| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
テキスト・ノードは、「コンポーネント」ペインの「テキスト」セクションで使用できます。Oracle Data Minerでは、次のテキスト・ノードがサポートされます。
Oracle Database 12cに接続している場合、自動データ準備(ADP)を使用できるため、データの使用方法を指定する「テキスト」タブを使用してテキスト・データを準備できます。
|
注意: テキストの処理には、Oracle Textのナレッジ・ベースが必要です。ナレッジ・ベースをインストールするには、Oracle Database Examplesをインストールする必要があります。例のインストール手順は、接続しているOracle Databaseのリリース向けのOracle Database Examplesインストレーション・ガイドを参照してください。 |
|
関連項目:
|
テーマ: テーマは、所定のドキュメントと関連付けられているトピックです。1つのドキュメントに多数のテーマが存在する場合があります。テーマは、ドキュメント内に出現する必要はありません。たとえば、ワードSan Franciscoを含むドキュメントがテーマの1つとしてCaliforniaを持つ場合があります。
ストップワード: ストップワードは、テキスト変換中に索引付けされないワードです。通常、ストップワードは下位レベルの情報を提供するワードを指します。英語では、通常a、the、thisまたはwithがストップワードです。
ストップリスト: ストップリストは、ストップワードのリストです。Oracle Textには各言語のストップリストが用意されています。デフォルトでは、索引付け時に使用言語に対して、Oracle Textのデフォルトのストップリストが使用されます。デフォルトのストップリストを編集したり、新しいストップリストを作成できます。
|
注意: Oracle Data Minerでは、ストップリストはすべての変換にわたって共有されるものであり、特定の変換によって所有されません。 |
ストップテーマ: ストップテーマは、索引付け時にスキップされるテーマです。ストップテーマは、これらをストップリストに追加することで指定されます。
Oracle Textでは、ストップワードおよびストップテーマを使用して、テキスト・マイニング時に無視しても問題のないテキストを示します。
Oracle Textのレクサーは、指定された言語に応じてソース・テキストをトークンまたはテーマ(通常はワード)に分割します。レクサーは、トークンの抽出にレクサー・プリファレンスに定義されたパラメータを使用します。パラメータには次のものが含まれます。
トークンを区切る文字の定義。たとえば、空白です。
テキストをすべて大文字に変換する条件または変換しない条件。
テーマ・トークンを作成するためのテキスト分析テキスト。これは、テーマの索引付けが有効化されているときに行われます。
|
関連項目: 『Oracle Textリファレンス』 |
テキストは、マイニングする前に変換プロセスを行う必要があります。データが正しく変換されると、ケース表を使用して、データ・マイニング・モデルの構築、テストまたはスコアリングを行うことができます。ケース表は、リレーショナル表である必要があります。それは、ビューとしては作成できません。
Oracle Data Miningのソース表には、1つ以上のテキストの列を含めることができます。テキスト列はターゲットとしては使用できません。
次のOracle Data Miningアルゴリズムでテキストがサポートされます。
異常検出(1クラス・サポート・ベクター・マシン)
分類アルゴリズム: Naive Bayes、一般化線形モデルおよびサポート・ベクター・マシン
ディシジョン・ツリー(Oracle Database 12cに接続している場合)
クラスタリング・アルゴリズム: k- Meansおよび期待値の最大化
特徴抽出アルゴリズム: Nonnegative Matrix Factorization、特異値分解および主成分分析
回帰アルゴリズム: 一般化線形モデルおよびサポート・ベクター・マシン
|
注意: 次のアルゴリズムではテキストはサポートされません。
Oracle Database 11gに接続されているO-Clusterおよびディシジョン・ツリーを使用する場合、すべてのテキスト属性はモデル構築に対して自動的にフィルタ処理で除外されます。 |
