|
|
| Sun ONE Directory Server 5.2 Deployment Guide |
Chapter 4 Designing the Directory Tree
The directory information tree (DIT) provides a way to refer to the data stored in your directory. The types of information stored, the physical nature of your enterprise, the applications that use your directory, and the types of replication you use shape the design of the directory tree. This chapter outlines the steps for designing your own directory tree, and includes the following sections:
- Introduction to the Directory Tree
- Designing Your Directory Tree
- Grouping Directory Entries and Managing Attributes
- Directory Tree Design Examples
- Other Directory Tree Resources
Introduction to the Directory Tree
The directory tree provides a way for your directory data to be named and referred to by client applications. The directory tree interacts closely with other design decisions, including how you distribute, replicate, or control access to directory data. Designing an adequate directory tree upfront will be less time-consuming than redesigning an inadequate directory tree after deployment.
A well-designed directory tree provides the following:
- Simplified directory data maintenance
- Flexibility in creating replication policies and access controls
- Support for the applications using your directory
- Simplified directory navigation for users
The structure of your directory tree follows the hierarchical LDAP model. Your directory tree provides a way to organize your data, for example, by group, by people, or by place. It also determines how you partition data across multiple servers. For example, each database needs data to be partitioned at the suffix level. Without the proper directory tree structure, you may not be able to spread your data across multiple servers as you would like.
In addition to these considerations, you must bear in mind that your replication configuration possibilities will be restricted by the type of directory tree structure that you choose. You must carefully define your directory tree partitions for replication to work, and if you only want to replicate portions of your directory tree, that desire needs to be taken into account during your directory tree design process. In the same way, if you plan to use access controls on branch points, you need to take that into account at directory tree design time.
Designing Your Directory Tree
This section guides you through the major decisions you make during the directory tree design process. The directory tree design process involves choosing a suffix to contain your data, determining the hierarchical relationship amongst data entries, and naming the entries in your directory tree hierarchy. The following sections describe the directory tree design process in more detail:
Choosing a Suffix
The suffix is the name of the entry at the root of your tree, below which you store your directory data. Your directory can contain more than one suffix. You may choose to use multiple suffixes if you have two or more directory trees of information that do not have a natural common root.
By default, the standard Sun ONE Directory Server deployment contains multiple suffixes, one for storing data and the others for data needed by internal directory operations (such as configuration information and your directory schema). For more information on these standard directory suffixes, refer to Chapter 3, "Creating Your Directory Tree" in the Sun ONE Directory Server Administration Guide.
Suffix Naming Conventions
All entries in your directory should be located below a common base entry that is called the suffix. You can have more than one suffix in your directory and it is important to consider the following recommendations for naming the directory suffix:
- Globally unique
- Static, so that it rarely changes, if ever
- Short, so that entries beneath it are easier to read on screen
- Easy for a person to type and remember
In a single enterprise environment, choose a directory suffix that aligns with a DNS name or Internet domain name of your enterprise. For example, if your enterprise owns the domain name of Example.com, then you should use a directory suffix of:
dc=example,dc=com
The dc (domainComponent) attribute represents your suffix by breaking your domain name into its component parts.
Normally, you can use any attribute that you like to name your suffix. However, for a hosting organization, we recommend that the suffix contain only the following attributes:
- c (countryName)
Contains the two-digit code representing the country name, as defined by ISO.
- l (localityName)
Identifies the county, city, or other geographical area where the entry is located or which is associated with the entry.
- st (stateOrProvinceName)
Identifies the state or province where the entry resides.
- o (organizationName)
Identifies the name of the organization to which the entry belongs.
The presence of these attributes allows for interoperability with subscriber applications. For example, a hosting organization might use these attributes to create the following suffix for one of its clients, Example.com:
o=Example.com,st=Washington,c=US
For more information on these attributes, see Table 4-1.
Using an organization name followed by a country designation is typical of the X.500 naming convention for suffixes.
Naming Multiple Suffixes
Each suffix that you use with your directory is a unique directory tree. You can create multiple directory trees stored in separate databases served by Directory Server. For example, you could create separate suffixes for the Example.com and the Example2.com and store them in separate databases as illustrated in Figure 4-1:
Figure 4-1 Two Suffixes Stored in Two Different Databases
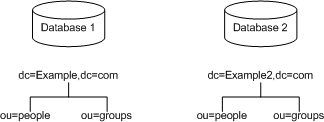
The databases could be stored on a single server or multiple servers depending upon resource constraints.
Creating Your Directory Tree Structure
You need to decide whether to use a flat or hierarchical tree structure. As a general rule, strive to make your directory tree as flat as possible. However, a certain amount of hierarchy can be important later on when you partition data across multiple databases, prepare replication, and set access controls.
The structure of your tree involves the following steps and considerations:
- Branching Your Directory
- Identifying Branch Points
- Replication Considerations
- Access Control Considerations
Branching Your Directory
Design your hierarchy to avoid problematic name changes. The flatter a namespace is, the less likely the names are to change. The likelihood of a name changing is roughly proportional to the number of components in the name that can potentially change. The more hierarchical the directory tree, the more components in the names, and the more likely the names are to change.
The following guidelines are specific to designing your directory tree hierarchy:
- Branch your tree to represent only the largest organizational subdivisions in your enterprise.
Any such branch points should be limited to divisions (Corporate Information Services, Customer Support, Sales and Professional Services, and so forth). Make sure that the divisions you use to branch your directory tree are stable; do not perform this kind of branching if your enterprise reorganizes frequently.
- Use functional or generic names rather than actual organizational names for your branch points.
Names change and you do not want to have to change your directory tree every time your enterprise renames its divisions. Instead, use generic names that represent the function of the organization (for example, use Engineering instead of Widget Research and Development).
- If you have multiple organizations that perform similar functions, try creating a single branch point for that function instead of branching based along divisional lines.
