| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
モデルをテストすることによって、モデルの予測の正確性を推測できます。分類モデルと回帰モデルをテストし、分類モデルをチューニングできます。
この項では、次の項目について説明します。
分類モデルは、テスト・データセット内の既知のターゲット値と予測値を比較することによってテストされます。通常、分類プロジェクト用の履歴データは、次の2つのデータ・セットに分割されます。
モデルの構築用
モデルのテスト用
モデルを適用するテスト・データは、モデルの構築で使用したデータと互換性があることが必要で、モデル構築データが準備されたのと同じ方法で準備される必要があります。
分類モデルと回帰モデルをテストするには、次の方法があります。
入力データを構築データとテスト・データに分割します。これがデフォルトです。テスト・データは、構築データを2つのサブセットにランダムに分割することによって作成されます。入力データの40%がテスト・データに使用されます。
すべての構築データをテスト・データとして使用します。
2つのデータ・ソース・ノードを構築ノードにアタッチします。
構築ノードに接続する最初のデータ・ソースは、構築データのソースです。
接続する2番目のノードは、テスト・データのソースです。
「プロパティ」ペインの「テスト」セクションで「テストの実施」の選択を解除し、テスト・ノードを使用します。「テスト」セクションではテストの実施方法を定義します。デフォルトでは、すべての分類モデルと回帰モデルがテストされます。
Oracle Data Minerは、モデルを評価できるように分類モデルのテスト・メトリックを提供します。
テスト後、モデルをチューニングできます。
テスト・メトリックでは、既知の値をモデルがどれくらい正確に予測するかを評価します。テスト設定では、計算するメトリックを指定し、メトリックの計算を制御します。デフォルトでは、Oracle Data Minerは分類モデルの次のメトリックを計算します。
パフォーマンス測定、予測信頼度、平均精度、全体精度およびコスト
パフォーマンス・マトリックス(コンフュージョン・マトリックスとも呼ばれます)
プリファレンス設定を使用してデフォルトを変更できます。
テスト結果を表示するには、最初にノードのモデルをテストします。
分類ノードでデフォルト・テストを使用してモデルをテストした場合は、次の手順を実行します。
分類ノードを実行します。
ノードを右クリックし、「テスト結果の表示」を選択します。
モデルを表示するには、目的のモデルを選択します。分類モデル・テスト・ビューアが開きます。
ノードのすべてのモデルのテスト結果を比較するには、「テスト結果の比較」を選択します。
テスト・ノードを使用してモデルをテストした場合は、次の手順を実行します。
テスト・ノードを実行します。
ノードを右クリックし、「テスト結果の表示」を選択します。
モデルを表示するには、目的のモデルを選択します。分類モデル・テスト・ビューアが開きます。
ノードのすべてのモデルのテスト結果を比較するには、「テスト結果の比較」を選択します。
次のパフォーマンス・メジャーが計算されます。
これらの値は、個別に表示することも、すべてを同時に表示することもできます。パフォーマンス・メジャーを表示するには、次の手順を実行します。
表示するメジャーを選択します。または、「メジャー」リストから「すべてのメジャー」を選択します。
「ソート基準」リストを使用してメジャーをソートします。次の項目でソートできます。
名前(デフォルト)
メジャー
作成日。
ソートは降順(デフォルト)または昇順を指定できます。
予測信頼度では、モデルの精度の推定値が提供されます。予測信頼度は、0から1までの数値です。Oracle Data Minerでは、予測信頼度はパーセンテージで表示されます。たとえば、59の予測信頼度は、59% (0.59)の予測信頼度を意味します。
予測信頼度は、テストしたモデルによる予測がナイーブ・モデルによる予測よりどの程度適切かを示します。ナイーブ・モデルでは、数値ターゲットの平均値およびカテゴリ・ターゲットの最頻値が常に予測されます。
Predictive Confidence = MAX[(1-Error of model/Error of Naive Model),0]X100
各要素の意味は次のとおりです。
モデルのエラーは(1 - 平均精度/100)
ナイーブ・モデルのエラーは(ターゲット・クラスの数- 1)/ターゲット・クラスの数
予測信頼度が0の場合、モデルの予測がナイーブ・モデルを使用した予測と同程度であることを示します。
予測信頼度が1の場合、予測が完全であることを示します。
予測信頼度が0.5の場合、モデルによりナイーブ・モデルのエラーが50%削減されたことを示します。
平均精度とは、モデルによる予測が、テスト・データでの実際の分類と比較してどの程度正確かをパーセンテージで表したものです。平均精度を計算する式は次のとおりです。
Average Accuracy = (TP/(TP+FP)+TN/(FN+TN))/Number of classes*100
各要素の意味は次のとおりです。
TPは真陽性。
TNは真陰性。
FPは偽陽性。
FNは偽陰性。
各クラスの平均精度は、可能性がある他のすべてのしきい値で得られる精度よりも高い特定の確率しきい値で得られます。
全体精度とは、モデルによる予測が、テスト・データでの実際の分類と比較してどの程度正確かをパーセンテージで表したものです。全体精度を計算する式は次のとおりです。
Overall Accuracy = (TP+TN)/(TP+FP+FN+TN)*100
各要素の意味は次のとおりです。
TPは真陽性。
TNは真陰性。
FPは偽陽性。
FNは偽陰性。
分類の問題では、不適切な決定に伴うコストの指定が重要になる場合があります。指定することで、誤った分類によるコストが極端に異なっている場合に役立つことがあります。
たとえば、問題はユーザーが販促の郵便物に応答するかどうかを予測することであるとします。ターゲットには、YES (顧客が応答する)とNO (顧客が応答しない)の2つのカテゴリがあります。販促に対してポジティブで応答すると$500が生成され、郵送のコストは$5になります。この場合、シナリオは次のとおりです。
モデルでYESが予想され、実際の値がYESの場合、誤った分類のコストは$0です。
モデルでYESが予想され、実際の値がNOの場合、誤った分類のコストは$5です。
モデルでNOが予想され、実際の値がYESの場合、誤った分類のコストは$500です。
モデルでNOが予想され、実際の値がNOの場合、誤った分類のコストは$0です。
分類のアルゴリズムでは、最もコストのかからない解決を提案するため、スコアリング時にコスト・マトリックスが使用されます。コスト・マトリックスを指定しない場合、すべての誤った分類が等しく重要であるとみなされます。
SVMモデルを構築する場合は、コスト・マトリックスではなくモデルの重みを使用してコストを指定します。
パフォーマンス・マトリックスは、モデルによる予測をテスト・データでの実際の分類と比較した場合の、正確な予測と不正確な予測の数を表したものです。構築データから取得した検証サンプル(分類アクティビティの分割ステップで作成されたテスト・セット)にモデルを適用することによって計算されます。ターゲットの値は既知です。既知の値がモデルによって予測された値と比較されます。パフォーマンス・マトリックスでは、次のことを行います。
モデルの可能性を測定し、誤った値と正しい値を予測します
モデルによって発生する可能性があるエラーのタイプを示します