テキストのデータ準備は、接続先のOracle Databaseのバージョンによって異なります。
Oracle Data Mining 12c Release 1 (12.1)およびそれ以前では、非構造化テキスト・データが存在する場合、テキスト・マイニング前のテキスト処理にテキスト変換が含まれます。Oracle Data Miningではテキスト処理が大幅な強化されており、入力に非構造化テキスト・データが存在する場合のデータ・マイニング・プロセス(モデルの構築、デプロイメントおよびスコアリング)が簡素化されます。非構造化テキストおよびテキスト変換の要点のいくつかは次のとおりです。
非構造化テキストには、Webページ、ドキュメント・ライブラリ、Microsoft PowerPointプレゼンテーション、製品仕様、電子メール・メッセージ、レポートのコメント・フィールド、コール・センターのメモなどのデータ項目が含まれます。
CLOB列および長いVARCHAR2列は、Oracle Data Miningにより自動的に非構造化テキストとして解釈されます。
短いVARCHAR2、CHAR、BLOBおよびBFILEの列を、非構造化テキストとして指定できます。
非構造化テキストをマイニング用に変換するために、Oracle Data Miningでは、Oracle Textユーティリティおよび用語の重み付け方針を使用します。
テキスト用語が抽出され、テキスト索引内の数値が付与されます。
テキスト変換プロセスは、モデルおよび個々の属性に対して構成可能です。モデル・ノードの定義時に、テキスト・ノードのデータ準備を指定できます。
テキストの変換後に、テキストは、データ・マイニング・アルゴリズムでマイニングできます。
Oracle Data Mining 11gリリース2 (11.2)およびそれ以前では、テキスト・マイニングの実行前に次のプロセスが必要です。
抽出または特徴抽出: これは、テキストがマイニング可能な単位(用語)に分類される特殊な事前処理ステップです。テキストの用語は、キーワードまたはその他のドキュメント派生の特徴です。
テキストの準備: テキストの準備では、テキストの構築ノードを使用してテキスト列を変換します。テキストの構築では、HTMLまたはXMLドキュメントはサポートされません。また、いずれのバイナリ・データ型もサポートされません。
Oracle Data Minerは、Oracle Textの機能を使用してテキスト列を事前処理します。
テキストの適用ノードでは、テキストの構築ノードまたはテキスト・ノードのいずれかの既存のテキスト変換を新しいデータに適用できます。これにより、構築データが変換された方法と同じ方法で適用データが変換されることが保証されます。
テキストの適用はパラレルに実行できます。詳細は、「パラレル処理について」を参照してください。
テキストの適用ノードに関するこの項では、次の項目について説明します。
テキストの適用ノードは、テキストの構築ノードまたはテキスト・ノードのいずれかの既存のテキスト変換を新しいデータに適用します。これにより、構築データが変換された方法と同じ方法で適用データが変換されることが保証されます。
|
注意: ノード内のすべてのモデルは、同じケースIDを持つ必要があります。 |
テキストの適用ノードを作成する前に、まず、ワークフローを作成します。次に、データ・ソース・ノードを作成します。
テキストの適用ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
ワークフロー・エディタで「テキスト」を展開して、「テキストの適用」をクリックします。
テキストの適用ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
ノードに関連付けられたデータがないことがGUIに表示されます。このため、それは実行できません。
テキストの適用のデータを提供するノードに移動します。右クリックして、「接続」を選択します。テキストの構築まで線をドラッグし、再度クリックします。
|
注意: 適用データは、構築データと互換性がある必要があります。 |
テキスト列がどのように準備されたかを示すテキストの構築ノードまたはテキスト・ノードに移動します。たとえば、適用対象モデルのテキストの構築ノードに移動します。テキストの構築ノードを適用ノードにリンクします。
