|
|
| Sun ONE Application Server 7, Update 1 Administrator's Guide |
Configuring Naming and ResourcesThis module describes the J2EE Resources used by Sun ONE Application Server and discusses the methods used to create and manage these resources:
This module includes the following topics:
- About J2EE Naming Services and Resources
- About Java Naming and Directory Interface (JNDI)
- About Persistence Manager Resources
- About JDBC Resources
- About Java Mail Resources
About J2EE Naming Services and Resources
J2EE applications including EJBs, web application components and application clients may access a wide variety of resources such as resource managers, data sources (for example SQL datasources), connection factories, mail sessions, Java Message Service destination objects, and URL connection factories. The J2EE platform exposes such resources to the applications via Java Naming and Directory (JNDI) naming service.
Sun ONE Application Server allows you to create and manage the following J2EE resources:
JDBC Datasources
A JDBC Datasource is a J2EE resource that you can create and manage using Sun ONE Application Server.
The JDBC API is the API for connectivity with relational database systems. The JDBC API has two parts:
- An application-level interface used by the application components to access databases.
- A service provider interface to attach a JDBC driver to the J2EE platform.
A JDBC DataSource object is the representation of a data source in the Java programming language. In basic terms, a data source is a facility for storing data. It can be as sophisticated as a complex database for a large corporation or as simple as a file with rows and columns. A JDBC Datasource is a J2EE resource that can be created and managed via Sun ONE Application Server.
For more information on JDBC Datasources, see "About JDBC Resources".
Java Mail Sessions
JMS destinations are J2EE resources that can be created and managed via Sun ONE Application Server.
Many internet applications require the ability to send email notifications, so the J2EE platform includes the JavaMail API along with a JavaMail service provider that allows an application component to send internet mail. The JavaMail API has two parts:
- An application-level interface used by the application components to send mail
- A service provider interface used at the J2EE SPI level.
Java Mail Sessions are J2EE resources that can be created and managed via Sun ONE Application Server. For more information on Java Mail Sessions, see "About Java Mail Resources".
JMS Destinations
Java Messaging Service (JMS) is a standard API for messaging that supports reliable point-to-point messaging as well as the publish-subscribe model. This specification requires a JMS provider that implements both point-to-point messaging and publish-subscribe messaging.
JMS provides for two general types of administered objects: connection factories and destinations. While both encapsulate provider-specific information, they have very different uses within a JMS client. A connection factory is used to create connections to a message server, and destination objects are used to identify physical destinations used by the JMS messaging service.
About Java Naming and Directory Interface (JNDI)
This section discusses the Java Naming and Directory Interface (JNDI). Java Naming and Directory Interface (JNDI) is an application programming interface (API) for accessing different kinds of naming and directory services. J2EE components locate objects by invoking the JNDI lookup method.
This section covers the following topics:
- JNDI Architecture
- J2EE Naming Services
- Naming References and Binding Information
- Naming References in J2EE Standard Deployment Descriptor
- JNDI Connection Factories
JNDI Architecture
The JNDI architecture consists of an Application Programmer's Interface (API) and a Service Provider Interface (SPI). Java applications use the JNDI API to access a variety of naming and directory services. The SPI enables a variety of naming and directory services to be plugged in transparently, thereby allowing the Java application using the JNDI API to access their services. The following figure, "Overview of the JNDI Architecture," illustrates the services than can be accessed through the JNDI API:
Overview of the JNDI Architecture
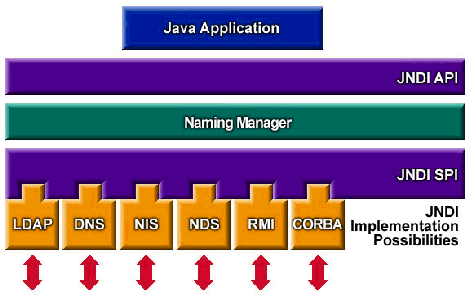
J2EE Naming Services
A JNDI name is a people-friendly name for an object. These names are bound to their objects by the naming and directory service that is provided by a J2EE server. Because J2EE components access this service through the JNDI API, we usually refer to an object's people-friendly name as its JNDI name. The JNDI name of the Pointbase database is jdbc/Pointbase. When it starts up, Sun ONE Application Server reads information from configuration file and automatically adds JNDI database names to the name space.
J2EE application clients, enterprise beans, and web components are required to have access to a JNDI naming environment.
The application component's naming environment is a mechanism that allows customization of the application component's business logic during deployment or assembly. Use of the application component's environment allows the application component to be customized without the need to access or change the application component's source code.
A J2EE container implements the application component's environment, and provides it to the application component instance as a JNDI naming context. The application component's environment is used as follows:
- The application component's business methods access the environment using the JNDI interfaces. The application component provider declares in the deployment descriptor all the environment entries that the application component expects to be provided in its environment at runtime.
- The container provides an implementation of the JNDI naming context that stores the application component environment. The container also provides the tools that allow the deployer to create and manage the environment of each application component.
- A deployer uses the tools provided by the container to initialize the environment entries that are declared in the application component's deployment descriptor. The deployer can set and modify the values of the environment entries.
- The container makes the environment naming context available to the application component instances at runtime. The application component's instances use the JNDI interfaces to obtain the values of the environment entries.
Each application component defines its own set of environment entries. All instances of an application component within the same container share the same environment entries. Application component instances are not allowed to modify the environment at runtime. For more information on how J2EE containers such as the Web Container and EJB Containers use the JNDI naming service to look up objects, please see "Configuring J2EE Containers".
Naming References and Binding Information
A resource reference is an element in a deployment descriptor that identifies the component's coded name for the resource. More specifically, the coded name references a connection factory for the resource. In the example given in the following section, the resource reference name is jdbc/SavingsAccountDB.
The JNDI name of a resource and the name of the resource reference are not the same. This approach to naming requires that you map the two names before deployment, but it also decouples components from resources. Because of this de-coupling, if at a later time the component needs to access a different resource, you don't have to change the name in the code. This flexibility also makes it easier for you to assemble J2EE applications from preexisting components.
The following table, "JNDI Lookups and Their Associated References," lists JNDI lookups and their associated references for the J2EE resources used by Sun ONE Application Server.
Naming References in J2EE Standard Deployment Descriptor
A naming reference is a string used by the application to look up an object in the given naming context. For each J2EE application, there is a naming context and the references are configured in the standard component deployment descriptors.This section describes the standard deployment descriptor features used in Sun ONE Application Server. This section covers the following topics:
- Application Environment Entries
- EJB References
- References to Resource Manager Connection Factories
- Resource Environment References
- UserTransaction References
- COSNaming Service
Application Environment Entries
Environment entries, defined using <env-entry>, provide a way of specifying deployment time parameters to J2EE applications. Note that in case of web applications, the servlet context initialization parameters could be defined using <context-param>, but <env-entry> is the preferred way because application deployers to configure such applications parameters by explicitly specifying the name, type and values for them.
The following sample describes the syntax of <env-entry> as specified in the J2EE standard deployment descriptors:
<env-entry>
<description> Send pincode by mail </description>
<env-entry-name> mailPincode </env-entry-name>
<env-entry-value> false </env-entry-value>
<env-entry-type> java.lang.Boolean </env-entry-type>
</env-entry>The <env-entry-type> tag specifies a fully qualified class name for the entry. Here is a code snippet to lookup the <env-entry> using JNDI from an application component (a term referring to a servlet/JSP or an entity bean or an IIOP application client):
Context initContext = new InitialContext();
Boolean mailPincode = (Boolean)
initContext.lookup("java:comp/env/mailPincode");// one could use relative names into the sub-context
Context envContext = initContext.lookup("java:comp/env");
Boolean mailPincode = (Boolean)
envContext.lookup("mailPincode");EJB References
Apart from deployment descriptor support, the JNDI naming service enables applications to use "logical" names (called EJB references) to map to the home interfaces of enterprise beans, as described in the following example:
<ejb-ref>
<ejb-ref-name> ejb/EmplRecord </ejb-ref-name>
<ejb-ref-type> Entity </ejb-ref-type>
<home> com.wombat.empl.EmployeeRecordHome </home>
<remote> com.wombat.empl.EmployeeRecord </remote>
<ejb-link> EmployeeEJB </ejb-link>
</ejb-ref>An application component such as a JSP could access the EJB home object using JNDI, as described in the following example:
Context initContext = new InitialContext();
Context envContext = initContext.lookup("java:comp/env");
Object result = envContext.lookup("ejb/EmplRecord");
EmployeeRecordHome emplRecordHome = (EmployeeRecordHome)
javax.rmi.PortableRemoteObject.narrow(result, EmployeeRecordHome.class);The ejb-ref-name element defines the string used in the application code (as in the above given example). The ejb-link element links this reference to target enterprise bean defined using the ejb-name element of the entity bean defined in the ejb-jar.xml. It is also possible to provide the linkage without modifying either the application deployment descriptor or the enterprise bean descriptor.
References to Resource Manager Connection Factories
A factory is an object that creates other objects on demand. A resource factory creates resource objects, such as database connections or message service connections. They are configured using <resource-ref> element in the standard deployment descriptors.