列が予測値、行が実際の値となります。たとえば、0と1の値を持つターゲットを予測する場合、マトリックスの右上のセルの数値は偽陽性の予測を示します。つまり、実際の値が0の場合は1の予測を示します。
受信者操作特性(ROC)分析は、分類モデルの評価に役立つ方法です。ROCは2項分類のみに適用されます。ROCは曲線として描画されます。ROC曲線下面積により、2項分類モデルの識別能力が測定されます。ROCしきい値の正確な値は、モデルで解決しようとしている問題によって異なります。
ROC曲線は、個々のモデル間で比較する手段を提供し、高比率のポジティブ結果が得られるしきい値を決定するという点で、リフト・グラフに似ています。ROC曲線では、次のことを行います。
個々のモデルを比較し、高比率のポジティブ結果が得られるしきい値を決定する手段を提供します。
モデルの意思決定能力を的確にとらえることができます。たとえば、モデルがどの程度正確にネガティブ・クラスまたはポジティブ・クラスを予測できるかを判断できます。
分類モデルにおいて予測値と実際のターゲット値を比較します。
受信者操作特性(ROC)では、what-if分析がサポートされています。ROCを使用して、変更されたモデル設定を試し、パフォーマンス・マトリックスに対する効果を確認できます。たとえば、ビジネスの問題で、ポジティブ予測の数がある固定数以下であるという要件の制約内で偽陰性値を可能なかぎり減らす必要があるとします。高い値が予想される各顧客にインセンティブを提供できますが、予算により、最大で170のインセンティブに制約されます。一方、偽陰性は失った機会を表すため、そのような誤りを防ぐ必要があります。
パフォーマンス・マトリックスの変更を表示するには、次の手順を実行します。
右上隅で「カスタム動作点の編集」をクリックします。「カスタムしきい値ダイアログの指定」ボックスが開きます。
「カスタムしきい値ダイアログの指定」ボックスで、目的の設定を指定し、変更を「カスタム精度」フィールドに表示します。
パフォーマンス・マトリックスを変更すると、ポジティブ予測になる確率を変更することになります。通常、各ケースに割り当てられた確率が調べられ、確率が0.5以上の場合、ポジティブ予測が行われます。コスト・マトリックスを変更すると、ポジティブ予測しきい値が0.5以外の値に変更され、変更された値がグラフの下にある表の最初の列に表示されます。
リフトは、ランダムに生成された予測と比較して、分類モデルの予測がどの程度信頼できるかを計算したものです。リフトは2項分類と非2項分類に適用されます。
リフトでは、モデルにより実際の正数のターゲット値が検出される速さを測定します。たとえば、リフトでは、オファーに応答する可能性がある顧客の50%を把握するにはどれだけの顧客データベースを調べる必要があるかを計算できます。
グラフのx軸は分位に分割されます。グラフ上にカーソルを置くと、正確な値が表示されます。グラフの下で、選択した分位を使用して目的の分位を選択できます。デフォルトの分位は、分位1です。
リフトを計算するために、Oracle Data Miningは次の処理を実行します。
テスト・データにモデルを適用し、予測されたターゲット値と実際のターゲット値を収集します。これは、パフォーマンス・マトリックスの計算に使用される同じデータです。
予測された結果を確率、つまり、ポジティブ予測の信頼度でソートします。
ランク付けされたリストを等しい部分(分位)に分割します。デフォルトは100です。
各分位の実際の正の値をカウントします。
リフトは、「累積リフト」または「累積陽性例」(デフォルト)のいずれかとしてグラフ表示できます。グラフを変更するには、「表示」リストから適切な値を選択します。「ターゲット値」リストでターゲット値を選択することもできます。
利益では、最大限の利益を得るために、開始コスト、増分収益、増分コスト、予算および母集団にユーザー指定の値が使用されます。
Oracle Data Minerでは、利益は次のように計算されます。
Profit = -1 * Startup Cost + (Incremental Revenue * Targets Cumulative - Incremental Cost * (Targets Cumulative + Non Targets Cumulative)) * Population / Total Targets
利益は、正または負の場合があります。つまり、損失となる場合があります。
このモデルで予測される利益を表示するには、目的の「ターゲット値」を選択します。選択した母集団%を変更できます。デフォルトは1パーセントです。
投資利益率(ROI)とは、投資金額に対する投資で得たまたは失った(実現しているかいないかに関係なく)金額の割合のことです。Oracle Data Miningでは、次の式が使用されます。
ROI = ((profit - cost) / cost) * 100 where profit = Incremental Revenue * Targets Cumulative, cost = Incremental Cost * (Targets Cumulative + Non Targets Cumulative)
この例では、利益およびROIの計算方法を示します。
利益を計算する手順:
利益は分位に対して計算されます。この例では、分位20に対する利益およびROIを計算します。
リフト・グラフ・データを参照して、分位20の累積ターゲットの値を見つけます。この値が18であるとします。
分位20の累積非ターゲットの値が2であるとします。リフト・グラフを参照してこの値を見つけます。
合計ターゲットを計算します。これは、最後の分位の累積ターゲットに最後の分位の累積非ターゲットを加えたものです。この値が100であるとします。
次の値はすべてユーザーが指定します。ビジネスの問題に基づいて値を指定する必要があります。
開始コスト= 1000
増分収益= 10
増分コスト= 5
予算= 10000
母集団= 2000
次の式を使用して利益を計算します
Profit = -1 * Startup Cost + (Incremental Revenue * Targets Cumulative - Incremental Cost * (Targets Cumulative + Non Targets Cumulative)) * Population / Total Targets
この例で値を置換すると、次のようになります
Profit = -1 * 1000 + (10 * 18 - 5 * (18 + 2) * 2000 / 100 = 600
ROIを計算するには、次の式を使用します。
ROI = ((profit - cost) / cost) * 100 profit = Incremental Revenue * Targets Cumulative, cost = Incremental Cost * (Targets Cumulative + Non Targets Cumulative)
この例で値を置換すると、次のようになります
ROI = ((180 - 100) / 100) * 100 = 80
このユースケースでは、利益およびROI計算の結果を解釈する方法を示します。
通販キャンペーンを実行するとします。各顧客にカタログを郵送します。カタログから商品を購入する可能性がある顧客にカタログを郵送します。
「利益およびROIの例」の入力データを使用します
開始コスト= 1000。これはキャンペーンを開始するための総コストです。
増分収益= 10。これは販売または新規顧客による推定収益です。
予算= 10000。これは使用できる合計金額です。
母集団= 2000。これはケースの合計数です。
したがって、各分位に20ケースが含まれます。
