| Oracle® Enterprise Data Quality for Product Data Fusion PIM Integration Implementation and User's Guide Release 11g R1 (11.1.1.6) Part Number E29148-02 |
|
|
PDF · Mobi · ePub |
| Oracle® Enterprise Data Quality for Product Data Fusion PIM Integration Implementation and User's Guide Release 11g R1 (11.1.1.6) Part Number E29148-02 |
|
|
PDF · Mobi · ePub |
This chapter describes how to maintain your EDQP DSAs and data lens using the real time synchronization with Fusion PIMDH. These best practices have been developed so that you can easily ensure that your changing data is processed correctly.
The data lens generated by Autobuild contains the structure you need for the PIM metadata synchronization. The Item Definitions, attributes, phrases, and terms have been created from the PIM export metadata; term rules and standardization rules can be modified in order to adequately handle the variability seen in production data.
In order to keep your data lens synchronized with the PIM metadata, there are editing restrictions on certain data lens elements: All additions, deletions, and renames should be done only in synchronization with Fusion PIMDH. Unless your metadata has changed, and you are performing deletions based on changes reported in the Semantic Knowledge Structure report, these guidelines should be followed:
Neither add nor delete Item Definitions.
Neither add nor delete attributes from any Item Definitions.
Do not modify the Item Definition Attribute Alias. If the alias is modified, the standardized attribute value cannot be loaded into PIMDH.
Value set guidelines:
Do not add any values to the value set phrase rules.
It is permissible to add term variants to the valid value term rules.
The following is an overview of recommendations for refining your data lens in the EDQP Knowledge Studio:
Ensure that the required attributes in the Item Definition are being recognized.
If the ICC name is not identical to the item name found in product data, use the following steps in Knowledge Studio:
Add term and phrase rules to your data lens.
Associate the new phrase rule with the appropriate required attribute in your Item Definition.
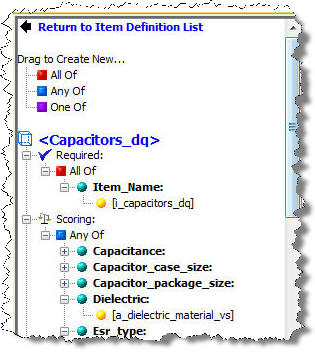
Review and resolve ambiguities.
If there are any recognition or Item Definition ambiguities in your sample data, review and resolve them.
Increase recognition coverage.
Using your data lens sample data files, apply the standard data lens development methodology for completing recognition as appropriate.
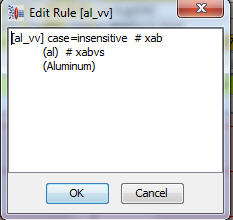
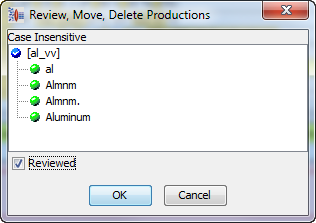
You may need to increase the coverage of your data lens to account for variants of attribute values found in your sample data. As you review your sample data files, examine the unrecognized text. If you encounter any tokens which should be associated with terms and attributes in your data lens, add them. In the following example, the selected line, "AL" is recognized as being a member of a valid value within a value set. In the following line of data the token "Aluminum" is unrecognized.
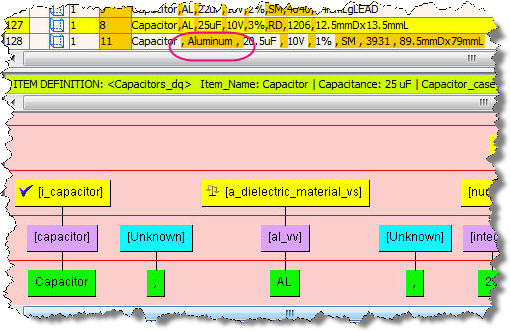
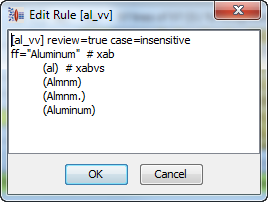
Since "Aluminum" is a variant of the valid value "AL", the token "Aluminum" should be added as a term variant to the term rule [al_vv]:
Review Units of Measure.