For example, even if you have multiple marketing organizations, each of which is responsible for a specific product line, create a single Marketing subtree. All marketing entries then belong to that tree.
Following are specific guidelines for the enterprise and hosting environment.
Branching in an Enterprise Environment
Name changes can be avoided if you base your directory tree structure on information that is not likely to change. For example, base the structure on types of objects in the tree rather than organizations. Some of the objects you might use to define your structure are:
- ou=people
- ou=groups
- ou=contracts
- ou=employees
- ou=services
A directory tree organized using these objects in an example enterprise Example.com, might appear as illustrated in Figure 4-2:
Figure 4-2 Sample Directory Information Tree Using 5 Branching Points

It is wise to try to use only the traditional attributes (shown in Table 4-1). Using traditional attributes increases the likelihood of retaining compatibility with third-party LDAP client applications. Using the traditional attributes also means that they will be known to the default directory schema, which makes it easier to build entries for the branch DN.
Table 4-1 Traditional DN Branch Point Attributes
Attribute Name
Definition
c
A country name.
o
An organization name. This attribute is typically used to represent a large divisional branching such as a corporate division, academic discipline (the humanities, the sciences), subsidiary, or other major branching within the enterprise. You should also use this attribute to represent a domain name as discussed in "Suffix Naming Conventions".
ou
An organizational unit. This attribute is typically used to represent a smaller divisional branching of your enterprise than an organization. Organizational units are generally subordinate to the preceding organization.
st
A state or province name.
l
A locality, such as a city, country, office, or facility name.
dc
A domain component as discussed in "Suffix Naming Conventions".
Branching in a Hosting Environment
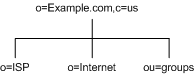
For a hosting environment, create a tree that contains two entries of the object class organization(o) and one entry of the organizationalUnit(ou) object class beneath the suffix. For example, the ISP Example.com branches their directory as illustrated in Figure 4-3:
Figure 4-3 ISP Example.com Directory Information Tree
Identifying Branch Points
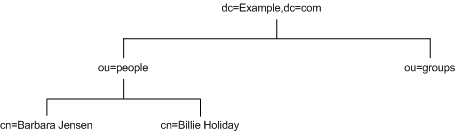
As you decide how to branch your directory tree, you will need to decide what attributes you will use to identify the branch points. Remember that a DN is a unique string composed of attribute-data pairs. For example, the DN of an entry for Barbara Jensen, an employee of Example.com Corporation, appears as follows:
cn=Barbara Jensen,ou=people,dc=example,dc=com
Each attribute-data pair represents a branch point in your directory tree. For example, the directory tree for the enterprise Example.com Corporation appears as illustrated in Figure 4-4:
Figure 4-4 Example.com Corporation Directory Information Tree
Likewise the directory tree for ExampleHost.com, an internet host would appear as illustrated in Figure 4-5:
Figure 4-5 ExampleHost.com Internet Host Directory Information Tree
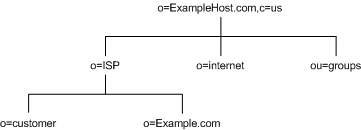
Beneath the suffix entry, o=ExampleHost.com,c=US, the tree is split into three branches. The ISP branch contains customer data and internal information for Example.com. The internet branch is the domain tree. The groups branch contains information about the administrative groups.
It is important to be consistent when choosing attributes for your branch points. Some LDAP client applications may be confused if the distinguished name (DN) format is inconsistent across your directory tree. That is, if l (localityName) is subordinate to o (organizationName)in one part of your directory tree, then make sure l is subordinate to o in all other parts of your directory.
Replication Considerations
During directory tree design, consider which entries you are replicating. A natural way to describe a set of entries to be replicated is to specify the distinguished name (DN) at the top of a subtree and replicate all entries below it. This subtree also corresponds to a database, a directory partition containing a portion of the directory data.
For example, in an enterprise environment you can organize your directory tree so that it corresponds to the network names in your enterprise. Network names tend not to change, so the directory tree structure will be stable. Further, using network names to create the top level branches of your directory tree is useful when you use replication to tie together different directory servers.
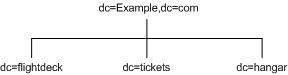
For example, Example.com Corporation has three primary networks known as flightdeck.Example.com, tickets.Example.com, and hanger.Example.com. They initially branch their directory tree as illustrated in Figure 4-6:
Figure 4-6 Three Primary Networks in Example.com Corporation DIT
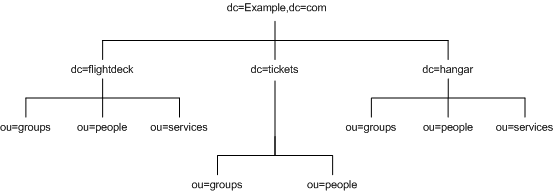
After creating the initial structure of the tree, they create additional branches as illustrated in Figure 4-7:
Figure 4-7 Detailed View of Three Primary Networks in Example.com Corporation DIT
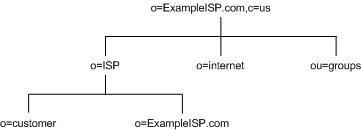
As another example, ExampleISP.com, an ISP company, branch their directory as illustrated in Figure 4-8:
Figure 4-8 Directory Information Tree for ExampleISP.com
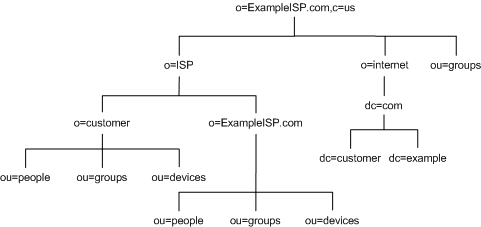
After creating the initial structure of their directory tree, they create additional branches as illustrated in Figure 4-9:
Figure 4-9 Detailed View of the DIT for ExampleISP.com
Both the enterprise and the hosting organization design their data hierarchies based on information that is not likely to change often.
