| Numerical Computation Guide |
What Every Computer Scientist Should Know About Floating-Point Arithmetic
Note – This appendix is an edited reprint of the paper What Every Computer Scientist Should Know About Floating-Point Arithmetic, by David Goldberg, published in the March, 1991 issue of Computing Surveys. Copyright 1991, Association for Computing Machinery, Inc., reprinted by permission.
Abstract
Floating-point arithmetic is considered an esoteric subject by many people. This is rather surprising because floating-point is ubiquitous in computer systems. Almost every language has a floating-point datatype; computers from PCs to supercomputers have floating-point accelerators; most compilers will be called upon to compile floating-point algorithms from time to time; and virtually every operating system must respond to floating-point exceptions such as overflow. This paper presents a tutorial on those aspects of floating-point that have a direct impact on designers of computer systems. It begins with background on floating-point representation and rounding error, continues with a discussion of the IEEE floating-point standard, and concludes with numerous examples of how computer builders can better support floating-point.
Categories and Subject Descriptors: (Primary) C.0 [Computer Systems Organization]: General -- instruction set design; D.3.4 [Programming Languages]: Processors -- compilers, optimization; G.1.0 [Numerical Analysis]: General -- computer arithmetic, error analysis, numerical algorithms (Secondary)
D.2.1 [Software Engineering]: Requirements/Specifications -- languages; D.3.4 Programming Languages]: Formal Definitions and Theory -- semantics; D.4.1 Operating Systems]: Process Management -- synchronization.
General Terms: Algorithms, Design, Languages
Additional Key Words and Phrases: Denormalized number, exception, floating-point, floating-point standard, gradual underflow, guard digit, NaN, overflow, relative error, rounding error, rounding mode, ulp, underflow.
Introduction
Builders of computer systems often need information about floating-point arithmetic. There are, however, remarkably few sources of detailed information about it. One of the few books on the subject, Floating-Point Computation by Pat Sterbenz, is long out of print. This paper is a tutorial on those aspects of floating-point arithmetic (floating-point hereafter) that have a direct connection to systems building. It consists of three loosely connected parts. The first section, Rounding Error, discusses the implications of using different rounding strategies for the basic operations of addition, subtraction, multiplication and division. It also contains background information on the two methods of measuring rounding error, ulps and
relativeerror. The second part discusses the IEEE floating-point standard, which is becoming rapidly accepted by commercial hardware manufacturers. Included in the IEEE standard is the rounding method for basic operations. The discussion of the standard draws on the material in the section Rounding Error. The third part discusses the connections between floating-point and the design of various aspects of computer systems. Topics include instruction set design, optimizing compilers and exception handling.I have tried to avoid making statements about floating-point without also giving reasons why the statements are true, especially since the justifications involve nothing more complicated than elementary calculus. Those explanations that are not central to the main argument have been grouped into a section called "The Details," so that they can be skipped if desired. In particular, the proofs of many of the theorems appear in this section. The end of each proof is marked with the z symbol. When a proof is not included, the z appears immediately following the statement of the theorem.
Rounding Error
Squeezing infinitely many real numbers into a finite number of bits requires an approximate representation. Although there are infinitely many integers, in most programs the result of integer computations can be stored in 32 bits. In contrast, given any fixed number of bits, most calculations with real numbers will produce quantities that cannot be exactly represented using that many bits. Therefore the result of a floating-point calculation must often be rounded in order to fit back into its finite representation. This rounding error is the characteristic feature of floating-point computation. The section Relative Error and Ulps describes how it is measured.
Since most floating-point calculations have rounding error anyway, does it matter if the basic arithmetic operations introduce a little bit more rounding error than necessary? That question is a main theme throughout this section. The section Guard Digits discusses guard digits, a means of reducing the error when subtracting two nearby numbers. Guard digits were considered sufficiently important by IBM that in 1968 it added a guard digit to the double precision format in the System/360 architecture (single precision already had a guard digit), and retrofitted all existing machines in the field. Two examples are given to illustrate the utility of guard digits.
The IEEE standard goes further than just requiring the use of a guard digit. It gives an algorithm for addition, subtraction, multiplication, division and square root, and requires that implementations produce the same result as that algorithm. Thus, when a program is moved from one machine to another, the results of the basic operations will be the same in every bit if both machines support the IEEE standard. This greatly simplifies the porting of programs. Other uses of this precise specification are given in Exactly Rounded Operations.
Floating-point Formats
Several different representations of real numbers have been proposed, but by far the most widely used is the floating-point representation.1 Floating-point representations have a base
(which is always assumed to be even) and a precision p. If
In general, a floating-point number will be represented as ± d.dd... d ×
(1).
The term floating-point number will be used to mean a real number that can be exactly represented in the format under discussion. Two other parameters associated with floating-point representations are the largest and smallest allowable exponents, emax and emin. Since there are
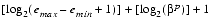
bits, where the final +1 is for the sign bit. The precise encoding is not important for now.
There are two reasons why a real number might not be exactly representable as a floating-point number. The most common situation is illustrated by the decimal number 0.1. Although it has a finite decimal representation, in binary it has an infinite repeating representation. Thus when
or smaller than 1.0 ×
. Most of this paper discusses issues due to the first reason. However, numbers that are out of range will be discussed in the sections Infinity and Denormalized Numbers.
Floating-point representations are not necessarily unique. For example, both 0.01 × 101 and 1.00 × 10-1 represent 0.1. If the leading digit is nonzero (d0
0 in equation (1) above), then the representation is said to be normalized. The floating-point number 1.00 × 10-1 is normalized, while 0.01 × 101 is not. When
, since this preserves the fact that the numerical ordering of nonnegative real numbers corresponds to the lexicographic ordering of their floating-point representations.3 When the exponent is stored in a k bit field, that means that only 2k - 1 values are available for use as exponents, since one must be reserved to represent 0.
Note that the × in a floating-point number is part of the notation, and different from a floating-point multiply operation. The meaning of the × symbol should be clear from the context. For example, the expression (2.5 × 10-3) × (4.0 × 102) involves only a single floating-point multiplication.
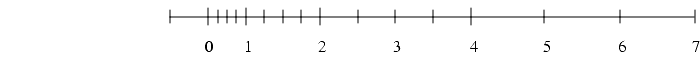
FIGURE D-1 Normalized numbers when
Relative Error and Ulps
Since rounding error is inherent in floating-point computation, it is important to have a way to measure this error. Consider the floating-point format with
d.d...d - (z/
.0005.
To compute the relative error that corresponds to .5 ulp, observe that when a real number is approximated by the closest possible floating-point number d.dd...dd ×
(2)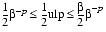
In particular, the relative error corresponding to .5 ulp can vary by a factor of
= (
In the example above, the relative error was .00159/3.14159
To illustrate the difference between ulps and relative error, consider the real number x = 12.35. It is approximated by
= 1.24 × 101. The error is 0.5 ulps, the relative error is 0.8
. The exact value is 8x = 98.8, while the computed value is 8
= 9.92 × 101. The error is now 4.0 ulps, but the relative error is still 0.8
The most natural way to measure rounding error is in ulps. For example rounding to the nearest floating-point number corresponds to an error of less than or equal to .5 ulp. However, when analyzing the rounding error caused by various formulas, relative error is a better measure. A good illustration of this is the analysis in the section Theorem 9. Since
When only the order of magnitude of rounding error is of interest, ulps and
(3) contaminated digits
Guard Digits
One method of computing the difference between two floating-point numbers is to compute the difference exactly and then round it to the nearest floating-point number. This is very expensive if the operands differ greatly in size. Assuming p = 3, 2.15 × 1012 - 1.25 × 10-5 would be calculated as
- x = 2.15 × 1012
y = .0000000000000000125 × 1012
x - y = 2.1499999999999999875 × 1012which rounds to 2.15 × 1012. Rather than using all these digits, floating-point hardware normally operates on a fixed number of digits. Suppose that the number of digits kept is p, and that when the smaller operand is shifted right, digits are simply discarded (as opposed to rounding). Then 2.15 × 1012 - 1.25 × 10-5 becomes
- x = 2.15 × 1012
y = 0.00 × 1012
x - y = 2.15 × 1012The answer is exactly the same as if the difference had been computed exactly and then rounded. Take another example: 10.1 - 9.93. This becomes
- x = 1.01 × 101
y = 0.99 × 101
x - y = .02 × 101The correct answer is .17, so the computed difference is off by 30 ulps and is wrong in every digit! How bad can the error be?
Theorem 1
- Using a floating-point format with parameters
Proof
- A relative error of
...
When
- x = 1.010 × 101
y = 0.993 × 101
x - y = .017 × 101and the answer is exact. With a single guard digit, the relative error of the result may be greater than
- x = 1.10 × 102
y = .085 × 102
x - y = 1.015 × 102This rounds to 102, compared with the correct answer of 101.41, for a relative error of .006, which is greater than
Theorem 2
- If x and y are floating-point numbers in a format with parameters
This theorem will be proven in Rounding Error. Addition is included in the above theorem since x and y can be positive or negative.
Cancellation
The last section can be summarized by saying that without a guard digit, the relative error committed when subtracting two nearby quantities can be very large. In other words, the evaluation of any expression containing a subtraction (or an addition of quantities with opposite signs) could result in a relative error so large that all the digits are meaningless (Theorem 1). When subtracting nearby quantities, the most significant digits in the operands match and cancel each other. There are two kinds of cancellation: catastrophic and benign.
Catastrophic cancellation occurs when the operands are subject to rounding errors. For example in the quadratic formula, the expression b2 - 4ac occurs. The quantities b2 and 4ac are subject to rounding errors since they are the results of floating-point multiplications. Suppose that they are rounded to the nearest floating-point number, and so are accurate to within .5 ulp. When they are subtracted, cancellation can cause many of the accurate digits to disappear, leaving behind mainly digits contaminated by rounding error. Hence the difference might have an error of many ulps. For example, consider b = 3.34, a = 1.22, and c = 2.28. The exact value of b2 - 4ac is .0292. But b2 rounds to 11.2 and 4ac rounds to 11.1, hence the final answer is .1 which is an error by 70 ulps, even though 11.2 - 11.1 is exactly equal to .16. The subtraction did not introduce any error, but rather exposed the error introduced in the earlier multiplications.
Benign cancellation occurs when subtracting exactly known quantities. If x and y have no rounding error, then by Theorem 2 if the subtraction is done with a guard digit, the difference x-y has a very small relative error (less than 2
A formula that exhibits catastrophic cancellation can sometimes be rearranged to eliminate the problem. Again consider the quadratic formula
(4)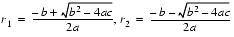
When
, then
does not involve a cancellation and
.
But the other addition (subtraction) in one of the formulas will have a catastrophic cancellation. To avoid this, multiply the numerator and denominator of r1 by
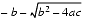
(and similarly for r2) to obtain
(5)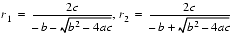
If
and
, then computing r1 using formula (4) will involve a cancellation. Therefore, use formula (5) for computing r1 and (4) for r2. On the other hand, if b < 0, use (4) for computing r1 and (5) for r2.
The expression x2 - y2 is another formula that exhibits catastrophic cancellation. It is more accurate to evaluate it as (x - y)(x + y).7 Unlike the quadratic formula, this improved form still has a subtraction, but it is a benign cancellation of quantities without rounding error, not a catastrophic one. By Theorem 2, the relative error in x - y is at most 2
In order to avoid confusion between exact and computed values, the following notation is used. Whereas x - y denotes the exact difference of x and y, x
y denotes the computed difference (i.e., with rounding error). Similarly
,
, and
denote computed addition, multiplication, and division, respectively. All caps indicate the computed value of a function, as in
LN(x)orSQRT(x). Lowercase functions and traditional mathematical notation denote their exact values as in ln(x) and.
Although (x
y)
and
. For example,
and
might be exactly known decimal numbers that cannot be expressed exactly in binary. In this case, even though x
y is a good approximation to x - y, it can have a huge relative error compared to the true expression
, and so the advantage of (x + y)(x - y) over x2 - y2 is not as dramatic. Since computing (x + y)(x - y) is about the same amount of work as computing x2 - y2, it is clearly the preferred form in this case. In general, however, replacing a catastrophic cancellation by a benign one is not worthwhile if the expense is large, because the input is often (but not always) an approximation. But eliminating a cancellation entirely (as in the quadratic formula) is worthwhile even if the data are not exact. Throughout this paper, it will be assumed that the floating-point inputs to an algorithm are exact and that the results are computed as accurately as possible.
The expression x2 - y2 is more accurate when rewritten as (x - y)(x + y) because a catastrophic cancellation is replaced with a benign one. We next present more interesting examples of formulas exhibiting catastrophic cancellation that can be rewritten to exhibit only benign cancellation.
The area of a triangle can be expressed directly in terms of the lengths of its sides a, b, and c as
(6)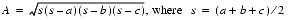
(Suppose the triangle is very flat; that is, a
There is a way to rewrite formula (6) so that it will return accurate results even for flat triangles [Kahan 1986]. It is
(7)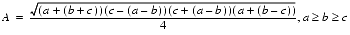
If a, b, and c do not satisfy a
b
Although formula (7) is much more accurate than (6) for this example, it would be nice to know how well (7) performs in general.
Theorem 3
- The rounding error incurred when using (7) to compute the area of a triangle is at most 11
.005, and that square roots are computed to within 1/2 ulp.
The condition that e < .005 is met in virtually every actual floating-point system. For example when
In statements like Theorem 3 that discuss the relative error of an expression, it is understood that the expression is computed using floating-point arithmetic. In particular, the relative error is actually of the expression
(8)SQRT((a(a
b))
b))
c)))
4
Because of the cumbersome nature of (8), in the statement of theorems we will usually say the computed value of E rather than writing out E with circle notation.
Error bounds are usually too pessimistic. In the numerical example given above, the computed value of (7) is 2.35, compared with a true value of 2.34216 for a relative error of 0.7
A final example of an expression that can be rewritten to use benign cancellation is (1 + x)n, where
100. This expression arises in financial calculations. Consider depositing $100 every day into a bank account that earns an annual interest rate of 6%, compounded daily. If n = 365 and i = .06, the amount of money accumulated at the end of one year is
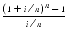
dollars. If this is computed using
The troublesome expression (1 + i/n)n can be rewritten as enln(1 + i/n), where now the problem is to compute ln(1 + x) for small x. One approach is to use the approximation ln(1 + x)
Theorem 4 assumes that
LN(x)approximates ln(x) to within 1/2 ulp. The problem it solves is that when x is small,LN(1.
Theorem 4
- If ln(1 + x) is computed using the formula
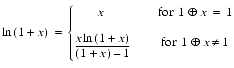
- the relative error is at most 5
This formula will work for any value of x but is only interesting for
, which is where catastrophic cancellation occurs in the naive formula ln(1 + x). Although the formula may seem mysterious, there is a simple explanation for why it works. Write ln(1 + x) as
.
