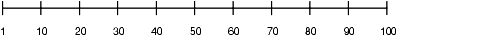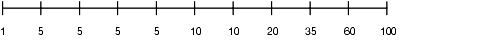| Oracle® Databaseパフォーマンス・チューニング・ガイド 11gリリース2 (11.2) B56312-06 |
|



 前 |
 次 |
この章では、問合せオプティマイザにとって統計が重要である理由、およびDBMS_STATSパッケージを使用したオプティマイザ統計の収集方法と使用方法を説明します。
この章には次の項があります。
オプティマイザ統計は、データベースおよびデータベース内のオブジェクトに関する詳細を表します。問合せオプティマイザは、これらの統計を使用して各SQL文に最適な実行計画を選択します。
オプティマイザ統計には次のものがあります。
表統計
行数
ブロック数
行の平均長さ
列統計情報
列内の個別値(NDV)数
列内のNULL数
データ配分(ヒストグラム)
拡張統計
索引統計
リーフ・ブロック数
レベル
クラスタ化係数
システム統計
I/Oパフォーマンスと使用率
CPUパフォーマンスと使用率
|
注意: オプティマイザ統計と、V$ビューで参照可能なパフォーマンス統計を混同しないでください。 |
オプティマイザ統計は、データ・ディクショナリに格納されます。これらの統計は、データ・ディクショナリ・ビューを使用してアクセスできます。
データベース内のオブジェクトは絶えず変化するため、オブジェクトを正確に表すには統計を定期的に更新する必要があります。Oracle Databaseでは、オプティマイザ統計は自動的に管理されます。
DBMS_STATSパッケージを使用して、オプティマイザ統計を手動で管理できます。たとえば、統計のコピーを保存し、リストアできます。データベースから統計をエクスポートし、別のデータベースにインポートできます。たとえば、本番システムからテスト・システムに統計をエクスポートできます。また、統計が変更されないようにロックすることもできます。
自動オプティマイザ統計収集は、有効にすることをお薦めします。有効な場合は、統計がないか失効している表のオプティマイザ統計を自動的に収集します。表に新規の統計が必要な場合は、表と、関連する索引の両方について統計が収集されます。
自動収集により、オプティマイザの管理に関連する多数の手動タスクが削減されます。また、統計の欠如または失効のために不適切な実行計画が生成されるリスクが大幅に減ります。
自動オプティマイザ統計収集は、DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROCプロシージャをコールします。この内部プロシージャの動作は、GATHER AUTOオプションを使用したDBMS_STATS.GATHER_DATABASE_STATSプロシージャに類似しています。主な違いは、GATHER_DATABASE_STATS_JOB_PROCでは、統計を必要とするデータベース・オブジェクトが優先され、メンテナンス・ウィンドウがクローズする前に、統計の更新を最も必要としているオブジェクトが最初に処理されます。
この項では、次の項目について説明します。
自動化メンテナンス・タスク・インフラストラクチャ(AutoTask)は、メンテナンス・ウィンドウと呼ばれるOracle Schedulerウィンドウで自動的に実行されるようにタスクをスケジュールします。デフォルトでは、1つのウィンドウが週の各曜日にスケジュールされます。自動オプティマイザ統計収集は、AutoTaskの一部として実行されます。デフォルトで有効になっており、事前定義されたすべてのメンテナンス・ウィンドウで実行されます。
なんらかの理由で自動オプティマイザ統計収集が無効な場合は、DBMS_AUTO_TASK_ADMINパッケージのENABLEプロシージャを使用してこの機能を有効にすることができます。
BEGIN
DBMS_AUTO_TASK_ADMIN.ENABLE(
client_name => 'auto optimizer stats collection'
, operation => NULL
, window_name => NULL
);
END;
/
自動オプティマイザ統計収集を無効化する場合、次のようにDBMS_AUTO_TASK_ADMINパッケージのDISABLEプロシージャを使用してこの機能を無効化できます。
BEGIN
DBMS_AUTO_TASK_ADMIN.DISABLE(
client_name => 'auto optimizer stats collection'
, operation => NULL
, window_name => NULL
);
END;
/
自動オプティマイザ統計収集は、「失効している統計の判別」で説明するように変更監視機能に依存します。この機能が無効な場合、自動オプティマイザ統計収集ジョブは、失効した統計を検出できません。この機能は、STATISTICS_LEVELパラメータがTYPICALまたはALLに設定されている場合に有効になります。デフォルト値はTYPICALです。
|
関連項目:
|
この項では、次の内容を説明します。
適度な速さで変更されるほとんどのデータベース・オブジェクトには、自動オプティマイザ統計収集で十分です。ただし、場合によっては、適切に収集できないことがあります。収集はメンテナンス・ウィンドウで実行されるため、1日を通して大幅に変更される表の統計は古くなる可能性があります。通常、この種のオブジェクトには次の2つのタイプがあります。
日中に削除または切り捨てられて再作成される変化しやすい表
オブジェクトの合計サイズの10%以上が追加される大規模バルク・ロードの対象となるオブジェクト
揮発性の高い表の場合は、次の2つのアプローチがあります。
これらの表では、統計をNULLに設定できます。Oracle Databaseでは、統計のない表が検出されると、問合せ最適化の一部として必要な統計を動的に収集します。OPTIMIZER_DYNAMIC_SAMPLINGパラメータは、この動的統計機能を制御します。このパラメータの値を2(デフォルト)以上に設定します。統計をNULLに設定するには、統計を削除した後、ロックします。
BEGIN
DBMS_STATS.DELETE_TABLE_STATS('OE','ORDERS');
DBMS_STATS.LOCK_TABLE_STATS('OE','ORDERS');
END;
/
動的統計レベルの設定方法については、「動的統計レベル」を参照してください。
この種の表の統計は、表の典型的な状態を表す値に設定できます。表に典型的な行数が含まれているときに、その表の統計を収集し、統計をロックする必要があります。
通常、この方法は自動オプティマイザ統計収集よりも効率的です。これは、夜間のバッチ・ウィンドウで表に関して生成された統計が、日中のワークロードに関して最も適切な統計であるとはかぎらないためです。
バルク・ロードの対象となる表では、ロード処理の直後に、統計収集プロシージャを実行します。可能であれば、バルク・ロードの実行と同じスクリプトまたはジョブの一部としてプロシージャを実行します。
データベースは次の方法で外部表の統計を収集できます。
GATHER_TABLE_STATSプロシージャ
GATHER_SCHEMA_STATSプロシージャ
GATHER_DATABASE_STATSプロシージャ
自動オプティマイザ統計収集処理
GATHER_TABLE_STATSを使用している場合は、外部表のサンプリングがサポートされていないため、ESTIMATE_PERCENTオプションをNULL、100、またはAUTO_SAMPLEに明示的に設定します。外部表に対するデータ操作は許可されないため、データベースで外部表の統計が失効としてマークされることはありません。たとえば基礎となるデータファイルが変更されたなどの理由で、外部表に新しい統計が必要な場合は、既存の統計を削除してから統計を再収集します。
STATISTICS_LEVELをBASICに設定して監視機能を無効にすると、自動オプティマイザ統計収集では失効している統計を検出できません。この場合、統計を手動で収集する必要があります。自動監視機能の詳細は、「失効している統計の判別」を参照してください。
システム統計は、手動で収集する必要のある別のタイプの統計です。データベースでは、これらの統計を自動的に収集しません。詳細は、「システム統計」を参照してください。
動的パフォーマンス表などの固定オブジェクトでは、GATHER_FIXED_OBJECTS_STATSプロシージャを使用して手動で統計を収集する必要があります。固定オブジェクトは、現在のデータベース・アクティビティを記録します。統計は、代表的なアクティビティがデータベースで行われているときに収集する必要があります。
ディクショナリ内で統計が変更されるたびに、後でリストアできるように前のバージョンの統計が自動的に保存されます。統計をリストアするには、DBMS_STATSパッケージのRESTOREプロシージャを使用します。詳細は、「前のバージョンの統計のリストア」を参照してください。
「手動統計を使用する場合」で説明したように、揮発性の高い表など、表またはスキーマに関してDBMS_STATS_JOBプロセスによる新規統計の収集を中止する必要がある場合があります。このような場合は、DBMS_STATSパッケージに表またはスキーマの統計をロックするためのプロシージャが用意されています。詳細は、「表統計またはスキーマ統計のロック」を参照してください。