total population /number of quantiles = 2000/100 = 20
各分位の販売促進のコストは、(増分コスト*分位当たりのケース数) = $5 * 20 = $100となります。
分位当たりの累積コストは次のとおりです。
分位1のコストは、$1000 (開始コスト) + $100 (分位1の販売促進のコスト) = $1100です。
分位2のコストは、$1100 (分位1のコスト) + $100 (分位2のコスト)です。
分位3のコストは、$1200です。
すべての中間値を計算した場合、累積コストは、分位90では$10,000、分位100では$11,000となります。予算は$10,000です。Oracle Data Minerで利益グラフを確認すると、90番目の分位の利益グラフに予算の線が描画されていることがわかります。
「利益およびROIの例」で、利益が$600、ROIが80%と計算しましたが、これは、母集団(400)の最初の20分位にカタログを郵送した場合、キャンペーンで(80%のROIを持つ) $600の利益が生まれることを意味します。
顧客の最初の20分位にカタログをランダムに郵送した場合、利益は次のようになります
Profit = -1 * Startup Cost
+ (Incremental Revenue * Targets Cumulative - Incremental Cost
* (Targets Cumulative + Non Targets Cumulative))
* Population / Total Targets
Profit = -1 * 1000 + (10 * 10 - 5 * (10 + 10)) * 2000 / 100 = -$1000
つまり、利益はありません。
分類モデルに関するこの項では、次の項目について説明します。
テスト・ビューアを開くには、分類ノード、または分類モデルをテストするテスト・ノードのコンテキスト・メニューで、「テスト結果の表示」または「テスト結果の比較」を選択します。表示する結果を選択します。
分類モデル・テスト・ビューアには次のタブが表示されます。
「パフォーマンス」タブには、生成された各モデルのパフォーマンスの全体的なサマリーが示されます。このタブには、複数の共通テスト・メトリックのテスト結果が表示されます。次の情報が表示されます。
すべてのメジャー(デフォルト)。「メジャー」リストでは、表示するメジャーを選択できます。デフォルトでは、すべてのメジャーが表示されます。選択したメジャーはグラフとして表示されます。複数のモデルのテスト結果を比較する場合は、各モデルにグラフで異なる色が割り当てられます。
コスト(コストを指定した場合、またはシステムによりコストが計算された場合)
「ソート基準」フィールドで、ソート属性およびソート順を指定できます。最初のリストは、ソート属性のメジャー、作成日または名前(デフォルト)です。2番目のリストは、ソート順の昇順または降順(デフォルト)です。
グラフの下の「モデル」表により、グラフに示された情報が補足されます。この表は、分割線を使用して最小化できます。「モデル」表にはヒストグラムのデータがまとめられています。
名前。モデルの名前およびグラフでのモデルの色。
予測信頼度パーセント
全体精度パーセント
平均精度パーセント
コスト、コストを指定した場合(コストはOracle Data Minerでディシジョン・ツリー用に計算されます)
アルゴリズム(モデル構築に使用されます)
作成日
デフォルトでは、選択したモデルの結果が表示されます。モデルのリストを変更するには、![]() をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、ヒストグラムとサマリー情報の両方が削除されます。
をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、ヒストグラムとサマリー情報の両方が削除されます。
パフォーマンス・マトリックスは、モデルによる予測をテスト・データでの実際の分類と比較した場合の、正確な予測と不正確な予測の数を表したものです。選択したモデルの詳細を表示するか、すべてのモデルのパフォーマンス・マトリックスを比較できます。
最初にモデルを選択します。1つのモデルのテスト結果を表示している場合は、そのモデルの詳細が自動的に表示されます。
上部ペインに、「平均精度」および「全体精度」が、各ターゲット値の正確な予測を表示するグリッドで表示されます。コストを指定した場合は、コスト情報が表示されます。
下部ペインに、実際の値を示す行と予測値を示す列を含む、選択したモデルの「パフォーマンス・マトリックス」が表示されます。正確な予測の割合およびコストが各列に表示されます。
合計、正確な予測の割合、および正確な予測と不正確な予測のコストを表示するには、「合計およびコストの表示」を選択します。
このオプションでは、ノードのテストされたすべてのモデルのパフォーマンス情報を比較します。
上部ペインに、各モデルについて次の情報が示されます。
正確な予測の割合
正確な予測の数。
合計ケース・カウント。
コスト情報。
さらに詳細を表示するには、モデルを選択します。
下部ペインに、上部ペインで選択したモデルのターゲット値の詳細が表示されます。メジャーを選択します。
正しい予測(デフォルト): ターゲット属性の各値の正しい予測が表示されます
コスト: ターゲットの各値のコストが表示されます
受信者操作特性(ROC)では、2項分類モデルにおいて予測値と実際のターゲット値を比較します。
ROCを編集および表示する手順:
「ターゲット」値を選択します。その値のROC曲線が表示されます。
「カスタム動作点の編集」をクリックして動作点を変更します。ROCグラフに各モデルのROCを示す線が表示されます。グラフの下部にあるキーに示された値を示す点がグラフ上でマークされます。グラフの下のROCサマリー結果表により、グラフに示された情報が補足されます。この表は、分割線を使用して最小化できます。
下部ペインの「モデル」グリッドには、次のサマリー情報が含まれています。
名前
曲線下の面積
最大全体精度パーセンテージ
最大平均精度パーセンテージ
カスタム精度パーセンテージ
モデル精度パーセンテージ
アルゴリズム
作成日時
モデルを選択して をクリックすると「ROC詳細ダイアログ」ボックスが表示され、確率しきい値の統計が表示されます。
をクリックすると「ROC詳細ダイアログ」ボックスが表示され、確率しきい値の統計が表示されます。
モデルのリストを変更するには、![]() をクリックして「テスト結果選択の編集」ダイアログ・ボックスを開きます。デフォルトでは、ノード内のすべてのモデルの結果が表示されます。
をクリックして「テスト結果選択の編集」ダイアログ・ボックスを開きます。デフォルトでは、ノード内のすべてのモデルの結果が表示されます。
結果を表示しないモデルのチェック・ボックスの選択を解除します。モデルの選択を解除した場合、そのモデルのROC曲線と詳細の両方が表示されません。
作業を終了後、「OK」をクリックします。
「ROC詳細ダイアログ」には、確率しきい値の統計が表示されます。確率しきい値ごとに次が表示されます。
真陽性
偽陰性
偽陽性
真陰性
真陽性比率
偽陽性比率
全体精度
平均精度
「OK」をクリックしてダイアログ・ボックスを閉じます。
リフト・グラフには、少なくとも次の3本の線が表示されます。
各モデルのリフトを示す線
ランダム・モデルの赤色の線
しきい値の青色の縦線
グラフのx軸は分位に分割されます。グラフでは、モデルからのリフトと、ナイーブ・モデル(ランダム)および理想リフトからのリフトが示されます。
リフト・ビューアは、複数のモデルの指定されたターゲット値のリフト結果を比較します。「累積陽性例」または「累積リフト」のいずれかが表示されます。