変換の詳細を表示または変更するには、テキストの適用ノードを右クリックして「編集」を選択します。これにより、「テキスト適用ノードの編集」ダイアログ・ボックスが開きます。
ノードの実行準備が完了しました。ノードを右クリックし、「実行」を選択します。
「テキスト適用ノードの編集」ダイアログ・ボックスでは、構築データで実行されたテキスト変換を表示できます。適用データは、構築データと同じ方法で準備する必要があります。
「テキスト適用ノードの編集」ダイアログ・ボックスを開くには、テキストの適用ノードを右クリックして「編集」を選択するか、ノードをダブルクリックします。
テキストの適用ノードを右クリックし、「編集」をクリックします。または、テキストの適用ノードをダブルクリックできます。
「テキスト適用ノードの編集」には、次の2つのペインがあります。
上部ペインでは、次のタスクを実行できます。
ケースID: このフィールドでケースIDを指定します。これはオプションです。
属性の表示: ドロップダウン・リストから、「すべて」または「テキストおよび変換済」を選択します。各属性に対して、次が表示されます。
型: 属性のデータ型です。テキスト変換が適用された属性の型は、DM_NESTED_NUMERICALSです。
ソース: 変換された列のソース列です。
変換: テキスト変換のタイプです(「トークン」または「テーマ」)。
出力: 属性が後続ノードに渡されるかどうかを示します。デフォルトでは、すべてのノードが渡されます。
ストップリストの表示。ストップリストを表示するには、変換された列を選択して「ストップリストの表示」をクリックします。ストップリスト・エディタが起動します。ストップリスト内の項目を表示できます。
テキスト変換の表示および編集: テキスト変換の定義を表示するには、変換された属性を選択して をクリックします。これにより、「テキスト変換の追加/編集」ダイアログ・ボックスが開きます。
をクリックします。これにより、「テキスト変換の追加/編集」ダイアログ・ボックスが開きます。
属性の除外: 属性を除外するには、オプションを選択して、グリッドの「出力」列で をクリックします。アイコンが
をクリックします。アイコンが に変わります。除外された属性は、後続の操作に渡されません。未変換バージョンのテキスト列は、除外する必要がある場合があります。
に変わります。除外された属性は、後続の操作に渡されません。未変換バージョンのテキスト列は、除外する必要がある場合があります。
属性を含める: 属性を含めるには、アイコンを再度クリックします。アイコンがに変わり、それが含まれていることを示します。
下部ペインでは、ノードの実行後にテキスト変換の表示が可能です。
「OK」をクリックします。
テキストの構築ノードまたはテキスト・ノードで定義されたテキスト変換の効果を、「テキスト変換の表示」ウィンドウで表示できます。「テキスト変換の表示」ウィンドウにアクセスするには、次の手順を実行します。
テキストの適用ノードをダブルクリックするか、ノードを右クリックして「編集」を選択し、「テキスト適用ノードの編集」ダイアログ・ボックスを開きます。
上部ペインで、変換された属性の名前を選択します。
下部ペインで、次の操作を実行します。
「トークン」または「テーマ」をクリックします。グリッドに、ドキュメント内のすべてのトークンまたはテーマ、および各トークンまたはテーマの頻度が表示されます。検索フィールドを使用して、トピックまたはテーマを名前(デフォルト)または頻度で検索します。
「出力」をクリックして、属性のサンプルのトークンまたはテーマを表示します。「出力サンプル」には、属性のサンプルが、ケースID (指定した場合)または行ID (ケースIDを指定しなかった場合)別にリストされます。IDを検索できます。
IDをクリックします。変換されていない属性からの元のテキストが表示され、さらに、その中で特定されたトークンまたはテーマ、および各トークンまたはテーマの頻度も表示されます。
「OK」をクリックします。
テキストの適用ノードのプロパティでは、ノードで定義されているモデルに関する情報を表示および変更できます。
ノードのプロパティを表示するには、ノードをクリックします。プロパティが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
テキストの適用のプロパティには、次のセクションがあります。
ノード名およびノードに関するコメントが表示されます。このタブから、ノード名の変更およびコメントの編集が可能です。新しいノード名およびコメントは、ノード名およびノードのコメントの要件を満たす必要があります。