Access Control Considerations
Introducing hierarchy into your directory tree can be used to enable certain types of access control. As with replication, it is easier to group together similar entries and then administer them from a single branch.
You can also enable the distribution of administration through a hierarchical directory tree. For example, if you want to give an administrator from the marketing department access to the marketing entries and an administrator from the sales department access to the sales entries, you can do so through your directory tree design.
You can set access controls based on the directory content rather than the directory tree. The ACI filtered target mechanism lets you define a single access control rule stating that a directory entry has access to all entries containing a particular attribute value. For example, you could set an ACI filter that gives the sales administrator access to all the entries containing the attribute ou=Sales.
However, ACI filters can be difficult to manage. You must decide which method of access control is best suited to your directory: organizational branching in your directory tree hierarchy, ACI filters, or a combination of the two. To facilitate the management of ACIs in your directory, Sun ONE Directory Server 5.2 provides functionality called getEffectiveRights to request which access control rights a given user has to directory entries and attributes. This getEffectiveRights functionality helps to ease user administration, access control policy verification, and debugging and is explained in more detail in Chapter 7 "Designing a Secure Directory."
Naming Entries
After designing the hierarchy of your directory tree, you need to decide which attributes to use when naming the entries within the structure. Generally, names are created by choosing one or more of the attribute values to form a relative distinguished name (RDN). The RDN is the left-most DN attribute value. The attributes you use depend on the type of entry you are naming.
Your entry names should adhere to the following rules:
- The attribute you select for naming should be unlikely to change.
- The name must be unique across your directory. A unique name ensures that a DN can refer to at most one entry in your directory.
When creating entries, define the RDN within the entry. By defining at least the RDN within the entry, you can locate the entry more easily. This is because searches are not performed against the actual DN but rather against the attribute values stored in the entry itself.
Attribute names have a meaning, so try to use the attribute name that matches the type of entry it represents. For example, do not use l (locality) to represent an organization, or c (country) to represent an organizational unit.
The following sections provide tips on naming entries:
Naming Person Entries
The person entry's name, the DN, must be unique. Traditionally, distinguished names use the commonName, or cn, attribute to name their person entries. That is, an entry for a person named Babs Jensen might have the distinguished name of:
cn=Babs Jensen,dc=example,dc=com
While allowing you to instantly recognize the person associated with the entry, it might not be unique in an organization where two people have identical names. This quickly leads to a problem known as DN name collisions, which are multiple entries with the same distinguished name.
You can avoid common name collisions by adding a unique identifier to the common name. For example:
cn=Babs Jensen+employeeNumber=23,dc=example,dc=com
However, this can lead to awkward common names for large directories and can be difficult to maintain.
A better method is to identify your person entries with some attribute other than cn. Consider using one of the following attributes:
- uid
Use the uid (userID) attribute to specify some unique value of the person. Possibilities include a user login ID or an employee number. A subscriber in a hosting environment should be identified by the uid attribute.
Use the mail attribute to contain the value for the person's e-mail address. This option can lead to awkward DNs that include duplicate attribute values (for example: mail=bjensen@Example.com, dc=example,dc=com), so you should use this option only if you cannot find some unique value that you can use with the uid attribute. For example, you would use the mail attribute instead of the uid attribute if your enterprise does not assign employee numbers or user IDs for temporary or contract employees.
- employeeNumber
For employees of the inetOrgPerson object class, consider using an employer assigned attribute value such as employeeNumber.
Whatever you decide to use for an attribute-data pair for person entry RDNs, you should make sure that they are unique, permanent values.
Considerations for Person Entries in a Hosted Environment
If a person is a subscriber to a service, the entry should be of object class inetUser and the entry should contain the uid attribute. The attribute must be unique within a customer subtree.
If a person is part of the hosting organization, represent them as an inetOrgPerson with the nsManagedPerson object class.
Placing Person Entries in the DIT
Here are some guidelines for placing people entries in your directory tree:
- People in an enterprise should be located in the directory tree below the organization's entry.
- Subscribers to a hosting organization need to be below the ou=people branch for the hosted organization.
Naming Organization Entries
The organization entry name, like other entry names, must be unique. Using the legal name of the organization along with other attribute values helps ensure the name is unique. For example, you might name an organization entry as follows:
o=Example.com+st=Washington,o=ISP,c=US
You can also use trademarks; however, they are not guaranteed to be unique.
In a hosting environment, you need to include the following attributes in the organization's entry:
- o (organizationName)
- objectClass with values of top, organization, and nsManagedDomain
Naming Other Kinds of Entries
Your directory will contain entries that represent many things, such as localities, states, countries, devices, servers, network information, and other kinds of data.
For these types of entries, use the commonName (cn) attribute in the RDN if possible. For example, if you are naming a group entry, name it as follows:
cn=allAdministrators,dc=example,dc=com
However, sometimes you need to name an entry whose object class does not support the commonName attribute. Instead, use an attribute that is supported by the entry's object class.
There does not have to be any correspondence between the attributes used for the entry's DN and the attributes actually used in the entry. However, having identifying attributes visible in the DN simplifies the administration of your directory tree.
Grouping Directory Entries and Managing Attributes
Your directory tree organizes the information of your entries hierarchically. This hierarchy is a type of grouping mechanism, though it is not well suited for associations between dispersed entries, for organizations that change frequently, or for data that is repeated in many entries. Directory Server provides you with groups and roles that are also grouping mechanisms but that offer more flexible associations between entries.
In addition to these grouping mechanisms, Directory Server provides the class of service (CoS) mechanism for managing attributes so that they are shared between entries in a way that is invisible to applications. Like the role mechanism, CoS generates virtual attributes on the entries as they are retrieved. However, CoS does not define membership but rather allows related entries to share data for coherence and space considerations.