自動オプティマイザ統計収集を使用しない場合は、DBMS_STATSを実行して、システム・スキーマを含むすべてのスキーマで統計を手動で収集する必要があります。データベースの内容が定期的に変更される場合は、データベース・オブジェクトの特性を正確に表すために統計も定期的に収集する必要があります。
この項では、次の項目について説明します。
DBMS_STATSパッケージを使用して統計を収集できます。このPL/SQLパッケージは、統計の変更、表示、エクスポート、インポートおよび削除にも使用されます。
DBMS_STATSパッケージでは、表と索引の統計、および表の個別の列とパーティションの統計を収集できます。クラスタ統計は収集しません。ただし、クラスタ全体ではなく、個別の表の統計をDBMS_STATSを使用して収集できます。
表、列または索引の統計を生成する場合に、分析したオブジェクトの統計がデータ・ディクショナリに含まれる場合、Oracle Databaseは既存の統計を更新します。古い統計は保存されます。必要に応じて、後でリストアできます。「前のバージョンの統計のリストア」を参照してください。
システム・スキーマの統計を収集する場合は、DBMS_STATS.GATHER_DICTIONARY_STATSプロシージャを使用できます。このプロシージャでは、SYSやSYSTEMを含むすべてのシステム・スキーマと、CTXSYSやDRSYSなどの他のオプション・スキーマの統計が収集されます。
データベース・オブジェクトの統計が更新されると、そのオブジェクトにアクセスする現在解析済のSQL文は無効になります。文が次に実行されるときに、文が再解析され、オプティマイザは新しい統計に基づいて新しい実行計画を自動的に選択します。リモート・データベース上で新しい統計を持つオブジェクトにアクセスする分散型の文は、無効にされません。新しい統計は、次回にSQL文が解析されると有効になります。
表13-1に、DBMS_STATSパッケージにおけるデータベース・オブジェクトの統計収集のためのプロシージャを示します。
表13-1 DBMS_STATSパッケージの統計収集プロシージャ
| プロシージャ | 収集対象 |
|---|---|
|
索引統計 |
|
|
表、列および索引の統計 |
|
|
スキーマ内のすべてのオブジェクトの統計 |
|
|
すべてのディクショナリ・オブジェクトの統計 |
|
|
データベース内のすべてのオブジェクトの統計 |
|
関連項目: すべてのDBMS_STATSプロシージャの構文と例については、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
前述のプロシージャを統計収集に使用する場合は、次のようにいくつか重要な考慮事項があります。
統計収集操作では、サンプリングを使用して統計を予測できます。サンプリングは、統計収集の重要なテクニックです。サンプリングを使用せずに統計を収集するには、全表スキャンと表全体のソートが必要です。サンプリングを使用すると、統計収集に必要なリソースが最小限に抑えられます。
サンプリングは、DBMS_STATSプロシージャのESTIMATE_PERCENT引数を使用して指定します。サンプリング率は任意の値に設定できますが、必要な統計を正確に収集し、最大のパフォーマンスを得るには、DBMS_STATS収集プロシージャのESTIMATE_PERCENTパラメータをDBMS_STATS.AUTO_SAMPLE_SIZEに設定することをお薦めします。AUTO_SAMPLE_SIZEを使用すると、オブジェクトの統計プロパティに基づいて、適切な統計のために必要な最善のサンプル・サイズがOracle Databaseにより決定されます。統計のタイプごとに要件が異なるため、実際に取得されるサンプルのサイズは、表、列または索引間で異なる場合があります。たとえば、自動サンプリングでOEスキーマ内のすべての表に関する表統計および列統計情報を収集するには、次のように使用できます。
EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('OE',DBMS_STATS.AUTO_SAMPLE_SIZE);
ESTIMATE_PERCENTパラメータを手動で指定すると、指定されたパーセントで生成されたサンプルの大きさが十分でない場合に、DBMS_STATS収集プロシージャによりサンプリング率が自動的に増加されます。これによって、見積り値の変動が少なくなり、安定性が保証されます。
統計の収集操作は、シリアルまたはパラレルのどちらでも実行できます。並列度は、DBMS_STATS収集プロシージャのDEGREE引数で指定できます。データベースでは、パラレル統計収集をサンプリングと併用できます。DEGREEパラメータをDBMS_STATS.AUTO_DEGREEに設定することをお薦めします。このように設定すると、Oracle Databaseは、オブジェクトのサイズとパラレル関連のinit.oraパラメータの設定に基づいて適切な並列度を選択できます。
クラスタ索引、ドメイン索引およびビットマップ結合索引など、特定のタイプの索引統計は、パラレルでは収集されないことに注意してください。
パーティション表および索引に対して、DBMS_STATSは、各パーティションの個別の統計を収集できます。また、全表または全索引のグローバル統計も収集できます。コンポジット・パーティションについても同様に、DBMS_STATSはサブパーティション、パーティション、全表および全索引の個別の統計を収集できます。
最適化を行ったSQL文によっては、オプティマイザがパーティション統計、サブパーティション統計またはグローバル統計を使用するかどうかを選択できます。大多数のアプリケーションにとっては、グローバル統計とパーティション統計の両方とも重要です。
収集するパーティション統計のタイプは、DBMS_STATSプロシージャのGRANULARITY引数で指定します。GRANULARITYをAUTOに設定して、パーティションのタイプに応じてサブパーティション統計、パーティション統計またはグローバル統計を収集することをお薦めします。ALL設定では、常にすべての統計タイプが収集されます。
|
関連項目: DBMS_STATSの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
通常、パーティション表では、新しいパーティションに新しいデータを追加します。新しいパーティションを追加し、データをロードした場合、新しいパーティションで統計を収集してグローバルな統計を最新の状態に維持する必要があります。
INCREMENTALを使用して、データベースで全表スキャンを実行してパーティション表のグローバル統計を維持するかどうかを決定できます。DBMS_STATS.SET_TABLE_PREFプロシージャを使用して、INCREMENTAL値を変更できます。
INCREMENTAL=false(デフォルト)の場合、データベースは常に全表スキャンを使用してグローバル統計を維持します。大規模な表では、これは大量にリソースを消費し、時間のかかる操作です。必須の全表スキャンのかわりとなるのが、増分統計の収集です。次の条件を満たす場合、データベースは変更されたパーティションのみをスキャンしてグローバル統計を増分的に更新します。
パーティション表のINCREMENTAL値がtrueです。
パーティション表のPUBLISH値がtrueです。
表の統計を収集するときに、ユーザーがESTIMATE_PERCENTにAUTO_SAMPLE_SIZEを、GRANULARITYにAUTOを指定しています。
表の統計を増分的に収集すると、次のような結果になります。
SYSAUX表領域では、パーティション表のグローバル統計を維持するために追加の領域が使用されます。
表がコンポジット・パーティションを使用する場合は、データベースは変更されたサブパーティションの統計のみを収集します。データベースは、未変更のサブパーティションに対しては、サブパーティション・レベルの統計を収集しません。このようにして、データベースは未変更のパーティションをスキップして作業を減らします。
表が増分統計を使用しており、この表にローカルでパーティション化された索引がある場合は、データベースは、変更された(未変更でない)索引パーティションに対してグローバル・レベルで索引統計を収集します。データベースは、パーティション・レベルの統計からグローバル索引統計を生成することはしません。そのかわりに、データベースは全索引スキャンを実行してグローバル索引統計を収集します。
|
関連項目: DBMS_STATSの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
表の統計を収集する場合、DBMS_STATSでは表内の列のデータ配分情報が収集されます。データ配分に関して最も基本的な情報は、列の最大値と最小値です。ただし、列のデータに偏りがある場合、このレベルの統計ではオプティマイザのニーズが十分に満たされない場合があります。データ配分に偏りがある場合は、指定した列のデータ配分を記述するヒストグラムも列統計の一部として作成できます。ヒストグラムの詳細は、「ヒストグラムの表示」を参照してください。
ヒストグラムは、DBMS_STATS収集プロシージャのMETHOD_OPT引数を使用して指定します。METHOD_OPTはFOR ALL COLUMNS SIZE AUTOに設定することをお薦めします。この設定では、ヒストグラムが必要な列および各ヒストグラムのバケット数(サイズ)が自動的に決定されます。また、これらの情報は手動でも指定できます。
|
