| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章は、データ・ウェアハウスの作成および管理に有効な情報について説明します。内容は次のとおりです。
データ変換は最も複雑で、抽出、変換およびロード(ETL)プロセスの中で最も処理時間がかかることがあります。データ変換では、単純なデータ変換からかなり複雑なデータのクレンジング・テクニックまで実行できます。変換は、データベース外(フラット・ファイルなど)でも実装されることがありますが、ほとんどの場合はOracleデータベース内で行います。
この章では、Oracle Database内でスケーラブルで効果的なデータ変換を実装するテクニックについて説明します。この章の例は比較的単純です。実際のデータ変換は、通常、はるかに複雑です。ただし、この章で説明した変換テクニックは、実際のデータ変換要件のほとんどを満たしており、その他の方法よりスケーラブルで、少ないプログラミングで済みます。
この章では、データ・ウェアハウスで発生する一般的な変換をすべて説明しているわけではありません。これらの変換を実装するために使用できる基本的なテクニックの種類を示し、最適なテクニックの選択方法を説明します。
アーキテクチャの観点では、データ変換には次の2通りの方法があります。
ほとんどのデータ・ウェアハウスのデータ変換のロジックは、複数のステップから構成されています。たとえば、sales表に挿入するために新しいレコードを変換する場合、各ディメンション・キーの妥当性チェックを行うには、個別のロジック変換ステップに従う必要がある場合があります。
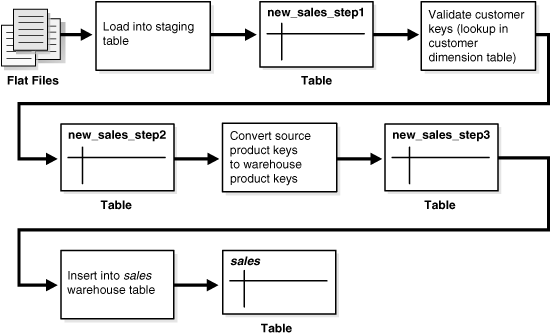
図15-1は、変換ロジックをグラフィカルに示したものです。
Oracle Databaseを変換エンジンとして使用する場合、一般的な方法では、変換をそれぞれ別々のSQL操作として実装し、各ステップの処理結果を格納するために別々の一時的なステージング表(図15-1の表new_sales_step1やnew_sales_step2など)を作成します。また、ロードしてから変換するこの方法では、変換プロセス全体にチェックポイント取得を実行するスキームが提供されます。このスキームによって、プロセスの監視および再起動が簡単になります。ただし、マルチステージングには、領域と時間の必要性が増大するというデメリットもあります。
また、多数の単純なロジック変換を、単一のSQL文または単一のPL/SQLプロシージャに結合することも可能です。このような結合を行うと、各ステップを個別に実行するよりパフォーマンスが向上することがありますが、同時に、個々の変換の変更、追加、削除や、失敗した変換からのリカバリが困難になる場合があります。
ETLプロセス・フローは動的に変更でき、データベースはETLソリューションに不可欠の部品になります。
新機能により従来は必要だったプロセス・ステップの一部が廃止になりますが、改造してデータ・フローとデータ変換を強化し、よりスケーラブルで中断のないものにできます。タスクは変換してからロードするという(ほとんどのタスクがデータベース外部で実行される)シリアル・プロセスや、ロードしてから変換するというプロセスから拡張され、ロードしながら変換するプロセスへとシフトします。
Oracleでは、ETLシナリオに関連するすべての問題とタスクに対処できるように、多様な新機能が用意されています。データベースは、汎用的なソリューションに対処するのではなく、ツールキット機能を提供するということを理解する必要があります。基礎となるデータベースは、特定の顧客のニーズに合せて最も適切なETLプロセス・フローを有効化する必要があり、技術的な観点での要件や制約がないようにする必要があります。図15-2に、以降で説明する新機能を示します。
ロードの全体的な速度は、生データをいかに速くステージング領域から読み取ることができるか、データベースのターゲット表に書き込むことができるかにより決まります。生データはできるだけ多くの物理ディスクにステージングし、生データの読取りがロード時のボトルネックにならないようにすることを強くお薦めします。
データをステージングするのに最適な場所はOracle Database File System(DBFS)です。DBFSはSecureFile LOBとしてデータベースに格納されたファイルへのアクセスに使用できるマウント可能なファイルシステムを作成します。DBFSはローカルのファイルシステムのように見える共有ネットワーク・ファイルシステムを提供するという点でNFSと似ています。DBFSはデータ・ウェアハウスとは別のデータベースに作成し、DIRECT_IOオプションを使用してマウントして、ファイルシステムとの間の生データ・ファイルの移動時にシステム・ページ・キャッシュの競合が起きないようにします。DBFSの設定の詳細は、『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』を参照してください。
データ・ウェアハウスへのロードには、次のメカニズムを使用できます。
データ変換をデータベース内で行うには、生データがデータベースでアクセス可能になっている必要があります。その方法の1つは、データベースにロードすることです。データをOracleデータ・ウェアハウスに転送するいくつかのテクニックについては、第14章「データ・ウェアハウスにおける転送」を参照してください。データを転送する最も一般的なテクニックは、フラット・ファイルを使用する方法です。
データをフラット・ファイルからOracleデータ・ウェアハウスへ移動するには、SQL*Loaderを使用します。このデータのロード中に、SQL*Loaderを使用して、基本的なデータ変換の実装を行うこともできます。ダイレクト・パスSQL*Loaderを使用すると、データ型変換や単純なNULL処理などの基本的なデータ操作は、データのロード中に自動的に解決できます。パフォーマンスの理由から、ほとんどのデータ・ウェアハウスでは、ダイレクト・パス・ロードが選択されます。
従来型パス・ローダーは、ダイレクト・パス・ローダーより広範囲な機能をデータ変換で使用できます。SQL関数は、列の値がロードされるときに、すべての列に適用できます。これによって、データのロード中に、豊富な機能を使用して変換できるようになります。ただし、従来型パス・ローダーはダイレクト・パス・ローダーより低速です。このような理由から、従来型パス・ローダーを使用するのは、主に少量のデータをロードおよび変換する場合にしてください。
ここでは、SQL*Loader制御ファイルの単純な例を示します。このファイルでは、外部ファイルsh_sales.datからshサンプル・スキーマのsales表にデータがロードされます。外部フラット・ファイルsh_sales.datは、日次レベルで集計された売上トランザクション・データで構成されています。この外部ファイルのすべての列がsales表にロードされるわけではありません。この外部ファイルは、shサンプル・スキーマの2番目のファクト表をロードするためのソースとしても使用されます。これには、外部表が使用されます。
次に、sales表をロードする制御ファイル(sh_sales.ctl)を示します。
LOAD DATA INFILE sh_sales.dat APPEND INTO TABLE sales FIELDS TERMINATED BY "|" (PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, PROMO_ID, QUANTITY_SOLD, AMOUNT_SOLD)
このロードには、次のコマンドを使用できます。
$ sqlldr control=sh_sales.ctl direct=true Username: Password:
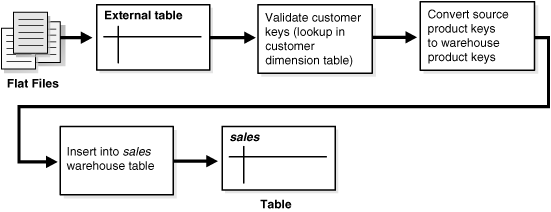
外部データソースを処理するもう1つのアプローチは、外部表を使用することです。Oracleの外部表機能では、外部データを直接およびパラレルに問い合せて結合できる仮想表として使用できます。この場合、外部データを最初にデータベースにロードする必要はありません。そのまま、SQL、PL/SQLおよびJavaを使用して外部データにアクセスできます。
外部表を使用すると、ロード・フェーズを変換フェーズとパイプライン化できます。データ・ストリーミングを中断せずに、変換プロセスをロード・プロセスとマージできます。データベースで比較や変換などの処理を行うために、データベース内でデータをステージングする必要はなくなります。たとえば、外部表からのSELECTと組み合わせたダイレクト・パスのINSERT AS SELECT文で、従来型ロードの変換機能を使用できます。
外部表と通常の表の主な違いは、外部で編成された表は読取り専用であることです。DML操作(UPDATE/INSERT/DELETE)は実行できず、索引も作成できません。
外部表は既存のSQL*Loader機能の大部分に準拠しており、ほとんどの場合において、より優れた機能を提供します。外部表は、外部ソース全体を既存のデータベース・オブジェクトと結合する必要がある環境、またはデータを複雑な方法で変換する必要がある環境で特に有効です。たとえば、SQL*Loaderとは異なり、任意のSQL変換を適用してダイレクト・パス・インサートを使用できます。さらに、ファイル(圧縮されたデータファイルなど)を処理する実行対象のプログラム(zcatなど)を指定し、その出力(圧縮されていないデータファイルなど)をOracle Databaseで利用できるようにすることもできます。つまり、大量の圧縮データをロードする際に、先にそのデータをディスクに展開する必要がないということです。
