|
| |
| Sun Java(TM) System Directory Server 5.2 2005Q1 Technical Overview | |
Chapter 4
Directory Server AvailabilityFor your directory service to be successful it must of course be highly available. This chapter examines the replication mechanism offered by Directory Server whereby directory data is automatically copied from one directory to another, Directory Server's backup strategies and possibilities, as well as the high availability support provided by Sun Cluster 3.1 Agent. This chapter is divided into the following sections:
Replicating Your Directory Server
This section examines:
and provides you with a solid understanding of what Directory Server has to offer in terms of replication.
Replication Concepts
Replication is the mechanism that automatically copies directory data from one Directory Server to another. Using replication you can copy any directory tree or subtree (stored in its own suffix) between servers. Replication enables you to provide a highly available directory service, and to distribute data geographically. In practical terms replication provides the following benefits:
Fault tolerance and failover
By replicating directory trees to multiple servers, you can ensure that your directory is available even if a hardware, software, or network problem prevents directory client applications from accessing a particular Directory Server. Note that for write failover, you must have more than one master copy of your data in the replication environment.
Reduced response time by load balancing
By replicating directory tree across servers, you can reduce the access load on a given machine, thereby improving server response time. Replication is not however a solution for write scalability (which must instead be achieved by data partitioning).
Reduced response time by localizing data
By replicating directory entries to a location close to your users, you can improve directory response time.
Local data management
Replication enables you to own and manage data locally, while sharing it with other Directory Servers across your enterprise.
This section sets out to provide you with a basic understanding of Directory Server replication concepts and examines following:
Replica
A database that participates in replication is defined as a replica. There are three kinds of replica:
- Master, or read-write, replica: a read-write database that contains a master copy of the director data. A master replica can process update requests from directory clients.
- Consumer replica: a read-only database that contains a copy of the information held in the master replica. A consumer replica can process search requests from directory clients but refers update requests to master replicas.
- Hub replica: a read-only database, like a consumer replica, but stored on a Directory Server that supplies one or more consumer replicas.
You can configure Directory Server to manage several replicas, and each replica can play a different role in replication.
Suppliers and Consumers
A Directory Server that replicates to other servers is called a supplier. A Directory Server that is updated by other servers is called a consumer. The supplier replays all the updates on the consumer through specially designed LDAP v3 extended operations.
A server can be both a supplier and a consumer in the following cases:
- When the server contains a hub replica, that is receives updates from a supplier and replicates the changes to consumer(s). For more information refer to Cascading Replication.
- In multi-master replication, when a master replica is mastered on two or more different Directory Servers, each server acts as a supplier and a consumer of the other server. For more information refer to Multi-Master Replication.
- When the server manages a combination of master replicas and consumer replicas.
A server that plays the role of a consumer only, i.e. only contains a consumer replica, is called a dedicated consumer.
Replication Agreement
Directory Server uses replication agreements to define how replication occurs between two servers. It identifies amongst other things, the suffix to replicate, the consumer server to which the data is pushed, the times during which replication can occur, how the connection is secured (SSL or not). Note that a replication agreement describes replication between one supplier and one consumer. The replication agreement is configured on the supplier, and must be enabled for replication to work. It is possible to enable or disable existing replication agreements, which can be useful should you currently have no need for a replication agreement, but want to maintain its configuration for future use or backup possibilities.
Online Replica Promotion and Demotion
Directory Server enables you to promote and demote replicas online. Promoting or demoting a replica changes its role in the replication topology. Dedicated consumers may be promoted to hubs, and hubs may be promoted to masters. In the same way masters may be demoted to hubs, and hubs demoted to consumers. Note that both the promotion and demotion procedures are of necessity incremental: for promotion you must go from consumer to hub, then hub to master replica and vice versa for online demotion.
Online replica promotion and demotion provides increased flexibility and failover capabilities.
Consumer Initialization and Incremental Updates
Consumer initialization, or total update, is the process by which all data is physically copied from the supplier to the consumer. Once you have created a replication agreement, the consumer defined by that agreement must be initialized. When a consumer has been initialized, the supplier can begin replaying, or replicating update operations to the consumer. Under normal circumstances, the consumer should not require further initialization. However, if the data on a supplier is restored from a backup, you may need to reinitialize the consumers dependent on that supplier. For example if a restored supplier is the only supplier for a consumer in the topology, consumer reinitialization may be necessary. Initialization is possible both online and offline.
