詳細情報を確認する必要があります。
「グローバル・キャッシュ・ブロックのアクセス待機時間」グラフのいずれかのメトリックをクリックすると、そのタイプのキャッシュ・ブロックの詳細を表示できます。たとえば、メトリックの「平均現行ブロック受信時間」をクリックすると、インスタンスごとの平均現行ブロック受信時間ページが表示され、クラスタにあるノードに対する平均現行ブロック受信時間を最大で4つまで示すサマリー・チャートを表示します。データをサマリー・グラフに表示するか、タイル・グラフを使用するかを選択できます。サマリー・チャートを選択した場合、デフォルトでは上位4つの受信時間を持つインスタンスが表示されます。タイル・グラフを選択すると、各ノードのデータがそれぞれのグラフに表示されます。どのノードをサマリーに表示するか、タイル・グラフにするかをカスタマイズできます。
インスタンスごとの平均現行ブロック受信時間ページまたは、「クラスタ・キャッシュ一貫性」ページで、アクティブ・セッション履歴の概要グラフにあるスライダ・バーを使用して過去1時間以内の5分の時間枠(期間)に焦点を当てることもできます。このスライダ・バーを使用すると、キャッシュ一貫性の高いアクティビティ期間に実行されていた上位のセッション、サービス、モジュール、アクション、またはSQL文を識別できます。
ページ上部にある「メトリック」リストを使用して、表示されるメトリックを変更できます。選択できるメトリックを次に示します。
平均CRブロック受信時間
平均現行ブロック受信時間
受信されたGC現行ブロック
受信されたGC CRブロック
物理読取り
グローバル・キャッシュ・ブロック転送
各メトリックによって、そのメトリックの監視ページが表示されます。各メトリックの監視ページでは、サマリー・グラフまたはタイル・グラフでそのメトリックのデータを表示できます。また、メトリックの監視ページの「最大」、「平均」、「最小」グラフに、すべてのアクティブなクラスタ・データベース・インスタンスのメトリックの最大値、平均値および最小値を表示できます。
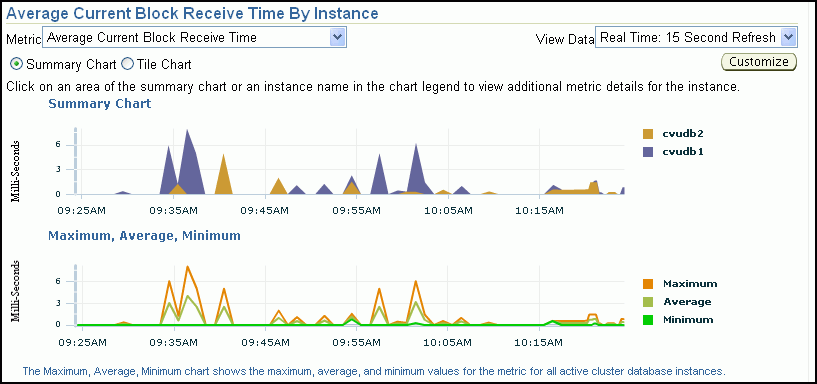
「クラスタ・データベース: パフォーマンス」ページにある「クラスタ・ホストのロード平均」グラフには、データベース外部で発生する可能性がある問題が表示されます。このグラフには、クラスタ内で使用可能なノードについて、過去1時間のロードの最大値、平均値および最小値が表示されます。
ロード平均がクラスタ内のすべてのホストのCPU合計数の平均より高い場合、多数のプロセスがCPUのリソースを待機しています。多くの場合、チューニングされていないSQL文によって、CPU使用率が高くなります。ロード平均値を、「平均アクティブ・セッション」グラフの「使用中のCPU」に表示されている値と比較します。セッションの値が低くてロード平均の値が高い場合、ホストでは監視対象データベース以外のものによってCPUが使用されています。
「クラスタ・ホストのロード平均」グラフに表示されるロード値ラベルのいずれかをクリックすると、そのロード値の詳細を表示できます。たとえば、「平均」ラベルをクリックすると、「ホスト: ロード平均」ページが表示され、クラスタにある4つまでのノードのホスト・ノード平均が表示されます。
データを、サマリー・グラフに表示するか、各ノードのデータをまとめて1画面に表示するか、各ノードのデータがそれぞれのグラフに表示されるタイル・グラフを使用するかを選択できます。「カスタマイズ」をクリックし、各行に表示されるタイル・グラフの数またはタイル・グラフを順序付けする方法を変更できます。
「ホスト: 平均ロード」ページに表示されるデータの変更の詳細は、Oracle Enterprise Managerのオンライン・ヘルプを参照してください。
「クラスタ・データベース: パフォーマンス」ページの「平均アクティブ・セッション」グラフでは、データベース内で考えられる問題が表示されます。「カテゴリ」は待機クラスとも呼ばれ、データベース内でCPUやディスクI/Oなどのリソースを使用している部分が表示されます。CPU時間を待機時間と比較すると、レスポンス時間のうちどれくらいの時間が、他のプロセスに保持されている可能性のあるリソースの待機ではなく有効な作業に消費されているかを確認できます。
このグラフには、データベースまたはインスタンスのワークロードが表示され、パフォーマンスの問題が示されます。クラスタ・データベース・レベルでは、このグラフに、すべてのインスタンスにわたる集約待機クラス統計が示されます。より詳細に分析するために、グラフの下部にあるクリップボード・アイコンをクリックして、その期間のデータベースのADDM分析を表示することができます。
「平均アクティブ・セッション」グラフのピークを「データベース・スループット」グラフのピークと比較します。「平均アクティブ・セッション」グラフに待機中のセッションが多数表示され、内部的な競合が示されている場合でも、スループットが高ければ、状況は許容できる可能性があります。内部的な競合が低く、スループットが高い場合も、データベースはおそらく効率よく実行されています。一方、内部的な競合が高くスループットが低い場合は、データベースのチューニングを検討してください。
「平均アクティブ・セッション」グラフの横にある待機クラスの凡例をクリックすると、それぞれの「インスタンスごとのアクティブ・セッション」ページに格納されているインスタンス・レベルの情報を表示できます。「インスタンスごとのアクティブ・セッション」ページの「待機クラス」アクション・リストを使用して、異なる待機クラスを表示できます。「インスタンスごとのアクティブ・セッション」ページには、最大4つのインスタンスのサービス時間が表示されます。「カスタマイズ」ボタンを使用すると、表示されるインスタンスを選択できます。インスタンスのデータは、タイル・グラフを使用して別々に表示するか、または1つのサマリー・グラフにまとめることができます。
特定のカテゴリの待機イベントが増加する原因となっている問題を診断して修正する必要がある場合に、問題のあるインスタンスを選択して、待機イベントの他、データベース・リソースの多くを消費しているSQL、セッション、サービス、モジュールおよびアクションを表示できます。
|
参照:
|
「パフォーマンス」ページの最後のグラフでは、様々なデータベース・リソースの使用率が監視されます。このグラフの上部の「スループット」タブをクリックすると、「データベース・スループット」グラフを表示できます。