注意: DBMS_STATSを使用するとき表からすべての行を削除する必要がある場合、同じ表を削除して再度作成するかわりに、TRUNCATEを使用します。表を削除すると、自動ヒストグラム収集機能が使用するワークロード情報と、RESTORE_*_STATSプロシージャが使用する保存された統計履歴が消失します。このデータなしでは、これらの機能は適切に動作しません。 |
データベース・オブジェクトは時間の経過とともに変化するため、統計を定期的に収集する必要があります。Oracle Databaseの表監視機能により、特定のデータベース・オブジェクトの新しいデータベース統計が必要かどうかを確認できます。この監視機能は、STATISTICS_LEVELがTYPICALまたはALLに設定されている場合にデフォルトで有効になります。
監視では、最新の統計収集以降の、表に対するINSERT、UPDATEおよびDELETEの概数と、その表が切り捨てられているかどうかを追跡します。USER_TAB_MODIFICATIONSビューで、表の変更に関する情報にアクセスできます。データの変更後、このビューに情報が伝播するまでに数分の遅延が発生することがあります。メモリーに保存されている未処理の監視情報を即時に反映させるには、DBMS_STATS.FLUSH_DATABASE_MONITORING_INFOプロシージャを使用します。
OPTIONSパラメータをGATHER STALEまたはGATHER AUTOに設定すると、GATHER_DATABASE_STATSまたはGATHER_SCHEMA_STATSプロシージャは、統計が失効している表に関して新規の統計を収集します。監視される表の変更が10%を超えた場合、これらの統計は失効したものとみなされ、再度収集されます。
DBMS_STATS.SET_*_PREFSプロシージャを使用して、統計を収集するDBMS_STATSプロシージャで使用するパラメータのデフォルト値を設定できます。各パラメータのプリファレンスを表、スキーマ、データベースおよびグローバル・レベルで設定して、きめの細かい制御を提供できます。
|
注意: 前のリリースでは、デフォルトのパラメータ値の設定に、DBMS_STATS.SET_PARMプロシージャを使用していました。これらの変更の有効範囲は、SET_PARMの実行後に発生したすべての操作でした。Oracle Database 11gでは、SET_PARMは非推奨です。 |
DBMS_STATS.SET_*_PREFSプロシージャを使用して、次のパラメータを変更できます。
AUTOSTATS_TARGET(SET_GLOBAL_PREFSのみ)
CASCADE
DEGREE
ESTIMATE_PERCENT
GRANULARITY
INCREMENTAL
METHOD_OPT
NO_INVALIDATE
PUBLISH
STALE_PERCENT
表13-2に、プリファレンスを設定するDBMS_STATSプロシージャのリストを示します。DBMS_STAT.GATHER_*_STATSプロシージャで設定したパラメータ値は、他の設定を上書きします。パラメータが設定されていない場合、データベースは表レベルのプリファレンスをチェックします。表のプリファレンスが存在しない場合は、GLOBALプリファレンスを使用します。
表13-2 統計収集のプリファレンスの設定
| プロシージャ | 目的 |
|---|---|
|
|
指定した表において |
|
|
指定したスキーマのすべての既存オブジェクトにおいて このプロシージャは、指定されたスキーマの各表で |
|
|
データベースのすべてのユーザー定義のスキーマにおいて このプロシージャは、指定されたスキーマの各表で |
|
|
既存の表プリファレンスを持たないデータベース内のオブジェクトにおいて 表プリファレンスが設定されているか、
|
|
関連項目: すべてのDBMS_STATSプロシージャの構文と例については、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
統計を手動で収集する場合は、その収集方法を決定するのみでなく、新規統計の収集時期と頻度も決定する必要があります。
表の増分変更が行われるアプリケーションの場合は、新規の統計を週または月に1回収集するのみでかまいません。このような環境で最も簡単に統計を収集する方法は、スクリプトまたはジョブ・スケジューリング・ツールを使用して、GATHER_SCHEMA_STATSおよびGATHER_DATABASE_STATSプロシージャを定期的に実行することです。収集の頻度によって、統計収集プロセスで起こるオーバーヘッドの処理に対し、オプティマイザの正確な統計を出すタスクのバランスをとります。
バルク・ロードを使用する場合など、バッチ操作で大幅に変更される表の場合は、その表の統計をバッチ操作の一部として収集します。ロード操作が完了した直後に、DBMS_STATSプロシージャをコールします。
ときには、単一パーティションのみが変更される場合があります。この場合は、表全体ではなく、変更されたパーティションでのみ統計を収集できます。ただし、パーティション表のグローバル統計の収集も必要な場合があります。
|
関連項目: DBMS_STATSパッケージのGATHER_SCHEMA_STATSおよびGATHER_DATABASE_STATSプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
DBMS_STATSを使用すると、2つの異なるソースの表の統計を比較できます。表13-3に、統計を比較するためのDBMS_STATSパッケージのファンクションを示します。
表13-3 統計を比較するDBMS_STATSパッケージのファンクション
| プロシージャ | 比較対象 |
|---|---|
|
保留中の統計とタイムスタンプの時点の統計またはディクショナリの統計 |
|
|
2つの異なるソースの表の統計 |
|
|
過去の2つのタイムスタンプからの表の統計、およびそれらのタイムスタンプの時点の統計 |
表13-3のファンクションでは、索引、列およびパーティションなどの依存オブジェクトの統計も比較します。これらの統計間の差分が特定のしきい値を超える場合、両方のソースのオブジェクトの統計が表示されます。ファンクションの引数としてしきい値を指定できます。デフォルトは10%です。Oracle Databaseでは、最初のソースに相当する統計を基本として使用し、異なる割合を計算します。
|
関連項目: DBMS_STATSパッケージのDIFF_TABLE_STATS_*ファンクションの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
システム統計は、問合せオプティマイザに対してシステムのハードウェア特性(I/OとCPUのパフォーマンスおよび使用率など)を記述します。実行計画の選択時に、オプティマイザで各問合せに必要なI/OおよびCPUリソースが見積られます。システム統計を使用すると、問合せオプティマイザはI/OおよびCPUコストをより正確に見積ることができ、問合せオプティマイザはより適切な実行計画を選択できます。
Oracle Databaseでは、システム統計を収集する際に、指定された期間のシステム・アクティビティを分析するか(作業負荷統計)、作業負荷をシミュレートします(非作業負荷統計)。統計は、DBMS_STATS.GATHER_SYSTEM_STATSプロシージャを使用して収集されます。システム統計を収集することをお薦めします。
|
注意: ディクショナリ・システム統計を更新するには、DBA権限またはGATHER_SYSTEM_STATISTICSロールが必要です。 |
表13-4に、DBMS_STATSパッケージにより収集されたオプティマイザのシステム統計と、特定のシステム統計の収集または手動設定のオプションを示します。
表13-4 DBMS_STATパッケージ内のオプティマイザのシステム統計
| パラメータ名 | 説明 | 初期化 | 統計の収集または設定のオプション | 単位 |
|---|---|---|---|---|
|
|
作業負荷のない場合のCPU速度を表します。CPU速度は、1秒当たりのCPU平均サイクル数です。 |
システム起動時 |
|
100万/秒 |
|
|
I/Oシーク時間は、シーク時間、待機時間およびオペレーティング・システム・オーバーヘッド時間を合計したものです。 |
システム起動時 10(デフォルト) |
|
ミリ秒 |
|
|
I/O転送速度は、1回の読取りリクエストでOracleデータベースがデータを読み取ることができる速度です。 |
システム起動時 4096(デフォルト) |
|
バイト/ミリ秒 |
|
|
作業負荷をかけた場合のCPU速度を表します。CPU速度は、1秒当たりのCPU平均サイクル数です。 |
なし |
|
100万/秒 |
|
|
最大I/Oスループットは、I/Oサブシステムが発揮できる最大スループットです。 |
なし |
|
バイト/秒 |
|
|
スレーブI/Oスループットは、パラレル・スレーブの平均I/Oスループットです。 |
なし |
|
バイト/秒 |
|
|
単一ブロック読取り時間は、単一ブロックをランダムに読み取る平均時間です。 |
なし |
|
ミリ秒 |
|
|
マルチブロック読取りは、マルチブロックを順に読み取る平均時間です。 |
なし |
|
ミリ秒 |
|
|
マルチブロック・カウントは、平均マルチブロック順次読取りカウントです。 |
なし |
|
ブロック |
表、索引、列の統計とは異なり、システム統計の更新時には、解析済のSQL文は無効にされません。新しいSQL文はすべて、新しい統計を使用して解析されます。
システム統計の収集方法には2つのオプションがあります。
