Collecting from Legacy Systems
This chapter covers the following topics:
- Overview
- Setting Up the Collection of Transaction Data into the Planning Server
- Process
- Setting Up Batch Uploads
- Sequence of Data Uploads
- Preprocessing Engine
- Setting Up Legacy Instance
- Running Legacy Collections Using the Form-Based Application (Collect Flat-File Data)
- Running Legacy Collections Using the Self-Service Application (Collect Flat-File Data - Self Service)
- Purging Legacy Data
- SRP Streams - Self Service
- Shipment History - Self Service
Overview
Legacy Collection provides an open framework for consulting and system integrators to bring data from legacy systems into Oracle VCP. You can upload data by batch upload of flat files. This is achieved in part by extending the interface table capabilities. A preprocessing engine validates the incoming data from legacy application and ensures that referential integrity is maintained. All business objects can be imported into VCP using flat files.
In addition to collecting data from your EBS instance to your planning instance, you can collect data to the Planning instance from:
-
Your non-Oracle (legacy) systems.
-
Your trading partners' non-Oracle systems
To collect data from your non-Oracle ERP systems or your trading partners' systems, you can either model each non-Oracle ERP system or trading partner as:
-
an Oracle Applications organization and store their setup and transaction data there.
-
a 100% Legacy collection, in which case no standard EBS instance is defined or collected from.
Setup information includes organization setup, items, bills of material, resources, routings, and sourcing information. Transaction data is of the following types:
-
On-hand balance
-
Purchase orders
-
Purchase requisition
-
Work orders
-
Work Order component demand
-
Intransit shipment and receipt
-
Planned orders
-
Local forecasts
-
Demand schedules
-
Sales orders
-
Item suppliers
-
Supplier capacities
-
Supplier flex fences
You can perform the following steps to collect data from your trading partners' non-Oracle systems to your planning instance:
-
Load setup data (such as items, BOMs, Trading Partners) from the trading partner's system to flat files. Load the flat files to the source (Oracle EBS) instance using the standard interfaces and use standard collections to move it to the destination (planning) server.
-
Load transaction data from flat files to the staging tables (MSC_ST%) on the planning server. Use legacy collections to move data from the legacy instance to the planning server.
The following diagram illustrates the flow of data from non-Oracle ERP (legacy) systems to an Oracle EBS application and the planning server.
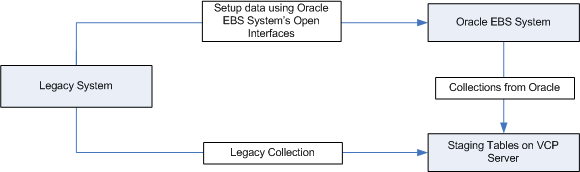
Setting Up the Collection of Transaction Data into the Planning Server
To set up the collection of transaction data into the Planning Server
-
Define two types of organizations in the source instance. The first organization is for OEM and the second is for supplier and customer. You also need to define sourcing rules between the OEM organization and the supplier and customer organization.
-
Import the setup data from your non-Oracle ERP system into the supplier and customer organization using the Oracle EBS open interfaces such as Items open interface, BOM open interface.
To load the organizations for trading partners, you must first define the trading partners in previous loads .
-
Collect all data from the OEM and supplier and customer organizations into your destination instance (planning server).
-
Load transaction data into each supplier and customer organization's flat files. Using either an Oracle Applications form or the self-service application, you can load data from the non-Oracle ERP system into the organizations. If you are using the self-service method, you can upload a zip file containing all the data.
Process
You push legacy data, such as items, bills of materials, routings, etc. into Oracle VCP staging tables using batch upload. Batch upload is done using Oracle SQL*Loader. SQL*Loader requires that data is brought over in a format described in a control file. Oracle has provided control files for all the staging tables. The list of control files is available in Oracle iSupport.
The following diagram shows the movement of data from legacy systems into the Oracle VCP server via staging tables using the batch upload process.