These entry grouping and attribute management mechanisms and their associated advantages and limitations are described in the following sections:
- Static and Dynamic Groups
- Managed, Filtered, and Nested Roles
- Role Enumeration and Role Membership Enumeration
- Role Scope
- Role Limitations
- Deciding Between Groups and Roles
- Managing Attributes with Class of Service (CoS)
- About CoS
- Cos Definition Entries and CoS Template Entries
- CoS Priorities
- Pointer CoS, Indirect CoS, and Classic CoS
- CoS Limitations
Static and Dynamic Groups
A group is an entry that identifies the other entries that are its members. The scope of possible members of a group is the entire directory, regardless of where the group definition entries are located, which makes this grouping mechanism flexible, especially when your organization is one that undergoes frequent changes. Once you know the name of a group, it is easy to retrieve all of its member entries. The following list discusses the characteristics of both static and dynamic groups and helps you to understand in which cases it might be preferable to use each type of groups:
- Static groups explicitly name their member entries. An entry that defines a static group uses the groupOfNames or groupOfUniqueNames object class and contains the DN of each member as a value of the member or uniqueMember attribute, respectively. The member attribute contains a DN against which the server checks to establish group membership and the uniqueMember attribute syntax comprises a DN followed by an optional unique identifier, against which the server would conduct its membership check. However, today Directory Server only supports the groupOfNames (member attribute) native access control processing. For more information on the syntax of the uniqueMember attribute refer to RFC 2256: A Summary of the X.500(96) User Schema for use with LDAPv3 http://www.ietf.org/rfc/rfc2256.txt).
- Static groups are suitable for groups with few members, such as the group of directory administrators, and as a result not for groups with thousands of members. We recommend that you avoid creating static groups with more than 20,000 members, because they will have very poor performance. For groups of this size and more, we recommend using dynamic groups or roles. If you must use static groups to define groups with more than 20,000 members, use groups of groups rather than a single, large, static group.
- Dynamic groups specify a filter, and all entries that match the filter are members of the given group. These groups are dynamic because membership is defined every time the filter is evaluated. The definition entry of a dynamic group belongs to the groupOfUniqueNames and groupOfURLs object classes. The group members are listed either by one or more filters represented as LDAP URL values of the memberURL attribute or by one or more DNs as values of the uniqueMember attribute.
Note By inserting the DN of another group against the uniqueMember attribute of a dynamic group you can place groups inside other groups, i.e., you can nest groups.
Although both types of groups may identify members anywhere in the directory, we recommend that the group definitions themselves be located under an appropriately named node such as ou=Groups. This makes them easy to find, for example, when defining access control instructions (ACIs) that grant or restrict access when the bind credentials are members of a group.
Managed, Filtered, and Nested Roles
Roles are a new entry grouping mechanism that automatically identify all roles of which any entry is a member. Each role has members, or entries that possess the role. As with groups, you can specify role members either explicitly or dynamically. When you retrieve any entry in the directory, you can immediately know the roles to which it belongs, since the roles mechanism automatically generates the nsRole attribute containing the DN of all role definitions in which the entry is a member. This overcomes the main disadvantage of the group mechanism.
The role mechanism is very simple to use from the client perspective because the directory automatically computes all role membership. Every entry belonging to a role will be given the nsRole virtual attribute whose values are the DNs of all roles for which the entry is a member. The nsRole attribute is said to be virtual because it is generated on-the-fly by the server and never actually stored in the directory. This means that evaluating roles is more resource intensive than evaluating groups because the server does the work for the client application. However, checking role membership is uniform and is performed transparently on the server side.
Sun ONE Directory Server supports the following three types of roles:
- Managed Roles - Explicitly assign a role to member entries.
- Filtered Roles - Entries are members if they match a specified LDAP filter. In this way, the role depends upon the attributes contained in each entry.
- Nested Roles - Allow you to create roles that contain other roles.
Managed Roles
Managed roles are similar to static groups, except that membership is defined in each member entry and not in the role definition entry. With managed roles, the administrator assigns a given role by adding the nsRoleDN attribute to the participating entries. The value of this attribute is the DN of the role definition entry. The static role definition entry only defines the scope of its effect. Members of that role are entries in the scope that name the DN of the role definition entry in their nsRoleDN attribute.
Filtered Roles
Filtered roles are similar to dynamic groups: they define a filter that determines the members of the role. The value of their nsRoleFilter attribute, defines the filtered role. Whenever the server returns an entry in the scope of a filtered role that matches its filter string, that entry will contain the generated nsRole attribute identifying the role.
Nested Roles
A nested role lists the definition entries of other roles and combines all the members of their roles. In other words, if an entry is a member of a role that is listed in a nested role, then the entry is also a member of the nested role. Nested roles allow you to create roles that contain other roles.
Role Enumeration and Role Membership Enumeration
Role Enumeration
The nsRole attribute is read like any other attribute, and clients may use it to enumerate all roles to which any entry belongs. The nsRole attribute may only be used by the roles mechanism and is protected against all modifications. However, it can be read, so should your security requirements be such that you do not want to expose your role membership to read access, you may want to define access controls to protect it against reading.
Role Membership Enumeration
In contrast to previous releases of Directory Server, you can now perform searches on virtual attributes, which means that it is now possible to perform a search on the nsRole attribute, and enumerate the members of your role. However, it is important to bear in mind that non-indexed attributes in a search operation may have a considerable performance impact. Searches based on equality filters are likely to be indexed and as a result efficient, but negation searches for example will not be indexed and will result in poorer performance. Since the nsRoleDN attribute is indexed by default, searches on managed roles should be relatively efficient. However, with regard to filtered and nested roles, where filters can contain both indexed and non-indexed attributes, care should be taken to ensure that the filter contains at least one indexed attribute so as not to launch a non-indexed search.