The following examples describe the use of factories:
Example A:
Declaration of a reference to a JDBC connection factory that returns objects of type javax.sql.DataSource:
<resource-ref>
<description> Primary database </description>
<res-ref-name> jdbc/primaryDB </res-ref-name>
<res-type> javax.sql.DataSource </res-type>
<res-auth> Container </res-auth>
</resource-ref>Example B:
Here is an example reference to JavaMail Session resource factory:
<resource-ref>
<description> mail Session </description>
<res-ref-name> mail/Session </res-ref-name>
<res-type> javax.mail.Session </res-type>
<res-auth> Container </res-auth>
</resource-ref><res-type> is a fully-qualified class name of the resource factory. The <res-auth> variable can be assigned either Container or Application as a value. To know more about configuring Java Mail session resource factories, please see "About Java Mail Resources".
If Container is specified, the web container handles the authentication before binding the resource factory to JNDI lookup registry. If Application is specified, the servlet must handle authentication programmatically. Different resource factories are looked up under a separate sub-context that describes the resource type, follows:
- jdbc/ for a JDBC javax.sql.DataSource factory
- jms/ for a JMS javax.jms.QueueConnectionFactory or javax.jms.TopicConnectionFactory
- mail/ for a JavaMail javax.mail.Session factory
- url/ for a java.net.URL factory
Here is a code snippet to get JDBC connection from an application component with the container handling the authentication:
InitialContext initContext = new InitialContext();
DataSource source =
(DataSource) initContext.lookup("java:comp/env/jdbc/primaryDB");
Connection conn = source.getConnection();Please note that in order to ensure that for these resource references work, the res-ref-name must map to valid resource factory at runtime.
Resource Environment References
Resource environment references provide a way of accessing, via JNDI lookups, administered objects associated with a resource. For example, an application may need to access a JMS Destination object. The <resource-env-ref> element, defined in the standard deployment descriptors lets applications declare the resource requirements.
The main difference between <resource-env-ref> and <resource-ref> element is the absence of specific resource authentication requirement; both these elements have to be backed up by a resource factory descriptor.
Example:
<resource-env-ref>
<description> My Topic </description>
<res-env-ref-name> jms/MyTopic </res-ref-name>
<res-env-ref-type> javax.jms.Topic </res-type>
</resource-env-ref>The following piece of code allows you to access a JMS Topic object:
InitialContext initContext = new InitialContext();
javax.jms.Topic myTopic =
(javax.jms.Topic) initContext.lookup("java:comp/env/jms/MyTopic");Note that in order these resource-env-ref variables to work, the administrators will have to make target resource factories available at run-time. For more information about accessing JMS Topics and Queue destinations, see "Using the JMS Service."
UserTransaction References
J2EE requires that containers provide a UserTransaction object implementation at the JNDI name java:comp/UserTransaction. A UserTransaction object lets applications to start, commit and abort transactions.
To programmatically initiate and perform transactions, components obtain reference to the container's default transaction co-ordinator, by doing a JNDI lookup for java:comp/UserTransaction. The returned object implements javax.transaction.UserTransaction interface and can be used in the program to begin, commit, rollback and query status of transactions. JNDI implementation in Sun ONE Application Server supports such lookup of the transaction co-ordinator. For more information about the javax.transaction.UserTransaction interface, see "Using Transaction Services".
Initial Naming Context
The naming support in Sun ONE Application Server is based primarily on J2EE 1.3, with a few added enhancements.When an application component creates the initial context, via InitialContext(), Sun ONE Application Server returns an object that serves as a handle to the application's naming environment. This object in turn provides sub-contexts for the java:comp/env namespace. Each application gets its own namespace, that is, java:comp/env name space is per application and objects bound in one application's namespace don't collide with objects bound in other applications.
COSNaming Service
The EJB interoperability protocol requires the use of the COSNaming protocol for lookup of EJB objects using the JNDI API.
EJB containers are required to be able to publish EJBHome object references in a CORBA CosNaming service. The CosNaming service must implement the IDL interfaces in the CosNaming module defined, and allow clients to invoke the resolve and list operations over IIOP.
The CosNaming service must follow the requirements in the CORBA Interoperable Name Service specification for providing the host, port and object key for its root NamingContext object. The CosNaming service must be able to service IIOP invocations on the root NamingContext at the advertised host, port and object key.
Client containers (that is, EJB, web or application client containers) are required to include a JNDI CosNaming service provider that uses the mechanisms defined in the Interoperable Name Service specification to contact the server's CosNaming service and to resolve the EJBHome object using standard CosNaming APIs. The JNDI CosNaming service provider may or may not use the JNDI SPI architecture. The JNDI CosNaming service provider must access the root NamingContext of the server's CosNaming service by creating an object reference from the following URL:
corbaloc:iiop:1.2@<host>:<port>/<objectkey> (where <host>, <port>, and <objectkey> are the values corresponding to the root NamingContext advertised by the server's CosNaming Service), or by using an equivalent mechanism.
At deployment time, the developer of the client container should obtain the host, port and object key of the server's CosNaming service and the CosNaming name of the server EJBHome object (for example, by browsing the server's namespace) for each ejb-ref element in the client components's deployment descriptor. The ejb-ref-name (which is used by the client code in the JNDI lokup call) should then be linked to the EJBHome object's CosNaming name. At runtime, the client component's JNDI lookup call uses the CosNaming service provider, which contacts the server's CosNaming service, resolves the CosNaming name, and returns the EJBHome object reference to the client component.
Since the EJBHome object's name is scoped within the namespace of the CosNaming service that is accessible at the provided host and port, it is not necessary to federate the namespaces of the client and server containers.
The advantage of using CosNaming is better integration with the IIOP infrastructure that is already required for inter operability, as well as inter operability with non-J2EE CORBA clients and servers. Since CosNaming stores only CORBA objects it is likely that vendors will use other enterprise directory services for storing other resources.
Sun ONE Application Server incorporates all the naming resources of JNDI, based on the J2EE 1.3 specification.
CosNaming provider.To support a global JNDI namespace (accessible to IIOP application clients), Sun ONE Application Server includes J2EE based CosNaming provider which supports binding of CORBA references (remote EJB references). The InitialContext returned to the IIOP clients is a CosNaming provider. An instance of Sun ONE Application Server server registers the entity beans for the IIOP clients to lookup and bind to.
Note that Sun ONE Application Server treats objects stored in CosNaming and the local JNDI naming environment are transient: that is, on each server startup as well as application reloading, all relevant objects are rebound to the namespace again. To know more about configuring support for CORBA/IIOP clients, see "Configuring the Server For Corba/IIOP Clients".
JNDI Connection Factories
For J2EE web applications, the deployment descriptor in the web.xml file is the placeholder for defining references to application environment entries, resource manager (such as SQL Data Source) connection factories, or EJBs. Applications look up such references using the JNDI InitialNamingContext provided by the J2EE containers. This makes applications portable to different application server environments by just making changes to the deployment descriptor, that is, without accessing or modifying the application's source code. Likewise, J2EE requires the deployment descriptors for entity beans (ejb-jar.xml) as well as the IIOP application clients (application-client.xml) to be the primary vehicles for these JNDI naming references.
A connection factory is an object that produces connection objects that enable a J2EE component to access a resource. The connection factory for a database is a javax.sql.DataSource object, which creates a java.sql.Connection object.
In Sun ONE Application Server, you can configure the means of accessing the following resources and resource factories:
- JDBC connection factories
- JMS Connection factories based on MQ
- JavaMail Session connection factories
- JCA Connector factories
- Generic, custom user-written resource object factories.
- Support for external resource repositories such as LDAP
All Sun ONE Application Server resource factories are specified within the <resources> </resources> tags in server.xml and have a JNDI name specified using the jndi-name attribute. This attribute is used to register the factory in the server-wide namespace. Deployers can map user-specified, application-specific resource reference names (declared within resource-ref or resource-env-ref elements) to these server-wide resource factories using the resource-ref-mapping element. This enables deployment time decisions to be made with regards to which JDBC drivers (and other resource factories) to use for a given application.
A custom resource accesses a local JNDI repository and an external resource accesses an external JNDI repository. Both types of resources need user-specified factory class elements, JNDI name attributes, etc. In this section, we will discuss how to configure JNDI connection factory resources, for J2EE resources, and how to access these resources.
The following topics are covered in this section:
- To Create a Custom Resource
- To Create an External JNDI Resource
- Accessing External JNDI Repositories
- Mapping Application Resource References
- About URL Connection Factory Resources
- Mapping Application Resource Environment References
- Mapping EJB References
To Create a Custom Resource
The custom-resource element defined in server.xml provides a way of specifying a custom server-wide resource object factory. Such object factories implement the javax.naming.spi.ObjectFactory interface. This element associates a JNDI name (specified through the jndi-name sub-element like other Sun ONE Application Server resources) to be used in the server-wide namespace, its type, name of the resource factory class and a set of standard properties used to instantiate the same.
The following example illustrates the implementation of the javax.naming.spi.ObjectFactory interface:
<resources> <custom-resource jndi-name="test/myBean"
res-type="test.MyBean"factory-class="test.MyBeanFactory"
enabled="true"><property name="foo" value="test custom bean prop" />
</custom-resource>
</resources>You need to ensure that the resource reference's environment references and EJB references are linked to the configured server-wide resources defined using the custom-resource and external-jndi-resource tags in server.xml. Dynamic redeployment of application components is an issue for the JNDI naming environment. Sun ONE Application Server will release all the application specific references and rebind all the new references into the newly installed application's naming context.
To create a custom resource using the Administration interface:
- In the left pane of the Administration interface, open the Sun ONE Application Server instance whose JNDI configuration you want to modify.