As previously described, if a unit of measure is specified in the column ATTR_BASE_UOM_CODE that is not present in the data lens, then it must be added to the appropriate term rule because AutoBuild does not add it. Then, you should examine the relevant Item Definition attribute and associate the modified UOM phrase rule with it.
Review term and phrase standardizations.
Examine the standardized attribute values in the tabs Standardize Items | Test Attributes.
Term Standardization - Many of the term standardization rules in the Match_Attributes Standardization Type may have been provided by the Smart Glossary import used in the AutoBuild process. Review these standardization rules and either keep or modify them.
Phrase concatenation - Some of your multi-term attribute values may require concatenation.
Note:
If you selected the Create Replace all Rules option in AutoBuild, the preceding standardization occurs automatically.Match rules.
Review the match type and match rules associated with Match_Attributes. The Exact_Match rules have been created based on data from the metadata export.
Activation of Item Definitions.
By default, the Item Definitions are inactive upon finishing the Autobuild process. Activate your Item Definitions before running a DSA that processes data through your data lens.
Refine Item Definitions.
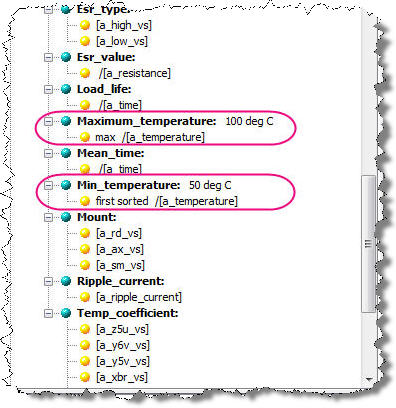
Use search logic and value logic as necessary. The use of search logic is necessary to constrain the attribute values in the following example. The following line of data contains two temperature values:
Capacitor,AL,22uF,10V,50 deg C, 100 deg C,1%,RD,.10S,10mmDx16mmL
Use of value logic in the Item Definition is necessary to correctly associate the minimum and the maximum temperature values with the correct attributes.
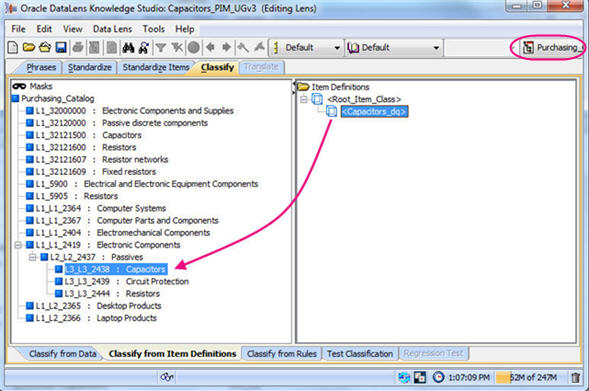
If you have added an Alternate Catalog, classify your data.
Using standard classification methodology, create classification rules by classifying from Item Definitions, Rules or Data.
After making your refinements, check in your data lens and deploy it to Production.