テキストの適用ノードのコンテキスト・メニューを表示するには、ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「テキスト適用ノードの編集」ダイアログ・ボックスが開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
テキストの構築ノードは、1つ以上の「テキスト」列を含むデータ・ソースを準備します。データを使用してモデルを構築できます。
テキストの構築はパラレルに実行できます。
テキストの構築ノードに関するこの項では、次の項目について説明します。
テキストの構築ノードによって、各テスト列のテキスト変換を定義できます。変換された列は、テキストをサポートする任意のアルゴリズムを使用したモデルの構築に使用できます。
|
注意: O-Clusterおよびディシジョン・ツリーでは、テキストはサポートされません。 |
テキストの構築ノードでは、デフォルトではNMFアルゴリズムを使用して1つのモデルを構築します。変換された列(複数可)は、後続ノードに渡され、変換されていない列は渡されません。
ノード内のすべてのモデルは、同じケースIDを持ちます。
テキストの構築ノードを作成する前に、ワークフローを作成します。次に、データ・ソース・ノードを特定または作成します。
テキストの構築ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
ワークフロー・エディタで「テキスト」を展開して、「テキストの構築」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
ノードに関連付けられたデータがないことがGUIに表示されます。このため、それは実行できません。
テキストの構築ノードのデータを提供するノードに移動します。右クリックして、「接続」を選択します。テキストの構築まで線をドラッグし、再度クリックします。
デフォルトの設定をそのまま使用するか、テキストの詳細を編集します。変換の詳細を編集するには、ノードを右クリックして「編集」を選択します。テキストの構築ノードの編集ダイアログ・ボックスが開きます。
ノードの実行準備が完了しました。ノードを右クリックし、「実行」を選択します。
「テキスト作成ノードの編集」ダイアログ・ボックスでは、テキスト列の変換を定義できます。変換されたテキスト列は、データ・マイニングに使用できます。
「テキスト作成ノードの編集」ダイアログ・ボックスを開く手順:
テキストの構築ノードを右クリックし、「編集」をクリックします。または、ノードをダブルクリックします。テキストの構築ノードの編集ダイアログ・ボックスが開きます。
「テキスト作成ノードの編集」ダイアログ・ボックスには2つのペインがあります。
上部ペインでは、次のタスクを実行できます。
ケースIDの指定(オプション)。
ストップリスト・エディタのオープン。
属性の表示: ドロップダウン・リストから、「すべて」または「テキストおよび変換済」を選択します。各属性に対して、次が表示されます。
型: 属性のデータ型です。テキスト変換が適用された属性の型は、DM_NESTED_NUMERICALSです。
ソース: 変換された列のソース列です。
変換: テキスト変換のタイプです(「トークン」または「テーマ」)。
出力: 属性が後続ノードに渡されるかどうかを示します。デフォルトでは、すべてのノードが渡されます。
変換の定義: 変換を定義するには、テキスト属性を選択して をクリックします。「テキスト変換の追加/編集」ダイアログ・ボックスで、テキスト変換を定義します。各テキストについて、この手順を繰り返します。
をクリックします。「テキスト変換の追加/編集」ダイアログ・ボックスで、テキスト変換を定義します。各テキストについて、この手順を繰り返します。
変換の編集: 変換された属性を選択してをクリックします。
変換の削除: 変換された属性を選択して をクリックします。
をクリックします。
属性の除外: 属性を除外するには、それを選択して、グリッドの「出力」列でをクリックします。アイコンがに変わります。除外された属性は、後続の操作に渡されません。未変換バージョンのテキスト列は、除外する必要がある場合があります。
属性を含める: 属性を含めるには、アイコンを再度クリックします。アイコンがに変わり、それが含まれていることを示します。