Legacy Application
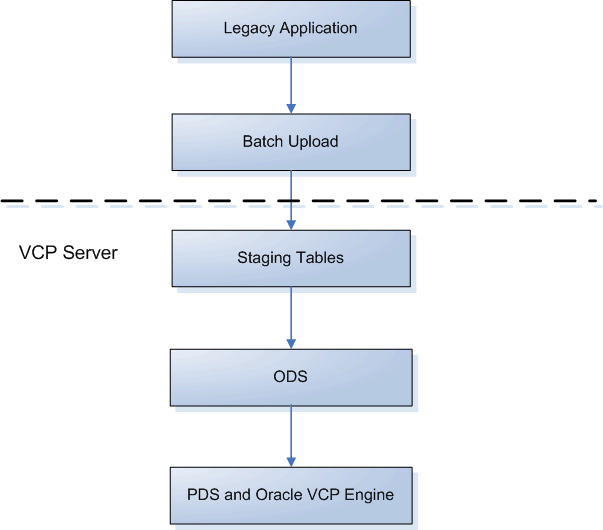
Setting Up Batch Uploads
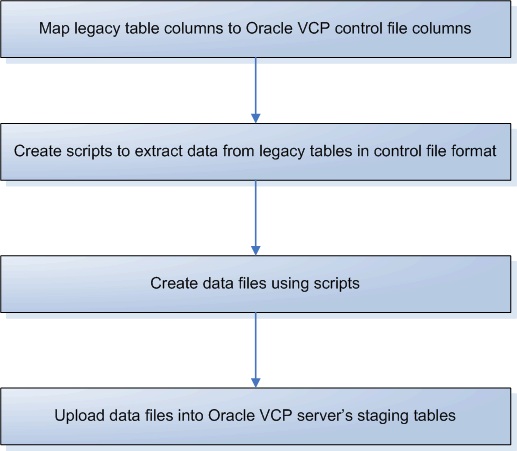
To set up batch uploads
You must do the following to set up the batch uploads:
-
Map the Oracle VCP staging tables' control files (a control file is a template that specifies the input data format) to the legacy system's tables. All the control files (*.ctl) are installed in $MSC_TOP/patch/115/import. All files are named for the staging table to be populated. For example, the Items Base table is MSC_SYSTEM_ITEMS, so we populate MSC_ST_SYSTEM_ITEMS using MSC_ST_SYSTEM_ITEMS.ctl file.
Note: Control files like MSC*_F.ctl are for the Advanced Planning Command Center application and not relevant to the Advanced Supply Chain Planning application.
-
Create scripts to extract data from the legacy system in the format prescribed by the control files.
When loading for trading partner sites, provide values for the location for organizations (Partner Type = 3); do not provide values for the location for customer and supplier sites (Partner Type = 1 or 2).
For example, the following is the control file for Purchase Order Supplies (MSC_ST_SUPPLIES_PO.ctl)
OPTIONS (BINDSIZE=1000000, ROWS=1000, SILENT=(FEEDBACK,DISCARDS)) LOAD DATA INFILE 'MSC_ST_SUPPLIES_PO.DAT' APPEND INTO TABLE MSC.MSC_ST_SUPPLIES FIELDS TERMINATED BY '-' ( ITEM_NAME, ORGANIZATION_CODE, NEW_SCHEDULE_DATE, SUPPLIER_NAME, FIRM_PLANNED_TYPE "NVL(:FIRM_PLANNED_TYPE,1)", SUPPLIER_SITE_CODE, PURCH_LINE_NUM, ORDER_NUMBER, SR_INSTANCE_CODE, REVISION "NVL(:REVISION,1)", UNIT_NUMBER, NEW_ORDER_QUANTITY, NEW_DOCK_DATE, PROJECT_NUMBER, TASK_NUMBER, PLANNING_GROUP, DELIVERY_PRICE, QTY_SCRAPPED, FROM_ORGANIZATION_CODE, ORDER_TYPE CONSTANT '1' DELETED_FLAG "DECODE(:DELETED_FLAG,1,1,2,2,2)", COMPANY_NAME "NVL(:COMPANY_NAME,-1)", END_ORDER_NUMBER, END_ORDER_RELEASE_NUMBER, END_ORDER_LINE_NUMBER ORDER_RELEASE_NUMBER, COMMENTS, SHIP_TO_PARTY_NAME, SHIP_TO_SITE_CODE, SR_INSTANCE_ID CONSTANT '0', PROCESS_FLAG CONSTANT '1', DATA_SOURCE_TYPE CONSTANT 'BATCH', LAST_UPDATE_LOGIN CONSTANT '-1', LAST_UPDATE_DATE SYSDATE, CREATION_DATE SYSDATE )
The script to extract Purchase Order data for this format from a legacy system hosted on an Oracle database could look like the following:
SET HEAD OFF'; SET LINESIZE 200; SET PAGESIZE 50000; SPOOL ON; SPOOL MSC_ST_SUPPLIES_PO.dat; SELECT DISTINCT ITEM_TAB.ITEM_NAME||'~'|| ITEM_TAB.ORGANIZATION_CODE||'~'|| PO_TAB.EXPECTED_DELIVERY_DATE||'~'|| SITES_TAB.TP_NAME||'~'|| 1||'~'|| /* All orders are treated as Firmed */ SITES_TAB.TP_SITE_CODE||'~'|| PO_TAB.LINE_NUM||'~'|| PO_TAB.PO_NUMBER||'~'|| &&SR_INSTANCE_CODE||'~'|| NVL(ITEM_TAB.ITEM_REVISION,1)||'~'|| YES||'~'|| PO_TAB.MRP_PRIMARY_QUANTITY||'~'|| PO_TAB.EXPECTED_DOCK_DATE||'~'|| PO_TAB.PROJECT_ID||'~'|| PO_TAB.TASK_ID||'~'|| YES||'~'|| PO_TAB.UNIT_PRICE||'~'|| 0||'~'|| 1 ||'~'|| /* All records are either for Insert/Change. No deletions are being uploaded */ YES||'~'|| -1||'~'|| YES||'~'|| YES||'~'|| YES||'~'|| YES||'~'|| YES||'~'|| YES||'~'|| YES||'~'|| 0||'~'|| 1||'~'|| 'BATCH'||'~'|| -1||'~'|| SYSDATE||'~'|| SYSDATE FROM <LEGACY_SUPPLY_TABLE> PO_TAB, <LEGACY_ITEMS> ITEM_TAB, <LEGACY_PARTNER_SITES> SITES_TAB WHERE PO_TAB.ORGANIZATION_ID = ITEM_TAB.ORGANIZATION_ID AND PO_TAB.ITEM_ID = ITEM_TAB.INVENTORY_ITEM_ID AND PO_TAB.VENDOR_ID = SITES_TAB.SR_TP_ID AND PO_TAB.VENDOR_SITE_ID = SITES_TAB.SR_TP_SITE_ID;