「データベース・スループット」グラフは、「平均アクティブ・セッション」グラフに表示される任意のリソース競合を要約する他、ユーザーやアプリケーションのためにデータベースが実行中の作業の量を示します。「1秒当たり」ビューは、1秒当たりのログオン数に対するトランザクションの数、REDOサイズに対する物理読取りの量を示します。「1トランザクション当たり」ビューは、トランザクション当たりのREDOサイズに対する物理読取りの量を示します。「ログオン」は、データベースにログオンしているユーザー数を示します。
また、グラフの右にある凡例をクリックして「インスタンスごとのデータベース・スループット」ページを表示し、インスタンス・レベルの情報を取得できます。このページには、「データベース・スループット」グラフに表示されたインスタンス(最大4つまで)の詳細が表示されます。「カスタマイズ」ボタンを使用すると、表示されるインスタンスを選択できます。インスタンスのデータは、タイル・グラフを使用して別々に表示するか、または1つのサマリー・グラフにまとめることができます。このページを使用すると、特定のインスタンスに対するスループットを表示できるため、スループットの問題の診断に役立ちます。
「インスタンスごとのデータベース・スループット」ページでさらにドリルダウンして、最もリソースを消費しているインスタンスのセッションを参照できます。グラフの直下の凡例のインスタンス名をクリックして、そのインスタンスの「上位コンシューマ」ページの「上位セッション」サブページに移動します。
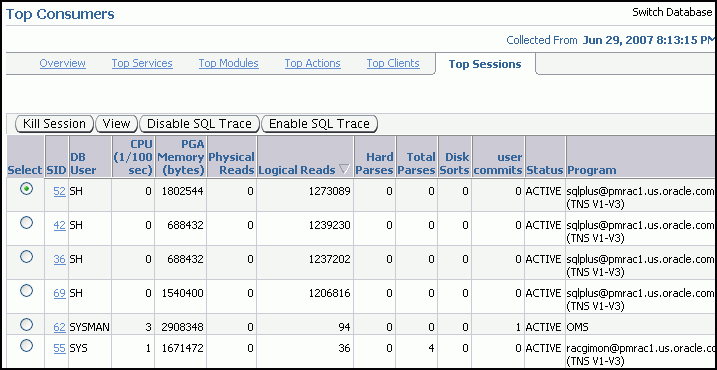
このページの詳細は、Oracle Enterprise Managerのヘルプ・システムを参照してください。
|
参照:
|
「パフォーマンス」ページの最後のグラフでは、様々なデータベース・リソースの使用率が監視されます。このグラフの上部の「サービス」タブをクリックすると、「サービス」グラフを表示できます。
「サービス」グラフには、アクティブ・セッションで使用されている上位サービスが表示されます。アクティブ・セッションのみが表示されます。グラフ右側にあるサービス凡例をクリックすると、「上位コンシューマ」ページの「サービス」サブページに移動できます。デフォルトでは、「アクティビティ」サブタブが選択されています。このページでは、サービスの待機クラスごとにセッション・ロードを示すリアルタイム・データを表示できます。
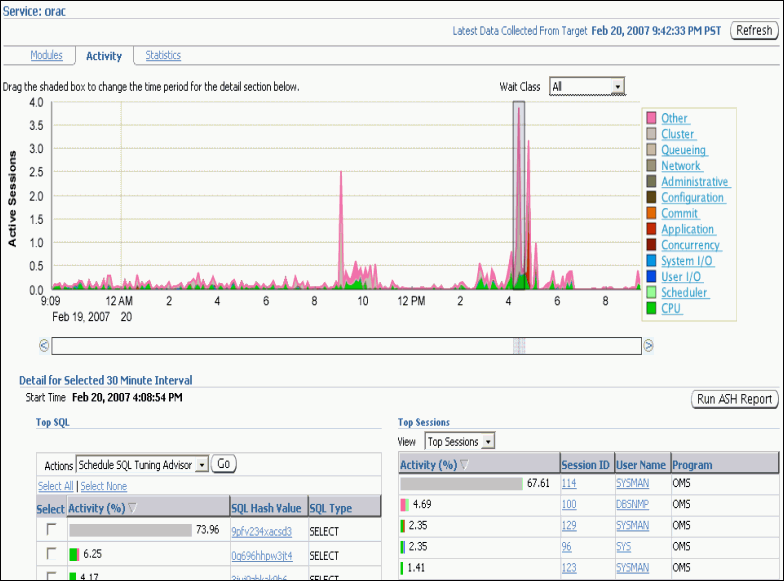
このページの詳細は、Oracle Enterprise Managerのヘルプ・システムを参照してください。
「パフォーマンス」ページの最後のグラフでは、様々なデータベース・リソースの使用率が監視されます。このグラフの上部の「インスタンス」タブをクリックすると、「インスタンスごとのアクティブ・セッション」グラフを表示できます。
「インスタンスごとのアクティブ・セッション」グラフには、「平均アクティブ・セッション」グラフに示されるすべてのリソース競合のサマリーが表示されます。このグラフを使用すると、各インスタンスでのデータベースのワークロードを簡単に確認できます。
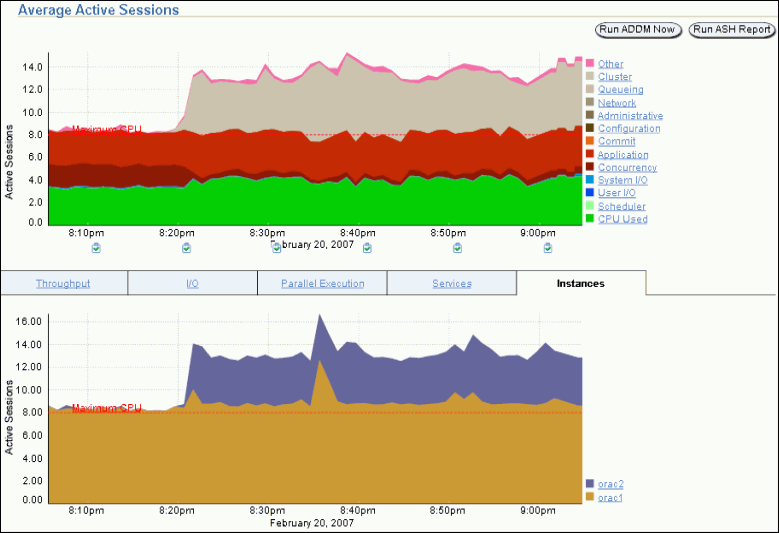
グラフ右側にある凡例をクリックして、「上位セッション」ページにアクセスすると、インスタンス・レベルの情報を参照することもできます。「上位セッション」ページでは、最もシステム・リソースを消費するセッションを示すリアルタイム・データを参照できます。
このページの詳細は、Oracle Enterprise Managerのヘルプ・システムを参照してください。
「クラスタ・データベース: パフォーマンス」ページの「その他の監視リンク」セクションおよび「その他の監視リンク」セクションには、クラスタ・データベースのパフォーマンスの評価に役立つその他のグラフへのリンクがあります。
この項の内容は次のとおりです。
|
参照:
|
「クラスタ・キャッシュ一貫性」ページには、クラスタのキャッシュ一貫性のメトリックに関するサマリーのグラフが含まれます。
表8-1に、「クラスタ・キャッシュ一貫性」グラフの説明、および問題を解決するためのより包括的な情報にアクセスする方法を示します。
表8-1 「クラスタ・キャッシュ一貫性」グラフ
「クラスタ・キャッシュ一貫性」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで「クラスタ・キャッシュ一貫性」をクリックします。
または、「グローバル・キャッシュ・ブロックのアクセス待機時間」グラフの右側にある凡例のいずれかをクリックします。
「クラスタ・キャッシュ一貫性」ページが表示されます。
「上位コンシューマ」ページのタブで、多くのシステムのリソースを消費しているサービス、モジュール、アクション、クライアント、およびセッションのリアルタイムまたは収集ベースのデータを参照できます。
「上位コンシューマ」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで「上位コンシューマ」をクリックします。
このようにアクセスすると、デフォルトでは、「上位コンシューマ」ページに最初に「概要」タブが表示され、このタブに上位リソース・コンシューマに関して集計されたサマリー・データが示されます。
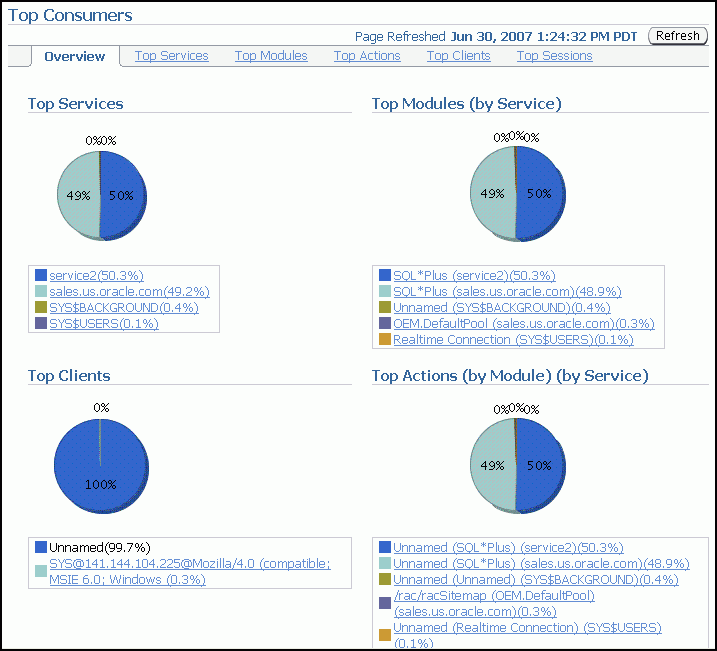
(オプション)コンシューマを表すグラフの一部をクリックするか、そのコンシューマのグラフの下のリンクをクリックして、コンシューマに関するインスタンス・レベルの情報を表示します。
表示されたページに、コンシューマを処理している実行中のインスタンスが表示されます。
(オプション)「アクション」または「モジュール」列の名前を開いて、個別のインスタンスのデータを表示します。
「上位セッション」ページには、集計されたデータに基づいた、セッションのリアルタイム・サマリー・リストが表示されます。システム・リソースを最も消費しているセッション(上位セッションと呼ばれる)を確認し、そのセッションを停止するかどうかを決定できます。
「上位セッション」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで「上位コンシューマ」をクリックします。
「上位コンシューマ」ページで、「上位セッション」サブタブをクリックします。
「トップ・アクティビティ」ページには、待機、サービスおよびインスタンスごとのクラスタ・データベース・アクティビティを表示できます。また、「トップ・アクティビティ」グラフのスライダ・バーを動かすと、5分ごとの上位SQLと上位セッションの詳細が表示できます。
「上位SQL」の詳細セクションでは、問題のあるSQL文を選択して、それらの文に対してSQLチューニング・アドバイザをスケジュールするか、またはSQLチューニング・セットを作成できます。
