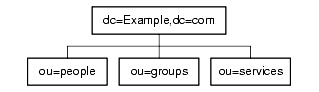|
| |
| Sun Java(TM) System Directory Server 5.2 2005Q1 Deployment Planning Guide | |
Chapter 5
Distribution, Chaining, and ReferralsChapter 4, "The Directory Information Tree," described how Directory Server stores entries. Because Directory Server can store a large number of entries, you may need to distribute entries across more than one server. The directory topology describes how you divide your directory tree among multiple physical Directory Servers, and how these servers link with one another.
This chapter describes how you can use data distribution, chaining, and referrals to manage directory data more effectively. It is divided into the following topics:
Topology OverviewA distributed directory is one in which the directory tree is spread across multiple physical Directory Servers. Dividing your directory in this way enables you to:
When a directory is divided among several servers, each server is responsible for only a part of the directory tree. The distributed directory works in a similar way to the Domain Name Service (DNS), which assigns each portion of the DNS namespace to a particular DNS server. In the same way, you can distribute your directory namespace across servers while maintaining, from a client point of view, a single directory tree.
Directory Server also provides the referral and chaining mechanisms for linking directory data stored in different databases. (The suffix is the basic unit for tasks such as replication, performing backups, and restoring data.) The remainder of this chapter describes suffixes, referrals, and chaining, and describes how you can design indexes to improve directory performance.
Distributing DataDistributing data enables you to scale your directory across multiple server instances, without the need for all directory entries to be located on each server in your enterprise. The server instances may or may not (depending on performance requirements) be stored on several machines. A distributed directory can therefore hold a much larger number of entries than would be possible with a single server.
In addition, you can configure your directory to hide the distribution details from the user or client application. As far as directory clients are concerned, a single directory answers their directory queries.
The following sections describe the mechanics of data distribution in more detail:
Using Multiple Databases
Directory Server stores data in LDBM databases. The LDBM database is a high-performance disk-based database. Each database consists of a set of large files that contains all of the data assigned to it. You can store different portions of your directory tree in different databases. Imagine, for example, your directory tree contains three subsuffixes, as shown in Figure 5-1.
Figure 5-1 Directory Tree With Three Subsuffixes
You can store the data of the three subsuffixes in three separate databases as shown in Figure 5-2.
Figure 5-2 Three Subsuffixes Stored in Three Separate Databases
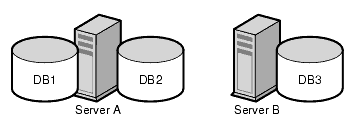
When you divide your directory tree among a number of databases, these databases can be distributed across multiple servers, which generally equates to several physical machines to improve performance. The three databases in the preceeding figure can be stored on two servers as shown in Figure 5-3.
Figure 5-3 Example.com's Three Databases Stored on Two Servers A and B
Distributing databases across multiple servers reduces the amount of work each server needs to do. Thus, the directory can be made to scale to a much larger number of entries than would be possible with a single server. Directory Server also supports adding databases dynamically, so you can add new databases as required, without taking the entire directory off-line.
About Suffixes
Each database contains the data within a suffix of Directory Server. You can create both suffixes and subsuffixes to organize the contents of your directory tree. A suffix is the entry at the root of a tree. It can be the root of the entire directory tree, or part of a larger tree.
A subsuffix is a branch underneath a suffix. Subsuffixes represent the distribution of directory data.
For example, the directory tree for Example.com is shown in Figure 5-4.
Figure 5-4 Example.com Directory Tree
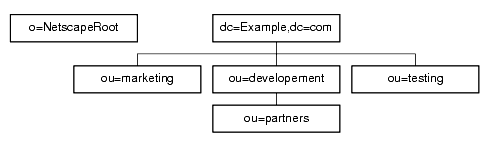
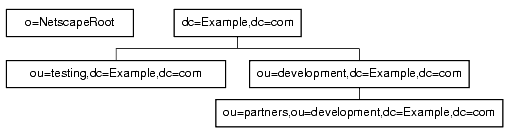
Example.com decides to split their directory tree across five different databases, as illustrated in Figure 5-5.