-
Run the scripts to get the data files and ftp these to the concurrent manager node. The steps to upload these files into Oracle VCP are described below under Running Legacy Collections.
Sequence of Data Uploads
Data must be uploaded in a specific sequence because fields from some dat files may use values that are defined in other dat files. For example, since there are calendar_code references in MSC_ST_TRADING_PARTNERS.ctl, calendar information needs to be loaded before trading partner information.
Load all this information either together or in the following order:
-
Upload calendar data information. All the calendar data files corresponding to calendar's control files (MSC_ST_CALENDARS.ctl, MSC_ST_WORKDAY_PATTERNS.ctl, MSC_ST_SHIFT_TIMES.ctl, MSC_ST_CALENDAR_EXCEPTIONS.ctl, MSC_ST_SHIFT_EXCEPTIONS.ctl) need to be uploaded in one single run. Based on the information provided, the calendar is built on the VCP server. If calendar already exists in ODS tables on the VCP server and you want to rebuild the calendar again, then the entire information (all the above mentioned files) must be sent again. Also, in this case for MSC_ST_CALENDARS.ctl the OVERWRITE_FLAG should be sent as Y.
-
Upload the UOM information. The control file for this is MSC_ST_UNITS_OF_MEASURE.ctl.
-
Upload the Demand Class information.
-
Upload the Trading Partner information. The control files for setting up trading partners are MSC_ST_TRADING_PARTNERS.ctl, MSC_ST_TRADING_PARTNER_SITES.ctl, MSC_ST_LOCATION_ASSOCIATIONS.ctl, MSC_ST_SUB_INVENTORIES.ctl and MSC_ST_PARTNER_CONTACTS.
The trading partner sites, location associations, sub inventories and contacts can be uploaded along with the trading partner information and also in subsequent runs. Only MSC_ST_TRADING_PARTNERS.ctl can be uploaded in the first run.
MSC_ST_TRADING_PARTNERS.ctl has CALENDAR_CODE field. This should refer to a valid calendar code existing on the planning server or to a calendar code that you are uploading in this run of collections. If calendar does not exist on the planning server and has not been uploaded either, then the trading partner record is not accepted and is marked as error.
-
Upload the category sets information. The control file for setting up category sets is MSC_ST_CATEGORY_SETS.ctl
-
Upload the designators information for forecast, MDS and MPS. The control files required are: MSC_ST_DESIGNATORS_MDS.ctl, MSC_ST_DESIGNATORS_FORECAST.ctl and MSC_ST_DESIGNATORS_PLAN_ORDERS.ctl. The forecast, MDS and MPS records can be uploaded now or in subsequent runs.
-
Upload the projects and tasks information. The control file name is MSC_ST_PROJECT_TASKS.ctl
-
Upload the items information as per the MSC_ST_SYSTEM_ITEMS.ctl file. If the UOM_CODE of the data file has an invalid value (that is, a value that does not exist in the planning system and is also not being uploaded along with items as per the MSC_ST_UNITS_OF_MEASURE.ctl in this upload) the item records are errored out.
-
Upload the item related information; for example, supplier capacity, supplies and demands, categories, UOM conversions, and sourcing rules. Upload the data as per the preprocessing diagram shown below and make sure that the items are valid; that is, the items exist in the planning system or are being uploaded in this run of legacy collections.