The left hand factor can be computed exactly, but the right hand factor µ(x) = ln(1 + x)/x will suffer a large rounding error when adding 1 to x. However, µ is almost constant, since ln(1 + x)
, computing
will be a good approximation to xµ(x) = ln(1 + x). Is there a value for
for which
and
can be computed accurately? There is; namely
= (1
1, because then 1 +
is exactly equal to 1
The results of this section can be summarized by saying that a guard digit guarantees accuracy when nearby precisely known quantities are subtracted (benign cancellation). Sometimes a formula that gives inaccurate results can be rewritten to have much higher numerical accuracy by using benign cancellation; however, the procedure only works if subtraction is performed using a guard digit. The price of a guard digit is not high, because it merely requires making the adder one bit wider. For a 54 bit double precision adder, the additional cost is less than 2%. For this price, you gain the ability to run many algorithms such as formula (6) for computing the area of a triangle and the expression ln(1 + x). Although most modern computers have a guard digit, there are a few (such as Cray systems) that do not.
Exactly Rounded Operations
When floating-point operations are done with a guard digit, they are not as accurate as if they were computed exactly then rounded to the nearest floating-point number. Operations performed in this manner will be called exactly rounded.8 The example immediately preceding Theorem 2 shows that a single guard digit will not always give exactly rounded results. The previous section gave several examples of algorithms that require a guard digit in order to work properly. This section gives examples of algorithms that require exact rounding.
So far, the definition of rounding has not been given. Rounding is straightforward, with the exception of how to round halfway cases; for example, should 12.5 round to 12 or 13? One school of thought divides the 10 digits in half, letting {0, 1, 2, 3, 4} round down, and {5, 6, 7, 8, 9} round up; thus 12.5 would round to 13. This is how rounding works on Digital Equipment Corporation's VAX computers. Another school of thought says that since numbers ending in 5 are halfway between two possible roundings, they should round down half the time and round up the other half. One way of obtaining this 50% behavior to require that the rounded result have its least significant digit be even. Thus 12.5 rounds to 12 rather than 13 because 2 is even. Which of these methods is best, round up or round to even? Reiser and Knuth [1975] offer the following reason for preferring round to even.
Theorem 5
- Let x and y be floating-point numbers, and define x0 = x, x1 = (x0
y)
y)
are exactly rounded using round to even, then either xn = x for all n or xn = x1 for all n
To clarify this result, consider
x0y = 1.56, x1 = 1.56
.555 = 1.01, x1
y = 1.01
and each successive value of xn increases by .01, until xn = 9.45 (n
One application of exact rounding occurs in multiple precision arithmetic. There are two basic approaches to higher precision. One approach represents floating-point numbers using a very large significand, which is stored in an array of words, and codes the routines for manipulating these numbers in assembly language. The second approach represents higher precision floating-point numbers as an array of ordinary floating-point numbers, where adding the elements of the array in infinite precision recovers the high precision floating-point number. It is this second approach that will be discussed here. The advantage of using an array of floating-point numbers is that it can be coded portably in a high level language, but it requires exactly rounded arithmetic.
The key to multiplication in this system is representing a product xy as a sum, where each summand has the same precision as x and y. This can be done by splitting x and y. Writing x = xh + xl and y = yh + yl, the exact product is
xy = xh yh + xh yl + xl yh + xl yl.
If x and y have p bit significands, the summands will also have p bit significands provided that xl, xh, yh, yl can be represented using [p/2] bits. When p is even, it is easy to find a splitting. The number x0.x1 ... xp - 1 can be written as the sum of x0.x1 ... xp/2 - 1 and 0.0 ... 0xp/2 ... xp - 1. When p is odd, this simple splitting method will not work. An extra bit can, however, be gained by using negative numbers. For example, if
Theorem 6
xh = (m
- Let p be the floating-point precision, with the restriction that p is even when
(m
x), xl = x
xh,
and each xi is representable using [p/2] bits of precision.
To see how this theorem works in an example, let
.000201 = .03480, which is identical to the exactly rounded result. To show that Theorem 6 really requires exact rounding, consider p = 3,
x = 28. Therefore, xh = 4 and xl = 3, hence xl is not representable with [p/2] = 1 bit.
As a final example of exact rounding, consider dividing m by 10. The result is a floating-point number that will in general not be equal to m/10. When
Theorem 7
- When
n)
Proof
(9)
- Scaling by a power of two is harmless, since it changes only the exponent, not the significand. If q = m/n, then scale n so that 2p - 1
- If
= m
n, to prove the theorem requires showing that
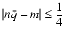
|
- That is because m has at most 1 bit right of the binary point, so n
will round to m. To deal with the halfway case when |n
- m| = 1/4, note that since the initial unscaled m had |m| < 2p - 1, its low-order bit was 0, so the low-order bit of the scaled m is also 0. Thus, halfway cases will round to m.
- Suppose that q = .q1q2 ..., and let
= .q1q2 ... qp1. To estimate |n
- m|, first compute
- q| = |N/2p + 1 - m/n|,
- where N is an odd integer. Since n = 2i + 2j and 2p - 1
.
|
- The numerator is an integer, and since N is odd, it is in fact an odd integer. Thus,
- q|
|m-n
- Assume q <
(the case q >
is similar).10 Then n
< m, and
|= m-n
= n(q-
) = n(q-(
-2-p-1))
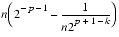
=(2p-1+2k)2-p-1-2-p-1+k =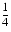
- This establishes (9) and proves the theorem.11 z
The theorem holds true for any base
We are now in a position to answer the question, Does it matter if the basic arithmetic operations introduce a little more rounding error than necessary? The answer is that it does matter, because accurate basic operations enable us to prove that formulas are "correct" in the sense they have a small relative error. The section Cancellation discussed several algorithms that require guard digits to produce correct results in this sense. If the input to those formulas are numbers representing imprecise measurements, however, the bounds of Theorems 3 and 4 become less interesting. The reason is that the benign cancellation x - y can become catastrophic if x and y are only approximations to some measured quantity. But accurate operations are useful even in the face of inexact data, because they enable us to establish exact relationships like those discussed in Theorems 6 and 7. These are useful even if every floating-point variable is only an approximation to some actual value.
The IEEE Standard
There are two different IEEE standards for floating-point computation. IEEE 754 is a binary standard that requires
This section provides a tour of the IEEE standard. Each subsection discusses one aspect of the standard and why it was included. It is not the purpose of this paper to argue that the IEEE standard is the best possible floating-point standard but rather to accept the standard as given and provide an introduction to its use. For full details consult the standards themselves [IEEE 1987; Cody et al. 1984].
Formats and Operations
Base
It is clear why IEEE 854 allows
There are several reasons why IEEE 854 requires that if the base is not 10, it must be 2. The section Relative Error and Ulps mentioned one reason: the results of error analyses are much tighter when
to about
=
. To get a similar exponent range when
Another possible explanation for choosing
) = 105 possible pairs of distinct numbers from this set. However, in the
In most modern hardware, the performance gained by avoiding a shift for a subset of operands is negligible, and so the small wobble of
, but rather 0.
IEEE 754 single precision is encoded in 32 bits using 1 bit for the sign, 8 bits for the exponent, and 23 bits for the significand. However, it uses a hidden bit, so the significand is 24 bits (p = 24), even though it is encoded using only 23 bits.
Precision
The IEEE standard defines four different precisions: single, double, single-extended, and double-extended. In IEEE 754, single and double precision correspond roughly to what most floating-point hardware provides. Single precision occupies a single 32 bit word, double precision two consecutive 32 bit words. Extended precision is a format that offers at least a little extra precision and exponent range (TABLE D-1).
TABLE D-1 IEEE 754 Format Parameters p 24 53 emax +127 +1023 > 16383 emin -126 -1022 Exponent width in bits 8 11 Format width in bits 32 64
The IEEE standard only specifies a lower bound on how many extra bits extended precision provides. The minimum allowable double-extended format is sometimes referred to as 80-bit format, even though the table shows it using 79 bits. The reason is that hardware implementations of extended precision normally do not use a hidden bit, and so would use 80 rather than 79 bits.13
The standard puts the most emphasis on extended precision, making no recommendation concerning double precision, but strongly recommending that Implementations should support the extended format corresponding to the widest basic format supported, ...
One motivation for extended precision comes from calculators, which will often display 10 digits, but use 13 digits internally. By displaying only 10 of the 13 digits, the calculator appears to the user as a "black box" that computes exponentials, cosines, etc. to 10 digits of accuracy. For the calculator to compute functions like exp, log and cos to within 10 digits with reasonable efficiency, it needs a few extra digits to work with. It is not hard to find a simple rational expression that approximates log with an error of 500 units in the last place. Thus computing with 13 digits gives an answer correct to 10 digits. By keeping these extra 3 digits hidden, the calculator presents a simple model to the operator.
Extended precision in the IEEE standard serves a similar function. It enables libraries to efficiently compute quantities to within about .5 ulp in single (or double) precision, giving the user of those libraries a simple model, namely that each primitive operation, be it a simple multiply or an invocation of log, returns a value accurate to within about .5 ulp. However, when using extended precision, it is important to make sure that its use is transparent to the user. For example, on a calculator, if the internal representation of a displayed value is not rounded to the same precision as the display, then the result of further operations will depend on the hidden digits and appear unpredictable to the user.
To illustrate extended precision further, consider the problem of converting between IEEE 754 single precision and decimal. Ideally, single precision numbers will be printed with enough digits so that when the decimal number is read back in, the single precision number can be recovered. It turns out that 9 decimal digits are enough to recover a single precision binary number (see the section Binary to Decimal Conversion). When converting a decimal number back to its unique binary representation, a rounding error as small as 1 ulp is fatal, because it will give the wrong answer. Here is a situation where extended precision is vital for an efficient algorithm. When single-extended is available, a very straightforward method exists for converting a decimal number to a single precision binary one. First read in the 9 decimal digits as an integer N, ignoring the decimal point. From TABLE D-1, p
If double precision is supported, then the algorithm above would be run in double precision rather than single-extended, but to convert double precision to a 17-digit decimal number and back would require the double-extended format.
Exponent
Since the exponent can be positive or negative, some method must be chosen to represent its sign. Two common methods of representing signed numbers are sign/magnitude and two's complement. Sign/magnitude is the system used for the sign of the significand in the IEEE formats: one bit is used to hold the sign, the rest of the bits represent the magnitude of the number. The two's complement representation is often used in integer arithmetic. In this scheme, a number in the range [-2p-1, 2p-1 - 1] is represented by the smallest nonnegative number that is congruent to it modulo 2p.
The IEEE binary standard does not use either of these methods to represent the exponent, but instead uses a biased representation. In the case of single precision, where the exponent is stored in 8 bits, the bias is 127 (for double precision it is 1023). What this means is that if
is the value of the exponent bits interpreted as an unsigned integer, then the exponent of the floating-point number is
- 127. This is often called the unbiased exponent to distinguish from the biased exponent
.
Referring to TABLE D-1, single precision has emax = 127 and emin = -126. The reason for having |emin| < emax is so that the reciprocal of the smallest number
will not overflow. Although it is true that the reciprocal of the largest number will underflow, underflow is usually less serious than overflow. The section Base explained that emin - 1 is used for representing 0, and Special Quantities will introduce a use for emax + 1. In IEEE single precision, this means that the biased exponents range between emin - 1 = -127 and emax + 1 = 128, whereas the unbiased exponents range between 0 and 255, which are exactly the nonnegative numbers that can be represented using 8 bits.
Operations
The IEEE standard requires that the result of addition, subtraction, multiplication and division be exactly rounded. That is, the result must be computed exactly and then rounded to the nearest floating-point number (using round to even). The section Guard Digits pointed out that computing the exact difference or sum of two floating-point numbers can be very expensive when their exponents are substantially different. That section introduced guard digits, which provide a practical way of computing differences while guaranteeing that the relative error is small. However, computing with a single guard digit will not always give the same answer as computing the exact result and then rounding. By introducing a second guard digit and a third sticky bit, differences can be computed at only a little more cost than with a single guard digit, but the result is the same as if the difference were computed exactly and then rounded [Goldberg 1990]. Thus the standard can be implemented efficiently.
One reason for completely specifying the results of arithmetic operations is to improve the portability of software. When a program is moved between two machines and both support IEEE arithmetic, then if any intermediate result differs, it must be because of software bugs, not from differences in arithmetic. Another advantage of precise specification is that it makes it easier to reason about floating-point. Proofs about floating-point are hard enough, without having to deal with multiple cases arising from multiple kinds of arithmetic. Just as integer programs can be proven to be correct, so can floating-point programs, although what is proven in that case is that the rounding error of the result satisfies certain bounds. Theorem 4 is an example of such a proof. These proofs are made much easier when the operations being reasoned about are precisely specified. Once an algorithm is proven to be correct for IEEE arithmetic, it will work correctly on any machine supporting the IEEE standard.
Brown [1981] has proposed axioms for floating-point that include most of the existing floating-point hardware. However, proofs in this system cannot verify the algorithms of sections Cancellation and Exactly Rounded Operations, which require features not present on all hardware. Furthermore, Brown's axioms are more complex than simply defining operations to be performed exactly and then rounded. Thus proving theorems from Brown's axioms is usually more difficult than proving them assuming operations are exactly rounded.
There is not complete agreement on what operations a floating-point standard should cover. In addition to the basic operations +, -, × and /, the IEEE standard also specifies that square root, remainder, and conversion between integer and floating-point be correctly rounded. It also requires that conversion between internal formats and decimal be correctly rounded (except for very large numbers). Kulisch and Miranker [1986] have proposed adding inner product to the list of operations that are precisely specified. They note that when inner products are computed in IEEE arithmetic, the final answer can be quite wrong. For example sums are a special case of inner products, and the sum ((2 × 10-30 + 1030) - 1030) - 10-30 is exactly equal to 10-30, but on a machine with IEEE arithmetic the computed result will be -10-30. It is possible to compute inner products to within 1 ulp with less hardware than it takes to implement a fast multiplier [Kirchner and Kulish 1987].14 15
All the operations mentioned in the standard are required to be exactly rounded except conversion between decimal and binary. The reason is that efficient algorithms for exactly rounding all the operations are known, except conversion. For conversion, the best known efficient algorithms produce results that are slightly worse than exactly rounded ones [Coonen 1984].
The IEEE standard does not require transcendental functions to be exactly rounded because of the table maker's dilemma. To illustrate, suppose you are making a table of the exponential function to 4 places. Then exp(1.626) = 5.0835. Should this be rounded to 5.083 or 5.084? If exp(1.626) is computed more carefully, it becomes 5.08350. And then 5.083500. And then 5.0835000. Since exp is transcendental, this could go on arbitrarily long before distinguishing whether exp(1.626) is 5.083500...0ddd or 5.0834999...9ddd. Thus it is not practical to specify that the precision of transcendental functions be the same as if they were computed to infinite precision and then rounded. Another approach would be to specify transcendental functions algorithmically. But there does not appear to be a single algorithm that works well across all hardware architectures. Rational approximation, CORDIC,16 and large tables are three different techniques that are used for computing transcendentals on contemporary machines. Each is appropriate for a different class of hardware, and at present no single algorithm works acceptably over the wide range of current hardware.