デフォルトでは、選択した期間に対する「上位セッション」が表示されます。このセクションの「表示」アクション・リストを使用して、次のいずれかに表示を変更できます。
上位セッション
上位サービス
上位モジュール
上位アクション
上位クライアント
上位ファイル
上位オブジェクト
上位PL/SQL
上位インスタンス
「トップ・アクティビティ」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで「トップ・アクティビティ」をクリックします。
「トップ・アクティビティ」ページが表示されます。
|
参照:
|
「インスタンス・アクティビティ」ページにより、カーソル、トランザクション、セッション、論理I/O、物理I/O、およびネットI/Oなどの一般メトリック・カテゴリ内の複数のメトリックのインスタンス・アクティビティを表示できます。毎秒のデータまたはトランザクションごとのデータを参照できます。
「インスタンス・アクティビティ」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで「インスタンス・アクティビティ」をクリックします。
(オプション)グラフィック・モードの場合にグラフの下のメトリック凡例をクリックするか、表モードの場合にサマリー表で名前をクリックして、特定のメトリックの上位セッション統計にアクセスします。
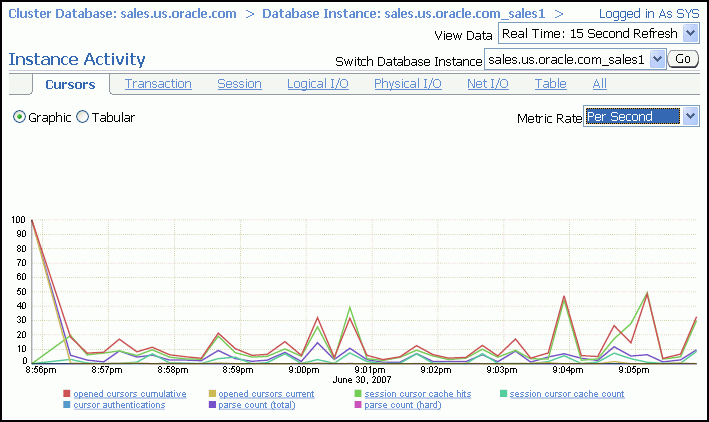
(オプション)「データベース・インスタンスの切替え」リストを使用して、データをグラフに表示するインスタンスを変更します。
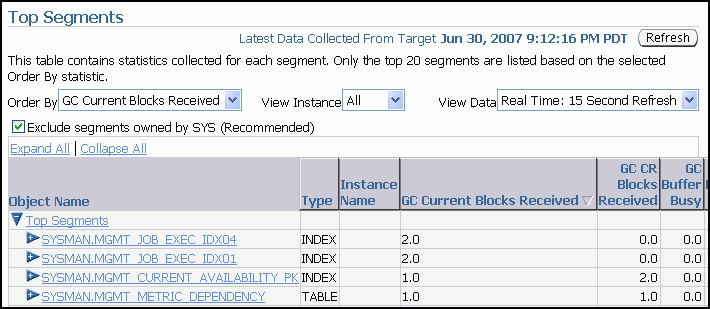
セグメント・レベルでの統計を収集して確認すると、データベース内のアクセス頻度が高い表または索引を効率的に識別できます。「上位セグメント」ページでは、セグメント・レベルの統計を収集して、個々のセグメントに関連するパフォーマンスの問題を識別できます。このページは、オブジェクトが受信した読取り一貫性ブロックおよび現行ブロックの数も追跡するため、特にOracle RACに有効です。受信した現行ブロックの数が多く、バッファ待機数も多い場合、リソースの競合が発生している場合があります。
「上位セグメント」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで「上位セグメント」をクリックします。
すべてのインスタンスのセグメント、またはフィルタを使用して特定のインスタンスのセグメントを表示できます。
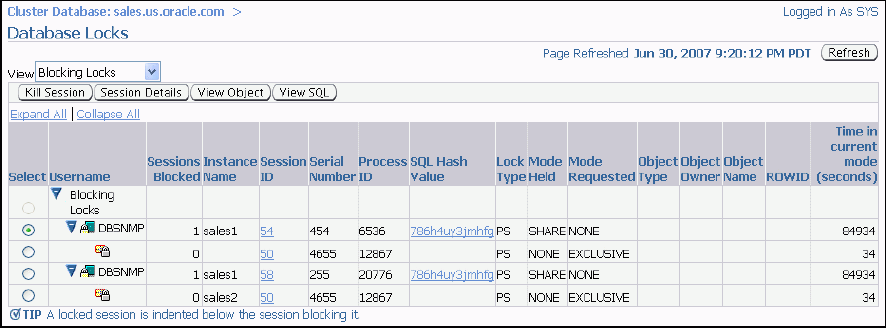
「データベース・ロック」ページでは、複数のインスタンスが同じオブジェクトをロックしているかどうかを判別できます。このページには、ユーザー・ロック、すべてのデータベース・ロック、あるいは他のユーザーまたはアプリケーションをブロックしているロックが表示されます。これらの情報を使用して、オブジェクトの不要なロックを行っているセッションを中断できます。
「データベース・ロック」ページにアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「パフォーマンス」を選択します。
「パフォーマンス」サブページが表示されます。
ページ下部の「その他の監視リンク」セクションで、「データベース・ロック」をクリックします。
Database Controlを使用すると、使用しているクラスタ環境をグラフィカルに表示できます。トポロジ表示を使用すると、クラスタ・データベース環境を構成しているコンポーネント(データベース・インスタンス、リスナー、Oracle ASMインスタンス、ホスト、インタフェースなど)を簡単に確認できます。
トポロジのダイアグラムをクリックして制御をアクティブにすると、コンポーネントの上にマウスを置いて、そのコンポーネントのステータスおよび構成の詳細を確認することができます。トポロジ・チャート内にあるコンポーネントを選択してから、そのコンポーネントを右クリックすると、そのコンポーネント特有のメニュー・アクションのセットを表示できます。
クラスタ・データベース環境のトポロジを表示するには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで「トポロジ」を選択します。
「トポロジ」サブページが表示されます。
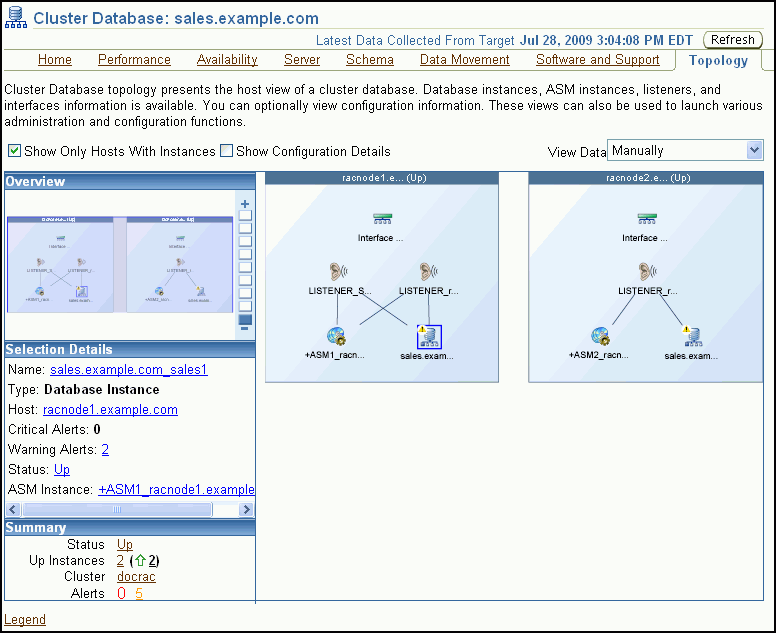
(オプション)トポロジのダイアグラム内の任意のコンポーネント上でマウス・カーソルを動かし、そのコンポーネントに関する情報をポップアップ・ボックスに表示します。
トポロジのダイアグラム内の任意のコンポーネントを選択し、「選択の詳細」セクションに表示される情報を変更します。
(オプション)ページ下部にある「凡例」をクリックし、左側に「トポロジの凡例」ページを表示します。
このページでは、クラスタ・トポロジおよびクラスタ・データベース・トポロジで使用されるアイコンについて説明されています。
(オプション)現在選択されているコンポーネントを右クリックして、そのコンポーネントで使用可能なメニュー・アクションを表示します。
Oracle Enterprise Managerを使用して、Oracle Clusterwareを監視できます。Oracle Enterprise Managerで使用可能な監視機能には、次のものがあります。
クラスタの各ノードのOracle Clusterwareステータスの表示
VIPが再配置された場合の通知の受信
プライベート・インターコネクト全体に対するスループットの監視
nodeappsが停止または起動した場合の通知の受信
データベース・インスタンスがVIPではなくパブリック・インタフェースを使用している場合のアラートの表示
OCRまたは投票ディスク関連の問題、ノードの削除、およびその他のクラスタウェア・エラーに関するクラスタウェア・アラート・ログの監視
Oracle Database 11gリリース2では、Oracle Clusterwareリソースを監視したり、個々のコンポーネントのクラスタ・コンポーネント状態監視を使用することもできます。リソースを監視するには、「クラスタ: ホーム」ページの「管理」リンクをクリックします。個々のクラスタ・コンポーネントの状態を監視するには、「クラスタ: ホーム」ページの「関連リンク」セクションで「すべてのメトリック」リンクをクリックします。
この項の内容は次のとおりです。
「クラスタ・データベース: ホーム」ページから、複数の方法でOracle Clusterwareの情報にアクセスできます。