外部ファイルsh_sales.gzに表される、売上トランザクション・データ全体の構造を表す外部表sales_transactions_extを作成できます。製品部門では、製品と時間単位の原価分析が特に重要です。したがって、shスキーマにファクト表costを作成します。処理するソース・データは、salesファクト表の場合と同じです。ただし、提供される全ディメンション情報を調査するわけではないため、costファクト表のデータはsalesファクト表のデータより疎い密度になっています。たとえば、すべての異なる物流チャネルが1つに集計されます。
ディメンションの一部は使用されないため、前述のような詳細情報の集計を行わないとcostファクト表にデータをロードできません。
外部表フレームワークは、そのソリューションを提供します。SQL*Loaderでは集計を適用する前にデータをロードする必要がありましたが、それとは異なり、次のように単一のSQL DML文中にロードと変換を組み合せることができます。ターゲット表に挿入する前にデータを一時的にステージングする必要はありません。
オブジェクト・ディレクトリがすでに存在し、sh_sales.gzファイルを含むディレクトリと不良ファイルおよびログ・ファイルを含むディレクトリを指定する必要があります。
CREATE TABLE sales_transactions_ext
(PROD_ID NUMBER, CUST_ID NUMBER,
TIME_ID DATE, CHANNEL_ID NUMBER,
PROMO_ID NUMBER, QUANTITY_SOLD NUMBER,
AMOUNT_SOLD NUMBER(10,2), UNIT_COST NUMBER(10,2),
UNIT_PRICE NUMBER(10,2))
ORGANIZATION external (TYPE oracle_loader
DEFAULT DIRECTORY data_file_dir ACCESS PARAMETERS
(RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII
PREPROCESSOR EXECDIR:'zcat'
BADFILE log_file_dir:'sh_sales.bad_xt'
LOGFILE log_file_dir:'sh_sales.log_xt'
FIELDS TERMINATED BY "|" LDRTRIM
( PROD_ID, CUST_ID,
TIME_ID DATE(10) "YYYY-MM-DD",
CHANNEL_ID, PROMO_ID, QUANTITY_SOLD, AMOUNT_SOLD,
UNIT_COST, UNIT_PRICE))
location ('sh_sales.gz')
)REJECT LIMIT UNLIMITED;
これで、外部表をデータベースから使用し、外部データの一部の列にのみアクセスし、データをグルーピングして、costsファクト表に挿入できます。
INSERT /*+ APPEND */ INTO COSTS (TIME_ID, PROD_ID, UNIT_COST, UNIT_PRICE) SELECT TIME_ID, PROD_ID, AVG(UNIT_COST), AVG(amount_sold/quantity_sold) FROM sales_transactions_ext GROUP BY time_id, prod_id;
|
参照:
|
OCIおよびダイレクト・パスAPIが頻繁に使用されるのは、変換と計算がデータベースの外部で実行され、フラット・ファイルのステージングを必要としない場合です。
エクスポートとインポートは、データがそのままターゲット・システムに挿入される場合に使用されます。複雑な抽出は実行できません。詳細は、第13章「データ・ウェアハウスにおける抽出」を参照してください。
データがデータベースにロードされると、SQL操作を使用してデータ変換を実行できます。SQLデータ変換を実装するには、次の4つの基本的なテクニックがあります。
CREATE TABLE ... AS SELECT文(CTAS)は、大規模なデータセットを操作する場合に強力なツールです。後述する例のように、多くのデータ変換は標準SQLで記述でき、CTASにより、SQL問合せを効果的に実行してその問合せ結果を新しいデータベース表に格納する機能が提供されます。INSERT /*+APPEND*/ ...AS SELECT文の機能は、既存のデータベース表に対して同様の機能を提供します。
データ・ウェアハウス環境では、CTASは、最大のパフォーマンスを得るためにNOLOGGINGモードで、パラレルで実行されます。
簡単で一般的なデータ変換は、データの置換えです。データ置換えによる変換では、1つの列のいくつかまたはすべての値が変更されます。たとえば、sales表にchannel_id列があるとします。この列は、指定された売上トランザクションが企業自体の売上(直接販売)によるものか、または販売店(間接販売)によるものかを指定するために使用されます。
データ・ウェアハウスの複数のソース・システムからデータを受け取る場合があるとします。これらのソース・システムのうち、直接販売のみを処理し、間接販売チャネルには関与していないソース・システムがあるとします。データ・ウェアハウスがこのシステムから売上データを最初に受け取ると、すべての売上レコードのsales.channel_idフィールドはNULL値になります。これらのNULL値は、適切なキー値に設定する必要があります。たとえば、ターゲットとなるsales表の文への挿入の一部としてSQL関数を使用すると、この操作を効率的に行うことができます。ソース表sales_activity_directの構造は、次のとおりです。
DESC sales_activity_direct Name Null? Type ------------ ----- ---------------- SALES_DATE DATE PRODUCT_ID NUMBER CUSTOMER_ID NUMBER PROMOTION_ID NUMBER AMOUNT NUMBER QUANTITY NUMBER
次のSQL文は、sales_activity_directのデータをサンプル・スキーマのsales表に挿入します。ここでは、売上日時(sales_date)の値を午前0時に切り捨てるSQL関数を使用し、固定チャネルIDとして3を割り当てます。
INSERT /*+ APPEND NOLOGGING PARALLEL */
INTO sales SELECT product_id, customer_id, TRUNC(sales_date), 3,
promotion_id, quantity, amount
FROM sales_activity_direct;
データ置換を実装するもう1つのテクニックは、UPDATE文を使用してsales.channel_id列を変更することです。UPDATEによって正しい結果が戻されます。ただし、データ置換による変換で多数(またはすべての行)の変更が必要であれば、UPDATEではなくCTAS文を使用する方が効率的な場合があります。
Oracle Databaseのマージ機能では、表または表外の単一表ビューに行を条件付きで更新または挿入できるように、SQLキーワードMERGEを導入することでSQLが拡張されます。条件は、ON句に指定します。これは、純粋な大量ロードと並んでデータ・ウェアハウスの同期化における最も一般的な操作です。
ここでは、マージの各種実装について説明します。この例では、ディメンション表productsの新規データをデータ・ウェアハウスに転送し、挿入または更新する必要があるとします。表products_deltaの構造はproductsと同じです。
例15-1 SQLを使用したマージ操作
MERGE INTO products t USING products_delta s ON (t.prod_id=s.prod_id) WHEN MATCHED THEN UPDATE SET t.prod_list_price=s.prod_list_price, t.prod_min_price=s.prod_min_price WHEN NOT MATCHED THEN INSERT (prod_id, prod_name, prod_desc, prod_subcategory, prod_subcategory_desc, prod_category, prod_category_desc, prod_status, prod_list_price, prod_min_price) VALUES (s.prod_id, s.prod_name, s.prod_desc, s.prod_subcategory, s.prod_subcategory_desc, s.prod_category, s.prod_category_desc, s.prod_status, s.prod_list_price, s.prod_min_price);
多くの場合、外部データソースは、様々なターゲット・オブジェクトに挿入できるように、論理属性に基づいて分離する必要があります。また、通常、データ・ウェアハウス環境では、同じソース・データが複数のターゲット・オブジェクトに分岐しています。マルチテーブル・インサートでは、この種の変換用に新しいSQL文が用意されており、ビジネス上の変換ルールに応じてデータを複数または1つのターゲットにできます。この挿入は、ビジネス・ルールに基づいて条件付きで行う方法と、無条件で行う方法があります。