複数のモデルのリフトを比較する場合は、各モデルの線が異なる色で表示されます。グラフの下の表に、モデルの名前およびそのモデルの結果を表示するために使用された色が示されます。
ビューアには、次のコントロールがあります。
表示: 「累積陽性例」(デフォルト)または「累積リフト」のいずれかの表示オプションを選択します。
ターゲット値: 比較用のターゲット値を選択します。デフォルト・ターゲット値は、発生する頻度が最も低いターゲット値です。
しきい値は、分位の選択に使用される青色の縦線です。しきい値が移動すると、リフト詳細表の各テスト結果の詳細は、選択した分位に対応する「リフト・グラフ」上の点に変更されます。しきい値を移動するには、分位線上のインジケータをドラッグします。ここでは、分位は20に設定されています。

グラフの下のデータ表により、グラフに示された情報が補足されます。この表は、分割線を使用して最小化できます。
この表には次の列が含まれます。
名前。モデルの名前およびグラフでのモデルの色
累積リフト
累積利益パーセンテージ
パーセンテージ累積レコード
累積ターゲット密度
アルゴリズム
作成日(日時)
「モデル」グリッドの上部に「リフト詳細ダイアログ」アイコンがあります。モデルを選択してアイコンをクリックすると「リフト詳細ダイアログ」ボックスが開き、100分位のリフト詳細が表示されます。
モデルのリストを変更するには、![]() をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、そのモデルのリフト曲線と詳細情報の両方が表示されません。デフォルトでは、ノード内のすべてのモデルの結果が表示されます。
をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、そのモデルのリフト曲線と詳細情報の両方が表示されません。デフォルトでは、ノード内のすべてのモデルの結果が表示されます。
「リフト詳細ダイアログ」には、1から100までの各分位の統計が表示されます。「OK」をクリックしてダイアログ・ボックスを閉じます。
しきい値確率は、常に標準確率を反映するわけではありません。たとえば、分類ノードでは、次の3つの異なるパフォーマンス設定を指定できます。
平均化: すべてのターゲット・クラス値にバランス重みを適用します。
自然: 重みを適用しません。
カスタム: ユーザー作成のカスタム重みファイルを適用します。
分類モデルのデフォルトは「平均化」です。「平均化」は、使用されるアルゴリズムに応じて、モデルに重みまたはコストを渡すことによって実装されます。
しきい値確率は、実際は標準確率ではなくコストを反映します。
「平均化」と「自然」の差異を確認するには、次の手順を実行します。
分類モデルを作成します。
パフォーマンス設定のオプションを選択し、次のリフト詳細を表示します。
自然: しきい値確率値は、各分位の最大確率です。
平均化: しきい値はコストを反映します。各分位の最小のコスト値が表示されます。
「利益」グラフには、少なくとも次の3本の線が表示されます。
各モデルの利益を示す線
予算を示す線
しきい値を示す線
しきい値は、分位の選択に使用される青色の縦線です。しきい値が移動すると、リフト詳細表の各テスト結果の詳細は、選択した分位に対応する「リフト・グラフ」上の点に変更されます。しきい値を移動するには、分位線上のインジケータをドラッグします。ここでは、分位は20に設定されています。
利益の値を指定するには、「利益設定」をクリックして「利益設定ダイアログ」を開きます。
複数のモデルの利益を比較する場合は、各モデルの線が異なる色で表示されます。グラフの下の表に、モデルの名前およびそのモデルの結果を表示するために使用された色が示されます。
下部ペインには、「モデル」グリッドが表示され、グラフに示された情報を補足します。この表は、分割線を使用して最小化できます。
この表には次の列が含まれます。
名前。モデルの名前およびグラフでのモデルの色。
利益
ROIパーセンテージ
累積レコード・パーセンテージ
累積ターゲット密度
最大利益
最大利益母集団パーセンテージ
アルゴリズム
作成日(および時間)
「モデル」グリッドの上部に詳細参照アイコンがあります。モデルを選択してをクリックすると、「利益詳細ダイアログ」ボックスが表示され、1から100までの各分位の統計が表示されます。
モデルのリストを変更するには、![]() をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、そのモデルの利益曲線と詳細情報の両方が表示されません。デフォルトでは、ノード内のすべてのモデルの結果が表示されます。
をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、そのモデルの利益曲線と詳細情報の両方が表示されません。デフォルトでは、ノード内のすべてのモデルの結果が表示されます。
1から100までの分位の利益に関する統計が表示されます。「OK」をクリックしてダイアログ・ボックスを閉じます。
「利益設定」をクリックして次の値を変更します。
開始コスト: 利益を生成するプロセスを開始するコスト。デフォルトは1です。
増分収益: それぞれの正確な予測で得られる増分収益。デフォルトは1です。
増分コスト: 各追加項目のコスト。デフォルトは1です。
予算: 超えることができない総コスト。デフォルト値は1です。
母集団: モデルが適用される個々のケースの数。デフォルトは100です。
「OK」をクリックして設定を保存します。
分類構築ノードのすべてのモデルのテスト結果を比較するには、次の手順を実行します。
分類ノードの実行時にモデルをテストした場合は、モデルを含む分類ノードを右クリックし、「テスト結果の比較」を選択します。
テスト・ノードで分類モデルをテストした場合は、モデルをテストするテスト・ノードを右クリックし、「テスト結果の比較」を選択します。
テスト結果を比較する分類モデル・テスト・ビューアが開きます。比較により、ビジネスの問題を最適に解決するモデルを選択できます。
「パフォーマンス」タブでは、各モデルのグラフが異なる色で表示されます。他のタブでは、リフトなどのメジャーを表す線に同じ色が使用されます。
各モデルに関連付けられた色が各タブの下部ページに表示されます。
分類の「テスト結果の比較」には、次のサブタブが表示されます。
パフォーマンス: 下部パネルにリストされたモデルのパフォーマンス結果が上部ペインで比較されます。
モデルのリストを編集するには、モデルをリストしたペインの上にある![]() をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。デフォルトでは、すべてのモデルのテスト結果が比較されます。
をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。デフォルトでは、すべてのモデルのテスト結果が比較されます。
パフォーマンス・マトリックス: 各モデルのパフォーマンス・マトリックスが表示されます。「モデルの比較」(パフォーマンス・マトリックスの比較)または「詳細」(選択したモデルのパフォーマンス・マトリックス)を表示できます。
ROC: 下部ペインにリストされたモデルのROC曲線が比較されます。
曲線に関する情報を表示するには、モデルを選択してクリックします。
モデルのリストを編集するには、モデルをリストしたペインの上にある![]() をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。
をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。