Role Scope
In previous releases of Directory Server the scope of role was limited to the subtree of the role definition. If you wanted to have shared roles across different subtrees, they had to be at the root of the tree, which meant that cross subtree roles were limited and complicated to administer. Imagine a engineer working for the engineering department of a large enterprise Example.com, who needed to access an application controlled by the sales department. If a role had been created for the sales administrators to control access to this application within the sales subtree, then the engineer who did not belong to the sales subtree, but instead the engineering subtree, had no way of accessing the application in question, as role scope was strictly subtree limited. Given that groups did not (and still do not) have the same scope limitations, the solution would have been to add the engineer to the group of users in the sales organization that had access to the application. However, as this solution was necessarily a group based one, the advantages of the roles mechanism would have been lost as a result.
Sun ONE Directory Server 5.2 provides a new attribute that allows the scope of a role to be extended beyond the subtree of the role definition entry. This new single-valued attribute nsRoleScopeDN contains the DN of the scope we want to add to an existing role.
Note The new scope extending nsRoleScopeDN attribute can only be added to a nested role.
Our previous example of the engineer working for Example.com requiring access to a sales application will help illustrate how the scope of a role can now be extended. Imagine the two main subtrees in the Example.com directory tree: o=eng,dc=example,dc=com for the engineering subtree and o=sales, dc=example,dc=com for the sales subtree. To extend the scope of a sales subtree role called SalesAppManagedRole that governs access to a sales application, to include an engineer user in the engineering subtree, you would need to do the following:
- Create a role for the engineer user in the engineering subtree, for example, EngineerManagedRole. (In our example we have chosen to create a managed role but it could just as well have been a filtered or nested role).
- Create a nested role, for example, SalesAppPlusEngNestedRole, in the sales subtree to house the newly created EngineerManagedRole role and the initial SalesAppManagedRole role.
- Add the new nsRoleScopeDN attribute to the new SalesAppPlusEngNestedRole nested role, with the DN of the engineering subtree scope you want to add, i.e. in this case o=eng,dc=example,dc=com.
The new SalesAppPlusEngNestedRole nested role would read as follows:
dn:cn=SalesAppPlusEngNestedRole,dc=example,dc=com
objectclass:LDAPsubentry
objectclass:nsRoleDefinition
objectclass:nsComplexRoleDefinition
objectclass:nsNestedRoleDefinition
nsRoleDN:cn=SalesAppManagedRole,o=sales,dc=example,dc=com
nsRoleDN:cn=EngineerManagedRole,o=eng,dc=example,dc=com
nsRoleScopeDN:o=eng,dc=example,dc=com
From an access control point of view, it is essential that the necessary permissions be granted to the engineering user wanting to access the sales application, so that access can in fact be gained to the SalesAppPlusEngNestedRole role, and in turn the actual sales application. Similarly, in the context of replication you must be sure to replicate the entire scope of your role, because if you fail to replicate the extended scope you will encounter problems.
Role Limitations
When creating roles to support your directory service, you need to be aware of the following limitations:
- Roles and chaining
If your directory tree is distributed over several servers using the chaining feature, entries that define roles must be located on the same server as the entries possessing those roles. If one server, A, receives entries from another server, B, through chaining, those entries will contain the roles defined on B, but will not be assigned any of the roles defined on A.
- Filtered Roles cannot use CoS generated attributes
The filter string of a filtered role cannot be based on the values of a CoS virtual attribute. For further information see "About CoS". However, the specifier attribute in a Cos definition may reference the nsRole attribute generated by a role definition. For further information concerning the creation of role-based attributes, refer to "Creating Role-Based Attributes" in Chapter 5 of the Sun ONE Directory Server Administration Guide.
- Extending the Scope of Roles
Only scope your roles to different subtrees on the same server instance. Scoping roles to other servers may result in unpredictable behavior.
Deciding Between Groups and Roles
The groups and roles mechanisms provide some overlapping functionality that can lead to some ambiguity. Both methods of grouping entries have advantages and disadvantages. Generally speaking, the newer roles mechanism is designed to provide frequently required functionality in a more efficient manner. However, because the choice of a grouping mechanism influences your server complexity and determines how your client processes membership information, you need to plan your grouping mechanism carefully. You must be sure to understand what type of set membership query and set management operations you will be needing to perform in order to decide which mechanism fits your needs. The following two parts in this section present the advantages and disadvantages of both mechanisms and should guide you in your design choice. We strongly recommend that you document your design choice to allow administrators to maintain the grouping policy consistently at a later date.
This section is divided into the following parts:
Advantages of the Groups Mechanism
- Static Groups are preferable to roles for enumerating members, when membership does not exceed 20,000 members.
If you only need to enumerate members of a given set, then it is less costly to use static groups, provided that the number of members does not exceed 20,000 as static groups with more than this number of members would have a negative impact on performance. Enumerating members of a static group by retrieving the member attribute is easier than recovering all entries that share a role, thus making them more suited to member enumeration operations.
- Static groups are preferable to roles for set management operations such as assigning and removing members.
If you want to assign a user to a set or remove a user from a set the simplest grouping mechanism for performing this task is static groups because it does not involve having special access rights to add the user to the group.
Having the right to create the group entry automatically gives you the right to assign members to that group, which is not the case for managed and filtered roles, where the administrator must also have the right to write the nsroledn attribute to the user entry. The same access right restrictions also apply indirectly to nested roles, as the ability to create a nested role implies the ability to be able to pull together other roles that have already been defined.
- Dynamic groups are preferable to roles for use in filter-based ACIs.
If you only need to find all members based on a filter, such as for designating bind rules in ACIs, use dynamic groups. Although filtered roles are similar to dynamic groups, they will trigger the roles mechanism and generate the virtual nsRole attribute. If your client does not need the nsRole value, opting for dynamic groups will avoid the overhead of this computation.
- Groups are preferable to roles for adding or removing sets into or from existing sets.
If you want to add or remove a set into or from an existing set, then the groups mechanism is the simplest to use, as there are no nesting restrictions. The roles mechanism, on the other hand, only allows nested roles to receive other roles.
- Groups are preferable to roles if freedom of scope for grouping your entries is critical to your deployment.