下部ペインでは、ノードの実行後にテスト変換の表示が可能です。
「OK」をクリックします。
テキスト変換の効果を表示する手順:
テキストの構築ノードをダブルクリックするか、ノードを右クリックして「編集」を選択し、「テキスト作成ノードの編集」ダイアログ・ボックスを開きます。
上部ペインで、変換された属性の名前を選択します。
下部ペインで、次の操作を実行します。
「トークン」または「テーマ」をクリックします。グリッドに、ドキュメント内のすべてのトークンまたはテーマ、および各トークンまたはテーマの頻度が表示されます。検索フィールドを使用して、トピックまたはテーマを名前(デフォルト)または頻度で検索します。
ストップリストにトークンまたはテーマを追加するには、それを選択して「ストップリストへ追加」をクリックします。
「出力」をクリックして、属性のサンプルのトークンまたはテーマを表示します。「出力サンプル」には、属性のサンプルが、ケースID (指定した場合)または行ID (ケースIDを指定しなかった場合)別にリストされます。IDを検索できます。
IDをクリックします。変換されていない属性からの元のテキストが表示され、さらに、その中で特定されたトークンまたはテーマ、および各トークンまたはテーマの頻度も表示されます。
「OK」をクリックします。
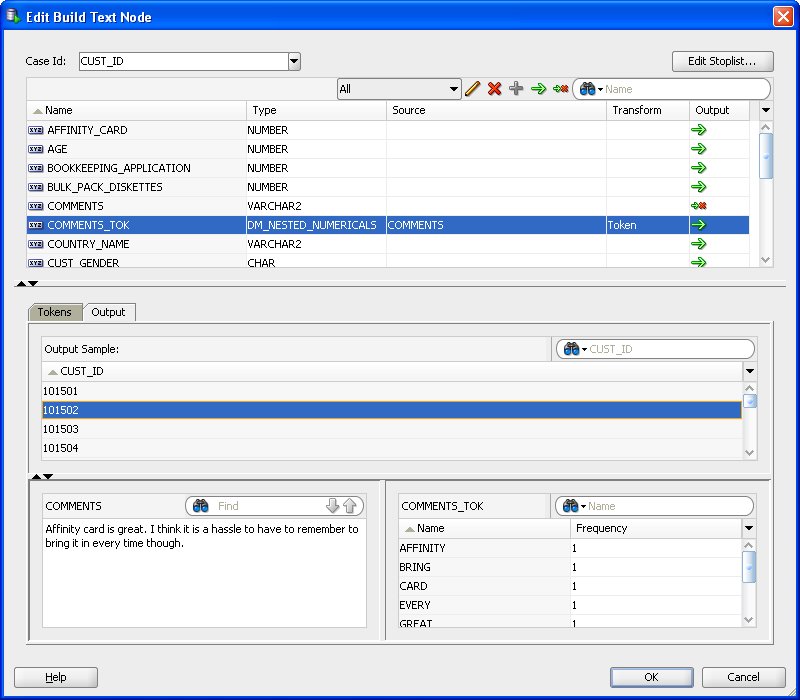
「テキスト変換の追加/編集」ダイアログ・ボックスを、「テキスト作成ノードの編集」ダイアログ・ボックスから開くことができます。テキスト変換を開くまたは編集するには、 をクリックします。次の図に、変換のデフォルト値を示します。
をクリックします。次の図に、変換のデフォルト値を示します。
ソース列: これは、変換対象列の名前です。
変換タイプ: これは、「トークン」(デフォルト)または「テーマ」です。
出力列: これは、新しい列の名前です。デフォルト名は、変換タイプに応じてソース列名にTOK (トークンの場合)またはTHM (テーマの場合)が追加されます。出力列名を指定するには、「自動」の選択を解除し、「出力列」フィールドに名前を入力します。
「設定」セクションでは、テキストおよび変換の特性を指定します。
言語: 次のいずれか1つのオプションを選択します。
1つの言語: デフォルトでは、1つの言語が指定されています。「英語」がデフォルトの言語です。別の言語を選択できます。
多言語: 複数の言語を指定するにはこのオプションを選択します。たとえば、アラビア語、トルコ語、タイ語およびヨーロッパ言語などのシングルバイト言語を指定するには、「シングルバイト」リストからこれらを選択します。
中国語(簡体字または繁体字)、日本語または韓国語などのマルチバイト言語を指定するには、「マルチバイト」言語からこれらを選択します。
ストップリスト: Oracle Textには、複数の単体言語についてストップリストがデフォルトで用意されています。デフォルトのストップリストがある場合、それが選択されています。いくつかの言語では、デフォルトのストップリストはありません。この属性に対して以前に作成された任意のストップリストを、ドロップダウン・リストから選択できます。次のタスクを実行できます。
ストップリストの編集: ストップリストを編集するには、をクリックします。ストップリスト・エディタが開きます。
ストップリストの追加: ストップリストを追加するには、をクリックします。ストップリスト・エディタが開きます。
トークン: トークンを選択した場合、デフォルトは次のとおりです。
ドキュメント当たりの最大数: 50 (デフォルト)
ドキュメント全体にわたる最大数: 3000 (デフォルト)
これらの値は変更できます。ドキュメント当たりおよびドキュメント全体のトークン数のカットオフはランキングを対象としたもので、トークンの絶対数を対象としていません。同順位がある場合、ドキュメント全体で3000を超えるトークンを持つことができます。
テーマ: テーマを選択した場合、デフォルトは次のとおりです。
ドキュメント当たりの最大数: 50 (デフォルト)
ドキュメント全体にわたる最大数: 3000 (デフォルト)
これらの値は変更できます。ドキュメント当たりおよびドキュメント全体のテーマ数のカットオフはランキングを対象としたもので、テーマの絶対数を対象としていません。同順位がある場合、ドキュメント全体で3000を超えるテーマを持つことができます。