-
Upload categories using control file MSC_ST_ITEM_CATEGORIES.ctl.
-
Upload sourcing rules using control file MSC_ST_ITEM_SOURCING.ctl.
-
Upload UOM conversions using MSC_ST_UOM_CONVERSIONS.ctl, MSC_ST_UOM_CLASS_CONVERSIONS.ctl.
-
Upload resources using control file MSC_ST_DEPARTMENT_RESOURCEs.ctl.
-
Upload bill of materials using the following control files: MSC_ST_BOMS.ctl, MSC_ST_BOM_COMPONENTS.ctl, and MSC_ST_COMPONENT_SUBSTITUTES.ctl. You can upload BOM components and substitutes to BOM at the same time or upload these in later runs.
-
Upload routings using the following control files: MSC_ST_ROUTINGS.ctl, MSC_ST_ROUTING_OPERATIONS.ctl, and MSC_ST_OPERATION_RESOURCES.ctl. You can upload resources to operations at the same time or upload these in later runs.
-
Upload supplier capacity using the following control files: MSC_ST_ITEM_SUPPLIERS.ctl, MSC_ST_SUPPLIER_CAPACITIES.ctl, and MSC_ST_SUPPLIER_FLEX_FENCES.ctl. You can upload MSC_ST_SUPPLIER_CAPACITIES.ctl with MSC_ST_ITEM_SUPPLIERS.ctl or in subsequent runs. You can also upload MSC_ST_SUPPLIER_FLEX_FENCES.ctl with MSC_ST_ITEM_SUPPLIERS.ctl or in subsequent runs.
-
Load material supply for work order after routings are loaded because there is a field ROUTING_NAME in MSC_ST_SUPPLIES_WO.ctl.
-
Upload resource demand using the control file MSC_ST_RESOURCE_REQUIREMENTS.ctl. If WIP_ENTITY_NAME is not valid (it was not previously loaded using the MSC_ST_SUPPLIES_WO.ctl and also is not loaded in this run using this control file) the record is errored out.
Preprocessing Engine
After data from the legacy application has been loaded onto the planning server, it undergoes preprocessing before it can be used by the planning engine.
Preprocessing generates IDs for the entities coming into the planning system based on a set of user-defined keys (UDKs). For example, to identify an item record in the planning system, the UDK is Instance Code, Organization code, Item Name and Company Name. (Company Name is required only if Collaborative Planning is being deployed, which requires that the profile MSC: Configuration is set to the Advanced Supply Chain Planner responsibility to either 'APS and CP' or 'CP'. For standalone VCP, the profile is set to 'APS' and this value defaults to -1.) A UDK uniquely identifies an existing record in the staging tables. UDKs are used as reference to update existing records in the staging tables.
The preprocessing program is a concurrent program that runs independently from the Planning engine and Global ATP engine.
After the data files have been brought over to the concurrent manager node, the legacy collection request sets the pre-processing engine to read and load the data files into the staging tables. It can then preprocess the data and load the data into the main planning tables (ODS), all in a single run.
The preprocessing engine has the intelligence to handle scenarios wherein transaction data and any prerequisite setup data needed to perform this transaction co-exist in a single data load.
The figure below shows the sequence in which the uploaded data is processed by the preprocessing engine. The preprocessing engine possesses parallel processing capabilities. Parallel processing is enabled for processing items and item-related entities as shown in the diagram. Items, supplies and demand records can further be broken into sub-batches and processed in parallel.
Preprocessing Architecture
Preprocessing Architecture
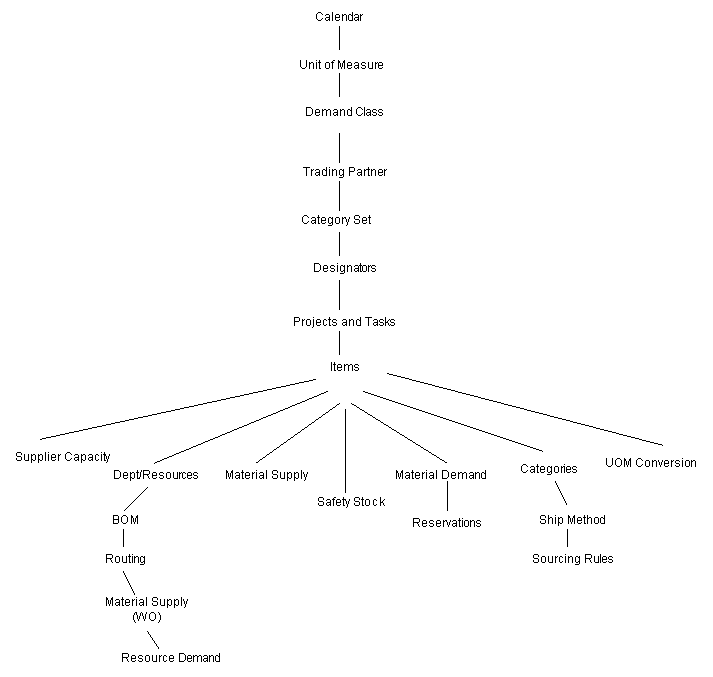
The above architecture also makes it necessary to ensure that all the setup related data is sent to the planning server to avoid errors while processing the transactions. For example, a purchase order line coming into the planning server referring to an item that has not been sent to the server is flagged as an error. Also, the supplier for the item should have been defined as well.