- Open the JNDI tab and click Custom Resources. If any custom resources have been created already, they will be listed in the right pane. To create a new custom resource, click New. You will see the "JNDI Custom Resources Page" in the right pane of the Administration interface:
JNDI Custom Resources Page
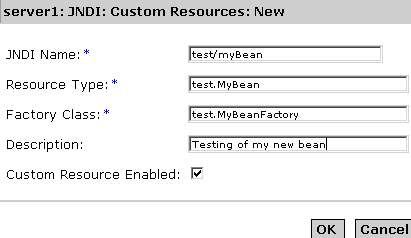
- In the JNDI Name field, enter the name that is to be used to access the resource. This name will be registered in the JNDI naming service.
- In the Resource Type field, enter a fully qualified type definition, as shown in the example above. Your Resource Type definition should follow this format: xxx.xxx.
- In the Factory Class field, enter a factory class name for the custom resource you are creating. The Factory Class is the user-specified name for the factory class. This class implements the javax.naming.spi.ObjectFactory interface.
- In the Description field, enter a description for the resource you're creating. This description is a string value and can comprise a maximum of 250 characters.
- Mark the Custom Resource Enabled checkbox, to enable the custom resource.
- Click OK to save your custom resource.
To Create an External JNDI Resource
To create an external resource using the Administration interface:
- In the left pane of the Administration interface, open the Sun ONE Application Server instance whose JNDI configuration you want to modify.
- Open JNDI and select External Resources. If any external resources have been created already, they will be listed in the right pane. To create a new external resource, click New.
You will see the following window, shown in the "JNDI External Resources Page" in the right pane of the Administration interface:
JNDI External Resources Page
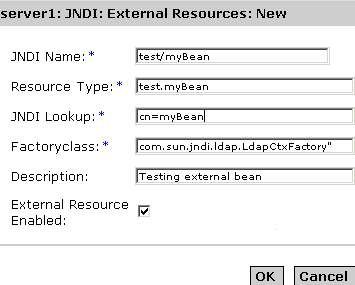
- In the JNDI Name field, enter the name that is to be used to access the resource. This name will be registered in the JNDI naming service.
- In the Resource Type field, enter a fully qualified type definition, as shown in the example above. Your Resource Type definition should follow this format: xxx.xxx.
- In the JNDI Lookup field, enter the JNDI value to look up in the external repository. For example, if you are creating an external resource to connect to an external repository, to test a bean class, your JNDI Lookup could read cn=testmybean.
- In the Factory Class field, enter a JNDI factory class external repository, for example, com.sun.jndi.ldap. This class implements the javax.naming.spi.ObjectFactory interface.
- In the Description field, enter a description for the resource you're creating. This description is a string value and can comprise a maximum of 250 characters.
- Mark the External Resource Enabled checkbox, to enable the external resource.
- Click OK to save your custom resource.
Accessing External JNDI Repositories
Often applications running on Sun ONE Application Server require access to resources stored in an external JNDI repository. For example, generic Java objects could be stored in an LDAP server as per the Java schema. External JNDI resource elements let users configure such external resource repositories. The external JNDI factory must implement javax.naming.spi.InitialContextFactory interface.
Example:
<resources>
<!-- external-jndi-resource element specifies how to access J2EE resources
-- stored in an external JNDI repository. The following example
-- illustrates how to access a java object stored in LDAP.
-- factory-class element specifies the JNDI InitialContext factory that
-- needs to be used to access the resource factory. property element
-- corresponds to the environment applicable to the external JNDI context
-- and jndi-lookup-name refers to the JNDI name to lookup to fetch the
-- designated (in this case the java) object.
-->
<external-jndi-resource jndi-name="test/myBean"
jndi-lookup-name="cn=myBean"
res-type="test.myBean"
factory-class="com.sun.jndi.ldap.LdapCtxFactory"><property name="PROVIDER-URL" value="ldap://ldapserver:389/o=myObjects" />
<property name="SECURITY_AUTHENTICATION" value="simple" />
<property name="SECURITY_PRINCIPAL", value="cn=joeSmith, o=Engineering" />
<property name="SECURITY_CREDENTIALS" value="changeit" />
</external-jndi-resource>
</resources>Mapping Application Resource References
Application-specific resource references must be mapped to pre-defined server-wide resource factories. The Sun ONE Application Server specific resource reference mapping element is used for this.
In the following example, we look at a web application's deployment descriptor web.xml where a resource reference is specified to a JDBC DataSource.
<resource-ref>
<res-ref-name> jdbc/EstoreDataSource </res-ref-name>
<res-type> javax.sql.DataSource </res-type>
<res-auth> Container </res-auth>
</resource-ref>The desired res-ref-name can also be mapped to the container-wide Orcale JDBC connection resource factory, as follows:
<resource-ref>
<res-ref-name> jdbc/EstoreDataSource </resource-ref-name>
<jndi-name> jdbc/estore/InventoryDB </jndi-name>
</resource-ref>About URL Connection Factory Resources
URL connection factories do not require any resource to be defined in server.xml. The jndi-name element of the corresponding Sun ONE Application Server application (web or ejb) deployment descriptor specifies the target URL.
For example, let us assume that a web application's deployment descriptor web.xml specifies a java.net.URL resource reference and this is mapped to the URL http://www.sun.com/index.html in sun-web.xml:
The mapping would be as follows:
<resource-ref>
<res-ref-name>myURL</res-ref-name>
<res-type>java.net.URL</res-type>
<res-auth>Container</res-auth>
</resource-ref><sun-web-app>
<resource-ref>
<res-ref-name>myURL</res-ref-name>
<jndi-name> http://www.sun.com/index.html </jndi-name>
</resource-ref>
</sun-web-app>Mapping Application Resource Environment References
Application-specific resource environment reference declarations must be mapped to target resource objects available in the application server's runtime environment. The resource environment mapping element defined in the Sun ONE Application Server-specific configuration file lets deployers map as follows:
Example:
<resource-env-ref>
<description> My Topic </description>
<res-env-ref-name> jms/MyTopic </res-ref-name>
<res-env-ref-type> javax.jms.Topic </res-type>
</resource-env-ref>This reference is mapped to the jms/iMQ/Topics/Stocks/SUNW topic defined in server.xml. See the Sun ONE Application Server Administrator's Configuration File Reference for more information.
<resource-env-ref-mapping>
<res-env-ref-name> jms/MyTopic </res-ref-name>
<jndi-name> jms/iMQ/Topics/Stocks/SUNW </jndi-name>
</resource-env-ref-mapping>Mapping EJB References
It's also possible to decouple the actual ejb-name used in the application code from the ejb-name used for the target enterprise bean. This is particularly useful when you do not want to modify the web application deployment descriptor, web.xml and use the ejb-name of the enterprise bean deployment descriptor. The Sun ONE Application Server specific configuration allows you to map the ejb-ref-name element to the target bean's ejb-name without using the ejb-ref-mapping element in the Sun ONE Application Server specific deployment descriptor.
Example:
<ejb-ref>
<ejb-ref-name> ejb/EmplRecord </ejb-ref-name>
<ejb-ref-type> Entity </ejb-ref-type>
<home> com.wombat.empl.EmployeeRecordHome </home>
<remote> com.wombat.empl.EmployeeRecord </remote>
</ejb-ref><ejb-ref>
<ejb-ref-name> ejb/EmplRecord </ejb-ref-name>
<jndi-name> AccountEJB </jndi-name>
</ejb-ref-mapping>About Persistence Manager Resources
This module describes persistence and establishes a framework for the use of the pluggable Persistence Managers that are supported by Sun ONE Application Server.
This module covers the following topics:
- What is Persistence?
- The Role of the Persistence Manager
- Pre-Deployment Bean Configuration
- Creating a New Persistence Manager
What is Persistence?
A key aspect of most business applications is the programmatic manipulation of persistent data; long-lived data stored outside of an application. Although persistent data is read into transient memory for the purpose of using or modifying it, it is written out to a relational database or flat file system for long-term storage.
In object-oriented programming systems, persistent data is represented in memory as one or more data objects manipulated by application code. In general, the correspondence between persistent data in a data store and its representation as a persistent data object in memory is achieved through a number of software layers as shown in the following figure, "Basic Persistence Scheme":
Basic Persistence Scheme
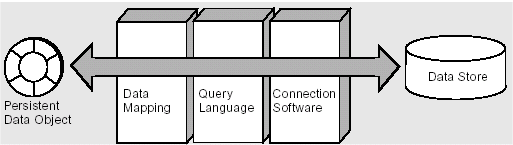
Each data store has an interface to the outside world through driver software used to set up and maintain a connection between the data store and an application. With this connection established, a query language is used to retrieve information from the data store and read it into an application, or conversely, to write data from the application into the data store. Another layer provides a mapping between data objects in memory and the information in the data store.
Through this general scheme, programmers can represent persistent data as runtime objects to be used and manipulated by an application. The scheme supports all basic persistence operations—often abbreviated as CRUD:
- C - Creating persistent data (inserting in a data store)
- R - Retrieving persistent data (selecting from a data store)
- U - Updating persistent data
- D - Deleting persistent data
The Role of the Persistence Manager
The Persistence Manager (PM) is responsible for the persistence of entity beans with Container-managed Persistence, in the EJB container. The entity bean provider is responsible for providing the entity bean class as an abstract class. The Persistence Manager provider's tools are responsible for providing the concrete implementations. They can achieve this by sub-classing the abstract entity bean and related classes and providing an concrete implementation or by utilizing encapsulation and delegation.
The classes provided by the persistence manager's tools are responsible for managing the relationships between the entity beans and for managing the access to their persistent state. The PM tools are also responsible for providing the implementations of the java.util.Collection classes that are used in the maintaining the container managed relationships (CMRs).