Groups are flexible in terms of scope as the scope for possible members is the entire directory, regardless of where the group definition entries are located. Although roles can also extend their scope beyond a given subtree, they can only do so by adding a scope-extending attribute nsRoleScopeDN to a nested role, which constitutes a scope extension limitation.
Advantages of the Roles Mechanism
- Roles are preferable to groups if you want to enumerate members of a given set and find all set membership for a given entry.
The roles mechanism is your best choice for enumerating members of a given set and finding all set membership for a given entry, as roles push this information out to the user entry where it can be cached to make subsequent membership tests more efficient. The server performs all computations, and the client only needs to read the values of the nsRole attribute. In addition to this, all types of roles appear in this attribute, allowing the client to process all roles uniformly. Generally speaking roles can do both operations more efficiently and with simpler clients than is possible with groups.
- Roles are preferable to groups if you want to integrate your grouping mechanism with existing Directory Server functionality such as CoS, Password Policy, Account Inactivation and ACIs.
If you want to use the membership of a set "naturally" in the server, that is, take advantage of the computation work that the server will automatically do regarding membership, then the roles mechanism is your best option. This is ultimately what roles were designed for, which means that they can be used in resource-orientated ACIs, as a basis for CoS, as part of more complex search filters, Password Policy, Account Inactivation, etc. Groups do not allow you to do this kind of integration work.
Managing Attributes with Class of Service (CoS)
As previously stated in the introduction to this section on grouping directory entries and managing attributes, the class of service (CoS) mechanism allows you to share attributes between entries in a way that is invisible to applications. CoS generates virtual attributes on entries as they are retrieved, in the same way as the roles mechanism. CoS does not define membership, in that it does not group entries in the way that the roles mechanism does, but rather allows related entries share data for coherence and space considerations. This section examines the CoS mechanism in more detail and is divided into the following parts:
- About CoS
- CoS Definition Entries and Template Entries
- CoS Priorities
- Pointer, Indirect, and Classic CoS
- CoS Limitations
About CoS
Imagine a directory containing thousands of entries that all have the same value for the facsimileTelephoneNumber attribute. Traditionally, to change the fax number, you would need to update each entry individually, a large job for administrators that is not only time consuming but also runs the risk of not updating all entries. Using CoS, the fax number is stored in a single place, and Directory Server automatically generates the facsimileTelephoneNumber attribute on every concerned entry as it is returned.
To client applications, a generated CoS attribute is retrieved just as any other attribute. However, directory administrators now have only a single fax value to manage. In addition, because there are less values actually stored in the directory, the database uses less disk space. The CoS mechanism also allows entries to override a generated value or to generate multiple values for the same attribute.
Note As CoS virtual attributes are not indexed, referencing them in an LDAP search filter may have an impact on performance.
The generated CoS attributes may be multi-valued from several templates. Specifiers may designate several template entries, or there may be several CoS definitions for the same attribute. Alternatively, you may specify template priorities so that only one value is generated from all chosen templates. For more information, refer to "Defining Class of Service (CoS)" in Chapter 5 of the Sun ONE Directory Server Administration Guide.
Roles and the classic CoS can be used together to provide role-based attributes. These attributes appear on an entry because it possesses a particular role with an associated class of service template. For example, you could use a role-based attribute to set the server look through limit on an role-by-role basis.
CoS functionality can be used recursively. In other words, Directory Server lets you generate attributes through CoS that depend on other attributes generated through CoS. Complex CoS schemes may simplify client application access to information and ease administration of repeated attributes, but they also increase management complexity and degrade server performance. Avoid overly complex CoS schemes, for example, many indirect CoS schemes can be redefined as classic or pointer CoS.
Finally, avoid changing CoS definitions more often than is strictly necessary. Modifications to CoS definitions do not take effect immediately, because the server caches CoS information. Although caching accelerates read access to generated attribute entries, when changes to CoS information actually occur, the server must reconstruct the cache, a task that takes some time, usually in the order of seconds. During cache reconstruction, read operations may still access the old cached information, rather than the newly modified information, which means that if you change CoS definitions too frequently, you are likely to be accessing outdated data.
Cos Definition Entries and CoS Template Entries
The CoS mechanism relies on two types of helper entries called the CoS definition entry and the CoS template entry. This section examines both entries in more detail and is divided into the following parts:
CoS Definition Entry
The CoS definition entry identifies the type of CoS you are using and the names of the CoS attribute that will be generated. Like the role definition entry, it inherits from the LDAPsubentry object class. The location of the definition entry determines the scope of the CoS deviations, which is the entire subtree below the parent of the CoS definition entry. All entries in the branch of the definition entry's parent are called target entries for the CoS definition. Multiple definitions may exist for the same CoS attribute, which, as a result, may be multi-valued.
The CoS definition entry is an instance of the cosSuperDefinition object class. The CoS definition entry also inherits from one of the following object classes to specify the type of CoS:
- cosPointerDefinition
- cosIndirectDefinition
- cosClassicDefinition
The CoS definition entry contains the attributes specific to each type of CoS for naming the virtual CoS attribute, the template DN, and the specifier attribute in target entries, if needed. By default, the CoS mechanism will not override the value of an existing attribute with the same name as the CoS attribute. However, the syntax of the CoS definition entry allows you to control this behavior.
CoS Template Entry
The CoS template entry contains the value that will be generated for the CoS attribute. All entries within the scope of the CoS will use the values defined here. There may be several templates, each with a different value, in which case the generated attribute may be multi-valued. The CoS mechanism will select one of these values based on the contents of both the definition entry and the target entry.
The CoS template entry is an instance of the cosTemplate object class. The CoS template entry contains the value or values of the attributes generated by the CoS mechanism. The template entries for a given CoS are stored in the directory tree at the same level as the CoS definition.