The replication updates sent to the consumer as the modifications are made (that is, the updates that follow the initialization) are called incremental updates. Provided that the updates originate from different replicas, Directory Server allows a consumer to be incrementally updated by several suppliers at once.
Data Consistency
Consistency refers to how closely the contents of replicated databases match each other at any given time. When you set up replication between two servers, part of the configuration is to schedule updates. The supplier determines when consumers must be updated, and initiates replication. Replication can start only after consumers have been initialized.
Directory Server provides the option of keeping replicas always synchronized, or of scheduling updates for a particular time of day, or day of the week. The advantage of keeping replicas always in sync is that data remains consistent across your topology. The cost, however, is the network traffic resulting from the frequent update operations. It is for you to decide what best suits your needs in terms of data consistency and your possibilities in terms of network connections and network traffic loads.
Possible Replication Configurations
Directory Server supports single master, cascading, and multi-master replication, all of which ensure the high availability of directory services for both read and write operations. Directory Server also provides a new replication feature, called fractional replication, for content security. We will examine the following configuration possibilities in this section:
Single Master Replication
In the most basic replication configuration, a supplier copies a master replica directly to one or more consumers. In this configuration, all directory modifications are made to the master replica, and the consumers contain read-only copies of the data. All modifications are propagated to the consumer replicas, in accordance with the replication agreement.
A single master replication configuration can be useful if you have a suffix that receives a large number of search and update requests from clients, as it allows you to distribute the search request load to the consumer which frees up the supplier for the update requests. Note that a supplier can replicate to several consumers, allowing you to distribute loads yet further, with the total number of consumers that a single supplier can manage depending on the speed of your network and the total number of entries that are modified on daily basis.
Cascading Replication
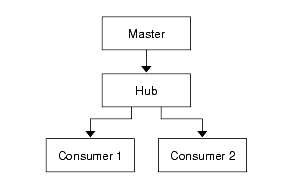
In cascading replication, Directory Server acts as a hub supplier. A hub is a read-only database, like a consumer replica, however, a hub also accepts replication from one or more master replicas and replicates the changes to consumer servers. Figure 4-1 illustrates a basic cascading replication scenario:
Figure 4-1
Cascading Replication Scenario
In a single master replication scenario, with one master and many consumers, the master's resources are consumed by replicating information. Using cascading replication, the master concentrates on handling operations, while the hub handles replicating data to all of the consumers.
You primarily use cascading replication to balance heavy traffic loads, reduce connection costs with local hubs in a geographically distributed environment, and increase performance. Using cascading replication, you can optimize the use of your hardware resources.
You can tune your cascaded architecture so that it optimizes the indexes, logs, and cache size of your Directory Server. For example, you can optimize the indexes on each server so that you have an update index for the supplier, a common name index for consumer 1 and a phone number index for Consumer 2.
Multi-Master Replication
Directory Server supports four-way multi-master replication over wide area networks. This means that in multi-master replication, a master replica is available on up to four Directory Servers. A master replica is a read-write database that contains a master copy of the directory data. Each master acts as a supplier and a consumer to the other Directory Servers.
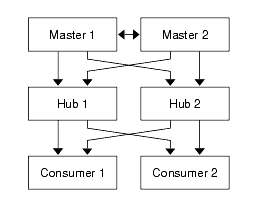
When combined with single master and cascading replication scenarios, multi-master replication provides a highly flexible and scalable replication environment for enterprises and service providers with global data center operations. Figure 4-2 illustrates a multi-master and cascading replication scenario:
Figure 4-2 Multi-Master and Cascading Replication Scenario
Four-way multi-master replication is ideal for distributed deployments. For example, an enterprise could establish two masters in San Francisco and two masters in New York. If something happened to both of the masters at a single location, the two masters at the other location can continue to provide the service.
Multi-master deployments provide 24x7 service levels with write failover. For example, if one server fails, the others remain available for writes. When the server comes back online, it receives replication updates from the other masters.