Records in the staging tables are checked for multiple occurrences of the same UDK combination. For instance, in the case of data coming in via XML, if two or more item records are found in the staging table having the same combination of instance code, organization code, item name and company name, preprocessing picks the latest record for further processing and the older records are flagged as errors. For instance, for data coming in via batch upload, if two or more item records are found in the staging table having same combination of instance code, organization code, item name and company name, preprocessing flags those records as errors because preprocessing is not able to determine which is the correct record to be picked up. Error messages are written to the staging table in column ERROR_TEXT in each MSC_ST Staging table.
Data Cleansing
Preprocessing cleanses the incoming data to make it fit for the planning engine. Data that are invalid but are not critical for planning purposes are automatically replaced by default values. This is done to avoid the overhead of resending data. In such cases warning messages are generated. Based on these warning messages, you can resend corrected data. These corrected values then replace the default values.
Error Processing
Errors occur in preprocessing if any of the critical validations fail. In such cases the records are immediately flagged with an error status and do not undergo further processing. These errors are logged in the Oracle VCP table, MSC_ERRORS. These records can be resubmitted after correcting the errors reported by the preprocessing engine.
If XML Gateway is installed, error and warning messages encountered during preprocessing can be emailed to the System Administrator, whose email id can be specified in a XML Gateway profile, ECX: System Administrator Email Address.
Net Change
Preprocessing works on the net change principle. Users need to send only new and changed data to the planning server between successive plan runs. However, a purge program has been provided to carry out a complete refresh. After a complete refresh, all setup and transaction data have to be pushed again into the Oracle VCP server. The purge program also allows partial deletion of supplies and demands. Supply and demand records that fall earlier than a user-specified date can be deleted from the VCP server.
Data Transformation
Character fields have been provided in some cases even where the planning engine requires a numeric value for easy adaptation to legacy data. If numeric values are provided in these fields then the preprocessing engine will pass on the same value to the planning engine. Otherwise it will either generate a new numeric value corresponding to the character value or default a pre-determined constant. For example, the planning engine expects the calendar's shift identifier to be a numeric value. The legacy application may define its workday shifts as A, B and C. The preprocessing engine would then generate a new numeric value corresponding to these character values. It then passes these shift numbers to the planning engine for subsequent processing. Other examples of this kind of flexibility are operation sequence number and resource sequence number. If these fields get a nonnumeric value, instead of not accepting the record, preprocessing replaces these with a numeric constant - 1.
Denormalized Tables
To simplify mapping of the staging tables to the legacy application's tables, wherever possible the staging tables have been denormalized. For instance, the sourcing rules can be uploaded using a single table. This information is then broken down by preprocessing and sent to four different tables within the VCP server. Denormalization has been provided for:
-
sourcing rules
-
projects and tasks
-
resource availability and simulations sets
-
forecast sets and forecasts
-
routings
Workday Calendar Build
You have the option of building the workday calendar in the VCP server by providing just summary information: calendar start date, end date, shift information, workday pattern and exceptions. The preprocessor has an embedded calendar build program, which will explode this data to get the working and nonworking days and also the shifts available for each working day. You must specify the workday calendar code for each planning organization that you upload into the VCP server. Otherwise, the record for the planning organization will not be accepted. You may want to rebuild the calendar if there is a change in the summary information at the source. This can be easily achieved by just uploading the new summary information with the calendar's OVERWRITE_FLAG set to 'Y'.
Purge Program
You can purge all uploaded data or selectively purge supply and demands with dates on or before a date that you specify. However, calendars, planning organizations, suppliers and customers cannot be purged. Except for the calendar, these can be disabled if required.
Customization
You may want to add custom validations to enable preprocessing to filter out unwanted incoming data. The preprocessing engine provides hooks for each entity that can be used to plug in custom validations.
Setting Up Legacy Instance
To set up legacy instance
The system default installation creates one instance partition and five plan partitions. Use this process if you need to create an instance partition.
-
From the System Administrator responsibility, select Requests > Run.
The Submit a New Request screen appears.