これには、複数の表がターゲットとなっている場合に、INSERT ... SELECT文を使用できるというメリットがあります。これにより、2つの別の方法でのデメリットを回避できます。従来は、n個の独立したINSERT … SELECT文を取り扱う必要があり、同じソース・データをn回処理するため、変換による作業負荷もn倍になっていました。または、プロシージャによるアプローチを選択し、挿入の処理方法を行ごとに判断する必要がありました。このソリューションには、SQLで使用可能な高速のアクセス・パスへのダイレクト・アクセスが欠けています。
既存の文を使用する場合と同様に、新しいINSERT ... SELECT文も、パラレル化してダイレクト・ロード機能とともに使用することでパフォーマンスを改善できます。
例15-2 無条件の挿入
次の文では、sales_activity_directに格納されているトランザクションの売上情報が日次で集計され、今日のsalesおよびcostsファクト表に挿入されます。
INSERT ALL
INTO sales VALUES (product_id, customer_id, today, 3, promotion_id,
quantity_per_day, amount_per_day)
INTO costs VALUES (product_id, today, promotion_id, 3,
product_cost, product_price)
SELECT TRUNC(s.sales_date) AS today, s.product_id, s.customer_id,
s.promotion_id, SUM(s.amount) AS amount_per_day, SUM(s.quantity)
quantity_per_day, p.prod_min_price*0.8 AS product_cost, p.prod_list_price
AS product_price
FROM sales_activity_direct s, products p
WHERE s.product_id = p.prod_id AND TRUNC(sales_date) = TRUNC(SYSDATE)
GROUP BY TRUNC(sales_date), s.product_id, s.customer_id, s.promotion_id,
p.prod_min_price*0.8, p.prod_list_price;
例15-3 条件付きのALL挿入
次の文では、有効な宣伝を伴うすべての売上トランザクションについて、salesおよびcosts表に1行が挿入され、ある顧客による複数の同一注文に関する情報が別の表cum_sales_activityに格納されます。売上トランザクションには、2行を挿入できるものと、まったく挿入できないものがあります。
INSERT ALL
WHEN promotion_id IN (SELECT promo_id FROM promotions) THEN
INTO sales VALUES (product_id, customer_id, today, 3, promotion_id,
quantity_per_day, amount_per_day)
INTO costs VALUES (product_id, today, promotion_id, 3,
product_cost, product_price)
WHEN num_of_orders > 1 THEN
INTO cum_sales_activity VALUES (today, product_id, customer_id,
promotion_id, quantity_per_day, amount_per_day, num_of_orders)
SELECT TRUNC(s.sales_date) AS today, s.product_id, s.customer_id,
s.promotion_id, SUM(s.amount) AS amount_per_day, SUM(s.quantity)
quantity_per_day, COUNT(*) num_of_orders, p.prod_min_price*0.8
AS product_cost, p.prod_list_price AS product_price
FROM sales_activity_direct s, products p
WHERE s.product_id = p.prod_id
AND TRUNC(sales_date) = TRUNC(SYSDATE)
GROUP BY TRUNC(sales_date), s.product_id, s.customer_id,
s.promotion_id, p.prod_min_price*0.8, p.prod_list_price;
例15-4 条件付きのFIRST挿入
次の文では、製品注文の合計数量と重量に従って、適切な出荷リストに挿入されます。例外は大量注文の場合で、重量区分が大きすぎないかぎり急送されます。数量のない注文として表されているこの単純な例では、すべての不適切な注文は別の表に格納されます。ここでは、適切な表large_freight_shipping、express_shipping、default_shippingおよびincorrect_sales_orderが存在するものとします。
INSERT FIRST WHEN (sum_quantity_sold > 10 AND prod_weight_class < 5) AND
sum_quantity_sold >=1) OR (sum_quantity_sold > 5 AND prod_weight_class > 5) THEN
INTO large_freight_shipping VALUES
(time_id, cust_id, prod_id, prod_weight_class, sum_quantity_sold)
WHEN sum_amount_sold > 1000 AND sum_quantity_sold >=1 THEN
INTO express_shipping VALUES
(time_id, cust_id, prod_id, prod_weight_class,
sum_amount_sold, sum_quantity_sold)
WHEN (sum_quantity_sold >=1) THEN INTO default_shipping VALUES
(time_id, cust_id, prod_id, sum_quantity_sold)
ELSE INTO incorrect_sales_order VALUES (time_id, cust_id, prod_id)
SELECT s.time_id, s.cust_id, s.prod_id, p.prod_weight_class,
SUM(amount_sold) AS sum_amount_sold,
SUM(quantity_sold) AS sum_quantity_sold
FROM sales s, products p
WHERE s.prod_id = p.prod_id AND s.time_id = TRUNC(SYSDATE)
GROUP BY s.time_id, s.cust_id, s.prod_id, p.prod_weight_class;
例15-5 条件付き挿入と無条件の挿入の混在型
次の例では、新規顧客がcustomers表に挿入され、cust_credit_limitが4501以上のすべての新規顧客がさらなる販促対象として別個の表に格納されます。
INSERT FIRST WHEN cust_credit_limit >= 4500 THEN INTO customers INTO customers_special VALUES (cust_id, cust_credit_limit) ELSE INTO customers SELECT * FROM customers_new;
データ・ウェアハウス環境では、PL/SQLなどの手続き型言語を使用して、複雑な変換をOracle Databaseで実装できます。CTASが表全体を操作し、パラレル化を強調するのに対して、PL/SQLでは、行ベースの方法で、非常に高度な変換規則に対応できます。たとえば、PL/SQLプロシージャを使用して、複数のカーソルをオープンして複数のソース表からデータを読み取り、複雑なビジネス・ルールを使用してこのデータを結合できます。これによって、変換されたデータを1つ以上のターゲット表に挿入できます。標準SQL文を使用して、同じ手順の操作を表現するのは困難または不可能です。
手続き型言語を使用すると、複雑なETL処理内で特定の変換(または多数の変換ステップ)をカプセル化し、中間のステージング・エリアからデータを読み取り、出力として新しい表オブジェクトを生成できます。以前に生成された変換の入力表と後続の変換には、この特定の変換により生成される表が使用されます。また、ETLプロセス全体でこのようにカプセル化された変換ステップをシームレスに統合できるため、相互の行セットがストリーム化され、中間的なステージングが不要になります。テーブル・ファンクションを使用すると、このような動作を実装できます。
テーブル・ファンクションにより、PL/SQL、CまたはJavaで実装された変換のパイプライン実行またはパラレル実行がサポートされます。前述のシナリオは、中間的なステージング表を使用せずに実行でき、各種変換ステップでのデータ・フローは中断されません。
テーブル・ファンクションは、出力として行セットを生成できる関数として定義されます。また、テーブル・ファンクションは入力として行セットを使用できます。Oracle9iまでのPL/SQLファンクションには、次のようなデメリットがありました。
