| Oracle® Secure Enterprise Search Administrator's Guide 11g Release 2 (11.2.2) Part Number E23427-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Secure Enterprise Search Administrator's Guide 11g Release 2 (11.2.2) Part Number E23427-01 |
|
|
PDF · Mobi · ePub |
Monitor the crawling process in the Oracle SES Administration GUI by using a combination of the following:
Check the crawl progress and crawl status on the Home - Schedules page. (Click Refresh Status.)
Monitor your crawler statistics on the Home - Schedules - Crawler Progress Summary page and the Home - Statistics page.
Monitor the log file for the current schedule.
See Also:
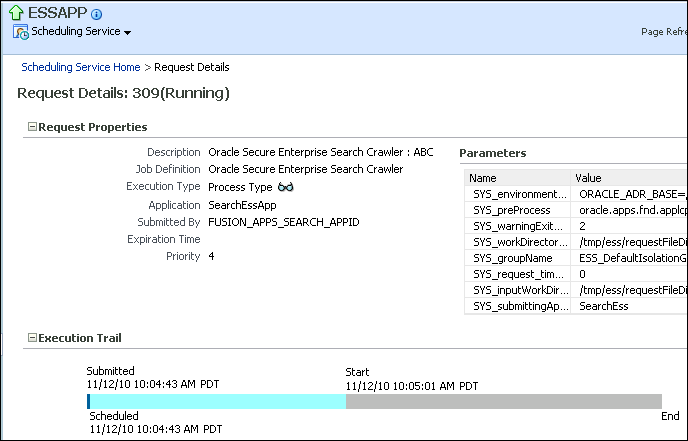
"Tuning Crawl Performance"In Oracle Fusion Applications, you can also monitor crawler jobs in Enterprise Manager Fusion Applications Control. Figure 3-1 shows a crawler schedule named ABC, which appears in the Scheduling Services with a prefix of Oracle Secure Enterprise Search Crawler. The FUSION_APPS_SEARCH_APPID application identity submits all crawler jobs. All Oracle SES connectors use this identity to crawl searchable repositories within Fusion Applications.
Figure 3-1 Oracle SES Crawls Reported in Fusion Applications Control
The following crawler statistics are shown on the Home - Schedules - Crawler Progress Summary page. Some statistics are also shown in the log file under "Crawling results".
Documents to Fetch: Number of URLs in the queue waiting to be crawled. The log file uses the phrase "Documents to Process".
Documents Fetched: Number of documents retrieved by the crawler.
Document Fetch Failures: Number of documents whose contents cannot be retrieved by the crawler. This could be due to an inability to connect to the Web site, slow server response time causing time-outs, or authorization requirements. Problems encountered after successfully fetching the document are not considered here; for example, documents that are too big or duplicate documents that were ignored.
Documents Rejected: Number of URL links encountered but not considered for crawling. The rejection could be due to boundary rules, the robots exclusion rule, the mime type inclusion rule, the crawling depth limit, or the URL rewriter discard directive.
Documents Discovered: Total number of documents discovered so far. This is roughly equal to (documents to fetch) + (documents fetched) + (document fetch failures) + (documents rejected).
Documents Indexed: Number of documents that have been indexed or are pending indexing.
Documents Non-Indexable: Number of documents that cannot be indexed; for example, a file source directory or a document with robots NOINDEX metatag.
Document Conversion Failures: Number of document filtering errors. This is counted whenever a document cannot be converted to HTML format.
The log file records all crawler activity, warnings, and error messages for a particular schedule. It includes messages logged at startup, run time, and shutdown. Logging everything can create very large log files when crawling a large number of documents. However, in certain situations, it can be beneficial to configure the crawler to print detailed activity to each schedule log file.
On the Global Settings - Crawler Configuration page, you can select either to log everything or to log only summary information. You can also select the language the crawler uses to generate the log file.
A new log file is created when you restart the crawler. The location of the crawler log file can be found on the Home - Schedules - Crawler Progress Summary page. The crawler maintains the past seven versions of its log file. The most recent log file is shown in the Oracle SES Administration GUI. You can view the other log files in the file system.
The format of the log file name is:
search.crawler.iSES_Instance_IDdsData_Source_ID.timestamp.log
Where:
SES_Instance_ID is the SID of the SES database.
Data_Source_ID is the identifier of the data source being crawled.
timestamp is the starting time in Greenwich Mean Time (GMT) 24-hour MMDDHHmm format (month, day, hour, minute).
Each logging message in the log file is one line, containing the following six tab delimited columns, in order:
Timestamp
Message level
Crawler thread name
Component name. It is typically the name of the executing Java class.
Module name. It can be internal Java class method name
Message
Most crawler configuration tasks are controlled in the Oracle SES Administration GUI, but certain features (like title fallback, character set detection, and indexing the title of multimedia files) are controlled only by the Administration API. Configuration of the crawler is described by the crawlerSettings object.
The crawler uses a set of codes to indicate the crawling result of the crawled URL. Besides the standard HTTP status codes, it uses its own codes for non-HTTP related situations.
See Also:
Appendix B, "URL Crawler Status Codes"
|
Copyright © 2006, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|