リフト: 下部ペインにリストされたモデルのリフトが比較されます。リフトの詳細は、「リフト」を参照してください。
モデルのリストを編集するには、モデルをリストしたペインの上にある![]() をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。
をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。
利益: 下部ペインにリストされたモデルの利益曲線が比較されます。
モデルのリストを編集するには、モデルをリストしたペインの上にある![]() をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。
をクリックします。これにより、テスト選択の編集(分類および回帰)ダイアログ・ボックスが表示されます。
デフォルトでは、構築ノードの正常に構築されたすべてのモデルのテスト結果が選択されます。モデルのテスト結果を表示しない場合は、モデルの選択を解除します。
作業を終了後、「OK」をクリックします。
モデルをチューニングする場合は、いくつかある方法の1つを選択して導出コスト・マトリックスを作成します。導出コスト・マトリックスは、後続のテストおよび適用操作に使用されます。各チューニング・ダイアログ・ボックスには、チューニングの実行方法における異なる目的があります。
|
注意: モデルをチューニングするには、モデルを構築する同じノードでモデルをテストする必要があります。 |
必要に応じて、チューニングを削除し、ノードを再実行できます。
モデルをチューニングするには、次の手順を実行します。
構築ノードの「プロパティ」ペインを開きます。ノードを右クリックし、「プロパティに移動」を選択します。
「テスト」セクションに移動します。「モデル・チューニングに対して選択したテスト結果を生成」を選択します。
モデル・テスト操作で、対応するテスト結果のバイアスがかけられていないテスト結果(コスト・マトリックスが使用されていない)が生成されます。バイアスがかけられていないテスト結果は、チューニング・オプションを初期化する「チューニング設定」ダイアログ・ボックスで決定されます。たとえば、「テスト結果」に「ROC」のみが選択されている場合、テスト操作では通常のROC結果とバイアスがかけられていないROC結果が生成されます。
構築ノードを実行します。構築ノードでモデルをテストする必要があります。これは分類構築ノードのデフォルトの動作です。
構築ノードの「プロパティ」ペインで、「モデル」セクションに移動します。チューニングするモデルを選択し、メニュー・バーのチューニング・アイコン をクリックします。
をクリックします。
ドロップダウン・リストから「チューニング」を選択します。
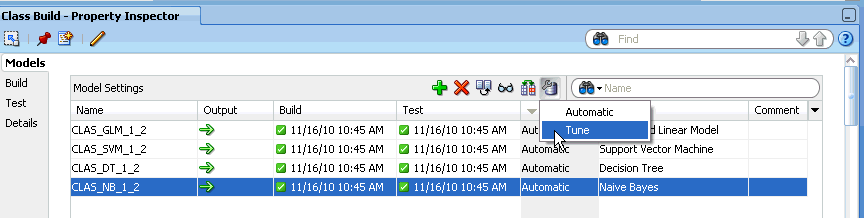
「チューニング設定」ダイアログ・ボックスが開き、使用可能なすべてのテスト結果が表示されます。
1つの手法を使用してモデルをチューニングできます。たとえば、コストまたはリフトを使用してチューニングできますが、コストとリフトを同時に使用することはできません。
複数のモデルをチューニングする場合は、ダイアログ・ボックスの下部ペインの「モデル」リストからモデルを選択します。最初のモデルをチューニングした後、このペインに戻り、別のモデルを選択します。
チューニングするテスト結果のタブをクリックします。次のタブがあります。
モデルのチューニングが終了したら、右側のペインで「チューニング」をクリックしてチューニングを生成します。下部ペインの「モデル」リストで、チューニング設定が「自動」から新しい設定に変更されます。
ノードで必要なだけモデルをチューニングします。他のチューニング・タブに移動し、そこからチューニングを実行します。チューニングが終了したら、「OK」をクリックします。
セッション中にチューニング指定を変更されたモデルはすべて、テスト結果が未実行としてマークされます。ノードを再度実行すると、次の処理が行われます。
新しいコスト・マトリックスが生成され、モデルに挿入されます。
現在のモデルの動作に関する全テスト結果情報を示す新しいテスト結果が生成されます。
チューニングしたモデルを実行します。モデルの実行が完了すると、「プロパティ」の「モデル」セクションに各モデルのチューニング方法が示されます。たとえば、コストを変更することによってモデルをチューニングした場合、そのモデルの「チューニング」エントリは「チューニング - コスト」になります。
構築ノードを右クリックし、チューニングしたモデルの「テスト結果の表示」を選択してチューニングの効果を確認します。
必要な結果を得るには、チューニング手順を複数回実行する必要がある場合があります。必要に応じて、モデルのチューニングを削除できます。
モデルのチューニングを削除するには、次の手順を実行します。
ノードを右クリックし、「プロパティに移動」を選択します。
「モデル」セクションに移動し、をクリックします。
「自動」を選択します。
ノードを実行します。
「チューニング設定」の「コスト」タブでは、スコアリングの目的でターゲットのコストを指定できます。
デフォルトでは、コスト・マトリックスは、構築データ・ソースのすべての既知のターゲット値に基づいて最初に生成されます。コスト・マトリックスは、最初はコスト値が1に設定されます。
コストを指定するには、次の手順を実行します。
構築ノードの「プロパティ」ペインを開きます。ノードを右クリックし、「プロパティに移動」を選択します。
「テスト」セクションで、「モデル・チューニングに対して選択したテスト結果を生成」を選択し、ノードを実行します。
「モデル」セクションで、チューニングするモデルを選択し、をクリックします。
ドロップダウン・リストから「チューニング」を選択します。「チューニング設定」ダイアログ・ボックスが開きます。
「チューニング設定」ダイアログ・ボックスで、「コスト」タブに移動します。
複数のモデルをチューニングする場合は、下部ペインの「モデル」リストからモデルを選択します。最初のモデルをチューニングした後、このペインに戻り、別のモデルを選択します。
コストを指定するターゲット値を選択します。
適切なオプションを選択します。
偽陽性: ケースをターゲットとして不正に識別しています。(デフォルト)
偽陰性: ケースを非ターゲットとして不正に識別しています。
「重み」フィールドで、コストの重みを指定します。
「適用」をクリックして、指定したコストをコスト・マトリックスに追加します。
目的のすべてのターゲット値のコストを定義します。
マトリックスを適用するには、右上のペインで「チューニング」をクリックします。
作成したコスト・マトリックスを表示するには、導出したマトリックスをクリックします。導出したコスト・マトリックスを調べます。行った選択を変更して、チューニングを続行できます。
終了したら、「OK」をクリックしてチューニングを確定します。チューニングを取り消す場合は、「取消」をクリックします。
チューニングを取り消すには、「リセット」をクリックします。チューニングが「自動」に戻ります。
チューニングの影響を確認するには、モデル・ノードに戻ります。
分類の問題では、多くの場合、正確な分類または不正確な分類に関連付けられたコストまたはベネフィットを指定することが重要です。指定することで、誤った分類によるコストが極端に異なっている場合に役立つことがあります。
コスト・マトリックスを作成して、コストを最小限に抑える、または最大のベネフィットを得るバイアスをモデルにかけることができます。コスト/ベネフィット・マトリックスは、モデルがスコアリングされる場合に考慮されます。