入力としてカーソルを使用できません。
パラレル化またはパイプライン化できません。
現在、ファンクションにこのような制限はありません。テーブル・ファンクションでは、次のことができるため、データベース機能が拡張されます。
1つの関数から複数行を戻すことができます。
SQL副問合せ(複数行の選択)の結果を関数に直接渡すことができます。
関数に入力としてカーソルを使用できます。
関数をパラレル化できます。
結果セットが作成されるとすぐに次の処理に段階的に渡します。これは段階的パイプライン処理と呼ばれます。
テーブル・ファンクションは、ネイティブなPL/SQLインタフェースを使用してPL/SQLで定義するか、Oracle Data Cartridge Interface(ODCI)を使用してJavaまたはCで定義できます。
|
関連項目:
|
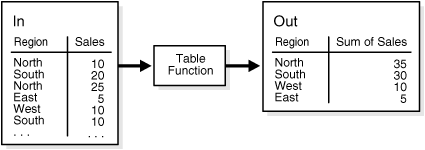
行セットを入力してSUM操作の実行後に行セットを出力する典型的な集計を、図15-3に示します。
この操作のための疑似コードは次のようになります。
INSERT INTO Out SELECT * FROM ("Table Function"(SELECT * FROM In));
このテーブル・ファンクションは、InでのSELECTの結果を入力として使用し、レコード・セットを異なるフォーマットでダイレクト挿入用の出力としてOutに渡します。
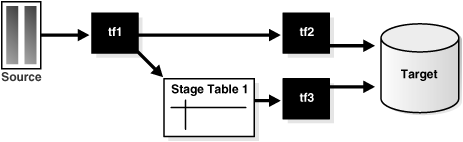
また、テーブル・ファンクションでは、データをアトミック・トランザクションの適用範囲内で分岐させることができます。これは、効率的なロギング・メカニズムや、他の独立した変換の分岐など、様々な場合に使用できます。このような使用例では、単一のステージング表が必要です。
このための疑似コードは次のようになります。
INSERT INTO target SELECT * FROM (tf2(SELECT * FROM (tf1(SELECT * FROM source))));
この場合は、targetに挿入され、アトミック・トランザクションの適用範囲内でtf1の一部としてStage Table 1にも挿入されます。
INSERT INTO target SELECT * FROM tf3(SELT * FROM stage_table1);
例15-6 テーブル・ファンクションの基本
次の例は、テーブル・ファンクションの基本を示しており、これらの関数内に実装された複雑なビジネス・ルールは使用されていません。あくまでも具体例を示すことが目的であり、すべてPL/SQLで実装されています。
テーブル・ファンクションはレコード・セットを戻し、入力としてカーソルを使用できます。この例を使用する前に、shサンプル・スキーマの他に次のデータベース・オブジェクトを設定する必要があります。
CREATE TYPE product_t AS OBJECT (
prod_id NUMBER(6)
, prod_name VARCHAR2(50)
, prod_desc VARCHAR2(4000)
, prod_subcategory VARCHAR2(50)
, prod_subcategory_desc VARCHAR2(2000)
, prod_category VARCHAR2(50)
, prod_category_desc VARCHAR2(2000)
, prod_weight_class NUMBER(2)
, prod_unit_of_measure VARCHAR2(20)
, prod_pack_size VARCHAR2(30)
, supplier_id NUMBER(6)
, prod_status VARCHAR2(20)
, prod_list_price NUMBER(8,2)
, prod_min_price NUMBER(8,2)
);
/
CREATE TYPE product_t_table AS TABLE OF product_t;
/
COMMIT;
CREATE OR REPLACE PACKAGE cursor_PKG AS
TYPE product_t_rec IS RECORD (
prod_id NUMBER(6)
, prod_name VARCHAR2(50)
, prod_desc VARCHAR2(4000)
, prod_subcategory VARCHAR2(50)
, prod_subcategory_desc VARCHAR2(2000)
, prod_category VARCHAR2(50)
, prod_category_desc VARCHAR2(2000)
, prod_weight_class NUMBER(2)
, prod_unit_of_measure VARCHAR2(20)
, prod_pack_size VARCHAR2(30)
, supplier_id NUMBER(6)
, prod_status VARCHAR2(20)
, prod_list_price NUMBER(8,2)
, prod_min_price NUMBER(8,2));
TYPE product_t_rectab IS TABLE OF product_t_rec;
TYPE strong_refcur_t IS REF CURSOR RETURN product_t_rec;
TYPE refcur_t IS REF CURSOR;
END;
/
REM artificial help table, used later
CREATE TABLE obsolete_products_errors (prod_id NUMBER, msg VARCHAR2(2000));
次の例は、prod_category Electronicsを除くすべての廃止製品を表示する単純なフィルタ処理です。このテーブル・ファンクションは、結果セットとしてレコード・セットを戻し、入力として弱い型指定を持つREF CURSORを使用しています。
CREATE OR REPLACE FUNCTION obsolete_products(cur cursor_pkg.refcur_t)
RETURN product_t_table
IS
prod_id NUMBER(6);
prod_name VARCHAR2(50);
prod_desc VARCHAR2(4000);
prod_subcategory VARCHAR2(50);
prod_subcategory_desc VARCHAR2(2000);
prod_category VARCHAR2(50);
prod_category_desc VARCHAR2(2000);
prod_weight_class NUMBER(2);
prod_unit_of_measure VARCHAR2(20);
prod_pack_size VARCHAR2(30);
supplier_id NUMBER(6);
prod_status VARCHAR2(20);
prod_list_price NUMBER(8,2);
prod_min_price NUMBER(8,2);
sales NUMBER:=0;
objset product_t_table := product_t_table();
i NUMBER := 0;
BEGIN
LOOP
-- Fetch from cursor variable
FETCH cur INTO prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class,
prod_unit_of_measure, prod_pack_size, supplier_id, prod_status,
prod_list_price, prod_min_price;
EXIT WHEN cur%NOTFOUND; -- exit when last row is fetched
-- Category Electronics is not meant to be obsolete and will be suppressed
IF prod_status='obsolete' AND prod_category != 'Electronics' THEN
-- append to collection
i:=i+1;
objset.extend;
objset(i):=product_t( prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc,
prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id,
prod_status, prod_list_price, prod_min_price);
END IF;
END LOOP;
CLOSE cur;
RETURN objset;
END;
/
このテーブル・ファンクションをSQL文に使用すると、次の結果が表示されます。ここでは、出力用にSQLの機能を追加使用しています。
SELECT DISTINCT UPPER(prod_category), prod_status
FROM TABLE(obsolete_products(
CURSOR(SELECT prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class,
prod_unit_of_measure, prod_pack_size,
supplier_id, prod_status, prod_list_price, prod_min_price
FROM products)));
次の例では、前述の例と同じフィルタ処理を実装しています。両者の主な違いは、次のとおりです。
