| Oracle® Database VLDBおよびパーティショニング・ガイド 11g リリース2 (11.2) B56316-03 |
|



 前 |
 次 |
この章では、パーティション化によって、可用性、管理性およびパフォーマンスの効果がどのように上がるかについて概要を説明します。また、特定のパーティション化計画をいつ使用するべきかのガイドラインを示します。表のパーティション化を中心に説明しますが、ほとんどの推奨事項および考慮事項は索引のパーティション化にも適用できます。
この章では次の項について説明します。
パーティション・プルーニングは、データ・ウェアハウスの重要なパフォーマンス機能です。パーティション・プルーニングでは、オプティマイザによりSQL文のFROM句とWHERE句が分析され、パーティション・アクセス・リストを構築するときに不要なパーティションが削除されます。この機能によって、Oracle Databaseは、SQL文に関連するパーティションに限定して処理を実行できるようになります。
この項の内容は次のとおりです。
パーティション・プルーニングを行うと、ディスクから取得するデータ容量が大幅に削減され、処理時間が短縮します。このため、問合せのパフォーマンスが向上し、リソース使用率が最適化されます。グローバルなパーティション索引を使用して異なる列の索引および表をパーティション化する場合は、基礎となる表が排除できない場合でもパーティション・プルーニングにより索引パーティションが排除されます。
実際のSQL文に応じて、Oracle Databaseにより静的プルーニングおよび動的プルーニングが使用されます。静的プルーニングは、事前にアクセスしたパーティションの情報を使用してコンパイル時に行われます。動的プルーニングは実行時に行われます。つまり、文がアクセスする正確なパーティションは事前にはわかりません。静的プルーニングのサンプルの使用例は、パーティション・キー列に固定リテラルがあるWHERE条件を含むSQL文です。動的プルーニングの例は、WHERE条件内の演算子または関数の使用です。
パーティション・プルーニングは、プルーニングが行われるオブジェクトの統計に影響します。また文の実行計画にも影響します。
Oracle Databaseでパーティション・プルーニングが行われるのは、レンジ・パーティション化列またはリスト・パーティション化列で、範囲述語、LIKE述語、等価述語、INリスト述語を使用したとき、またハッシュ・パーティション化列で等価述語およびINリスト述語を使用したときです。
コンポジット・パーティション化されたオブジェクトでは、Oracle Databaseは関連する述語を使用して両方のレベルでプルーニングを実行できます。例3-1の表sales_range_hashを確認してください。これは、列s_saledateでレンジ・パーティション化され、列s_productidでハッシュ・サブパーティション化されています。
例3-1 パーティション・プルーニングによる表の作成
CREATE TABLE sales_range_hash(
s_productid NUMBER,
s_saledate DATE,
s_custid NUMBER,
s_totalprice NUMBER)
PARTITION BY RANGE (s_saledate)
SUBPARTITION BY HASH (s_productid) SUBPARTITIONS 8
(PARTITION sal99q1 VALUES LESS THAN
(TO_DATE('01-APR-1999', 'DD-MON-YYYY')),
PARTITION sal99q2 VALUES LESS THAN
(TO_DATE('01-JUL-1999', 'DD-MON-YYYY')),
PARTITION sal99q3 VALUES LESS THAN
(TO_DATE('01-OCT-1999', 'DD-MON-YYYY')),
PARTITION sal99q4 VALUES LESS THAN
(TO_DATE('01-JAN-2000', 'DD-MON-YYYY')));
SELECT * FROM sales_range_hash
WHERE s_saledate BETWEEN (TO_DATE('01-JUL-1999', 'DD-MON-YYYY'))
AND (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')) AND s_productid = 1200;
パーティション列に対する述語を使用して、次のようにパーティション・プルーニングが行われます。
レンジ・パーティション化を使用して、1999年の第3四半期と第4四半期に相当するパーティションsal99q2とsal99q3のみにアクセスします。
ハッシュ・サブパーティション化を使用して、各パーティションで、s_productid=1200の行を格納する1つのサブパーティションのみにアクセスします。サブパーティションと述語のマッピングは、Oracle内部のハッシュ分散関数に基づいて計算されます。
参照パーティション表では、参照表の結合を介してパーティション・プルーニングを利用できます。仮想列に基づくパーティション表では、仮想列定義式を使用するSQL文でパーティション・プルーニングを利用できます。
Oracleがパーティション・プルーニングを使用するかどうかは、EXPLAIN PLAN文の計画表または共有SQL領域にある文の実行計画に示されます。
パーティション・プルーニング情報は、計画列PSTART (PARTITION_START)およびPSTOP (PARTITION_STOP)に反映されます。シリアル文の場合、プルーニング情報はOPERATION列とOPTIONS列にも反映されます。
|
関連項目: EXPLAIN PLANとその解釈方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
多くの場合、Oracleはコンパイル時にアクセスするパーティションを決定します。静的パーティション・プルーニングが行われるのは、静的な述語を使用したときですが、次の場合を除きます。
副問合せの結果を使用してパーティション・プルーニングが行われる場合。
オプティマイザがスター型変換を使用して問合せを再作成し、スター型変換の後でプルーニングが行われる場合。
最も有効な実行計画がネステッド・ループである場合。
これら3つの場合には、動的プルーニングが使用されます。
解析時にOracleが、隣接するどのパーティション・セットがアクセスされるかを識別できると、実行計画のPSTART列とPSTOP列に、アクセスされるパーティションの開始値と終了値が示されます。動的プルーニングを含む他のパーティション・プルーニングでは、PSTARTおよびPSTOPのKEY値と、オプションでその他の属性が表示されます。
次に例を示します。
SQL> explain plan for select * from sales where time_id = to_date('01-jan-2001', 'dd-mon-yyyy');
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------
Plan hash value: 3971874201
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 673 | 19517 | 27 (8)| 00:00:01 | | |
| 1 | PARTITION RANGE SINGLE| | 673 | 19517 | 27 (8)| 00:00:01 | 17 | 17 |
|* 2 | TABLE ACCESS FULL | SALES | 673 | 19517 | 27 (8)| 00:00:01 | 17 | 17 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("TIME_ID"=TO_DATE('2001-01-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
この計画では、PSTART列とPSTOP列に示されているようにOracleがパーティション番号17にアクセスします。OPERATION列にPARTITION RANGE SINGLEとあり、1つのパーティションのみにアクセスすることを示します。OPERATIONにPARTITION RANGE ALLと表示されている場合は、すべてのパーティションにアクセスし、実質的にはプルーニングは行われません。このとき、PSTARTには表の最初のパーティションが示され、PSTOPには最後のパーティションが示されます。
時間隔パーティション表の全表スキャンを含む実行計画では、作成された時間隔パーティションの数にかかわらず、PSTARTに1、PSTOPに1048575が示されます。
動的プルーニングが行われるのは、プルーニングが可能で、静的プルーニングが不可能な場合です。次に動的プルーニングのいくつかの例を示します。
パーティション列に対してバインド変数を使用する文では、動的プルーニングが行われます。次に例を示します。
SQL> explain plan for select * from sales s where time_id in ( :a, :b, :c, :d);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------
Plan hash value: 513834092
---------------------------------------------------------------------------------------------------
| Id | Operation | Name |Rows|Bytes|Cost (%CPU)| Time | Pstart| Pstop|
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | |2517|72993| 292 (0)|00:00:04| | |
| 1 | INLIST ITERATOR | | | | | | | |
| 2 | PARTITION RANGE ITERATOR | |2517|72993| 292 (0)|00:00:04|KEY(I) |KEY(I)|
| 3 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |2517|72993| 292 (0)|00:00:04|KEY(I) |KEY(I)|
| 4 | BITMAP CONVERSION TO ROWIDS | | | | | | | |
|* 5 | BITMAP INDEX SINGLE VALUE |SALES_TIME_BIX| | | | |KEY(I) |KEY(I)|
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("TIME_ID"=:A OR "TIME_ID"=:B OR "TIME_ID"=:C OR "TIME_ID"=:D)
パラレル実行計画では、次の例のようにpstart列とpstop列のみにパーティション・プルーニング情報が含まれ、operation列にはパラレル操作の情報が含まれます。
SQL> explain plan for select * from sales where time_id in (:a, :b, :c, :d);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------
Plan hash value: 4058105390
-------------------------------------------------------------------------------------------------
| Id| Operation | Name |Rows|Bytes|Cost(%CP| Time |Pstart| Pstop| TQ |INOUT| PQ Dis|
-------------------------------------------------------------------------------------------------
| 0| SELECT STATEMENT | |2517|72993| 75(36)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM)|:TQ10000|2517|72993| 75(36)|00:00:01| | |Q1,00| P->S|QC(RAND|
| 3| PX BLOCK ITERATOR| |2517|72993| 75(36)|00:00:01|KEY(I)|KEY(I)|Q1,00| PCWC| |
|* 4| TABLE ACCESS FULL| SALES |2517|72993| 75(36)|00:00:01|KEY(I)|KEY(I)|Q1,00| PCWP| |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("TIME_ID"=:A OR "TIME_ID"=:B OR "TIME_ID"=:C OR "TIME_ID"=:D)
|
関連項目: EXPLAIN PLANとその解釈方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
パーティション列に対して明示的に副問合せを使用する文では、動的プルーニングが行われます。次に例を示します。
SQL> explain plan for select sum(amount_sold) from sales where time_id in
(select time_id from times where fiscal_year = 2000);
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 3827742054
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 25 | 523 (5)| 00:00:07 | | |
| 1 | SORT AGGREGATE | | 1 | 25 | | | | |
|* 2 | HASH JOIN | | 191K| 4676K| 523 (5)| 00:00:07 | | |
|* 3 | TABLE ACCESS FULL | TIMES | 304 | 3648 | 18 (0)| 00:00:01 | | |
| 4 | PARTITION RANGE SUBQUERY| | 918K| 11M| 498 (4)| 00:00:06 |KEY(SQ)|KEY(SQ)|
| 5 | TABLE ACCESS FULL | SALES | 918K| 11M| 498 (4)| 00:00:06 |KEY(SQ)|KEY(SQ)|
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("TIME_ID"="TIME_ID")
3 - filter("FISCAL_YEAR"=2000)
|
関連項目: EXPLAIN PLANとその解釈方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
データベースによってスター型変換を使用して変換される文では、動的なプルーニングが行われます。次に例を示します。
SQL> explain plan for select p.prod_name, t.time_id, sum(s.amount_sold)
from sales s, times t, products p