たとえば、顧客が販促の郵便物に応答するかどうかを予測することが問題であるとします。ターゲットには、YES (顧客が応答する)とNO (顧客が応答しない)の2つのカテゴリがあります。販促に対してポジティブで応答すると$500が生成され、郵送のコストは$5になります。モデルを構築した後、モデル予測とテストの保持された実際のデータを比較します。この時点で、様々な誤った分類の相対コストを評価できます。
モデルでYESが予想され、実際の値がYESの場合、誤った分類のコストは$0です。
モデルでYESが予想され、実際の値がNOの場合、誤った分類のコストは$5です。
モデルでNOが予想され、実際の値がYESの場合、誤った分類のコストは$495です。
モデルでNOが予想され、実際の値がNOの場合、コストは$0です。
同じコストを使用して、ベネフィットの観点から結果の相対値に取り組むことができます。YES (応答者)を正しく予測した場合、ベネフィットは$495になります。NO (非応答者)を正しく予測した場合、郵便物の送付を回避できるため、ベネフィットは$5.00になります。最もコストが低い解決を見つけることが目的であるため、ベネフィットは負の数として表されます。
「ベネフィット」タブでは次のことができます。
ターゲットの各値のベネフィットを指定します。指定した値はコスト・ベネフィット・マトリックスに適用されます。ベネフィットの指定は、多数のターゲット値がある場合に役立ちます。
最も重要な値を示します。
「ベネフィット」タブを使用してモデルをチューニングする手順:
構築ノードの「プロパティ」ペインを開きます。ノードを右クリックし、「プロパティに移動」を選択します。
「テスト」セクションで、「モデル・チューニングに対して選択したテスト結果を生成」を選択し、ノードを実行します。
「モデル」セクションで、チューニングするモデルを選択し、をクリックします。
ドロップダウン・リストから「チューニング」を選択します。新しいタブに「チューニング設定」ダイアログ・ボックスが開きます。
「チューニング設定」ダイアログ・ボックスで、「ベネフィット」をクリックします。
複数のモデルをチューニングする場合は、下部ペインの「モデル」リストからモデルを選択します。最初のモデルをチューニングした後、このペインに戻り、別のモデルを選択します。
チューニングするターゲット値を「ターゲット値」リストから選択します。
選択したターゲットのベネフィット値を指定します。ベネフィット値は、正または負の値を指定できます。ターゲット値の追加のベネフィットがある場合、ベネフィット値を他のベネフィット値よりも大きくする必要があります。各ターゲット値のデフォルトのベネフィット値は0です。
選択したターゲットのベネフィット値を「ベネフィット」ボックスに入力し、「適用」をクリックしてコスト・ベネフィット・マトリックスを更新します。
ベネフィット値の指定が終了したら、右側の列で「チューニング」をクリックします。
「表示」をクリックして、導出されたコスト・マトリックスを確認します。
終了したら、「OK」をクリックしてチューニングを確定するか、「取消」をクリックしてチューニングを取り消します。
「ROC」は2項モデルでのみサポートされています。「ROC」チューニング・タブでは、標準のROCテスト・ビューアにサイド・パネルが追加されます。次の情報が表示されます:
右上のペインの「パフォーマンス・マトリックス」では、次のマトリックスを表示できます。
全体精度: ROCグラフ上の最大全体精度点のコスト・マトリックス。
平均精度: 最大平均精度点のコスト・マトリックス。
カスタム精度: カスタム動作点のコスト・マトリックス。
このオプションを使用可能にするには、カスタム動作点を指定する必要があります。
モデル精度: 現在のモデルの現行パフォーマンス・マトリックス(概算)。
次の計算を使用して、提供されたROC結果からモデル精度を導出できます。
埋込みコスト・マトリックスがない場合は、50%しきい値点またはこれに最も近い点を見つけます。埋込みコスト・マトリックスがある場合は、最小コスト点を見つけます。モデルで埋込みコスト・マトリックスを使用するには、モデルをチューニングしておくか、構築ノードのデフォルト設定でコスト・マトリックスまたはコスト・ベネフィットを定義しておく必要があります。
「パフォーマンス・マトリックス」グリッドに、選択したオプションのパフォーマンス・マトリックスが表示されます。
「チューニング」をクリックして、次を実行します。
現在のパフォーマンス・オプションがモデルのチューニングに使用するオプションとして選択されます。
その確率しきい値でROC結果からコスト・マトリックスを導出します。
このパネルの下部にある「チューニング設定」が更新され、新しいマトリックスが表示されます。
「クリア」をクリックして、チューニング指定をクリアし、チューニングを「自動」に設定します。つまり、チューニングは実行されません。
ROCのチューニングを実行するには、次の手順を実行します。
構築ノードの「プロパティ」ペインを開きます。ノードを右クリックし、「プロパティに移動」を選択します。
「テスト」セクションで、「モデル・チューニングに対して選択したテスト結果を生成」を選択し、ノードを実行します。詳細は、「分類モデルのチューニング」を参照してください。
「モデル」セクションで、チューニングするモデルを選択し、をクリックします。
ドロップダウン・リストから「チューニング」を選択します。新しいタブに「チューニング設定」ダイアログ・ボックスが開きます。
「チューニング設定」ダイアログ・ボックスで、「ROC」タブに移動します。
複数のモデルをチューニングする場合は、下部ペインの「モデル」リストからモデルを選択します。最初のモデルをチューニングした後、このペインに戻り、別のモデルを選択します。
ターゲット値を選択します。ROCの場合は、2つの値のみがあります。
デフォルト点を使用しない場合は、カスタム動作点を選択します。詳細は、「カスタム動作点の選択」を参照してください。
使用するパフォーマンス・マトリックスの種類を選択します。
全体精度(デフォルト)
平均精度
カスタム精度。このオプションを選択した場合は、「パフォーマンス・マトリックス」に値を入力します。
モデル精度
「チューニング」をクリックします。同じパネルに新しいチューニング設定がパフォーマンス・マトリックスとして表示されます。導出したコスト・マトリックスを調べます。行った選択を変更して、チューニングを続行できます。
終了したら、「OK」をクリックしてチューニングを確定するか、「取消」をクリックしてチューニングを取り消します。
チューニングをリセットするには、「リセット」をクリックします。
チューニングの影響を確認するには、モデル・ノードを実行します。
「カスタムしきい値ダイアログの指定」ボックスでは、ノードのすべてのモデルのカスタム動作点を編集できます。
ヒット率または誤認警報を変更するには、適切なオプションをクリックし、使用する値を調整します。
または、「偽陽性」あるいは「偽陰性」の比率を指定できます。これを行うには、適切なオプションを選択し、比率を指定します。
作業を終了後、「OK」をクリックします。
受信者操作特性(ROC)は、確率しきい値の変化を試し、モデルの予測能力に対するその結果の効果を確認する方法です。
ROCグラフの横軸では、偽陽性比率がパーセンテージとして測定されます。
縦軸は真陽性比率を表します。
ROC曲線では左上隅が最適位置です。つまり、TP (真陽性)率が高くFP (偽陽性)率が低いことを表します。
ROC曲線下面積により、2項分類モデルの識別能力が測定されます。この測定は、ターゲット分布が不均衡である(1つのターゲット・クラスが他のクラスに比べて顕著である)データ・セットに対して特に有効です。曲線下の面積が大きいほど、実際のネガティブ・ケースではなく実際のポジティブ・ケースが高い確率でポジティブに割り当てられるという尤度も高くなります。