Pre-Deployment Bean Configuration
The Enterprise Java Beans standard provides two types of persistence for Entity Beans. These are the Container Managed Persistence (CMP) and Bean Managed Persistence (BMP) The EJB 2.0 specification does not define a standard API between a EJB server and the persistence manager.
This section describes the integration requirements at deployment and code-generation. Deployment can be used to mean multiple things. Generally speaking, the deployment process can be thought of three distinct steps: Configuration, Code-generation and installation.
A number of properties must be specified for a bean, including the persistence mechanism used, persistence vendor, and the version in use, and additional information required by the persistence mechanism. Most of the persistence vendors have a concept of a project, which represents all the related beans and their dependant classes, which can be deployed as a single unit. There can be a vendor specific xml file per project.
The three standard files supported for deployment purposes include ejb-jar.xml, sun-ejb-jar.xml and sun-cmp-mappings.xml. Each EJB module with CMP beans in the sun-ejb-jar.xml must have a <pm-descriptors> with at least one <pm-descriptor> element, which specifies five more attributes. These five attributes are pm-identifier, pm-version, pm-config, pm-class-generator, and pm-mapping-factory.
The Sun ONE Application Server-specific descriptor (as in sunEjb_jar_2_0.DTD) defines the persistence manager related tags. A sample CMP descriptor might look like the one below as defined in the Sun ONE Application Server DTD:
PM descriptors contain one or more pm descriptors, but only of them must be in use at any given time
-->
<!ELEMENT pm-descriptors ( pm-descriptor+, pm-inuse)>
<!--
pm-descriptor describes the properties for the persistence manager
associated with entity bean
-->
<!ELEMENT pm-descriptor ( pm-identifier, pm-version, pm-config?, pm-class-generator?,
pm-mapping-factory?)>
<!--
This element describes the vendor who provided the PM implementation, for example this could be Sun ONE Application Server Transparent Persistence, TopLink, Versant or CocoBase:
-->
<!ELEMENT pm-identifier (#PCDATA)>
<!--
pm-version further specifies which version of PM vendor product to be used
-->
<!ELEMENT pm-version (#PCDATA)>
<!--
pm-config specifies the vendor specific config file to be used
-->
<!ELEMENT pm-config (#PCDATA)>
<!--
pm-class-generator specifies the vendor specific concrete class generator
This is the name of the class specific to a vendor:
-->
<!ELEMENT pm-class-generator (#PCDATA)>
<!--
pm-mapping-factory specifies the vendor specific mapping factory
This is the name of the class specific to a vendor:
-->
<!ELEMENT pm-mapping-factory (#PCDATA)>
Creating a New Persistence Manager
Using the Administration interface, you can create a new Persistence Manager instance. To create a new persistence manager instance:
- From the left pane of the Administration interface, open the Sun ONE Application Server instance for which you want to create a new Persistence Manager. Click Persistence Manager from the list of server components displayed.
If any persistence managers have been created for that specific instance of Sun ONE Application Server, you will see the list displayed in the right pane of the Administration interface.
- To create a new Persistence Manager, click New. You will see the following window shown in the figure "Creating a New Persistence Manager":
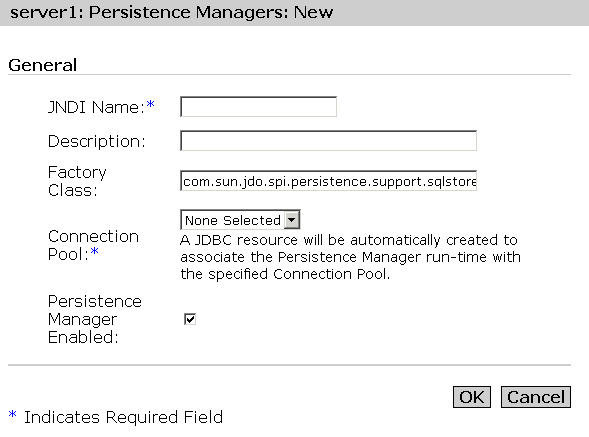
Creating a New Persistence Manager
- This is the JNDI Name used by the application server run-time to locate a particular Persistence Manager on behalf of an application. The name must the same as that defined in the entity bean's cmp-resource element of the sun specific deployment descriptor.
- In the Description field, provide a description for the new persistence manager. The value for this field is string, and can comprise up to 250 characters.
- In the Factory Class field, provide a factory class connection for the persistence manager. The setEntityContext looks up this connection factory through the JNDI name lookup. The factory class name is the classname of the Persistence Manager Factory that creates Persistence Manager instances. By default this will be set to the Sun ONE Application Server's internal Persistence Manager Factory class; if you use an alternative implementation you must ensure that this class is available in the server classpath.
- From the Connection Pool drop-down list, select a database connection pool, into which the new persistence manager will be pooled. With connection pooling, an entity bean can request a single connection and use it to execute concurrent statements for multiple client threads. Just like any other database access, the Persistence Manager will use connection pooling to improve performance and scalability. Choose an existing connection pool or "None Selected" if you haven't yet created the pool.
Note: a JDBC Resource will be automatically created to allow the PM runtime to bind to the connection pool using JNDI - the JNDI name of the JDBC Resource will be the same as the PM JNDI Name with a prefix of "PM." Deleting a Persistence Manager will also delete the associated JDBC Resource.
- To enable the persistence manager, mark the Persistence Manager Enabled checkbox. The persistence manager is now enabled for the connection factory specified.
- Click OK to save your changes.
About JDBC Resources
This module talks about the JDBC API in general, and JDBC resources and their implementation and usage in Sun ONE Application Server, in specific.
This module consists of the following sections:
- About the JDBC API
- About Database Access Models
- About JDBC Datasources
- About JDBC Connections
- About JDBC Transactions
About the JDBC API
The JDBC API is a Java API for accessing virtually any kind of tabular data. (As a point of interest, JDBC is the trademarked name and is not an acronym; nevertheless, JDBC is often thought of as standing for "Java Database Connectivity.") The JDBC API consists of a set of classes and interfaces written in the Java programming language that provide a standard API for tool/database developers and makes it possible to write database applications using an all-Java API.
The JDBC API makes it easy to send SQL statements to relational database systems and supports all dialects of SQL. But the JDBC 3.0 API goes beyond SQL, also making it possible to interact with other kinds of data sources, such as files that are outside of a database.
The value of the JDBC API is that an application can access virtually any data source and run on any platform with a Java virtual machine. In other words, with the JDBC API, it isn't necessary to write one program to access a Sybase database, another program to access an Oracle database, another program to access an IBM DB2 database, and so on. You can write a single program using the JDBC API, and the program will be able to send SQL or other statements to the appropriate data source. And, with an application written in the Java programming language, you do not have to worry about writing different applications to run on different platforms. The combination of the Java platform and the JDBC API lets a programmer write once, and run the code from anywhere.
What Does The JDBC API Do?
A JDBC technology-based driver (JDBC driver) makes it possible to do three things:
- Establish a connection with a data source
- Send queries and update statements to the data source
- Process the results
The following code fragment gives a simple example of these three steps:
Context ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("jdbc/AcmeDB");
Connection con = ds.getConnection("myLogin", "myPassword");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM Table1");
while (rs.next()) {
int x = rs.getInt("a");
String s = rs.getString("b");
float f = rs.getFloat("c");
}
About Database Access Models
The JDBC API supports both two-tier and three-tier models for database access. Sun ONE Application Server incorporates the more popular, two-tier database access model.
This section covers the following topics:
Two-Tier Database Access Model
In the two-tier database access model a Java applet or application talks directly to the data source using a DBMS-proprietary protocol. This access model requires a JDBC driver that can communicate with the particular data source being accessed. A user's commands are delivered to the database or other data source, and the results of those statements are sent back to the user. The data source may be located on another machine to which the user is connected via a network. This configuration is referred to as a client/server configuration, with the user's machine as the client, and the machine housing the data source as the server. The network can be an intranet, which, for example, connects employees within a corporation, or it can be the Internet.
Three-Tier Database Access Model
In the three-tier database access model, the Java applet or application sends commands to a "middle tier" of services, which then sends the commands to the data source. The client application communicates with the middle tier via HTTP, RM, CORBA, or other calls. The middle tier communicates with the data store through a DBMS-proprietary protocol. The data source processes the commands and sends the results back to the middle tier, which then sends them to the user. MIS directors find the three-tier model very attractive because the middle tier makes it possible to maintain control over access and the kinds of updates that can be made to corporate data. Another advantage is that it simplifies the deployment of applications. Finally, in many cases, the three-tier architecture can provide performance advantages.
About JDBC Datasources
A DataSource object is the representation of a data source in the Java programming language. In basic terms, a data source is a facility for storing data. It can be as sophisticated as a complex database for a large corporation or as simple as a file with rows and columns. A data source can reside on a remote server, or it can be on a local desktop machine. Applications access a data source using a connection, and a DataSource object can be thought of as a factory for connections to the particular data source that the DataSource instance represents. The DataSource interface provides two methods for establishing a connection with a data source.
A DataSource object has properties that identify and describe the data source it represents. Also, a DataSource object works with a JNDI naming service and is created, deployed, and managed separately from the applications that use it. A driver vendor will provide a class that is a basic implementation of the DataSource interface as part of its JDBC 2.0 or 3.0 driver product.
This section covers the following topics:
Properties Of a DataSource Object
A DataSource object has a set of properties that identify and describe the real world data source that it represents. These properties include information like the location of the database server, the name of the database, the network protocol to use to communicate with the server, and so on. DataSource properties follow the JavaBeans design pattern and are usually set when a DataSource object is deployed.