Oracle Clusterwareの情報にアクセスするには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページの「一般」セクションで「クラスタ」の横にあるリンクをクリックし、「クラスタ: ホーム」ページを表示します。
「クラスタ・データベース: ホーム」ページに戻るには、「データベース」タブをクリックします。
「診断サマリー」で、「インターコネクト・アラート」の横にある番号をクリックし、クラスタの「インターコネクト」サブページを表示します。
「クラスタ・データベース: ホーム」ページに戻るには、「データベース」タブをクリックします。
「高可用性」セクションで、「問題のサービス」の横にある番号をクリックし、「クラスタ: ホーム」ページを表示します。
「クラスタ・データベース: ホーム」ページに戻るには、「データベース」タブをクリックします。
「トポロジ」を選択します。グラフィック表示されたノードをクリックして、制御をアクティブにします。「インタフェース」コンポーネントをクリックします。「インタフェース」コンポーネントを右クリックし、メニューから「詳細の表示」を選択し、クラスタの「インターコネクト」サブページを表示します。
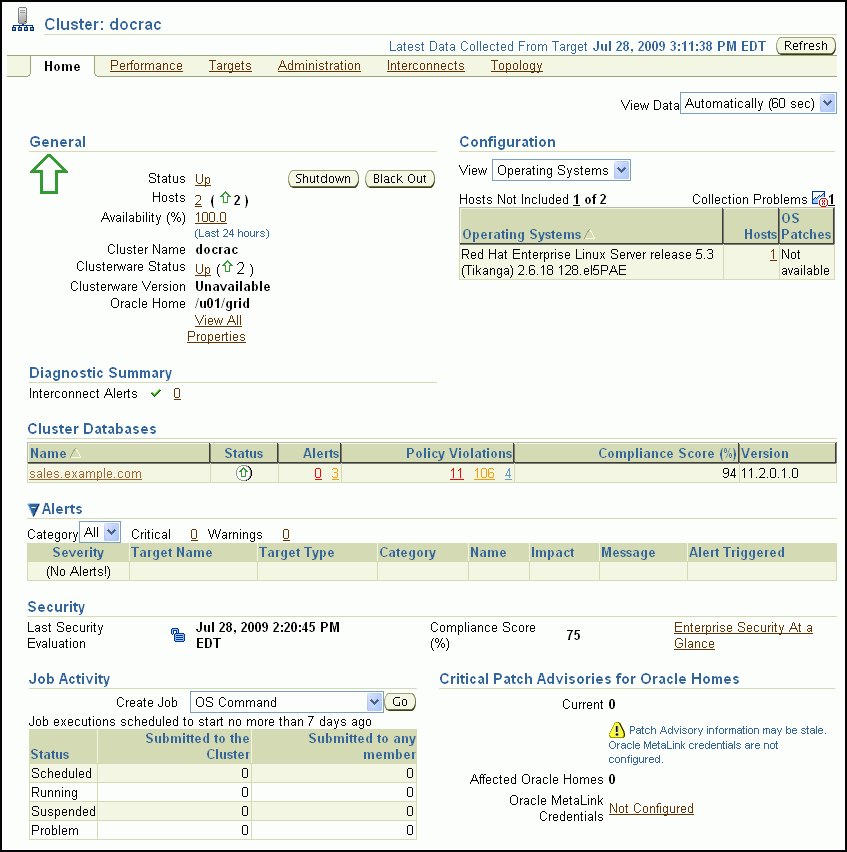
クラスタのホームページでは、クラスタの状態およびワークロードを監視できます。ここでは、一般的なクラスタの主要な状態情報を提供し、定期的に更新しています。
「クラスタ: ホーム」ページの様々なセクションで、ホスト、ターゲットおよびクラスタウェア・コンポーネントのクラスタ環境とステータスに関する情報が提供されています。たとえば、「アラート」セクションおよび「診断サマリー」セクションでは、クラスタの操作に影響のあるエラーおよびパフォーマンスの問題について警告します。提供されたリンクをクリックすると、問題のある領域の詳細を参照できます。
クラスタの全般的な状態を監視するには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページの「一般」セクションで、「クラスタ」の横にあるリンクをクリックします。
「クラスタ: ホーム」ページを表示します。
(オプション)「リフレッシュ」ボタンをクリックして、表示される情報を更新します。
クラスタからデータが最後に収集された日時が「リフレッシュ」ボタンの左に表示されます。
「一般」セクションでクラスタの概要を把握します。このセクションには次の情報が含まれています。
クラスタのステータス(稼働中または停止中)
「ステータス」リンクをクリックすると、クラスタの可用性の詳細にドリルダウンできます。
クラスタ内のホストの数
クラスタ名
Oracle Clusterware全体およびホストごとのステータス
Oracle Clusterwareのバージョン
Oracle Clusterwareホーム・ディレクトリ
「構成」セクションで、「表示」リストを使用し、次の情報から、クラスタ内の使用可能なホストに対して表示する情報を選択します。
オペレーティング・システム(ホストおよびOSパッチを含む)
ハードウェア(ハードウェア構成およびホストを含む)
詳細を表示するには、「ホスト」または「OSパッチ」の下のリンクをクリックします。
アクティブなインターコネクト・アラートの数を含む「診断サマリー」セクションを表示します。アラートの数をクリックすると、「インターコネクト」サブページが表示されます。
「クラスタ・データベース」表を参照し、このクラスタに関連付けられているクラスタ・データベース、それらのデータベースの可用性、それらのデータベースに発行されたアラートまたはポリシー違反、それらのデータベースのセキュリティ・コンプライアンス・スコア、およびデータベース・ソフトウェア・バージョンを確認します。
「アラート」セクションを確認します。このセクションには次の項目が含まれています。
「カテゴリ」リスト
オプションで、リストからカテゴリを選択すると、そのカテゴリのアラートのみが表示されます。
クリティカル
これは、クリティカルのしきい値を超えたメトリックと、インシデントによって発生したアラート(クリティカル・エラー)などのその他のクリティカル・アラートを合計した数です。
警告
これは、警告のしきい値を超えたメトリックの数です。
「アラート」表
「アラート」表には、発行されたすべてのアラートの情報がそれぞれの重大度とともに表示されます。アラートの詳細を表示するには、「メッセージ」列のアラート・メッセージをクリックします。
アラートがトリガーされると、アラートの対象のメトリック名が「名前」列に表示されます。アラートの重大度アイコン(「警告」または「クリティカル」)が、アラートがトリガーされた時間、アラートの値、およびメトリック値が最後にチェックされた時間とともに表示されます。
「セキュリティ」セクションに、クラスタの「最終セキュリティ評価」の日付および「コンプライアンス・スコア」を表示します。
コンプライアンス・スコアは、0から100までの値で、100はセキュリティ・ポリシーに完全に準拠している状態を示します。ターゲットとポリシーの組合せごとにコンプライアンス・スコアを計算する場合は、違反の重大度およびポリシーの重要性によって大きく影響され、テストされた行の合計数に対する違反している行の割合によってはそれほど影響されません。
「ジョブ・アクティビティ」セクションで、過去7日間にクラスタへ発行されたジョブの状態を確認します。
「Oracleホーム用クリティカル・パッチ・アドバイザ」セクションを確認して、Oracle Clusterwareに適用するパッチが存在するかどうかを判断します。
使用可能なパッチを表示するには、「My Oracle Supportの資格証明の検証」の説明に従って、まずMy Oracle Support(以前のOracleMetaLink)の資格証明を設定しておく必要があります。
ページ下部の「ホスト」表に、クラスタ内の各ホストの基本パフォーマンス統計を表示します。
この統計の詳細を表示するには、この表のリンクをクリックします。
ページ上部のサブタブを使用して、「パフォーマンス」、「ターゲット」、「インターコネクト」または「トポロジ」の詳細を表示します。
「クラスタ」の「パフォーマンス」ページには、「CPU」、「メモリー」、「ディスクI/O」など、クラスタのすべてのホストについての過去の使用率の統計が表示されます。これにより、Enterprise Manager環境の構成要素の1つであるクラスタの概観を確認できます。この情報に基づいて、リソースの追加または再配分の必要の有無を判断できます。
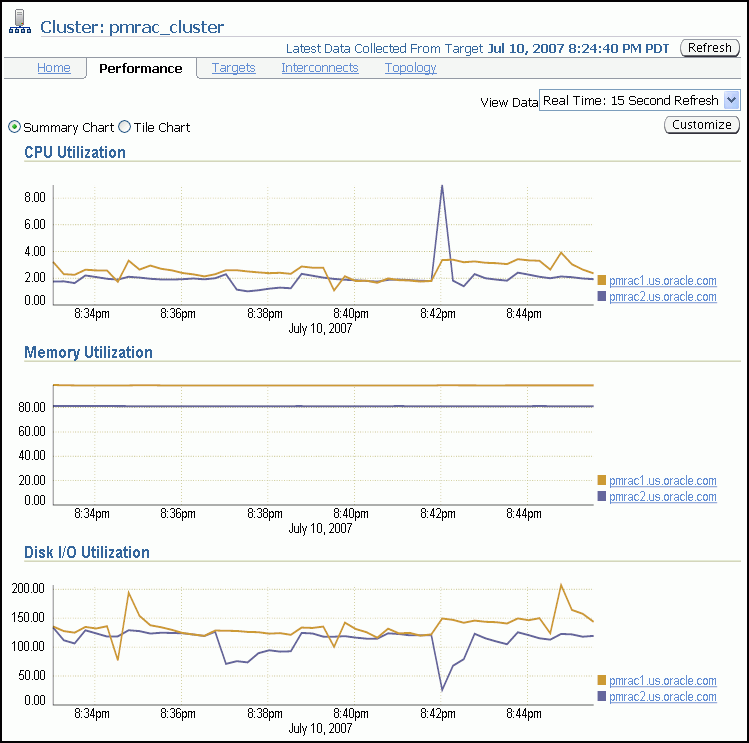
「クラスタ: パフォーマンス」ページのグラフを使用すると、次のことができます。