where s.time_id = t.time_id and s.prod_id = p.prod_id and t.fiscal_year = 2000
and t.fiscal_week_number = 3 and p.prod_category = 'Hardware'
group by t.time_id, p.prod_name;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------
Plan hash value: 4020965003
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Pstart| Pstop |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 79 | | |
| 1 | HASH GROUP BY | | 1 | 79 | | |
|* 2 | HASH JOIN | | 1 | 79 | | |
|* 3 | HASH JOIN | | 2 | 64 | | |
|* 4 | TABLE ACCESS FULL | TIMES | 6 | 90 | | |
| 5 | PARTITION RANGE SUBQUERY | | 587 | 9979 |KEY(SQ)|KEY(SQ)|
| 6 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES | 587 | 9979 |KEY(SQ)|KEY(SQ)|
| 7 | BITMAP CONVERSION TO ROWIDS | | | | | |
| 8 | BITMAP AND | | | | | |
| 9 | BITMAP MERGE | | | | | |
| 10 | BITMAP KEY ITERATION | | | | | |
| 11 | BUFFER SORT | | | | | |
|* 12 | TABLE ACCESS FULL | TIMES | 6 | 90 | | |
|* 13 | BITMAP INDEX RANGE SCAN | SALES_TIME_BIX | | |KEY(SQ)|KEY(SQ)|
| 14 | BITMAP MERGE | | | | | |
| 15 | BITMAP KEY ITERATION | | | | | |
| 16 | BUFFER SORT | | | | | |
| 17 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 14 | 658 | | |
|* 18 | INDEX RANGE SCAN | PRODUCTS_PROD_CAT_IX | 14 | | | |
|* 19 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX | | |KEY(SQ)|KEY(SQ)|
| 20 | TABLE ACCESS BY INDEX ROWID | PRODUCTS | 14 | 658 | | |
|* 21 | INDEX RANGE SCAN | PRODUCTS_PROD_CAT_IX | 14 | | | |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="P"."PROD_ID")
3 - access("S"."TIME_ID"="T"."TIME_ID")
4 - filter("T"."FISCAL_WEEK_NUMBER"=3 AND "T"."FISCAL_YEAR"=2000)
12 - filter("T"."FISCAL_WEEK_NUMBER"=3 AND "T"."FISCAL_YEAR"=2000)
13 - access("S"."TIME_ID"="T"."TIME_ID")
18 - access("P"."PROD_CATEGORY"='Hardware')
19 - access("S"."PROD_ID"="P"."PROD_ID")
21 - access("P"."PROD_CATEGORY"='Hardware')
Note
-----
- star transformation used for this statement
|
注意: Cost (%CPU)列とTime列は、この例の計画表の出力では削除されています。 |
|
関連項目: EXPLAIN PLANとその解釈方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
ネステッド・ループ結合を使用すると最も効率的に実行される文では、動的プルーニングが使用されます。次に例を示します。
SQL> explain plan for select t.time_id, sum(s.amount_sold)
from sales s, times t
where s.time_id = t.time_id and t.fiscal_year = 2000 and t.fiscal_week_number = 3
group by t.time_id;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 50737729
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 168 | 126 (4)| 00:00:02 | | |
| 1 | HASH GROUP BY | | 6 | 168 | 126 (4)| 00:00:02 | | |
| 2 | NESTED LOOPS | | 3683 | 100K| 125 (4)| 00:00:02 | | |
|* 3 | TABLE ACCESS FULL | TIMES | 6 | 90 | 18 (0)| 00:00:01 | | |
| 4 | PARTITION RANGE ITERATOR| | 629 | 8177 | 18 (6)| 00:00:01 | KEY | KEY |
|* 5 | TABLE ACCESS FULL | SALES | 629 | 8177 | 18 (6)| 00:00:01 | KEY | KEY |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("T"."FISCAL_WEEK_NUMBER"=3 AND "T"."FISCAL_YEAR"=2000)
5 - filter("S"."TIME_ID"="T"."TIME_ID")
|
関連項目: EXPLAIN PLANとその解釈方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
パーティション・プルーニングを使用するときは、次の点を考慮する必要があります。
パーティション・プルーニングから最大限のパフォーマンスを得るには、データベースによって変換が必要となるデータ型を指定しないようにしてください。データ型が変換されると、その他の点で静的プルーニングが可能な場合でも、通常は動的プルーニングが行われます。静的プルーニングを利用するSQL文は、動的プルーニングを利用するSQL文よりもパフォーマンスが高くなります。
OracleのDATEデータ型を使用すると、一般的なデータ型変換が行われます。OracleのDATEデータ型は文字列ではありませんが、データベースを問い合せたときに文字列のように表示されます。表示形式はインスタンスまたはセッションのNLS設定で定義されます。したがって、データをDATEフィールドに挿入するとき、またはそのようなフィールドに述語を指定するとき、同じ変換を逆向きに実行する必要があります。
変換は暗黙に実行するか、TO_DATE変換を指定して明示的に実行することができます。TO_DATE関数を適切に適用した場合のみ、データベースが一意に日付値を判別して、その値を静的プルーニングに潜在的に使用できるようになります。これは、1つのパーティションにアクセスするために特に役立ちます。
Oracle DatabaseのサンプルSHスキーマに対して実行する次の例を考えてください。2000年の合計収益を問い合せる場合があります。この問合せの結果を取得する方法はたくさんありますが、すべての方法の効率が同じではありません。
explain plan for SELECT SUM(amount_sold) total_revenue FROM sales, WHERE time_id between '01-JAN-00' and '31-DEC-00';
計画は次のようになります。
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 525 (8)| 00:00:07 | | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | | |
|* 2 | FILTER | | | | | | | |
| 3 | PARTITION RANGE ITERATOR| | 230K| 2932K| 525 (8)| 00:00:07 | KEY | KEY |
|* 4 | TABLE ACCESS FULL | SALES | 230K| 2932K| 525 (8)| 00:00:07 | KEY | KEY |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE('01-JAN-00')<=TO_DATE('31-DEC-00'))
4 - filter("TIME_ID">='01-JAN-00' AND "TIME_ID"<='31-DEC-00')
この場合、PSTARTとPSTOP両方のキーワードKEYは、動的パーティション・プルーニングが実行時に行われることを示します。次の例について考えてみます。
explain plan for select sum(amount_sold) from sales where time_id between '01-JAN-2000' and '31-DEC-2000' ;
この実行計画は次のようになります。
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 127 (4)| | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | |
| 2 | PARTITION RANGE ITERATOR| | 230K| 2932K| 127 (4)| 13 | 16 |
|* 3 | TABLE ACCESS FULL | SALES | 230K| 2932K| 127 (4)| 13 | 16 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', "syyyy-mm-dd hh24:mi:ss'))
|
注意: Time列は、この実行計画からは削除されています。 |
この実行計画では静的パーティション・プルーニングが示されます。問合せは、隣接するパーティション13から16にアクセスします。この場合は、日付形式の指定方法が、NLS日付形式の設定と一致しています。この例では最も効果的な実行計画が示されていますが、NLS日付形式設定を利用して特定の形式を定義することはできません。
alter session set nls_date_format='fmdd Month yyyy'; explain plan for select sum(amount_sold) from sales where time_id between '01-JAN-2000' and '31-DEC-2000' ;
この実行計画は次のようになります。
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 525 (8)| | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | |
|* 2 | FILTER | | | | | | |
| 3 | PARTITION RANGE ITERATOR| | 230K| 2932K| 525 (8)| KEY | KEY |
|* 4 | TABLE ACCESS FULL | SALES | 230K| 2932K| 525 (8)| KEY | KEY |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE('01-JAN-2000')<=TO_DATE('31-DEC-2000'))
4 - filter("TIME_ID">='01-JAN-2000' AND "TIME_ID"<='31-DEC-2000')
|
注意: Time列は、この実行計画からは削除されています。 |
動的プルーニングを使用するこの計画は、静的プルーニングの実行計画よりも効率が悪くなります。静的パーティション・プルーニング計画を保証するには、パーティション列のデータ型と一致するようにデータ型を明示的に変換する必要があります。次に例を示します。
explain plan for select sum(amount_sold)
from sales
where time_id between to_date('01-JAN-2000','dd-MON-yyyy')
and to_date('31-DEC-2000','dd-MON-yyyy') ;
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 127 (4)| | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | |
| 2 | PARTITION RANGE ITERATOR| | 230K| 2932K| 127 (4)| 13 | 16 |
|* 3 | TABLE ACCESS FULL | SALES | 230K| 2932K| 127 (4)| 13 | 16 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
|
注意: Time列は、この実行計画からは削除されています。 |
|
関連項目:
|
オプティマイザがプルーニングを実行できない場合がいくつかあります。一般的な理由の1つは、パーティション列に対する演算子の使用です。これには、明示的な演算子(たとえば関数)も、文を実行するために必要なデータ型変換の一環としてOracleが導入した暗黙の演算子も該当します。たとえば、次の問合せについて考えてみます。
EXPLAIN PLAN FOR
SELECT SUM(quantity_sold)
FROM sales
WHERE time_id = TO_TIMESTAMP('1-jan-2000', 'dd-mon-yyyy');
time_idはDATE型ですが、Oracleは同じデータ型を取得するためにTIMESTAMP型に変換する必要があるため、この述語は内部で次のように変更されます。
TO_TIMESTAMP(time_id) = TO_TIMESTAMP('1-jan-2000', 'dd-mon-yyyy')
この文の実行計画は次のとおりです。
--------------------------------------------------------------------------------------------
|Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 11 | 6 (17)| 00:00:01 | | |
| 1 | SORT AGGREGATE | | 1 | 11 | | | | |
| 2 | PARTITION RANGE ALL| | 10 | 110 | 6 (17)| 00:00:01 | 1 | 16 |