To encourage uniformity among DataSource implementations from different vendors, the JDBC 2.0 API specifies a standard set of properties and a standard name for each property.
An instance of a class that implements the DataSource interface represents one particular data source. Every connection produced by that instance will reference the same data source. In a basic DataSource implementation, a call to the method DataSource.getConnection returns a connection object that, like the connection object returned by the DriverManager facility, is a physical connection to the data source.
JNDI provides a uniform way for an application to find and access remote services over the network. The remote service may be any enterprise service, including a messaging service or an application-specific service, but, of course, a JDBC application is interested mainly in a database service. Once a DataSource object is created and registered with a JNDI naming service, an application can use the JNDI API to access that DataSource object, which can then be used to connect to the data source it represents.
DataSource objects that implement connection pooling likewise produce a connection to the particular data source that the DataSource class represents. The connection object that the method DataSource.getConnection returns, however, is a handle to a PooledConnection object rather than being a physical connection. An application uses the connection object just as it usually does and is generally unaware that it is in any way different. Connection pooling has no effect whatever on application code except that a pooled connection, as is true with all connections, should always be explicitly closed. When an application closes a connection that is pooled, the connection joins a pool of reusable connections. The next time DataSource.getConnection is called, a handle to one of these pooled connections will be returned if one is available. Because connection pooling avoids creating a new physical connection every time one is requested, it can help to make applications run significantly faster.
A DataSource class can likewise be implemented to work with a distributed transaction environment. An EJB server, for example, supports distributed transactions and requires a DataSource class that is implemented to interact with it. In this case, the DataSource.getConnection method returns a Connection object that can be used in a distributed transaction. As a rule, EJB servers provide support for connection pooling as well as distributed transactions. Like connection pooling, transaction management is handled internally, so using distributed transactions is easy. The only requirement is that when a transaction is distributed (this involves two or more data sources), the application cannot call the transaction methods as either commit or rollback. It also cannot put the connection in auto-commit mode. The reason for these restrictions is that a transaction manager begins and ends a distributed transaction under the covers, so an application cannot do anything that would affect the time that a transaction begins or ends. To know more about Java transactions, please see "Using Transaction Services."
Registering a JDBC Resource
You can register a JDBC resource with Sun ONE Application Server using either the Administration interface or the command-line interface.
This section covers the following topics:
- Registering a Resource Using the Command Line
- Registering a Resource Using the Administration Interface
Registering a Resource Using the Command Line
To register a JDBC resource using the command line interface, run the following command:
./asadmin create-jdbc-resource
The XML snippet, for registering a JDBC resource, would have to specify a few attributes, as below (excerpted from sun-server_7_0.dtd).
<!-- JDBC javax.sql.DataSource resource definition -->
<!ELEMENT jdbc-resource (description?, property*)>
<!ATTLIST jdbc-resource jndi-name CDATA #REQUIRED
pool-name CDATA #REQUIRED
enabled %boolean; 'true'>
Note that all this specifies, is the symbolic name with which applications will refer to this data source, from inside J2EE applications. pool-name attribute points to a named pool definition, that specifies all aspects of database connectivity. The enabled attribute can be used by the administrator to turn off some resources.
Registering a Resource Using the Administration Interface
To register a datasource using the Administration interface:
- In the left pane of the Administration interface, open the Sun ONE Application Server instance for which you want to register a JDBC resource.
- Open JDBC.
- Under JDBC, click JDBC Resource.
- In the right pane, click New. The page for creating a new JDBC resource, shown in the figure "Creating a New JDBC Resource," appears in the right pane.
Creating a New JDBC Resource
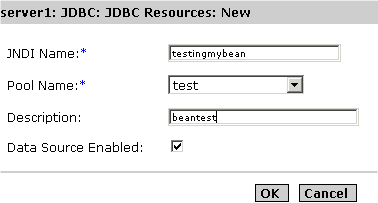
- Provide the JNDI name for the resource that you are creating.
JDBC Resources are stored in the JNDI repository and are accessed using the JNDI name. The JNDI name has an explicit root at Java:comp:env/ so you do not need to specify that part of the name. It is recommended that JDBC Resources (DataSources) are stored under the 'jdbc' sub-context so your JNDI name would be similar to jdbc/EmployeeDB_DS.
- Select a pool name for the new datasource, from the list of pool names in the Pool Name drop-down list. All registered connection pools will appear in this drop-down list. The pool name that you select points to a named pool definition, that specifies all aspects of database connectivity. More than one JDBC resource can use a single pool definition. To know more about how to configure JDBC connection pools, see "Creating a New JDBC Connection Pool Using the Administration Interface".
- In the Description field, provide a brief description that describes the purpose of the data source. Your description must not exceed 250 characters.
- Mark the Enabled checkbox to enable or disable a datasource. A datasource cannot be used to connect to a database unless it is enabled.
- Click OK to register the new datasource, or click Cancel to cancel the new datasource. When you click cancel, you are returned to the main JDBC resources page, from where you can create a new datasource again.
About JDBC Connections
A Connection object represents a connection with a database. A connection session includes the SQL statements that are executed and the results that are returned over that connection. A single application can have one or more connections with a single database, or it can have connections with many different databases.
A user can get information about a Connection object's database by invoking the Connection.getMetaData method. This method returns a DatabaseMetaData object that contains information about the database's tables, the SQL grammar it supports, its stored procedures, the capabilities of this connection, and so on.
An application uses a Connection object produced by a DataSource object. As is always the case, an application should include a "finally" block to assure that connections are closed even if an exception is thrown. This is even more important if the Connection object is a pooled connection because it makes sure that a valid connection will always be put back into the pool of available connections. The following code fragment, in which con is Connection object, is an example of a finally block that closes a connection if it is valid.
finally{
if (con != null) con.close();
}
Note that a finally block appears after a try/catch block, as shown in the following example, where ds is a DataSource object.
try {
Connection con = ds.getConnection("user", "secret");
// . . . code to do the application's work
} catch {
// . . . code to handle an SQLException
} finally {
if (con != null) con.close();
}
This section covers the following topics:
- About JDBC URLs
- Configuring JDBC Connection Pools
- About Connection Pooling
- Monitoring JDBC Connection Pooling
- About Connection Sharing
About JDBC URLs
A URL (Uniform Resource Locator) gives information for locating a resource on the Internet. It can be thought of as an address.
A JDBC URL provides a way of identifying a data source so that the appropriate driver will recognize it and establish a connection with it. Driver writers are the ones who actually determine what the JDBC URL that identifies a particular driver will be. Users do not need to worry about how to form a JDBC URL; they simply use the URL supplied with the drivers they are using. JDBC's role is to recommend some conventions for driver writers to follow in structuring their JDBC URLs.
Since JDBC URLs are used with various kinds of drivers, the conventions are, of necessity, very flexible. First, they allow different drivers to use different schemes for naming databases. The ODBC sub-protocol, for example, lets the URL contain attribute values (but does not require them).
Second, JDBC URLs allow driver writers to encode all necessary connection information within them. This makes it possible, for example, for an applet that wants to talk to a given database to open the database connection without requiring the user to do any system administration chores.
Third, JDBC URLs allow a level of indirection. This means that the JDBC URL may refer to a logical host or database name that is dynamically translated to the actual name by a network naming system. This allows system administrators to avoid specifying particular hosts as part of the JDBC name. There are a number of different network name services, and there is no restriction about which ones can be used.
The standard syntax for JDBC URLs is shown here. It has three parts, which are separated by colons.
jdbc:<subprotocol>:<subname>
The three parts of a JDBC URL are broken down as follows:
- jdbc-the protocol:
The protocol in a JDBC URL is always jdbc.
- <subprotocol>
The name of the driver or the name of a database connectivity mechanism, which may be supported by one or more drivers. A prominent example of a sub-protocol name is ODBC, which has been reserved for URLs that specify ODBC-style data source names. For example, to access a database through a JDBC-ODBC bridge, one might use a URL such as jdbc:odbc:fred.
In this example, the subprotocol is ODBC, and the subname fred is a local ODBC data source.
If one wants to use a network name service (so that the database name in the JDBC URL does not have to be its actual name), the naming service can be the subprotocol. So, for example, one might have a URL such as:
jdbc:dcenaming:accounts-payable
In this example, the URL specifies that the local DCE naming service should resolve the database name accounts-payable into a more specific name that can be used to connect to the real database.
- <subname>:
A way to identify the data source. The subname can vary, depending on the subprotocol, and it can have any internal syntax the driver writer chooses, including a sub-subname. The point of a subname is to give enough information to locate the data source. In the previous example, fred is enough because ODBC provides the remainder of the information. A data source on a remote server requires more information, however. If the data source is to be accessed over the Internet, for example, the network address should be included in the JDBC URL as part of the subname and should adhere to the following standard URL naming convention:
//hostname:port/subsubname
Supposing that dbnet is a protocol for connecting to a host on the Internet, a JDBC URL might look like this:
jdbc:dbnet://wombat:356/fred
Configuring JDBC Connection Pools
Sun ONE Application Server allows users to create named JDBC connection pools. A JDBC connection pool defines the properties used to create a connection pool. A pool definition is named, and a definition can be reused to configure multiple JDBC resources. Each named pool definition results in an instantiation of a physical pool at server start-up. If two or more JDBC resources point to the same pool definition, they will be using the same pool of connections at run time.