全ホスト間でのクラスタのCPU、メモリーおよびディスクI/Oチャートを表示します。
グラフ右側の凡例のホスト名をクリックして、各ホストのCPU、メモリーおよびディスクI/Oチャートをそれぞれ別々に表示します。
「クラスタ: パフォーマンス」ページにも、「ホスト」表が表示されます。この「ホスト」表には、クラスタのホスト、それらのホストの可用性、それらのホストに発行されたアラート、CPU使用率、メモリー使用率、および1秒当たりのI/Oのサマリー情報が表示されます。「ホスト」表でホスト名をクリックすると、そのホストの「パフォーマンス」ページに移動できます。

「クラスタ: ターゲット」ページでは、クラスタの全ターゲットのリストが表示されます。この表には、ターゲットの名前、タイプ、ホスト、場所とともに、ターゲットの可用性、警告、クリティカル・アラートおよび最新ロード時間が含まれます。
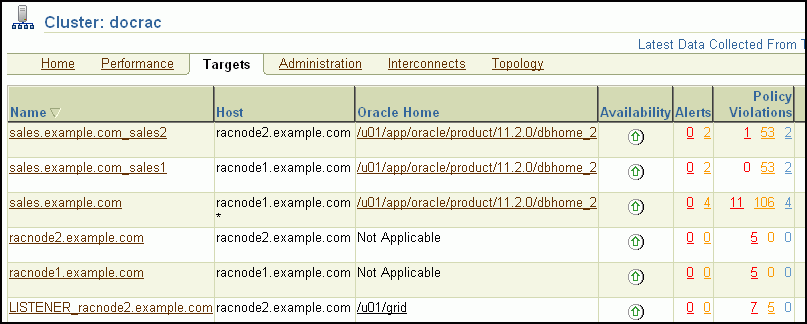
そのターゲットのホームページを表示するには、ターゲット名をクリックします。また、特定の項目、アラートまたはメトリックの詳細を表示するには、表内の各リンクをクリックします。
「ホスト」表には、クラスタのホスト、その可用性、これらのホストについて発行されたアラート、CPUおよびメモリー使用率、ならびに1秒当たりのI/Oが表示されます。
|
注意: デフォルトでは、指定されたユーザーがサーバー・プールを作成できます。この権限を持つオペレーティング・システム・ユーザーを制限するには、特定のユーザーをCRS管理者のリストに追加することをお薦めします。CRS管理者のリストへのユーザーの追加の詳細は、『Oracle Clusterware管理およびデプロイメント・ガイド』を参照してください。 |
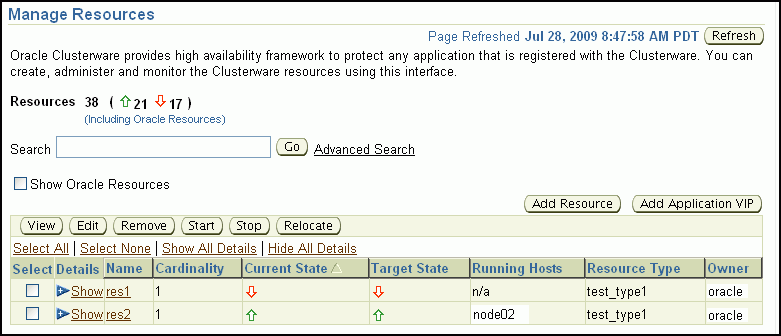
「クラスタ: 管理」ページで、Oracle Clusterwareリソースの管理、サーバー・プールの作成および管理を実行できます。このページで、Oracle Databaseの「サービスのクオリティ管理」を構成することもできます。この機能は、Oracle Database 11gリリース2(11.2.0.2)から使用可能です。

「リソースの管理」をクリックすると、リソース・ページに移動します。このページでは、Oracle Clusterwareに登録したリソースを起動、停止または再配置できます。
|
参照:
|
「クラスタ: インターコネクト」ページは、インターコネクト・インタフェースの監視、構成の問題の判別、過剰トラフィックなどの転送率に関連する問題の特定を行う場合に有効です。このページは、個々のインスタンスおよびデータベースに起因するインターコネクトへの負荷を判別する際に役立ちます。Oracle以外のアプリケーションによるインターコネクトの遅延が即時に特定できる場合もあります。
このページを使用して、次のタスクを実行できます。
クラスタにわたって構成されているすべてのインタフェースの表示
インタフェースの統計(絶対転送率、エラーなど)の表示
インタフェースのタイプ(プライベート・インタフェース、パブリック・インタフェースなど)の判別
インスタンスが使用するネットワークがパブリック・ネットワークか、またはプライベート・ネットワークかの判別
現在どのデータベース・インスタンスがどのインタフェースを使用しているかの判別
そのインスタンスがインタフェースの転送率にどの程度寄与しているかの判別
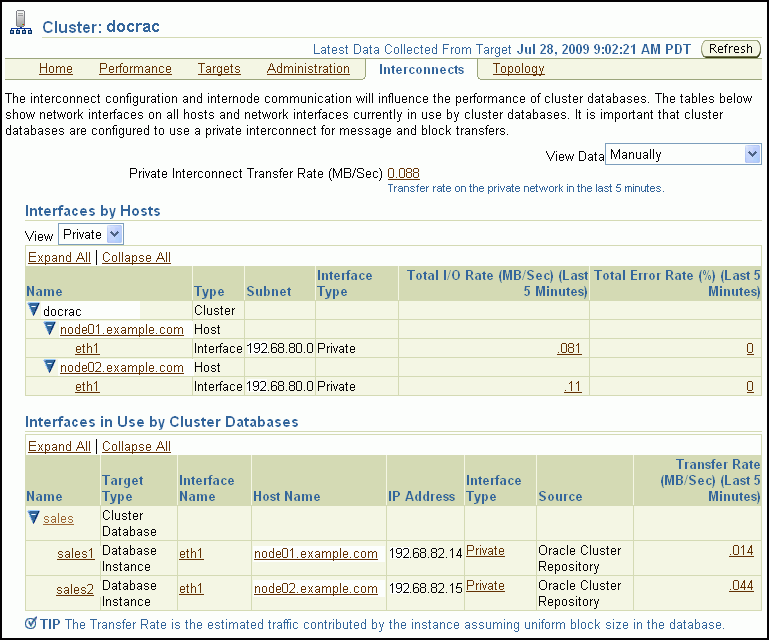
プライベート・インターコネクト転送速度の値は、クラスタ内のすべてのプライベート・ネットワークの予測通信量であるプライベート・インターコネクト通信のグローバル・ビューを示します。通信量は、クラスタで認識されるすべてのプライベート・インタフェースの入力率のサマリーとして計算されます。たとえば、トラフィック率が高い場合、プライベート・インタフェースの「ホスト別インタフェース」表にある「合計I/Oレート(MB/秒)(過去5分間)」列の値も大きくなります。この列の数値が高い場合、ネットワークの使用率が高い原因を特定する必要があります。数値をクリックすると、履歴統計およびメトリック値を示す「ネットワーク・インタフェース合計I/Oレート(MB/秒)」ページにアクセスできます。
「ホスト別インタフェース」表を使用すると、次のページにドリルダウンできます。
ホスト: ホーム
ハードウェア詳細
ネットワーク・インタフェース合計I/Oレート(MB/秒)
ネットワーク・インタフェース合計エラー率(%)
「クラスタ・データベースで使用中のインタフェース」表を使用すると、合計転送速度を確認できます。この値は、インターコネクトとして使用しているインタフェースに対して、個々のインスタンスによって生成されるネットワーク・トラフィックを示します。この値は、インスタンスが他のインスタンスと通信する頻度を示しています。
Oracle Enterprise Managerのトポロジ・ビューアを使用すると、クラスタ内のターゲット・タイプ間の関係をビジュアル表示することができます。選択内容の詳細の拡大や縮小、パン、および確認が可能です。システム・ターゲット・タイプはそれぞれ個別のアイコンで表され、すべてのターゲット・タイプに対して、選択範囲を囲むフレームなどの標準化されたビジュアル・インジケータが使用されます。
トポロジ・ビューアにより、システム構成に基づいてアイコンが移入されます。リスナーがインスタンスにサービスを提供している場合、リスナー・アイコンとインスタンス・アイコンが直線で結ばれます。クラスタ・データベースがOracle ASMを使用するように構成されている場合、トポロジにはクラスタOracle ASMとクラスタ・データベースの関係が表示されます。
「構成の詳細の表示」オプションの選択を解除した場合、トポロジではアラートや全体的ステータスなどの一般情報を含む、環境の監視ビューが表示されます。「構成の詳細の表示」オプションを選択した場合、任意のトポロジ・ビューに有効な追加の詳細が「選択の詳細」ページに表示されます。たとえば、「リスナー」コンポーネントの場合は、コンピュータ名とポート番号も表示されます。
アイコンをクリックしてからマウスの右ボタンを使用すると、使用可能なアクションのメニューが表示されます。いくつかのアクションでは、ターゲット・タイプに関連するページに移動して、タスクの監視またはチューニングを実行できます。
このページの詳細は、Oracle Enterprise Managerのオンライン・ヘルプを参照してください。