この例では、強い型指定を持つREF CURSORを入力として使用しており、次に示す例の1つのように、そのカーソルのオブジェクトに基づいてパラレル化できます。
テーブル・ファンクションは、レコードの作成直後に段階的に結果セットを戻します。
CREATE OR REPLACE FUNCTION
obsolete_products_pipe(cur cursor_pkg.strong_refcur_t) RETURN product_t_table
PIPELINED
PARALLEL_ENABLE (PARTITION cur BY ANY) IS
prod_id NUMBER(6);
prod_name VARCHAR2(50);
prod_desc VARCHAR2(4000);
prod_subcategory VARCHAR2(50);
prod_subcategory_desc VARCHAR2(2000);
prod_category VARCHAR2(50);
prod_category_desc VARCHAR2(2000);
prod_weight_class NUMBER(2);
prod_unit_of_measure VARCHAR2(20);
prod_pack_size VARCHAR2(30);
supplier_id NUMBER(6);
prod_status VARCHAR2(20);
prod_list_price NUMBER(8,2);
prod_min_price NUMBER(8,2);
sales NUMBER:=0;
BEGIN
LOOP
-- Fetch from cursor variable
FETCH cur INTO prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc,
prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id,
prod_status, prod_list_price, prod_min_price;
EXIT WHEN cur%NOTFOUND; -- exit when last row is fetched
IF prod_status='obsolete' AND prod_category !='Electronics' THEN
PIPE ROW (product_t( prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class,
prod_unit_of_measure, prod_pack_size, supplier_id, prod_status,
prod_list_price, prod_min_price));
END IF;
END LOOP;
CLOSE cur;
RETURN;
END;
/
次のようなテーブル・ファンクションを使用できます。
SELECT DISTINCT prod_category,
DECODE(prod_status,'obsolete','NO LONGER AVAILABLE','N/A')
FROM TABLE(obsolete_products_pipe(
CURSOR(SELECT prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc,
prod_weight_class, prod_unit_of_measure, prod_pack_size,
supplier_id, prod_status, prod_list_price, prod_min_price
FROM products)));
ここで、入力表productsの並列度を変更し、再度同じ文を発行します。
ALTER TABLE products PARALLEL 4;
セッション統計は、文がパラレル化されていることを示します。
SELECT * FROM V$PQ_SESSTAT WHERE statistic='Queries Parallelized'; STATISTIC LAST_QUERY SESSION_TOTAL -------------------- ---------- ------------- Queries Parallelized 1 3 1 row selected.
テーブル・ファンクションでは、結果を永続表の構造に分岐させることもできます。これを次の例に示します。誤ってステータスobsoleteに設定されている特定のprod_category(デフォルトはElectronics)の製品を除き、それ以外のすべての廃止製品が関数のフィルタにより戻されます。テーブル・ファンクションの結果セットは、他のすべての廃止製品カテゴリで構成されます。検出された間違ったprod_idは、別個の表構造obsolete_products_errorに格納されます。テーブル・ファンクションが自律型トランザクションの一部である場合、サブプログラム呼出しでのエラーを回避するために、各PIPE ROW文の前にCOMMITまたはROLLBACKを実行する必要があることに注意してください。その結果セットは、他のすべての廃止製品カテゴリで構成されます。さらに、通常の変数をテーブル・ファンクションとともに使用する方法を示します。
CREATE OR REPLACE FUNCTION obsolete_products_dml(cur cursor_pkg.strong_refcur_t,
prod_cat varchar2 DEFAULT 'Electronics') RETURN product_t_table
PIPELINED
PARALLEL_ENABLE (PARTITION cur BY ANY) IS
PRAGMA AUTONOMOUS_TRANSACTION;
prod_id NUMBER(6);
prod_name VARCHAR2(50);
prod_desc VARCHAR2(4000);
prod_subcategory VARCHAR2(50);
prod_subcategory_desc VARCHAR2(2000);
prod_category VARCHAR2(50);
prod_category_desc VARCHAR2(2000);
prod_weight_class NUMBER(2);
prod_unit_of_measure VARCHAR2(20);
prod_pack_size VARCHAR2(30);
supplier_id NUMBER(6);
prod_status VARCHAR2(20);
prod_list_price NUMBER(8,2);
prod_min_price NUMBER(8,2);
sales NUMBER:=0;
BEGIN
LOOP
-- Fetch from cursor variable
FETCH cur INTO prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class,
prod_unit_of_measure, prod_pack_size, supplier_id, prod_status,
prod_list_price, prod_min_price;
EXIT WHEN cur%NOTFOUND; -- exit when last row is fetched
IF prod_status='obsolete' THEN
IF prod_category=prod_cat THEN
INSERT INTO obsolete_products_errors VALUES
(prod_id, 'correction: category '||UPPER(prod_cat)||' still
available');
COMMIT;
ELSE
PIPE ROW (product_t( prod_id, prod_name, prod_desc, prod_subcategory,
prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class,
prod_unit_of_measure, prod_pack_size, supplier_id, prod_status,
prod_list_price, prod_min_price));
END IF;
END IF;
END LOOP;
CLOSE cur;
RETURN;
END;
/
次の問合せでは、誤ってステータスobsoleteに設定されているprod_category Electronicsを除き、すべての廃止製品グループが示されます。
SELECT DISTINCT prod_category, prod_status FROM TABLE(obsolete_products_dml( CURSOR(SELECT prod_id, prod_name, prod_desc, prod_subcategory, prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_price FROM products)));
このように、prod_category Electronicsには、誤って廃止された製品があります。
SELECT DISTINCT msg FROM obsolete_products_errors;
2番目の入力変数を利用すると、Electronics以外の対象となる別の製品グループを指定できます。