-
Select Single Request and select the OK button.
The Submit Request form appears.
-
In the Name field, select Create APS Partitions and select the OK button.
The Parameters screen appears.
-
Enter the number of plan partitions and instance partitions and select the OK button.
The partitions are created.
-
Change to the Advanced Planning Administrator responsibility. From the Navigator, select Admin > Instances.
The Application Instances screen appears.
-
Specify the Instance Code for the legacy instance and set the Instance Type as Other. Leave the fields From Source to APS and From APS To Source blank. Fill the other fields for the instance as specified in the online help.
You are now set to use the batch upload solution. Using the Running Legacy Collections process described below, upload the Workday Calendar data and Planning Organizations for this instance. This data can be uploaded along with the other entities' data. Preprocessing has the intelligence to consider the new organizations that have come in the same batch upload. After Legacy Collection is completed, you can view these organizations using the Organizations button at the bottom of the Instance Setup form.
Note: Setting up batch uploads and setting up legacy instance steps can occur in parallel up to creation of scripts for data uploads. However, for getting the data files from the scripts, the instance code is required.
-
Error messages for errors that occurred during preprocessing can be sent to the system administrator if Oracle XML Gateway is installed. You can specify the email address for sending the error messages using the Profile ECS: System Administrator Email Address.
-
For enabling XML inbound/outbound for the planning system, you need to install the Oracle XML Gateway. After the planning organizations have been collected, the valid transactions for each of these organizations can be registered in the XML Gateway. To configure the XML Gateway, please refer to the Oracle XML Gateway User Guide.
Running Legacy Collections Using the Form-Based Application (Collect Flat-File Data)
Using either an Oracle Applications form or the self-service application page, you can upload data from flat files to the legacy instance and finally to the planning engine. Using the form, you upload each data file separately.
Using the self-service method, you can upload a zip file containing all data files. Each type of data file, such as work order supply or BOM header, is identified using a tag in the file name. Ensure that you do not zip the entire directory but add individual files to the zip file.
To collect into a legacy instance using the form-based application
-
Copy all the data files conforming to the control files in the $MSC_TOP/patch/<version>/import in a directory on the concurrent manager node. If there are more than one concurrent manager nodes and if these are not NFS mounted, then the data files need to be copied to all the nodes in same directory structure. This directory (or all the directories in case of multiple non-NFS mounted concurrent manager nodes) should have read/write privileges to all users, because SQL*Loader discards files for the data that could not be uploaded due to errors.
-
Choose the Advanced Supply Chain Planner, Standard responsibility.
-
In the Navigator, choose Collections > Legacy Systems > Collect Flat File Data.
The Planning Data Collection screen appears showing three programs: Flat File Loader, Pre-Process Monitor, and Planning ODS Load. Planning ODS Load moves the data from the staging tables to the ODS.
-
Choose the Parameters field for Flat File Loader.
The Parameters screen appears.
-
Enter the required information and the File Names for all the data files that you want to upload. You can either enter the directory path in the Data File's Directory field and then enter the file names for each entity to be uploaded in the File Name fields, or you can leave the Data File's Directory field blank and enter the complete path and file name of each entity in the File Name fields. The second option is useful if all the data files are not kept in the same directory.
The Total Number of Workers field specifies the number of maximum number of loader workers that should be running in parallel at any given point in time. A loader worker is launched for each file name specified.
-
When finished entering information for this screen, choose the OK button.
-
Choose the Parameters field for Pre-Process Monitor.
The Parameters screen appears.
-
Specify the entities that you want to be preprocessed for the legacy instance.
The Processing Batch Size field determines the size of batches while processing the records in the staging tables. A larger batch size is faster but requires more system resources. The current default batch size is 1000.
The Total Number of Workers field specifies the number of concurrent processes to be launched to process the data in parallel.
-
When finished entering information for this screen, choose the OK button.
-
Choose the Parameters field for Planning ODS Load.
The Parameters screen appears.
-
This program moves data from the staging tables to Oracle Value Chain Planning's main tables (ODS). Specify whether you want the Sourcing History to be recalculated or purged after the data has been moved, and whether you want to refresh the collected data in the Advanced Planning Command Center (APCC).
-
When finished entering information for this screen, choose the OK button.
The Planning Data Collection screen appears.
-
Press the Submit button to allow the concurrent manager to schedule the request as per the schedule options that you specify.
-
Use the View Requests Form to monitor the progress of the different programs.
-
Using the Advanced Supply Chain Planner responsibility, navigate to Collections > View Collected Data menu option to view the data coming into the planning server.
Running Legacy Collections Using the Self-Service Application (Collect Flat-File Data - Self Service)
The self-service application is used for small amounts of data.