Oracle Database管理ツールを使用せず、手動でインストールやデータベース作成プロセスを完了しようとすると問題が発生することがあります。また、データベース管理者やシステム管理者がオペレーティング・システムまたはクラスタの重要な構成手順をインストール前に行わなかったために発生する問題もあります。Oracle ClusterwareとOracle Databaseのコンポーネントはいずれも、トラブルシューティングできるサブコンポーネントを持っています。クラスタ・レディ・サービス・コントロール(CRSCTL)・コマンドのcheckを使用すると、複数のOracle Clusterwareコンポーネントのステータスを同時に判別できます。
この項の内容は次のとおりです。
rootオペレーティング・システム・ユーザーとしてCRSCTLコマンドを使用すると、Oracle Clusterwareのインストール上の問題を診断し、Oracle Clusterwareを動的にデバッグできます。この項の内容は次のとおりです。
Oracle Clusterwareは、重要なイベントが発生すると、アラート・メッセージで通知します。たとえば、クラスタ・レディ・サービス(CRS)・デーモン・プロセスが起動した場合、中断された場合、フェイルオーバー・プロセスが失敗した場合、またはOracle Clusterwareリソースの自動再起動が失敗した場合などに、CRSデーモン・プロセスからのアラート・メッセージが表示されます。
Oracle Enterprise Managerは、クラスタウェア・ログ・ファイルを監視し、エラーが検出されると「クラスタ: ホーム」ページにアラートを表示します。たとえば、投票ディスクが利用できない場合はCRS-1604エラーが発生し、「クラスタ・ホーム」ページにクリティカル・アラートが書き込まれます。「メトリックとポリシー設定」ページで、エラー検出およびアラート設定をカスタマイズできます。
深刻なエラーを見つけるには、まずOracle Clusterwareを確認します。多くの場合、ここには特定のコンポーネントに関する詳細情報を提供する他の診断ログへの参照が含まれます。Oracle Clusterwareのログ・ファイルの場所は、CRS_home/log/hostname/alerthostname.logです。CRS_homeはOracle Clusterwareがインストールされたディレクトリ、hostnameはローカル・ノードのホスト名です。
Oracle RACでは、統合されたログ・ディレクトリ構造を使用して、すべてのOracle Clusterwareのコンポーネント・ログ・ファイルが格納されます。この統合された構造によって、診断情報の収集が簡略化され、データ取得や問題分析がしやすくなります。
次の各ログ・ファイルの場所で、ノード名はhostnameです。たとえば、racnode2およびCRS_homeは、Oracle Clusterwareソフトウェアがインストールされたディレクトリです。
CRSデーモンcrsdのログ・ファイルは、次のディレクトリにあります。
CRS_home/log/hostname/crsd/
CSSデーモンcssdのログ・ファイルは、次のディレクトリにあります。
CRS_home/log/hostname/cssd/
EVMデーモンevmdのログ・ファイルは、次のディレクトリにあります。
CRS_home/log/hostname/evmd/
Oracle Cluster Registry(OCR)のログ・ファイルは、次のディレクトリにあります。
CRS_home/log/hostname/client/
Oracle RAC高可用性コンポーネントの一部である各プログラムには、そのプログラムに対して排他的に割り当てられるサブディレクトリがあります。サブディレクトリの名前は、プログラム名と同じです。
|
注意: 任意のOracle Clusterwareコンポーネントがコア・ダンプ・ファイルを生成する場合、そのコンポーネントのログ・ディレクトリのサブディレクトリにダンプ・ファイルが配置されます。 |
Oracle Clusterwareコンポーネントまたはデーモンのステータスを表示するには、CRSCTLのcheckコマンドを使用します。
クラスタウェア・インストールの条件を決定するには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
CRSCTLを使用し、次のコマンドを使用してOracle Clusterwareのステータスをチェックします。
# crsctl check crs
次の構文を使用すると、個々のOracle Clusterwareデーモンのステータスをチェックできます。daemonは、crsd、cssdまたはevmdです。
# crsctl check daemon
クラスタの任意のノードで実行されているすべてのOracle Clusterwareリソースのステータスをリストするには、次のコマンドを使用します。
# crsctl status resource -t
このコマンドはすべての登録済Oracle Clusterwareリソースのステータスをリストします。このリストには、VIP、リスナー、データベース、サービス、Oracle ASMインスタンスおよびディスク・グループが含まれます。
Oracle Clusterwareの診断収集スクリプトによってOracle Clusterwareのインストールに関する診断情報が収集されます。Oracleサポート・サービスで問題を解決するために、診断によって追加情報が提供されます。Cluster Synchronization Services(CSS)、Event Manager(EVM)、およびCluster Ready Services(CRS)デーモンの状態が表示されます。
Oracle Clusterwareの診断収集スクリプトを実行するには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
次のようなオペレーティング・システム・プロンプトからdiagcollection.plスクリプトを実行します。Grid_homeは、クラスタ用Oracle Grid Infrastructureインストールのホーム・ディレクトリです。
# Grid_home/bin/diagcollection.pl --collect
CRSCTLコマンドを実行して、Oracle Clusterデーモン、イベント・マネージャ(EVM)、およびそれらのモジュールのデバッグを有効化できます。
Oracle Clusterwareコンポーネントのデバッグを有効化するには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