Figure 5-5 Example.com Corporation's Directory Tree Split Across Five Databases
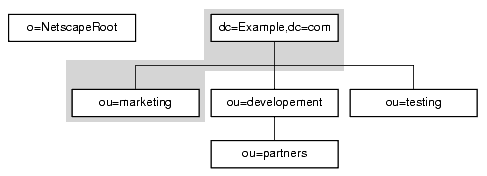
o=NetscapeRoot and dc=Example,dc=com are both suffixes. ou=testing,dc=Example,dc=com, ou=development,dc=Example,dc=com, and ou=partners,ou=development,dc=Example,dc=com are subsuffixes of the dc=Example,dc=com suffix. The suffix dc=Example,dc=com contains the data in the ou=marketing branch of the original directory tree.
The suffixes and subsuffixes that result from this division contain entries as shown in Figure 5-6.
Figure 5-6 Example.com Corporation Suffixes and Associated Entries
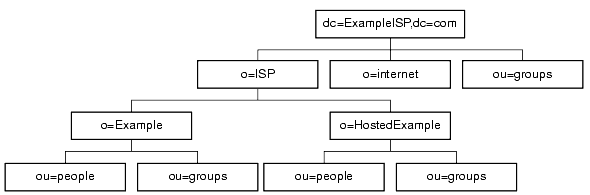
Your directory might contain more than one suffix. For example, an ISP, ExampleISP.com might host several websites, one for its own website ExampleISP.com and one for another website called HostedExample.com. The ISP can choose between creating one suffix, which houses everything, or two suffixes to separate the hosted part of the organization from internal ExampleISP.com data.
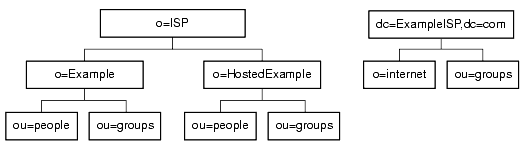
The first solution with just one suffix for all data, would result in a directory information tree as shown in Figure 5-7.
Figure 5-7 ExampleISP.com Directory Tree with One Suffix
If the ISP created two suffixes, one corresponding to its own naming context, and one corresponding to the organizations it hosts, the directory information tree would appear as follows:
Figure 5-8 ExampleISP.com's Directory Tree With Two Suffixes
The entries for each hosted organization (o=Example and o=HostedExample) are subsuffixes of the o=ISP suffix, with the ou=people and the ou=groups branches as subsuffixes of each hosted organization.
Referrals and ChainingWhen data is distributed over several suffixes, you must define the relationships between the distributed data. You do this using pointers to directory information held in different suffixes. Directory Server provides the referral and chaining mechanisms to link distributed data into a single directory tree.
The following sections describe and compare these two mechanisms.
Using Referrals
A referral is a piece of information returned by a server that tells a client application which server to contact to proceed with an operation request. Directory Server supports three types of referrals:
All referrals are returned in the format of an LDAP uniform resource locator (URL). The following sections describe the structure of an LDAP referral, and the three referral types supported by Directory Server.
Structure of an LDAP Referral
An LDAP referral contains information in the format of an LDAP URL. An LDAP URL contains the following information:
For example, a client application searches dc=Example,dc=com for entries with a surname Jensen. A referral returns the following LDAP URL to the client application:
ldap://europe.Example.com:389/ou=people,l=europe,dc=Example,dc=com
The referral tells the client application to contact the host europe.Example.com on LDAP port 389 and submit a search rooted at ou=people,l=europe,dc=Example,dc=com.
The LDAP client application determines how a referral is handled. Some client applications automatically retry the operation on the server to which they have been referred. Other client applications simply return the referral information to the user. Most LDAP client applications provided by Directory Server (such as the command-line utilities) automatically follow the referral. The same bind credentials you supply on the initial server request are used to access the referred server.
Most client applications follow a limited number of referrals, or hops. The limit on the number of referrals followed reduces the time a client application spends trying to complete a directory lookup request and helps eliminate hung processes caused by circular referral patterns.
Default Referrals
Directory Server determines whether a default referral should be returned by comparing the DN of the requested directory object against the directory suffixes supported by the local server. If the DN does not match the supported suffixes, Directory Server returns a default referral.