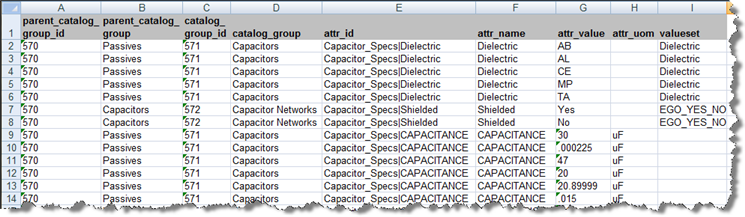
Certain attributes may have been set up in PIM to have value sets and valid values. The attribute values are restricted such that only the values specified are valid. When you create a Semantic Model, this value set and valid information is exported from the Fusion PIMDH and it appears in your metadata worksheet. The data lens created from the metadata will reflect the valid value and value set information from the metadata worksheet. If there is a value set for an attribute, the VALUESET column will be populated with the name of the value set, and the valid values appear in the attr_value column as in the following example:
There are two types of value sets: Standard Value Sets and Yes/No Value Sets. The following describe how EDQP handles them in a data lens:
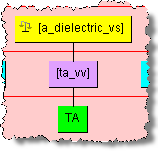
In a standard value set, the valid values correspond to the standardized forms of attribute values that are likely to be found in product data. In this example, 'Dielectric' is the attribute identified in the 'value set' column and 'AB', 'AL', 'CE', 'MP', and 'TA' in the 'attr_value' column. The value is considered to be an abbreviation unless it exceeds four characters, in which case, the fullform in the EDQP Knowledge Studio is set to this value. For example using the metadata in "Value Set Example Spreadsheet", 'AL' would set the term as an abbreviation while 'Aluminum' would set it to the full form. The phrase structure for the abbreviation is:
The Yes/No value set is a special form of the value set; this value set has 'yes' and 'no' (and alternate forms, such as 'y' and 'n') as the valid values. For example, using the metadata in "Value Set Example Spreadsheet", the value set is a yes/no value set, and the valid values are "yes" and "no". The data lens is created such that there are phrase and term rules to recognized forms of "shielded" and "not-shielded". Additionally, the standardization rules for these 'y' and 'n' attributes will be set to "yes" and "no". The phrase structure for the yes, or shielded, term is:
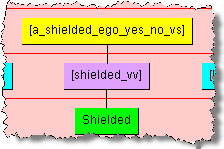
All variations of both yes and no are created in the data lens. For example, the variations of 'not shielded' would be:
In the data lens, all value set phrase rule names are created with a '_vs' appended to the attribute and '_vv' appended to the term rule name so that they are easily identified in phrase structures.
Refining value set phrase structures in the Knowledge Studio is the same as described in the previous section. Since it is possible for some text nodes and term rules to be recognized by multiple rules, it is necessary to review those attribute in your data lens that are based on value sets. For example, the 'Aluminum' attribute could be a production of the 'a_dielectric_vs' phrase rule. When appropriate, it is important to refine your data lens value sets by adding the full forms for the valid value term rules which are abbreviations. For example, you will need to add the term variant 'aluminum' to the term rule 'al_vv'. Additionally, set the full form to be 'aluminum. Using the 'Aluminum' example as in the following phrase rule:
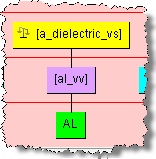
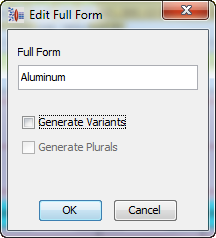
You would edit the 'al_vv' term and add the 'Aluminum' full form (variants can be generated as well):
Then review the phrase rule to ensure that it was added properly:
Finally, review the productions of the 'a_dielectic_vs' phrase rule:
Note:
Since AutoBuild ignores duplicate phrase productions when created from a value set, you should review all productions carefully.Using Autobuild, you can synchronize your Fusion PIMDH metadata with your data lenses. It is possible that your metadata may change over time. You may have new categories, attributes, or attribute values or changes in attribute names. Attributes may be deleted from categories. Using AutoBuild you can synchronize your Item Definitions with your ICCs.
After creating a new metadata import spreadsheet reflecting the changes in metadata, you run Autobuild and update an existing data lens thus revising with the changes. The following actions occur:
AutoBuild reports on four types of changes in the metadata and this information is reported in the Semantic Knowledge Structure sheet in your metadata import workbook:
New metadata.
Renamed metadata. Entity existed in prior version of lens, and has received a new name in the current metadata
Existing metadata. No change compared to previous version.
Not present in metadata. Entity existed in previous version, but not in current version and thus should be deleted from data lens.
AutoBuild makes the specified changes to category and attribute names in your data lens.
AutoBuild adds the specified new category, attribute, or value information to your data lens.
You must manually delete any items not present in current metadata. Autobuild does not perform deletions to your data lens. Refer to the AutoBuild Semantic Knowledge Structure report for guidance.