Special Quantities
On some floating-point hardware every bit pattern represents a valid floating-point number. The IBM System/370 is an example of this. On the other hand, the VAXTM reserves some bit patterns to represent special numbers called reserved operands. This idea goes back to the CDC 6600, which had bit patterns for the special quantities
INDEFINITEandINFINITY.The IEEE standard continues in this tradition and has NaNs (Not a Number) and infinities. Without any special quantities, there is no good way to handle exceptional situations like taking the square root of a negative number, other than aborting computation. Under IBM System/370 FORTRAN, the default action in response to computing the square root of a negative number like -4 results in the printing of an error message. Since every bit pattern represents a valid number, the return value of square root must be some floating-point number. In the case of System/370 FORTRAN,
is returned. In IEEE arithmetic, a NaN is returned in this situation.
The IEEE standard specifies the following special values (see TABLE D-2): ± 0, denormalized numbers, ±
and NaNs (there is more than one NaN, as explained in the next section). These special values are all encoded with exponents of either emax + 1 or emin - 1 (it was already pointed out that 0 has an exponent of emin - 1).
TABLE D-2 IEEE 754 Special Values e = emin - 1 f = 0 ±0 e = emin - 1 f 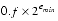
emin -- 1.f × 2e e = emax + 1 f = 0 ± e = emax + 1 f NaN
NaNs
Traditionally, the computation of 0/0 or
has been treated as an unrecoverable error which causes a computation to halt. However, there are examples where it makes sense for a computation to continue in such a situation. Consider a subroutine that finds the zeros of a function f, say
zero(f). Traditionally, zero finders require the user to input an interval [a, b] on which the function is defined and over which the zero finder will search. That is, the subroutine is called aszero(f,a,b). A more useful zero finder would not require the user to input this extra information. This more general zero finder is especially appropriate for calculators, where it is natural to simply key in a function, and awkward to then have to specify the domain. However, it is easy to see why most zero finders require a domain. The zero finder does its work by probing the functionfat various values. If it probed for a value outside the domain off, the code forfmight well compute 0/0 or, and the computation would halt, unnecessarily aborting the zero finding process.
This problem can be avoided by introducing a special value called NaN, and specifying that the computation of expressions like 0/0 and
produce NaN, rather than halting. A list of some of the situations that can cause a NaN are given in TABLE D-3. Then when
zero(f)probes outside the domain off, the code forfwill return NaN, and the zero finder can continue. That is,zero(f)is not "punished" for making an incorrect guess. With this example in mind, it is easy to see what the result of combining a NaN with an ordinary floating-point number should be. Suppose that the final statement offisreturn(-b +sqrt(d))/(2*a). If d < 0, thenfshould return a NaN. Since d < 0,sqrt(d)is a NaN, and-b + sqrt(d)will be a NaN, if the sum of a NaN and any other number is a NaN. Similarly if one operand of a division operation is a NaN, the quotient should be a NaN. In general, whenever a NaN participates in a floating-point operation, the result is another NaN.
TABLE D-3 Operations That Produce a NaN + × 0 × / 0/0, REMx REM0,REMy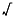
(when x < 0)
Another approach to writing a zero solver that doesn't require the user to input a domain is to use signals. The zero-finder could install a signal handler for floating-point exceptions. Then if
fwas evaluated outside its domain and raised an exception, control would be returned to the zero solver. The problem with this approach is that every language has a different method of handling signals (if it has a method at all), and so it has no hope of portability.In IEEE 754, NaNs are often represented as floating-point numbers with the exponent emax + 1 and nonzero significands. Implementations are free to put system-dependent information into the significand. Thus there is not a unique NaN, but rather a whole family of NaNs. When a NaN and an ordinary floating-point number are combined, the result should be the same as the NaN operand. Thus if the result of a long computation is a NaN, the system-dependent information in the significand will be the information that was generated when the first NaN in the computation was generated. Actually, there is a caveat to the last statement. If both operands are NaNs, then the result will be one of those NaNs, but it might not be the NaN that was generated first.
Infinity
Just as NaNs provide a way to continue a computation when expressions like 0/0 or
are encountered, infinities provide a way to continue when an overflow occurs. This is much safer than simply returning the largest representable number. As an example, consider computing
, when
, which is drastically wrong: the correct answer is 5 × 1070. In IEEE arithmetic, the result of x2 is
. So the final result is
The division of 0 by 0 results in a NaN. A nonzero number divided by 0, however, returns infinity: 1/0 =
0 and g(x)
The rule for determining the result of an operation that has infinity as an operand is simple: replace infinity with a finite number x and take the limit as x
.
Similarly, 4 -
=
When a subexpression evaluates to a NaN, the value of the entire expression is also a NaN. In the case of ±
, but infinity arithmetic will give the wrong answer because it will yield 0, rather than a number near 1/x. However, x/(x2 + 1) can be rewritten as 1/(x + x-1). This improved expression will not overflow prematurely and because of infinity arithmetic will have the correct value when x = 0: 1/(0 + 0-1) = 1/(0 +
Signed Zero
Zero is represented by the exponent emin - 1 and a zero significand. Since the sign bit can take on two different values, there are two zeros, +0 and -0. If a distinction were made when comparing +0 and -0, simple tests like
if(x=0)would have very unpredictable behavior, depending on the sign ofx. Thus the IEEE standard defines comparison so that +0 = -0, rather than -0 < +0. Although it would be possible always to ignore the sign of zero, the IEEE standard does not do so. When a multiplication or division involves a signed zero, the usual sign rules apply in computing the sign of the answer. Thus 3·(+0) = +0, and +0/-3 = -0. If zero did not have a sign, then the relation 1/(1/x) = x would fail to hold when x = ±Another example of the use of signed zero concerns underflow and functions that have a discontinuity at 0, such as log. In IEEE arithmetic, it is natural to define log 0 = -
Probably the most interesting use of signed zero occurs in complex arithmetic. To take a simple example, consider the equation
. This is certainly true when z
and
. Thus,
! The problem can be traced to the fact that square root is multi-valued, and there is no way to select the values so that it is continuous in the entire complex plane. However, square root is continuous if a branch cut consisting of all negative real numbers is excluded from consideration. This leaves the problem of what to do for the negative real numbers, which are of the form -x + i0, where x > 0. Signed zero provides a perfect way to resolve this problem. Numbers of the form x + i(+0) have one sign
and numbers of the form x + i(-0) on the other side of the branch cut have the other sign
. In fact, the natural formulas for computing
will give these results.
Back to
1/z = 1/(-1 + i0) = [(-1- i0)]/[(-1 + i0)(-1 - i0)] = (-1 -- i0)/((-1)2 - 02) = -1 + i(-0),. If z =1 = -1 + i0, then
and so
, while
. Thus IEEE arithmetic preserves this identity for all z. Some more sophisticated examples are given by Kahan [1987]. Although distinguishing between +0 and -0 has advantages, it can occasionally be confusing. For example, signed zero destroys the relation x = y
1/x = 1/y, which is false when x = +0 and y = -0. However, the IEEE committee decided that the advantages of utilizing the sign of zero outweighed the disadvantages.
Denormalized Numbers
Consider normalized floating-point numbers with
(10) x = yy = 0 even though x
It's very easy to imagine writing the code fragment,
if(xy)thenz=1/(x-y), and much later having a program fail due to a spurious division by zero. Tracking down bugs like this is frustrating and time consuming. On a more philosophical level, computer science textbooks often point out that even though it is currently impractical to prove large programs correct, designing programs with the idea of proving them often results in better code. For example, introducing invariants is quite useful, even if they aren't going to be used as part of a proof. Floating-point code is just like any other code: it helps to have provable facts on which to depend. For example, when analyzing formula (6), it was very helpful to know that x/2 < y < 2xx
y = x - y. Similarly, knowing that (10) is true makes writing reliable floating-point code easier. If it is only true for most numbers, it cannot be used to prove anything.
The IEEE standard uses denormalized18 numbers, which guarantee (10), as well as other useful relations. They are the most controversial part of the standard and probably accounted for the long delay in getting 754 approved. Most high performance hardware that claims to be IEEE compatible does not support denormalized numbers directly, but rather traps when consuming or producing denormals, and leaves it to software to simulate the IEEE standard.19 The idea behind denormalized numbers goes back to Goldberg [1967] and is very simple. When the exponent is emin, the significand does not have to be normalized, so that when
There is a small snag when
Recall the example of
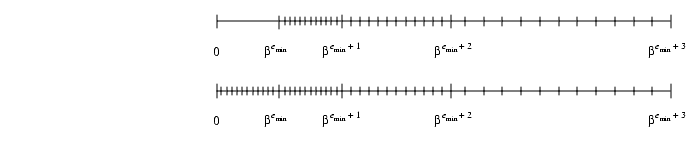
FIGURE D-2 Flush To Zero Compared With Gradual Underflow
FIGURE D-2 illustrates denormalized numbers. The top number line in the figure shows normalized floating-point numbers. Notice the gap between 0 and the smallest normalized number
. If the result of a floating-point calculation falls into this gulf, it is flushed to zero. The bottom number line shows what happens when denormals are added to the set of floating-point numbers. The "gulf" is filled in, and when the result of a calculation is less than
, it is represented by the nearest denormal. When denormalized numbers are added to the number line, the spacing between adjacent floating-point numbers varies in a regular way: adjacent spacings are either the same length or differ by a factor of
spacing abruptly changes fromto
, which is a factor of
, rather than the orderly change by a factor of
Without gradual underflow, the simple expression x - y can have a very large relative error for normalized inputs, as was seen above for x = 6.87 × 10-97 and y = 6.81 × 10-97. Large relative errors can happen even without cancellation, as the following example shows [Demmel 1984]. Consider dividing two complex numbers, a + ib and c + id. The obvious formula
· i
suffers from the problem that if either component of the denominator c + id is larger than
, the formula will overflow, even though the final result may be well within range. A better method of computing the quotients is to use Smith's formula:
(11)
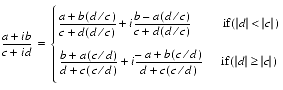
Applying Smith's formula to (2 · 10-98 + i10-98)/(4 · 10-98 + i(2 · 10-98)) gives the correct answer of 0.5 with gradual underflow. It yields 0.4 with flush to zero, an error of 100 ulps. It is typical for denormalized numbers to guarantee error bounds for arguments all the way down to 1.0 x
.
Exceptions, Flags and Trap Handlers
When an exceptional condition like division by zero or overflow occurs in IEEE arithmetic, the default is to deliver a result and continue. Typical of the default results are NaN for 0/0 and
, and
Sometimes continuing execution in the face of exception conditions is not appropriate. The section Infinity gave the example of x/(x2 + 1). When x >
, the denominator is infinite, resulting in a final answer of 0, which is totally wrong. Although for this formula the problem can be solved by rewriting it as 1/(x + x-1), rewriting may not always solve the problem. The IEEE standard strongly recommends that implementations allow trap handlers to be installed. Then when an exception occurs, the trap handler is called instead of setting the flag. The value returned by the trap handler will be used as the result of the operation. It is the responsibility of the trap handler to either clear or set the status flag; otherwise, the value of the flag is allowed to be undefined.
The IEEE standard divides exceptions into 5 classes: overflow, underflow, division by zero, invalid operation and inexact. There is a separate status flag for each class of exception. The meaning of the first three exceptions is self-evident. Invalid operation covers the situations listed in TABLE D-3, and any comparison that involves a NaN. The default result of an operation that causes an invalid exception is to return a NaN, but the converse is not true. When one of the operands to an operation is a NaN, the result is a NaN but no invalid exception is raised unless the operation also satisfies one of the conditions in TABLE D-3.20
TABLE D-4 Exceptions in IEEE 754* overflow ± round(x2- )
underflow 0, or denormal
round(x2 divide by zero ± operands invalid NaN operands inexact round(x) round(x)
*x is the exact result of the operation,
.
The inexact exception is raised when the result of a floating-point operation is not exact. In the
There is an implementation issue connected with the fact that the inexact exception is raised so often. If floating-point hardware does not have flags of its own, but instead interrupts the operating system to signal a floating-point exception, the cost of inexact exceptions could be prohibitive. This cost can be avoided by having the status flags maintained by software. The first time an exception is raised, set the software flag for the appropriate class, and tell the floating-point hardware to mask off that class of exceptions. Then all further exceptions will run without interrupting the operating system. When a user resets that status flag, the hardware mask is re-enabled.
Trap Handlers
One obvious use for trap handlers is for backward compatibility. Old codes that expect to be aborted when exceptions occur can install a trap handler that aborts the process. This is especially useful for codes with a loop like
doSuntil(x>=100). Since comparing a NaN to a number with <,xever becomes a NaN.There is a more interesting use for trap handlers that comes up when computing products such as
that could potentially overflow. One solution is to use logarithms, and compute exp
instead. The problem with this approach is that it is less accurate, and that it costs more than the simple expression
, even if there is no overflow. There is another solution using trap handlers called over/underflow counting that avoids both of these problems [Sterbenz 1974].
The idea is as follows. There is a global counter initialized to zero. Whenever the partial product
overflows for some k, the trap handler increments the counter by one and returns the overflowed quantity with the exponent wrapped around. In IEEE 754 single precision, emax = 127, so if pk = 1.45 × 2130, it will overflow and cause the trap handler to be called, which will wrap the exponent back into range, changing pk to 1.45 × 2-62 (see below). Similarly, if pk underflows, the counter would be decremented, and negative exponent would get wrapped around into a positive one. When all the multiplications are done, if the counter is zero then the final product is pn. If the counter is positive, the product overflowed, if the counter is negative, it underflowed. If none of the partial products are out of range, the trap handler is never called and the computation incurs no extra cost. Even if there are over/underflows, the calculation is more accurate than if it had been computed with logarithms, because each pk was computed from pk - 1 using a full precision multiply. Barnett [1987] discusses a formula where the full accuracy of over/underflow counting turned up an error in earlier tables of that formula.
IEEE 754 specifies that when an overflow or underflow trap handler is called, it is passed the wrapped-around result as an argument. The definition of wrapped-around for overflow is that the result is computed as if to infinite precision, then divided by 2
Rounding Modes
In the IEEE standard, rounding occurs whenever an operation has a result that is not exact, since (with the exception of binary decimal conversion) each operation is computed exactly and then rounded. By default, rounding means round toward nearest. The standard requires that three other rounding modes be provided, namely round toward 0, round toward +
One application of rounding modes occurs in interval arithmetic (another is mentioned in Binary to Decimal Conversion). When using interval arithmetic, the sum of two numbers x and y is an interval
, where
is x
is x
. Without rounding modes, interval arithmetic is usually implemented by computing
and
, where
is machine epsilon.21 This results in overestimates for the size of the intervals. Since the result of an operation in interval arithmetic is an interval, in general the input to an operation will also be an interval. If two intervals
, and
, are added, the result is
, where
is
with the rounding mode set to round toward -
is
with the rounding mode set to round toward +
When a floating-point calculation is performed using interval arithmetic, the final answer is an interval that contains the exact result of the calculation. This is not very helpful if the interval turns out to be large (as it often does), since the correct answer could be anywhere in that interval. Interval arithmetic makes more sense when used in conjunction with a multiple precision floating-point package. The calculation is first performed with some precision p. If interval arithmetic suggests that the final answer may be inaccurate, the computation is redone with higher and higher precisions until the final interval is a reasonable size.