The multi-master replication protocol is streamlined, allowing you to:
You can implement a fully connected four-way multi-master replication topology, guaranteeing replication even if one or more masters fail. This type of deployment is appropriate for systems that have stringent availability requirements.
In terms of data consistency, multi-master replication uses a loose consistency replication model. This means that the same entries can be changed on different servers. When replication occurs between the two servers, the conflicting changes need to be resolved. Resolution occurs automatically, based on the timestamp associated with the change on each server.
Multi-Master Replication over Wide Area Networks (WAN)
The improved replication mechanism provided by Directory Server allows you to distribute directory databases across machines or network boundaries. The WAN, despite the challenges it introduces in terms of higher latency, lower bandwidth and a potentially higher number of errors (such as disconnections, packet loss, packets out of order, and congestion), no longer constitutes a stumbling block to replication configurations. For more detail on these replication performance enhancements see Enhanced Replication Performance.
Fractional Replication
In Directory Server, fractional replication allows you to replicate a subset of attributes for all the entries in a given database. This filtering functionality can be valuable in replication environments where Directory Servers are separated by WANs where one of your major objectives is to keep replication costs to a minimum.
Business Scenarios and Their Associated Replication Solutions
Now that you are familiar with basic replication concepts and configurations we will examine three different business scenarios with their associated replication solutions, to provide you with an initial understanding of how you might choose to deploy the replication possibilities Directory Server provides. This section will present the following scenarios:
Small Site with Local Availability Imperatives
Suppose your entire enterprise is contained within a single building. This building has a fast (100 MB per second) and lightly used network. The network is stable and you are reasonably confident of the reliability of your server hardware and OS platforms. You are also sure that a single server's performance will easily handle your site's load. However, as an online retail business, albeit a small business, high availability is crucial to your business success.
In this case, replicate at least once to ensure availability when your primary server is shut down for maintenance or hardware upgrades. Also, set up a DNS round robin to improve LDAP connection performance in the event that one of your Directory Servers becomes unavailable. Alternatively, use an LDAP proxy such as Sun Java System Directory Proxy Server. For more information on Directory Proxy Server, see http://www.sun.com/software/products/directory_proxy/home_dir_proxy.html.
Large Site with Heavy Network Traffic
Suppose your entire enterprise is contained within two buildings. The network is stable and you are reasonably confident of the reliability of your server hardware and OS platforms, and that a single server's performance will easily handle the load placed on a server within each building. However, the network has to support heavy loads, and is often saturated during normal working hours.
Also assume that you have slow (ISDN) connections between the buildings, and that this connection is very busy during normal business hours. Fortunately, however, there is no real need for close data consistency.
A typical replication strategy for this scenario would be:
This server should be placed in the building that contains the largest number of people responsible for the master copy of the data. Call this Building A. Choosing Building A to house the master copy of the data should help you to ensure that an increased number update operations are likely to be made from the same building, thus taking advantage of a faster and more reliable network connection.
- Create two replicas in the second building (Building B).
- As there is no need for close consistency between the master copy of the data and the replicated copies, schedule replication so that it occurs only during off peak hours, to alleviate network traffic loads.
- Configure cascading replication in each building with an increased number of consumers dedicated to lookups on the local data to provide further load balancing.
International Site with Data Privacy, High Availability and Performance Imperatives
Suppose your enterprise comprises two major data centers - one in France and the other in the USA - separated by a WAN. Not only do you need to replicate over a WAN, but you do not want your partners to have access to all data and want to filter out certain data. Your network is very busy during normal business hours and as an online banking institution it is essential for you to have high availability and optimized performance.
A typical replication strategy for this scenario would be:
- Hold master copies of directory data on servers in both data centers.
- Deploy a fully meshed, four-way, multi-master replication topology between France and the USA to provide high-availability and write-failover across the deployment.
Write-failover in both sites is essential to your 24x7 availability needs, and despite the performance strain it may place on your system, is not negotiable. The replication performance enhancements afforded by Directory Server, render it possible to configure a fully meshed, four-way, multi-master replication topology over the WAN. Although this topology threatens to place a strain on the system, the fact that you have a master copy of the data in each location, will prevent local users from having to perform update and lookup operations over the dial-up connection, thus optimizing performance.