テーマには「テーマ・タイプ」の指定が含まれます。デフォルトは、「シングル」です。「完全」を選択できます。
頻度: デフォルトは「条件頻度」です。「条件頻度 - IDF」を選択できます。
|
注意: 頻度の設定は保持されます。これを変更すると、変更した値がデフォルトになります。 |
単語出現頻度は、ドキュメント自身内の単語出現頻度を使用します。それは、コレクション情報を考慮に入れません。
単語出現頻度 - IDFは、従来のTF-IDFです。それは、ドキュメントからの情報(単語出現頻度)およびコレクションレベルの情報(IDFに加えて、コレクションに対して単語の全体の最大数が設定されている場合は使用する単語)を考慮に入れます。
TF-IDF (単語出現頻度-逆文書頻度)は、情報取得およびテキスト・マイニングで一般的に使用される重みです。この重みは、コレクション内のドキュメント対するワードの重要度を評価するための統計的な手法です。重要度はドキュメント内でワードが出現する回数に比例して増加しますが、コレクション内のワードの頻度によりオフセットされます。
ストップリスト・エディタでは、既存のストップリストの編集または新規ストップリストの作成が可能です。ストップリストは、すべてのワークフロー間で共有されます。このダイアログ・ボックスで、このノードで定義された変換に関連付けられているストップリストの他に、任意のストップリストを編集できます。
ストップリスト・エディタにアクセスするには、テキストの構築ノードをダブルクリックしてテキストの構築ノードの編集を開きます。ストップリストを表示、編集および作成する手順:
「ストップリストの編集」をクリックします。
ストップリスト・エディタが開きます。すべての変換に対するすべてのストップリストがリストされます。
ストップリストを追加するには、をクリックします。新規ストップリスト・エディタ・ウィザードが開きます。
既存のストップリストを変更するには、「カスタム・ストップリスト」リストからストップリストを選択します。
ストップリスト内の項目が下部ペインにリストされます。
ストップリストから項目を削除するには、項目を選択してをクリックします。
選択したリストにストップワードまたはストップテーマを追加するには、をクリックします。「ストップワード/ストップテーマの追加」ダイアログ・ボックスが開きます。
ストップリストを削除するには、それを「カスタム・ストップリスト」リストで選択してをクリックします。
新規ストップリスト・エディタ・ウィザードでは、次のタスクを実行できます。
新規ストップリストを作成します。ストップリストを作成するには、をクリックします。新規ストップリスト・ウィザードが起動します。このウィザードには次の2つのステップがあります。
既存のストップリストからワードを削除します。
複数のストップリストを結合して新しいストップリストを作成します。たとえば、ドキュメントがフランス語と英語の両方である場合、フランス語と英語のストップリストを結合できます。
すべてのストップワードおよびストップテーマを追加する空のストップリストを作成します。
ストップリストを定義するには、次の手順を実行します。
提供された名前をそのまま使用するか、別の名前を入力します。
デフォルトで選択されている「次のストップリストを拡張」は、既存のストップリストを結合および変更することで新規ストップリストの作成を可能にします。
拡張する1つ以上のストップリストを選択します。複数のストップリストを選択すると、これらが結合されます。
完全に新規のストップリストを作成するには、「空」を選択して、ストップリストの言語を選択します。デフォルトは英語です。
「次へ」をクリックします。
ストップワードおよびストップテーマを追加または削除するには、次の手順を実行します。
項目をストップリストに追加するには、をクリックします。「ストップワード/ストップテーマの追加」ダイアログ・ボックスが開きます。
ストップリストから項目を削除するには、それを選択してをクリックします。
完了後、「終了」をクリックします。
このダイアログ・ボックスでは、ストップワードおよびストップテーマをストップリストに追加します。
ストップワードを、カンマで区切って入力します。
作業を終了後、「OK」をクリックします。
テキストの構築ノードのプロパティでは、ノードで定義されているモデルに関する情報を表示および変更できます。「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