これらのオプションは、物理データベースおよび作業負荷の収集プロセスを容易にします。作業負荷システム統計が収集されると、非作業負荷システム統計は無視されます。非作業負荷システム統計は、データベースの初回の起動時にデフォルト値に初期化されます。
|
関連項目: システム統計を実装するためのDBMS_STATSパッケージのプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
作業負荷統計には次のものがあります。
シングルおよびマルチブロックの読取り時間
mbrc
CPU速度(cpuspeed)
最大システム・スループット
平均スレーブ・スループット
シングルおよびマルチブロックの読取り時間、mbrc、CPU速度(cpuspeed)、最大システム・スループットおよび平均スレーブ・スループット。データベースでは、作業負荷の開始から終了までの間の、物理的な順次およびランダム読取りの数を比較して、sreadtim、mreadtimおよびmbrcを計算します。これらの値は、バッファ・キャッシュが同期読取りリクエストを完了したときに変更されるカウンタを通して実装されます。
このカウンタはバッファ・キャッシュ内にあるため、これらにはI/O遅延のほかに、ラッチの競合およびタスク・スイッチングに関連する待機も含まれます。このように、作業負荷統計は、作業負荷ウィンドウでシステムが実行するアクティビティに応じて異なります。システムがI/Oバウンドの場合(ラッチ競合およびI/Oスループット)、この状況は統計に反映されるため、データベースで統計が使用された後にI/O集中の低減化計画が推奨されます。さらに、作業負荷統計収集は、追加のオーバーヘッドを生成しません。
作業負荷統計を収集するには、次のいずれかのタスクを実行します。
作業負荷ウィンドウの開始時にDBMS_STATS.GATHER_SYSTEM_STATS('start')プロシージャを実行し、作業負荷ウィンドウの終了時にDBMS_STATS.GATHER_SYSTEM_STATS('stop')プロシージャを実行します。
DBMS_STATS.GATHER_SYSTEM_STATS('interval', interval=>N)を実行します。Nは、統計収集が自動停止する時間(分)です。
システム統計を削除するには、dbms_stats.delete_system_stats()を実行します。作業負荷統計が削除され、デフォルトの非作業負荷統計にリセットされます。
作業負荷統計を収集する場合、作業負荷統計の一部として収集されたmbrcの値を使用して全表スキャンのコストを見積ることができます。ただし、作業負荷統計の収集プロセスでシリアル作業負荷の間に表スキャンが実行されない場合(OLTPシステムでしばしば発生します)、mbrcおよびmreadtimの値が収集されない場合があります。また、DSSシステムでは全表スキャンが頻繁に実行されますが、パラレル実行によってバッファ・キャッシュがバイパスされる可能性があります。このような場合でも、バッファ・キャッシュを使用して索引参照が実行されるため、sreadtimの値は収集されます。
mbrcまたはmreadtimの値を収集できないか、または収集してもそれらの検証ができない場合で、sreadtimおよびcpuspeedの値が収集されている場合は、sreadtimおよびcpuspeedの値のみがコスト計算に使用されます。この場合、オプティマイザは初期化パラメータDB_FILE_MULTIBLOCK_READ_COUNTの値を使用して全表スキャンを見積ることができます。ただし、DB_FILE_MULTIBLOCK_READ_COUNTを設定しないか、0(ゼロ)に設定する場合、オプティマイザは値8を使用してコストを見積ります。
非作業負荷統計は、I/O転送速度、I/Oシーク時間およびCPU速度(cpuspeednw)で構成されています。作業負荷統計と非作業負荷統計の主な違いは、収集方法にあります。
非作業負荷統計は、すべてのデータファイルに対してランダム読取りを発行してデータを収集しますが、作業負荷統計は、データベース・アクティビティの発生時に更新されるカウンタを使用します。ioseektimは、ディスク・ヘッドがデータを読み取る位置に移動する時間を表します。この値は通常、ディスクの回転速度およびディスクまたはRAIDの仕様に応じて5から15ミリ秒の間で変化します。I/O転送速度は、オペレーティング・システムの1つのプロセスでI/Oサブシステムからのデータの読取りが可能な速度を表します。この値は、毎秒数MBから数百MBまで大きく変化します。Oracle Databaseでは、I/O転送速度に比較的低い値のデフォルト設定を使用しています。
デフォルトでは、Oracle Databaseで非作業負荷統計とCPUコスト・モデルが使用されます。非作業負荷統計の値は、最初のインスタンス起動時にデフォルトに初期化されます。
ioseektim = 10ms iotrfspeed = 4096 bytes/ms cpuspeednw = gathered value, varies based on system
作業負荷統計を収集する場合、非作業負荷統計は無視され、作業負荷統計が使用されます。
非作業負荷統計を収集するには、引数なしでDBMS_STATS.GATHER_SYSTEM_STATS()を実行します。非作業負荷統計の収集プロセスの際に、I/Oシステムにオーバーヘッドが発生します。この収集プロセスは、I/Oのパフォーマンスおよびデータベースのサイズによって数秒から数分かかることがあります。
この情報は分析され、整合性が検証されます。場合により、非作業負荷統計の値はデフォルト値のままになることがあります。このような場合は、統計収集プロセスを繰り返すか、DBMS_STATS.SET_SYSTEM_STATSプロシージャを使用してI/Oシステムの仕様に応じた値に手動で設定します。
この項では、次の項目について説明します。
Oracle Database 11gリリース2(11.2)以上では、統計を収集する際に次のオプションがあります。
収集操作の終了時に統計を自動的に公開します(デフォルト動作)。
新しい統計を保留中として保存します。
新規統計を保留中として保存すると、新規統計を検証して、それらが適切である場合にのみ公開できます。
統計を収集したらすぐに自動的に公開するかどうかを確認するには、次のようにDBMS_STATSパッケージを使用します。
SELECT DBMS_STATS.GET_PREFS('PUBLISH') PUBLISH FROM DUAL;
この問合せは、TRUE またはFALSEを戻します。TRUEは統計が収集時に公開されることを示し、FALSEは統計が保留中として保存されることを示します。
|
注意: 公開された統計は、USER_TAB_STATISTICSやUSER_IND_STATISTICSなどのデータ・ディクショナリ・ビューに格納されます。保留中の統計は、USER_TAB_PENDING_STATSやUSER_IND_PENDING_STATSなどのビューに格納されます。 |
PUBLISH設定は、スキーマ・レベルまたは表レベルで変更できます。たとえば、SHスキーマのcustomers表のPUBLISH設定を変更するには、次の文を実行します。
EXEC DBMS_STATS.SET_TABLE_PREFS('SH', 'CUSTOMERS', 'PUBLISH', 'false');
これで、customers表の統計が収集される場合に、その統計は収集ジョブの完了時に自動的に公開されなくなります。かわりに、新規に収集された統計はUSER_TAB_PENDING_STATS表に格納されます。
デフォルトでは、オプティマイザはデータ・ディクショナリ・ビューに格納されている公開済の統計を使用します。新規に収集された保留中の統計をオプティマイザで使用する場合は、OPTIMIZER_USE_PENDING_STATISTICS初期化パラメータをTRUEに設定し(デフォルト値はFALSE)、表またはスキーマに対してワークロードを実行します。
ALTER SESSION SET OPTIMIZER_USE_PENDING_STATISTICS = TRUE;
オプティマイザでは、SQL文をコンパイルする際に、公開された統計ではなく、保留中の統計を使用します。保留中の統計が有効である場合、次の文を実行して公開できます。
EXEC DBMS_STATS.PUBLISH_PENDING_STATS(null, null);
特定のデータベース・オブジェクトに関する保留中の統計を公開することもできます。たとえば、次の文を使用します。
EXEC DBMS_STATS.PUBLISH_PENDING_STATS('SH','CUSTOMERS');
保留中の統計を公開しない場合は、次の文を実行してそれらの統計を削除します。
EXEC DBMS_STATS.DELETE_PENDING_STATS('SH','CUSTOMERS');
保留中の統計は、DBMS_STATS.EXPORT_PENDING_STATSファンクションを使用してエクスポートできます。保留中の統計をテスト・システムにエクスポートすると、新規統計に対してすべてのワークロードを実行できます。
DBMS_STATSでは拡張統計の収集が可能で、複数の述語が1つの表の異なる列に存在する場合や、述語で式を使用する場合に、拡張統計によりカーディナリティ予測を改善できます。拡張は、列グループまたは式のいずれかになります。
Oracle Databaseでは次の種類の拡張統計がサポートされます。
列グループの統計