Flags
The IEEE standard has a number of flags and modes. As discussed above, there is one status flag for each of the five exceptions: underflow, overflow, division by zero, invalid operation and inexact. There are four rounding modes: round toward nearest, round toward +
Consider writing a subroutine to compute xn, where n is an integer. When n > 0, a simple routine like
PositivePower(x,n) {while (n is even) {x = x*xn = n/2}u = xwhile (true) {n = n/2if (n==0) return ux = x*xif (n is odd) u = u*x}
If n < 0, then a more accurate way to compute xn is not to call
PositivePower(1/x,-n)but rather1/PositivePower(x,-n), because the first expression multiplies n quantities each of which have a rounding error from the division (i.e., 1/x). In the second expression these are exact (i.e., x), and the final division commits just one additional rounding error. Unfortunately, these is a slight snag in this strategy. IfPositivePower(x,-n)underflows, then either the underflow trap handler will be called, or else the underflow status flag will be set. This is incorrect, because if x-n underflows, then xn will either overflow or be in range.22 But since the IEEE standard gives the user access to all the flags, the subroutine can easily correct for this. It simply turns off the overflow and underflow trap enable bits and saves the overflow and underflow status bits. It then computes1/PositivePower(x,-n). If neither the overflow nor underflow status bit is set, it restores them together with the trap enable bits. If one of the status bits is set, it restores the flags and redoes the calculation usingPositivePower(1/x,-n), which causes the correct exceptions to occur.Another example of the use of flags occurs when computing arccos via the formula
arccos x = 2 arctan.
If arctan(
/2, then arccos(-1) will correctly evaluate to 2·arctan(
Systems Aspects
The design of almost every aspect of a computer system requires knowledge about floating-point. Computer architectures usually have floating-point instructions, compilers must generate those floating-point instructions, and the operating system must decide what to do when exception conditions are raised for those floating-point instructions. Computer system designers rarely get guidance from numerical analysis texts, which are typically aimed at users and writers of software, not at computer designers. As an example of how plausible design decisions can lead to unexpected behavior, consider the following BASIC program.
When compiled and run using Borland's Turbo Basic on an IBM PC, the program prints
NotEqual! This example will be analyzed in the next sectionIncidentally, some people think that the solution to such anomalies is never to compare floating-point numbers for equality, but instead to consider them equal if they are within some error bound E. This is hardly a cure-all because it raises as many questions as it answers. What should the value of E be? If x < 0 and y > 0 are within E, should they really be considered to be equal, even though they have different signs? Furthermore, the relation defined by this rule, a ~ b
Instruction Sets
It is quite common for an algorithm to require a short burst of higher precision in order to produce accurate results. One example occurs in the quadratic formula (
)/2a. As discussed in the section Proof of Theorem 4, when b2
The computation of b2 - 4ac in double precision when each of the quantities a, b, and c are in single precision is easy if there is a multiplication instruction that takes two single precision numbers and produces a double precision result. In order to produce the exactly rounded product of two p-digit numbers, a multiplier needs to generate the entire 2p bits of product, although it may throw bits away as it proceeds. Thus, hardware to compute a double precision product from single precision operands will normally be only a little more expensive than a single precision multiplier, and much cheaper than a double precision multiplier. Despite this, modern instruction sets tend to provide only instructions that produce a result of the same precision as the operands.23
If an instruction that combines two single precision operands to produce a double precision product was only useful for the quadratic formula, it wouldn't be worth adding to an instruction set. However, this instruction has many other uses. Consider the problem of solving a system of linear equations,
a11x1 + a12x2 + · · · + a1nxn= b1
a21x1 + a22x2 + · · · + a2nxn= b2
· · ·
an1x1 + an2x2 + · · ·+ annxn= bn
which can be written in matrix form as Ax = b, where
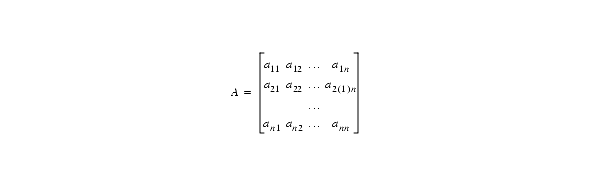
Suppose that a solution x(1) is computed by some method, perhaps Gaussian elimination. There is a simple way to improve the accuracy of the result called iterative improvement. First compute
(12)= Ax(1) - b
(13) Ay =
Note that if x(1) is an exact solution, then
(14) x(2) = x(1) - y
The three steps (12), (13), and (14) can be repeated, replacing x(1) with x(2), and x(2) with x(3). This argument that x(i + 1) is more accurate than x(i) is only informal. For more information, see [Golub and Van Loan 1989].
When performing iterative improvement,
To summarize, instructions that multiply two floating-point numbers and return a product with twice the precision of the operands make a useful addition to a floating-point instruction set. Some of the implications of this for compilers are discussed in the next section.
Languages and Compilers
The interaction of compilers and floating-point is discussed in Farnum [1988], and much of the discussion in this section is taken from that paper.
Ambiguity
Ideally, a language definition should define the semantics of the language precisely enough to prove statements about programs. While this is usually true for the integer part of a language, language definitions often have a large grey area when it comes to floating-point. Perhaps this is due to the fact that many language designers believe that nothing can be proven about floating-point, since it entails rounding error. If so, the previous sections have demonstrated the fallacy in this reasoning. This section discusses some common grey areas in language definitions, including suggestions about how to deal with them.
Remarkably enough, some languages don't clearly specify that if
xis a floating-point variable (with say a value of3.0/10.0), then every occurrence of (say)10.0*xmust have the same value. For example Ada, which is based on Brown's model, seems to imply that floating-point arithmetic only has to satisfy Brown's axioms, and thus expressions can have one of many possible values. Thinking about floating-point in this fuzzy way stands in sharp contrast to the IEEE model, where the result of each floating-point operation is precisely defined. In the IEEE model, we can prove that(3.0/10.0)*10.0evaluates to3(Theorem 7). In Brown's model, we cannot.Another ambiguity in most language definitions concerns what happens on overflow, underflow and other exceptions. The IEEE standard precisely specifies the behavior of exceptions, and so languages that use the standard as a model can avoid any ambiguity on this point.
Another grey area concerns the interpretation of parentheses. Due to roundoff errors, the associative laws of algebra do not necessarily hold for floating-point numbers. For example, the expression
(x+y)+zhas a totally different answer thanx+(y+z)when x = 1030, y = -1030 and z = 1 (it is 1 in the former case, 0 in the latter). The importance of preserving parentheses cannot be overemphasized. The algorithms presented in theorems 3, 4 and 6 all depend on it. For example, in Theorem 6, the formula xh = mx - (mx - x) would reduce to xh = x if it weren't for parentheses, thereby destroying the entire algorithm. A language definition that does not require parentheses to be honored is useless for floating-point calculations.Subexpression evaluation is imprecisely defined in many languages. Suppose that
dsis double precision, butxandyare single precision. Then in the expressionds+x*yis the product performed in single or double precision? Another example: inx+m/nwheremandnare integers, is the division an integer operation or a floating-point one? There are two ways to deal with this problem, neither of which is completely satisfactory. The first is to require that all variables in an expression have the same type. This is the simplest solution, but has some drawbacks. First of all, languages like Pascal that have subrange types allow mixing subrange variables with integer variables, so it is somewhat bizarre to prohibit mixing single and double precision variables. Another problem concerns constants. In the expression0.1*x, most languages interpret 0.1 to be a single precision constant. Now suppose the programmer decides to change the declaration of all the floating-point variables from single to double precision. If 0.1 is still treated as a single precision constant, then there will be a compile time error. The programmer will have to hunt down and change every floating-point constant.The second approach is to allow mixed expressions, in which case rules for subexpression evaluation must be provided. There are a number of guiding examples. The original definition of C required that every floating-point expression be computed in double precision [Kernighan and Ritchie 1978]. This leads to anomalies like the example at the beginning of this section. The expression
3.0/7.0is computed in double precision, but ifqis a single-precision variable, the quotient is rounded to single precision for storage. Since 3/7 is a repeating binary fraction, its computed value in double precision is different from its stored value in single precision. Thus the comparison q = 3/7 fails. This suggests that computing every expression in the highest precision available is not a good rule.Another guiding example is inner products. If the inner product has thousands of terms, the rounding error in the sum can become substantial. One way to reduce this rounding error is to accumulate the sums in double precision (this will be discussed in more detail in the section Optimizers). If
dis a double precision variable, andx[]andy[]are single precision arrays, then the inner product loop will look liked=d+x[i]*y[i]. If the multiplication is done in single precision, than much of the advantage of double precision accumulation is lost, because the product is truncated to single precision just before being added to a double precision variable.A rule that covers both of the previous two examples is to compute an expression in the highest precision of any variable that occurs in that expression. Then
q=3.0/7.0will be computed entirely in single precision24 and will have the boolean value true, whereasd=d+x[i]*y[i]will be computed in double precision, gaining the full advantage of double precision accumulation. However, this rule is too simplistic to cover all cases cleanly. Ifdxanddyare double precision variables, the expressiony=x+single(dx-dy)contains a double precision variable, but performing the sum in double precision would be pointless, because both operands are single precision, as is the result.A more sophisticated subexpression evaluation rule is as follows. First assign each operation a tentative precision, which is the maximum of the precisions of its operands. This assignment has to be carried out from the leaves to the root of the expression tree. Then perform a second pass from the root to the leaves. In this pass, assign to each operation the maximum of the tentative precision and the precision expected by the parent. In the case of
q=3.0/7.0, every leaf is single precision, so all the operations are done in single precision. In the case ofd=d+x[i]*y[i], the tentative precision of the multiply operation is single precision, but in the second pass it gets promoted to double precision, because its parent operation expects a double precision operand. And iny=x+single(dx-dy), the addition is done in single precision. Farnum [1988] presents evidence that this algorithm in not difficult to implement.The disadvantage of this rule is that the evaluation of a subexpression depends on the expression in which it is embedded. This can have some annoying consequences. For example, suppose you are debugging a program and want to know the value of a subexpression. You cannot simply type the subexpression to the debugger and ask it to be evaluated, because the value of the subexpression in the program depends on the expression it is embedded in. A final comment on subexpressions: since converting decimal constants to binary is an operation, the evaluation rule also affects the interpretation of decimal constants. This is especially important for constants like
0.1which are not exactly representable in binary.Another potential grey area occurs when a language includes exponentiation as one of its built-in operations. Unlike the basic arithmetic operations, the value of exponentiation is not always obvious [Kahan and Coonen 1982]. If
**is the exponentiation operator, then(-3)**3certainly has the value -27. However,(-3.0)**3.0is problematical. If the**operator checks for integer powers, it would compute(-3.0)**3.0as -3.03 = -27. On the other hand, if the formula xy = eylogx is used to define**for real arguments, then depending on the log function, the result could be a NaN (using the natural definition of log(x) =NaNwhen x < 0). If the FORTRANCLOGfunction is used however, then the answer will be -27, because the ANSI FORTRAN standard definesCLOG(-3.0)to be iIn fact, the FORTRAN standard says that
- Any arithmetic operation whose result is not mathematically defined is prohibited...
Unfortunately, with the introduction of ±
(-3.0)**3.0to be -27.The IEEE Standard
The section The IEEE Standard," discussed many of the features of the IEEE standard. However, the IEEE standard says nothing about how these features are to be accessed from a programming language. Thus, there is usually a mismatch between floating-point hardware that supports the standard and programming languages like C, Pascal or FORTRAN. Some of the IEEE capabilities can be accessed through a library of subroutine calls. For example the IEEE standard requires that square root be exactly rounded, and the square root function is often implemented directly in hardware. This functionality is easily accessed via a library square root routine. However, other aspects of the standard are not so easily implemented as subroutines. For example, most computer languages specify at most two floating-point types, while the IEEE standard has four different precisions (although the recommended configurations are single plus single-extended or single, double, and double-extended). Infinity provides another example. Constants to represent ±
A more subtle situation is manipulating the state associated with a computation, where the state consists of the rounding modes, trap enable bits, trap handlers and exception flags. One approach is to provide subroutines for reading and writing the state. In addition, a single call that can atomically set a new value and return the old value is often useful. As the examples in the section Flags show, a very common pattern of modifying IEEE state is to change it only within the scope of a block or subroutine. Thus the burden is on the programmer to find each exit from the block, and make sure the state is restored. Language support for setting the state precisely in the scope of a block would be very useful here. Modula-3 is one language that implements this idea for trap handlers [Nelson 1991].
There are a number of minor points that need to be considered when implementing the IEEE standard in a language. Since x - x = +0 for all x,27 (+0) - (+0) = +0. However, -(+0) = -0, thus -x should not be defined as 0 - x. The introduction of NaNs can be confusing, because a NaN is never equal to any other number (including another NaN), so x = x is no longer always true. In fact, the expression x
Isnanis not provided. Furthermore, NaNs are unordered with respect to all other numbers, so xcomparefunction that returns one of <, =, >, or unordered can make it easier for the programmer to deal with comparisons.Although the IEEE standard defines the basic floating-point operations to return a NaN if any operand is a NaN, this might not always be the best definition for compound operations. For example when computing the appropriate scale factor to use in plotting a graph, the maximum of a set of values must be computed. In this case it makes sense for the max operation to simply ignore NaNs.
Finally, rounding can be a problem. The IEEE standard defines rounding very precisely, and it depends on the current value of the rounding modes. This sometimes conflicts with the definition of implicit rounding in type conversions or the explicit
roundfunction in languages. This means that programs which wish to use IEEE rounding can't use the natural language primitives, and conversely the language primitives will be inefficient to implement on the ever increasing number of IEEE machines.Optimizers
Compiler texts tend to ignore the subject of floating-point. For example Aho et al. [1986] mentions replacing
x/2.0withx*0.5, leading the reader to assume thatx/10.0should be replaced by0.1*x. However, these two expressions do not have the same semantics on a binary machine, because 0.1 cannot be represented exactly in binary. This textbook also suggests replacingx*y-x*zbyx*(y-z), even though we have seen that these two expressions can have quite different values when y(x+y)+zcan have a totally different answer thanx+(y+z), as discussed above. There is a problem closely related to preserving parentheses that is illustrated by the following code
:This is designed to give an estimate for machine epsilon. If an optimizing compiler notices that eps + 1 > 1
), it will compute the largest number x for which x/2 is rounded to 0 (x
). Avoiding this kind of "optimization" is so important that it is worth presenting one more very useful algorithm that is totally ruined by it.
Many problems, such as numerical integration and the numerical solution of differential equations involve computing sums with many terms. Because each addition can potentially introduce an error as large as .5 ulp, a sum involving thousands of terms can have quite a bit of rounding error. A simple way to correct for this is to store the partial summand in a double precision variable and to perform each addition using double precision. If the calculation is being done in single precision, performing the sum in double precision is easy on most computer systems. However, if the calculation is already being done in double precision, doubling the precision is not so simple. One method that is sometimes advocated is to sort the numbers and add them from smallest to largest. However, there is a much more efficient method which dramatically improves the accuracy of sums, namely
Theorem 8 (Kahan Summation Formula)
- Suppose that
is computed using the following algorithm
for j = 2 to N {Y = X[j] - C;T = S + Y;C = (T - S) - Y;S = T;}
- Then the computed sum S is equal to
where
.