In the following example, the shaded cells represent new metadata:
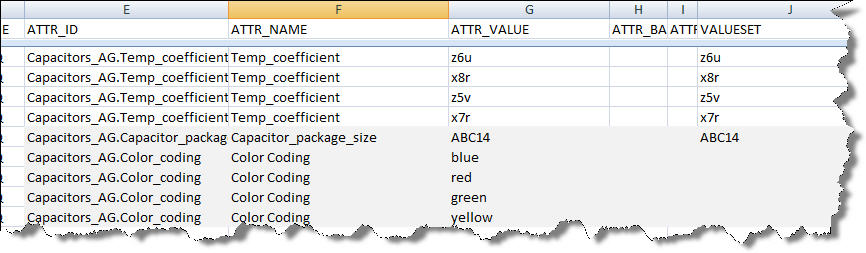
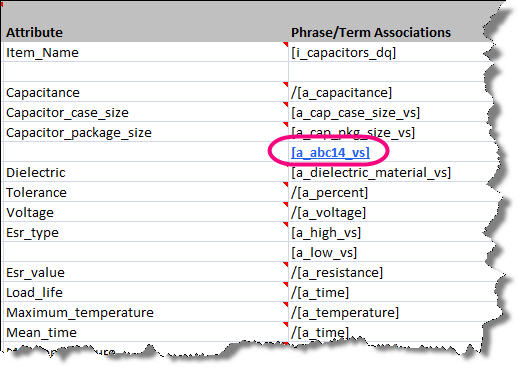
This additional information is represented in the Semantic Knowledge Structure report as follows. The attribute "Capacitor_package_size" has a new attribute value.
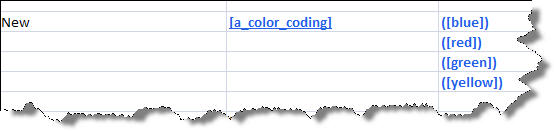
This report also reports new term rules as follows:
The attribute 'Mount' was renamed to 'Mount_type' as in the following example:

If your PIM data contains renamed item definitions or attribute, be sure to confirm that these renames are reflected in the data lens. Manual renaming may be required.
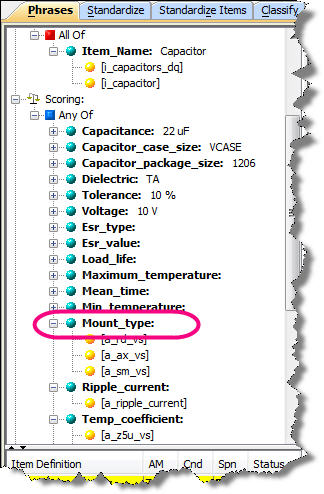
To determine if a deletion should be made in the data lens, the user should review the AutoBuild report and examine all items flagged as 'DELETE'. If a category, attribute, or attribute value is not present in the current metadata export file, but was in the previous version of the metadata export, it is identified as a 'DELETE' in the AutoBuild report.

In the preceding figure, there are two deletions. The first rule tagged for deletion represents a value set value that was absent from the current export of the Fusion PIMDH DQ metadata. Both the phrase rule and term rule must be manually deleted from the data lens as in the following:
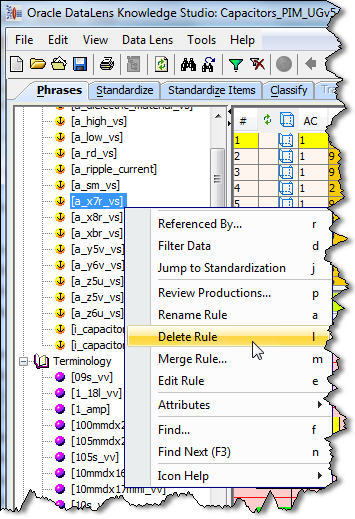
The second rule tagged for deletion is '[i_capacitor]' and should remain in the data lens because this rule was manually added to the data lens in order to recognize the item in product data. This rule is used as the required item name attribute in the Item Definition, and thus should remain in the data lens.
|
Copyright © 2012, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|