For example, a directory client requests the following directory entry:
uid=bjensen,ou=people,dc=Example,dc=com
However, the server manages only entries stored under the dc=europe,dc=Example,dc=com suffix. The directory returns a referral to the client that indicates which server to contact for entries stored in the dc=Example,dc=com suffix. The client then contacts the appropriate server and resubmits the original request.
You configure the default referral to point to a Directory Server that has more knowledge about the distribution of your directory. Default referrals for the server are set by the nsslapd-referral attribute, stored in the dse.ldif configuration file.
For information on configuring default referrals, see "Setting the Default Referrals" in the Directory Server Administration Guide.
Suffix Referrals
If you want to limit access to a suffix without disabling it completely, you can modify the access permissions to allow read-only access. In this case you must define a suffix referral to another server for write operations. You can also deny both read and write access and define a referral for all operations on the suffix. Suffix referrals can also be used to temporarily point a client application to a different server. For example, you might add a referral to a suffix so that the suffix points to a different server while backing up the contents of the suffix.
Imagine you have two major sites in the US, one based in New York and the other in Los Angeles. A client application sends a query which concerns the New York site as follows:
uid=bjensen,ou=people,dc=US,dc=Example,dc=com
You can configure a suffix referral to dc=NewYork,dc=US,dc=Example,dc=com so that the request is processed by the suffix that contains the dc=NewYork subtree.
Suffix referrals are configured with the nsslapd-state and nsslapd-referral attributes in the mapping tree entry for that suffix. The nsslapd-referral attribute specifies the LDAP URL(s) to be returned by the suffix. The nsslapd-state attribute can take one of four values:
- nsslapd-state: backend where the suffix processes all operations.
- nsslapd-state: disabled where the suffix is not available for processing and an error is returned in response to requests made by client applications.
- nsslapd-state: referral where a referral is returned for all requests made to this suffix.
- nsslapd-state: referral on update where the suffix is used for all operations except update requests, which receive a referral. The referral on update state is used internally by the server when replication is configured, to prevent consumers from processing update requests. However, you can also use this state to restrict access to read operations on certain suffixes for load balancing or performance.
For information on configuring suffix referrals, see "Setting Access Permissions and Referrals" in the Directory Server Administration Guide.
Smart Referrals
Directory Server also supports smart referrals, which enable you to associate a directory entry or directory tree to a specific LDAP URL. Associating directory entries to specific LDAP URLs enables you to refer requests to any of the following:
Unlike default referrals, smart referrals are stored within the directory itself.
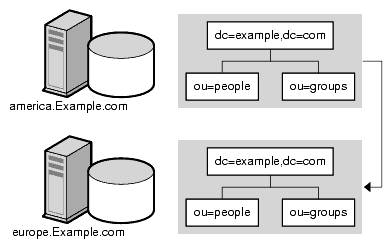
For example, the directory for the American office of Example.com contains the following directory branch point: ou=people,dc=Example,dc=com.
You redirect all requests on this branch to the ou=people branch of the European office of Example.com by specifying a smart referral on the ou=people entry itself. This smart referral appears as follows :
ldap://europe.Example.com:389/ou=people,dc=Example,dc=com
Any requests made to the people branch of the American directory are redirected to the European directory. An illustration of this smart referral is shown in Figure 5-9.
Figure 5-9 Smart Referral From American Directory to European Directory
You can use the same mechanism to redirect queries to a different server that uses a different namespace. For example, an employee working in the Italian office of Example.com makes a request to the European directory for the phone number of an Example.com employee in America. The referral returned by the directory is:
ldap://europe.Example.com:389/ou=US employees,dc=Example,dc=com
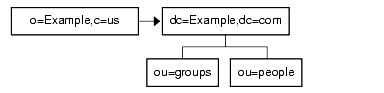
Finally, if you serve multiple suffixes on the same server, you can redirect queries from one namespace to another namespace served on the same machine. If you want to redirect all queries on the local machine for o=Example,c=us to dc=Example,dc=com, you would put the following smart referral on the o=Example,c=us entry:
ldap:///dc=Example,dc=com
as illustrated in Figure 5-10.