テキストの構築ノードの「プロパティ」ペインには、次のセクションがあります。
「テキスト作成ノードの編集」ダイアログ・ボックスで定義した変換を表示します。このタブで変換を編集できます。
テキストの構築ノードを右クリックします。次のセクションが表示されます。
編集。テキスト適用を編集します。「テキスト作成ノードの編集」ダイアログ・ボックスが開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
テキスト参照ノードでは、現在のワークフローまたは別のワークフロー内のテキストの構築ノードで定義されているテキスト変換を参照できます。
たとえば、テキスト・モデルを構築する1つのワークフロー(つまり、テキストの構築ノードを含むワークフロー)があり、最初のワークフローで作成されたモデルを適用する別のワークフローを作成する場合、テキスト参照を使用して、テキストの適用で必要とされるテキスト変換情報を提供できます。
この項では、次の項目について説明します。
テキスト参照ノードを作成する前に、ワークフローを作成します。次に、データ・ソースを特定または作成します。
テキストの構築ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
ワークフロー・エディタで「テキスト」を展開して、「テキスト参照」をクリックします。
ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。
GUIに、ノードには定義済のテキストの構築ノードへの参照がないことが示されます。
「テキスト参照ノードの編集」ダイアログ・ボックスに移動して、参照先のテキストの構築ノードを選択します。
ノードの使用準備が完了しました。それをテキストの適用ノードに接続します。テキスト参照ノードが、テキストの構築ノードのかわりに使用されます。
「テキスト参照ノードの編集」ダイアログ・ボックスでは、テキストの構築ノードを選択して、その変換を現在のワークフローの現在の位置で使用できるようにします。「テキスト参照ノードの編集」を開くには、次の手順を実行します。
ノードを右クリックし、「編集」を選択します。または、ノードをダブルクリックします。「テキスト参照ノードの編集」ダイアログ・ボックスには2つのペインがあります。
上部ペインで「選択」をクリックします。テキストの構築ノードの選択ダイアログ・ボックスが開きます。
テキストの構築ノードを選択すると、変換されたすべてのノードのトークンまたはテーマを表示できます。上部ペインで、変換されたノードを選択します。
下部ペインで、トークンおよびテーマ、およびその頻度が表示されます。検索を、トークンまたはテーマ(デフォルト)または頻度で実行できます。
「OK」をクリックします。
「ビルド・テキスト・ノードの選択」ダイアログ・ボックスで、現在のワークフロー(デフォルト)またはすべてのワークフロー内のテキストの構築ノードを選択できます。「表示」では、選択対象のテキストの構築ノードのリストを指定します。
「表示」フィールドで、「すべてのワークフロー」または「現在のワークフロー」(デフォルト)のいずれかを選択します。
「検索」フィールドで、プロジェクト(デフォルト)、ワークフロー、またはノードでテキストの構築ノードを検索できます。
「使用可能ノード」グリッドからテキストの構築ノードを選択します。それぞれのテキストの構築ノードについて、プロジェクト、ワークフローおよびステータスがグリッドに表示されます。
「OK」をクリックします。
|
注意: 完全ではないテキスト・ノードは選択できません。 |
テキストの構築ノードのプロパティでは、ノードで定義されているモデルに関する情報を表示および変更できます。ノードのプロパティを表示するには、ノードをクリックします。「プロパティ」ペインが閉じている場合は、「表示」に移動して「プロパティ」をクリックします。または、ノードを右クリックし、「プロパティに移動」をクリックします。
テキストの構築の「プロパティ」ペインには、次のセクションがあります。
テキスト参照ノードを右クリックします。次のセクションが表示されます。
編集。テキスト適用を編集します。「テキスト参照ノードの編集」が開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合に表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。