この種類の拡張統計では、同じ表の複数の列が1つのSQL文に同時に存在する場合のカーディナリティ予測を改善できます。「列グループの統計の管理」を参照してください。
式の統計
この種類の拡張統計では、組込みファンクションやユーザー定義ファンクションなどの式を述語で使用する際にオプティマイザの見積りが改善されます。「式の統計の管理」を参照してください。
|
注意: 仮想列の拡張統計を作成することはできません。仮想列の制限事項は、『Oracle Database SQL言語リファレンス』を参照してください。 |
問合せのWHERE句に、1つの表からの複数の列を指定した場合(複数の単一列条件)、列グループの総合的な選択性が列の関係に大きく左右される場合があります。
例として、shスキーマのcustomers表を検討します。cust_state_province列とcountry_id列は、各顧客のcust_state_provinceがcountry_idを決定するという関係にあります。次のように、cust_state_provinceがCaliforniaであるという条件でcustomers表を問い合せるとします。
SELECT COUNT(*) FROM sh.customers WHERE cust_state_province = 'CA';
この問合せは、次の値を戻します。
COUNT(*)
----------
3341
country_id列が52790(アメリカ合衆国)の場合、次のようにcountry_idに関する別の条件を追加しても結果は変わりません。次の問合せを実行します。
SELECT COUNT(*) FROM customers WHERE cust_state_province = 'CA' AND country_id=52790;
この問合せは、前の問合せと同じ値を戻します。
COUNT(*)
----------
3341
次の問合せのように、country_idが52775(ブラジル)などの異なる値を持つ場合を考えます。
SELECT COUNT(*) FROM customers WHERE cust_state_province = 'CA' AND country_id=52775;
この場合、次の値を戻します。
COUNT(*)
----------
0
個々の列の統計を使用すると、オプティマイザでは、cust_state_province列とcountry_id列の関係を認識できません。これらの列をグループ(列グループ)として統計を収集することで、オプティマイザでは、個々の列統計に基づいて値を生成することなく、そのグループに関するより正確な選択値を得ることができます。
DBMS_STATSパッケージを使用して手動で列グループを作成できます。このパッケージを使用すると、列グループの作成、列グループ名の取得、または表からの列グループの削除が可能になります。
CREATE_EXTENDED_STATISTICSファンクションを使用して、列グループを作成します。CREATE_EXTENDED_STATISTICSファンクションでは、新規に作成された列グループのシステム生成名が戻されます。表13-5に、このファンクションの入力パラメータを示します。
表13-5 create_extended_statisticsファンクションのパラメータ
| パラメータ | 説明 |
|---|---|
|
|
スキーマ所有者。 |
|
|
列グループが追加される表の名前。 |
|
|
列グループの列。 |
たとえば、cust_state_provinceおよびcountry_id列で構成される列グループをSHスキーマのcustomers表に追加するには、次のPL/SQLブロックを実行します。
DECLARE
cg_name VARCHAR2(30);
BEGIN
cg_name := DBMS_STATS.CREATE_EXTENDED_STATS(null,'customers',
'(cust_state_province,country_id)');
END;
/
show_extended_stats_nameファンクションを使用して、任意の列セットに対応する列グループの名前を取得します。表13-6に、このファンクションの入力パラメータを示します。
表13-6 show_extended_stats_nameファンクションのパラメータ
| パラメータ | 説明 |
|---|---|
|
|
スキーマ所有者。 |
|
|
列グループが属している表の名前。 |
|
|
列グループの名前。 |
たとえば、次の問合せを使用すると、customers表の列セットの列グループ名を取得できます。
SELECT SYS.DBMS_STATS.SHOW_EXTENDED_STATS_NAME('sh','customers',
'(cust_state_province,country_id)') col_group_name
FROM DUAL;
出力は、次のようなものです。
COL_GROUP_NAME ---------------- SYS_STU#S#WF25Z#QAHIHE#MOFFMM
DROP_EXTENDED_STATSファンクションを使用して、表から列グループを削除します。表13-7に、このファンクションの入力パラメータを示します。
表13-7 drop_extended_statsファンクションのパラメータ
| パラメータ | 説明 |
|---|---|
|
|
スキーマ所有者。 |
|
|
列グループが属している表の名前。 |
|
|
削除する列グループの名前。 |
たとえば、次の文を使用すると、customers表から列グループを削除できます。
EXEC DBMS_STATS.DROP_EXTENDED_STATS('sh','customers',
'(cust_state_province,country_id)');
ディクショナリ表USER_STAT_EXTENSIONSを使用して、複数列の統計に関する情報を取得します。
SELECT EXTENSION_NAME, EXTENSION FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='CUSTOMERS';
EXTENSION_NAME EXTENSION
-------------------------------------------------------------------------
SYS_STU#S#WF25Z#QAHIHE#MOFFMM_ ("CUST_STATE_PROVINCE","COUNTRY_ID")
次の問合せを使用すると、個別値の数と、列グループにヒストグラムが作成されているかどうかを確認できます。
SELECT e.EXTENSION col_group, t.NUM_DISTINCT, t.HISTOGRAM FROM USER_STAT_EXTENSIONS e, USER_TAB_COL_STATISTICS t WHERE e.EXTENSION_NAME=t.COLUMN_NAME AND e.TABLE_NAME=t.TABLE_NAME AND t.TABLE_NAME='CUSTOMERS';
COL_GROUP NUM_DISTINCT HISTOGRAM
-------------------------------------------------------------------------------
("COUNTRY_ID","CUST_STATE_PROVINCE") 145 FREQUENCY
DBMS_STATSパッケージのMETHOD_OPT引数を使用して、列グループの統計を収集します。この引数の値をFOR ALL COLUMNS SIZE AUTOに設定すると、オプティマイザは、既存のすべての列グループに関する統計を収集します。新規の列グループに関する統計を収集するには、FOR COLUMNSを使用してグループを指定します。列グループは、統計収集の一部として自動的に作成されます。
たとえば、次の文では、customers表のcust_state_provinceおよびcountry_id列に対応する新規列グループが作成され、表全体と新規列グループに関する統計(ヒストグラムを含む)が収集されます。
EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','CUSTOMERS',METHOD_OPT =>
'FOR ALL COLUMNS SIZE SKEWONLY
FOR COLUMNS (CUST_STATE_PROVINCE,COUNTRY_ID) SIZE SKEWONLY');
|
注意: オプティマイザは、等価述語でのみ複数列の統計を使用します。 |
問合せのWHERE句で列に関数が適用される場合(function(col1)=constant)、オプティマイザでは、その関数が列の選択性に与える影響を認識できません。式function(col1)に関する式の統計を収集することで、より正確な選択値を取得できます。
このような関数の例は、次のとおりです。
SELECT COUNT(*) FROM CUSTOMERS WHERE LOWER(CUST_STATE_PROVINCE)='ca';
GATHER_TABLE_STATSプロシージャの一部として、次のように式の統計を作成できます。
EXEC DBMS_STATS.GATHER_TABLE_STATS('sh','customers', method_opt =>
'FOR ALL COLUMNS SIZE SKEWONLY
FOR COLUMNS (LOWER(cust_state_province)) SIZE SKEWONLY');