Figure 5-10 Smart Referral Traffic
Because you are redirecting queries from one namespace to another on the same machine, there is no need to provide the host:port information pair which usually appears in the URL. Because this pair is empty in the URL, the URL pointing to the same Directory Server contains three slashes.
Note
To make best use of referrals, do not make the base of your search below where the referral is configured.
For more information on LDAP URLs see "LDAP URL Reference" in the Directory Server Administration Reference. For more information on how to include smart URLs on Directory Server entries, see "Creating Smart Referrals" in the Directory Server Administration Guide.
Tips for Designing Smart Referrals
Consider the following points when using smart referrals:
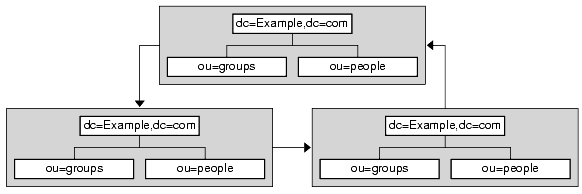
A complex web of referrals makes directory administration difficult. Also, overusing smart referrals can lead to circular referral patterns, in which a referral points to an LDAP URL, which in turn points to another LDAP URL, and so on until a referral somewhere in the chain points back to the original server. A circular referral pattern is depicted in Figure 5-11:
Figure 5-11 Circular Referral Pattern Caused by the Overuse of Smart Referrals
Limit referrals to handling redirection at the suffix level. Smart referrals allow you to redirect lookup requests for leaf (non-branch) entries to different servers and DNs. As a result, you may be tempted to use smart referrals as an aliasing mechanism, leading to a complex directory structure that is difficult to secure. By limiting referrals to the suffix or major branch points of your directory tree, you can limit the number of referrals that you have to manage, and reduce administrative overhead.
Access control does not cross referral boundaries. Even if the server where the request originated allows access to an entry, when a smart referral sends a client request to another server, the client application may be refused access.
Also, the client credentials must be available on the server to which the client is referred for client authentication to take place.
Using Chaining
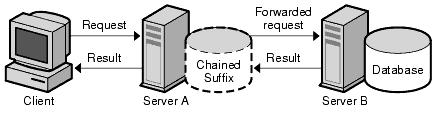
Chaining is a method for relaying requests to another server. This method is implemented through chained suffixes. As described in Distributing Data, a chained suffix contains no data. Instead, it redirects client application requests to remote servers that contain the data.
During chaining, a server receives a request from a client application for data it does not contain. Using the chained suffix, the server then contacts other servers on behalf of the client application and returns the results to the client application. This operation is illustrated in Figure 5-12.
Figure 5-12 Chaining Operation
Each chained suffix is associated to a remote server holding data. You can also configure alternate remote servers containing replicas of the data for the chained suffix to use when there is a failure. For more information on configuring chained suffixes, refer to "Creating Chained Suffixes" in the Directory Server Administration Guide.
Chained suffixes provide the following features:
You can add or remove a part of the directory from the system while the entire system remains available to client applications. The chained suffix can temporarily return referrals to the application until entries have been redistributed across the directory. You can also implement this functionality through the suffix itself, which can return a referral rather than forwarding a client application on to the database.
The chained suffix impersonates the client application, providing the appropriate authorization identity to the remote server. You can disable user impersonation on the remote servers when access control evaluation is not required. For more information regarding access control and chained suffixes see "Access Control Through Chained Suffixes"in the Directory Server Administration Guide .
Deciding Between Referrals and Chaining
Both methods of linking directory partitions have advantages and disadvantages. The method, or combination of methods, you choose depends on the specific needs of your directory.
The main difference between using referrals and using chaining is the location of the intelligence that knows how to locate the distributed information. In a chained system, the intelligence is implemented in the servers. In a system that uses referrals, the intelligence is implemented in the client application.
While chaining reduces client complexity, it does so at the cost of increased server complexity. Chained servers must work with remote servers and send the results to directory clients.
With referrals, the client must handle locating the referral and collating search results. However, referrals offer more flexibility for the writers of client applications and allow developers to provide better feedback to users about the progress of a distributed directory operation.