Note When possible, definition and template entries should be located in the same place to make for easier management. It is also wise to name them in a way that suggests the functionality they provide. For example, a definition entry DN such as "cn=classicCosGenerateEmployeeType,ou=People,dc=example,dc=com" is more descriptive than "cn=ClassicCos1,ou=People,dc=example,dc=com". For more information about the object classes and attributes associated with each type of CoS, refer to " Defining Class of Service (CoS)" in Chapter 5 of the Sun ONE Directory Server Administration Guide.
CoS Priorities
It is possible to create CoS schemes that compete with each other to provide an attribute value. For example, you might have a multi-valued cosSpecifier in your CoS definition entry. In such a case, you can specify a template priority on each template entry to determine which template provides the attribute value. Set the template priority using the cosPriority attribute. This attribute represents the global priority of a particular template numerically. A priority of zero is the highest possible priority.
Templates that contain no cosPriority attribute are considered the lowest possible priority. In the case where two or more templates are considered to supply an attribute value and they have the same (or no) priority, a value is chosen arbitrarily.
For example, a CoS template entry appears as follows:
dn: cn=exampleUS,cn=data
objectclass: top
objectclass: cosTemplate
postalCode: 44438
cosPriority: 0This template entry contains the value for the postalCode attribute. It contains a priority of zero, which means it has precedence over any other conflicting templates that define a different postalCode value.
Pointer CoS, Indirect CoS, and Classic CoS
There are three types of CoS that differ in how the template, and thus the generated value, is selected. The three different types of CoS presented in more detail in this section are:
Pointer CoS
Pointer CoS is the simplest type of CoS, in that the pointer CoS definition entry gives the DN of a specific template entry of the cosTemplate object class. All target entries will have the same CoS attribute value, as defined by this template.
Pointer CoS Example
This example shows a CoS that defines a common postal code for all of the entries stored under dc=example,dc=com. The three entries (CoS definition entry, CoS template entry and the target entry) for this example are shown in Figure 4-10:
Figure 4-10 Example of a Pointer CoS Definition and Template
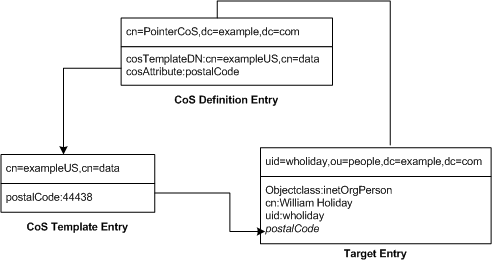
The template entry is identified by its DN, cn=exampleUS,cn=data, in the CoS definition entry. Each time the postalCode attribute is queried on entries under dc=example,dc=com, Directory Server returns the value available in the template entry cn=exampleUS,cn=data. Therefore, the postal code will appear with the entry uid=wholiday,ou=people,dc=example,dc=com, but it is not stored there. When we imagine a scenario where several shared attributes are generated by CoS for thousands or millions or entries, instead of existing as real attributes in each entry, we appreciate the storage space savings and performance gains that CoS makes possible.
Indirect CoS
Indirect CoS allows any entry in the directory to be a template and provide the CoS value. The indirect CoS definition entry identifies an attribute, called the indirect specifier, whose value in a target entry determines the template used for that entry. The indirect specifier attribute in the target entry must contain a DN. With indirect CoS, each target entry may use a different template and thus have a different value for the CoS attribute.
For example, an indirect CoS that generates the departmentNumber attribute may use an employee's manager as the specifier. When retrieving a target entry, the CoS mechanism will use the DN value of the manager attribute as the template. It will then generate the departmentNumber attribute for the employee using the same value as the manager's department number.
Indirect CoS Example
This example of an indirect CoS uses the manager attribute of the target entry to identify the template entry. In this way, the CoS mechanism can generate the departmentNumber attribute of all employees to be the same as their manager's, ensuring that it is always up to date. The three entries for this example are shown in Figure 4-11:
Figure 4-11 Example of an Indirect CoS Definition and Template
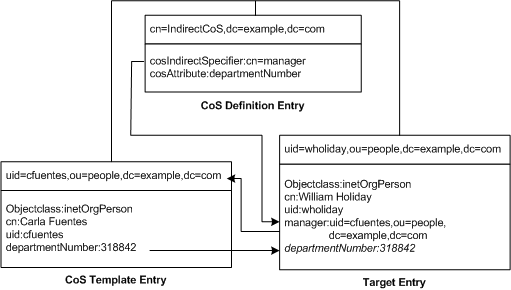
The indirect CoS definition entry names the specifier attribute, which in this example, is the manager attribute. William Holiday's entry is one of the target entries of this CoS, and his manager attribute contains the DN of cn=Carla Fuentes,ou=people,dc=example,dc=com. Therefore, Carla Fuentes' entry is the template, which in turn provides the departmentNumber attribute value of 318842.
Classic CoS
Classic CoS combines the pointer and indirect CoS behavior. The classic CoS definition entry identifies the base DN of the template and a specifier attribute. The value of the specifier attribute in the target entries is then used to construct the DN of the template entry as follows:
cn=specifierValue,baseDN
The template containing the CoS values is determined by the combination of the RDN (relative domain name) value of the specifier attribute in the target entry and the template's base DN.
Classic CoS templates are entries of the cosTemplate object class to avoid the performance issue associated with arbitrary indirect CoS templates.
Classic CoS Example
The classic CoS mechanism determines the DN of the template from the base DN given in the definition entry and the specifier attribute in the target entry. The value of the specifier attribute will be taken as the cn value in the template DN. Template DNs for classic CoS must therefore have the following structure:
cn=specifierValue,baseDN
The example inFigure 4-12 shows a classis CoS definition that generates a value for the postal code attribute:
Figure 4-12 Example of a Classic CoS Definition and Template
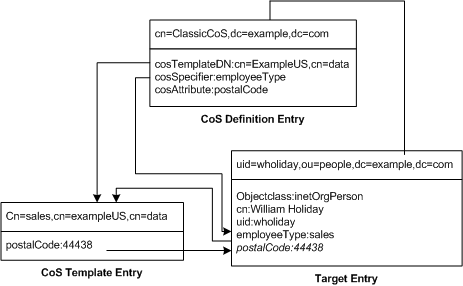
In this example, the Cos definition entry's cosSpecifier attribute names the employeeType attribute. The combination of this attribute and the template DN identifies the template entry as cn=sales,cn=exampleUS,cn=data. The template entry then provides the value of the postalCode attribute to the target entry.