ROC曲線は、個々のモデル間で比較する手段を提供し、高比率のポジティブ・ヒットが得られるしきい値を決定するという点で、リフト・グラフに似ています。ROCは、最初は信号検出理論で、雑音の多いチャネルで信号を送信する場合に真のヒット比率と誤認警報比率を測定するために使用されました。
リフトは、ランダムに生成された予測と比較して、分類モデルの予測がどの程度信頼できるかを計算したものです。
リフトを使用してモデルをチューニングするには、次の手順を実行します。
構築ノードの「プロパティ」ペインを開きます。ノードを右クリックし、「プロパティに移動」を選択します。
「テスト」セクションで、「モデル・チューニングに対して選択したテスト結果を生成」を選択し、ノードを実行します。
「モデル」セクションで、チューニングするモデルを選択し、をクリックします。
ドロップダウン・リストから「チューニング」を選択します。新しいタブに「チューニング設定」ダイアログ・ボックスが開きます。
「チューニング設定」ダイアログ・ボックスで、「リフト」タブに移動します。
複数のモデルをチューニングする場合は、下部ペインの「モデル」リストからモデルを選択します。最初のモデルをチューニングした後、このペインに戻り、別のモデルを選択します。
チューニングするターゲット値を「ターゲット値」リストから選択します。
「累積陽性例」グラフ(デフォルト)を使用してチューニングするか、「累積リフト・グラフ」を使用してチューニングするかを選択します。「表示」リストからグラフを選択します。
いずれのグラフにも、複数の曲線が表示されます。チューニングしているモデルのリフト曲線(理想リフト)、およびランダム・リフト(予測がランダムなモデルのリフト)です。
グラフには、しきい値(目的の分位)を示す青色の縦線も表示されます。
分位でスライダを使用して選択した分位がリフト・グラフの下に表示されます。スライダを移動すると、青色の縦棒がその分位に移動し、チューニング・パネルがその点のパフォーマンス・マトリックスで更新されます。
「パフォーマンス・マトリックス」の下の「チューニング」をクリックします。同じパネルに新しいチューニング設定がパフォーマンス・マトリックスとして表示されます。導出したコスト・マトリックスを調べます。行った選択を変更して、チューニングを続行できます。
終了したら、「OK」をクリックしてチューニングを確定するか、「取消」をクリックしてチューニングを取り消します。
チューニングをリセットするには、「リセット」をクリックします。
チューニングの影響を確認するには、モデル・ノードを実行します。
リフトとは、全体としての母集団の肯定的な反応者に対するセグメントの肯定的な反応者の比率のことです。たとえば、母集団の反応率が20%と予測されたが、母集団のあるセグメントの反応率が60%と予測された場合、そのセグメントのリフトは3 (60%/20%)となります。リフトでは、次のことが測定されます。
母集団のセグメント内のポジティブ予測の集中度。全体としての母集団のポジティブ予測の比率に対する改良度を指定します。
マーケティング・アプリケーションにおけるターゲット・モデルのパフォーマンス。ターゲット・モデルの目的は、マーケティング・キャンペーンに対する肯定的な反応者が潜在的に多数集まっている母集団のセグメントを特定することです。
リフトの概念には、2項ターゲットのみが含まれます。反応者または非反応者、YESまたはNOです。リフトを多クラス・ターゲットに対して計算するには、優先ポジティブ・クラスを指定し、他のすべてのターゲット・クラス値を1つにまとめます。つまり事実上、多クラス・ターゲットを2項ターゲットに変更します。リフトは2項分類と非2項分類の両方に適用できます。
リフトの計算は、ターゲット値が既知のテスト・データにモデルを適用することによって開始されます。次に、予測された結果が、予測信頼度が最も高いものから最も低いものへ、確率の順にソートされます。ランク付けされたリストは分位(等しい部分)に分割されます。デフォルトの分位数は100です。
「利益」タブでは利益を最大化する方法が提供されます。
構築ノードの「プロパティ」を開きます。ノードを右クリックし、「プロパティに移動」を選択します。
「テスト」セクションで、「モデル・チューニングに対して選択したテスト結果を生成」を選択し、ノードを実行します。
「モデル」セクションで、チューニングするモデルを選択し、をクリックします。
ドロップダウン・リストから「チューニング」を選択します。新しいタブに「チューニング設定」ダイアログ・ボックスが開きます。
「チューニング設定」ダイアログ・ボックスで、「利益」タブに移動します。
複数のモデルをチューニングする場合は、下部ペインの「モデル」リストからモデルを選択します。最初のモデルをチューニングした後、このペインに戻り、別のモデルを選択します。
チューニングするターゲット値を「ターゲット値」リストから選択します。
「利益設定」をクリックし、「利益設定」ダイアログ・ボックスで値を指定します。
「利益設定」を指定すると、指定した値がグラフに反映されます。
グラフの下のスライダを使用して、しきい値(青色の縦線)を調整します。
「パフォーマンス・マトリックス」の下の「チューニング」をクリックします。同じパネルに新しいチューニング設定がパフォーマンス・マトリックスとして表示されます。導出したコスト・マトリックスを調べます。行った選択を変更して、チューニングを続行できます。
終了したら、「OK」をクリックしてチューニングを確定するか、「取消」をクリックしてチューニングを取り消します。
チューニングをリセットするには、「リセット」をクリックします。
チューニングの影響を確認するには、モデル・ノードを実行します。
「開始コスト」、「増分収益」、「増分コスト」および「予算」のデフォルト値はすべて1です。「母集団」のデフォルト値は100です。これらの値を、ビジネスの問題に適した値に変更します。
「OK」をクリックします。
回帰モデルは、テスト・データ・セット内の既知のターゲット値と予測値を比較することによってテストされます。通常、回帰プロジェクト用の履歴データは、次の2つのデータ・セットに分割されます。
モデルの構築用
モデルのテスト用
モデルを適用するテスト・データは、モデルの構築で使用したデータと互換性があることが必要で、モデル構築データが準備されたのと同じ方法で準備される必要があります。
分類モデルと回帰モデルをテストするには、次の方法があります。
入力データを構築データとテスト・データに分割します。これがデフォルトです。テスト・データは、構築データを2つのサブセットにランダムに分割することによって作成されます。入力データの40%がテスト・データに使用されます。
すべての構築データをテスト・データとして使用します。
2つのデータ・ソース・ノードを構築ノードにアタッチします。
構築ノードに接続する最初のデータ・ソースは、構築データのソースです。
接続する2番目のノードは、テスト・データのソースです。
「プロパティ」ペインの「テスト」セクションで「テストの実施」の選択を解除し、テスト・ノードを使用します。デフォルトでは、すべての分類モデルと回帰モデルがテストされます。
テスト設定では、計算するメトリックを指定し、メトリックの計算を制御します。
Oracle Data Miningでは、回帰モデルを評価するための次のような情報が提供されます。
テスト結果を表示するには、最初にノードのモデルをテストします。
回帰ノードでデフォルト・テストを使用してモデルをテストした場合は、ノードを実行し、ノードを右クリックします。「テスト結果の表示」を選択し、目的のモデルを選択します。回帰モデル・テスト・ビューアが起動します。ノードのすべてのモデルのテスト結果を比較するには、「テスト結果の比較」を選択します。