To collect into a legacy instance using the self-service application
-
From the Advanced Supply Chain Planner (or Advanced Planning Administrator) responsibility, navigate to Collections > Legacy Systems > Collect Flat File Data - Self Service.
The Oracle Collaborative Planning page appears.
-
Click the Download link to download the Oracle Applications (OA) template.
All zipped .dat files, for example, bills of material and calendar appear.
You can read the OATemplateReadme.html file for information on how to load various entities into Oracle VCP using flat files. Open the ExcelLoad.xlt file, and import your data files from the APS menu to view and modify them.
Note: Resource Balance Flag: Indicates whether a resource is load balanced. Valid values are:
-
1: Yes
-
2: No
This flag is only for Oracle Process Manufacturing. Since you cannot use legacy collections with Oracle Process Manufacturing, always leave this field null.
Unit of Measure: Load all base unit of measure comversions without an item name This creates rows in MSC_UOM_CONVERSIONS with INVENTORY_ITEM_ID = 0, for example:
-
Base UOM: LB
-
Standard conversions: KG - LB, Gram - LB, Kiloton - LB, mg - LB, Oz - LB, Ton - LB,
For specific conversions across UOM Class or specific intra-class unit of measure conversions for some items, load them using the item name
-
-
When all files have been imported to the templates, zip the files.
-
From the Oracle Collaborative Planning page, File Name field, click Browse to navigate to the zip file location.
-
Select the zip file containing the data files to be uploaded.
-
Click Start Load Now.
The concurrent request starts. You can note down the request id for your reference.
After the completion of this request, navigate to Collections Workbench to view the collected data.
Purging Legacy Data
There are two options for purging legacy data:
-
Purge Collected Data deletes the data from the ODS table as well as the local id table (MSC_LOCAL_ID_XXX).
-
Purge StagingTables purges Oracle Applications and legacy data from the staging tables. Use it before launching new collections when a previous data collection run failed, or if you find data corruption in the staging tables.
To purge collected data
-
Choose the Advanced Supply Chain Planner responsibility.
-
From the Navigator, choose Collections > Legacy System > Purge Collected Data. The Purge Parameters window appears.
The following table shows the values for this screen.
Field Value Instance Legacy source instance against which the purge program is to be run. Complete Refresh Specify whether to perform a complete refresh or not. Valid values: No, Yes. Delete Records Up to Date The date range up to which all the records will be deleted from the collected data. Defaults to the current date. Delete Supplies Specify whether to delete supply-related entries from the collected data. Valid values: No, Yes (will always be Yes if complete refresh is Yes). Delete Demands Specify whether to delete demand-related entries from the collected data. Valid values: No, Yes (will always be Yes if complete refresh is Yes).
Example: Complete Refresh = Yes, Delete Supplies and Demands
In this case, the following tables get purged from ODS:
MSC_SYSTEM_ITEMS
MSC_BOMS
MSC_BOM_COMPONENTS
MSC_COMPONENT_SUBSTITUTES
MSC_ROUTINGS
MSC_ROUTING_OPERATIONS
MSC_OPERATION_RESOURCES
MSC_OPERATION_COMPONENTS
MSC_OPERATION_RESOURCE_SEQS
MSC_PROCESS_EFFECTIVITY
MSC_DEPARTMENT_RESOURCES
MSC_RESOURCE_SHIFTS
MSC_RESOURCE_CHANGES
MSC_SIMULATION_SETS
MSC_PROJECTS
MSC_PROJECT_TASKS
MSC_ITEM_CATEGORIES
MSC_DESIGNATORS (Here program updates disable date as current date instead of deleting)
MSC_DEMANDS
MSC_SALES_ORDERS
MSC_SUPPLIES
MSC_INTERORG_SHIP_METHODS
MSC_ABC_CLASSES
MSC_ST_RESOURCE_GROUPS
MSC_ST_DEMAND_CLASSES
MSC_ST_RESERVATIONS MSC_ST_SAFETY_STOCKS
In addition, the entities listed in the following table, which are stored in the LID table will be deleted.