Using the naive formula
, the computed sum is equal to
where |
j| < (n - j)e. Comparing this with the error in the Kahan summation formula shows a dramatic improvement. Each summand is perturbed by only 2e, instead of perturbations as large as ne in the simple formula. Details are in, Errors In Summation.
An optimizer that believed floating-point arithmetic obeyed the laws of algebra would conclude that C = [T-S] - Y = [(S+Y)-S] - Y = 0, rendering the algorithm completely useless. These examples can be summarized by saying that optimizers should be extremely cautious when applying algebraic identities that hold for the mathematical real numbers to expressions involving floating-point variables.
Another way that optimizers can change the semantics of floating-point code involves constants. In the expression
1.0E-40*x, there is an implicit decimal to binary conversion operation that converts the decimal number to a binary constant. Because this constant cannot be represented exactly in binary, the inexact exception should be raised. In addition, the underflow flag should to be set if the expression is evaluated in single precision. Since the constant is inexact, its exact conversion to binary depends on the current value of the IEEE rounding modes. Thus an optimizer that converts1.0E-40to binary at compile time would be changing the semantics of the program. However, constants like 27.5 which are exactly representable in the smallest available precision can be safely converted at compile time, since they are always exact, cannot raise any exception, and are unaffected by the rounding modes. Constants that are intended to be converted at compile time should be done with a constant declaration, such asconstpi=3.14159265.Common subexpression elimination is another example of an optimization that can change floating-point semantics, as illustrated by the following code
Although
A*Bcan appear to be a common subexpression, it is not because the rounding mode is different at the two evaluation sites. Three final examples: x = x cannot be replaced by the boolean constanttrue, because it fails when x is a NaN; -x = 0 - x fails for x = +0; and x < y is not the opposite of xDespite these examples, there are useful optimizations that can be done on floating-point code. First of all, there are algebraic identities that are valid for floating-point numbers. Some examples in IEEE arithmetic are x + y = y + x, 2 × x = x + x, 1 × x = x, and 0.5× x = x/2. However, even these simple identities can fail on a few machines such as CDC and Cray supercomputers. Instruction scheduling and in-line procedure substitution are two other potentially useful optimizations.28
As a final example, consider the expression
dx=x*y, wherexandyare single precision variables, anddxis double precision. On machines that have an instruction that multiplies two single precision numbers to produce a double precision number,dx=x*ycan get mapped to that instruction, rather than compiled to a series of instructions that convert the operands to double and then perform a double to double precision multiply.Some compiler writers view restrictions which prohibit converting (x + y) + z to x + (y + z) as irrelevant, of interest only to programmers who use unportable tricks. Perhaps they have in mind that floating-point numbers model real numbers and should obey the same laws that real numbers do. The problem with real number semantics is that they are extremely expensive to implement. Every time two n bit numbers are multiplied, the product will have 2n bits. Every time two n bit numbers with widely spaced exponents are added, the number of bits in the sum is n + the space between the exponents. The sum could have up to (emax - emin) + n bits, or roughly 2·emax + n bits. An algorithm that involves thousands of operations (such as solving a linear system) will soon be operating on numbers with many significant bits, and be hopelessly slow. The implementation of library functions such as sin and cos is even more difficult, because the value of these transcendental functions aren't rational numbers. Exact integer arithmetic is often provided by lisp systems and is handy for some problems. However, exact floating-point arithmetic is rarely useful.
The fact is that there are useful algorithms (like the Kahan summation formula) that exploit the fact that (x + y) + z
a
holds (as well as similar bounds for -, × and /). Since these bounds hold for almost all commercial hardware, it would be foolish for numerical programmers to ignore such algorithms, and it would be irresponsible for compiler writers to destroy these algorithms by pretending that floating-point variables have real number semantics.
Exception Handling
The topics discussed up to now have primarily concerned systems implications of accuracy and precision. Trap handlers also raise some interesting systems issues. The IEEE standard strongly recommends that users be able to specify a trap handler for each of the five classes of exceptions, and the section Trap Handlers, gave some applications of user defined trap handlers. In the case of invalid operation and division by zero exceptions, the handler should be provided with the operands, otherwise, with the exactly rounded result. Depending on the programming language being used, the trap handler might be able to access other variables in the program as well. For all exceptions, the trap handler must be able to identify what operation was being performed and the precision of its destination.
The IEEE standard assumes that operations are conceptually serial and that when an interrupt occurs, it is possible to identify the operation and its operands. On machines which have pipelining or multiple arithmetic units, when an exception occurs, it may not be enough to simply have the trap handler examine the program counter. Hardware support for identifying exactly which operation trapped may be necessary.
Another problem is illustrated by the following program fragment.
Suppose the second multiply raises an exception, and the trap handler wants to use the value of
a. On hardware that can do an add and multiply in parallel, an optimizer would probably move the addition operation ahead of the second multiply, so that the add can proceed in parallel with the first multiply. Thus when the second multiply traps,a=b+chas already been executed, potentially changing the result ofa. It would not be reasonable for a compiler to avoid this kind of optimization, because every floating-point operation can potentially trap, and thus virtually all instruction scheduling optimizations would be eliminated. This problem can be avoided by prohibiting trap handlers from accessing any variables of the program directly. Instead, the handler can be given the operands or result as an argument.But there are still problems. In the fragment
the two instructions might well be executed in parallel. If the multiply traps, its argument
zcould already have been overwritten by the addition, especially since addition is usually faster than multiply. Computer systems that support the IEEE standard must provide some way to save the value ofz, either in hardware or by having the compiler avoid such a situation in the first place.W. Kahan has proposed using presubstitution instead of trap handlers to avoid these problems. In this method, the user specifies an exception and the value he wants to be used as the result when the exception occurs. As an example, suppose that in code for computing (sin x)/x, the user decides that x = 0 is so rare that it would improve performance to avoid a test for x = 0, and instead handle this case when a 0/0 trap occurs. Using IEEE trap handlers, the user would write a handler that returns a value of 1 and install it before computing sin x/x. Using presubstitution, the user would specify that when an invalid operation occurs, the value 1 should be used. Kahan calls this presubstitution, because the value to be used must be specified before the exception occurs. When using trap handlers, the value to be returned can be computed when the trap occurs.
The advantage of presubstitution is that it has a straightforward hardware implementation.29 As soon as the type of exception has been determined, it can be used to index a table which contains the desired result of the operation. Although presubstitution has some attractive attributes, the widespread acceptance of the IEEE standard makes it unlikely to be widely implemented by hardware manufacturers.
The Details
A number of claims have been made in this paper concerning properties of floating-point arithmetic. We now proceed to show that floating-point is not black magic, but rather is a straightforward subject whose claims can be verified mathematically. This section is divided into three parts. The first part presents an introduction to error analysis, and provides the details for the section Rounding Error. The second part explores binary to decimal conversion, filling in some gaps from the section The IEEE Standard. The third part discusses the Kahan summation formula, which was used as an example in the section Systems Aspects.
Rounding Error
In the discussion of rounding error, it was stated that a single guard digit is enough to guarantee that addition and subtraction will always be accurate (Theorem 2). We now proceed to verify this fact. Theorem 2 has two parts, one for subtraction and one for addition. The part for subtraction is
Theorem 9
If x and y are positive floating-point numbers in a format with parameters
e
Proof
(15) y -
- Interchange x and y if necessary so that x > y. It is also harmless to scale x and y so that x is represented by x0.x1 ... xp - 1 ×
be y truncated to p + 1 digits. Then
< (
(16) |
- From the definition of guard digit, the computed value of x - y is x -
rounded to be a floating-point number, that is, (x -
) +
(17)
- The exact difference is x - y, so the error is (x - y) - (x -
+
- y +
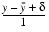
- Secondly, if x -
< 1, then
> (
(18)
- in this case the relative error is bounded by
.
- The final case is when x - y < 1 but x -
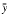
= 1, in which case
When
Theorem 10
If x
Proof
- The algorithm for addition with k guard digits is similar to that for subtraction. If x
- We will verify the theorem when no guard digits are used; the general case is similar. There is no loss of generality in assuming that x
.
The sum is at least
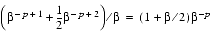
It is obvious that combining these two theorems gives Theorem 2. Theorem 2 gives the relative error for performing one operation. Comparing the rounding error of x2 - y2 and (x + y) (x - y) requires knowing the relative error of multiple operations. The relative error of x
(19) xy is
y) - (x - y)] / (x - y), which satisfies |
y = (x - y) (1 +
(20) x
Assuming that multiplication is performed by computing the exact product and then rounding, the relative error is at most .5 ulp, so
(21) u
for any floating-point numbers u and v. Putting these three equations together (letting u = x
(22) (xy and v = x
y)
So the relative error incurred when computing (x - y) (x + y) is
(23)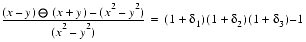
This relative error is equal to
A similar analysis of (x
(x(y
y)
(y
= ((x2 - y2) (1 +
When x and y are nearby, the error term (
We next turn to an analysis of the formula for the area of a triangle. In order to estimate the maximum error that can occur when computing with (7), the following fact will be needed.
Theorem 11
- If subtraction is performed with a guard digit, and y/2
Proof
- Note that if x and y have the same exponent, then certainly x
y is exact. Otherwise, from the condition of the theorem, the exponents can differ by at most 1. Scale and interchange x and y if necessary so that 0
y will compute x - y exactly and round to a floating-point number. If the difference is of the form 0.d1 ... dp, the difference will already be p digits long, and no rounding is necessary. Since x
When
Theorem 12
- If subtraction uses a guard digit, and if a,b and c are the sides of a triangle (a
Proof
(a
- Let's examine the factors one by one. From Theorem 10, b
(a + b + c) (1 - 2
- and thus
(24) (a
- This means that there is an
1 so that
(25) (c
- The next term involves the potentially catastrophic subtraction of c and a
b, because ab may have rounding error. Because a, b and c are the sides of a triangle, a
b is exact, hence c
(a - b) is a harmless subtraction which can be estimated from Theorem 9 to be
(a
b)) = (c - (a - b)) (1 +
(26) (c
- The third term is the sum of two exact positive quantities, so
b)) = (c + (a - b)) (1 +
(27) (a
- Finally, the last term is
c)) = (a + (b - c)) (1 +
(a
- using both Theorem 9 and Theorem 10. If multiplication is assumed to be exactly rounded, so that x
) with |
(a
b)) (c
b)) (a
c))
E = (1 +
- where
- An upper bound for E is (1 + 2
Theorem 12 certainly shows that there is no catastrophic cancellation in formula (7). So although it is not necessary to show formula (7) is numerically stable, it is satisfying to have a bound for the entire formula, which is what Theorem 3 of Cancellation gives.
Proof of Theorem 3
q = (a + (b + c)) (c - (a - b)) (c + (a - b)) (a + (b - c))
- Let
Q = (a
- and
(a
b))
b))
c)).
(28)
- Then, Theorem 12 shows that Q = q(1 +
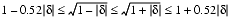
- provided
,
- with |
is (1 +
To make the heuristic explanation immediately following the statement of Theorem 4 precise, the next theorem describes just how closely µ(x) approximates a constant.
Theorem 13
- If µ(x) = ln(1 + x)/x, then for 0
,
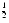
.
Proof
- Note that µ(x) = 1 - x/2 + x2/3 - ... is an alternating series with decreasing terms, so for x
has decreasing terms, so -
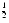
+ 2x/3, or -
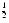
. z
Proof of Theorem 4
- Since the Taylor series for ln
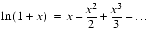
(29)
- is an alternating series, 0 < x - ln(1 + x) < x2/2, the relative error incurred when approximating ln(1 + x) by x is bounded by x/2. If 1
- When 1
via 1
. Then since 0
1 =
. If division and logarithms are computed to within
ulp, then the computed value of the expression ln(1 + x)/((1 + x) - 1) is
(1 +
(1 +
) (1 +
where |
(30) µ(), use the mean value theorem, which says that
) - µ(x) = (
- x)µ'(
x·ln(1
- for some
. From the definition of
, it follows that |
- x|
) - µ(x)|
)/µ(x) - 1|
) = µ(x) (1 +
1)
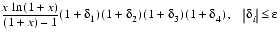
(1 +
- It is easy to check that if
An interesting example of error analysis using formulas (19), (20), and (21) occurs in the quadratic formula
. The section Cancellation, explained how rewriting the equation will eliminate the potential cancellation caused by the ± operation. But there is another potential cancellation that can occur when computing d = b2 - 4ac. This one cannot be eliminated by a simple rearrangement of the formula. Roughly speaking, when b2
If b2
.
Proof: Write (b
(4a
, the first term d(
. Thus the computed value of
is
.
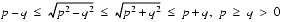
,
,
so the absolute error in
a is about
. Since
, and thus the absolute error of
destroys the bottom half of the bits of the roots r1
, and this expression does not have meaningful bits in the position corresponding to the lower order half of ri, then the lower order bits of ri cannot be meaningful. z
Finally, we turn to the proof of Theorem 6. It is based on the following fact, which is proven in the section Theorem 14 and Theorem 8.
Theorem 14
- Let 0 < k < p, and set m =
(m
x) is exactly equal to x rounded to p - k significant digits. More precisely, x is rounded by taking the significand of x, imagining a radix point just left of the k least significant digits and rounding to an integer.
Proof of Theorem 6
- By Theorem 14, xh is x rounded to p - k =
places. If there is no carry out, then certainly xh can be represented with
significant digits. Suppose there is a carry-out. If x = x0.x1 ... xp - 1 ×
digits.
- To deal with xl, scale x to be an integer satisfying
where
is the p - k high order digits of x, and
is the k low order digits. There are three cases to consider. If
, then rounding x to p - k places is the same as chopping and
, and
. Since
has at most k digits, if p is even, then
has at most k =
=
digits. Otherwise,
is representable with k - 1
significant bits. The second case is when
, and then computing xh involves rounding up, so xh =
+
-
-
has at most k digits, so is representable with
p/2
digits. Finally, if
= (
or
+
Theorem 6 gives a way to express the product of two working precision numbers exactly as a sum. There is a companion formula for expressing a sum exactly. If |x|
(x
Binary to Decimal Conversion
Since single precision has p = 24, and 224 < 108, you might expect that converting a binary number to 8 decimal digits would be sufficient to recover the original binary number. However, this is not the case.
Theorem 15
- When a binary IEEE single precision number is converted to the closest eight digit decimal number, it is not always possible to uniquely recover the binary number from the decimal one. However, if nine decimal digits are used, then converting the decimal number to the closest binary number will recover the original floating-point number.