|*3 | TABLE ACCESS FULL | SALES | 10 | 110 | 6 (17)| 00:00:01 | 1 | 16 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(INTERNAL_FUNCTION("TIME_ID")=TO_TIMESTAMP('1-jan-2000',:B1))
15 rows selected
このSELECT文は、プルーニングによって1つのパーティションが限定される場合でも、すべてのパーティションにアクセスします。2000年の合計売上高を調べる例を考えてみます。問合せを構成するもう1つの方法は、次のとおりです。
EXPLAIN PLAN FOR SELECT SUM(amount_sold) FROM sales WHERE TO_CHAR(time_id,'yyyy') = '2000';
この問合せは関数コールをパーティション・キー列に適用します。通常はこのためにパーティション・プルーニングが無効になります。実行計画では全表スキャンが示され、パーティション・プルーニングはありません。
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 527 (9)| 00:00:07 | | |
| 1 | SORT AGGREGATE | | 1 | 13 | | | | |
| 2 | PARTITION RANGE ALL| | 9188 | 116K| 527 (9)| 00:00:07 | 1 | 28 |
|* 3 | TABLE ACCESS FULL | SALES | 9188 | 116K| 527 (9)| 00:00:07 | 1 | 28 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(TO_CHAR(INTERNAL_FUNCTION("TIME_ID"),'yyyy')='2000')
パーティション列に対しては暗黙的にも明示的にも関数を使用しないことをお薦めします。問合せがよく関数コールを使用する場合は、このようなケースでパーティション・プルーニングを利用できるように仮想列と仮想列パーティション化の使用を検討してください。
次の例は、EXPLAIN PLAN文がコレクション表を含むときに、どのように表示されるかを示します(コレクション表は、ここでは便宜上、ソートされたコレクション表またはネスト表とします)。これは、「XMLTypeおよびオブジェクトのコレクションのパーティション化」のCREATE TABLE文に基づいています。該当するパーティションのみに制約されるため、全表アクセスは実行されないことに注意してください。
EXPLAIN PLAN FOR SELECT p.ad_textdocs_ntab FROM print_media_part p; Explained. PLAN_TABLE_OUTPUT ----------------------------------------------------------------------- Plan hash value: 2207588228 ----------------------------------------------------------------------- | Id | Operation | Name | Pstart| Pstop | ----------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | 1 | PARTITION REFERENCE SINGLE| | KEY | KEY | | 2 | TABLE ACCESS FULL | TEXTDOC_NT | KEY | KEY | | 3 | PARTITION RANGE ALL | | 1 | 2 | | 4 | TABLE ACCESS FULL | PRINT_MEDIA_PART | 1 | 2 | ----------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement
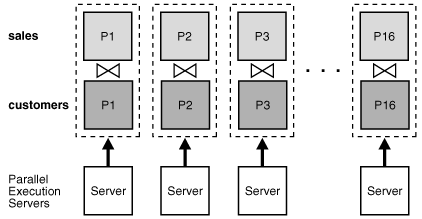
パーティション・ワイズ結合では、結合がパラレルで実行されるときにパラレル実行サーバー間で交換されるデータ量が最小限に抑えられ、問合せのレスポンス時間が短縮されます。レスポンス時間は大幅に短縮され、CPUとメモリー・リソースの使用率が改善されます。Oracle Real Application Clusters (Oracle RAC)環境では、パーティション・ワイズ結合でも、インターコネクトでのデータ・トラフィックが回避されるか、少なくとも制限されます。これは、大規模な結合操作で優れたスケーラビリティを実現するために重要です。
パーティション・ワイズ結合では、フル(完全)またはパーシャル(部分)を選択できます。どちらの種類の結合を使用するかはOracle Databaseによって判別されます。
この項の内容は次のとおりです。
フル・パーティション・ワイズ結合では、結合される2つの表の対のパーティション間で、大きな結合が小さな結合に分割されます。この機能を使用するには、両方の表を結合キーで同一レベルでパーティション化するか、参照パーティション化を使用する必要があります。たとえば、sales表とcustomer表の列cust_idによる大規模な結合について考えてみます。例3-2に示す、「1999年の第3四半期に品物の購入数が100を超えたすべての顧客のレコードを検索する」という問合せは、このような結合を実行するSQL文の典型的な例です。
例3-2 フル・パーティション・ワイズ結合による問合せ
SELECT c.cust_last_name, COUNT(*)
FROM sales s, customers c
WHERE s.cust_id = c.cust_id AND
s.time_id BETWEEN TO_DATE('01-JUL-1999', 'DD-MON-YYYY') AND
(TO_DATE('01-OCT-1999', 'DD-MON-YYYY'))
GROUP BY c.cust_last_name HAVING COUNT(*) > 100;
このような大規模な結合は、データ・ウェアハウス環境ではよく行われます。この場合、customer表全体が1四半期分のsalesデータに結合されます。大規模なデータ・ウェアハウス・アプリケーションの場合には、数百万行の結合を意味することもあります。ここは明らかにハッシュ結合が使用されます。両方の表がcust_id列で同一レベル・パーティション化されている場合は、このハッシュ結合の処理時間をさらに短縮できます。この機能によりフル・パーティション・ワイズ結合が使用可能になります。
フル・パーティション・ワイズ結合をパラレルで実行するとき、パラレル化のグラニュルはパーティションです。このため、並列度はパーティション数に制限されます。たとえば、問合せの並列度を16に設定するには少なくとも16のパーティションが必要です。
2つの表を同一レベル・パーティション化するには様々なパーティション化方法を使用できます。これらの方法の概要を次の項で説明します。
これは最も単純な方法です。2つの表が両方とも結合列によってパーティション化されます。例では、customers表とsales表の両方がcust_id列でパーティション化されます。このパーティション化方法では、表をcust_id (両方とも同じ顧客ID番号を表す)で結合するフル・パーティション・ワイズ結合が有効になります。このシナリオは、レンジ - レンジ、リスト - リストおよびハッシュ - ハッシュ・パーティション化に対応します。時間隔 - レンジおよび時間隔 - 時間隔のフル・パーティション・ワイズ結合もサポートされ、レンジ - レンジと比較できます。
シリアルでは、この結合は、ハッシュ・パーティションの一致する組の間で、1回ずつ順番に実行されます。1組のパーティションが結合されると、別の組の結合が開始されます。すべてのパーティションの組が処理されると、結合が完了します。作業負荷を均等に分散するためには、要求した並列度よりも多数のパーティションを使用するか、要求した並列度と同数の同一サイズ・パーティションを使用する必要があります。同一サイズ・パーティションを作成するには、パーティション数を2の累乗として、一意の列(またはほぼ一意の列)に対してハッシュ・パーティション化を使用することをお薦めします。
|
注意:
|
フル・パーティション・ワイズ結合のパラレル実行は、シリアル実行を単にパラレル化したものです。パーティションが1組ずつ結合されるかわりに、問合せサーバーによってパーティションの複数の組がパラレルに結合されます。図3-1に、フル・パーティション・ワイズ結合のパラレル実行を示します。
次の例は、同数のパーティションを含むようにハッシュで同等にパーティション化されたsalesとcustomersの実行計画を示します。この計画はフル・パーティション・ワイズ結合を示しています。
explain plan for SELECT c.cust_last_name, COUNT(*)
FROM sales s, customers c
WHERE s.cust_id = c.cust_id AND
s.time_id BETWEEN TO_DATE('01-JUL-1999', 'DD-MON-YYYY') AND
(TO_DATE('01-OCT-1999', 'DD-MON-YYYY'))
GROUP BY c.cust_last_name HAVING COUNT(*) > 100;
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 46 | 1196 | | | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 46 | 1196 | | | Q1,01 | P->S | QC (RAND) |
|* 3 | FILTER | | | | | | Q1,01 | PCWC | |
| 4 | HASH GROUP BY | | 46 | 1196 | | | Q1,01 | PCWP | |
| 5 | PX RECEIVE | | 46 | 1196 | | | Q1,01 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | 46 | 1196 | | | Q1,00 | P->P | HASH |
| 7 | HASH GROUP BY | | 46 | 1196 | | | Q1,00 | PCWP | |
| 8 | PX PARTITION HASH ALL| | 59158 | 1502K| 1 | 16 | Q1,00 | PCWC | |
|* 9 | HASH JOIN | | 59158 | 1502K| | | Q1,00 | PCWP | |
| 10 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 704K| 1 | 16 | Q1,00 | PCWP | |
|* 11 | TABLE ACCESS FULL | SALES | 59158 | 751K| 1 | 16 | Q1,00 | PCWP | |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
9 - access("S"."CUST_ID"="C"."CUST_ID")
11 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
|
注意: Cost (%CPU)列とTime列は、この例の計画表の出力では削除されています。 |
超並列処理(MPP)プラットフォームで実行されているOracle RAC環境で適切なスケーラビリティを得るには、パーティションをノード上に配置することが重要です。リモートI/Oを回避するには、一致する2つのパーティションが、同じノードに対してアフィニティを持っている必要があります。ボトルネックを回避し、システムで使用可能なすべてのCPUリソースを使用するために、パーティションの組がすべてのノードに分散される必要があります。
ノードの数よりパーティションの組の数が多い場合は、ノードで複数の組を管理できます。たとえば、ノード数が8のシステムでパーティションが16組ある場合は、各ノードが2組のパーティションに対応します。
|
関連項目: データ・アフィニティの詳細は、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』を参照してください。 |
この方法は、単一レベル-単一レベル方法の一種です。このシナリオでは、1つの表(通常は大きい方の表)が2つのディメンションでコンポジット・パーティション化され、サブパーティション・キーとして結合列が使用されます。この例ではsales表が、履歴データを格納する表の一般的な例です。レンジ・パーティション化は、履歴情報を格納する表に対して、通常最初に行うパーティション化方法です。
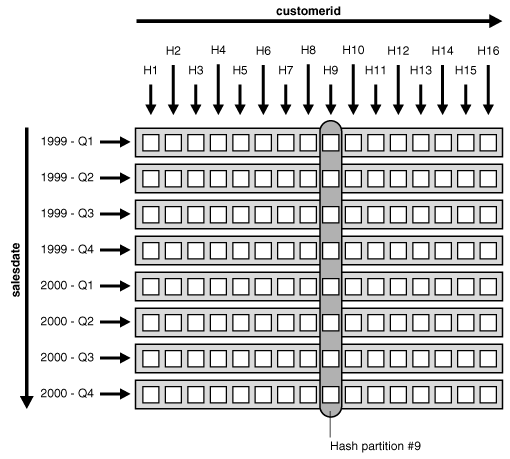
たとえば、sales表を列time_idの範囲によって8個のパーティションにパーティション化するとします。また、2年分のデータがあり、各パーティションは四半期を表します。レンジ・パーティション化のかわりに、コンポジット・パーティション化を使用して、time_idでのパーティション化を維持しながらフル・パーティション・ワイズ結合を有効にすることができます。たとえば、sales表をtime_idの範囲でパーティション化し、各パーティションを16個のサブパーティションを使用してcust_idのハッシュでサブパーティション化します(サブパーティションの合計は128個)。customers表は、16パーティションでのハッシュ・パーティション化を使用できます。
ここで説明した方法を使用すると、フル・パーティション・ワイズ結合は、単一レベル-単一レベルのハッシュ-ハッシュ方法と同様に動作します。また、結合も、両方の表のハッシュ・パーティションの組の間で、16の小規模な結合に分割されます。違いは、sales表の各ハッシュ・パーティションが、各レンジ・パーティションから1つずつ、8つのサブパーティションの集合で構成されているということです。
図3-2は、sales表でハッシュ・パーティション化がどのように実現されるかを示します。各セルがサブパーティションを表します。全体で8個のレンジ・パーティションがあり、各行は1つのレンジ・パーティションに対応します。各レンジ・パーティションには16個のサブパーティションがあります。全体で16個のハッシュ・パーティションがあり、各列は1つのハッシュ・パーティションに対応します。各ハッシュ・パーティションには8個のサブパーティションがあります。ハッシュ・パーティションを定義できるのは、すべてのパーティションに同数のサブパーティション(ここでは16個)がある場合のみです。
ハッシュ・パーティションはコンポジット表では暗黙的に扱われます。ただし、データ・ディクショナリには記録されず、レンジ・パーティションやリスト・パーティションのようにDDLコマンドを使用して処理することはできません。
次の例では、sales表のフル・パーティション・ワイズ結合の実行計画が示されます。この表は、time_idについてレンジ・パーティション化され、cust_idについてハッシュでサブパーティション化されています。
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Pstart| Pstop |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | | | P->S | QC (RAND) |