次のコマンドを使用してコンポーネントのモジュール名を取得します。component_nameは、デバッグを有効にするcrs、evm、cssなどのコンポーネント名です。
# crsctl lsmodules component_name
たとえば、cssコンポーネントのモジュールの表示では、次のような結果が戻ります。
# crsctl lsmodules css The following are the CSS modules :: CSSD COMMCRS COMMNS
component_nameが、有効化するデバッグのOracle Clusterwareコンポーネントの名前で、moduleがモジュールの名前で、さらにdebugging_levelが1から5のいずれかの番号であり、次のようなCRSCTLを使用します。
# crsctl debug logcomponentmodule:debugging_level
たとえば、cssコンポーネントのCSSDモジュールの最下位レベルのトレースを有効化するには、次のコマンドを使用します。
# crsctl debug log css CSSD:1
CRSCTLコマンドを使用して、Oracle Clusterwareに管理されているリソースのデバッグを有効にします。
Oracle Clusterwareリソースのデバッグを有効にするには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
次のコマンドを実行し、デバッグの対象にできるリソースのリストを取得します。
# crsctl check crs
次のコマンドを実行してデバッグを有効にします。resource_nameはora.racnode1.vipなどのOracle Clusterwareリソース名、debugging_levelは1から5のいずれかの数字です。
# crsctl debug log res resource_name:debugging_level
Oracle Clusterwareのデーモンが有効な場合、ノードが起動したときに自動的に起動します。自動的に起動しないようにするには、crsctlコマンドを使用してデーモンを無効にします。
すべてのOracle Clusterwareデーモンの自動起動を有効にするには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
次のCRSCTLコマンドを実行します。
# crsctl enable crs
すべてのOracle Clusterwareデーモンの自動起動を無効にするには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
次のCRSCTLコマンドを実行します。
# crsctl disable crs
|
参照:
|
クラスタ検証ユーティリティ(CVU)は、構成における様々な問題の診断を支援するユーティリティです。
この項の内容は次のとおりです。
CVUのcomp nodeappコマンドを使用して、すべてのノード上でのノード・アプリケーション、つまり仮想IP(VIP)、Oracle Notification Services(ONS)およびグローバル・サービス・デーモン(GSD)の存在を確認します。
ノード・アプリケーションの存在を確認するには、次の手順を実行します。
コマンド・ウィンドウで、Oracle Clusterwareソフトウェア・インストールを所有するユーザーとしてオペレーティング・システムにログインします。
次の構文でCVUのcomp nodeappコマンドを使用します。
cluvfy comp nodeapp [ -n node_list] [-verbose]
node_listはチェックするノードを表します。
cluvfyコマンドが特定のノードのUNKNOWNの値を戻す場合、CVUではチェックに成功したか失敗したかは判別できません。次のどの理由で失敗したかを判別します。
ノードが停止している。
CRS_home/binディレクトリまたはOracle_home/binディレクトリにCVUが必要とする実行可能ファイルが存在しない。
CVUを実行したユーザー・アカウントに対して、ノード上の一般的なオペレーティング・システム実行可能ファイルを実行する権限が付与されていない。
オペレーティング・システム・パッチまたは必要なパッケージがノードに適用されていない。
そのノードのカーネル・パラメータが正しく構成されていないため、チェックの実行に必要なオペレーティング・システム・リソースをCVUが取得できない。
CVUのcomp crsコマンドを使用して、すべてのOracle Clusterwareコンポーネントの存在を確認します。
Oracle Clusterwareコンポーネントの整合性を検証するには、次の手順を実行します。
コマンド・ウィンドウで、Oracle Clusterwareソフトウェア・インストールを所有するユーザーとしてオペレーティング・システムにログインします。
次の構文でCVUのcomp crsコマンドを使用します。
cluvfy comp crs [ -n node_list] [-verbose]
node_listはチェックするノードを表します。
CVUのcomp ocrコマンドを使用して、Oracle Clusterwareレジストリの整合性を検証します。
Oracle Clusterwareレジストリの整合性を検証するには、次の手順を実行します。
コマンド・ウィンドウで、Oracle Clusterwareソフトウェア・インストールを所有するユーザーとしてオペレーティング・システムにログインします。
次の構文でCVUのcomp ocrコマンドを使用します。
cluvfy comp ocr [ -n node_list] [-verbose]
node_listはチェックするノードを表します。
CVUのcomp cluコマンドを使用して、クラスタ内のすべてのノードにクラスタ構成の同一ビューがあるかチェックします。
クラスタの整合性を検証するには、次の手順を実行します。
コマンド・ウィンドウで、Oracle Clusterwareソフトウェア・インストールを所有するユーザーとしてオペレーティング・システムにログインします。
次の構文でCVUのcomp cluコマンドを使用します。
cluvfy comp clu [-verbose]
|
参照:
|
キャッシュ・フュージョンでは、高速インターコネクトを使用して別のインスタンスのバッファ・キャッシュにデータ・ブロックが送信されるため、Oracle RACのパフォーマンスが向上します。最大限のパフォーマンスを得るために、高速インターコネクトは帯域幅が最も高いプライベート・ネットワークである必要があります。