Proof
[N -
- Binary single precision numbers lying in the half open interval [103, 210) = [1000, 1024) have 10 bits to the left of the binary point, and 14 bits to the right of the binary point. Thus there are (210 - 103)214 = 393,216 different binary numbers in that interval. If decimal numbers are represented with 8 digits, then there are (210 - 103)104 = 240,000 decimal numbers in the same interval. There is no way that 240,000 decimal numbers could represent 393,216 different binary numbers. So 8 decimal digits are not enough to uniquely represent each single precision binary number.
- To show that 9 digits are sufficient, it is enough to show that the spacing between binary numbers is always greater than the spacing between decimal numbers. This will ensure that for each decimal number N, the interval
ulp, N +
ulp]
- contains at most one binary number. Thus each binary number rounds to a unique decimal number which in turn rounds to a unique binary number.
- To show that the spacing between binary numbers is always greater than the spacing between decimal numbers, consider an interval [10n, 10n + 1]. On this interval, the spacing between consecutive decimal numbers is 10(n + 1) - 9. On [10n, 2m], where m is the smallest integer so that 10n < 2m, the spacing of binary numbers is 2m - 24, and the spacing gets larger further on in the interval. Thus it is enough to check that 10(n + 1) - 9 < 2m - 24. But in fact, since 10n < 2m, then 10(n + 1) - 9 = 10n10-8 < 2m10-8 < 2m2-24. z
The same argument applied to double precision shows that 17 decimal digits are required to recover a double precision number.
Binary-decimal conversion also provides another example of the use of flags. Recall from the section Precision, that to recover a binary number from its decimal expansion, the decimal to binary conversion must be computed exactly. That conversion is performed by multiplying the quantities N and 10|P| (which are both exact if p < 13) in single-extended precision and then rounding this to single precision (or dividing if p < 0; both cases are similar). Of course the computation of N · 10|P| cannot be exact; it is the combined operation round(N · 10|P|) that must be exact, where the rounding is from single-extended to single precision. To see why it might fail to be exact, take the simple case of
By using the IEEE flags, double rounding can be avoided as follows. Save the current value of the inexact flag, and then reset it. Set the rounding mode to round-to-zero. Then perform the multiplication N · 10|P|. Store the new value of the inexact flag in
ixflag, and restore the rounding mode and inexact flag. Ifixflagis 0, then N · 10|P| is exact, so round(N · 10|P|) will be correct down to the last bit. Ifixflagis 1, then some digits were truncated, since round-to-zero always truncates. The significand of the product will look like 1.b1...b22b23...b31. A double rounding error may occur if b23 ...b31 = 10...0. A simple way to account for both cases is to perform a logicalORofixflagwith b31. Then round(N · 10|P|) will be computed correctly in all cases.Errors In Summation
The section Optimizers, mentioned the problem of accurately computing very long sums. The simplest approach to improving accuracy is to double the precision. To get a rough estimate of how much doubling the precision improves the accuracy of a sum, let s1 = x1, s2 = s1
(31)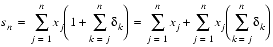
The first equality of (31) shows that the computed value of
is the same as if an exact summation was performed on perturbed values of xj. The first term x1 is perturbed by n
. Doubling the precision has the effect of squaring
for any reasonable value of n. Thus, doubling the precision takes the maximum perturbation of n
. Thus the 2
For an intuitive explanation of why the Kahan summation formula works, consider the following diagram of the procedure.
Each time a summand is added, there is a correction factor C which will be applied on the next loop. So first subtract the correction C computed in the previous loop from Xj, giving the corrected summand Y. Then add this summand to the running sum S. The low order bits of Y (namely Yl) are lost in the sum. Next compute the high order bits of Y by computing T - S. When Y is subtracted from this, the low order bits of Y will be recovered. These are the bits that were lost in the first sum in the diagram. They become the correction factor for the next loop. A formal proof of Theorem 8, taken from Knuth [1981] page 572, appears in the section Theorem 14 and Theorem 8."
Summary
It is not uncommon for computer system designers to neglect the parts of a system related to floating-point. This is probably due to the fact that floating-point is given very little (if any) attention in the computer science curriculum. This in turn has caused the apparently widespread belief that floating-point is not a quantifiable subject, and so there is little point in fussing over the details of hardware and software that deal with it.
This paper has demonstrated that it is possible to reason rigorously about floating-point. For example, floating-point algorithms involving cancellation can be proven to have small relative errors if the underlying hardware has a guard digit, and there is an efficient algorithm for binary-decimal conversion that can be proven to be invertible, provided that extended precision is supported. The task of constructing reliable floating-point software is made much easier when the underlying computer system is supportive of floating-point. In addition to the two examples just mentioned (guard digits and extended precision), the section Systems Aspects of this paper has examples ranging from instruction set design to compiler optimization illustrating how to better support floating-point.
The increasing acceptance of the IEEE floating-point standard means that codes that utilize features of the standard are becoming ever more portable. The section The IEEE Standard, gave numerous examples illustrating how the features of the IEEE standard can be used in writing practical floating-point codes.
Acknowledgments
This article was inspired by a course given by W. Kahan at Sun Microsystems from May through July of 1988, which was very ably organized by David Hough of Sun. My hope is to enable others to learn about the interaction of floating-point and computer systems without having to get up in time to attend 8:00 a.m. lectures. Thanks are due to Kahan and many of my colleagues at Xerox PARC (especially John Gilbert) for reading drafts of this paper and providing many useful comments. Reviews from Paul Hilfinger and an anonymous referee also helped improve the presentation.
References
Aho, Alfred V., Sethi, R., and Ullman J. D. 1986. Compilers: Principles, Techniques and Tools, Addison-Wesley, Reading, MA.
ANSI 1978. American National Standard Programming Language FORTRAN, ANSI Standard X3.9-1978, American National Standards Institute, New York, NY.
Barnett, David 1987. A Portable Floating-Point Environment, unpublished manuscript.
Brown, W. S. 1981. A Simple but Realistic Model of Floating-Point Computation, ACM Trans. on Math. Software 7(4), pp. 445-480.
Cody, W. J et. al. 1984. A Proposed Radix- and Word-length-independent Standard for Floating-point Arithmetic, IEEE Micro 4(4), pp. 86-100.
Cody, W. J. 1988. Floating-Point Standards -- Theory and Practice, in "Reliability in Computing: the role of interval methods in scientific computing", ed. by Ramon E. Moore, pp. 99-107, Academic Press, Boston, MA.
Coonen, Jerome 1984. Contributions to a Proposed Standard for Binary Floating-Point Arithmetic, PhD Thesis, Univ. of California, Berkeley.
Dekker, T. J. 1971. A Floating-Point Technique for Extending the Available Precision, Numer. Math. 18(3), pp. 224-242.
Demmel, James 1984. Underflow and the Reliability of Numerical Software, SIAM J. Sci. Stat. Comput. 5(4), pp. 887-919.
Farnum, Charles 1988. Compiler Support for Floating-point Computation, Software-Practice and Experience, 18(7), pp. 701-709.
Forsythe, G. E. and Moler, C. B. 1967. Computer Solution of Linear Algebraic Systems, Prentice-Hall, Englewood Cliffs, NJ.
Goldberg, I. Bennett 1967. 27 Bits Are Not Enough for 8-Digit Accuracy, Comm. of the ACM. 10(2), pp 105-106.
Goldberg, David 1990. Computer Arithmetic, in "Computer Architecture: A Quantitative Approach", by David Patterson and John L. Hennessy, Appendix A, Morgan Kaufmann, Los Altos, CA.
Golub, Gene H. and Van Loan, Charles F. 1989. Matrix Computations, 2nd edition,The Johns Hopkins University Press, Baltimore Maryland.
Graham, Ronald L. , Knuth, Donald E. and Patashnik, Oren. 1989. Concrete Mathematics, Addison-Wesley, Reading, MA, p.162.
Hewlett Packard 1982. HP-15C Advanced Functions Handbook.
IEEE 1987. IEEE Standard 754-1985 for Binary Floating-point Arithmetic, IEEE, (1985). Reprinted in SIGPLAN 22(2) pp. 9-25.
Kahan, W. 1972. A Survey Of Error Analysis, in Information Processing 71, Vol 2, pp. 1214 - 1239 (Ljubljana, Yugoslavia), North Holland, Amsterdam.
Kahan, W. 1986. Calculating Area and Angle of a Needle-like Triangle, unpublished manuscript.
Kahan, W. 1987. Branch Cuts for Complex Elementary Functions, in "The State of the Art in Numerical Analysis", ed. by M.J.D. Powell and A. Iserles (Univ of Birmingham, England), Chapter 7, Oxford University Press, New York.
Kahan, W. 1988. Unpublished lectures given at Sun Microsystems, Mountain View, CA.
Kahan, W. and Coonen, Jerome T. 1982. The Near Orthogonality of Syntax, Semantics, and Diagnostics in Numerical Programming Environments, in "The Relationship Between Numerical Computation And Programming Languages", ed. by J. K. Reid, pp. 103-115, North-Holland, Amsterdam.
Kahan, W. and LeBlanc, E. 1985. Anomalies in the IBM Acrith Package, Proc. 7th IEEE Symposium on Computer Arithmetic (Urbana, Illinois), pp. 322-331.
Kernighan, Brian W. and Ritchie, Dennis M. 1978. The C Programming Language, Prentice-Hall, Englewood Cliffs, NJ.
Kirchner, R. and Kulisch, U. 1987. Arithmetic for Vector Processors, Proc. 8th IEEE Symposium on Computer Arithmetic (Como, Italy), pp. 256-269.
Knuth, Donald E., 1981. The Art of Computer Programming, Volume II, Second Edition, Addison-Wesley, Reading, MA.
Kulisch, U. W., and Miranker, W. L. 1986. The Arithmetic of the Digital Computer: A New Approach, SIAM Review 28(1), pp 1-36.
Matula, D. W. and Kornerup, P. 1985. Finite Precision Rational Arithmetic: Slash Number Systems, IEEE Trans. on Comput. C-34(1), pp 3-18.
Nelson, G. 1991. Systems Programming With Modula-3, Prentice-Hall, Englewood Cliffs, NJ.
Reiser, John F. and Knuth, Donald E. 1975. Evading the Drift in Floating-point Addition, Information Processing Letters 3(3), pp 84-87.
Sterbenz, Pat H. 1974. Floating-Point Computation, Prentice-Hall, Englewood Cliffs, NJ.
Swartzlander, Earl E. and Alexopoulos, Aristides G. 1975. The Sign/Logarithm Number System, IEEE Trans. Comput. C-24(12), pp. 1238-1242.
Walther, J. S., 1971. A unified algorithm for elementary functions, Proceedings of the AFIP Spring Joint Computer Conf. 38, pp. 379-385.
Theorem 14 and Theorem 8
This section contains two of the more technical proofs that were omitted from the text.
Theorem 14
- Let 0 < k < p, and set m =
(m
x) is exactly equal to x rounded to p - k significant digits. More precisely, x is rounded by taking the significand of x, imagining a radix point just left of the k least significant digits, and rounding to an integer.
Proof
(32) m
- The proof breaks up into two cases, depending on whether or not the computation of mx =
- Assume there is no carry out. It is harmless to scale x so that it is an integer. Then the computation of mx = x +
aa...aabb...bbaa...aabb...bb
+zz...zzbb...bb- where x has been partitioned into two parts. The low order k digits are marked
band the high order p - k digits are markeda. To compute mb) so
(33) r = 1 if
- The value of r is 1 if
.bb...bis greater thanand 0 otherwise. More precisely
a.bb...brounds to a + 1, r = 0 otherwise.
(34) (m
- Next compute m
x. The top line is
Bis the digit that results from addingrto the lowest order digitb.
aa...aabb...bB00...00bb...bb
-zz... zzZ00...00- If
.bb...b<then r = 0, subtracting causes a borrow from the digit marked
B, but the difference is rounded up, and so the net effect is that the rounded difference equals the top line, which is.bb...b>then r = 1, and 1 is subtracted from
Bbecause of the borrow, so the result is.bb...b=. If r = 0 then
Bis even,Zis odd, and the difference is rounded up, givingBis odd,Zis even, the difference is rounded down, so again the difference isx =
(m
- Combining equations (32) and (34) gives (m
x) = x - x mod(
r00...00bb...bb
+ aa...aabb...bb
-aa...aA00...00- The rule for computing r, equation (33), is the same as the rule for rounding
a...ab...bto p - k places. Thus computing mx - (mx - x) in floating-point arithmetic precision is exactly equal to rounding x to p - k places, in the case when x +- When x +
aa...aabb...bbaa...aabb...bb
+zz...zZbb...bb- Thus, m
aa...aabb...bb00...00w
- bb... bb
+zz ... zZbb ...bb31- Rounding gives (m
x =
.bb...b>or if
.bb...b=and b0 = 1.32 Finally,
x) = mx - x mod(
= x - x mod(
- And once again, r = 1 exactly when rounding
a...ab...bto p - k places involves rounding up. Thus Theorem 14 is proven in all cases. zTheorem 8 (Kahan Summation Formula)
- Suppose that
is computed using the following algorithm
for j = 2 to N {
- Then the computed sum S is equal to S =
xj (1 +
Proof
C1 = 2
- First recall how the error estimate for the simple formula
- yk = xk
ck - 1 = (xk - ck - 1) (1 +
- sk = sk - 1
k)
- ck = (sk
sk - 1)
yk= [(sk - sk - 1) (1 +
k) - yk] (1 +
- where all the Greek letters are bounded by
- When k = 1,
- c1 = (s1(1 +
- = y1((1 + s1) (1 +
- = x1(s1 +
- s1 - c1 = x1[(1 + s1) - (s1 + g1 + s1g1) (1 + d1)](1 + h1)
- = x1[1 - g1 - s1d1 - s1g1 - d1g1 - s1g1d1](1 + h1)
- Calling the coefficients of x1 in these expressions Ck and Sk respectively, then
S1 = +
C2 =
- To get the general formula for Sk and Ck, expand the definitions of sk and ck, ignoring all terms involving xi with i > 1 to get
- sk = (sk - 1 + yk)(1 +
- = [sk - 1 + (xk - ck - 1) (1 +
- = [(sk - 1 - ck - 1) -
- ck = [{sk - sk - 1}(1 +
- = [{((sk - 1 - ck - 1) -
- = [{(sk - 1 - ck - 1)
- = [(sk - 1 - ck - 1)
- sk - ck = ((sk - 1 - ck - 1) -
- - [(sk - 1 - ck - 1)
- = (sk- 1 - ck - 1)((1 +
- + ck - 1(-
- = (s- 1 - ck - 1) (1 -
- + ck - 1 - [
- Since Sk and Ck are only being computed up to order
- Ck= (
- Sk= ((1 + 2
(
- Using these formulas gives
S2 = 1 +
Ck =
- and in general it is easy to check by induction that
Sk = 1 +
Finally, what is wanted is the coefficient of x1 in sk. To get this value, let xn + 1 = 0, let all the Greek letters with subscripts of n + 1 equal 0, and compute sn + 1. Then sn + 1 = sn - cn, and the coefficient of x1 in sn is less than the coefficient in sn + 1, which is Sn = 1 +
Differences Among IEEE 754 Implementations
Note – This section is not part of the published paper. It has been added to clarify certain points and correct possible misconceptions about the IEEE standard that the reader might infer from the paper. This material was not written by David Goldberg, but it appears here with his permission.