|* 3 | FILTER | | | | PCWC | |
| 4 | HASH GROUP BY | | | | PCWP | |
| 5 | PX RECEIVE | | | | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | | | P->P | HASH |
| 7 | HASH GROUP BY | | | | PCWP | |
| 8 | PX PARTITION HASH ALL | | 1 | 16 | PCWC | |
|* 9 | HASH JOIN | | | | PCWP | |
| 10 | TABLE ACCESS FULL | CUSTOMERS | 1 | 16 | PCWP | |
| 11 | PX PARTITION RANGE ITERATOR| | 8 | 9 | PCWC | |
|* 12 | TABLE ACCESS FULL | SALES | 113 | 144 | PCWP | |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
9 - access("S"."CUST_ID"="C"."CUST_ID")
12 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
|
注意: Rows列、Cost (%CPU)列、Time列およびTQ列は、この例の計画表の出力では削除されています。 |
コンポジット-単一レベルのパーティション化が効率的なのは、あるディメンションではプルーニングを行い、別のディメンションではフル・パーティション・ワイズ結合を行えるためです。前述の問合せの例では、1999年の第3四半期に相当するサブパーティション(図3-2の3番目の行)のみをスキャンして、プルーニングが実現されます。Oracleによって、フル・パーティション・ワイズ結合が使用され、これらのサブパーティションがcustomer表と結合されます。
単一レベル-単一レベルのパーティション・ワイズ結合のすべての特性は、コンポジット-単一レベルのパーティション・ワイズ結合にも該当します。特に、この例では、2つの方法は次の2つの点で共通しています。
この場合のフル・パーティション・ワイズ結合の並列度は、16を超えることはありません。sales表に128のサブパーティションがあっても、ハッシュ・パーティションは16のみであるためです。
MPPシステムでのデータ配置と同じルールが適用されます。違いは、サブパーティションがサブパーティションの集合であることのみです。これらのすべてのサブパーティションを、他の表の一致するハッシュ・パーティションと同じノードに配置する必要があります。たとえば、図3-2では、sales表のハッシュ・パーティション9(楕円で囲まれた8つのサブパーティション)をcustomers表のハッシュ・パーティション9と同じノードに格納します。
必要に応じて、customers表をコンポジット方法でパーティション化することもできます。たとえば、郵便番号の列についてこの表をレンジ・パーティション化して、郵便番号に基づくプルーニングを使用可能にできます。その後、同数(16)のパーティションを使用し、cust_idについてハッシュでサブパーティション化し、ハッシュ・ディメンションでパーティション・ワイズ結合を使用可能にします。
フル・パーティション・ワイズ結合は、パーティションとサブパーティションのすべての組合せ(パーティションとパーティション、パーティションとサブパーティション、サブパーティションとパーティション、サブパーティションとサブパーティション)で行うことができます。
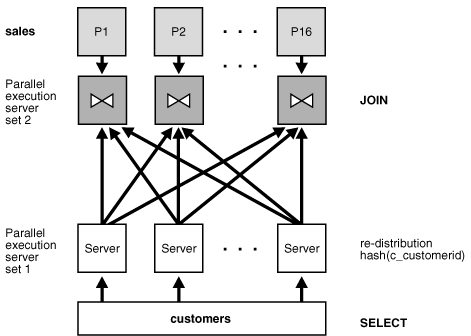
Oracle Databaseでは、パラレル時のみパーシャル・パーティション・ワイズ結合が実行できます。フル・パーティション・ワイズ結合と異なり、パーシャル・パーティション・ワイズ結合では、両方の表ではなく、一方の表のみを結合キーでパーティション化する必要があります。パーティション化された表は、参照表と呼ばれます。もう一方の表は、パーティション化してもしなくてもかまいません。パーシャル・パーティション・ワイズ結合は、フル・パーティション・ワイズ結合よりも一般的です。
パーシャル・パーティション・ワイズ結合を実行するために、データベースによって、参照表のパーティション化に基づいて、もう一方の表が動的に再パーティション化されます。もう一方の表が再パーティション化された後は、フル・パーティション・ワイズ結合と同様に実行されます。
パーシャル・パーティション・ワイズ結合が、非パーティション表の結合よりパフォーマンス上でメリットがあるのは、結合操作の間に参照表が移動しないことです。非パーティション表間のパラレル結合では、両方の入力表を結合キーについて再分散する必要があります。この再分散操作には、パラレル実行サーバー間での行の交換が伴います。これはCPU集中型の操作であり、Oracle RAC環境ではインターコネクト・トラフィックが増大する原因になります。結合キー(外部キーまたは主キー)で大規模な表をパーティション化すると、そのキーで表を結合するたびにこの再分散が発生することを防止できます。ただし、外部キーで表をパーティション化する場合(最も一般的な場合)は、多くの問合せに含まれる外部キーを選択する必要があります。
パーシャル・パーティション・ワイズ結合を説明するために、前のsales/customersの例を使用します。customersがパーティション化されていないか、cust_id以外の列でパーティション化されているとします。salesは多くの場合cust_idでcustomersと結合されることが多く、この結合がアプリケーションのワークロードを占有します。このため、salesをcust_idでパーティション化して、customersとsalesが結合されるたびに、パーシャル・パーティション・ワイズ結合が使用可能になるようにします。フル・パーティション・ワイズ結合と同じく、次に示す他の方法もあります。
パーシャル・パーティション・ワイズ結合を使用可能にする最も簡単な方法は、sales表をcust_idでハッシュ・パーティション化することです。パーティションは、パーシャル・パーティション・ワイズ結合操作におけるパラレル化の最小グラニュルであるため、並列度の最大値はパーティションの数によって決定されます。
パーシャル・パーティション・ワイズ結合のパラレル実行を図3-3に示します。ここでは、並列度とsalesのパーティション数はどちらも16です。この実行では、2つのセットの問合せサーバーが使用されます。図3-3のセット1はcustomers表をパラレルでスキャンします。スキャン操作のパラレル化のグラニュルはブロックの範囲です。
セット1によって選択されたcustomers表の行(この場合はすべての行)は、cust_idをハッシュすることで、セット2の問合せサーバーに再分散されます。たとえば、sales表のパーティションP1の行と一致する可能性があるcustomers表の行はすべて、セット2の問合せサーバー1に送られます。セット2の問合せサーバーが受け取った行は、sales表にある対応するパーティションの行と結合されます。セット2の問合せサーバー1は、受け取ったcustomers表のすべての行とsales表のパーティションP1を結合します。
次の例に、sales表とcustomers表のパーシャル・パーティション・ワイズ結合の実行計画を示します。
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Pstart| Pstop |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | | | P->S | QC (RAND) |
|* 3 | FILTER | | | | PCWC | |
| 4 | HASH GROUP BY | | | | PCWP | |
| 5 | PX RECEIVE | | | | PCWP | |
| 6 | PX SEND HASH | :TQ10001 | | | P->P | HASH |
| 7 | HASH GROUP BY | | | | PCWP | |
|* 8 | HASH JOIN | | | | PCWP | |
| 9 | PART JOIN FILTER CREATE | :BF0000 | | | PCWP | |
| 10 | PX RECEIVE | | | | PCWP | |
| 11 | PX SEND PARTITION (KEY) | :TQ10000 | | | P->P | PART (KEY) |
| 12 | PX BLOCK ITERATOR | | | | PCWC | |
| 13 | TABLE ACCESS FULL | CUSTOMERS | | | PCWP | |
| 14 | PX PARTITION HASH JOIN-FILTER| |:BF0000|:BF0000| PCWC | |
|* 15 | TABLE ACCESS FULL | SALES |:BF0000|:BF0000| PCWP | |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
8 - access("S"."CUST_ID"="C"."CUST_ID")
15 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
PX行ソースがあるため、計画に示されているように、問合せはパラレルで実行されることに注意してください。1つの表、SALES表がパーティション化されています。PX PARTITION HASH行ソースに、PX SEND PARTITIONによって結合を実行する別のスレーブ・セットに分散されたパーティション化されていない表CUSTOMERSが含まれているため、このことを判別できます。
|
注意: Rows列、Cost (%CPU)列、Time列およびTQ列は、この例の計画表の出力では削除されています。 |
|
注意: この項の説明はハッシュ・パーティション化についてですが、レンジ、リストおよび時間隔のパーシャル・パーティション・ワイズ結合にも当てはまります。 |
フル・パーティション・ワイズ結合に関する考慮点は、次のようにパーシャル・パーティション・ワイズ結合にも適用されます。
並列度は、パーティションの数と同じでなくてもかまいません。図3-3では、16の問合せサーバー2組で問合せが実行されています。ここでは、セット2の各問合せサーバーに1つのパーティションが割り当てられます。パーティションの数は常に並列度の倍数である必要があります。
MPPにおけるOracle RRAC環境では、リモートI/Oを回避するために、sales表の各ハッシュ・パーティションが1つのノードのみに対してアフィニティを持つことが望ましいとされます。また、ボトルネックを回避し、システムで使用可能なすべてのCPUリソースを使用するために、パーティションをすべてのノードに分散させます。ノードの数よりパーティションの数が多い場合は、1つのノードで複数のパーティションを管理できます。
|
関連項目: データ・アフィニティの詳細は、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』を参照してください。 |
フル・パーティション・ワイズ結合と同様に、sales表の最適なパーティション化方法は、time_id列に対してレンジ方法を使用することです。これは、sales表が、履歴データを格納する表の典型であるためです。このレンジ・パーティション化を維持して、パーシャル・パーティション・ワイズ結合を使用可能にするには、sales表をcust_id列でハッシュによってサブパーティション化し、各パーティションが16のサブパーティションに分かれるようにします。問合せによってcustomers表とsales表が結合され、time_idに関する選択述語がその問合せにある場合、プルーニングとパーシャル・パーティション・ワイズ結合の両方を使用できます。
sales表がコンポジット・パーティション化されているとき、パーシャル・パーティション・ワイズ結合のパラレル化のグラニュルは、サブパーティションではなくハッシュ・パーティションです。コンポジット表のハッシュ・パーティションの図は、図3-2を参照してください。ハッシュ・パーティションの数は並列度の倍数である必要があります。また、MPPシステムでは、各ハッシュ・パーティションが1つのノードに対してアフィニティを持つようにしてください。前の例では、1つのハッシュ・パーティションを構成する8個のサブパーティションが同じノードに対するアフィニティを持っています。
|
注意: この項の説明はレンジ-ハッシュに関してですが、他のすべての組合せのコンポジット・パーシャル・パーティション・ワイズ結合にも当てはまります。 |
次の例では、salesとcustomersの間の問合せの実行計画が示されます。sales表は、time_idについてレンジ・パーティション化され、cust_idについてハッシュでサブパーティション化されています。
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Pstart| Pstop |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | | | P->S | QC (RAND) |
|* 3 | FILTER | | | | PCWC | |
| 4 | HASH GROUP BY | | | | PCWP | |
| 5 | PX RECEIVE | | | | PCWP | |
| 6 | PX SEND HASH | :TQ10001 | | | P->P | HASH |
| 7 | HASH GROUP BY | | | | PCWP | |
|* 8 | HASH JOIN | | | | PCWP | |
| 9 | PART JOIN FILTER CREATE | :BF0000 | | | PCWP | |
| 10 | PX RECEIVE | | | | PCWP | |
| 11 | PX SEND PARTITION (KEY) | :TQ10000 | | | P->P | PART (KEY) |
| 12 | PX BLOCK ITERATOR | | | | PCWC | |
| 13 | TABLE ACCESS FULL | CUSTOMERS | | | PCWP | |
| 14 | PX PARTITION RANGE ITERATOR| | 8 | 9 | PCWC | |
| 15 | PX PARTITION HASH ALL | | 1 | 16 | PCWC | |
|* 16 | TABLE ACCESS FULL | SALES | 113 | 144 | PCWP | |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(COUNT(SYS_OP_CSR(SYS_OP_MSR(COUNT(*)),0))>100)
8 - access("S"."CUST_ID"="C"."CUST_ID")
16 - filter("S"."TIME_ID"<=TO_DATE(' 1999-10-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"S"."TIME_ID">=TO_DATE(' 1999-07-01
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
|
注意: Rows列、Cost (%CPU)列、Time列およびTQ列は、この例の計画表の出力では削除されています。 |