SELECT DISTINCT prod_category, prod_status FROM TABLE(obsolete_products_dml( CURSOR(SELECT prod_id, prod_name, prod_desc, prod_subcategory, prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_price FROM products),'Photo'));
テーブル・ファンクションは通常の表と同様に使用できるため、次のようにネストできます。
SELECT DISTINCT prod_category, prod_status FROM TABLE(obsolete_products_dml(CURSOR(SELECT * FROM TABLE(obsolete_products_pipe(CURSOR(SELECT prod_id, prod_name, prod_desc, prod_subcategory, prod_subcategory_desc, prod_category, prod_category_desc, prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_price FROM products))))));
Oracle DatabaseのETLの最大のメリットはツールキット機能です。この機能を後述の機能と組み合せると、ETL処理を改善してスピードアップできます。たとえば、入力として外部表を使用し、それを既存の表と結合し、パラレル化されたテーブル・ファンクションの入力に使用して、複雑なビジネス・ロジックを処理できます。このテーブル・ファンクションはMERGE操作の入力ソースとして使用できるため、フラット・ファイルとして提供されたデータ・ウェアハウス用の新規情報をストリーム化し、ETLプロセスを通じて単一の文中で処理できます。
テーブル・ファンクションおよびPL/SQLプログラミングの詳細は、『Oracle Database PL/SQL言語リファレンス』を参照してください。その他の言語で実装されるテーブル・ファンクションの詳細は、『Oracle Databaseデータ・カートリッジ開発者ガイド』を参照してください。
外部ソースなど、特に様々なソースからのデータを処理する場合、データをロードおよび変換する際に、制約に従っていないデータに遭遇する場合がよくあります。この不適切なデータによって、長時間のロードや変換の操作が中断させられると、多くの時間とリソースが無駄になります。以降の項では、エラーの2つの主な原因とその対処方法について説明します。
論理的に制約に従っていないデータは、データを使用する前に認識されているビジネス・ルールに違反します。ほとんどの場合、この種のエラー処理は、ロードまたは変換プロセスに組み込まれます。ただし、すべてのレコードに対するエラー識別にかかるコストが膨大となり、かつデータ・ルール違反であってもビジネス・ルールが適用される可能性があるような状況(数百の列をテストして、それらがNOT NULLかどうかを確認するなど)では、プログラマは多くの場合、既知の論理エラーの場合でも一般的に処理する方を選択します。この例は、「データ・エラーのシナリオ」に示しています。
論理的なルールの組込みは、簡単な場合(データの入力ストリームに対してフィルタ条件を適用するなど)もあれば、複雑な場合(不適切なデータを異なる変換ワークフローに送り込むなど)もあります。次に、例をいくつか示します。
SQLを使用した論理データ・エラーのフィルタ処理。特定の条件を満たさないデータを、処理する前にフィルタにかけて除外します。
論理データ・エラーの識別と選別。これは、複雑なケースでは、例15-6「テーブル・ファンクションの基本」に示すようにプロシージャによるアプローチで、単純なケースでは、例15-1「SQLを使用したマージ操作」に示すようにSQLを使用して行うことができます。
論理エラーと異なり、データ・ルールの違反は、ロード・プロセスや変換プロセスでは通常想定していません。操作では処理されないこのような想定外のデータ・ルールの違反(データ・エラー)によって、処理は失敗します。データ・ルールの違反は、データベース内で発生し、文を失敗させるエラー状況です。この例として、データ型の変換エラーや制約違反があります。
かつてのSQLでは、大量処理の一部として行レベルでデータ・エラーを処理する方法がありませんでした。データベース内のデータ・エラーを処理する唯一の手段は、PL/SQLを使用することでした。現在では、DML操作の続行中でもデータ・エラーのログを特別なエラー表に記録できるようになりました。
以降の項では、PL/SQLおよびDMLエラー・ロギング表を使用した例外処理について簡単に説明します。
次の文は、PL/SQLを使用してエラー処理を行う方法の例を示しています。ここでは、すべてのエラーを捕捉するために、プロシージャによるレコードレベルの処理を使用する必要があります。この文は、「エラー・ロギング表を使用したデータ・エラーの処理」で説明している文とほぼ同じです。
DECLARE
errm number default 0;
BEGIN
FOR crec IN (SELECT product_id, customer_id, TRUNC(sales_date) sd,
promotion_id, quantity, amount
FROM sales_activity_direct) loop
BEGIN
INSERT INTO sales VALUES (crec.product_id, crec.customer_id,
crec.sd, 3, crec.promotion_id,
crec.quantity, crec.amount);
exception
WHEN others then
errm := sqlerrm;
INSERT INTO sales_activity_error
VALUES (errm, crec.product_id, crec.customer_id, crec.sd,
crec.promotion_id, crec.quantity, crec.amount);
END;
END loop;
END;
/
DMLエラー・ロギングによって既存のDML機能が拡張され、ユーザーがエラー・ロギング表の名前を指定すると、DML操作中に検出されたエラーがOracle Databaseによってその表に記録されるようになりました。これにより、どのようなエラーが検出されてもDML操作を完了でき、後でエラーのある行において対処措置をとることができます。
このDMLエラー・ロギング表は、ターゲット列に起こり得るエラーを格納可能なデータ型を使用した、DML操作のターゲット表の列のすべてまたはサブセットを表すユーザー定義の列のセット、およびいくつかの必須の制御列から構成されています。たとえば、ターゲット表のNUMBER列のTO_NUMデータ型変換エラーを格納するには、エラー・ロギング表にVARCHAR2データ型が必要となります。DMLエラー・ロギング表を作成するには、DBMS_ERRLOGパッケージを使用する必要があります。このパッケージおよびロギング表の構造の詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
DMLターゲット表とエラー・ロギング表の間の列名のマッピングによって、制御列以外のどの列がDML操作でロギングされるかが決まります。
次の文は、DMLエラー・ロギングによって「SQLを使用したデータの変換」の例を強化する方法を示します。
INSERT /*+ APPEND PARALLEL */
INTO sales SELECT product_id, customer_id, TRUNC(sales_date), 3,
promotion_id, quantity, amount
FROM sales_activity_direct
LOG ERRORS INTO sales_activity_errors('load_20040802')
REJECT LIMIT UNLIMITED
すべてのデータ・エラーのログが、オプションのタグload_20040802で識別される表sales_activity_errorsに記録されます。このINSERT文は、データ・エラーが存在する場合でも成功します。この文を使用する前にDMLエラー・ロギング表を作成しておく必要がある点に注意してください。
REJECT LIMIT Xを指定していた場合、この文は失敗し、エラー・メッセージ「エラーX=1」が示されます。このエラー・メッセージは、拒否制限(REJECT LIMIT)によって異なる場合があります。文が失敗した場合、DML文のみがロールバックされ、DMLエラー・ロギング表への挿入操作はロールバックされません。エラー・ロギング表には、X+1個の行が含まれます。
DMLエラー・ロギング表は、実行ユーザーとは異なるスキーマに配置できますが、その場合、表の完全な名前を指定する必要があります。状況に応じてDMLエラー・ロギング表の名前を省略することもできます。その場合、DBMS_ERRLOGパッケージによって生成される表のデフォルト名が使用されます。
次に、DML操作中にログに書き込まれるエラーを示します。
大きすぎる列値
制約違反(NOT NULL制約、一意制約、参照制約およびチェック制約)
トリガー実行中に発生したエラー
副問合せの列と表の対応列との間の型変換で発生したエラー
パーティション・マッピング・エラー
次の条件下ではエラー・ロギング機能が機能せず、文は失敗してロールバックします。
遅延制約の違反
領域不足エラー
一意制約や索引の違反を招くすべてのINSERT操作(INSERTまたはMERGE)
一意制約や索引の違反を招くすべてのUPDATE操作(UPDATEまたはMERGE)