CoS Limitations
The CoS functionality is a complex mechanism which, for performance and security reasons, is subject to the following limitations.
- Restricted Subtrees
You cannot create CoS definitions in either the cn=config or cn=schema subtrees.
- Searches in suffixes where an attribute is declared as a CoS generated attribute will result in an unindexed search.
CoS generated attributes will only result in unindexed searches in suffixes where they are declared as CoS attributes. This may have a significant impact on performance. In suffixes where the same attribute is NOT declared as a CoS attribute, then the search will be indexed.
- Restricted Attribute Types
The following attribute types should not be generated by the CoS mechanism because they will not have the same behavior as real attributes of the same name:
- userPassword - A CoS-generated password value cannot be used to bind to the directory server.
- aci - The directory server will not apply any access control based on the contents of a virtual ACI value defined by CoS.
- objectclass - The directory server will not perform schema checking on the value of a virtual object class defined by CoS.
- nsRoleDN - A CoS-generated nsRoleDN value will not be used by the server to generate roles.
- All templates must be local
The DNs of template entries, either in a CoS definition or in the specifier of the target entry, must refer to local entries in the directory. Templates and the values they contain cannot be retrieved through directory chaining or referrals.
- CoS virtual values cannot be combined with real values
The values of a CoS attribute are never a combination of real values from the entry and virtual values from the templates. When the CoS overrides a real attribute value, it replaces all real values with those from the templates. However, the CoS mechanism can combine virtual values from several CoS definition entries as described in the "CoS Limitations" section of the Sun ONE Directory Server Administration Guide.
- Filtered Roles cannot use CoS generated attributes
The filter string of a filtered role cannot be based on the values of a CoS virtual attribute. However, the specifier attribute in a CoS definition may reference the nsRole attribute generated by a role definition. For more information see the "Creating Role-Based Attributes" section in the Sun ONE Directory Server Administration Guide.
- Access Control Instructions (ACIs)
The server controls access to attributes generated by a CoS in exactly the same way as regular, stored attributes. However, access control rules that depend on the value of attributes generated by CoS are subject to the conditions described in "Restricted Attribute Types".
- CoS Cache Latency
The CoS cache is an internal Directory Server structure which keeps all CoS data in memory to improve performance. This cache is optimized for retrieving CoS data to be used in computing virtual attributes, even while CoS definition and template entries are being updated. Therefore, once definition and template entries have been added or modified, there may be a slight delay before they are taken into account. This delay depends upon the number and complexity of CoS definitions, as well as the current server load, but it is usually in the order of a few seconds. Bear this latency in mind before embarking on overly complex CoS configurations.
Directory Tree Design Examples
The following sections provide examples of directory trees designed to support a flat hierarchy as well as several examples of more complicated hierarchies.
Directory Tree for an International Enterprise
To support an international enterprise, root your directory tree in your Internet domain name and then branch your tree for each country where your enterprise has operations immediately below that root point. In "Suffix Naming Conventions", you are advised to avoid rooting your directory tree in a country designator. This is especially true if your enterprise is international in scope.
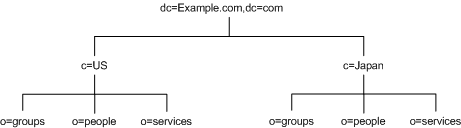
Because LDAP places no restrictions on the order of the attributes in your DNs, you can use the c (countryName) attribute to represent each country branch as illustrated in Figure 4-13:
Figure 4-13 Use of c (countryName) Attribute to Represent Countries in a Directory Information tree
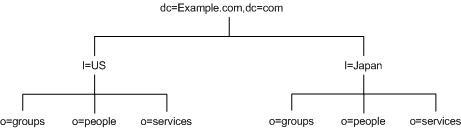
However, some administrators feel that this is stylistically awkward, so instead you could use the l (locality) attribute to represent different countries as shown in:
Figure 4-14 Use of l (locality) Attribute to Represent Countries in a Directory Information Tree
Directory Tree for an ISP
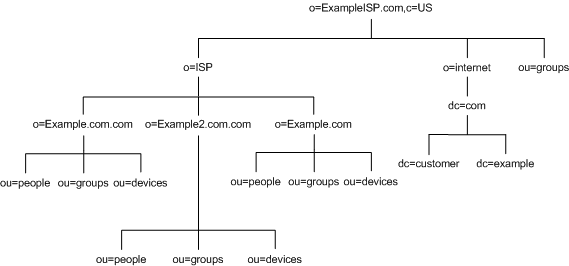
Internet service providers (ISPs) may support multiple enterprises with their directories. If you are an ISP, consider each of your customers as a unique enterprise and design their directory trees accordingly. For security reasons, each account should be provided with a unique directory tree that has a unique suffix and an independent security policy.
You can assign each customer a separate database, and store these databases on separate servers. Placing each directory tree in its own database allows you to back up and restore data for each directory tree without affecting your other customers.
In addition, partitioning helps reduce performance problems caused by disk contention, and reduces the number of accounts potentially affected by a disk outage. Figure 4-15 below shows the directory tree for Example.com, an ISP:
Figure 4-15 Directory Tree for Example.com ISP
Other Directory Tree Resources
Take a look at the following links for more information about designing your directory tree:
- RFC 2247: Using Domains in LDAP/X.500 Distinguished Names
http://www.ietf.org/rfc/rfc2247.txt
- RFC 2253: LDAPv3, UTF-8 String Representation of Distinguished Names
http://www.ietf.org/rfc/rfc2253.txt