索引のパーティション化に関するルールは、表についてのルールと似ています。
次の項目に該当しないかぎり、索引のパーティション化が可能です。
索引がクラスタ索引である。
索引がクラスタ化表に定義されている。
次のように、パーティション索引および非パーティション索引は、パーティション表および非パーティション表に混在させることができます。
パーティション表にパーティション索引または非パーティション索引を定義できる。
非パーティション表にパーティション索引または非パーティション索引を定義できる。
非パーティション表のビットマップ索引は、パーティション化できません。
パーティション表のビットマップ索引は、ローカル索引にする必要があります。
ただし、パーティション索引はパーティション表よりも複雑です。パーティション索引には次の3つのタイプがあるためです。
ローカル同一キー索引
ローカル非同一キー索引
グローバル同一キー索引
Oracle Databaseでは、これら3つのタイプがすべてサポートされています。ただし、いくつかの制限があります。たとえば、パーティション表でローカル一意索引を作成する場合、キーを式にすることはできません。
この項の内容は次のとおりです。
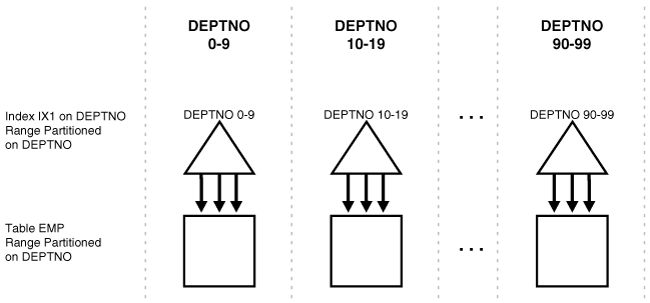
ローカル索引の場合、特定の索引パーティションのキーはすべて、基礎となる表の1つのパーティションに格納されている行のみを参照します。ローカル索引は、LOCAL属性を指定することで作成されます。
Oracleは、基礎となる表と同一レベルでパーティション化されるようにローカル索引を作成します。基礎となる表と同じ列で索引をパーティション化し、同じ数のパーティションまたはサブパーティションを作成して、基礎となる表の対応するパーティションと同じパーティション・バウンドを設定します。
また、Oracleは、基礎となる表のパーティションが追加、削除、マージまたは分割されたり、ハッシュ・パーティションやサブパーティションが追加または結合されたりした場合は、索引のパーティション化を自動的にメンテナンスします。これにより、索引のパーティションが表と同一レベルに保たれます。
パーティション列が索引列のサブセットを形成している場合は、ローカル索引をUNIQUEとして作成できます。この制限により、同一の索引キーを持つ行は同じパーティションにマップされることが保証され、一意性の違反を検出できるようになります。
ローカル索引には次のメリットがあります。
基礎となる表パーティションに対してSPLIT PARTITIONまたはADD PARTITION以外のメンテナンス操作を実行する際、再作成する必要のある索引パーティションが1つで済みます。
パーティション表にローカル索引しかない場合、パーティションのメンテナンス操作にかかる時間はパーティションのサイズに比例します。
ローカル索引によって、パーティションの独立性がサポートされます。
ローカル索引では、履歴表の古いデータのロールアウト、新しいデータのロールインをスムーズに実行できます。
Oracleは、ローカル索引は基礎となる表と同一レベルでパーティション化されるという特性を利用して、より適切な問合せのアクセス計画を生成できます。
ローカル索引を使用すると、表領域の不完全リカバリ作業が簡素化されます。表のパーティションまたはサブパーティションをある時点までリカバリするには、対応する索引エントリも同じ時点までリカバリする必要があります。この処理は、ローカル索引を使用している場合にのみ行うことができます。ローカル索引を使用している場合は、対応する表と索引のパーティションまたはサブパーティションをリカバリできます。
この項の内容は次のとおりです。
|
関連項目: DBMS_PCLXUTILパッケージの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
ローカル索引が同一キーになるのは、索引列の左プリフィックスでパーティション化され、サブパーティション化キーが索引キーに含まれる場合です。ローカル同一キー索引は、一意にも非一意にもできます。
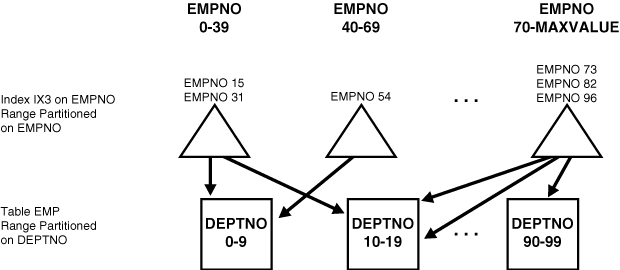
たとえば、sales表とそのローカル索引sales_ixがweek_num列でパーティション化されているとき、索引sales_ixがローカル同一キーになるのは列week_numおよびxaction_numに定義されている場合です。これに対して、索引sales_ixが列product_numに定義されている場合は、同一キーにはなりません。
図3-4に、ローカル同一キー索引の別の例を示します。
索引列の左プリフィックスでパーティション化されていないローカル索引は、非同一キー索引です。あるいは、索引キーにサブパーティション化キーが含まれない場合、ローカル索引は非同一キー索引です。パーティション化キーが索引キーのサブセットでない場合、一意のローカル非同一キー索引は定義できません。
図3-5に、ローカル非同一キー索引の例を示します。
グローバル・パーティション索引では、特定の索引パーティションのキーが、複数の基礎となる表のパーティションまたはサブパーティションに格納されている行を参照する場合があります。グローバル索引ではレンジ・パーティション化またはハッシュ・パーティション化が可能ですが、定義するパーティション表はどのタイプでもかまいません。
グローバル索引は、GLOBAL属性を指定することで作成されます。データベース管理者は、グローバル索引の作成時に最初のパーティション化を定義して、それ以降はパーティション化のメンテナンスを行う必要があります。索引パーティションは、必要に応じてマージまたは分割できます。
通常、グローバル索引を、基礎となる表と同一レベルでパーティション化することはありません。基礎となる表と同一レベルで索引をパーティション化することにデメリットはありませんが、問合せ計画を生成したりパーティションのメンテナンス操作を実行したりする際に、Oracleが同一レベル・パーティション化のメリットを利用することもありません。したがって、基礎となる表と同一レベルでパーティション化する索引は、LOCALとして作成する必要があります。
グローバル・パーティション索引には、すべてのパーティションのすべての行に対するエントリを持つBツリーが1つ含まれます。各索引パーティションは、表の中の様々なパーティションまたはサブパーティションを参照するキーを含むことができます。
グローバル索引の最上位パーティションのパーティション・バウンドは、含まれるすべての値がMAXVALUEであることが必要です。これにより、基礎となる表のすべての行を、確実に索引の中で表すことができるようになります。
この項の内容は次のとおりです。
グローバル・パーティション索引が同一キーになるのは、索引列の左プリフィックスでパーティション化される場合です。グローバル・パーティション索引が非同一キーになるのは、索引列の左プリフィックスでパーティション化されない場合です。Oracleでは、グローバル非同一キー・パーティション索引はサポートされていません。例は図3-6を参照してください。
グローバル同一キー・パーティション索引は、一意にも非一意にもできます。非パーティション索引は、グローバル同一キー非パーティション索引として扱われます。
次の理由から、グローバル・パーティション索引は、ローカル索引よりも管理が煩雑です。
基礎となる表のパーティションのデータが移動または削除された場合(SPLIT、MOVE、DROPまたはTRUNCATE)、グローバル索引のすべてのパーティションが影響を受けます。つまり、グローバル索引では、パーティションの独立性がサポートされていません。
基礎となる表のパーティションまたはサブパーティションをある時点までリカバリする場合は、グローバル索引の対応するすべてのエントリを同じ時点までリカバリする必要があります。これらのエントリは、索引のすべてのパーティションまたはサブパーティションに点在していたり、リカバリしない他のパーティションまたはサブパーティションのエントリと混在していたりする可能性があるので、この処理を行うには、グローバル索引全体を再作成する以外に方法はありません。
表3-1に、Oracleでサポートされている各タイプのパーティション索引をまとめます。重要な点は次のとおりです。
索引がローカルの場合は、基礎となる表と同一レベルでパーティション化されます。これ以外の索引はグローバルです。
同一キー索引は、索引列の左プリフィックスでパーティション化されます。これ以外の索引は非同一キーです。
表3-1 パーティション索引のタイプ
| 索引のタイプ | 表と同一レベルでパーティション化された索引 | 索引列の左プリフィックスでパーティション化された索引 | UNIQUE属性の可/不可 | 例: 表のパーティション化キー | 例: 索引列 | 例: 索引のパーティション化キー |
|---|---|---|---|---|---|---|
|
ローカル同一キー(任意のパーティション化方法) |
可能 |
可能 |
可能 |
A |
A、B |
A |
|
ローカル非同一キー(任意のパーティション化方法) |
可能 |
不可 |
可能脚注 1 |
A |
B、A |
A |
|
グローバル同一キー(レンジ・パーティション化のみ) |
不可脚注 2 |
可能 |
可能 |
A |
B |
B |
脚注1 一意ローカル非同一キー索引の場合、パーティション化キーは索引キーのサブセットにする必要があります。
脚注2 グローバル・パーティション索引は基礎となる表と同一レベルでパーティション化することもできますが、Oracleが同一レベル・パーティション化のメリットを利用したり、パーティションのメンテナンス操作(DROPまたはSPLIT PARTITION)の後に同一レベル・パーティション化をメンテナンスしたりすることはありません。
非同一キー索引は、履歴データベースで特に役立ちます。履歴データを含む表では、索引を1つの列に定義して、その列への高速アクセスの要件を満たすことが一般的です。ただし、古いデータの削除と新しいデータの取得の期間を合せるために、索引を別の列(基礎となる表と同じ列)でパーティション化することもできます。
sales表が週単位でパーティション化されているとします。1年分のデータが含まれ、13個のパーティションに分かれます。week_noでレンジ・パーティション化されており、4週が1パーティションになります。非同一キー・ローカル索引sales_ixをsalesに作成します。問合せでは口座番号を使用してデータに高速アクセスする必要があるため、sales_ix索引はacct_noに定義されます。ただし、これはsales表に合せてweek_noでパーティション化されています。4週ごとにsalesとsales_ixの一番古いパーティションが削除され、新しいパーティションが追加されます。
非同一キー索引のプローブは、同一キー索引のプローブよりも高コストです。索引が同一キー索引のときに(ローカルまたはグローバルのいずれでも)、索引列を含む条件がOracleに発行されると、パーティション・プルーニングによって、条件の適用範囲を索引パーティションのサブセットに限定できます。
たとえば、図3-4において、条件がdeptno=15である場合、オプティマイザはこの条件を索引の2番目のパーティションにのみ適用すればよいことを認識します。(条件にバインド変数が含まれている場合、オプティマイザは条件を適用するべきパーティションを正確には認識できませんが、関係があるパーティションは1つのみであることはわかっており、実行時には1つの索引パーティションにのみアクセスします。)
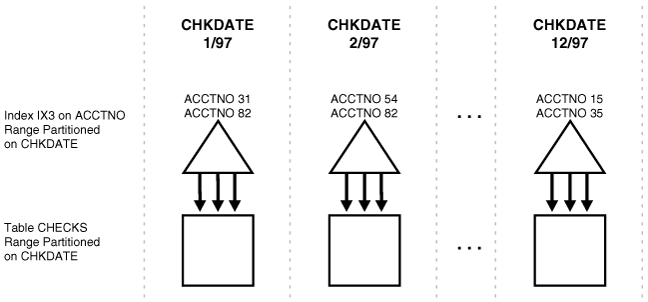
索引が非同一キー索引である場合、Oracleは通常、索引列を含む条件をN個の索引パーティションすべてに適用する必要があります。このためには、単一のキーを参照するか、または索引レンジ・スキャンを実行する必要があります。レンジ・スキャンの場合、Oracleは、N個の索引パーティションの情報を結合する必要もあります。たとえば、図3-5で、ローカル索引はchkdateでパーティション化されており、索引キーはacctnoにあります。条件がacctno=31である場合、Oracleは12個の索引パーティションすべてをプローブします。
パーティション列に対する条件もある場合は、索引のプローブを複数実行する必要はありません。Oracleは、ローカル索引は基礎となる表と同一レベルでパーティション化されるという特性を利用し、パーティション・キーに基づいてパーティションをプルーニングします。たとえば、図3-4において条件がchkdate<3/97である場合、Oracleがプローブする必要のあるパーティションは2つのみです。
このように、非同一キー索引では、パーティション・キーがWHERE句に含まれるが索引キーの一部ではない場合には、オプティマイザが、基礎となる表のパーティションに基づいてプローブするべき索引パーティションを判断します。
ローカルの非同一キー索引のキーを使用する大量の問合せおよびDML文がすべての索引パーティションをプローブする必要がある場合は、この仕組みによって、ローカル非同一キー索引がもたらすパーティションの独立性の程度が実質的に低くなります。
表の索引のパーティション化方法を決める際は、表にアクセスする必要があるアプリケーションの組合せを考慮します。どの方法を使用するかは、パフォーマンスと、可用性および管理性とのトレードオフになります。この項では、考慮する必要のあるいくつかのガイドラインを示します。
グローバル索引およびローカル同一キー索引では、索引パーティションのプローブ数が最小限になるので、ローカル非同一キー索引よりもパフォーマンスが向上します。
ローカル索引では、表のパーティションまたはサブパーティションのメンテナンス操作中でも、より高い可用性が得られます。ローカル非同一キー索引は、履歴データベースで特に有効です。
DSSアプリケーションでは、ローカル非同一キー索引によってパフォーマンスを向上させることができます。これは、索引キーに基づくレンジ問合せによって、多数の索引パーティションをパラレルにスキャンできるためです。
たとえば、図3-4のchecks表に対してacctno between 40 and 45という述語を使用する問合せでは、非同一キー索引ix3のすべてのパーティションのパラレル・スキャンが実行されます。また、図3-5のdeptno表に対してdeptno BETWEEN 40 AND 45という述語を使用する問合せは、同一キー索引ix1の1つのパーティションにアクセスするため、パラレル化できません。
履歴表では、索引はできるかぎりローカルにする必要があります。これにより、定期的なパーティション削除操作の影響を抑えることができます。
パーティション列以外の列の一意索引はグローバルにする必要があります。これは、キーにパーティション化キーが含まれていない一意ローカル非同一キー索引はサポートされていないためです。
使用できない索引は領域を消費しません。詳細は、『Oracle Database管理者ガイド』を参照してください。
デフォルトの物理属性は、CREATE INDEX文でパーティション索引を作成する際に初期指定されます。パーティション索引自体に対応するセグメントはないので、これらの属性はメンバー・パーティションの物理属性を導出する際にのみ使用されます。デフォルトの物理属性は、ALTER INDEX MODIFY DEFAULT ATTRIBUTESを使用して後から変更できます。
CREATE INDEXで作成されるパーティションの物理属性は、次のようにして決定されます。
索引に指定される(明示的またはデフォルト)物理属性の値が使用されるのは、対応するパーティション属性の値が指定されない場合です。LOCAL索引のパーティションのTABLESPACE属性の扱いは、このルールの重要な例外です。つまり、ユーザー指定のTABLESPACE値(パーティション・レベルと索引レベルの両方)がない場合、基礎となる表の対応するパーティションの物理属性の値が使用されます。