また、LONG、LOBまたはオブジェクト型の列については、エラー・ロギング表においてエラーを追跡できません。エラー・ロギングを使用する際の制約の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
DMLエラー・ロギングは、あらゆる種類のDML操作に適用できます。次の項では、これらの例について説明します。
外部ロード・ユーティリティとしてのSQL*Loaderにも、データ・エラーのロギング機能がありますが、データベース内部に統合されたETL処理のメリットがありません。
典型的な変換として、キー参照があります。たとえば、売上トランザクション・データが小売データ・ウェアハウスにロードされているとします。データ・ウェアハウスのsales表にはproduct_id列がありますが、ソース・システムから抽出された売上トランザクション・データには、製品IDではなくUPCコード(Uniform Price Codes)があります。そのため、新しい売上トランザクション・データをsales表に挿入できるようにするには、最初にUPCコードを製品IDに変換する必要があります。
この変換を実行するには、product_id値をUPCコードに関係付ける参照表が必要です。この表は、productディメンション表か、またはこの変換をサポートするために特別に作成された、データ・ウェアハウスにある別の表です。この例では、product_id列およびupc_code列を持つ、productという表があると想定しています。
このデータ置換による変換は、次のCTAS文を使用して実装できます。
CREATE TABLE temp_sales_step2 NOLOGGING PARALLEL AS SELECT sales_transaction_id, product.product_id sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount FROM temp_sales_step1, product WHERE temp_sales_step1.upc_code = product.upc_code;
このCTAS文は、有効な各UPCコードを、有効なproduct_id値に変換します。各UPCコードが有効であることをETLプロセスが保証している場合は、この文のみで変換全体を実装できます。
前述の例で、有効なUPCコードが付いていない新規の売上データ(論理データ・エラー)も処理する必要がある場合は、次のようにCTAS文を追加使用して無効な行を識別できます。
CREATE TABLE temp_sales_step1_invalid NOLOGGING PARALLEL AS SELECT * FROM temp_sales_step1 s WHERE NOT EXISTS (SELECT 1 FROM product p WHERE p.upc_code=s.upc_code);
無効なデータは別の表temp_sales_step1_invalidに格納され、ETLプロセスで別々に処理できます。
無効なデータを処理する別の方法として、次の文に示すように、元のCTASを変更して外部結合を使用します。
CREATE TABLE temp_sales_step2 NOLOGGING PARALLEL AS SELECT sales_transaction_id, product.product_id sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount FROM temp_sales_step1, product WHERE temp_sales_step1.upc_code = product.upc_code (+);
外部結合を使用すると、無効なUPCコードを含んでいた売上トランザクションに、NULLのproduct_idが割り当てられます。これらのトランザクションは後で処理できます。または、NULLのproduct_idで値を別の表に分離するマルチテーブル・インサートも使用できます。これは、予想されたエラー数がデータ全体の量と比較して相対的に少ないときに有効なアプローチとなる場合があります。後続の処理では、大きなターゲット表を扱う必要がなくなり、小さな表のみを扱うことになります。
INSERT /*+ APPEND PARALLEL */ FIRST WHEN sales_product_id IS NOT NULL THEN INTO temp_sales_step2 VALUES (sales_transaction_id, sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount) ELSE INTO temp_sales_step1_invalid VALUES (sales_transaction_id, sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount) SELECT sales_transaction_id, product.product_id sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount FROM temp_sales_step1, product WHERE temp_sales_step1.upc_code = product.upc_code (+);
このソリューションでは、空の表temp_sales_step2およびtemp_sales_step1_invalidがあらかじめ存在している必要がある点に注意してください。
無効なUPCコードを処理するには、他にも方法があります。あるデータ・ウェアハウスではNULL値のproduct_idをsales表に挿入するように選択されます。また、無効なUPCコードがすべて処理されるまで、バッチ全体のどの新規データもsales表に挿入できないデータ・ウェアハウスもあります。どの方法が適切かは、データ・ウェアハウスのビジネス要件によって決まります。特定の要件に関係なく、例外処理は、変換と同じく基本的なSQLによって処理されます。
データの質が不明の場合、前述の項で示した例を、次に示すように想定外のデータ・エラー(データ型の変換エラーなど)を処理するように強化できます。
INSERT /*+ APPEND PARALLEL */ FIRST
WHEN sales_product_id IS NOT NULL THEN
INTO temp_sales_step2
VALUES (sales_transaction_id, sales_product_id,
sales_customer_id, sales_time_id, sales_channel_id,
sales_quantity_sold, sales_dollar_amount)
LOG ERRORS INTO sales_step2_errors('load_20040804')
REJECT LIMIT UNLIMITED
ELSE
INTO temp_sales_step1_invalid
VALUES (sales_transaction_id, sales_product_id,
sales_customer_id, sales_time_id, sales_channel_id,
sales_quantity_sold, sales_dollar_amount)
LOG ERRORS INTO sales_step2_errors('load_20040804')
REJECT LIMIT UNLIMITED
SELECT sales_transaction_id, product.product_id sales_product_id,
sales_customer_id, sales_time_id, sales_channel_id,
sales_quantity_sold, sales_dollar_amount
FROM temp_sales_step1, product
WHERE temp_sales_step1.upc_code = product.upc_code (+);
この文は、表temp_sales_step1_invalidに有効な製品UPCコードが存在しないという論理データ・エラー、およびsales_step2_errorsという名前のDMLエラー・ロギング表において可能性のあるその他のすべてのエラーを追跡します。エラー・ロギング表は、複数のDML操作で使用できます。
または、NOT NULL制約を使用して、データベース・レベルで有効なUPCコードが存在するというビジネス・ルールを実施する方法もあります。外部結合を使用すると、有効なUPCコードを持たないすべての注文はNULL値にマップされ、データ・エラーとして扱われます。次の文では、これらのエラーを追跡するために、このDMLエラー・ロギング機能が使用されています。
INSERT /*+ APPEND PARALLEL */
INTO temp_sales_step2
VALUES (sales_transaction_id, sales_product_id,
sales_customer_id, sales_time_id, sales_channel_id,
sales_quantity_sold, sales_dollar_amount)
SELECT sales_transaction_id, product.product_id sales_product_id,
sales_customer_id, sales_time_id, sales_channel_id,
sales_quantity_sold, sales_dollar_amount
FROM temp_sales_step1, product
WHERE temp_sales_step1.upc_code = product.upc_code (+)