The preceding paper has shown that floating-point arithmetic must be implemented carefully, since programmers may depend on its properties for the correctness and accuracy of their programs. In particular, the IEEE standard requires a careful implementation, and it is possible to write useful programs that work correctly and deliver accurate results only on systems that conform to the standard. The reader might be tempted to conclude that such programs should be portable to all IEEE systems. Indeed, portable software would be easier to write if the remark "When a program is moved between two machines and both support IEEE arithmetic, then if any intermediate result differs, it must be because of software bugs, not from differences in arithmetic," were true.
Unfortunately, the IEEE standard does not guarantee that the same program will deliver identical results on all conforming systems. Most programs will actually produce different results on different systems for a variety of reasons. For one, most programs involve the conversion of numbers between decimal and binary formats, and the IEEE standard does not completely specify the accuracy with which such conversions must be performed. For another, many programs use elementary functions supplied by a system library, and the standard doesn't specify these functions at all. Of course, most programmers know that these features lie beyond the scope of the IEEE standard.
Many programmers may not realize that even a program that uses only the numeric formats and operations prescribed by the IEEE standard can compute different results on different systems. In fact, the authors of the standard intended to allow different implementations to obtain different results. Their intent is evident in the definition of the term destination in the IEEE 754 standard: "A destination may be either explicitly designated by the user or implicitly supplied by the system (for example, intermediate results in subexpressions or arguments for procedures). Some languages place the results of intermediate calculations in destinations beyond the user's control. Nonetheless, this standard defines the result of an operation in terms of that destination's format and the operands' values." (IEEE 754-1985, p. 7) In other words, the IEEE standard requires that each result be rounded correctly to the precision of the destination into which it will be placed, but the standard does not require that the precision of that destination be determined by a user's program. Thus, different systems may deliver their results to destinations with different precisions, causing the same program to produce different results (sometimes dramatically so), even though those systems all conform to the standard.
Several of the examples in the preceding paper depend on some knowledge of the way floating-point arithmetic is rounded. In order to rely on examples such as these, a programmer must be able to predict how a program will be interpreted, and in particular, on an IEEE system, what the precision of the destination of each arithmetic operation may be. Alas, the loophole in the IEEE standard's definition of destination undermines the programmer's ability to know how a program will be interpreted. Consequently, several of the examples given above, when implemented as apparently portable programs in a high-level language, may not work correctly on IEEE systems that normally deliver results to destinations with a different precision than the programmer expects. Other examples may work, but proving that they work may lie beyond the average programmer's ability.
In this section, we classify existing implementations of IEEE 754 arithmetic based on the precisions of the destination formats they normally use. We then review some examples from the paper to show that delivering results in a wider precision than a program expects can cause it to compute wrong results even though it is provably correct when the expected precision is used. We also revisit one of the proofs in the paper to illustrate the intellectual effort required to cope with unexpected precision even when it doesn't invalidate our programs. These examples show that despite all that the IEEE standard prescribes, the differences it allows among different implementations can prevent us from writing portable, efficient numerical software whose behavior we can accurately predict. To develop such software, then, we must first create programming languages and environments that limit the variability the IEEE standard permits and allow programmers to express the floating-point semantics upon which their programs depend.
Current IEEE 754 Implementations
Current implementations of IEEE 754 arithmetic can be divided into two groups distinguished by the degree to which they support different floating-point formats in hardware. Extended-based systems, exemplified by the Intel x86 family of processors, provide full support for an extended double precision format but only partial support for single and double precision: they provide instructions to load or store data in single and double precision, converting it on-the-fly to or from the extended double format, and they provide special modes (not the default) in which the results of arithmetic operations are rounded to single or double precision even though they are kept in registers in extended double format. (Motorola 68000 series processors round results to both the precision and range of the single or double formats in these modes. Intel x86 and compatible processors round results to the precision of the single or double formats but retain the same range as the extended double format.) Single/double systems, including most RISC processors, provide full support for single and double precision formats but no support for an IEEE-compliant extended double precision format. (The IBM POWER architecture provides only partial support for single precision, but for the purpose of this section, we classify it as a single/double system.)
To see how a computation might behave differently on an extended-based system than on a single/double system, consider a C version of the example from the section Systems Aspects:
int main() {double q;q = 3.0/7.0;if (q == 3.0/7.0) printf("Equal\n");else printf("Not Equal\n");return 0;}
Here the constants 3.0 and 7.0 are interpreted as double precision floating-point numbers, and the expression 3.0/7.0 inherits the
doubledata type. On a single/double system, the expression will be evaluated in double precision since that is the most efficient format to use. Thus,qwill be assigned the value 3.0/7.0 rounded correctly to double precision. In the next line, the expression 3.0/7.0 will again be evaluated in double precision, and of course the result will be equal to the value just assigned toq, so the program will print "Equal" as expected.On an extended-based system, even though the expression 3.0/7.0 has type
double, the quotient will be computed in a register in extended double format, and thus in the default mode, it will be rounded to extended double precision. When the resulting value is assigned to the variableq, however, it may then be stored in memory, and sinceqis declareddouble, the value will be rounded to double precision. In the next line, the expression 3.0/7.0 may again be evaluated in extended precision yielding a result that differs from the double precision value stored inq, causing the program to print "Not equal". Of course, other outcomes are possible, too: the compiler could decide to store and thus round the value of the expression 3.0/7.0 in the second line before comparing it withq, or it could keepqin a register in extended precision without storing it. An optimizing compiler might evaluate the expression 3.0/7.0 at compile time, perhaps in double precision or perhaps in extended double precision. (With one x86 compiler, the program prints "Equal" when compiled with optimization and "Not Equal" when compiled for debugging.) Finally, some compilers for extended-based systems automatically change the rounding precision mode to cause operations producing results in registers to round those results to single or double precision, albeit possibly with a wider range. Thus, on these systems, we can't predict the behavior of the program simply by reading its source code and applying a basic understanding of IEEE 754 arithmetic. Neither can we accuse the hardware or the compiler of failing to provide an IEEE 754 compliant environment; the hardware has delivered a correctly rounded result to each destination, as it is required to do, and the compiler has assigned some intermediate results to destinations that are beyond the user's control, as it is allowed to do.Pitfalls in Computations on Extended-Based Systems
Conventional wisdom maintains that extended-based systems must produce results that are at least as accurate, if not more accurate than those delivered on single/double systems, since the former always provide at least as much precision and often more than the latter. Trivial examples such as the C program above as well as more subtle programs based on the examples discussed below show that this wisdom is naive at best: some apparently portable programs, which are indeed portable across single/double systems, deliver incorrect results on extended-based systems precisely because the compiler and hardware conspire to occasionally provide more precision than the program expects.
Current programming languages make it difficult for a program to specify the precision it expects. As the section Languages and Compilers mentions, many programming languages don't specify that each occurrence of an expression like
10.0*xin the same context should evaluate to the same value. Some languages, such as Ada, were influenced in this respect by variations among different arithmetics prior to the IEEE standard. More recently, languages like ANSI C have been influenced by standard-conforming extended-based systems. In fact, the ANSI C standard explicitly allows a compiler to evaluate a floating-point expression to a precision wider than that normally associated with its type. As a result, the value of the expression10.0*xmay vary in ways that depend on a variety of factors: whether the expression is immediately assigned to a variable or appears as a subexpression in a larger expression; whether the expression participates in a comparison; whether the expression is passed as an argument to a function, and if so, whether the argument is passed by value or by reference; the current precision mode; the level of optimization at which the program was compiled; the precision mode and expression evaluation method used by the compiler when the program was compiled; and so on.Language standards are not entirely to blame for the vagaries of expression evaluation. Extended-based systems run most efficiently when expressions are evaluated in extended precision registers whenever possible, yet values that must be stored are stored in the narrowest precision required. Constraining a language to require that
10.0*xevaluate to the same value everywhere would impose a performance penalty on those systems. Unfortunately, allowing those systems to evaluate10.0*xdifferently in syntactically equivalent contexts imposes a penalty of its own on programmers of accurate numerical software by preventing them from relying on the syntax of their programs to express their intended semantics.Do real programs depend on the assumption that a given expression always evaluates to the same value? Recall the algorithm presented in Theorem 4 for computing ln(1 + x), written here in Fortran:
On an extended-based system, a compiler may evaluate the expression
1.0+xin the third line in extended precision and compare the result with1.0. When the same expression is passed to the log function in the sixth line, however, the compiler may store its value in memory, rounding it to single precision. Thus, ifxis not so small that1.0+xrounds to1.0in extended precision but small enough that1.0+xrounds to1.0in single precision, then the value returned bylog1p(x)will be zero instead ofx, and the relative error will be one--rather larger than 51.0+x, is evaluated in extended precision. In that case, ifxis small but not quite small enough that1.0+xrounds to1.0in single precision, then the value returned bylog1p(x)can exceed the correct value by nearly as much asx, and again the relative error can approach one. For a concrete example, takexto be 2-24 + 2-47, soxis the smallest single precision number such that1.0+xrounds up to the next larger number, 1 + 2-23. Thenlog(1.0+x)is approximately 2-23. Because the denominator in the expression in the sixth line is evaluated in extended precision, it is computed exactly and deliversx, solog1p(x)returns approximately 2-23, which is nearly twice as large as the exact value. (This actually happens with at least one compiler. When the preceding code is compiled by the Sun WorkShop Compilers 4.2.1 Fortran 77 compiler for x86 systems using the-Ooptimization flag, the generated code computes1.0+xexactly as described. As a result, the function delivers zero forlog1p(1.0e-10)and1.19209E-07forlog1p(5.97e-8).)For the algorithm of Theorem 4 to work correctly, the expression
1.0+xmust be evaluated the same way each time it appears; the algorithm can fail on extended-based systems only when1.0+xis evaluated to extended double precision in one instance and to single or double precision in another. Of course, sincelogis a generic intrinsic function in Fortran, a compiler could evaluate the expression1.0+xin extended precision throughout, computing its logarithm in the same precision, but evidently we cannot assume that the compiler will do so. (One can also imagine a similar example involving a user-defined function. In that case, a compiler could still keep the argument in extended precision even though the function returns a single precision result, but few if any existing Fortran compilers do this, either.) We might therefore attempt to ensure that1.0+xis evaluated consistently by assigning it to a variable. Unfortunately, if we declare that variablereal, we may still be foiled by a compiler that substitutes a value kept in a register in extended precision for one appearance of the variable and a value stored in memory in single precision for another. Instead, we would need to declare the variable with a type that corresponds to the extended precision format. Standard FORTRAN 77 does not provide a way to do this, and while Fortran 95 offers theSELECTED_REAL_KINDmechanism for describing various formats, it does not explicitly require implementations that evaluate expressions in extended precision to allow variables to be declared with that precision. In short, there is no portable way to write this program in standard Fortran that is guaranteed to prevent the expression1.0+xfrom being evaluated in a way that invalidates our proof.There are other examples that can malfunction on extended-based systems even when each subexpression is stored and thus rounded to the same precision. The cause is double-rounding. In the default precision mode, an extended-based system will initially round each result to extended double precision. If that result is then stored to double precision, it is rounded again. The combination of these two roundings can yield a value that is different than what would have been obtained by rounding the first result correctly to double precision. This can happen when the result as rounded to extended double precision is a "halfway case", i.e., it lies exactly halfway between two double precision numbers, so the second rounding is determined by the round-ties-to-even rule. If this second rounding rounds in the same direction as the first, the net rounding error will exceed half a unit in the last place. (Note, though, that double-rounding only affects double precision computations. One can prove that the sum, difference, product, or quotient of two p-bit numbers, or the square root of a p-bit number, rounded first to q bits and then to p bits gives the same value as if the result were rounded just once to p bits provided q
Some algorithms that depend on correct rounding can fail with double-rounding. In fact, even some algorithms that don't require correct rounding and work correctly on a variety of machines that don't conform to IEEE 754 can fail with double-rounding. The most useful of these are the portable algorithms for performing simulated multiple precision arithmetic mentioned in the section Exactly Rounded Operations. For example, the procedure described in Theorem 6 for splitting a floating-point number into high and low parts doesn't work correctly in double-rounding arithmetic: try to split the double precision number 252 + 3 × 226 - 1 into two parts each with at most 26 bits. When each operation is rounded correctly to double precision, the high order part is 252 + 227 and the low order part is 226 - 1, but when each operation is rounded first to extended double precision and then to double precision, the procedure produces a high order part of 252 + 228 and a low order part of -226 - 1. The latter number occupies 27 bits, so its square can't be computed exactly in double precision. Of course, it would still be possible to compute the square of this number in extended double precision, but the resulting algorithm would no longer be portable to single/double systems. Also, later steps in the multiple precision multiplication algorithm assume that all partial products have been computed in double precision. Handling a mixture of double and extended double variables correctly would make the implementation significantly more expensive.
Likewise, portable algorithms for adding multiple precision numbers represented as arrays of double precision numbers can fail in double-rounding arithmetic. These algorithms typically rely on a technique similar to Kahan's summation formula. As the informal explanation of the summation formula given on Errors In Summation suggests, if
sandyare floating-point variables with |s|y| and we compute:
then in most arithmetics,
erecovers exactly the roundoff error that occurred in computingt. This technique doesn't work in double-rounded arithmetic, however: ifs= 252 + 1 andy= 1/2 - 2-54, thens+yrounds first to 252 + 3/2 in extended double precision, and this value rounds to 252 + 2 in double precision by the round-ties-to-even rule; thus the net rounding error in computingtis 1/2 + 2-54, which is not representable exactly in double precision and so can't be computed exactly by the expression shown above. Here again, it would be possible to recover the roundoff error by computing the sum in extended double precision, but then a program would have to do extra work to reduce the final outputs back to double precision, and double-rounding could afflict this process, too. For this reason, although portable programs for simulating multiple precision arithmetic by these methods work correctly and efficiently on a wide variety of machines, they do not work as advertised on extended-based systems.Finally, some algorithms that at first sight appear to depend on correct rounding may in fact work correctly with double-rounding. In these cases, the cost of coping with double-rounding lies not in the implementation but in the verification that the algorithm works as advertised. To illustrate, we prove the following variant of Theorem 7:
Theorem 7'
- If m and n are integers representable in IEEE 754 double precision with |m| < 252 and n has the special form n = 2i + 2j, then (m
n)
Proof
Assume without loss that m > 0. Let q = m
n. Scaling by powers of two, we can consider an equivalent setting in which 252
Let e denote the rounding error in computing q, so that q = m/n + e, and the computed value q
In double-rounding arithmetic, it may still happen that q is the correctly rounded quotient (even though it was actually rounded twice), so |e| < 1/2 as above. In this case, we can appeal to the arguments of the previous paragraph provided we consider the fact that q
Finally, we are left to consider cases in which q is not the correctly rounded quotient due to double-rounding. In these cases, we have |e| < 1/2 + 2-(d + 1) in the worst case, where d is the number of extra bits in the extended double format. (All existing extended-based systems support an extended double format with exactly 64 significant bits; for this format, d = 64 - 53 = 11.) Because double-rounding only produces an incorrectly rounded result when the second rounding is determined by the round-ties-to-even rule, q must be an even integer. Thus if n has the form 1/2 + 2-(k + 1), then ne = nq - m is an integer multiple of 2-k, and
|ne| < (1/2 + 2-(k + 1))(1/2 + 2-(d + 1)) = 1/4 + 2-(k + 2) + 2-(d + 2) + 2-(k + d + 2).