ALTER TABLE ADD PARTITIONの処理中に作成されるローカル索引のパーティションの物理属性(前項で説明したTABLESPACE以外)は、各索引のデフォルトの物理属性に設定されます。
ALTER TABLE SPLIT PARTITIONで作成される索引パーティションの物理属性(TABLESPACE以外)は、次のようにして決定されます。
分割される索引パーティションの物理属性の値が使用されます。
既存の索引パーティションの物理属性は、ALTER INDEX MODIFY PARTITIONおよびALTER INDEX REBUILD PARTITIONで変更できます。その結果の属性は、次のようにして決定されます。
新しい値が指定されていない場合は、文が発行される前のパーティションの物理属性の値が使用されます。ALTER INDEX REBUILD PARTITIONで、パーティションが含まれる表領域を変更できることに注意してください。
ALTER INDEX SPLIT PARTITIONで作成されるグローバル索引パーティションの物理属性は、次のようにして決定されます。
新しい値が指定されていない場合は、分割されるパーティションの物理属性の値が使用されます。
索引のすべてのパーティションの(デフォルト値を持つ)物理属性は、ALTER INDEXで変更できます。たとえば、ALTER INDEX indexname NOLOGGINGは、indexnameのすべてのパーティションのロギング・モードをNOLOGGINGに変更します。
パーティションの追加や索引の再作成の詳しい例は、第4章「パーティションの管理」を参照してください。
いくつかのパーティションを圧縮するか、またはパーティション化されたヒープ構成表を作成できます。これを実行するには、完全なパーティション化された表を圧縮対象の表として定義するか、またはパーティション・レベルごとに定義するか、いずれかの定義を行います。特定の宣言のないパーティションは表定義から属性を継承し、表レベルの指定がない場合は表領域定義から継承します。
パーティションを圧縮するかまたは未圧縮のままにするかについての決定は、パーティション化されていない表と同じルールに従います。ただし、データを論理的に個別パーティションに区切る場合はレンジ・パーティション化とコンポジット・パーティション化を使用できるので、パーティション表は、主に読取り専用のデータ(パーティション)の圧縮部分として適切な候補です。たとえばこれは、古いデータが使用不可になる前の中間の段階としてのすべてのローリング・ウィンドウ操作に役立ちます。データ・セグメントを圧縮することにより、より多くの古いデータをオンラインで保持でき、追加の記憶域の使用量の負荷を最小化できます。
圧縮されていない既存の表パーティションを後で変更したり、圧縮済または圧縮されていない新しいパーティションを追加したり、データの移動を必要とするパーティション・メンテナンス操作(MERGE PARTITION、SPLIT PARTITION、MOVE PARTITIONなど)の中で圧縮属性を変更することもできます。パーティションにはデータを含めることもできますが、空のままでもかまいません。
部分的または完全に圧縮されたパーティション表のアクセスおよびメンテナンスは、まったく圧縮されていないパーティション表の場合と同じです。まったく圧縮されていないパーティション表に適用されることは、部分的または完全に圧縮されたパーティション表にも適用されます。
この項の内容は次のとおりです。
|
関連項目:
|
ビットマップ索引のあるパーティション表に対して表の圧縮を使用するには、最初に圧縮属性を導入する前に、次の処理を行う必要があります。
ビットマップ索引を使用不可としてマークします。
圧縮属性を設定します。
索引を再作成します。
圧縮パーティションを、まったく圧縮されていない既存のパーティション表に含める場合は、圧縮パーティションを追加する前に、既存のビットマップ索引をすべて削除するか、UNUSABLEとしてマークする必要があります。これは、パーティションにデータが含まれるかどうかにかかわらず実行する必要があります。また、表の1つ以上のパーティションを圧縮する操作とも無関係です。これは、Bツリー索引のみを含むパーティション表には適用されません。
表の圧縮が有効になっている各データ・ブロックでは、多数の行を収容する可能性があるため、ビットマップ索引構造のこのような再構築が必要です。表の圧縮の有効化は、最初に1回だけ実行する必要があります。その後のすべての操作は、圧縮されたパーティションや圧縮されていないパーティションへの影響や、圧縮属性の変更にかかわらず、圧縮されていないパーティション表、部分的に圧縮されたパーティション表または完全に圧縮されたパーティション表で、理想的に動作します。
パーティション表の部分的または完全な圧縮を将来計画している場合は、ビットマップ索引構造の再作成を回避するために、すべてのパーティション表を作成するときに圧縮パーティションを少なくとも1つ指定することをお薦めします。この圧縮パーティションは空のまま残しても、パーティション表を作成した後に削除してもかまいません。
圧縮パーティションを含むパーティション表では、未圧縮パーティション部分のビットマップ索引構造が多少大きくなる可能性があります。ただし、圧縮パーティションのビットマップ索引構造は、表の圧縮を行う前の適切なビットマップ索引構造よりも、通常は多少小さくなります。これは、実際の圧縮率によってかなり異なります。
|
注意: オブジェクトに対して圧縮が初めて適用され、使用可能なビットマップ索引セグメントがある場合は、エラーが生成されます。 |
次の文では、表salesの既存のパーティションsales_q1_1998が移動および圧縮されます。
ALTER TABLE sales MOVE PARTITION sales_q1_1998 TABLESPACE ts_arch_q1_1998 COMPRESS;
または、次のようにHybrid Columnar圧縮(HCC)を選択できます。
ALTER TABLE sales MOVE PARTITION sales_q1_1998 TABLESPACE ts_arch_q1_1998 COMPRESS FOR ARCHIVE LOW;
MOVE文を使用すると、パーティションsales_q1_1998のローカル索引が使用不可になります。ローカル索引は、次のように、後で再作成する必要があります。
ALTER TABLE sales MODIFY PARTITION sales_q1_1998 REBUILD UNUSABLE LOCAL INDEXES;
ユーザーが表にアクセスすることで悪影響が生じないように、操作全体を自動的に完了させるために、MOVE文にUPDATE INDEXES句を含めることもできます。
次の文では、既存の2つのパーティションが、別の表領域に新しい圧縮パーティションとしてマージされます。ローカル・ビットマップ索引は、次のように、後で再作成する必要があります。
ALTER TABLE sales MERGE PARTITIONS sales_q1_1998, sales_q2_1998 INTO PARTITION sales_1_1998 TABLESPACE ts_arch_1_1998 COMPRESS FOR OLTP UPDATE INDEXES;
パーティション管理操作の詳細と例は、第4章「パーティションの管理」を参照してください。
|
関連項目:
|
次の項では、パーティション化戦略の選択に関する推奨事項を示します。
レンジ・パーティション化は、履歴データをパーティション化する場合に便利です。レンジ・パーティション化の境界は、表または索引内でのパーティションの順序を定義します。
時間隔パーティション化は、レンジ・パーティション化の機能が拡張されたものです。ある時点を過ぎると、パーティションが時間の間隔によって定義されます。データがパーティションに挿入されると、データベースによって時間隔パーティションが自動的に作成されます。
レンジ・パーティション化または時間隔パーティション化は、DATE型の列の時間隔でデータを整理するためによく使用されます。したがって、レンジ・パーティションにアクセスするほとんどのSQL文では期間が指定されます。たとえば、特定の期間のデータを選択するSQL文です。このようなシナリオで、各パーティションが1か月のデータを表す場合、「2006年12月のデータを検索する」という問合せは2006年12月のパーティションだけにアクセスする必要があります。これにより、スキャンされるデータ容量が、存在するデータ全体の一部にまで減少します。これはパーティション・プルーニングと呼ばれる最適化方法です。
レンジ・パーティション化は、パーティションを簡単に追加または削除できるため、定期的に新しいデータをロードして、古いデータを削除する場合にも最適です。たとえば、過去36か月間のデータをオンラインでアクセスできるように、データのローリング・ウィンドウを維持することが一般的です。レンジ・パーティション化によりこのプロセスが簡略化されます。新しい月のデータを追加するには、別の表にロードし、クリーニングし、索引を作成してから、EXCHANGE PARTITION文を使用してレンジ・パーティション表に追加します。この間、元の表はオンラインになっています。新しいパーティションを追加したら、DROP PARTITION文を使用して一番古い月を削除できます。DROP PARTITION文を使用するかわりに、パーティションをアーカイブして読取り専用にすることもできますが、この方法を利用できるのはパーティションが別の表領域にある場合のみです。パーティション表への挿入を使用して、データのローリング・ウィンドウを実装することもできます。
時間隔パーティション化を使用すると、データが届いたときに時間隔パーティションを自動的かつ容易に作成できるようになります。また、時間隔パーティションは、その他すべてのパーティション・メンテナンス操作でも使用できます。時間隔パーティションのパーティション・メンテナンス操作の詳細は、第4章「パーティションの管理」を参照してください。
つまり、次のような場合にレンジ・パーティション化または時間隔パーティション化の使用を検討してください。
非常に大規模な表が、適切なパーティショニング化列(ORDER_DATEやPURCHASE_DATEなど)の範囲述語により頻繁にスキャンされる場合。その列で表をパーティション化することで、パーティション・プルーニングが可能になります。
データのローリング・ウィンドウを保持する場合。
大きい表では、割り当てられた時間枠内でバックアップやリストアなどの管理操作を完了できない場合。パーティション・レンジ列に基づいて表を小さい論理単位に分割できます。
例3-3では、2005年および2006年の2年間分の表salestableを作成し、その表を列s_salesdateの範囲でパーティション化して、8つの四半期にデータを分割します(1四半期が1つのパーティションに対応)。将来のパーティションは、月単位の間隔の定義により自動的に作成されます。時間隔パーティションは、ラウンドロビン法で指定リストの表領域に作成されます。短い間隔で売上数を分析するときに、パーティション・プルーニングを利用できます。sales表では、ローリング・ウィンドウの使用もサポートされます。
例3-1 レンジおよび時間隔パーティション化による表の作成
CREATE TABLE salestable
(s_productid NUMBER,
s_saledate DATE,
s_custid NUMBER,
s_totalprice NUMBER)
PARTITION BY RANGE(s_saledate)
INTERVAL(NUMTOYMINTERVAL(1,'MONTH')) STORE IN (tbs1,tbs2,tbs3,tbs4)
(PARTITION sal05q1 VALUES LESS THAN (TO_DATE('01-APR-2005', 'DD-MON-YYYY'))
TABLESPACE tbs1,
PARTITION sal05q2 VALUES LESS THAN (TO_DATE('01-JUL-2005', 'DD-MON-YYYY'))
TABLESPACE tbs2,
PARTITION sal05q3 VALUES LESS THAN (TO_DATE('01-OCT-2005', 'DD-MON-YYYY'))
TABLESPACE tbs3,
PARTITION sal05q4 VALUES LESS THAN (TO_DATE('01-JAN-2006', 'DD-MON-YYYY'))
TABLESPACE tbs4,
PARTITION sal06q1 VALUES LESS THAN (TO_DATE('01-APR-2006', 'DD-MON-YYYY'))
TABLESPACE tbs1,
PARTITION sal06q2 VALUES LESS THAN (TO_DATE('01-JUL-2006', 'DD-MON-YYYY'))
TABLESPACE tbs2,
PARTITION sal06q3 VALUES LESS THAN (TO_DATE('01-OCT-2006', 'DD-MON-YYYY'))
TABLESPACE tbs3,
PARTITION sal06q4 VALUES LESS THAN (TO_DATE('01-JAN-2007', 'DD-MON-YYYY'))
TABLESPACE tbs4);
パーティション化キーを指定できても、どのパーティションにデータを含めるべきかがわかりにくい場合があります。また、レンジ・パーティション化のように、類似したデータをグループ化するのではなく、データの業務上の意味や論理的な意味に対応しないようにデータを分散することが望ましい場合があります。ハッシュ・パーティション化では、パーティション化キーをハッシング・アルゴリズムに渡した結果に基づいて行がパーティションに配置されます。
この方法を使用すると、データはグループ化されるのではなく複数のパーティションにランダムに分散されます。この方法はデータによっては適していますが、履歴データを管理する方法としては効率的ではありません。ただし、ハッシュ・パーティションの一部のパフォーマンス特性は、レンジ・パーティションと同じです。たとえば、パーティション・プルーニングが行われるのは等価述語の場合のみです。また、パーティション・ワイズ結合、パラレル索引アクセスおよびパラレルDMLを使用することもできます。詳細は、「パーティション・ワイズ結合」を参照してください。
一般的なルールとして、次のような場合にハッシュ・パーティション化を使用します。
パーティション・サイズが同一である可能性が高いときに、パラレルのパーシャル・パーティション・ワイズ結合またはフル・パーティション・ワイズ結合を使用可能にする場合。
Oracle Real Application Clustersを使用するMPPプラットフォームのノード間に、データを均等に分散させる場合。結果として、インターノード・パラレル文を処理するときにインターコネクト・トラフィックが最小限になります。
パーティション化キー(多くの場合、値指定か値リストの制約がある)に基づいてパーティション・プルーニングおよびパーティション・ワイズ結合を使用する場合。
使用可能なすべてのデバイスに対してストライプ化およびミラー化を行うストレージ管理方法を使用しないときに、I/Oボトルネックを回避するためにデータをランダムに分散させる場合。
詳細は、第10章「VLDBのストレージ管理」を参照してください。
|
注意: ハッシュ・パーティション化では、パーティション・プルーニングで使用できるのは等価述語またはINリスト述語のみです。 |