テスト・ノードを使用してモデルをテストした場合は、テスト・ノードを実行し、ノードを右クリックします。「テスト結果の表示」を選択し、目的のモデルを選択します。回帰モデル・テスト・ビューアが起動します。ノードのすべてのモデルのテスト結果を比較するには、「テスト結果の比較」を選択します。
モデルをテストした構築ノードの「プロパティ」ペインの「モデル」セクションに移動し、![]() をクリックして、テスト結果を比較することもできます。
をクリックして、テスト結果を比較することもできます。
残差プロットは、残差の散布図です。各残差は、実際の値とモデルによって予測された値の差です。残差は、正の場合と負の場合があります。残差が小さい(0に近い)場合、予測は正確です。残差プロットは、一部のクラスの値の予測がその他よりも優れていることを示す場合があります。
Oracle Data Miningでは、回帰モデルの全体的な質を評価するために次の統計量が計算されます。
2乗平均平方根誤差: 近似線からのデータ・ポイントの平均2乗距離の平方根。
平均絶対誤差: 残差(誤差)の絶対値の平均。平均絶対誤差は2乗平均平方根誤差に非常に似ていますが、大きな誤差に対する感度は低くなります。
回帰モデルのヘルプには、次の項が含まれます。
回帰モデル・テスト・ビューアで情報を表示するには、次の手順を実行します。
(回帰モデルをテストする)回帰ノードまたはテスト・ノードを右クリックし、「テスト結果の表示」または「テスト結果の比較」を選択します。
回帰モデル・テスト・ビューアが開き、次のタブが表示されます。
「OK」をクリックします。
「パフォーマンス」タブには、複数の共通テスト・メトリックのテスト結果が表示されます。
回帰モデルの「パフォーマンス」タブには、すべてのモデルについて次のメジャーが表示されます。
すべてのメジャー(デフォルト)。「メジャー」リストでは、表示するメジャーを選択できます。デフォルトでは、すべてのメジャーが表示されます。選択したメジャーはグラフとして表示されます。複数のモデルのテスト結果を比較する場合は、各モデルにグラフで異なる色が割り当てられます。
予測信頼度: モデルの予測がナイーブ・モデルの予測よりどれだけ優れているかを測定します。回帰の予測信頼度は、分類の予測信頼度と同じメジャーです。
平均絶対誤差
2乗平均平方根誤差
平均予測値: 予測値の平均。
平均実際値: 実際値の平均。
2つの「ソート基準」リストで、ソート属性およびソート順を指定します。最初の「ソート基準」リストは、「メジャー」、「作成日」または「名前」(デフォルト)です。2番目の「ソート基準」リストは、ソート順の「昇順」または「降順」(デフォルト)です。
上部ペインにこれらのメジャーがヒストグラムとして表示されます。
下部ペインには、グラフに示された情報を補足する「モデル」グリッドが表示されます。この表は、分割線を使用して最小化できます。
「モデル」グリッドには、次の列が含まれます。
名前。モデルの名前およびグラフでのモデルの色。
予測信頼度
平均絶対誤差
2乗平均平方根誤差
平均予測値
平均実際値
アルゴリズム
作成日(および時間)
デフォルトでは、選択したモデルの結果が表示されます。モデルのリストを変更するには、![]() をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、そのモデルのヒストグラムと詳細情報の両方が表示されません。
をクリックし、結果を表示しないモデルの選択を解除します。モデルの選択を解除した場合、そのモデルのヒストグラムと詳細情報の両方が表示されません。
残差プロットタブには、残差プロットがモデルごとに表示されます。デフォルトでは、残差プロットはグラフとして表示されます。
数値結果を表示するには、をクリックします。
表示をグラフに戻すには、 をクリックします。
をクリックします。
別のモデルのプロットを表示するには、「表示」リストからモデルを選択し、「問合せ」をクリックします。
プロットをどのように表示するかを複数の方法で制御できます。
Y軸およびX軸に表示される情報を選択します。デフォルトでは次のように示されます。
X軸: 予測値
Y軸: 残差
これを変更するには、リストから情報を選択します。
デフォルトのサンプル・サイズは2000です。この値を増減できます。
プロットを並べて比較できます。デフォルトでは、プロットは比較されません。
これらのフィールドのいずれかを変更した場合は、「問合せ」をクリックして結果を確認します。
プロットを並べて比較するには、現在のモデルと比較するモデルを「比較」リストから選択し、「問合せ」をクリックします。残差プロットが並べて表示されます。
下部ペインに「残差結果のサマリー表」が表示されます。この表には、プロットに示された情報を補足する「モデル」グリッドが含まれています。この表は、分割線を使用して最小化できます。
この表には次の列が含まれます。
モデル。モデルの名前およびグラフでのモデルの色
予測信頼度
平均絶対誤差
2乗平均平方根誤差
平均予測値
平均実際値
アルゴリズム
作成日(および時間)
デフォルトでは、ノード内のすべてのモデルの結果が表示されます。モデルのリストを変更するには、![]() をクリックしてテスト選択の編集(分類および回帰)ダイアログ・ボックスを開きます。
をクリックしてテスト選択の編集(分類および回帰)ダイアログ・ボックスを開きます。
回帰構築ノードのすべてのモデルのテスト結果を比較するには、次の手順を実行します。
回帰ノードの実行時にモデルをテストした場合は、次の手順を実行します。
モデルを含む回帰ノードを右クリックします。
「テスト結果の比較」を選択します。
テスト・ノードの回帰モデルをテストした場合は、次の手順を実行します。
モデルをテストするテスト・ノードを右クリックします。
「テスト結果の比較」を選択します。
複数の回帰モデルのテスト結果を比較する場合、各モデルに色が関連付けられます。この色は、そのモデルの結果を示します。たとえば、モデルM1に紫色が関連付けられた場合、「パフォーマンス」タブのM1の棒グラフは紫色で表示されます。
デフォルトでは、ノードのすべてのモデルのテスト結果が比較されます。一部のテスト結果を比較しない場合は、![]() をクリックします。「テスト結果選択の編集」ダイアログ・ボックスが開きます。表示しない結果の選択を解除します。作業を終了後、「OK」をクリックします。
をクリックします。「テスト結果選択の編集」ダイアログ・ボックスが開きます。表示しない結果の選択を解除します。作業を終了後、「OK」をクリックします。
新しいタブで「テスト結果の比較」が開きます。次の2つのタブに結果が表示されます。
「パフォーマンス」タブ: 「パフォーマンス」タブでは次のメトリックが比較されます。
分類モデルの予測信頼度
平均絶対誤差
平均予測値
デフォルトでは、すべてのモデルのテスト結果が比較されます。モデルのリストを編集するには、モデルをリストしたペインの上にある![]() をクリックしてテスト選択の編集(分類および回帰)ダイアログ・ボックスを開きます。
をクリックしてテスト選択の編集(分類および回帰)ダイアログ・ボックスを開きます。
「残差」タブ: 各モデルの残差プロットが表示されます。
2つのプロットを並べて比較できます。デフォルトでは、すべてのモデルのテスト結果が比較されます。
モデルのリストを編集するには、モデルをリストしたペインの上にある![]() をクリックしてテスト選択の編集(分類および回帰)ダイアログ・ボックスを開きます。
をクリックしてテスト選択の編集(分類および回帰)ダイアログ・ボックスを開きます。