To safeguard your high-availability needs ensure that the replication agreements you configure between the two French and USA master pairs are configured over separate network links to guard against the eventuality of one of the network links becoming unavailable or unreliable.
- Deploy as many consumers as you require in each data center to reduce the load on your masters in terms of directory lookups.
- Set up fractional replication agreements between masters and consumers in both geographical locations, to filter out the data you do not wish your partners to access.
- Schedule replication so that it occurs only during off peak hours to optimize bandwidth.
Backup and Restoration Possibilities
In any failure situation involving data corruption or data loss, it is imperative that you have a recent backup of your data. If you do not have a recent backup, you will have to re-initialize a failed master from another master. This section briefly presents the tools available to you for backing up and restoring your data. The command line utilities presented in this chapter are subcommands of the directoryserver command. For more information, see the Directory Server Man Page Reference. Based on the advantages and limitations of each method, you will select what best suits your overall requirements. This section is divided into two parts:
Backup Methods
Directory Server provides two methods of backing up data: binary backup (db2bak) and backup to an LDIF file (db2ldif). Both of these methods have advantages and limitations, and knowing how to use each method will assist you in planning an effective backup strategy.
Binary Backup (db2bak)
Binary backup is performed at the file system level. The output of a binary backup is a set of binary files containing all entries, indexes, the change log and the transaction log. It does not back up the dse.ldif configuration file, which you will need to do manually to restore a previous configuration.
Performing a binary backup allows you to back up all suffixes at once, and is significantly faster than a backup to LDIF. However, binary backup can only be performed on a server with an identical configuration. For the detailed list of what an identical configuration implies see the Planning a Backup Strategy section in the Directory Server Deployment Planning Guide. At a minimum, perform a regular binary backup on each set of coherent machines (machines that have an identical configuration, as defined previously).
Backup to LDIF (db2ldif)
Backup to LDIF is performed at the suffix level. The output of db2ldif is a formatted LDIF file. As such, this process takes longer than a binary backup. Note that replication information is only backed up if you use the -r option when running db2ldif and that the dse.ldif configuration file is not backed up in a backup to LDIF. Back this file up manually to enable you to restore a previous configuration.
Backup to LDIF has the advantage of being able to be performed from any server regardless of its configuration. However, in situations where rapid backup and restoration are required, backup to LDIF may take too long to be viable.
Take time to formulate a backup strategy which is well adapted to your availability needs. For further restrictions related to backups and replication see the Planning a Backup Strategy section in the Directory Server Deployment Planning Guide.
Restoration Methods
Directory Server also provides two methods of restoring data: binary restore (bak2db) and restoration from an LDIF file (ldif2db). As with the backup methods discussed previously, both of these methods have advantages and limitations. Again it will be up to you to decide which best suits your overall requirements.
Binary Restore (bak2db)
Binary restore copies data at the database level. Restoring data using binary restore therefore has the advantage that all suffixes can be restored at once and that it is significantly faster than restoring from an LDIF file. However, restoring data using binary restore can only be performed on a server with an identical configuration, and in the event of you being unaware that your database was corrupt when you performed the binary backup, you risk restoring a corrupt database, since binary backup creates an exact copy of the database.
Restoration From LDIF (ldif2db)
Restoration from an LDIF file is performed at the suffix level. As such, this process takes longer than a binary restore. Restoration from an LDIF file has the advantage that it can be performed on any server, regardless of its configuration, and that it allows you to renew all the indexes (particularly useful where existing indexes are corrupt). Because a single LDIF file can be used to deploy an entire directory service, regardless of its replication topology, restoration from LDIF is particularly useful for the dynamic expansion and contraction of a directory service according to anticipated business needs. However, in situations where rapid restoration is required, restoration from an LDIF file may take too long to be viable.
High Availability Support
The Sun Cluster agent is a high availability agent that provides LDAP service failover. It is bundled with Directory Server and on certain hardware and deployment configurations, can be used to improve the availability of Sun Java System services provided by multiple servers.
With Cluster, one backup node is offline, but constantly checks the viability of the primary node. If it does not respond, the backup node takes over the IP identity of the original node, responding to operations requests. This feature is useful for directories that support large populations with strict availability requirements, such as large banks or telecommunication companies. For more information on Sun Cluster see Sun Cluster 3.1 Product Documentation.