これを行うには、次のようにCREATE_EXTENDED_STATISTICSファンクションも使用できます。
SELECT DBMS_STATS.CREATE_EXTENDED_STATS(null,'customers','(LOWER(cust_state_province))') FROM DUAL;
ディクショナリ表user_stat_extensionsを使用して、式の統計に関する情報を取得します。
SELECT EXTENSION_NAME, EXTENSION FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='CUSTOMERS';
EXTENSION_NAME EXTENSION
------------------------------------------------------------------------
SYS_STUBPHJSBRKOIK9O2YV3W8HOUE (LOWER("CUST_STATE_PROVINCE"))
次の問合せを使用すると、個別値の数と、ヒストグラムが作成されているかどうかを確認できます。
SELECT e.EXTENSION col_group, t.NUM_DISTINCT, t.HISTOGRAM FROM USER_STAT_EXTENSIONS e, USER_TAB_COL_STATISTICS t WHERE e.EXTENSION_NAME=t.COLUMN_NAME AND t.TABLE_NAME='CUSTOMERS';
COL_GROUP NUM_DISTINCT HISTOGRAM
------------------------------------------------------------------------
(LOWER("CUST_STATE_PROVINCE")) 145 FREQUENCY
ディクショナリ内で統計が変更されるたびに、後でリストアできるように前のバージョンの統計が自動的に保存されます。統計をリストアするには、DBMS_STATSパッケージのRESTOREプロシージャを使用します。これらのプロシージャは、引数としてタイムスタンプを使用し、そのタイムスタンプでの統計をリストアします。これは、新規に収集された統計では不適切な実行計画が作成され、管理者が前の統計セットに戻す必要がある場合に役立ちます。
統計の変更時刻を表示するディクショナリ・ビューがあります。これらのビューは、統計のリストアに使用するタイムスタンプを判断する場合に役立ちます。
カタログ・ビューDBA_OPTSTAT_OPERATIONSには、DBMS_STATSを使用してスキーマ・レベルとデータベース・レベルで実行された統計操作の履歴が含まれます。
*_TAB_STATS_HISTORYビュー(ALL、DBAまたはUSER)には、表統計の変更履歴が含まれます。
古い統計は、統計履歴の保存設定とシステムの最終分析時刻に基づいて、定期的かつ自動的に消去されます。DBMS_STATSのALTER_STATS_HISTORY_RETENTIONプロシージャを使用して保存期間を構成できます。デフォルト値は31日で、オプティマイザ統計を過去31日の任意の時点までリストアできることを意味します。
自動消去は、STATISTICS_LEVELパラメータがTYPICALまたはALLに設定されている場合に有効になります。自動消去が無効化されている場合は、PURGE_STATSプロシージャを使用して古いバージョンの統計を手動で消去する必要があります。
統計のリストアおよび消去に関連する他のDBMS_STATSプロシージャは、次のとおりです。
PURGE_STATS: タイムスタンプを超える古いバージョンを手動で消去できます。
GET_STATS_HISTORY_RETENTION: 現行の統計履歴の保存値を取得できます。
GET_STATS_HISTORY_AVAILABILITY: このファンクションを使用すると、統計履歴が使用可能な最も古いタイムスタンプを取得できます。最も古いタイムスタンプより前のタイムスタンプには、統計をリストアできません。
前のバージョンの統計をリストアする場合は、次の制限が適用されます。
RESTOREプロシージャでは、ユーザー定義統計はリストアできません。
統計の収集にANALYZEコマンドが使用された場合、古いバージョンの統計は格納されません。
|
注意: DBMS_STATSを使用する際に、表からすべての行を削除するには、同じ表を削除して再度作成するかわりに、TRUNCATEを使用します。表を削除すると、自動ヒストグラム収集機能が使用するワークロード情報と、RESTORE_*_STATSプロシージャが使用する保存された統計履歴が消失します。このデータなしでは、これらの機能は適切に動作しません。 |
統計をデータ・ディクショナリからエクスポートして、ユーザー所有の表にインポートできます。これにより、同じスキーマについて複数の統計のバージョンを作成できます。また、データベース間で統計のコピーもできます。この操作により、統計を本番データベースから小規模なテスト・データベースにコピーできます。
|
注意: 統計のエクスポートとインポートは、データ・ポンプ・エクスポートおよびインポート・ユーティリティとは異なる概念です。 |
統計をエクスポートする前に、その統計を保持する表を作成する必要があります。統計表は、DBMS_STATS.CREATE_STAT_TABLEプロシージャで作成します。表を作成した後、DBMS_STATS.EXPORT_*_STATSプロシージャを使用して、データ・ディクショナリから統計表に統計をエクスポートできます。統計をインポートするには、DBMS_STATS.IMPORT_*_STATSプロシージャを使用します。
オプティマイザでは、ユーザー所有の表に格納されている統計が使用されないことに注意してください。オプティマイザで使用されるのは、データ・ディクショナリに格納されている統計のみです。ユーザー所有の表内の統計をオプティマイザで使用するには、統計インポート・プロシージャを使用して、その統計をデータ・ディクショナリにインポートする必要があります。
統計をデータベース間で移動するには、最初のデータベース上の統計をエクスポートしてから、データ・ポンプ・エクスポートおよびインポート・ユーティリティまたは他のメカニズムを使用して統計表を第2のデータベースにコピーし、最後に統計を第2のデータベースにインポートする必要があります。
統計リストア機能は、ある面では統計のインポートおよびエクスポート機能に類似しています。通常、次の場合にはリストア機能を使用します。
統計の古いバージョンをリカバリする場合。たとえば、オプティマイザの動作を前の日付までリストアする場合などです。
データベースで統計履歴の保存および消去を管理する場合。
次の場合には、EXPORT/IMPORT_*_STATSプロシージャを使用する必要があります。
複数の統計セットを試験的に使用して値を増減させる場合。
データベース間で統計を移動する場合。たとえば、本番システムからテスト・システムに統計を移動する場合などです。
既知の統計セットを統計のリストアに必要な保存日数よりも長期間にわたって保存する場合。
表またはスキーマの統計は、ロックすることができます。統計をロックすると、ロックを解除するまで統計を変更できません。ロック・プロシージャは、統計が変化しないことを保証する必要のある静的環境に役立ちます。
DBMS_STATSパッケージには、ロックするための2つのプロシージャ(LOCK_SCHEMA_STATSおよびLOCK_TABLE_STATS)と、統計のロックを解除するための2つのプロシージャ(UNLOCK_SCHEMA_STATSおよびUNLOCK_TABLE_STATS)が用意されています。
SET_*_STATISTICSプロシージャを使用して、表、列、索引およびシステムの統計を設定できます。統計が不正確であったり一貫性がないとパフォーマンスが低下するため、この方法での統計の設定はお薦めしません。
Oracle Databaseでは、統計が欠落している表が検出されると、デフォルトでオプティマイザに必要な統計を動的に収集します。ただし、リモート表や外部表などの特定のタイプの表に対しては、Oracle Databaseは動的統計を収集しません。これらの場合および動的統計が無効になっている場合、オプティマイザの統計ではデフォルト値が使用されます。表13-8および表13-9を参照してください。
デフォルトでは、オプティマイザ統計が存在しないか、拡張が必要な場合、Oracle Databaseでは、動的統計が自動的に収集されます。統計を得るために、データベースは解析中に再帰的SQLを使用して表ブロックの小さなランダム・サンプルをスキャンします。
|
注意: 以前のリリースでは、動的統計は動的サンプリングと呼ばれていました。 |
この項では、次の項目について説明します。
オプティマイザ統計で存在しないものや不十分なものが拡張されると、オプティマイザは、述語選択の評価を向上させてプランを改善することができます。動的統計は、表ブロック・カウント、適用可能な索引ブロック・カウント、表のカーディナリティ(概算行数)および関連する結合列の統計などの統計を補完できます。
動的統計は、データベースにおいてデフォルトで有効化されています。この機能を無効化するには、初期化パラメータOPTIMIZER_DYNAMIC_SAMPLING=0を設定します。
動的統計レベルでは、データベースで動的統計を収集するタイミングと、統計の収集にオプティマイザが使用するサンプル・サイズの両方が制御されます。動的統計レベルを設定するには、OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータまたは文ヒントのいずれかを使用します。