LOG ERRORS INTO sales_step2_errors('load_20040804')
REJECT LIMIT UNLIMITED;
エラー・ロギング表には、DML操作の失敗の原因となったすべてのレコードが格納されます。この内容を利用して、あらゆるエラーを分析および修正できます。エラー・ロギング表の内容は、DML操作自体が成功したかどうかに関わりなく、すべてのDML操作に対して保持されます。拒否制限(REJECT LIMIT)に達したため、次のSQL文が失敗したものと仮定します。
SQL> INSERT /*+ APPEND NOLOGGING PARALLEL */ INTO sales_overall
2 SELECT * FROM sales_activity_direct
3 LOG ERRORS INTO err$_sales_overall ('load_test2')
4 REJECT LIMIT 10;
SELECT * FROM sales_activity_direct
*
ERROR at line 2:
ORA-01722: invalid number
エラー・ロギング表の名前err$_sales_overallは、DBMS_ERRLOGパッケージを使用して導出されたデフォルトの名前です。詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
生成されたエラー・メッセージは、最初のエラー制限に達した後で発生しています。次のエラー(番号11)は、エラーを生じさせたものです。表示されているエラー・メッセージは、制限を超過したエラーを基準としているため、たとえば、9番目のエラーは、11番目のエラーとは異なる場合があります。
ターゲット表sales_overallには入力されているレコードがありません(空の表だったと考えられる)が、エラー・ロギング表には、11個(REJECT LIMIT + 1)の行が含まれます。
SQL> SELECT COUNT(*) FROM sales_overall; COUNT(*) ---------- 0 SQL> SELECT COUNT(*) FROM err$_sales_overall; COUNT(*) ---------- 11
DMLエラー・ロギング表は、すべてのエラー・ロギング表に必須であるいくつかの固定の制御列で構成されます。Oracleエラー番号の他に、エラー・メッセージも格納されます。多くの場合、エラー・メッセージにより、データ・エラーの根本的原因を分析および解決するための詳細な情報が示されます。次のDMLエラー・ロギング表のSQL出力は、この違いを示しています。2番目の出力には、NOT NULL違反によって拒否された行の追加情報が含まれています。
SQL> SELECT DISTINCT ora_err_number$ FROM err$_sales_overall;
ORA_ERR_NUMBER$
---------------
1400
1722
1830
1847
SQL> SELECT DISTINCT ora_err_number$, ora_err_mesg$ FROM err$_sales_overall;
ORA_ERR_NUMBER$ ORA_ERR_MESG$
1400 ORA-01400: cannot insert NULL into
("SH"."SALES_OVERALL"."CUST_ID")
1400 ORA-01400: cannot insert NULL into
("SH"."SALES_OVERALL"."PROD_ID")
1722 ORA-01722: invalid number
1830 ORA-01830: date format picture ends before
converting entire input string
1847 ORA-01847: day of month must be between 1 and last
day of month
制御列の詳細は、『Oracle Database管理者ガイド』を参照してください。
データ・ウェアハウスは、多数の異なるソースからデータを受け取ることができます。これらのソース・システムには、リレーショナル・データベースではないものもあり、データ・ウェアハウスとは大きく異なるフォーマットでデータが格納されている場合があります。たとえば、売上レコードの集合を、次のフォームの非リレーショナル・データベースから受け取ったとします。
product_id, customer_id, weekly_start_date, sales_sun, sales_mon, sales_tue, sales_wed, sales_thu, sales_fri, sales_sat
入力表は次のようになります。
SELECT * FROM sales_input_table;
PRODUCT_ID CUSTOMER_ID WEEKLY_ST SALES_SUN SALES_MON SALES_TUE SALES_WED SALES_THU SALES_FRI SALES_SAT
---------- ----------- --------- ---------- ---------- ---------- -------------------- ---------- ----------
111 222 01-OCT-00 100 200 300 400 500 600 700
222 333 08-OCT-00 200 300 400 500 600 700 800
333 444 15-OCT-00 300 400 500 600 700 800 900
データ・ウェアハウスでは、次のような一般的なリレーショナル形式でshサンプル・スキーマのファクト表salesにこれらのレコードを格納します。
prod_id, cust_id, time_id, amount_sold
|
注意: この例では、簡潔にするために表の多数の列を無視しているため、sales表の多数の制約が使用禁止になっています。 |
これには、入力ストリームの各レコードが、データ・ウェアハウスのsales表の7つのレコードに変換されるように変換処理を作成する必要があります。通常、この操作はピボットと呼ばれ、Oracle Databaseでは複数の方法でこの操作を行えます。
前述の例の結果は、次のようになります。
SELECT prod_id, cust_id, time_id, amount_sold FROM sales;
PROD_ID CUST_ID TIME_ID AMOUNT_SOLD
---------- ---------- --------- -----------
111 222 01-OCT-00 100
111 222 02-OCT-00 200
111 222 03-OCT-00 300
111 222 04-OCT-00 400
111 222 05-OCT-00 500
111 222 06-OCT-00 600
111 222 07-OCT-00 700
222 333 08-OCT-00 200
222 333 09-OCT-00 300
222 333 10-OCT-00 400
222 333 11-OCT-00 500
222 333 12-OCT-00 600
222 333 13-OCT-00 700
222 333 14-OCT-00 800
333 444 15-OCT-00 300
333 444 16-OCT-00 400
333 444 17-OCT-00 500
333 444 18-OCT-00 600
333 444 19-OCT-00 700
333 444 20-OCT-00 800
333 444 21-OCT-00 900
例15-7 ピボット
次の例では、マルチテーブル・インサート構文を使用して、デモ表sh.salesに異なる構造を持つ入力表からデータを挿入しています。マルチテーブルINSERT文は次のようになります。
INSERT ALL INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date, sales_sun)
INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date+1, sales_mon)
INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date+2, sales_tue)
INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date+3, sales_wed)
INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date+4, sales_thu)
INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date+5, sales_fri)
INTO sales (prod_id, cust_id, time_id, amount_sold)
VALUES (product_id, customer_id, weekly_start_date+6, sales_sat)
SELECT product_id, customer_id, weekly_start_date, sales_sun,
sales_mon, sales_tue, sales_wed, sales_thu, sales_fri, sales_sat
FROM sales_input_table;
この文では、ソース表が1回のみスキャンされ、毎日の適切なデータが挿入されます。