The following sections describe some of the more specific differences between referrals and chaining in greater detail.
Usage Differences
Some client applications do not support referrals. Chaining allows client applications to communicate with a single server and still access the data stored on many servers. Sometimes referrals do not work when a company's network uses proxies. For example, a client application has permissions to speak to only one server inside a firewall. If they are referred to a different server, they will not be able to contact it successfully.
Also, with referrals a client must authenticate, meaning that the servers to which clients are being referred need to contain the client credentials. With chaining, client authentication takes place only once. Clients do not need to authenticate again on the servers to which their requests are chained.
Evaluating Access Controls
Chaining evaluates access controls differently from referrals. With referrals, a bind DN entry must exist on all of the target servers. With chaining, the client entry does not need to be on all of the target servers.
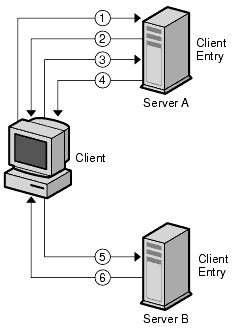
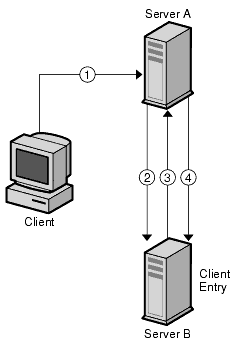
For example, a client sends a search request to Server A. Figure 5-13 shows how the operation would work using referrals.
Figure 5-13 Client Application Search Request Redirected Through a Referral
In this figure, the client application performs the following steps:
- The client application first binds with Server A.
- Server A contains an entry for the client that provides a user name and password, so returns a bind acceptance message. In order for the referral to work, the client entry must be present on Server A.
- The client application sends the operation request to Server A.
- However, Server A does not contain the information requested. Instead, Server A returns a referral to the client application telling them to contact Server B.
- The client application then sends a bind request to Server B. To bind successfully, Server B must also contain an entry for the client application.
- The bind is successful, and the client application can now resubmit its search operation to Server B.
This approach requires Server B to have a replicated copy of the client's entry from Server A.
Chaining solves this problem. A search request using chaining would work as shown in Figure 5-14.
Figure 5-14 Search Request using Chaining
In this figure, the following steps are performed:
- The client application binds with Server A and Server A tries to confirm that the user name and password are correct.
- Server A does not contain an entry corresponding to the client application. Instead, it contains a chained suffix to Server B, which contains the actual entry of the client. Server A sends a bind request to Server B.
- Server B sends an acceptance response to Server A.
- Server A then processes the client application's request using the chained suffix. The chained suffix contacts a remote data store located on Server B to process the search operation.
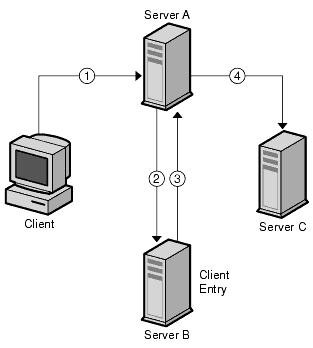
In a chained system, the entry corresponding to the client application does not need to be located on the same server as the data the client requests. Figure 5-15 illustrates how two chained suffixes can be used to satisfy a client's search request.
Figure 5-15 Chaining Using Two Chained Suffixes to Process a Client's Search Request
In Figure 5-15, the following steps are performed:
- The client application binds with Server A and Server A tries to confirm that the user name and password are correct.
- Server A does not contain an entry corresponding to the client application. Instead, it contains a chained suffix to Server B, which contains the actual entry of the client. Server A sends a bind request to Server B.
- Server B sends an acceptance response to Server A.
- Server A then processes the client application's request using another chained suffix. The chained suffix contacts a remote data store located on Server C to process the search operation.
However, chained suffixes do not support the following access controls:
- Controls that must access the content of the user entry are not supported when the user entry is located on a different server. This includes access controls based on groups, filters, and roles.
- Controls based on client IP addresses or DNS domains may be denied. This is because the chained suffix impersonates the client when it contacts remote servers. If the remote database contains IP-based access controls, it will evaluate them using the chained suffix's domain rather than the original client domain.