You can create and configure JDBC connection pools using the Administration interface and the Command Line Interface, as detailed in the following sections:
- Creating a New JDBC Connection Pool Using the Administration Interface
- Creating a New JDBC Connection Pool Using the Command-Line Interface
- Using the Command Line Interface to Manage JDBC Connection Pools
Creating a New JDBC Connection Pool Using the Administration Interface
To create a new JDBC connection pool using the Administration interface, perform the following tasks:
- In the left pane of the Administration interface, open the Sun ONE Application Server instance for which you want to create a JDBC connection pool.
- Select JDBC from the list of J2EE services listed under your Sun ONE Application Server, and open the ConnectionPools tab under it. You will see the figure "Creating a New JDBC Connection Pool" in the right pane of the Administration interface.
Creating a New JDBC Connection Pool
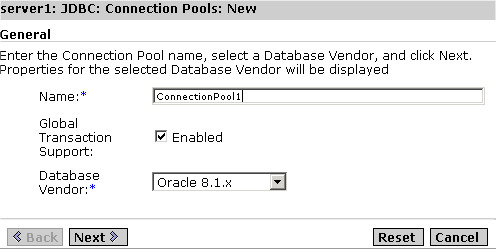
- In the Name field, provide a JNDI name of the connection pool that you are creating.
- Mark the Global Transaction Support Enabled checkbox to enable global Transaction support for the new connection pool. Connection pools that are capable of participating in global transactions, and are referred to as XA-capable connection pools.
- Select a database vendor, from the Database Vendor drop-down list, and click Next. You need to configure connection pool settings in the screen that is displayed next.
Configuring Connection Pool Settings
To configure pool settings, perform Step 1to Step 5 as given in "Creating a New JDBC Connection Pool Using the Administration Interface". When you click Next, as described in Step 5, a new page appears in the right pane of the Administration interface. It contains the following sections:
- General
- Properties
- Pool Settings
- Connection Validation
- Transaction Isolation
In the General section of this page, specify the values for the parameters provided, based on the guidelines given in the following table:
In the Properties section of this page you specify standard and proprietary JDBC connection pool properties; many of these properties are optional. By default the names of all of the standard properties are provided. You will need to consult your database vendor's documentation to determine which standard and vendor specific properties are required.
In the Pool Settings section of this window, specify the values for the parameters provided, based on the guidelines given in the following table:
In the Connection Validation and Transaction Isolation sections of this window, select the validation method and transaction isolation methods for the connection pool, based on the guidelines given in the following table:
Creating a New JDBC Connection Pool Using the Command-Line Interface
This section describes, through the use of examples, how to create JDBC connection pools using the Command Line Interface.
The following table lists all the options that you need to create connection pools, such as server name, password. Sample values have been used in the following table. It is recommended that you keep the parameters specific to your installation of Sun ONE Application Server ready, before running the commands explained in this section.
The following example makes use of the variables listed in the "Options required for creating JDBC Connection Pools using the Command Line Interface" table.
Example 1:
This example creates a JDBC connection pool called SampleJdbcConnectionPool. A two-step process is used, in this example, to create the JDBC connection pool, as follows:
Step 1 - Create a Connection Pool
The following is the command line interface syntax for creating a JDBC connection pool:
asadmin create-jdbc-connection-pool --user admin_user [--password admin_password] [--host localhost] [--port 4848] [--secure | -s] [--instance instancename] --datasourceclassname classname [--restype res_type] [--steadypoolsize 8] [--maxpoolsize 32] [--maxwait 60000] [--poolresize 2] [--idletimeout 300] [--isolationlevel isolation_level] [--isisolationguaranteed] [--isconnectvalidatereq=false] [--validationmethod auto-commit] [--validationtable tablename] [--failconnection=false] [--description text] [--property (name=value)[:name=value]*] connectionpool_id
For example, the following command will create a connection pool called SampleJdbcConnectionPool.
asadmin create-jdbc-connection-pool --user admin --password adminadmin --host sas.sun.com --port 8888 --instance server1 --restype javax.sql.XADataSource --datasourceclassname oracle.jdbc.xa.client.OracleXADataSource --description "Sample Jdbc Connection Pool" --property User="oracle":Password="oracle":URL="jdbc\:oracle\:thin\:@oracleser ver.sun.com\:1521\:ORA" SampleJdbcConnectionPool
Note If you want to enable "Global Transaction Support" for the new connection pool, set --restype javax.sql.XADataSource. In the URL property, replace the colon (:) with (\:)
Once the JDBC connection pool is created successfully, you see the following message:.
Created the JDBC connection pool resource with id = SampleJdbcConnectionPool
Step 2 - Apply Changes To the Instance
Now that you have successfully created a JDBC connection pool, you need to apply the changes to the current instance of Sun ONE Application Server.
The following is the syntax for applying the changes to your instance of Sun ONE Application Server.
asadmin reconfig --user admin_user [--password admin_password] [--host localhost] [--port adminport] [--secure | -s] [--discardmanualchanges=false|--keepmanualchanges=false] instancename
For example, the following command applies the changes to server1, the instance of Sun ONE Application Server.
asadmin reconfig --user admin --password adminadmin --host sas.sun.com --port 8888 server1
Once the changes are applied to your instance of Sun ONE Application Server, you will see the following message.
Successfully reconfigured
Using the Command Line Interface to Manage JDBC Connection Pools
You can use the command line interface to manage JDBC connection pools and their properties, as discussed in this section:
Listing Connection Pools. The following command lists all the connection pools created for server1, the instance of Sun ONE Application Server used in Step 2.
asadmin list-jdbc-connection-pools --user admin --password adminadmin --host sas.sun.com --port 8888 server1
Changing a JDBC Connection Pool Property. You can change a JDBC connection pool's property, for example, the maxPoolSize property, as follows:
- Run the following command to get the value specified for the JDBC connection pool attribute maxPoolSize.
asadmin get -u admin -w adminadmin -H sas.sun.com -p 8888 server1.jdbc-connection-pool.SampleJdbcConnectionPool.maxPoolSize
When you run this command, you will see the following result:
server1.jdbc-connection-pool.SampleJdbcConnectionPool.maxPoolSize = 32
Change the value of MaxPoolSize to 80, by running the following command:
asadmin set -u admin -w adminadmin -H sas.sun.com -p 8888 server1.jdbc-connection-pool.SampleJdbcConnectionPool.maxPoolSize="80"
Once the values are specified as indicated, you will see the following message:
Attribute maxPoolSize set to 80
- Apply the changes to your instance of Sun ONE Application Server using the following command:
asadmin reconfig --user admin --password adminadmin --host sas.sun.com --port 8888 server1
Changing the User Property. In the following piece of sample code, you can change the property "User" from oracle to System.
asadmin create-jdbc-connection-pool --user admin --password adminadmin --host sas.sun.com --port 8888 --instance server1 --restype javax.sql.XADataSource --datasourceclassname oracle.jdbc.xa.client.OracleXADataSource --description "Sample Jdbc Connection Pool" --property User="oracle":Password="oracle":URL="jdbc\:oracle\:thin\:@oracleserver.sun.com\:1521\ :ORA" SampleJdbcConnectionPool
- Run the following command to change the User property.
asadmin set -u admin -w adminadmin -H sas.sun.com -p 8888 server1.jdbc-connection-pool.SampleJdbcConnectionPool.property.User="System"
The name of the user is changed from Oracle to System.
- After you change the user name, run the following command to apply your changes:
asadmin reconfig --user admin --password adminadmin --host sas.sun.com --port 8888 server1
Creating a JDBC resource called SampleJdbcResource. You can create a JDBC resource, as detailed below. The following is the syntax for creating a JDBC resource:
asadmin create-jdbc-resource --user admin_user [--password admin_password] [--host localhost] [--port 4848] [--secure | -s] [--instance instancename] --connectionpoolid id [--enabled=true] [--description text] [--property (name=value)[:name=value]*] jndiname
- Run the following command to create a JDBC resource called SampleJdbcResource.
asadmin create-jdbc-resource --user admin --password adminadmin --host sas.sun.com --port 8888 --instance server1 --description "Sample Jdbc Resource" --connectionpoolid SampleJdbcConnectionPool jdbc/SampleJdbcResource
When you run this command, the JDBC resource is created, and you will see the following message:.
Created the external JDBC resource with jndiname = jdbc/SampleJdbcResource
- Next, you need to run the following command to apply the changes to your instance of Sun ONE Application Server.
asadmin reconfig --user admin --password adminadmin --host sas.sun.com --port 8888 server1
- Run the following command to list all the JDBC resources in the instance server1.
asadmin list-jdbc-resources --user admin --password adminadmin --host sas.sun.com --port 8888 server1
About Connection Pooling
Applications can obtain connections by first looking up the DataSource using JNDI. A sample code fragment to accomplish this, is shown below:
InitialContext ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("java:comp/env/jdbc/employee_ds");
After obtaining the DataSource, the application component can obtain connections in two ways depending on the value set on the <res-auth> element in the J2EE deployment descriptor. If the value of this element is Container, then the application can obtain a connection using ds.getConnection() method (that is, without specifying any sign-on information). Otherwise, the application has to give the sign-on information to obtain the connection from the resource manager like ds.getConnecion.(userName, password).
All requests to getConnection() will be served from a pool. The JDBC Connection pool will be created based on a set of parameters described in server.xml. When the pool is created, the pool contains the number of connections that are available initially. So the ds.getConnection() request can be satisfied with the connections currently available in the pool. The next request (if none of the previous connections have been returned to the pool) will find the pool empty and will result in the creation of incremented connections, subject to the limit of the maximum connections specified for the pool. The pool implementation will keep track of the number of connections that are created. If a getConnection() request finds the pool empty, or if the number of created connections is equal to the maximum connections in the pool, then the current request is blocked. This happens only if connection sharing is not possible, and continues until a connection is returned to the pool.