If k
|ne| < 1/2 + 2-(k + 1) + 2-(d + 1) + 2-(k + d + 1).
If k
The preceding proof shows that the product can incur double-rounding only if the quotient does, and even then, it rounds to the correct result. The proof also shows that extending our reasoning to include the possibility of double-rounding can be challenging even for a program with only two floating-point operations. For a more complicated program, it may be impossible to systematically account for the effects of double-rounding, not to mention more general combinations of double and extended double precision computations.
Programming Language Support for Extended Precision
The preceding examples should not be taken to suggest that extended precision per se is harmful. Many programs can benefit from extended precision when the programmer is able to use it selectively. Unfortunately, current programming languages do not provide sufficient means for a programmer to specify when and how extended precision should be used. To indicate what support is needed, we consider the ways in which we might want to manage the use of extended precision.
In a portable program that uses double precision as its nominal working precision, there are five ways we might want to control the use of a wider precision:
- Compile to produce the fastest code, using extended precision where possible on extended-based systems. Clearly most numerical software does not require more of the arithmetic than that the relative error in each operation is bounded by the "machine epsilon". When data in memory are stored in double precision, the machine epsilon is usually taken to be the largest relative roundoff error in that precision, since the input data are (rightly or wrongly) assumed to have been rounded when they were entered and the results will likewise be rounded when they are stored. Thus, while computing some of the intermediate results in extended precision may yield a more accurate result, extended precision is not essential. In this case, we might prefer that the compiler use extended precision only when it will not appreciably slow the program and use double precision otherwise.
- Use a format wider than double if it is reasonably fast and wide enough, otherwise resort to something else. Some computations can be performed more easily when extended precision is available, but they can also be carried out in double precision with only somewhat greater effort. Consider computing the Euclidean norm of a vector of double precision numbers. By computing the squares of the elements and accumulating their sum in an IEEE 754 extended double format with its wider exponent range, we can trivially avoid premature underflow or overflow for vectors of practical lengths. On extended-based systems, this is the fastest way to compute the norm. On single/double systems, an extended double format would have to be emulated in software (if one were supported at all), and such emulation would be much slower than simply using double precision, testing the exception flags to determine whether underflow or overflow occurred, and if so, repeating the computation with explicit scaling. Note that to support this use of extended precision, a language must provide both an indication of the widest available format that is reasonably fast, so that a program can choose which method to use, and environmental parameters that indicate the precision and range of each format, so that the program can verify that the widest fast format is wide enough (e.g., that it has wider range than double).
- Use a format wider than double even if it has to be emulated in software. For more complicated programs than the Euclidean norm example, the programmer may simply wish to avoid the need to write two versions of the program and instead rely on extended precision even if it is slow. Again, the language must provide environmental parameters so that the program can determine the range and precision of the widest available format.
- Don't use a wider precision; round results correctly to the precision of the double format, albeit possibly with extended range. For programs that are most easily written to depend on correctly rounded double precision arithmetic, including some of the examples mentioned above, a language must provide a way for the programmer to indicate that extended precision must not be used, even though intermediate results may be computed in registers with a wider exponent range than double. (Intermediate results computed in this way can still incur double-rounding if they underflow when stored to memory: if the result of an arithmetic operation is rounded first to 53 significant bits, then rounded again to fewer significant bits when it must be denormalized, the final result may differ from what would have been obtained by rounding just once to a denormalized number. Of course, this form of double-rounding is highly unlikely to affect any practical program adversely.)
- Round results correctly to both the precision and range of the double format. This strict enforcement of double precision would be most useful for programs that test either numerical software or the arithmetic itself near the limits of both the range and precision of the double format. Such careful test programs tend to be difficult to write in a portable way; they become even more difficult (and error prone) when they must employ dummy subroutines and other tricks to force results to be rounded to a particular format. Thus, a programmer using an extended-based system to develop robust software that must be portable to all IEEE 754 implementations would quickly come to appreciate being able to emulate the arithmetic of single/double systems without extraordinary effort.
No current language supports all five of these options. In fact, few languages have attempted to give the programmer the ability to control the use of extended precision at all. One notable exception is the ISO/IEC 9899:1999 Programming Languages - C standard, the latest revision to the C language, which is now in the final stages of standardization.
The C99 standard allows an implementation to evaluate expressions in a format wider than that normally associated with their type, but the C99 standard recommends using one of only three expression evaluation methods. The three recommended methods are characterized by the extent to which expressions are "promoted" to wider formats, and the implementation is encouraged to identify which method it uses by defining the preprocessor macro
FLT_EVAL_METHOD: ifFLT_EVAL_METHODis 0, each expression is evaluated in a format that corresponds to its type; ifFLT_EVAL_METHODis 1,floatexpressions are promoted to the format that corresponds todouble; and ifFLT_EVAL_METHODis 2,floatanddoubleexpressions are promoted to the format that corresponds tolong double. (An implementation is allowed to setFLT_EVAL_METHODto -1 to indicate that the expression evaluation method is indeterminable.) The C99 standard also requires that the<math.h>header file define the typesfloat_tanddouble_t, which are at least as wide asfloatanddouble, respectively, and are intended to match the types used to evaluatefloatanddoubleexpressions. For example, ifFLT_EVAL_METHODis 2, bothfloat_tanddouble_tarelong double. Finally, the C99 standard requires that the<float.h>header file define preprocessor macros that specify the range and precision of the formats corresponding to each floating-point type.The combination of features required or recommended by the C99 standard supports some of the five options listed above but not all. For example, if an implementation maps the
long doubletype to an extended double format and definesFLT_EVAL_METHODto be 2, the programmer can reasonably assume that extended precision is relatively fast, so programs like the Euclidean norm example can simply use intermediate variables of typelong double(ordouble_t). On the other hand, the same implementation must keep anonymous expressions in extended precision even when they are stored in memory (e.g., when the compiler must spill floating-point registers), and it must store the results of expressions assigned to variables declareddoubleto convert them to double precision even if they could have been kept in registers. Thus, neither thedoublenor thedouble_ttype can be compiled to produce the fastest code on current extended-based hardware.Likewise, the C99 standard provides solutions to some of the problems illustrated by the examples in this section but not all. A C99 standard version of the
log1pfunction is guaranteed to work correctly if the expression1.0+xis assigned to a variable (of any type) and that variable used throughout. A portable, efficient C99 standard program for splitting a double precision number into high and low parts, however, is more difficult: how can we split at the correct position and avoid double-rounding if we cannot guarantee thatdoubleexpressions are rounded correctly to double precision? One solution is to use thedouble_ttype to perform the splitting in double precision on single/double systems and in extended precision on extended-based systems, so that in either case the arithmetic will be correctly rounded. Theorem 14 says that we can split at any bit position provided we know the precision of the underlying arithmetic, and theFLT_EVAL_METHODand environmental parameter macros should give us this information.The following fragment shows one possible implementation:
Of course, to find this solution, the programmer must know that
doubleexpressions may be evaluated in extended precision, that the ensuing double-rounding problem can cause the algorithm to malfunction, and that extended precision may be used instead according to Theorem 14. A more obvious solution is simply to specify that each expression be rounded correctly to double precision. On extended-based systems, this merely requires changing the rounding precision mode, but unfortunately, the C99 standard does not provide a portable way to do this. (Early drafts of the Floating-Point C Edits, the working document that specified the changes to be made to the C90 standard to support floating-point, recommended that implementations on systems with rounding precision modes providefegetprecandfesetprecfunctions to get and set the rounding precision, analogous to thefegetroundandfesetroundfunctions that get and set the rounding direction. This recommendation was removed before the changes were made to the C99 standard.)Coincidentally, the C99 standard's approach to supporting portability among systems with different integer arithmetic capabilities suggests a better way to support different floating-point architectures. Each C99 standard implementation supplies an
<stdint.h>header file that defines those integer types the implementation supports, named according to their sizes and efficiency: for example,int32_tis an integer type exactly 32 bits wide,int_fast16_tis the implementation's fastest integer type at least 16 bits wide, andintmax_tis the widest integer type supported. One can imagine a similar scheme for floating-point types: for example,float53_tcould name a floating-point type with exactly 53 bit precision but possibly wider range,float_fast24_tcould name the implementation's fastest type with at least 24 bit precision, andfloatmax_tcould name the widest reasonably fast type supported. The fast types could allow compilers on extended-based systems to generate the fastest possible code subject only to the constraint that the values of named variables must not appear to change as a result of register spilling. The exact width types would cause compilers on extended-based systems to set the rounding precision mode to round to the specified precision, allowing wider range subject to the same constraint. Finally,double_tcould name a type with both the precision and range of the IEEE 754 double format, providing strict double evaluation. Together with environmental parameter macros named accordingly, such a scheme would readily support all five options described above and allow programmers to indicate easily and unambiguously the floating-point semantics their programs require.Must language support for extended precision be so complicated? On single/double systems, four of the five options listed above coincide, and there is no need to differentiate fast and exact width types. Extended-based systems, however, pose difficult choices: they support neither pure double precision nor pure extended precision computation as efficiently as a mixture of the two, and different programs call for different mixtures. Moreover, the choice of when to use extended precision should not be left to compiler writers, who are often tempted by benchmarks (and sometimes told outright by numerical analysts) to regard floating-point arithmetic as "inherently inexact" and therefore neither deserving nor capable of the predictability of integer arithmetic. Instead, the choice must be presented to programmers, and they will require languages capable of expressing their selection.
Conclusion
The foregoing remarks are not intended to disparage extended-based systems but to expose several fallacies, the first being that all IEEE 754 systems must deliver identical results for the same program. We have focused on differences between extended-based systems and single/double systems, but there are further differences among systems within each of these families. For example, some single/double systems provide a single instruction to multiply two numbers and add a third with just one final rounding. This operation, called a fused multiply-add, can cause the same program to produce different results across different single/double systems, and, like extended precision, it can even cause the same program to produce different results on the same system depending on whether and when it is used. (A fused multiply-add can also foil the splitting process of Theorem 6, although it can be used in a non-portable way to perform multiple precision multiplication without the need for splitting.) Even though the IEEE standard didn't anticipate such an operation, it nevertheless conforms: the intermediate product is delivered to a "destination" beyond the user's control that is wide enough to hold it exactly, and the final sum is rounded correctly to fit its single or double precision destination.
The idea that IEEE 754 prescribes precisely the result a given program must deliver is nonetheless appealing. Many programmers like to believe that they can understand the behavior of a program and prove that it will work correctly without reference to the compiler that compiles it or the computer that runs it. In many ways, supporting this belief is a worthwhile goal for the designers of computer systems and programming languages. Unfortunately, when it comes to floating-point arithmetic, the goal is virtually impossible to achieve. The authors of the IEEE standards knew that, and they didn't attempt to achieve it. As a result, despite nearly universal conformance to (most of) the IEEE 754 standard throughout the computer industry, programmers of portable software must continue to cope with unpredictable floating-point arithmetic.
If programmers are to exploit the features of IEEE 754, they will need programming languages that make floating-point arithmetic predictable. The C99 standard improves predictability to some degree at the expense of requiring programmers to write multiple versions of their programs, one for each
1 Examples of other representations are floating slash and signed logarithm [Matula and Kornerup 1985; Swartzlander and Alexopoulos 1975]. 2 This term was introduced by Forsythe and Moler [1967], and has generally replaced the older term mantissa. 3 This assumes the usual arrangement where the exponent is stored to the left of the significand. 4 Unless the number z is larger thanFLT_EVAL_METHOD. Whether future languages will choose instead to allow programmers to write a single program with syntax that unambiguously expresses the extent to which it depends on IEEE 754 semantics remains to be seen. Existing extended-based systems threaten that prospect by tempting us to assume that the compiler and the hardware can know better than the programmer how a computation should be performed on a given system. That assumption is the second fallacy: the accuracy required in a computed result depends not on the machine that produces it but only on the conclusions that will be drawn from it, and of the programmer, the compiler, and the hardware, at best only the programmer can know what those conclusions may be.+1 or smaller than
. Numbers which are out of range in this fashion will not be considered until further notice. 5 Let z' be the floating-point number that approximates z. Then
or
. In this case, (x - y)(x + y) has three rounding errors, but x2 - y2 has only two since the rounding error committed when computing the smaller of x2 and y2 does not affect the final subtraction. 8 Also commonly referred to as correctly rounded. - Ed. 9 When n = 845, xn= 9.45, xn + 0.555 = 10.0, and 10.0 - 0.555 = 9.45. Therefore, xn = x845 for n > 845. 10 Notice that in binary, q cannot equal
. - Ed. 11 Left as an exercise to the reader: extend the proof to bases other than 2. - Ed. 12 This appears to have first been published by Goldberg [1967], although Knuth ([1981], page 211) attributes this idea to Konrad Zuse.
13 According to Kahan, extended precision has 64 bits of significand because that was the widest precision across which carry propagation could be done on the Intel 8087 without increasing the cycle time [Kahan 1988].
14 Some arguments against including inner product as one of the basic operations are presented by Kahan and LeBlanc [1985]. 15 Kirchner writes: It is possible to compute inner products to within 1 ulp in hardware in one partial product per clock cycle. The additionally needed hardware compares to the multiplier array needed anyway for that speed.
16 CORDIC is an acronym for Coordinate Rotation Digital Computer and is a method of computing transcendental functions that uses mostly shifts and adds (i.e., very few multiplications and divisions) [Walther 1971]. It is the method additionally needed hardware compares to the multiplier array needed anyway for that speed. d used on both the Intel 8087 and the Motorola 68881.
17 Fine point: Although the default in IEEE arithmetic is to round overflowed numbers to
20 No invalid exception is raised unless a "trapping" NaN is involved in the operation. See section 6.2 of IEEE Std 754-1985. - Ed. 21may be greater than
if both x and y are negative. - Ed. 22 It can be in range because if x < 1, n < 0 and x-n is just a tiny bit smaller than the underflow threshold
, then
, and so may not overflow, since in all IEEE precisions, -emin < emax. 23 This is probably because designers like "orthogonal" instruction sets, where the precisions of a floating-point instruction are independent of the actual operation. Making a special case for multiplication destroys this orthogonality. 24 This assumes the common convention that
3.0is a single-precision constant, while3.0D0is a double precision constant. 25 The conclusion that 00 = 1 depends on the restriction that f be nonconstant. If this restriction is removed, then letting f be the identically 0 function gives 0 as a possible value for lim x
27 Unless the rounding mode is round toward -CALLSandCALLGinstructions. 29 The difficulty with presubstitution is that it requires either direct hardware implementation, or continuable floating-point traps if implemented in software. - Ed. 30 In this informal proof, assume that
|
Sun Microsystems, Inc. Copyright information. All rights reserved. Feedback |
Library | Contents | Previous | Next | Index |