表13-10に動的統計レベルを示します。デフォルトのレベルは2です。Oracle Database 11gリリース2 (11.2.0.4)以上では、レベル11を設定すると、データベースは、オプティマイザが最適と判断するあらゆるタイミングとレベルで統計を収集するようになりました。
表13-10 動的統計レベル
| レベル | オプティマイザで動的統計を使用するタイミング | サンプル・サイズ(ブロック) |
|---|---|---|
|
0 |
動的統計を使用しません。 |
該当なし |
|
1 |
次の基準を満たす場合のみ、統計を含まないすべての表に動的統計を使用します。
|
32 |
|
2 |
文の少なくとも1つの表に統計がない場合は、動的統計を使用します。これがデフォルトの設定です。 |
64 |
|
3 |
次のいずれかの条件に当てはまる場合は、動的統計を使用します。
|
64 |
|
4 |
次のいずれかの条件に当てはまる場合は、動的統計を使用します。
|
64 |
|
5 |
文がレベル4の基準を満たす場合は、動的統計を使用します。 |
128 |
|
6 |
文がレベル4の基準を満たす場合は、動的統計を使用します。 |
256 |
|
7 |
文がレベル4の基準を満たす場合は、動的統計を使用します。 |
512 |
|
8 |
文がレベル4の基準を満たす場合は、動的統計を使用します。 |
1024 |
|
9 |
文がレベル4の基準を満たす場合は、動的統計を使用します。 |
4086 |
|
10 |
文がレベル4の基準を満たす場合は、動的統計を使用します。 |
すべてのブロック |
|
11 |
オプティマイザが必要と判断した場合は、常に自動的に動的統計が使用されます。 |
自動的に決定 |
|
関連項目: DYNAMIC_SAMPLINGヒントの統計レベルの設定に関する詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
動的統計を使用するかどうかを決める主な要因は、最適な計画を生成するために十分な統計が使用可能かどうかということです。統計が十分でない場合、オプティマイザは動的統計を使用します。
一般に、オプティマイザは、動的統計ではなく、デフォルトの統計を使用して、表、索引および列の最適化時に必要な統計を計算します。オプティマイザは、いくつかの要因に基づいて動的統計を使用するかどうかを決定します。たとえば、並列実行がSQL文で使用されていると、データベースは自動的に動的統計を使用します。
オプティマイザは、次のような場合に、自動的に動的統計を収集します。
統計の欠落
問合せ内の表に統計がない場合、オプティマイザは最適化の前にこれらの表の基本的な統計を収集します。アプリケーションで、統計を収集するためのDBMS_STATSへのフォローアップ・コールなしに新しいオブジェクトが作成された、または統計が収集される前にオブジェクトで統計がロックされたという理由で、統計が欠落することがあります。
この場合、統計はDBMS_STATSパッケージを使用して収集された統計ほど高品質ではなく、完全でもありません。これは、文のコンパイル時間に及ぼす影響を限定的にするために妥協されます。
統計の失効
DBMS_STATSによって収集された統計は、古くなることがあります。通常、最後に統計が収集されて以降、表内の10%以上の行が変更されると、統計は失効します。
不十分な統計
オプティマイザが、列間の相関、列データ配分の偏り、式の統計などを考慮に入れずに、述語(フィルタまたは結合)の選択性またはGROUP BY句を見積る場合、統計は常に不十分なものになる可能性があります。
拡張統計により、オプティマイザは複雑な条件式に対して的確な品質のカーディナリティ予測を得ることができます。オプティマイザは、動的統計を使用して拡張統計の欠落を補完したり、たとえば非等価述語に対する拡張統計が使用できないときに動的統計を使用したりすることができます。
|
注意: データベースは、AS OF句を含む問合せに対して動的統計を使用しません。 |
Oracle Database 11gリリース2 (11.2.0.4)から、オプティマイザは、すべてのSQL文に対して、動的統計が有用であるかどうか、および使用する統計レベルを自動的に決定できるようになりました。OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータまたはSQLヒントのいずれかによってサンプリングレベルが11 (表13-10参照)に明示的に設定された場合にかぎり、オプティマイザはこのように動作します。
|
関連項目: OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータの詳細は、『Oracle Databaseリファレンス』を参照してください。 |
動的統計レベルを設定するベスト・プラクティスは、ALTER SESSIONを使用してOPTIMIZER_DYNAMIC_SAMPLING初期化パラメータに値を設定することです。すべてのSQL文に利点のある、システム全体の設定を決定することは容易ではありません。
前提事項
このチュートリアルでは、次のことが前提となっています。
次の問合せに対して選択性の見積りを修正する場合で、2つの相関列にWHERE句の述語があります。
SELECT * FROM sh.customers WHERE cust_city='Los Angeles' AND cust_state_province='CA';
前述の問合せはシリアル処理を使用します。
sh.customers表は、問合せの条件を満たす932の行を含みます。
sh.customers表に収集された統計があります。
cust_city列とcust_state_province列に索引を作成しています。
OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータが、デフォルト・レベルの2に設定されています。
動的統計レベルを手動設定する手順は次のとおりです。
適切な権限でSQL*Plusをデータベースに接続し、実行計画を次のようにEXPLAINします。
EXPLAIN PLAN FOR SELECT * FROM sh.customers WHERE cust_city='Los Angeles' AND cust_state_province='CA';
その計画を次のように問い合せます。
SET LINESIZE 130 SET PAGESIZE 0 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
出力が次のように表示されます(この例はページに収まるように再フォーマットされています)。
------------------------------------------------------------------------------- |Id| Operation | Name |Rows|Bytes|Cost | Time | ------------------------------------------------------------------------------- | 0| SELECT STATEMENT | | 53| 9593|53(0)|00:00:01| | 1| TABLE ACCESS BY INDEX ROWID|CUSTOMERS | 53| 9593|53(0)|00:00:01| |*2| INDEX RANGE SCAN |CUST_CITY_STATE_IND| 53| 9593| 3(0)|00:00:01| ------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("CUST_CITY"='Los Angeles' AND "CUST_STATE_PROVINCE"='CA')
WHERE句の列には実世界の相関関係がありますが、オプティマイザはロサンゼルスがカリフォルニアにあることを認識せず、両方の述語により、戻される行の数が減少すると想定しています。このように、表には条件を満たす932の行が含まれますが、太字で示すようにオプティマイザは53と見積っています。
データベースでこの計画に動的統計を使用したとすれば、計画出力のNoteセクションでこの事実が指摘されることになります。オプティマイザで動的統計が使用されなかった理由は、文がシリアルに実行されたことや、標準統計が存在することのほか、OPTIMIZER_DYNAMIC_SAMPLINGパラメータがデフォルトの2に設定されていることがあげられます。
次の文を使用して、セッションで動的統計レベルを4に設定します。
ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING=4;
この計画を再び次のようにEXPLAINします。
EXPLAIN PLAN FOR SELECT * FROM sh.customers WHERE cust_city='Los Angeles' AND cust_state_province='CA';
この新しい計画では、太字で示されている値932のように、行数の見積りがより正確に示されています。
PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------- Plan hash value: 2008213504 ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 932 | 271K| 406 (1)| 00:00:05 | |* 1 | TABLE ACCESS FULL| CUSTOMERS | 932 | 271K| 406 (1)| 00:00:05 | ------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("CUST_CITY"='Los Angeles' AND "CUST_STATE_PROVINCE"='CA') Note ----- - dynamic statistics used for this statement (level=4)
計画の一番下のメモは、サンプリング・レベルが4であることを示します。追加された動的統計によって、オプティマイザにcust_city列とcust_state_province列間の実世界の関係を認識させることで、行数が53ではなく932という、より正確な見積りを生成できるようになります。
|
関連項目:
|
一般的には、繰返しのないOLTP問合せなど、コンパイル時間を可能なかぎり速くすることが必要な問合せに対して、動的統計のコストが発生しないようにすることがベスト・プラクティスです。OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータを設定することでその機能を無効にできます。
セッション・レベルの動的統計を無効化する手順は次のとおりです。
適切な権限でSQL*Plusをデータベースに接続します。
動的統計レベルを0に設定します。
たとえば、次の文を実行します。
ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING=0;
|
関連項目: OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
この項では、次の内容を説明します。
表、索引および列の統計は、データ・ディクショナリに格納されます。データ・ディクショナリ内の統計を表示するには、適切なデータ・ディクショナリ・ビューを問い合せます(USER、ALLまたはDBA)。次のようなビューがあります。
DBA_TABLESおよびDBA_OBJECT_TABLES
DBA_TAB_STATISTICSおよびDBA_TAB_COL_STATISTICS
DBA_TAB_HISTOGRAMS
DBA_TAB_COLS
DBA_COL_GROUP_COLUMNS
DBA_INDEXESおよびDBA_IND_STATISTICS
DBA_CLUSTERS
DBA_TAB_PARTITIONSおよびDBA_TAB_SUBPARTITIONS
DBA_IND_PARTITIONSおよびDBA_IND_SUBPARTITIONS
DBA_PART_COL_STATISTICS
DBA_PART_HISTOGRAMS
DBA_SUBPART_COL_STATISTICS
DBA_SUBPART_HISTOGRAMS
|
関連項目: これらのビューの統計の詳細は、『Oracle Databaseリファレンス』を参照してください。 |
列の統計をヒストグラムとして格納できます。これらのヒストグラムは、列データの配分の正確な見積りを提供します。ヒストグラムによって、データが偏っている場合の選択性の見積りの精度が改善され、均一でないデータ配分が存在する最適な実行計画が得られます。
Oracle Databaseでは、列統計に次のタイプのヒストグラムを使用します。
このタイプのヒストグラムは、*TAB_COL_STATISTICSビュー(USERおよびDBA)のHISTOGRAM列に格納されます。この列の値は、HEIGHT BALANCED、FREQUENCYまたはNONEです。
高さ調整済ヒストグラムでは、列値がバケットに分割され、各バケットにほぼ同数の行が存在します。ヒストグラムは、値範囲でのエンドポイントの位置を示します。
値の範囲が1から100で、ヒストグラムが10バケットである列my_colについて考えます。my_colのデータ配分が均一な場合のヒストグラムは、図13-1のようになります。数字はエンドポイントの値です。たとえば、7番目のバケットには、値が60から70の行が含まれます。
各バケットの行数は、全行数の10%です。この均一に配分された例では、60から100の値の行が40%を占めます。
データ配分が均一でない場合のヒストグラムは、図13-2のようになります。この場合、ほとんどの行で、この列の値が5になっています。60から100の間の値を持っている行は、10%のみです。
高さ調整済ヒストグラムは、USER_TAB_HISTOGRAMS表を使用して表示できます(例13-1)。
例13-1 高さ調整済ヒストグラム統計の表示
BEGIN
DBMS_STATS.GATHER_table_STATS (
OWNNAME => 'OE',
TABNAME => 'INVENTORIES',
METHOD_OPT => 'FOR COLUMNS SIZE 10 quantity_on_hand' );
END;
/
SELECT COLUMN_NAME, NUM_DISTINCT, NUM_BUCKETS, HISTOGRAM
FROM USER_TAB_COL_STATISTICS
WHERE TABLE_NAME = 'INVENTORIES' AND COLUMN_NAME = 'QUANTITY_ON_HAND';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
------------------------------ ------------ ----------- ---------------
QUANTITY_ON_HAND 237 10 HEIGHT BALANCED
SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE
FROM USER_TAB_HISTOGRAMS
WHERE TABLE_NAME = 'INVENTORIES' AND COLUMN_NAME = 'QUANTITY_ON_HAND'
ORDER BY ENDPOINT_NUMBER;
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
0 0
1 27
2 42
3 57
4 74
5 98
6 123
7 149
8 175
9 202
10 353
例13-1の問合せ出力では、各行(1から10)はヒストグラムの各バケットに対応しています。Oracle Databaseでは、1番目のバケットの値(27)はquantity_on_hand列の最小値ではないため、このヒストグラムに特殊な0番目のバケットが追加されています。0番目のバケットは、quantity_on_handの最小値0です。
頻度ヒストグラムでは、列の各値がヒストグラムの1つのバケットに対応しています。各バケットには、この単一値の発生数が含まれます。たとえば、warehouse_id列の1の値が、36行に含まれているとします。値が1のエンドポイントのエンドポイント番号は36です。
次の条件に当てはまる場合、高さ調整済ヒストグラムのかわりに頻度ヒストグラムが自動的に作成されます。
個別値の数が、指定されたヒストグラム・バケットの数(最大254)以下である。
各列の値の繰返しが1回のみではない。
頻度ヒストグラムは、USER_TAB_HISTOGRAMSビューを使用して表示できます(例13-2)。
例13-2 頻度ヒストグラム統計の表示
BEGIN
DBMS_STATS.GATHER_TABLE_STATS (
OWNNAME => 'OE',
TABNAME => 'INVENTORIES',
METHOD_OPT => 'FOR COLUMNS SIZE 20 warehouse_id' );
END;
/
SELECT COLUMN_NAME, NUM_DISTINCT, NUM_BUCKETS, HISTOGRAM
FROM USER_TAB_COL_STATISTICS
WHERE TABLE_NAME = 'INVENTORIES' AND COLUMN_NAME = 'WAREHOUSE_ID';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
------------------------------ ------------ ----------- ---------------
WAREHOUSE_ID 9 9 FREQUENCY
SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE
FROM USER_TAB_HISTOGRAMS
WHERE TABLE_NAME = 'INVENTORIES' AND COLUMN_NAME = 'WAREHOUSE_ID'
ORDER BY ENDPOINT_NUMBER;
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
36 1
213 2
261 3
370 4
484 5
692 6
798 7
984 8
1112 9
例13-2の最初のバケットは、warehouse_idが1のバケットです。表の値は36倍で表示されます。これは次の問合せで確認できます。
oe@PROD> SELECT COUNT(*) FROM inventories WHERE warehouse_id = 1;
COUNT(*)
----------
36