The connection pool will continue to work properly even if the database crashes and comes up, while the server is still running. This can be accomplished only if you enable connection validation, as described in "Configuring Connection Pool Settings".
Depending on the value that you select from the Validation Type drop-down list, the following parameters are executed by the pool implementation program:
- If you choose auto-commit as your connection validation type, the system checks to see if the connection is valid by performing a conn.getAutoCommit() method. If the method does not throw an SQLException then the Connection is assumed to be valid. auto-commit is the default option for this parameter.
- If you chose meta-data as your connection validation type, then the conn.getMetaData() method will be performed, to check for metadata on the connection. and if the method didn't throw SQLException then the Connection is assumed to be valid.
- If you choose table as your connection validation type, then the query "Select * From <table-name>" will be executed. If this call doesn't throw an SQLException then the connection is assumed to be valid.
If you enable the fail-all-connections property, then if any connection in the pool is found to be invalid, all connections will be closed and re-established. Otherwise, invalidation and re-establishment is lazy and happens on use of individual connections.
The pool implementation also provides the ability to recycle all available connections in the pool. So if connections are idle beyond the idle period specified, they will be closed, bringing the pool size to the steady pool size. If the pool is extremely idle, it may result in the container having to re-establish stale connection and always keep the pool populated with a steady pool of usable connections. You must keep this in mind while determining whether to set the steady pool size relative to the maximum pool size.
Monitoring JDBC Connection Pooling
You may want to monitor the pool operation periodically, to determine if the pool size configuration is working effectively. The following table lists all the JDBC connection pooling parameters that can be monitored.
Note that the mechanics of enabling monitoring, and the attributes that can be monitored are likely to be improved in forthcoming releases.
About Connection Sharing
When multiple connections acquired by a J2EE application use the same resource manager, the pool implementation will provide connection sharing within the same transaction scope. The term transaction scope, can be understood from the following example:
Bean_A starts a transaction (Tx1) and obtains a connection. Bean_A then calls a method in Bean_B in the same transaction (Tx1). Now if Bean_B acquires a connection from the same DataSource and with the same sign-on information, it is clear that the same connection can be shared as only Bean_A will complete the transaction. Also, note that connections will be shared only if the resource sharing scope is set to Shareable in the J2ee deployment descriptor. If connection sharing is not desired, then the resource sharing scope must be set to Unshareable, in the deployment descriptor. Sun ONE Application Server provides connection sharing, as it provides better performance.
About JDBC Transactions
A transaction consists of one or more statements that have been executed, completed, and then either committed or rolled back. When the method commit or rollback is called, the current transaction ends and another one begins.
Generally a new Connection object is in auto-commit mode by default, meaning that when a statement is completed, the method commit will be called on that statement automatically. In this case, since each statement is committed individually, a transaction consists of only one statement. If the auto-commit mode has been disabled, a transaction will not terminate until the method commit or rollback is called explicitly, so it will include all the statements that have been executed since the last invocation of either commit or rollback. In this second case, all the statements in the transaction are committed or rolled back as a group.
The method commit makes permanent any changes an SQL statement makes to a database, and it also releases any locks held by the transaction. The method rollback will discard those changes.
In the case of two updates in one transaction, you might at times not want one change to take effect in an update, unless the other update is also affected. This can be accomplished by disabling auto-commit and grouping both updates into one transaction. If both updates are successful, then the commit method is called, making the effects of both updates permanent; if one fails or both fail, then the rollback method is called, restoring the values that existed before the updates were executed. Most JDBC drivers support transactions.
Classes and interfaces in the javax.sql package make it possible for Connection objects to be part of a distributed transaction, that is, a transaction that involves connections to more than one DBMS server. In order to be able to participate in distributed transactions, a Connection object must be produced by a DataSource object that has been implemented to work with the middle tier server's distributed transaction infrastructure. Unlike Connection objects produced by the DriverManager, a Connection object produced by such a DataSource object will have its auto-commit mode disabled by default. A standard implementation of a DataSource object, on the other hand, will produce Connection objects that are exactly the same as those produced by the DriverManager class.
When a Connection object is part of a distributed transaction, a transaction manager determines when the methods commit or rollback are called on it. Thus, when a Connection object is participating in a distributed transaction, an application should not do anything that affects when a connection begins or ends, such as calling the methods Connection.commit or Connection.rollback, or turning on the connection's auto-commit mode. These would interfere with the transaction manager's handling of the distributed transaction.
About Java Mail Resources
The JavaMail API allows for access to email messages contained in message stores, and for the creation and sending of email messages using a message transport. Specific support is included for Internet standard MIME messages. Access to message stores and transports is through protocol providers supporting specific store and transport protocols. The JavaMail API specification does not require any specific protocol providers, but JavaMail includes an IMAP message store provider and an SMTP message transport provider.
The JavaMail API provides a set of abstract classes defining objects that comprise a mail system. The API defines classes like Message, Store and Transport. The API can be extended and can be sub-classed to provide new protocols and to add functionality when necessary. In addition, the API provides concrete sub-classes of the abstract classes. These sub-classes, including MimeMessage and MimeBodyPart, implement widely used Internet mail protocols.
The JavaMail API draws heavily from IMAP, MAPI, CMC, c-client and other e-mail messaging system APIs. The JavaMail API supports many different messaging system implementation like, different message stores, different message formats, and different message transports. The JavaMail API provides a set of base classes and interfaces that define the API for client applications. Developers can sub-class JavaMail classes to provide the implementations of particular messaging systems, such as IMAP, POP3, and SMTP.
The following topics are covered in this section:
- About the JavaMail Message-handling Process
- About the Architectural Components of JavaMail
- About JavaBeans Activation Framework (JAF)
- About JavaMail Configuration Parameters
- J2EE Deployment Descriptor for JavaMail Session References
- Entries in Sun ONE Application Server Deployment Descriptor
- Creating a New JavaMail Session
- Configuring Advanced Resource Properties
About the JavaMail Message-handling Process
The JavaMail API performs the following functions, which comprise the standard mail handling process for a typical client application:
- Create a mail message consisting of a collection of header attributes and a block of data of some known data type as specified in the Content-Type header field. JavaMail uses the Part interface and the Message class to define a mail message. It uses the JAF-defined DataHandler object to contain data placed in the message.
- Create a Session object, which authenticates the user, and controls access to the message store and transport.
- Send the message to its recipient list.
- Retrieve a message from a message store.
- Execute a high-level command on a retrieved message. High-level commands like view and print are intended to be implemented via JAF-Aware JavaBeans.
Note Currently, the JavaMail framework does not define mechanisms that support message delivery, security, disconnected operation, directory services or filter functionality.
The following figure illustrates how the JavaMail API handles the message handling process:
Message Handling Process of the Java Mail APIThe JavaMail API is configured by using a static factory method to create a javax.mail.Session. Sun ONE Application Server requests a Session object using JNDI, and lists its need for a Session object in its deployment descriptor using a resource-ref element. A JavaMail API Session object is considered a resource factory.
Message transport is provided that is capable of handling addresses of type javax.mail.internet.InternetAddress and messages of type javax.mail.internet.MimeMessage. The default message transport must be properly configured to send such messages using the send method of the javax.mail.Transport class.
The Abstract Layer of the JavaMail API declares classes, interfaces and abstract methods intended to support mail handling functions that all mail systems support. API elements comprising the Abstract Layer are intended to be sub-classed and extended as necessary in order to support standard data types, and to interface with message access and message transport protocols as necessary.
The internet implementation layer implements part of the abstract layer using internet standards - RFC822 and MIME.
About the Architectural Components of JavaMail
This section describes the major components comprising the JavaMail architecture, given in the following topics:
The Message Class
The Message class is an abstract class that defines a set of attributes and a content for a mail message. Attributes of the Message class specify addressing information and define the structure of the content, including the content type. The content is represented as a DataHandler object that wraps around the actual data.
The Message class implements the Part interface. The Part interface defines attributes that are required to define and format data content carried by a Message object, and to interface successfully to a mail system. The Message class adds From, To, Subject, Reply-To, and other attributes necessary for message routing via a message transport system. When contained in a folder, a Message object has a set of flags associated with it. JavaMail provides Message subclasses that support specific messaging implementations.
The content of a message is a collection of bytes, or a reference to a collection of bytes, encapsulated within a Message object. JavaMail has no knowledge of the data type or format of the message content. A Message object interacts with its content through an intermediate layer—the JavaBeans Activation Framework (JAF). This separation allows a Message object to handle any arbitrary content and to transmit it using any appropriate transmission protocol by using calls to the same API methods. The message recipient usually knows the content data type and format and knows how to handle that content.
The JavaMail API also supports multipart Message objects, where each Bodypart defines its own set of attributes and content.
Message Storage and Retrieval
Messages are stored in Folder objects. A Folder object can contain sub-folders as well as messages, thus providing a tree-like folder hierarchy. The Folder class declares methods that fetch, append, copy and delete messages. A Folder object can also send events to components registered as event listeners.
The Store Class
The Store class defines a database that holds a folder hierarchy together with its messages. The Store class also specifies the access protocol that accesses folders and retrieves messages stored in folders. The Store class also provides methods to establish a connection to the database, to fetch folders and to close a connection. Service providers implementing Message Access protocols (IMAP, POP3 etc.) start off by sub-classing the Store class. A user typically starts a session with the mail system by connecting to a particular Store implementation.