| Entity Name | LID Table Name | Business Object |
|---|---|---|
| SR_INVENTORY_ITEM_ID | MSC_LOCAL_ID_ITEM | Item |
| ABC_CLASS_ID | MSC_LOCAL_ID_MISC | Item |
| BILL_SEQUENCE_ID | MSC_LOCAL_ID_SETUP | BOM |
| COMPONENT_SEQUENCE_ID | MSC_LOCAL_ID_SETUP | BOM |
| ROUTING_SEQUENCE_ID | MSC_LOCAL_ID_SETUP | Routing |
| OPERATION_SEQUENCE_ID | MSC_LOCAL_ID_SETUP | Routing |
| RESOURCE_SEQ_NUM | MSC_LOCAL_ID_SETUP | Routing |
| DEPARTMENT_ID | MSC_LOCAL_ID_SETUP | Department/Resources |
| LINE_ID | MSC_LOCAL_ID_SETUP | Department/Resources |
| RESOURCE_ID | MSC_LOCAL_ID_SETUP | Department/Resources |
| PROJECT_ID | MSC_LOCAL_ID_MISC | Project/Tasks |
| TASK_ID | MSC_LOCAL_ID_MISC | Project/Tasks |
| COSTING_GROUP_ID | MSC_LOCAL_ID_MISC | Project/Tasks |
| SR_CATEGORY_ID | MSC_LOCAL_ID_MISC | Categories |
| DISPOSITION_ID_FCT | MSC_LOCAL_ID_DEMAND | Demand (Forecast) |
| DISPOSITION_ID_MDS | MSC_LOCAL_ID_DEMAND | Demand (MDS) |
| SALES_ORDER_ID | MSC_LOCAL_ID_DEMAND | Demand (Sales Order) |
| DEMAND_ID | MSC_LOCAL_ID_DEMAND | Demand (Sales Order) |
| DISPOSITION_ID | MSC_LOCAL_ID_SUPPLY | Supplies |
| PO_LINE_ID | MSC_LOCAL_ID_SUPPLY | Supplies (PO/Req) |
| SCHEDULE_GROUP_ID | MSC_LOCAL_ID_SUPPLY | Supplies (MPS) |
| DISPOSTION_ID_MPS | MSC_LOCAL_ID_SUPPLY | Supplies (MPS) |
| SR_MTL_SUPPLY_ID | MSC_LOCAL_ID_SUPPLY | Supplies (On Hand) |
| WIP_ENTITY_ID | MSC_LOCAL_ID_SUPPLY | Supplies (WIP) |
The Purge program does not delete records related to following business objects from ODS or LID tables.
-
Trading partners (organization, supplier, customer)
-
Calendars
-
Category sets
-
Sourcing rules
-
UOM
Note: For the items in the _LID tables, a complete refresh for ALL organizations deletes the data. When the profile option MSC: Purge Staging and Entity Key Translation Tables is set to Y, then the ID_LID tables are truncated during the key transformation in the ODS load phase.
Example: Complete Refresh = No, Delete Supplies and Demands
If you do not request a complete refresh, only supply/demand business object records and those records whose creation date is less than the user-entered date get deleted from the ODS and LID tables.
To purge staging tables
-
Use the Advanced Supply Chain Planner responsibility.
-
From the Navigator, choose Collections > Legacy System > Purge Interface Tables. The Submit a New Request window appears.
-
Select Single Request and click OK. The Submit Request window appears.
-
Select Purge Interface Tables from the Reports list. The Parameters window appears.
-
Set the parameters and click Submit.
The following table shows the values for this screen.
Field Value Instance Legacy source instance against which the purge program is to be run. Delete Rejected Records Only Specify whether to delete only the rejected records or all records.
SRP Streams - Self Service
Legacy collections are supported for usage history for Demantra. Legacy collections of Install Base under Contracts are not currently supported. For more information about the EBS Service Parts Planning to Demantra Demand Management Integration, see "Demantra Demand Management to EBS Service Parts Planning Integration" in the Oracle Demantra Integration Guide.
To load usage history
-
From the Advanced Supply Chain Planner responsibility, navigate to Collections > Legacy > SRP Streams - Self Service. The Load SRP Streams form appears.
-
File Name: Specify the legacy data file. In the case of multiple files, the planner can unload a zip file with the individual .dat files.
Note: You can download templates for individual .dat files from this page.
-
Launch Download: Check this option if you would like to begin the download and launch the Demantra SPF Full Download workflow.
-
Instance: Choose from the available source instances.
-
Click Start Load Now to load the legacy data file(s) now.
Shipment History - Self Service
Legacy collections are supported for shipment history for Demantra. For more information, see:
-
"Demantra Demand Management to EBS Service Parts Planning Integration" in the Oracle Demantra Integration Guide
-
"Demantra Predictive Trade Planning to Siebel Integration" in the Oracle Demantra Integration Guide
.
To load usage history
-
From the Advanced Supply Chain Planner responsibility, navigate to Collections > Legacy > Shipment History - Self Service. The Load Shipment History form appears.
-
File Name: Specify the legacy data file. In the case of multiple files, the planner can unload a zip file with the individual .dat files.
Note: You can download templates for individual .dat files from this page.
-
Launch Download: Check this option if you would like to begin the download and launch the Demantra SPF GL Data Download workflow.
-
Instance: Choose from the available instances.
-
Click Start Load Now to load the legacy data file(s) now.