最適なデータ分散を実現するには次の要件を満たす必要があります。
一意またはほぼ一意の列または列の組合せを選択します。
作成するパーティションの数と、各パーティションのサブパーティションの数を2の累乗にします。たとえば、2、4、8、16、32、64、128などです。
例3-4では、パーティション化キーとして列s_productidを使用して、表sales_hashに4つのハッシュ・パーティションを作成します。products表とのパラレル結合では、パーシャル・パーティション・ワイズ結合またはフル・パーティション・ワイズ結合を利用できます。1つの製品または一連の製品の売上金額にアクセスする問合せでは、パーティション・プルーニングが利用されます。
例3-4 ハッシュ・パーティション化による表の作成
CREATE TABLE sales_hash (s_productid NUMBER, s_saledate DATE, s_custid NUMBER, s_totalprice NUMBER) PARTITION BY HASH(s_productid) ( PARTITION p1 TABLESPACE tbs1 , PARTITION p2 TABLESPACE tbs2 , PARTITION p3 TABLESPACE tbs3 , PARTITION p4 TABLESPACE tbs4 );
パーティション名を明示的に指定せず、ハッシュ・パーティション数を指定した場合は、パーティションの内部名が自動的に生成されます。また、STORE IN句を使用して、ラウンドロビン法で表領域にハッシュ・パーティションを割り当てることもできます。その他の例は、 第4章「パーティションの管理」を参照してください。
|
関連項目: パーティション化の構文は、『Oracle Database SQL言語リファレンス』を参照してください。 |
リスト・パーティション化を使用する必要があるのは、特に、離散値に基づいて行をパーティションにマップする場合です。例3-5では、オレゴン州とワシントン州のすべての顧客が1つのパーティションに格納され、他の州の顧客はその他のパーティションに格納されているとします。地域ごとに顧客の取引を分析する顧客口座担当者は、パーティション・プルーニングを利用できます。
例3-5 リスト・パーティション化による表の作成
CREATE TABLE accounts
( id NUMBER
, account_number NUMBER
, customer_id NUMBER
, branch_id NUMBER
, region VARCHAR(2)
, status VARCHAR2(1)
)
PARTITION BY LIST (region)
( PARTITION p_northwest VALUES ('OR', 'WA')
, PARTITION p_southwest VALUES ('AZ', 'UT', 'NM')
, PARTITION p_northeast VALUES ('NY', 'VM', 'NJ')
, PARTITION p_southeast VALUES ('FL', 'GA')
, PARTITION p_northcentral VALUES ('SD', 'WI')
, PARTITION p_southcentral VALUES ('OK', 'TX')
);
レンジ・パーティション化やハッシュ・パーティション化とは異なり、リスト・パーティション化では複数列のパーティション化キーはサポートされません。表がリスト・パーティション化される場合、パーティション化キーに使用できるのは表の1列のみです。
コンポジット・パーティション化には、2つのディメンションでパーティション化する利点があります。パフォーマンスの観点では、SQL文にもよりますが1つまたは2つのディメンションでのパーティション・プルーニングを利用できます。また、いずれかのディメンションでのフル・パーティション・ワイズ結合またはパーシャル・パーティション・ワイズ結合を使用できます。
1つの表でパラレル・バックアップおよびパラレル・リカバリを利用できます。また、コンポジット・パーティション化ではパーティション数が大幅に増加するため、効果的なパラレル実行が可能になります。管理の観点では、履歴データをサポートするためのローリング・ウィンドウを実装でき、多くの文がパーティション・プルーニングまたはパーティション・ワイズ結合の恩恵を受ける場合には、別のディメンションでのパーティション化も可能です。
表のバックアップを分割して、パーティション化キーによる指定に基づいてデータの格納方法を変更することができます。たとえば、特定の製品タイプのデータは読取り専用として圧縮形式で格納し、その他の製品タイプのデータは圧縮せずに保存することができます。
データベースでは、コンポジット・パーティション化された表の各サブパーティションが個別のセグメントとして格納されます。このため、サブパーティションのプロパティは、表のプロパティや、そのサブパーティションが属するパーティションとは異なる場合があります。
この項の内容は次のとおりです。
|
関連項目: 構文と制約の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
コンポジット・レンジ - ハッシュ・パーティション化が特によく使用されるのは、履歴を格納する表、結果として非常に大規模になる表、および他の大きな表と頻繁に結合される表です。このようなタイプの表(データ・ウェアハウス・システムの典型的な表)では、コンポジット・レンジ・ハッシュ・パーティション化によって、レンジ・レベルでのパーティション・プルーニングと、ハッシュ・レベルでのパラレルのフル・パーティション・ワイズ結合またはパーシャル・パーティション・ワイズ結合を利用できるようになります。場合によっては、特定のSQL文で両方のディメンションでのパーティション・プルーニングを利用できます。
また、コンポジット・レンジ・ハッシュ・パーティション化は、従来ハッシュ・パーティション化を使用し、同時にローリング・ウィンドウ方法も利用していた表で使用できます。時間経過に伴い、データをストレージ層間で移動し、圧縮して読取り専用表領域に格納し、最終的にはパージすることができます。情報ライフサイクル管理(ILM)シナリオでは、階層ストレージ方式を実装するためにレンジ・パーティションがよく使用されます。詳細は、第5章「情報ライフサイクル管理のためのパーティション化の使用」を参照してください。
例3-6は、インターネット・サービス・プロバイダのレンジ・ハッシュ・パーティション化されたpage_history表です。この表定義は、特定のclient_ip値(問合せがパーティション・プルーニングを利用可能)または多数のIPアドレス(問合せがフル・パーティション・ワイズ結合またはパーシャル・パーティション・ワイズ結合を利用可能)に関する履歴分析用に最適化されています。
例3-6 コンポジット・レンジ - ハッシュ・パーティション化による表の作成
CREATE TABLE page_history
( id NUMBER NOT NULL
, url VARCHAR2(300) NOT NULL
, view_date DATE NOT NULL
, client_ip VARCHAR2(23) NOT NULL
, from_url VARCHAR2(300)
, to_url VARCHAR2(300)
, timing_in_seconds NUMBER
) PARTITION BY RANGE(view_date) INTERVAL (NUMTODSINTERVAL(1,'DAY'))
SUBPARTITION BY HASH(client_ip)
SUBPARTITIONS 32
(PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-2006','dd-MON-yyyy')))
PARALLEL 32 COMPRESS;
この例では、時間隔パーティション化が使用されています。データが表に挿入されたときに時間隔パーティションを自動的に作成するために、レンジ・パーティション化に加えて時間隔パーティション化を使用できます。
コンポジット・レンジ・リスト・パーティション化は、履歴データを格納する大きな表でよく使用され、一般的に複数のディメンションでアクセスされます。通常は、データの履歴ビューが1つのアクセス・パスですが、業務によってはアクセス・パスとしてその他のカテゴリも使用されます。たとえば、地区の経理担当者は、その地区で特定の期間に加入した新顧客数に高い関心があります。ILMとその階層ストレージ方式が、レンジ・リスト・パーティション表を作成する一般的な理由です。古いデータを移動して圧縮しても、リスト・ディメンションのパーティション・プルーニングを引き続き行うことができます。
例3-7では、レンジ・リスト・パーティション化されたcall_detail_records表を作成します。電気通信会社はこの表を使用して、時間経過に応じて特定の種類の通信を分析できます。この表では、from_numberとto_numberに対するローカル索引が使用されます。
例3-7 コンポジット・レンジ - リスト・パーティション化による表の作成
CREATE TABLE call_detail_records
( id NUMBER
, from_number VARCHAR2(20)
, to_number VARCHAR2(20)
, date_of_call DATE
, distance VARCHAR2(1)
, call_duration_in_s NUMBER(4)
) PARTITION BY RANGE(date_of_call)
INTERVAL (NUMTODSINTERVAL(1,'DAY'))
SUBPARTITION BY LIST(distance)
SUBPARTITION TEMPLATE
( SUBPARTITION local VALUES('L') TABLESPACE tbs1
, SUBPARTITION medium_long VALUES ('M') TABLESPACE tbs2
, SUBPARTITION long_distance VALUES ('D') TABLESPACE tbs3
, SUBPARTITION international VALUES ('I') TABLESPACE tbs4
)
(PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-2005','dd-MON-yyyy')))
PARALLEL;
CREATE INDEX from_number_ix ON call_detail_records(from_number)
LOCAL PARALLEL NOLOGGING;
CREATE INDEX to_number_ix ON call_detail_records(to_number)
LOCAL PARALLEL NOLOGGING;
この例では、時間隔パーティション化が使用されています。データが表に挿入されたときに時間隔パーティションを自動的に作成するために、レンジ・パーティション化に加えて時間隔パーティション化を使用できます。
コンポジット・レンジ - レンジ・パーティション化は、時間関連のデータを複数の時間ディメンションで格納するアプリケーションに役立ちます。多くの場合、このようなアプリケーションは、データにアクセスするために特定の1つの時間ディメンションを使用するのではなく、別の時間ディメンションを使用することもあれば、同時に両方の時間ディメンションを使用することもあります。たとえば、Webショップが、発注時間と出荷時間(運送会社に渡した時間)に基づいて売上データを分析する場合があります。
コンポジット・レンジ・レンジ・パーティション化の他の業務例としては、ILMシナリオや、履歴データを格納して、データを別のディメンションの範囲で分類するアプリケーションがあります。
例3-8では、レンジ・レンジ・パーティション化された表account_balance_historyを示します。銀行は、低残高通知や特定の顧客カテゴリ向けキャンペーンについて顧客に連絡するために、個々のサブパーティションへのアクセスを利用できます。
例3-6 コンポジット・レンジ - レンジ・パーティション化による表の作成
CREATE TABLE account_balance_history
( id NUMBER NOT NULL
, account_number NUMBER NOT NULL
, customer_id NUMBER NOT NULL
, transaction_date DATE NOT NULL
, amount_credited NUMBER
, amount_debited NUMBER
, end_of_day_balance NUMBER NOT NULL
) PARTITION BY RANGE(transaction_date)
INTERVAL (NUMTODSINTERVAL(7,'DAY'))
SUBPARTITION BY RANGE(end_of_day_balance)
SUBPARTITION TEMPLATE
( SUBPARTITION unacceptable VALUES LESS THAN (-1000)
, SUBPARTITION credit VALUES LESS THAN (0)
, SUBPARTITION low VALUES LESS THAN (500)
, SUBPARTITION normal VALUES LESS THAN (5000)
, SUBPARTITION high VALUES LESS THAN (20000)
, SUBPARTITION extraordinary VALUES LESS THAN (MAXVALUE)
)
(PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-2007','dd-MON-yyyy')));
この例では、時間隔パーティション化が使用されています。データが表に挿入されたときに時間隔パーティションを自動的に作成するために、レンジ・パーティション化に加えて時間隔パーティション化を使用できます。ここでは、2007年1月1日(月曜日)から開始する7日間(1週間)の間隔が作成されています。
コンポジット・リスト - ハッシュ・パーティショニングが役立つのは、通常1つのディメンションに関してアクセスされる大規模な表で、(そのサイズのために)他の大きな表との結合で、別のディメンションに関してパラレルのフル・パーティション・ワイズ結合またはパーシャル・パーティション・ワイズ結合を利用する必要がある表です。
例3-9にcredit_card_accounts表を示します。この表は、経理担当者がその地域の口座にすぐにアクセスできるように、regionでリスト・パーティション化されています。サブパーティション計画はcustomer_idでのハッシュです。これにより、transactions表(customer_idでサブパーティション化されている)に対する問合せはフル・パーティション・ワイズ結合を利用できます。ハッシュ・パーティション化されたcustomers表との結合では、フル・パーティション・ワイズ結合を利用することもできます。この表にはis_active列にローカル・ビットマップ索引があります。
例3-9 コンポジット・リスト - ハッシュ・パーティション化による表の作成
CREATE TABLE credit_card_accounts
( account_number NUMBER(16) NOT NULL
, customer_id NUMBER NOT NULL
, customer_region VARCHAR2(2) NOT NULL