Message Composition and Transport
A client creates a new message by instantiating an appropriate Message subclass. It sets attributes like the recipient addresses and the subject, and inserts the content into the Message object. Finally, it sends the Message by invoking the Transport.send method. The Transport class models the transport agent that routes a message to its destination addresses. This class provides methods that send a message to a list of recipients. Invoking the Transport.send method with a Message object identifies the appropriate transport based on its destination addresses.
The Session Class
The Session class defines global and per-user mail-related properties that define the interface between a mail-enabled client and the network.
JavaMail system components use the Session object to set and get specific properties. The Session class also provides a default authenticated session object that desktop applications can share. The Session class is a final concrete class. It cannot be sub-classed. The Session class also acts as a factory for Store and Transport objects that implement specific access and transport protocols. By calling the appropriate factory method on a Session object, the client can obtain Store and Transport objects that support specific protocols.
About JavaBeans Activation Framework (JAF)
JavaMail uses the JavaBeans Activation Framework (JAF) in order to encapsulate message data, and to handle commands intended to interact with that data. Interaction with message data should take place via JAF-aware JavaBeans, which are not provided by the JavaMail API.
With the JavaBeans Activation Framework standard extension, developers who use Java technology can take advantage of standard services to determine the type of an arbitrary piece of data, encapsulate access to it, discover the operations available on it, and to instantiate the appropriate bean to perform said operation(s). For example, if a browser obtained a JPEG image, this framework would enable the browser to identify that stream of data as an JPEG image, and from that type, the browser could locate and instantiate an object that could manipulate, or view that image.
The JavaBeans Activation Framework API supports various MIME data types. The JavaMail API must include javax.activation.DataContentHandlers for the following MIME data types corresponding to the Java programming language type indicated in the following table.
JavaMail API MIME Data Type to Java Type Mappings
MIME Type
Java Type
Text/Plain
java.lang.String
Multipart/
javax.mail.internet.MIME.Multipart
Message/rfc822
javax.mail.internet.MIME.Message
The JavaBeans Activation Framework integrates support for MIME data types into the Java platform. MIME byte streams can be converted to and from Java programming language objects, using avax.activation.DataContentHandlerobjects. JavaBeans components can be specified for operating on MIME data, such as viewing or editing the data. The JavaBeans Activation Framework also provides a mechanism to map filename extensions to MIME types. The JavaBeans Activation Framework is used by the JavaMail API to handle the data included in email message. Typical J2EE applications will not need to use the JavaBeans Activation Framework directly, although applications making sophisticated use of email may need it.
About JavaMail Configuration Parameters
The following configuration parameters are used by JavaMail Resources in Sun ONE Application Server. These configuration parameters are name, value pairs that would be read from the mail-resource element of the server.xml file.
- JNDI Name
The JNDI Name specifies the name with which this mail resource will be referenced from a J2EE Application.
- Enabled
The enabled configuration parameter specifies whether this mail resource will be published in the JNDI tree and can be referenced. If a J2EE application references a resource which is disabled, it will receive a NameNotFoundException exception.
- store-protocol
Specifies the default Message Access Protocol. The Session.getStore() method returns a Store object that implements this protocol. The client can override this property and explicitly specify the protocol with the Session.getStore(String protocol) method.
- store-protocol class
Specifies the class name that implements the store protocol specified above. The default for this class is com.sun.mail.imap.IMAPStore.
- transport-protocol
Specifies the default Transport Protocol. The Session.getTransport() method returns a Transport object that implements this protocol. The client can override this property and explicitly specify the protocol by using Session.getTransport(String protocol) method.
- transport-protocol class
Specifies the class name that implements the transport protocol specified above. The default for this class is com.sun.mail.smtp.SMTPTransport.
- host
Specifies the default Mail server. The Store and Transport object's connect methods use this property, if the protocol specific host property is absent, to locate the target host.
- user
Specifies the username to provide when connecting to a Mail server. The Store and Transport object's connect methods use this property, if the protocol specific username property is absent, to obtain the username.
- from
Specifies the return address of the current user. Used by the InternetAddress.getLocalAddress method to specify the current user's email address.
- debug
Specifies the initial debug mode. Setting this property to true will turn on debug mode, while setting it to false turns debug mode off.
- mail-<protocol>-host
Specifies the protocol-specific default Mail server. This overrides the mail.host property. This property could be set depending on the value of the store-protocol attribute. For the values of imap or POP for store-protocol, you need to add properties with the name mail.imap.host or mail.pop3.host, respectively. The value for the specific property should be set as it is appropriate in your mail system configuration. For example, with store-protocol set to IMAP, the property name: mail-imap-host would bear the value: spaceduck.acme.com.
- mail-<protocol>-user
Specifies the protocol-specific default user name for connecting to the Mail server. This overrides the mail.user property. So this property could be mail.imap.user or mail.pop3.user depending on the selection of store-protocol attribute. For example, with store-protocol set to IMAP, the property name: mail-imap-user would bear the value fredbloggs.
J2EE Deployment Descriptor for JavaMail Session References
Once a JavaMail Resource is registered with the server, it can be referenced in any J2EE application component using a JNDI lookup. In order to deploy an application that references resource manager connection factories, the component provider must declare all the resource manager connection factory references in the standard J2EE 1.3 deployment descriptor.
The complete J2EE1.3 descriptor elements for JavaMail reference are described below:
<resource-ref>
<description>
JavaMail resource used for sending my mail
</description>
<res-ref-name>mail/MyMailSession</res-ref-name>
<res-type>javax.mail.Session</res-type>
<res-auth>Container</res-auth>
<res-sharing-scope>Shareable</res-sharing-scope>
</resource-ref>
Entries in Sun ONE Application Server Deployment Descriptor
For each deployed component that refers to a mail resource, the deployer must map the resource name used in the component to the actual jndi name with which the DataSource is registered with the naming service. The deploy tool is expected to help the deployer to easily make this mapping. This mapping is registered in the Sun ONE Application Server specific xml. The fragment of the Sun ONE Application Server specific XML containing the mapping is shown below:
<resource-ref>
<res-ref-name>mail/MyMailSession</res-ref-name>
<jndi-name>mail/Session</jndi-name>
</resource-ref>
Creating a New JavaMail Session
You can configure JavaMail sessions using the Administration interface. To create and configure a new JavaMail session, perform the following tasks:
- In left pane of the Administration interface, expand the Sun ONE Application Server instance, for which you want to create a new JavaMail session.
- Click JavaMail Sessions. You will see the following window, shown in the figure "Configuring a JavaMail Session", in the right pane of the Administration interface:
Configuring a JavaMail Session
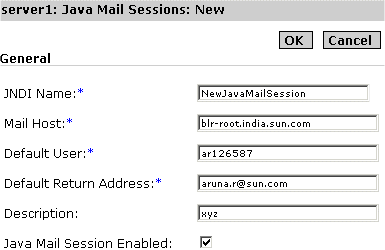
- In the JNDI Name text field, provide a JNDI name for the Java Mail session that you are creating. Once a Java Mail Resource is registered with the server, it can be referenced in any J2EE application component using a JNDI lookup.
- In the Mail Host text field, specify the DNS name of the default mail server. The connect methods of the Store and Transport objects use this property, to locate the target host, if the protocol-specific host property is absent.
- In the Default User text field, specify the username to provide when connecting to a Mail server. The connect methods of the Store and Transport objects use this property to obtain the username, if the protocol-specific username property is absent.
- In the Default Return Address field, specify the default return address of the current user. The default address should be in this form: username@host.
- In the Description field, provide a description for this Java Mail session.
- Mark the Java Mail Session Enabled checkbox to enable the Java Mail session that you created.
- Click OK to save the new JavaMail session that you have configured.
Configuring Advanced Resource Properties
You can configure several additional properties for your new JavaMail session using the Administration interface. The property name and value pairs depend upon the mail protocol in use. You can also directly specify these properties in the server.xml file.
To configure additional properties, perform the following tasks:
- In left pane of the Administration interface, expand the Sun ONE Application Server instance, whose JavaMail session configuration you want to modify.
- Click JavaMail Sessions. You will see the following window, shown in the figure "Configuring Additional Resources for JavaMail Session", in the right pane of the Administration interface, below the main configuration section explained in "Creating a New JavaMail Session":
Configuring Additional Resources for JavaMail Session

- In the Store Protocol text field, specify the store protocol that you would like to use for this specific JavaMail session, for example, POP3, or IMAP.
- In the Store Protocol Class text field, specify the class name of the store protocol that you have indicated, as shown in the given example.
- In the Transport Protocol text field, specify the transport protocol that you want to use for this specific session of JavaMail, for example, SMTP.
- In the Transport Protocol Class text field, specify the class name of the transport protocol you have indicated for this session, as shown in the above example.
- Mark the Debug Enabled checkbox, to enable debugging of this specific session of JavaMail. Enabling this checkbox turns the debug mode on.
- Click OK to save your additional properties configuration.
A complete sample of mail resource configuration is shown below:
<mail-resource
jndi-name = "mail/Session"
enabled = "true"
store-protocol = "imap"
store-protocol-class = "com.sun.mail.imap.IMAPStore"
transport-protocol = "smtp"
transport-protocol-class = "com.sun.mail.smtp.SMTPTransport"
host = "gopostal.acme.com"
user = "kingkong"
from = "kingkong@acme.com"
debug = "false">
<property name = "mail-imap-host" value = "spaceduck.acme.com"/>
<property name = "mail-imap-user" value = "fredbloggs"/>
</mail-resource>