ネットワーク接続の検証では、CVUコマンドラインでインタフェースを指定しない場合、すべての使用可能なネットワーク・インタフェースが検出されます。
相互接続の設定をチェックするには、次の手順を実行します。
コマンド・ウィンドウで、Oracle Clusterwareソフトウェア・インストールを所有するユーザーとしてオペレーティング・システムにログインします。
node_listで指定したクラスタ・ノードのアクセス可能性を検証するには、次のようなコンポーネント検証コマンドnodereachを使用します。srcnodeで指定するとローカル・ノードまたは別のクラスタ・ノードで検証できます。
cluvfy comp nodereach -n node_list [ -srcnode node ] [-verbose]
node_listに指定したノード間の接続性を、ローカル・ノードまたは任意の他のクラスタ・ノードから使用可能なネットワーク・インタフェースを介して検証するには、次の例に示すようにcomp nodeconコマンドを使用します。
cluvfy comp nodecon -n node_list -verbose
前述の例で示されるように、nodeconコマンドを発行すると、CVUは次のタスクを実行するように指示されます。
指定したクラスタ・ノード上で使用可能なすべてのネットワーク・インタフェースの検出
インタフェースに対応したIPアドレスおよびサブネットの確認
VIPとしての使用に適したインタフェースのリストおよびプライベート・インターコネクトのインタフェースのリストの取得
これらのインタフェースを介したすべてのノード間の接続性の検証
冗長モードでnodeconコマンドを実行して、インタフェース、IPアドレスおよびサブネット間のマッピングが識別できます。
特定のネットワーク・インタフェースを介したノード間の接続性を検証するには、-iオプションのあるcomp nodeconコマンドを使用して、interface_list引数によってチェックされるインタフェースを指定します。
cluvfy comp nodecon -n node_list -i interface_list [-verbose]
たとえば、次のコマンドを実行して、特定のネットワーク・インタフェースeth0を介してracnode1、racnode2およびracnode3ノード間の接続性を検証できます。
cluvfy comp nodecon -n racnode1,racnode2,racnode3 -i eth0 -verbose
|
参照:
|
トレースを有効にしないかぎり、CVUではトレース・ファイルは生成されません。CVUトレース・ファイルは、CRS_home/cv/logディレクトリで作成されます。Oracle RACではログ・ファイルは自動的にローテーションされ、最後に作成されたログ・ファイルの名前はcvutrace.log.0になります。必要に応じて、不要なログ・ファイルを削除するかアーカイブして、ディスク領域を再利用します。
CVUを使用したトレースを有効にするには、次の手順を実行します。
コマンド・ウィンドウで、rootユーザーとしてオペレーティング・システムにログインします。
環境変数SRVM_TRACEをtrueに設定します。
# set SRVM_TRACE=true; export SRVM_TRACE
コマンドを実行してトレースします。
アラート・メッセージがOracle Enterprise Managerに表示されます。アラート表は、単一インスタンスのデータベースの場合と同様の形式ですが、クラスタ・データベースの場合は、ターゲット名およびターゲット・タイプの列も表示されます。たとえば、ユーザーが割り当てられたログイン時間を超えて、orcl1インスタンスに接続していると、次の値を含むアラート・メッセージが表示されます。
ターゲット名: orcl_orcl1
ターゲット・タイプ: データベース・インスタンス
カテゴリ: レスポンス
名前: ユーザー・ログオン時間
メッセージ: ユーザー・ログオン時間は10250ミリ秒
アラート・トリガー: アラート条件が発生した日時
Oracle RACデータベースのアラート・メッセージを参照するには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで、「アラート」セクションまで下にスクロールします。
「関連アラート」セクションには、データベース以外のアラート・メッセージ(Oracle Netのアラート・メッセージなど)が表示されます。
データベースおよびデータベース・インスタンスに関するアラートを確認します。
次のスクリーンショットは、docracというクラスタ・データベースについてのアラート表示の例を示しています。
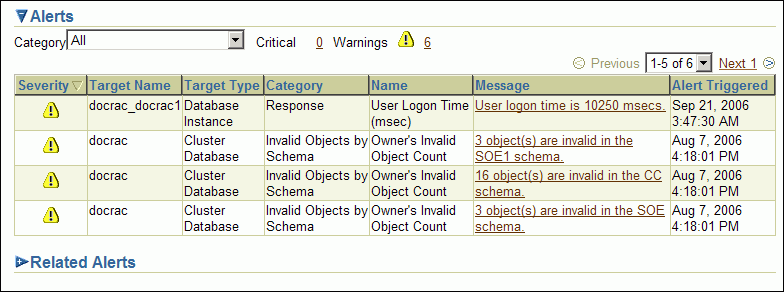
|
参照:
|
アラート・ログは、クラスタ・データベース内の各インスタンスに作成されます。
Oracle RACデータベース・インスタンスのアラート・ログを参照するには、次の手順を実行します。
「クラスタ・データベース: ホーム」ページで、「インスタンス」セクションまで下にスクロールします。
アラート・ログを表示するインスタンスの名前をクリックします。
「クラスタ・データベース・インスタンス: ホーム」ページが表示されます。
「診断サマリー」セクションで、「アラート・ログ」ヘッダーの横のリンクをクリックして、ORA-エラーを含むアラート・ログ・エントリを表示します。
「アラート・ログ・エラー」ページが表示されます。
(オプション)「関連リンク」セクションの「アラート・ログの内容」をクリックして、アラート・ログ内のすべてのエントリを表示します。
「アラート・ログの内容の表示」ページで、「実行」をクリックすると最新のエントリが表示されます。独自の検索条件を入力することもできます。
Oracle By Example(OBE)には、Oracle RACデータベースでのADDMの使用に関するビューレット(アニメーション・デモ)があります。
監視およびチューニングに関するビューレットを表示するには、ブラウザで次のURLを入力します。
http://www.oracle.com/technetwork/dbadev/index.html
画面左下のメニューから、「Database Learning Library」を選択します。次のパラメータを使用して検索を実行します。
Content Type: Demo
Functional Category: Grid
Product Suite: Oracle Database 11g (ODB11g)
「Use Global ADDM Analysis in a RAC Environment」などのタイトルをクリックして、デモを開始します。