, is_active VARCHAR2(1) NOT NULL
, date_opened DATE NOT NULL
) PARTITION BY LIST (customer_region)
SUBPARTITION BY HASH (customer_id)
SUBPARTITIONS 16
( PARTITION emea VALUES ('EU','ME','AF')
, PARTITION amer VALUES ('NA','LA')
, PARTITION apac VALUES ('SA','AU','NZ','IN','CH')
) PARALLEL;
CREATE BITMAP INDEX is_active_bix ON credit_card_accounts(is_active)
LOCAL PARALLEL NOLOGGING;
コンポジット・リスト・リスト・パーティション化が役立つのは、様々なディメンションに関してアクセスされることが多い大きな表です。特に、離散値に基づいてそれらのディメンションに行をマップできます。
例3-10に、非常にアクセス回数の多いcurrent_inventory表を示します。この表は、スーパーマーケット納入業者の地方倉庫の現在の在庫を反映するように絶えず更新されています。生鮮食品はその倉庫からスーパーマーケットに供給されるため、供給と配送を最適化することが重要です。この表は、warehouse_idとproduct_idにローカル索引があります。
例3-10 コンポジット・リスト - リスト・パーティション化による表の作成
CREATE TABLE current_inventory
( warehouse_id NUMBER
, warehouse_region VARCHAR2(2)
, product_id NUMBER
, product_category VARCHAR2(12)
, amount_in_stock NUMBER
, unit_of_shipping VARCHAR2(20)
, products_per_unit NUMBER
, last_updated DATE
) PARTITION BY LIST (warehouse_region)
SUBPARTITION BY LIST (product_category)
SUBPARTITION TEMPLATE
( SUBPARTITION perishable VALUES ('DAIRY','PRODUCE','MEAT','BREAD')
, SUBPARTITION non_perishable VALUES ('CANNED','PACKAGED')
, SUBPARTITION durable VALUES ('TOYS','KITCHENWARE')
)
( PARTITION p_northwest VALUES ('OR', 'WA')
, PARTITION p_southwest VALUES ('AZ', 'UT', 'NM')
, PARTITION p_northeast VALUES ('NY', 'VM', 'NJ')
, PARTITION p_southeast VALUES ('FL', 'GA')
, PARTITION p_northcentral VALUES ('SD', 'WI')
, PARTITION p_southcentral VALUES ('OK', 'TX')
);
CREATE INDEX warehouse_id_ix ON current_inventory(warehouse_id)
LOCAL PARALLEL NOLOGGING;
CREATE INDEX product_id_ix ON current_inventory(product_id)
LOCAL PARALLEL NOLOGGING;
コンポジット・リスト・レンジ・パーティション化が役立つのは、様々なディメンションに関してアクセスされる大きな表です。最もよく使用されるディメンションでは、離散値について行をパーティションに具体的にマップすることができます。リスト・レンジ・パーティション化は、リスト・パーティション内で範囲値を使用する表でよく使用されます。一方、レンジ・リスト・パーティション化は、レンジ・パーティション内の離散リスト値についてよく使用されます。リスト・レンジ・パーティション化は、履歴データの格納にはそれほど使用されませんが、同様のシナリオにはすべて対応します。レンジ・リスト・パーティション化は、時間隔リスト・パーティション化を使用して実装できますが、リスト・レンジ・パーティション化は時間隔パーティション化をサポートしていません。
例3-11に、様々な通貨単位での寄付額を格納するdonations表を示します。donationsは、金額に応じて、低、中、高にカテゴリ分けされています。通貨によってレンジは異なります。
例3-11 コンポジット・リスト - レンジ・パーティション化による表の作成
CREATE TABLE donations
( id NUMBER
, name VARCHAR2(60)
, beneficiary VARCHAR2(80)
, payment_method VARCHAR2(30)
, currency VARCHAR2(3)
, amount NUMBER
) PARTITION BY LIST (currency)
SUBPARTITION BY RANGE (amount)
( PARTITION p_eur VALUES ('EUR')
( SUBPARTITION p_eur_small VALUES LESS THAN (8)
, SUBPARTITION p_eur_medium VALUES LESS THAN (80)
, SUBPARTITION p_eur_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_gbp VALUES ('GBP')
( SUBPARTITION p_gbp_small VALUES LESS THAN (5)
, SUBPARTITION p_gbp_medium VALUES LESS THAN (50)
, SUBPARTITION p_gbp_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_aud_nzd_chf VALUES ('AUD','NZD','CHF')
( SUBPARTITION p_aud_nzd_chf_small VALUES LESS THAN (12)
, SUBPARTITION p_aud_nzd_chf_medium VALUES LESS THAN (120)
, SUBPARTITION p_aud_nzd_chf_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_jpy VALUES ('JPY')
( SUBPARTITION p_jpy_small VALUES LESS THAN (1200)
, SUBPARTITION p_jpy_medium VALUES LESS THAN (12000)
, SUBPARTITION p_jpy_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_inr VALUES ('INR')
( SUBPARTITION p_inr_small VALUES LESS THAN (400)
, SUBPARTITION p_inr_medium VALUES LESS THAN (4000)
, SUBPARTITION p_inr_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_zar VALUES ('ZAR')
( SUBPARTITION p_zar_small VALUES LESS THAN (70)
, SUBPARTITION p_zar_medium VALUES LESS THAN (700)
, SUBPARTITION p_zar_high VALUES LESS THAN (MAXVALUE)
)
, PARTITION p_default VALUES (DEFAULT)
( SUBPARTITION p_default_small VALUES LESS THAN (10)
, SUBPARTITION p_default_medium VALUES LESS THAN (100)
, SUBPARTITION p_default_high VALUES LESS THAN (MAXVALUE)
)
) ENABLE ROW MOVEMENT;
時間隔パーティション化は、レンジ・パーティション化されており、新しいパーティションで固定間隔を使用するすべての表で使用できます。時間隔パーティションは、そのパーティションのデータが挿入されたときに自動的に作成されます。このときまで、時間隔パーティションは存在しますが、そのパーティションのセグメントは作成されていません。
時間隔パーティション化の利点は、レンジ・パーティションを明示的に作成する必要がないことです。様々な間隔のレンジ・パーティションを作成しない場合、またはレンジ・パーティションを作成するときに常に特定のパーティション属性を設定する場合は、時間隔パーティション化の使用を検討する必要があります。時間隔の定義では表領域のリストを指定できることに注意してください。時間隔パーティションは、データベースによってラウンドロビン法で指定リストの表領域に作成されます。
アプリケーションをアップグレードし、レンジ・パーティション化または、様々なコンポジット・レンジ・パーティション化を使用する場合は、既存の表定義を簡単に変更して、時間隔パーティション化を使用することができます。時間隔パーティション表へのパーティションの手動追加はできないことに注意してください。新しいパーティションの作成を自動化している場合は、将来、レンジ・パーティションの明示的な作成が行われないようにアプリケーション・コードを変更する必要があります。
次の例に、サンプルのshスキーマのsales表を、レンジ・パーティション化から変更して、月単位の時間隔パーティション化の使用を開始する方法を示します。
ALTER TABLE sales SET INTERVAL (NUMTOYMINTERVAL(1,'MONTH'));
参照パーティション表では時間隔パーティションを使用することはできません。
時間隔パーティション化では、シリアル化可能なトランザクションは使用できません。まだセグメントのない時間隔パーティション表のパーティションにデータを挿入すると、エラーが発生します。
マスター表と子表の両方でパーティション・プルーニングを利用できるように、マスター表の列を子表に非正規化した場合(または、これから非正規化する場合)。
たとえば、order_dateはorders表には格納されますが、注文ごとに1つ以上の品目を格納するorder_items表には格納されません。注文データの履歴分析のパフォーマンスを高めるには、従来であれば、order_items表にorder_date列を複製して、order_items表でパーティション・プルーニングを使用できるようにするはずです。
このようなシナリオでは、order_dateを複製せずにすむように、参照パーティション化を検討する必要があります。両方の表を結合してorder_dateに対する条件を使用する問合せは、両方の表のパーティション・プルーニングを自動的に利用します。
2つの大きな表を頻繁に結合するときに、2つの表が結合キーでパーティション化されていないが、パーティション・ワイズ結合を利用する場合。
参照パーティション化により、フル・パーティション・ワイズ結合が暗黙に使用可能になります。
複数の表のデータが1つのライフサイクルに関連している場合。参照パーティション化を使用すると、管理上で大きなメリットが得られます。
マスター表でパーティション管理操作を行うと、子表でも自動的に行われます。たとえば、マスター表にパーティションを追加すると、その追加がすべての子表に自動的に伝播されます。
参照パーティション化を使用するには、マスター表と参照表の間の外部キー関係を有効にして施行する必要があります。参照パーティション表をカスケードできます。
仮想列でのパーティション化では、式についてパーティション化できます。つまり、他の列のデータを使用し、それらの列で計算を実行できます。PL/SQL関数コールは、パーティション化キーとして使用される仮想列の定義ではサポートされません。
仮想列のパーティション化では、すべてのパーティション化方法に加えて、パフォーマンスや管理のための機能もサポートされます。表のアクセスに頻繁に使用される述語が、列から直接取得するのではなく導出する場合には、パーティション・プルーニングの効果を得るために仮想列の使用を検討してください。従来、パーティション・プルーニングの効果を上げるためには、正しい値を取得して計算するために別の列を追加し、問合せで適切な検索を行えるように、列が常に正しい値を含むようにする必要がありました。
例3-12にcar_rentals表を示します。顧客の確認番号には、レンタカーを借りた場所として2文字の国名が含まれます。レンタカーの分析では通常は地域パターンが評価されるため、国別にパーティション化することに意味があります。
例3-12 仮想列でのパーティション化による表の作成
CREATE TABLE car_rentals
( id NUMBER NOT NULL
, customer_id NUMBER NOT NULL
, confirmation_number VARCHAR2(12) NOT NULL
, car_id NUMBER
, car_type VARCHAR2(10)
, requested_car_type VARCHAR2(10) NOT NULL
, reservation_date DATE NOT NULL
, start_date DATE NOT NULL
, end_date DATE
, country as (substr(confirmation_number,9,2))
) PARTITION BY LIST (country)
SUBPARTITION BY HASH (customer_id)
SUBPARTITIONS 16
( PARTITION north_america VALUES ('US','CA','MX')
, PARTITION south_america VALUES ('BR','AR','PE')
, PARTITION europe VALUES ('GB','DE','NL','BE','FR','ES','IT','CH')
, PARTITION apac VALUES ('NZ','AU','IN','CN')
) ENABLE ROW MOVEMENT;
この例では、列countryは、確認番号から導出される仮想列として定義されています。仮想列には記憶域は必要ありません。この例が示すように、行の移動は仮想列でサポートされています。仮想列が別のパーティションにある異なる値と評価されると、その行はデータベースによって別のパーティションに移動されます。
参照整合性制約が親表と子表の間に定義されているとき、索引は外部キーに定義され、その索引が格納される表領域は読取り専用になります。このとき、この制約の整合性チェックは、読取り一貫性バッファ・アクセスを使用せずにSQLで実装されます。
この実装が意味するのは、子がパーティション化されると、一部の子パーティションの索引のみが読取り専用表に含まれることと、非読取り専用子セグメントの1つに対して挿入が行われると、TMエンキューが子表に対してSXモードで獲得されることです。
SXモードはSリクエストとの互換性がありません。したがって、親に対する挿入の試行は、子に対するS TMエンキューを獲得しようとするため妨げられます。